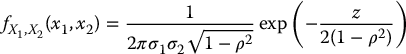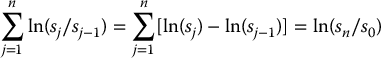Brownian motion is a very important stochastic process widely studied in probability and has been applied with success in many areas such as physics, economics and finance. Its name originates from botanist Robert Brown, who studied moving pollen particles in the early 1800s.
The first application of Brownian motion in finance can be traced back to Louis Bachelier in 1900 in his doctoral thesis titled Théorie de la spéculation. Then, physicist Albert Einstein and mathematician Norbert Wiener studied Brownian motion from a mathematical point of view. Later, in the 1960s and 1970s, (financial) economists Paul Samuelson, Fischer Black, Myron Scholes and Robert Merton all used this stochastic process for asset price modeling.
This part of the book (Chapters 14–20) is dedicated to the Black-Scholes-Merton model, a framework that laid the foundations of modern finance and largely contributed to the development of options markets in the early 1970s. The cornerstone of the model is a stochastic process known as Brownian motion and whose randomness drives stock prices.
Therefore, this chapter aims at providing the necessary background on Brownian motion to understand the Black-Scholes-Merton model and how to price and manage (hedge) options in that model. We also focus on simulation and estimation of this process, which are very important in practice.
Even if Brownian motion is a sophisticated mathematical object with many interesting properties, the role of this chapter is not to get overly technical but rather to understand the main properties and gain as much intuition as possible. More specifically, the objectives are to:
provide an introduction to the lognormal distribution;
compute truncated expectations and the stop-loss transform of a lognormally distributed random variable;
obtain a standard Brownian motion as the limit of random walks;
define standard Brownian motion and understand its basic properties;
relate the construction and properties of linear and geometric Brownian motions to standard Brownian motion;
simulate standard, linear and geometric Brownian motions to generate scenarios;
estimate a geometric Brownian motion from a given data set.
14.1 Normal and lognormal distributions
We begin this chapter with a primer on the normal distribution and the lognormal distribution.
14.1.1 Normal distribution
A random variable X is said to follow a normal distribution with mean and variance1 σ2 if its probability density function (p.d.f.) is given by
for all , or equivalently if its cumulative distribution function (c.d.f.) is given by
for all . In both cases, this is denoted by
In particular, a random variable Z is said to follow a standard normal distribution if μ = 0 and σ2 = 1 and this is denoted by . The p.d.f. and the c.d.f. of the standard normal distribution are given by
(14.1.1)
and
respectively. Because of the symmetry (around zero) of φ, we have that N(x) = 1 − N( − x), for all . The functions φ( · ) and N( · ) will be used very frequently in the following chapters. Figure 14.1 shows the p.d.f. (left panel) and c.d.f. (right panel) of the standard normal distribution.
Figure 14.1 Standard normal distribution (μ = 0 and σ2 = 1)
The notation emphasizes that probabilities are computed with the (actuarial) probability measure. This level of precision about the probability measure used is not crucial at this point but will become important for option pricing, as it was in the binomial model.
The normal distribution is also uniquely determined by its moment generating function (m.g.f.): if , then its m.g.f. (w.r.t. ) is given by
(14.1.2)
for all , and vice versa. Recall that the m.g.f. is a function of λ, while μ and σ2 are (fixed) parameters.
The normal distribution also has the following properties:
If , then . Conversely, if , then . This last transformation, from X to Z, is known as standardization. Hence, we deduce that
(14.1.3)
for all .
The normal distribution is additive: if and are independent, then .
Bivariate and multivariate normal distributions
We say that the couple (X1, X2) follows a bivariate normal distribution, or bivariate Gaussian distribution, if the bivariate p.d.f. of (X1, X2) is given by
where
for all .
The bivariate normal distribution is specified by five parameters: the means (μ1, μ2), the variances (σ21, σ22) and the correlation − 1 ⩽ ρ ⩽ 1. Indeed, we can deduce that and , and also that .
A multivariate normal distribution is defined similarly for a random vector (X1, X2, …, Xn). It is characterized by a vector of means and a covariance matrix. The multivariate normal distribution is also very important in modern portfolio theory to determine asset allocation.
14.1.2 Lognormal distribution
A random variable X is said to be lognormally distributed if Y = ln (X) follows a normal distribution. In other words, if Y follows a normal distribution then X = eY is said to follow a lognormal distribution. Note that this means that a lognormal random variable is a positive random variable.
More precisely, we say that X follows a lognormal distribution with parameters μ and σ2, which we will denote by
if . Then, its p.d.f. is given by
(14.1.4)
Figure 14.2 shows the p.d.f. (left panel) and c.d.f. (right panel) of a lognormal distribution. It should be clear that the lognormal distribution is not a symmetric distribution as is the normal distribution. Also, it puts no probability mass on the negative part of the real line.
Figure 14.2 Lognormal distribution with parameters μ = 0 and σ2 = 1
Example 14.1.1
Assume . Compute the following probability: .
First, taking the log on both sides, we can write
We know that . Then, standardizing Y, i.e. subtracting μ = −1 and dividing by to obtain a standard normal random variable , we can write
where we used the symmetry (around zero) of the standard normal distribution.
◼
We can generalize the calculations of the last example and identify the c.d.f. of a lognormally distributed random variable . Using equation (14.1.3), we see that it is simply given by
since, for x > 0, we have , where .
The lognormal distribution is not additive: if X1 and X2 are independent and lognormally distributed (possibly with different parameters), then we can not say that X1 + X2 is also lognormally distributed. However, it inherits the following two properties from the normal distribution:
If , then .
The lognormal distribution is multiplicative: if X1 and X2 are independent and lognormally distributed (possibly with different parameters), then X1 × X2 is also lognormally distributed.
Let us verify the second property. Assume that and are independent. This implies that and are also independent. Since the normal distribution is additive, we have that . Hence,
This last property will be very useful when dealing with geometric Brownian motion in Section 14.5.
Mean and variance
Computing the mean and variance of the lognormal distribution follows readily from the m.g.f. of the normal distribution as given in equation (14.1.2). Indeed, if , then and we can write
(14.1.5)
and
Finally, we deduce that
Note that we have not used the p.d.f. (nor the c.d.f.) of the lognormal distribution to compute these first two moments.
High order moments and moment generating function
It is easy to deduce that a lognormally distributed random variable X, with parameters μ and σ2, has moments of all orders: for any n ⩾ 1, we have
However, the m.g.f. of X does not exist, which means that we cannot write for a positive value of λ (this expectation does not exist). In fact, no matter the value of λ > 0, the integral
diverges. This means that the lognormal distribution is not uniquely determined by its moments.
Truncated expectations
In the following chapters, we will often compute truncated expectations of lognormally distributed random variables. This will be useful for option pricing in the Black-Scholes-Merton model.
Let us consider the following truncated expectation
where and where a > 0.
It is very tempting to immediately write down an integral using the p.d.f. of the lognormal distribution. Instead, let us use the fact that we can write X = eμ + σZ, where
Then, the truncated expectation can be rewritten as
(14.1.6)
To ease notation, let us set c = (ln (a) − μ)/σ and compute
The trick here is to complete the square: since we have that
then
Using this last equality together with (14.1.6), we can conclude that
Moreover, since , we can also write
where in the last step we used the symmetry of the standard normal distribution.
Stop-loss transforms
Recall that we defined in Chapter 6 the stop-loss function (x − a)+. Using its properties, we can write
The stop-loss transform2 of X, defined by , is thus
Finally, using the above calculations, we get the following identity:
(14.1.7)
This is the Black-Scholes formula in disguise. We will come back to this in Chapter 16.
14.2 Symmetric random walks
In this section, we provide the necessary background on (symmetric) random walks. It is the only discrete-time stochastic process we will consider in this chapter.
Let us consider a sequence of independent and identically distributed (iid) random variables {εi, i = 1, 2, …} whose common distribution is given by
We define the corresponding symmetric random walk (SRW)X = {Xn, n ⩾ 0} by X0 = 0 and, for n ⩾ 1, by
(14.2.1)
It is a discrete-time stochastic process. Figure 14.3 shows a path of a symmetric random walk up to time n = 10.
Figure 14.3 A symmetric random walk. At each time step, it moves upward or downward by 1 with equal probability 0.5
The term symmetric refers to the symmetry in the distribution of the εs: at each time step, the random walk moves up or down by a jump of magnitude 1, with equal probability 1/2. Indeed, for any n ⩾ 1, we have Xn − Xn − 1 = εn.
If the common distribution of the εs is not symmetric, then the random walk X = {Xn, n ⩾ 0} is said to be a non-symmetricrandom walk.
More generally, for times m and n such that 0 ⩽ m < n, the corresponding incrementXn − Xm is given by
We deduce easily that the increments of a SRW X = {Xn, n ⩾ 0} are independent (over non-overlapping time intervals) and stationary. More precisely,
for any m ⩾ 1 and 0 ⩽ n1 < n2 < … < nm, the random variables
are independent;
for any k, n ⩾ 1, the random variables Xn + k − Xk and Xn have the same distribution.
These two properties rely heavily on the fact that the εs are iid. Indeed, in the first case each increment is based on different εs whereas in the second case, both Xn + k − Xk and Xn are the sum of the same number of εs.
A SRW is a good model for the evolution of your wealth if you play a coin-toss game. Indeed, assume a fair coin is tossed repeatedly. Each time the coin ends up on heads (with probability 1/2), you win $1, otherwise you lose $1. Your gain/loss for the first toss (± 1) is modelled by ε1, the second one by ε2, etc. Therefore, Xn is the cumulative amount of gains/losses after n throws, i.e. your wealth after n tosses.
Random walks also play a key role in finance in the weak form of the efficient market hypothesis (EMH). If asset prices abide by this theory, an investor should not be consistently making profits by using past prices. As a result, asset prices should follow a (non-symmetric) random walk.
14.2.1 Markovian property
A SRW possesses the Markovian property, i.e. at each time step it depends only on the last known value, not on the preceding ones. Mathematically, for 0 ⩽ m < n,
for any , or equivalently
for any . Clearly, this comes from the fact that
No extra knowledge about ε1, ε2, …, εm is needed, except for the cumulative value Xm.
Said differently, if we want to predict the value of Xn (in the future) knowing the whole random walk up to time m (the present), only the knowledge of Xm is useful.
Consequently, for a function g( · ), we have
(14.2.2)
In particular, when m = n − 1, we have
Note that we do not need the random walk to be symmetric for it to be a Markov process.
14.2.2 Martingale property
A SRW possesses the martingale property, i.e. the prediction of a process in the future is given by its last known value. Mathematically, for 0 ⩽ m < n,
(14.2.3)
Since the SRW is also a Markov process, using (14.2.2), we can further write
Again, using the fact that Xn = Xm + ∑ni = m + 1εi and the linearity property of the conditional expectation, we further have
since ∑ni = m + 1εi is independent of Xm = ∑mj = 1εj and for each i. The fact that the random walk is symmetric is crucial for the martingale property.
Being a martingale, the coin toss game is said to be a fair game because the expected gain/loss at each coin toss (each one-step increment) is equal to zero.
It is important to understand that a stochastic process with the Markov property does not necessarily possess the martingale property. In particular, we know from equation (14.2.2) with g(x) = x that a Markov process X is such that
but this conditional expectation is not necessarily equal to Xm as in (14.2.3). We will encounter such a process in Section 14.5.3, namely geometric Brownian motion. The converse is also not true, meaning that a stochastic process that has the martingale property does not necessarily have the Markov property.
14.3 Standard Brownian motion
Brownian motion arises naturally as the limit of symmetric random walks. This section presents the construction of (standard) Brownian motion on that basis in addition to studying its properties. We will conclude the section by illustrating how to simulate a Brownian motion.
14.3.1 Construction as the limit of symmetric random walks
The symmetric random walk X = {Xn, n ⩾ 0} defined in equation (14.2.1) is a discrete-time stochastic process. To make it a continuous-time process, we can interpolate the trajectories or, even simpler, keep them constant in between time points. We will choose the latter option. More precisely, for each t ⩾ 0, set
where k is a non-negative integer. Note that for each t ⩾ 0, there is a unique such k: it is called the integer part of t and is often written as ⌊t⌋. In other words, we now have a continuous-time version of the SRW:
for each t ⩾ 1, while Xt = 0 for each 0 ⩽ t < 1. A sample path of this process is shown in Figure 14.4.
Figure 14.4 A symmetric random walk where the process is kept constant in between time steps
Our objective now is to see what happens (and what we would obtain) if we speed up this process, i.e. if we allow for more than one movement per unit time interval. If we want to have n movements per unit time interval, we can simply consider the process X(n) defined by
Indeed, between time 0 and time 1, the process makes n jumps:
In fact, this is the case for any unit time interval: for t ⩾ 0,
where ⌊n(t + 1)⌋ − ⌊nt⌋ = n. A sample path of the accelerated random walk X(2) is shown in Figure 14.5.
Figure 14.5 An accelerated symmetric random walk with n = 2
However, those n jumps are all of magnitude 1. We could keep on increasing n and see what happens at the limit, but we know from the Central Limit Theorem (CLT) that this is going nowhere. We must normalize the εs if we want to obtain some sort of convergence. Let us make this normalization depend on the number of jumps per unit time interval, that is let the process have jumps of magnitude .
We are now ready to identify the sequence of symmetric random walks that will converge to a standard Brownian motion. For each n ⩾ 1, we define the process W(n) = {W(n)t, t ⩾ 0} by
See the panels of Figure 14.6 for sample paths of W(1), W(2), W(4) and W(8).
Figure 14.6 Accelerated and rescaled symmetric random walks
For each fixed n, the continuous-time process W(n) = {W(n)t, t ⩾ 0} is a sort of (continuous-time) accelerated and rescaled symmetric random walk. When it moves, the process W(n) moves upward or downward with magnitude and equal probability 1/2. Consequently, for each fixed n, the increments of W(n) = {W(n)t, t ⩾ 0} are independent (over non-overlapping time intervals) and stationary. These properties are inherited from the underlying SRW X.
More precisely, we have:
for any m ⩾ 1 and 0 ⩽ t1 < t2 < … < tm, the random variables
are independent;
for any s, t ⩾ 0, the random variables W(n)t + s − W(n)t and W(n)s have the same distribution.
Note the similarities with the increments of X.
It is now time to take the limit when n goes to infinity. Since and , for each i ⩾ 1, we have that
for any n ⩾ 1 and t ⩾ 0.
From the CLT, we know that
converges to a -distributed random variable, as n goes to infinity. Let us denote this random variable obtained at the limit by W1. In other words, we have obtained
For any integer time t = k ⩾ 1, as
then, from the CLT, we have that
converges to a -distributed random variable, as n goes to infinity. Let us denote this random variable obtained at the limit by Wk, for each integer k ⩾ 1.
In general, at any real time t > 0, we will have that
converges to a -distributed random variable, as n goes to infinity, since
as n goes to infinity.3 Let us denote this random variable obtained at the limit by Wt, for each t > 0. Therefore, we have obtained: for all t > 0,
In conclusion, if we further set W0 = 0 and if we regroup the normal random variables Wt just obtained, then we have a continuous-time stochastic process W = {Wt, t ⩾ 0}. This process is called a standard Brownian motion. Luckily enough, this new process will also have independent and stationary increments.
14.3.2 Definition
Formally, the process W = {Wt, t ⩾ 0} we have just obtained is a standard Brownian motion (SBM), also known as a Wiener process. Mathematically, a standard Brownian motion is a continuous-time stochastic process issued from zero (W0 = 0), with independent and normally distributed (stationary) increments:
for all n ⩾ 1 and for any choice of time points 0 ⩽ t1 < t2 < … < tn, the following random variables are independent:
for all s < t, the random variable Wt − Ws has the same probability distribution as .
Figure 14.7 shows a sample path of a standard Brownian motion. We will explain in Section 14.3.6 how to generate such trajectories.
Figure 14.7 Sample path of a standard Brownian motion
This definition of standard Brownian motion follows directly from its construction as the limit of random walks, namely its increments over non-overlapping time intervals are independent and normally distributed.
Poisson process
The definition of a Brownian motion should be reminiscent of the definition of a Poisson process, well known in actuarial science. Indeed, a continuous-time stochastic process N = {Nt, t ⩾ 0} is said to be a Poisson process with rate λ if N0 = 0 and if it has the following additional properties:
for all n ⩾ 1 and for any choice of time points 0 ⩽ t1 < t2 < … < tn, the following random variables are independent:
for all s < t, the random variable Nt − Ns has the same probability distribution as Nt − s, i.e. a Poisson distribution with mean λ(t − s).
14.3.3 Distributional properties
From the definition of Brownian motion, we deduce that for each t > 0, the random variable Wt is normally distributed with mean 0 and variance t, i.e. for all ,
where and . Note that the variance (and the second moment) increases linearly with time.
Example 14.3.1
What is the probability that a Brownian motion is below − 1 at time 3.5?
We want to compute the following probability: . Since , then
◼
It is not enough to know the distribution of Wt at each time t to fully characterize a Brownian motion. We also need to specify the dependence structure. In fact, a standard Brownian motion is a Gaussian process, meaning that the random vector , extracted from this process, follows a multivariate normal distribution, for any choice of fixed times t1, t2, …, tn. In particular, for fixed times s and t, the joint normal distribution of (Ws, Wt) is characterized by its means, variances and its covariance function .
We already know that , for all t ⩾ 0. So, all that is left is to compute , for all s, t ⩾ 0, to fully specify the distribution of W. To compute the covariance function, we will rely on the properties of the increments.
First, note that
can be simplified to
since . Now, if we assume that s < t, then Wt − Ws is independent of Ws − W0 = Ws and we can write
By symmetry, if we assume that s > t, then we get . Consequently, we have obtained that
(14.3.1)
for all s, t ⩾ 0.
As a conclusion, the values taken by a Brownian motion at two different time points are not independent (the covariance is not equal to zero). That should have been expected since Ws is somewhat included inWt. Indeed, by definition of the approximating sequence of symmetric random walks, we had
Clearly, W(n)s and W(n)t are not independent. Since Ws and Wt can be obtained as the limits of W(n)s and W(n)t, they are also expected to be dependent, which is the case.
Example 14.3.2
What is the probability that a Brownian motion is below − 1 at time 3.5, knowing that it was equal to 1 at time 1.25?
We want to compute the following conditional probability: . Using the independence between W3.5 − W1.25 and W1.25, we can write
where we used the fact that the increment W3.5 − W1.25 follows a normal distribution with mean 0 and variance 2.25.
◼
14.3.4 Markovian property
A standard Brownian motion is a Markov process, i.e. for any 0 ⩽ t < T, we have
for all . In words, this means that the conditional distribution of WT given the history of the process up to time t is the same as its conditional distribution given Wt. Saying that a standard Brownian motion is a Markovian process means that for any fixed time t, knowing the value of the random variable Wt provides the same information as knowing the whole (truncated) trajectory Ws, 0 ⩽ s ⩽ t for the prediction of future values, in particular that of WT.
The Markovian property of a standard Brownian motion W = {Wt, t ⩾ 0} is also inherited from the same property for each W(n) = {W(n)t, t ⩾ 0} in the approximating sequence of accelerated and rescaled symmetric random walks.
Consequently, for a sufficiently well-behaved function g( · ), we can write
Note that the conditional expectation on the right-hand side is a function of Wt, so it is a random variable.
Building on the independence between WT − Wt and Wt, we can further write
(14.3.2)
Here is how to compute/understand the last expectation:
Consider x as a dummy variable and compute using the fact that , which will generate an expression in terms of x.
Set f(x) to be this expression computed in step 1).
Set .
Of course, the temporary function f and then the final expectation both depend on g. The following two examples will illustrate these steps.
Example 14.3.3
Let us compute using equation (14.3.2) with g(x) = x2.
The first step is to compute
where x is a dummy variable. Since , expanding the square, we get
which is, as announced, a function of x.
Now, we set f(x) = (T − t) + x2 and, finally, we have
As expected, this random variable is a function of Wt.
◼
It turns out that equation (14.3.2) is not vital in the previous example, but it will be quite handy in the following example.
Example 14.3.4
Let us compute using equation (14.3.2) with g(x) = (x)+ = max (x, 0).
The first step is to compute
where x is a dummy variable. Since , then
since y + x = (y + x)+ > 0 if and only if y > −x. Finally, since
we deduce that
We also have that 1 − N( − x) = N(x).
Now, we set
and, finally, we have
◼
14.3.5 Martingale property
Standard Brownian motion also inherits the martingale property from the approximating sequence of accelerated and rescaled symmetric random walks. More precisely, a standard Brownian motion W = {Wt, t ⩾ 0} is a martingale, i.e. for any 0 ⩽ t < T, we have
Note the resemblance with the condition in (14.2.3).
As W = {Wt, t ⩾ 0} is also a Markov process, we only need to show that
to verify that it is a martingale.
Once again, we will use the fact that WT = Wt + (WT − Wt) and the independence between WT − Wt and Wt. Using the linearity of conditional expectations, we can write
So, a standard Brownian motion is indeed a martingale.
Example 14.3.5
Let us verify that Mt = W2t − t, defined for each t ⩾ 0, is a martingale with respect to Brownian motion. In other words, we want to verify the following martingale property: for 0 ⩽ t < T, we want to have
Using the Markov property of Brownian motion, we already know that
and, by linearity of conditional expectations, we further have
Finally, from example 14.3.3, we already know that
Putting the pieces together yields the result.
◼
Sample path properties
Figure 14.7 seems to suggest that the trajectories of a Brownian motion are continuous (as functions of time) and it is indeed the case. However, it is beyond the scope of this book to provide a formal proof of the continuity of Brownian motion's paths.
Even though trajectories of a Brownian motion are continuous functions of time, they are nowhere differentiable. In other words, for each state of nature ω, the function t↦Wt(ω) is continuous but so irregular (it has spikes everywhere once we zoom in) that we cannot make sense of something like . This fact has huge mathematical consequences. From a modeling point of view, it means that we should be very careful when handling this stochastic process. In Chapter 15, we will come back to sample path properties of Brownian motion, as they motivate the definition of Ito's stochastic integral.
14.3.6 Simulation
For many applications in finance and actuarial science, simulations of Brownian motion trajectories over a given time interval [0, T] help generate stochastic scenarios of useful economic variables such as stock prices and interest rates (see also Chapter 19).
Since Brownian motion is a continuous-time stochastic process, it is impossible to simulate every Wt for every t ∈ [0, T] as this time interval is (uncountably) infinite. Instead, we choose n time points 0 < t1 < t2 < … < tn = T and simulate the random vector . This random vector is a discretized version of a Brownian motion trajectory over the time interval [0, T]. Of course, one should take n as large as possible. Simulation methods for continuous-time stochastic processes are often called discretization schemes.
To simulate a (discretized) path (W(0), W(h), W(2h), …, W((n − 1)h), W(T)) of a standard Brownian motion over the time interval [0, T], we make use of its definition. The algorithm is as follows:
We first choose n ⩾ 1 to divide the time interval [0, T] into smaller sub-intervals of the same size h = T/n: 0 < h < 2h < 3h < ... < (n − 1)h < T.
We define W(0) = 0 and then, for each i = 1, 2, …, n, we:
generate (see also section 19.1.3);
compute
The output is (W(0), W(h), W(2h), …, W((n − 1)h), W(T)), a sampled discretized trajectory of a standard Brownian motion, which is a synthetically generated realization of the random vector
Figure 14.8 gives two examples of such a discretized Brownian motion trajectory: the grey line is a trajectory with 100 time steps while the dotted line is a trajectory with 20 time steps.
Figure 14.8 Sample path of a discretized standard Brownian motion (SBM)
Even if we know that , for each i = 1, 2, …, n, we cannot simulate successively , then , and so on, with finally . Doing so would generate a sample of independent random variables and we know, from the above discussion, that the random vector has a multivariate normal distribution with dependence structure given by the covariance function in equation (14.3.1).
Example 14.3.6Simulation of a standard Brownian motion
Using a computer, you have generated the following four realizations from the standard normal distribution:
Using the random numbers in this order, let us generate a discretized sample path for a standard Brownian motion over the time interval .
We have n = 4 and and thus . Therefore, we define:
Then,
is the corresponding discretized trajectory of a standard Brownian motion. It is shown in Figure 14.9.
◼
Figure 14.9 Sample path of the standard Brownian motion depicted in example 14.3.6
14.4 Linear Brownian motion
Linear Brownian motion, also known as arithmetic Brownian motion or Brownian motion with drift, is obtained by transforming a standard Brownian motion using an affine function. In other words, a linear Brownian motion is a translated, tilted and stretched/dilated Brownian motion.
More precisely, for two constants and σ > 0, we define the corresponding linear Brownian motion, issued from , by X = {Xt, t ⩾ 0}, where
We call μ the drift coefficient and σ the volatility coefficient or diffusion coefficient of X.
The drift coefficient μ adds a trend, upward if μ > 0 or downward if μ < 0, while the volatility coefficient dilates (if σ > 1) or compresses (if σ < 1) the movements of the underlying standard Brownian motion. The effect of μ and σ on the Brownian motion is illustrated in Figure 14.10.
Figure 14.10 Sample paths of linear Brownian motions (black) along with the corresponding standard Brownian motion trajectories (grey)
14.4.1 Distributional properties
Because Xt is obtained as a linear transformation of Wt which is normally distributed, Xt is also normally distributed. For each t > 0, we have
We see that the mean increases (resp. decreases), as time goes by, at rate μ > 0 (resp. μ < 0) while the variance increases at rate σ2.
Example 14.4.1
What is the probability that a linear Brownian motion, issued from X0 = 0, with drift μ = −0.25 and with volatility σ = 0.1 is below − 1 at time 3.5?
We want to compute the following probability: , where
Since , we can write
◼
For fixed times 0 ⩽ s < t, we have
As the increment Wt − Ws is normally distributed with mean 0 and variance t − s, the increment Xt − Xs is also normally distributed but with mean μ(t − s) and variance σ2(t − s). Also, since the increments of a Brownian motion (over disjoint time intervals) are independent, and because a linear Brownian motion is just one affine transformation away from a standard Brownian motion, its increments are also independent.4
More precisely, a linear Brownian motion is (also) a stochastic process with independent and normally distributed (stationary) increments:
for all n ⩾ 1 and for all choice of time points 0 ⩽ t1 < t2 < … < tn, the following random variables are independent:
for all s < t, the random variable Xt − Xs has the same probability distribution as .
Example 14.4.2
For a linear Brownian motion starting at X0 = −2, with drift μ = 1 and diffusion σ = 3, calculate the probability that the process is below 10 at time 5 if it is already at 6.5 at time 2.
We need to compute . Subtracting X2 on both sides of the inequality, we obtain
as X5 − X2 is independent from X2.
Moreover, the increment X5 − X2 follows a normal distribution with mean 1 × (5 − 2) = 3 and variance 32 × (5 − 2) = 27. Therefore, the desired probability is
◼
Finally, we can compute the covariance of a linear Brownian motion at two different time points. Indeed, we have
14.4.2 Markovian property
Standard Brownian motion also transfers its Markovian property to linear Brownian motion X = {Xt, t ⩾ 0}. For any fixed times t and T such that 0 ⩽ t < T, we have
for all .
From the definition of linear Brownian motion, we know that Ws = σ− 1(Xs − X0 − μs), for all 0 ⩽ s ⩽ t. As a result, we quickly realize that conditioning on Xs, 0 ⩽ s ⩽ t is equivalent to conditioning on Ws, 0 ⩽ s ⩽ t.
In other words, saying that the linear Brownian motion X = {Xt, t ⩾ 0} is a Markov process also means that, for any 0 ⩽ t < T, we have
for all .
Consequently, to compute an expectation of the form
where t ⩽ T and where g( · ) is a function, we can rely on the algorithm behind equation (14.3.2). Indeed, since we can write
we are dealing with the same type of expectation.
Example 14.4.3
Let us compute , where 0 ⩽ t < T.
First, let us write
Using the linearity property of conditional expectations and expanding the square, we further have
where, in the last step, we used previously computed conditional expectations for standard Brownian motion (see the previous section).
◼
14.4.3 Martingale property
In general, linear Brownian motions are not martingales because they have a trend coming from the drift coefficient μ. However, when μ = 0, the corresponding linear Brownian motion takes the form Xt = X0 + σWt, for all t ⩾ 0. In this case, it is a martingale.
Formally, for t < T, we have
where, in the second last step, we used the fact that a standard Brownian motion is a martingale.
In conclusion, a linear Brownian motion X possesses the martingale property, i.e.
for all 0 ⩽ t < T, if and only if μ = 0.
14.4.4 Simulation
To simulate a (discretized) path (X(0), X(h), X(2h), …, X((n − 1)h), X(T)) of a linear Brownian motion with coefficients μ and σ over the time interval [0, T], there are two equivalent algorithms.
The first algorithm mimics the one for a standard Brownian motion:
We first choose n ⩾ 1 to divide the time interval [0, T] into smaller sub-intervals of the same size h = T/n: 0 < h < 2h < 3h < ... < (n − 1)h < T.
We define X(0) = X0 and then, for each i = 1, 2, …, n, we:
generate ;
compute
The output is (X(0), X(h), X(2h), …, X((n − 1)h), X(T)), a sampled discretized trajectory of a linear Brownian motion, which is a synthetically generated realization of the random vector
The second algorithm relies on the fact that we might have already simulated a standard Brownian motion, i.e. that we have generated
Then, we apply the corresponding transformation: for each i = 0, 1, …, n, we set
Again, the output is (X(0), X(T/n), X(2T/n), …, X((n − 1)T/n), X(T)) which is illustrated in Figure 14.11.
Figure 14.11 Sample path of a discretized linear Brownian motion
Example 14.4.4Simulation of a linear Brownian motion
Using the same random numbers as in example 14.3.6 (in the same order), we can generate a discretized sample path for a linear Brownian motion with drift μ = 2 and diffusion σ = 10, over the time interval . Assume the process starts at 0, i.e. that X0 = 0.
Again, we have n = 4, and . Therefore,
Then,
is the corresponding discretized trajectory of this linear Brownian motion. See Figure 14.12.
◼
Figure 14.12 Sample path generated in example 14.4.4
14.5 Geometric Brownian motion
A geometric Brownian motion is obtained by modifying a linear Brownian motion with an exponential function. More precisely, for two constants and σ > 0, we define the corresponding geometric Brownian motion (GBM), issued from S0 > 0, by S = {St, t ⩾ 0}, where
where X is a linear Brownian motion issued from X0 = ln (S0), with drift coefficient μ and volatility coefficient σ. Therefore, a GBM is a continuous-time stochastic process taking only positive values, which was not the case for standard and linear Brownian motions. Figure 14.13 illustrates three sample paths of geometric Brownian motions (with different parameters).
Figure 14.13 Sample paths of geometric Brownian motions (GBMs) with different parameters
14.5.1 Distributional properties
From the definition, we have that St is lognormally distributed, for each t > 0. Indeed, since we have
where
then
We deduce, from equation (14.1.5), that the mean (function) of a GBM is given by
We see that this mean increases (geometrically) with time if and only if .
Similarly, using the results of Section 14.1.2, we can compute the variance of a GBM (or any higher order moments):
Geometric Brownian motions have been used for decades as a mathematical model for the price of a risky asset. For example, GBM serves as a model for the stock price in the framework proposed by Black, Scholes and Merton (BSM). They are also used to generate economic scenarios in the banking and insurance industry.
Example 14.5.1
Assume a stock price evolves according to a GBM with parameters μ = 0.07 and σ = 0.3. The current stock price is S0 = 100. Assume the time unit is a calendar year. What is the probability that the stock price will be greater than $120 in 3 years from now?
We want to compute . We have
◼
From the definition, for 0 ⩽ t < T, we can write
As XT − Xt is normally distributed, then ST/St is lognormally distributed.
As opposed to standard and linear Brownian motions, the increments of a geometric Brownian motion are not independent nor stationary. However, since the increments of a linear Brownian motion (over disjoint time intervals) are independent and because a GBM is just an exponential transformation of a linear Brownian motion, then the relative increments of the GBM are independent.
More generally,
for all n ⩾ 1 and for all choice of time points 0 ⩽ t1 < t2 < … < tn, the following random variables are independent:
for all t < T, the random variable ST/St has the same probability distribution as .
From the properties of the relative increments of GBM, we can easily compute a conditional expectation of the form , where t < T. Indeed, we can write
because is independent of St (or equivalently of ). Consequently, since
because , we have that
(14.5.1)
As geometric Brownian motions are widely used to model asset prices, it is important to interpret this model from a financial standpoint. For t2 > t1, the random variable is the accumulation factor of $1 invested in S over the time interval [t1, t2]. Taking the logarithm of this accumulation factor, we get
the log-return of this asset, between time t1 and time t2.
Since the log-return has a normal distribution with mean μ(t2 − t1) and variance σ2(t2 − t1), μ can be interpreted as the mean annual log-return whereas σ is the annual volatility of the asset's log-returns.
14.5.2 Markovian property
Since geometric Brownian motion is one deterministic transformation away from standard Brownian motion (or linear Brownian motion), it is also a Markov process. This means that for any 0 ⩽ t < T, we have
for all .
As before, for a fixed t > 0, conditioning on Su, 0 ⩽ u ⩽ t is equivalent to conditioning on Xu, 0 ⩽ u ⩽ t or even Wu, 0 ⩽ u ⩽ t. Also, note that if we know the value of St, then we know the value of Wt, and vice versa. Consequently, for a GBM, the Markovian property can be restated as follows:
for all .
To compute an expectation of the form
where g( · ) is a function, we can rely on the algorithm based on equation (14.3.2). Again, since we can write
we are dealing with the same type of expectation.
We can also use more explicitly the fact that ST/St is independent of St and write
In this case, since knowing Wt is the same as knowing the value of St, we can compute this last expectation using the algorithm based on equation (14.3.2). This is illustrated in the following example.
Example 14.5.2
Let us compute , where t < T.
Following the previous methodology, we first compute
where x is a dummy variable. Since x > 0, using a property of the lognormal distribution, we have that . Therefore, we can apply the formula for the stop-loss transform of a lognormal distribution, as obtained in (14.1.7), and deduce that
with m = ln (x) + μ(T − t) and b2 = σ2(T − t). To conclude, we replace x by St in the last expression and then we obtain
◼
14.5.3 Martingale property
In general, geometric Brownian motions are not martingales because they have an exponential trend. Indeed, from equation (14.5.1), for 0 ⩽ t < T, we have
In other words, S satisfies the martingale property, i.e.
for all 0 ⩽ t < T, if and only if the parameters μ and σ are such that μ + σ2/2 = 0.
14.5.4 Simulation
As for linear Brownian motion, to simulate a (discretized) path (S(0), S(h), S(2h), …, S((n − 1)h), S(T)) of a geometric Brownian motion with coefficients μ and σ over the time interval [0, T], there are two equivalent algorithms.
The first algorithm is based on the properties of the relative increments:
We first choose n ⩾ 1 to divide the time interval [0, T] into smaller sub-intervals of the same size h = T/n: 0 < h < 2h < 3h < ... < (n − 1)h < T.
We define S(0) = S0 and then, for each i = 1, 2, …, n, we:
generate ;
compute
The output is (S(0), S(h), S(2h), …, S((n − 1)h), S(T)), a sampled discretized trajectory of a geometric Brownian motion, which is a synthetically generated realization of the random vector
The second algorithm relies on the fact that we might have already simulated a standard Brownian motion (or a linear Brownian motion), i.e. that we have generated
Then, we apply the corresponding exponential transformation: for each i = 0, 1, …, n, we set
Again, the output is a realization of the random vector (S0, Sh, S2h, …, S(n − 1)h, ST).
Example 14.5.3Simulation of a geometric Brownian motion
A stock currently trades for $100 and its mean annual log-return is 7% whereas its volatility is 25%. Using the random numbers from example 14.3.6 (in the same order), we can generate a discretized sample path for this geometric Brownian motion over the time interval .
Again, we have n = 4, and . Furthermore, we have S0 = 100, μ = 0.1 and σ = 0.25. Therefore,
Then,
is the corresponding discretized trajectory of this geometric Brownian motion. It is shown in Figure 14.14.
◼
Figure 14.14 Sample path of the geometric Brownian motion depicted in example 14.5.3
14.5.5 Estimation
Given the importance of GBM in financial and actuarial applications, a natural question arises: how should/can we determine the values of μ and σ given asset price data?
Assume that the time unit is a calendar year and that data is collected periodically (weekly, daily,5 hourly, etc.) at each time step of length h for a total of T years. Overall, we will have n = T/h observations. For example, if h = 1/12 and we collect T = 10 years of data, then we have a total of n = 120 observations.
The idea is to capitalize on the fact that the relative increments of a GBM are independent and identically distributed according to a lognormal distribution. Said differently, the random variables
are independent and distributed according to the same normal distribution: for all j = 1, 2, …, n, we have
For example, if μ and σ are annual parameters and if we collect monthly data for n consecutive months, i.e. if we have realized values for ln (Sj/12/S( j − 1)/12), where j = 1, 2, …, n, then these log-returns are drawn from a normal distribution with mean μ × 1/12 and variance σ2 × 1/12.
Fortunately, estimating parameters of a normal distribution is straightforward. We will estimate the parameters μ and σ2 using maximum likelihood estimation. Recall that the maximum likelihood estimators (MLEs) of the mean and the variance of a normal distribution are given by the sample mean and the sample variance. More precisely, if we have the following observations
and if we set xj = ln (sj/sj − 1), for each j = 1, 2, …, n, then the MLEs and , of μ and σ respectively, are given by
where and . Recall that s2x is a biased estimator for the variance of the xis but this bias decreases quickly for large samples. If one is concerned with such bias, one could replace s2x by
Example 14.5.4Maximum likelihood estimation of GBM
Assume that you have the following monthly data for the stock price of ABC inc.:
Date
Price
December 31st, 2015
51
January 31st, 2015
54
February 28th, 2015
61
March 31st, 2015
53
April 30th, 2015
49
In practice, the analyst would use the closing price of the asset at the end of the last trading day of any given month. Let us compute the MLE estimates of μ and σ corresponding to these observations.
We have n = 4 and h = 1/12. From our sample (s0, s1, s2, s3, s4) = (51, 54, 61, 53, 49) of prices, we must compute the corresponding sample of continuously compounded monthly log-returns: xj = ln (sj/sj − 1), for each j = 1, 2, 3, 4. And then we must compute the sample mean and sample variance.
The log-returns observed over each month are given in the following table:
Month
Log-return
January
February
March
April
The sample mean and variance are
Then, we easily obtain the following MLE estimates for the parameters:
◼
From the properties of the log function, we know that
and thus the MLE of μ can be further simplified as
Precision of the MLE for the drift
Although the computation of the MLE for μ is straightforward, it remains that is an imprecise estimator. Given that T = nh, then
No matter how frequently we collect data (how small h is), the variability of only decreases linearly with T, the number of years of data. For example, if we know that σ = 0.25, then 10 years of data implies that the 95% confidence interval around μ is which is very large when the mean annual log-return is typically μ ∈ [ − 0.2, 0.2]. The lesson here is that T needs to be large for the estimator of the drift to be precise.
14.6 Summary
Normal distribution
Notation: , with and .
Probability density function:
Cumulative distribution function of the standard normal distribution: N(z).
Standardization: if , then .
Cumulative distribution function of :
Moment generating function: .
Lognormal distribution
Notation: .
Representation: X = eY where .
Cumulative distribution function:
Expectation and variance:
Truncated expectations: for a > 0,
Stop-loss transforms: for a > 0,
Symmetric random walk
Jumps: independent εis such that .
Symmetric random walk: {Xn, n ⩾ 0} such that X0 = 0 and Xn = ∑ni = 1εi.
Properties of the increments:
for m ⩾ 1 and 0 ⩽ n1 < n2 < … < nm, the random variables
are independent;
for k, n ⩾ 1, the random variables Xn + k − Xk and Xn have the same distribution.
Markov property: for 1 ⩽ m < n,
Martingale property: for 0 ⩽ m < n,
Standard Brownian motion
Construction: limit of accelerated and rescaled symmetric random walks.
Definition: a process W = {Wt, t ⩾ 0} is a standard Brownian motion if
–W0 = 0;
–for all n ⩾ 1 and 0 ⩽ t1 < t2 < … < tn,
are independent;
–for all s < t, Wt − Ws has the same distribution as .
Mean function: , for all t ⩾ 0.
Variance function: , for all t ⩾ 0.
Dependence structure: , for all s, t ⩾ 0.
Markov property: for 0 ⩽ t < T,
Martingale property: for 0 ⩽ t < T,
Simulation: choose n, set h = T/n and set W(0) = 0, and then, for each i = 1, 2, …, n, generate and compute .
Linear Brownian motion
Definition: a linear Brownian motion with drift μ and diffusion σ is defined by
Distribution: .
Mean function: , for all t ⩾ 0.
Variance function: , for all t ⩾ 0.
Increments: independent and stationary, i.e.
–for all n ⩾ 1 and 0 ⩽ t1 < t2 < … < tn,
are independent;
– for all s < t, Xt − Xs has the same distribution as .
Markov property (with respect to W): for 0 ⩽ t < T,
A linear Brownian motion is a martingale if and only if μ = 0.
Simulation: choose n, set h = T/n and set X(0) = X0, and then, for each i = 1, 2, …, n, generate and compute .
Geometric Brownian motion
Definition: a geometric Brownian motion with parameters μ and σ is defined by
Distribution: .
Mean function: , for all t ⩾ 0.
Variance function: , for all t ⩾ 0.
Relative increments are independent and stationary, not the usual increments.
Markov property (with respect to W): for 0 ⩽ t < T,
A geometric Brownian motion is a martingale if and only if .
Simulation: choose n, set h = T/n and set S(0) = S0, and then, for each i = 1, 2, …, n, generate and compute .
Estimation: for a time step h and a sample {s0, s1, s2, …, sn}, then the MLEs for μ and σ are given by
where and s2x are the sample mean and the sample variance of xj = ln (sj/sj − 1), j = 1, 2, …, n.
14.7 Exercises
For and a constant a, compute using the properties of stop-loss functions.
A particle is randomly moving over one dimension according to a standard Brownian motion.
On average after ten periods, where will the particle be?
After five periods, you find the particle is located at −3. Where do you expect the particle to be five periods later?
In (b), what is the probability that the particle is above zero five periods later (given that after five periods, it is located at −3)?
Compute the following quantities:
;
;
;
;
.
Consider a random variable . For each t ⩾ 0, set . Argue that the stochastic process {Xt, t ⩾ 0} has continuous trajectories and verify that for each fixed t ⩾ 0, the random variable Xt follows a distribution. Is {Xt, t ⩾ 0} a standard Brownian motion? Justify your answer.
Let {Wt, t ⩾ 0} and be two independent standard Brownian motions and let ρ be a fixed number between 0 and 1. For each t ⩾ 0, set . Is {Xt, t ⩾ 0} a standard Brownian motion? Justify your answer.
Fix λ > 0. Verify that the stochastic process {Bt, t ⩾ 0}, defined by
is also a standard Brownian motion.
Verify that {Mt, t ⩾ 0}, defined by
is a martingale.
You just bought a vintage car for $20,000. Assume its future value can be modeled by a geometric Brownian motion with parameters μ = −0.14 and σ = 0.07.
What is its value expected to be in 4 years from now? What about its median value?
What is the probability that its price in 4 years will be greater than $20,000?
How much time must elapse so that the expected market value of the car corresponds to $1,000?
You have observed the following (annual) values for what you assume is a geometric Brownian motion: S0 = 100, S1 = 98, S2 = 100, S3 = 101, S4 = 105 and S5 = 104.
Compute the corresponding estimates for μ and σ2, given on an annual basis.
If your data were observed monthly instead of annually, how would your estimates be affected?
Using a computer, you have sampled the following normal random numbers: 0.9053, 1.4407, −1.0768, −1.3102, 0.0302. Using a time step h = 0.2, generate a sample a path for:
a standard Brownian motion;
a linear Brownian motion with X0 = 0, μ = 0.07, σ = 0.3;
a geometric Brownian motion with S0 = 100, μ = 0.07, σ = 0.3.
Consider a geometric Brownian motion given by St = S0exp (μt + σWt), for each t ⩾ 0.
For a fixed number a, verify that
For fixed numbers 0 < t < T, verify that
Identify the probability distribution of the following random variable:
Exercises 14.4 and 14.5 have been inspired by two exercises from Geneviève Gauthier, with her permission.