
Chapter 4
Exploring the Seafloor with Underwater Robots
Rafael Garcia1, Nuno Gracias1, Tudor Nicosevici1, Ricard Prados1, Natalia Hurtos1, Ricard Campos1, Javier Escartin2, Armagan Elibol3, Ramon Hegedus4 and Laszlo Neumann1
1Computer Vision and Robotics Institute, University of Girona, Girona, Spain
2Institute of Physics of Paris Globe, The National Centre for Scientific Research, Paris, France
3Department of Mathematical Engineering, Yildiz Technical University, Istanbul, Turkey
4Max Planck Institute for Informatics, Saarbruecken, Germany
4.1 Introduction
The ocean covers nearly 75% of our planet. Surprisingly, humans have explored a very small fraction of this unbelievably vast extent of the globe. The main reason for this is that the deep sea is a hostile environment, with absence of light and extreme pressures, making the ocean a dangerous place for human beings. Therefore, deep sea exploration, beyond the capacity of human divers, requires the use of underwater vehicles. Initially, such vehicles were operated by a pilot while carrying one or more scientists. Since all these manned submersibles have hovering capabilities, a skilled pilot would be able to survey the seafloor at very low altitude (i.e., distance from the vehicle to the seafloor) while studying target areas. Having the pilot on the survey loop allows real-time re-planning of the survey depending on the interests of the onboard scientists. However, human-operated vehicles have the limitation of restricted diving time (as a function of battery life, and air reserves for the crew).
These limitations have led to the development of unmanned underwater vehicles (UUVs), which represent a safer alternative since no human personnel need to dive into the ocean. UUVs can be classified into remotely operated vehicles (ROVs) and autonomous underwater vehicles (AUVs). ROVs are connected to a mother vessel through a tether, from which a pilot operator remotely controls the vehicle. The tether provides both control feedback signals and power, allowing real-time control and mission re-planning for the scientists. However, one of the greatest disadvantages of ROVs is the fact that the tether is generally affected by water currents, which in turn affects the motion of the vehicle. In addition, when working at depths beyond 500 m, the ship requires a tether management system (TMS),which acts as a “garage” to eliminate the effect of drag of the long length of umbilical attached to the ROV, increasing the design and operational complexity of the ship. Moreover, such vehicles require the supporting vessel to move in coordination with the ROV; thus, the ship should be equipped with dynamic positioning systems to automatically maintain its position and heading, which involves additional expenses associated with the cost of ship time.
AUVs do not require a pilot, nor do they require a tether. Therefore, they can be launched from smaller (and less expensive) vessels. AUVs are usually pre-programmed to carry out a specific trajectory. Their diving time is limited only by the autonomy of the on-board batteries, which often allow them to work for at least a whole day. Some AUVs are connected to the mother ship by means of an ultrasound link, providing communications and positioning cues (e.g., through an ultra short base line (USBL), while other AUVs navigate fully autonomously. As such, AUVs need to make their own decisions, within the mission parameters, based on the readings of the on-board sensors and their control architecture, without the (useful) feedback and decisions of a human operator. Due the aforementioned reasons, most AUVs are nowadays employed mostly for bathymetric mapping of the ocean floor (i.e., using a multibeam sonar to obtain a 2.5D digital terrain model of the seafloor). This allows the robot to travel at a relatively safe altitude—from 50 to 100 m above the ocean floor. In some cases, AUVs may also carry a side-scan sonar that aims to provide an understanding of the different types of textures and materials present on the seafloor. In such cases, the AUV needs to travel at lower altitude (between 10 and 15 m), increasing the associated risks.
Acquiring optical images with an AUV is an even more dangerous endeavor since the robot needs to get very close to the seafloor, which may lead to accidents that range from hitting the seafloor to being trapped by a fishing net. Most commercial AUVs nowadays typically navigate at 1.5–3 knots and do not have hovering capabilities (i.e., remaining in one place while keeping constant altitude). This makes them adequate for bathymetric mapping, and it also limits their capabilities for safely acquiring optical images. However, some scientific AUVs are able to move at much lower speeds, while others are even able to hover—for example, Seabed (WHOI) or Girona-500 (UdG)—enabling them to travel at very low altitudes (less than 2 m). These types of AUVs are, thus, more adequate for visual data acquisition.
4.2 Challenges of Underwater Imaging
When acquiring images of the ocean floor, the main challenges are caused by the special transmission properties of the light in the underwater medium (Wozniak and Dera 2007). The interaction between the light and the aquatic environment includes basically two processes: absorption—where light is gradually attenuated andeventually disappears from the image-forming process; scattering—a change in the direction of individual photons, mainly due to the various particles suspended in water. These transmission particularities of this medium result in additional challenges in underwater imaging, such as blurring of image features, limited range due to light absorption, clutter, and lack of structure in the regions of interest. Sometimes, small floating particles create a phenomenon called “marine snow” (essentially a backscattering effect), which makes image processing even more challenging.
Additionally, natural light is often not sufficient for imaging the sea floor. In such cases, one or more light sources are usually attached to the submersible, providing the necessary lighting. Such light sources, however, might increase the backscattering effect and tend to illuminate the scene in a nonuniform manner (producing a bright spot in the center of the image with a poorly illuminated area surrounding it). Moreover, the motion of the light source creates a shift of the shadows induced in the scene, generating a change in the brightness pattern as the vehicle moves. For this reason, application of standard computer vision techniques to underwater imaging requires first dealing with these inherent challenges (see Figure 4.1).

Figure 4.1 (a) Example of backscattering due to the reflection of rays from the light source on particles in suspension, hindering the identification of the seafloor texture. (b) Image depicting the effects produced by light attenuation of the water resulting in an evident loss of luminance in the regions farthest from the focus of the artificial lighting. (c) Example of the image acquired in shallow waters showing sunflickering patterns. (d) Image showing a generalized blurred appearance due to the small-angle forward-scattering phenomenon

Figure 4.2 Refracted sunlight creates illumination patterns on the seafloor, which vary in space and time following the dynamics of surface waves
In summary, numerous challenges need to be addressed when dealing with underwater vision: light scattering, light absorption, color shifts since absorption happens as a function of wavelength, shape distortions, visibility degradation, blurring effects, and many others. Among these many other situations, a good example would be sunflicker. This effect is produced when acquiring images of the seafloor in shallow waters on sunny days. In this situation, the images suffer from strong light fluctuations due to refraction, corrupting image appearance and altering human perception of the scene. These artifacts are caused by the intersection of the sunlight rays with the water surface waves and appear in the image as bright stripes that change quickly in both space and time (see Figure 4.2). Refracted sunlight generates dynamic patterns, which degrade the image quality and the information content of the acquired data. Therefore, the sunflickering effect creates a difficult challenge to any image processing pipeline, affecting the behavior of further image processing algorithms (mosaicing, segmentation, classification, etc.). For this reason, the development of online techniques to reduce or eliminate these artifacts becomes crucial in order to ensure optimal performance of underwater imaging algorithms (Gracias et al. 2008; Shihavuddin et al. 2012).

Figure 4.3 Scheme of underwater image formation with natural light as main illumination source. The signal reaching the camera is composed of two main components: attenuated direct light coming from the observed object and water-scattered natural illumination along this propagation path. Attenuation is due to both scattering and absorption
4.3 Online Computer Vision Techniques
4.3.1 Dehazing
Since underwater image processing has first to deal with the challenging processes described earlier, several image enhancement and restoration techniques have been proposed in the past few years. The term dehazing originates from the scientific literature that addresses restoration of images compromising atmospheric haze, which is essentially an effect of light scattering. Later this term, albeit somewhat inaccurately, developed a broader usage by denoting a similar image restoration scheme in other scenarios such as enhancement of underwater images. The underlying image formation model is based on single scattering with a single and unidirectional illumination source as depicted in Figure 4.3. Excluding absorption, in such a scheme (Bohren and Clothiaux, 2006) it can be shown that the wavelength-dependent radiance reaching the observer from a distant object in the presence of molecular/particulate scatterers can be formulated by a simple formula that clearly expresses the observed radiance ![]() being the sum of two components: the attenuated light coming from the object situated at distance
being the sum of two components: the attenuated light coming from the object situated at distance ![]() and the veiling light, that is, light scattered by all the molecules and particles along the line of sight between the object and observer.
and the veiling light, that is, light scattered by all the molecules and particles along the line of sight between the object and observer. ![]() , where
, where ![]() is the direct scene radiance transmitted from the object and
is the direct scene radiance transmitted from the object and ![]() is the veiling light parameter, which means the radiance that could be measured when source illumination scattered into the line of sight through an infinite optical depth and
is the veiling light parameter, which means the radiance that could be measured when source illumination scattered into the line of sight through an infinite optical depth and ![]() is the transmission. In the most general case, transmission is given by the following expression:
is the transmission. In the most general case, transmission is given by the following expression: ![]() , where
, where ![]() is the extinction coefficient characteristic at distance
is the extinction coefficient characteristic at distance ![]() ,
, ![]() is the wavelength, and
is the wavelength, and ![]() is the distance of the observed object. In general, the extinction coefficient is the sum of scattering and absorption coefficients. As for atmospheric image restoration cases, the effect of absorption can be deemed negligible (although this is only true in the presence of haze proper, but not in the case of dense fog, e.g., when absorption plays a major role). Hence, in this scheme, attenuation of the direct light from the observed object is merely due to scattering. The
is the distance of the observed object. In general, the extinction coefficient is the sum of scattering and absorption coefficients. As for atmospheric image restoration cases, the effect of absorption can be deemed negligible (although this is only true in the presence of haze proper, but not in the case of dense fog, e.g., when absorption plays a major role). Hence, in this scheme, attenuation of the direct light from the observed object is merely due to scattering. The ![]() integral is called the optical depth, which is thus the natural-scale factor of the hazing phenomenon. In dehazing methods, it is usually assumed that the scattering coefficient is constant across the field of view and the line of sight, so that transmission becomes as simple as
integral is called the optical depth, which is thus the natural-scale factor of the hazing phenomenon. In dehazing methods, it is usually assumed that the scattering coefficient is constant across the field of view and the line of sight, so that transmission becomes as simple as ![]() . This simplification carries the underlying assumption that the distribution of various scattering particles within the volume of the environment falling in the observer's field of view would be homogeneous. This may be more or less justified in a terrestrial scene, especially with a narrow field of view it seems reasonable to assume a spatially invariant scattering coefficient in a hazy atmosphere. The advantage of such a simple model is obvious: if a per-pixel depth map of the scene were known, then only a handful of unknown parameters remain, the estimation of which would presumably lead to a good restoration of the image. However, in reality, and this applies a fortiori to the underwater environment, the image formation is more subtle and complicated. First of all, within the water medium one should not neglect absorption, which has a different spectral behavior compared to that of scattering (see Figure 4.4). In this aspect, one of the inherent problems in underwater imaging is that due to the high absorption of water in the visible red spectral range, sometimes there is simply no signal recorded in the red-filtered pixels of a camera for anything but the closest objects. Another complication is that in a hazy atmosphere, Rayleigh scattering is the singlemost dominant factor creating the veiling effect on scene objects, whereas in seawater usually there is a significant concentration of floating particles exhibiting Mie scattering. As a consequence, there can be a wide variety of scatterers present bearing different characteristics (spectral and angular dependence) on the scattering process, with a possibly inhomogeneous distribution. On top of these, multiple scattering cannot be neglected, either. For further details, we refer the reader to Mobley (1994). Considering only a couple of such factors, the image formation model quickly becomes so complex that it becomes impossible to use it for any kind of reverse-engineering, what one would wish for by performing underwater image enhancement. Therefore, it is not for chance that the above-mentioned simple image formation model is directly or indirectly used in most dehazing approaches, as this level of model complexity is still tractable, despite its limited validity.
. This simplification carries the underlying assumption that the distribution of various scattering particles within the volume of the environment falling in the observer's field of view would be homogeneous. This may be more or less justified in a terrestrial scene, especially with a narrow field of view it seems reasonable to assume a spatially invariant scattering coefficient in a hazy atmosphere. The advantage of such a simple model is obvious: if a per-pixel depth map of the scene were known, then only a handful of unknown parameters remain, the estimation of which would presumably lead to a good restoration of the image. However, in reality, and this applies a fortiori to the underwater environment, the image formation is more subtle and complicated. First of all, within the water medium one should not neglect absorption, which has a different spectral behavior compared to that of scattering (see Figure 4.4). In this aspect, one of the inherent problems in underwater imaging is that due to the high absorption of water in the visible red spectral range, sometimes there is simply no signal recorded in the red-filtered pixels of a camera for anything but the closest objects. Another complication is that in a hazy atmosphere, Rayleigh scattering is the singlemost dominant factor creating the veiling effect on scene objects, whereas in seawater usually there is a significant concentration of floating particles exhibiting Mie scattering. As a consequence, there can be a wide variety of scatterers present bearing different characteristics (spectral and angular dependence) on the scattering process, with a possibly inhomogeneous distribution. On top of these, multiple scattering cannot be neglected, either. For further details, we refer the reader to Mobley (1994). Considering only a couple of such factors, the image formation model quickly becomes so complex that it becomes impossible to use it for any kind of reverse-engineering, what one would wish for by performing underwater image enhancement. Therefore, it is not for chance that the above-mentioned simple image formation model is directly or indirectly used in most dehazing approaches, as this level of model complexity is still tractable, despite its limited validity.

Figure 4.4 Absorption and scattering coefficients of pure seawater. Absorption (solid line (a)) and scattering (dotted line (b)) coefficients for pure seawater, as determined and given by Smith and Baker (1981) and
reproduced from Mobley (1994)
In order to put the single-scattering model to work, we see that it is crucial to have a scene depth estimation. Early methods of dehazing primarily rely on additional depth information or multiple observations of the same scene. Schechner et al. (2001) and Schechner and Karpel (2005) exploit the fact that the scattered veiling light (in both the atmosphere and underwater) is partially polarized, whereas the direct light coming from the object can be considered practically unpolarized. Hence, if per-pixel polarization data are acquired from the scene, one can separate well the direct and veiling signals. Based on this observation, they developed a quick method to reduce the veiling effect by using two images taken through a polarizer at different angles. Narasimhan and Nayar (2002 2003) propose a physics-based scattering model, using which the scene structure can be recovered from two or more weather images. Kopf et al. (2008) propose to dehaze an image by using the scene depth information directly accessible in georeferenced digital terrain and urban models. The inherent limitation of these approaches is that they require multiple, geometrically registered images of the same scene and/or special optical elements beyond a simple camera–lens combination. Hence, they are not usable on an arbitrary image or video footage acquired in scattering media. Furthermore, by relying on extra measurement/data, the applied technique may impose additional unknown parameters into the model used for image enhancement. For instance, polarization can provide valuable information about the veiling light component even though the degree of its partial polarization is not known a priori; it can be highly wavelength-dependent and, in general, it is a function of the scattering process.
In recent years, a new concept called Single Image Dehazing has emerged. Under this concept, novel algorithms have been proposed that attempt to carry out image restoration (in both terrestrial and underwater imaging) without requiring any additional information. This is a highly desired procedure since no other equipment is needed, apart from a standard camera, to acquire images. However, restoring the original scene to its true colors from a single image is a heavily underconstrained problem due to the fact that both attenuation of the object-reflected light and the intensity of the additional veiling light are dependent on the optical depth of the given object (Schechner and Karpel 2004). Consequently, such an ill-posed problem can only be resolved by imposing additional constraints through exploiting natural limits of the physical phenomena themselves, invariances, and statistics of certain natural image features. Extracting and leveraging these constraints also implies the need for sophisticated algorithms, often with a significant computational cost, such as image-matting methods, independent component analysis, or Markov random fields.
Fattal (2008) proposes an image formation model that accounts for surface shading and scene transmission. Under the assumption that the two functions are locally statistically uncorrelated, a haze image can be broken into regions of constant albedo, from which the scene transmission can be inferred. Tan (2009) proposes to enhance the visibility of a haze image by maximizing its local contrast. He et al. (2009) present an approach introducing the dark channel prior. This prior comes from an observation that most local patches in haze-free images often contain some low intensity, almost completely dark pixels. Ancuti et al. (2011) improved upon the dark channel prior method comparing the hue of the original image with the hue of the inverse image to estimate the airlight color and applying a layer-base dehazing technique. Tao et al. (2012) also extended the dark channel method considering the influence of multiple scattering in the atmosphere. This method needs the evaluation of the atmospheric point spread function and includes convolution and deconvolution steps, which increase the computational time. Kratz and Nishino (2009) model an image as a factorial Markov random field, in which the scene albedo and depth are two statistically independent latent layers. A canonical expectation maximization algorithm is implemented to factorize the image. Kratz's method can recover a haze-free image with fine edge details; however, it has high computational costs. Tarel and Hautiere (2009) present a single image dehazing algorithm that has the main advantage of speed: its complexity is a linear function of the number of image pixels. The method is controlled only by a few parameters and consists of atmospheric veil inference, image restoration and smoothing, and tone mapping. Luzon-Gonzalez et al. (2015) propose an image enhancement method that works in several adverse weather conditions based on the RGB response ratio constancy under illuminant changes. Their algorithm restores visibility, contrast, and color in degraded images with low computational times.
As for single image dehazing methods in the underwater environment, they mostly reiterate the ideas developed for atmospheric cases, with some variations. Carlevaris-Bianco et al. (2010) proposed an underwater dehazing algorithm using a prior based on the difference in attenuation among the different color channels, which allows for estimating the per-pixel scene depth. Then the scene radiance is recovered from the hazy image by modeling the true scene radiance as a Markov random field using the estimated depth map. Ancuti et al. (2012) developed a multiresolution method based on image fusion principles. They define two inputs that represent color-corrected and contrast-enhanced versions of the original underwater image and the associated weight maps for the fusion process, which evaluate several image qualities by specifying spatial pixel relationships. Chiang and Chen (2012) introduced a novel approach to enhance underwater images by compensating the attenuation discrepancy along the propagation path, which also takes the influence of the possible presence of an artificial light source into account. They evaluated the performance of their algorithm utilizing ground-truth color patches and have shown results with significantly enhanced visibility and good color fidelity. Serikawa and Lu (2013) also use a simple prior based on the difference in attenuation among the different color channels and estimate the depth map through the red-colored channel in underwater images. They propose to apply fast joint trilateral filtering on the depth map, forachieving an edge-preserving smoothing with a narrow spatial window in only a few iterations. Hitam and Awalludin (2013) present a method called mixture contrast limited adaptive histogram equalization (CLAHE). The method operates CLAHE on RGB and HSV color spaces, and the results are combined together using Euclidean norm. Anuradha and Kaur (2015) focus on the problem of uneven illumination often encountered in the underwater environment that is usually neglected in previous works. They propose a new LAB-color-space- and CLAHE-based image enhancement algorithm and they use image gradient-based smoothing to account for the illumination unevenness within the scene. They improve the performance of the underwater image enhancement techniques that utilize CLAHE.
From the recent literature, one can observe that single image dehazing remains a very much researched topic and particularly for underwater scenes there is definitely room for improvement. We can mainly distinguish two different approaches in the currently available techniques:
- 1. Physics-based algorithms, which aim at recovering per-pixel object radiance directly from an equation that models attenuation of the object signal and backscattered veiling light, according to a scheme identical or similar to Figure 4.3 and using certain priors that help estimation of unknown parameters.
- 2. Nonphysical algorithms, which rather attempt to enhance/change certain properties of the image, such as color balance and contrast, so that it looks less affected by the attenuation/scattering phenomena in the medium and provides a plausible appearance of the scene. Physics-based approaches can be beneficial in those scenarios, where the applied image formation model and additional priors resemble well the given circumstances where the images were taken, and especially when there is a way to physically validate certain parameters (e.g., measuring attenuation coefficients, calibrating against a target with known reflectance). In such cases, a physics-based algorithm may restore well the direct object signal. However, their performance also tends to be strongly limited for exactly the same reason. Take for example the scheme of Figure 4.3: this is only valid with natural light in shallow waters, and particularly when sunlight is present and dominating, so that illumination can be considered unidirectional. Once we go into very shallow waters, it is not sufficient anymore, as there are sunflickering effects seen on the seafloor. And once we submerge into deep water, where there is not enough natural light and we have to use artificial illumination to record images, the model becomes invalid and needs to be significantly altered.
In contrast, nonphysical algorithms, if well designed and not tied too strongly to a given image formation model, can be applied in a more robust way with varying illumination, scattering, and attenuation conditions. The challenge with such an approach is that an unnaturally looking result can be as easily achieved as a visually pleasing one, depending on certain adjustable parameters of the algorithm, the setting of which can be completely arbitrary and these might also need user interaction. Nevertheless, our team also opted for such a nonphysical, formal approach to underwater image enhancement that can be equally well applied in both shallow and deep waters, with natural and artificial or even mixed illumination sources, and it does not require prior information about the image content or scattering and absorption parameters. This method utilizes ideas from Tarel and Hautiere (2009) as well as the guided imaging filter of He et al. (2010) along with the principles of color constancy. Some sample results are illustrated in Figure 4.5, which highlight the significance of this approach under low to extreme low visibility conditions.

Figure 4.5 Image dehazing. Example of underwater image restoration in low to extreme low visibility conditions
Beyond the need for further improvement, open problems also remain in underwater image enhancement. For instance, it is a question: what is the best strategy to retrieve the object signal with proper contrast while combating the increasing noise. Ultimately, there are physical limits for restoring visibility since contrast of objects and image features is decreasing exponentially with the distance from the camera, and at some point they necessarily fall under the noise level of the camera sensor. Another question is what can be optimally done for restoring colors, when absorption in the red spectral range is so strong that there are only blue- and green-filtered signals recorded by the camera. More research could be done also on video applications, where temporal coherence could be exploited for better estimation of unknown parameters in the applied physical model or for better designed, nonphysical approaches.
4.3.2 Visual Odometry
Accurate vehicle localization and navigation are crucial to the successful completion of any type of autonomous mission. To this end, terrestrial applications typically employ GPS sensors that enable constant positioning estimation with no drift accumulation. In the underwater medium, however, GPS information is not available, increasing the complexity of autonomous navigation. As a result, extensive research efforts have been dedicated to this topic. Underwater navigation usually involves fusing the information from multiple sensors, such as long baseline, short baseline, Doppler velocity log, and inertial sensors, which allow estimations of the position, speed, and accelerations of the UUVs. More recently, advances in the area of computer vision, in terms of both hardware and software, have led to the development of vision-based navigation and positioning systems. Such systems employ one or more cameras mounted on the vehicle, typically coupled with artificialillumination systems for deep-sea missions. The images acquired by the cameras are processed in order to estimate the motion of the vehicle in real time using either two-dimensional (2D) mapping (mosaicing) or three-dimensional (3D) mapping techniques. Mosaicing was primarily developed as a technique that allows widening the coverage of the scene by aligning (stitching) images taken by a moving camera. This is particularly relevant in underwater mapping applications (Garcia et al. 2001 2003a 2005; Gracias and Santos-Victor 2000; Jaffe et al. 2002; Pizarro and Singh 2003; Singh et al. 2004 2007), where the field of view of the camera is very narrow due to the limited distance between the camera and the seafloor. Positioning based on mosaicing represents by far the most commonly used vision-based technique in underwater navigation, employing either image feature analysis or spatiotemporal image analysis. Image feature-based approaches (Eustice 2005; Fleischer 2000; Garcia et al. 2003b; Gracias 2002; Gracias et al. 2003) involve the extraction of features such as SURF (Bay et al. 2006), SIFT (Lowe 1999), FAST (Rosten and Drummond 2006), ORB (Rublee et al. 2011), and so on. These features are then characterized using descriptors (Bay et al. 2006; Lowe 1999) exploiting neighboring visual information. This enables feature matching between two time-consecutive images or feature tracking across multiple consecutive images, and ultimately the estimation of the camera motion. The motion of the camera is modeled by means of planar homographies (Hartley and Zisserman 2003; Negahdaripour et al. 2005), allowing estimation in up to 6 degrees of freedom (3 rotations + 3 translations). The vehicle position is then estimated by integrating the motion estimated from the homographies over time. Alternative mosaicing-based positioning systems use spatiotemporal image gradients in order to directly measure interframe vehicle motion (Madjidi and Negahdaripour 2006; Negahdaripour 1998; Negahdaripour and Madjidi 2003a). When the area surveyed by the vehicle exhibits prominent 3D variations, mosaicing-based approaches tend to yield low accuracy motion estimation due to the scene parallax. This shortcoming of mosaicing techniques has led to the development of 3D mapping-based UUV localization and navigation. Three-dimensional navigation techniques may involve multiple camera systems or a single camera for acquisition. When multiple-camera configurations are used (which are generally intercalibrated), image features are extracted and matched among the camera views. The 3D position of these image features is then recovered using triangulation techniques (Hartley and Zisserman 2003). Authors have proposed different approaches in stereo-based navigation. In Eustice et al. (2006b), Negahdaripour and Madjidi (2003b), Park et al. (2003), and Zhang and Negahdaripour (2003), the vehicle motion is estimated by recovering the 3D position of the features over consecutive image captures. An alternative strategy proposed in Ferrer and Garcia (2010), and Filippo et al. (2013) provides a 3D position estimation of image features for each stereo pair over time, registering the sets of 3D features in consecutive acquisitions. The relative camera motion is then recovered from the registration of the 3D points. In the case where a single camera is used for visual navigation (monocular vision), structure from motion (SfM) strategies are employed. Such techniques are similar to stereo navigation, except that the 3D camera motion has to be estimated during the 3D feature reconstruction. Initial SfM approaches used motion computation based on fundamental matrix (Beardsley et al. 1994; Longuet-Higgins 1981) and trifocal tensor (Fitzgibbon and Zisserman 1998). A more accurate alternative to these methods enables the recovery of vehicle position by directly registering the camera with 3D feature sets, using direct linear transformation (DLT) (Klein and Murray 2007). The use of direct camera registration is proposed by Pizarro (2004) and Pizarro et al. (2004) to deal with the problem of error accumulation in the large-area vehicle navigation. Here, the 3D map of the surveyed area is divided into submaps. Within the submaps, the camera pose is recovered directly by using resection methods and the submaps are registered using global alignment techniques. More recently, Nicosevici et al. (2009) proposed a framework for online navigation and mapping for UUVs employing a novel direct camera registration technique. This technique uses a dual-model DLT approach that is able to accurately cope with both planar and high 3D relief scenes.

Figure 4.6 Loop-closure detection. As the camera moves, there is an increasing uncertainty related to both the camera pose and the environment map. At instant  , the camera revisits a region of the scene previously visited at instant
, the camera revisits a region of the scene previously visited at instant  . If the visual observations between instants
. If the visual observations between instants  and
and  can be associated, the resulting information not only can be used to reduce the pose and map uncertainties at instant
can be associated, the resulting information not only can be used to reduce the pose and map uncertainties at instant  but also can be propagated to reduce the uncertainties at prior instants
but also can be propagated to reduce the uncertainties at prior instants
4.3.3 SLAM
Vision-based navigation is essentially a dead-reckoning process. During navigation and map building, the vision system estimates the camera pose relative to either previous poses or an environment map, while it builds the map from observations relative to camera poses. All estimations are prone to aliasing, noise, image distortions, and numerical errors, leading to inaccuracies in both pose and map inferences. Although generally small, these inaccuracies build up in time, leading to significant errors over large camera trajectories (Nicosevici et al. 2009). These errors can be reduced by taking advantage of the additional information resulting from cross-overs. Cross-overs (or loop-closures) are situations that appear when the robot revisits a region of the scene previously mapped during a visual survey. If correctly detected, these situations can be exploited in order to establish new constraints, allowing both camera pose and map errors to be decreased (see Figure 4.6) using either offline approaches, such as BA (Capel 2004; Madjidi and Negahdaripour 2005; McLauchlan and Jaenicke 2002; Sawhney et al. 1998; Triggs et al. 1999), or online approaches employing Gaussian filters, such as the popular Kalman filter (Caballero et al. 2007; Fleischer 2000; Garcia et al. 2002; Richmond and Rock, 2006) or nonparametric methods, such as those using particle filters (M. Montemerlo 2007; Montemerlo et al. 2003). In this context, the main open issue is the correct and efficient detection of loop closures.
A brute force loop-closure detection, where the current visual observations are compared to the entire map, would be much too computationally expensive, especially for online applications, due to the extremely large number of features that need to be matched.
As an alternative, the complexity of the loop-closure problem can be reduced by narrowing the search to the vicinity of the current camera pose. This is a widely used approach in the SLAM community, where the vision system is modeled as a sensor with a known uncertainty (Eustice et al. 2004 2005; Ila et al. 2007; Paz et al. 2008). However, an accurate estimation of the vehicle uncertainty is a complex problem and is generally affected by linearization approximations. To counterbalance this shortcoming, assuring the detection of the cross-over, current observations may be compared with a region of the map corresponding to a higher covariance than the estimated one (Jung and Lacroix 2003; Matthies and Shafer 1987). Doing so becomes computationally expensive, especially over large trajectory loops, where the covariance of the camera is high. Moreover, the noise model used for covariance estimation does not account for inaccuracies resulting from obstruction, temporary motion blur, sensor failures, and so on. These situations lead to poor vehicle pose estimation, not reflected in the uncertainty estimation, in which case the loop closure may not be detected.
Goedeme et al. (2006), Wahlgren and Duckett (2005), and Zhang (2011) propose a loop-closing detection method that computes the visual similarity using features. During navigation, they extract key points from each image (e.g., SIFT; Lowe (2004)). These features are matched among images, and the visual similarity is proportional to the number of successfully matched features. Generally, such methods are sensitive to occlusions while being computationally expensive, limiting their application over large navigation trajectories.
A more robust and computationally efficient alternative is to represent entire images as observations rather than individual image features. In this context, cross-overs are detected on the basis of image similarity, drastically decreasing the amount of data that need to be processed. The reduced computational cost related to such approaches enables brute force cross-over detection, even for large camera trajectories. This allows correct detection of trajectory loops, independent of camera pose and covariance estimation accuracy.
Initial proposals on image similarity cross-over detection use image representations based on a single global descriptor, embodying visual content such as color or texture (Bowling et al. 2005; Kroese et al. 2001; Lamon et al. 2001; Ramos et al. 2005; Torralba et al. 2003). Such global descriptors are sensitive to camera viewpoint and illumination changes, decreasing the robustness of the cross-over detection.
The emergence of modern feature extractors and descriptors has led to the development of new appearance-based cross-over detection techniques that represent visual content in terms of local image descriptors (Angeli et al. 2008a 2008b; Cummins and Newman 2007 2008; Wang et al. 2005). Inspired by advances in the fields of object recognition and content-based image retrieval (Opelt et al. 2004; Sivic 2006; Zhang et al. 2006), recent examples of such approaches describe images using bag of words (BoW) (see Figure 4.7). BoW image representation employs two stages: (i) in the training stage, sets of visual features are grouped or clustered together to generate visual vocabularies—collections of generalized visual features or visual words; (ii) in the second stage, the images are represented as histograms of visual word occurrences. While discarding the geometric information in images, BoW proved to be a very robust method for detecting visual similarities between images, allowing efficient cross-over detection even in the presence of illumination and camera perspective changes, partial occlusions, and so on.

Figure 4.7 BoW image representation. Images are represented by histograms of generalized visual features
In terms of clustering strategies, Schindler et al. (2007) proposed the use of kd-trees to build a visual vocabulary as proposed by Nister and Stewenius (2006). The vocabulary is then used for SLAM at the level of a city with good results. Galvez-Lopez and Tardos (2011) proposed the use of a vocabulary based on binary features for fast image matching.
Konolige et al. (2010) proposed a two-stage method in which visual vocabularies are first used to extract candidate views followed by a feature-based matching.
The main shortcoming of the above-mentioned methods is the use of a static vocabulary: the vocabulary is built a priori and remains constant during the recognition stage, failing to accurately model objects or scenes not present during training (Yeh et al. 2007). This shortcoming is particularly critical in the case of mapping and navigation, where a robot should be able to successfully detect loop-closure situations in uncontrolled environments. As a consequence, a series of authors in the SLAM community have proposed alternatives to address this problem. Notably, Filliat (2007) and Angeli et al. (2008a 2008b) assumed an initial vocabulary that is gradually incremented with new image features in an agglomerative manner using a user-defined distance threshold as the merging criterion. Alternatively, Cummins and Newman (2007 2008 2009), and later Paul and Newman (2010) and Glover et al. (2011), proposed a large-scale loop detection probabilistic framework based on BoW. They show good results employing ![]() -means-based static vocabularies built from large sets of visual information, not necessarily acquired in the same areas where the robot navigation takes place. As an alternative, Zhang (2011) proposed a workaround to the off-line vocabulary building stage by describing images directly using visual features, instead of vector-quantized representation of BoW. Here, the complexity of raw feature matching for loop-closure detection is partially reduced by means of a feature selection method that reduces the number of features extracted from images.
-means-based static vocabularies built from large sets of visual information, not necessarily acquired in the same areas where the robot navigation takes place. As an alternative, Zhang (2011) proposed a workaround to the off-line vocabulary building stage by describing images directly using visual features, instead of vector-quantized representation of BoW. Here, the complexity of raw feature matching for loop-closure detection is partially reduced by means of a feature selection method that reduces the number of features extracted from images.
Nicosevici and Garcia (2012) proposed a method aimed at increasing the efficiency and accuracy of loop detection in the context of online robot navigation and mapping called online visual vocabularies (OVV). It requires no user intervention and no a priori information about the environment. OVV creates a reduced vocabulary as soon as visual information becomes available during the robot survey. As the robot moves, the vocabulary is constantly updated in order to correctly model the visual information present in the scene.
OVV presents a novel incremental visual vocabulary building technique that is both scalable (thus suitable for online applications) and automatic (see Figure 4.8). In order to achieve this goal, it uses a modified version of agglomerative clustering. Agglomerative clustering algorithms begin with each element as a separate cluster—called hereafter elementary clusters—and merge them using some similarity measurement into successively larger clusters until some criterion is met (e.g., minimum number of clusters, maximum cluster radius).

Figure 4.8 Flowchart of OVV and image indexing. In every  frames, the vocabulary is updated with new visual features extracted from the last
frames, the vocabulary is updated with new visual features extracted from the last  frames. The complete set of features in the vocabulary is then merged until convergence. The obtained vocabulary is used to index the last
frames. The complete set of features in the vocabulary is then merged until convergence. The obtained vocabulary is used to index the last 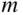 images. Also, the previously indexed frames are re-indexed to reflect the changes in the vocabulary
images. Also, the previously indexed frames are re-indexed to reflect the changes in the vocabulary
The convergence criterion is based on an objective function inspired by Fisher's linear discriminant (McLachlan 2004), maximizing the repetitiveness and discriminative power of the resulting vocabulary. Moreover, using a natural convergence criterion, the process eliminates the need of user-set parameters such as cluster radius or number of clusters, specific to other vocabulary building algorithms.
This OVV is of particular interest in underwater SLAM, especially in autonomous applications, due to its robustness, scalability, and its capacity to continuously adapt to new environmental elements on the journey with no human intervention.
4.3.4 Laser Scanning
The goal of deploying laser systems in underwater imaging applications is twofold: (i) increasing the effective range of the imaging devices and (ii) obtaining high-resolution 3D reconstructions. The use of finely controlled illumination devices based on lasers allows reducing the backscatter effect, making their deployment especially suitable in high-turbidity waters. These systems are usually comprised of a pulsating laser coupled with a range-gated camera. The backscatter effect is reduced by capturing the photons reflected from the target rather than the ones reflected by suspended particles. The selective photon capturing is carried out by finely synchronizing the electronic camera shutter with the laser pulses, taking into account the distance to the target and the time of flight of the light into the water medium (Caimi et al. 2008). Some implementations use spatially broadened lasers with range-gated intensified cameras allowing imaging of target with up to 40 degree field of view (Fournier et al. 1993 1995; Seet and He 2005). More recent implementations, such as LUCIE2, provide more compact configurations of such systems, allowing deployment on AUVs and ROVs (Weidemann et al. 2005). Other proposals employ off-the-shelf hardware. In this scenario, planar continuous lasers are typically coupled with one-dimensional (1D) or 2D cameras. Using specific camera-laser setups (e.g., mounting the laser at a certain distance from the camera), the backscatter effect can be reduced (Narasimhan et al. 2005). A hybrid approach is reported in Moore et al. (2000), where a pulsating laser system is coupled with a linear CCD camera. The pulsed laser allows short camera integration times, thereby reducing the influence of the ambient daylight signal in shallow waters and increasing the contrast in turbid environments. Three-dimensional reconstruction techniques employ lasers as structured light sources and 1D or 2D cameras as capture devices. Such techniques typically involve three main stages: (i) accurate calibration of the laser–camera setup, (ii) image filtering for detecting the laser scanline, and (iii) 3D reconstruction using triangulation algorithms (DePiero and Trivedi 1996). Roman et al. (2010) proposed a structured light system deployed on a ROV to create high-resolution bathymetric maps of underwater archeological sites. The system employs a 532-nm planar laser system to create sea-bottom profiles that are merged using the navigation data provided by the ROV. A similar approach is proposed in Tetlow and Spours (1999), where the authors used a laser scanning system to generate a model of an underwater site for ROV docking activities. A high-resolution seafloor scanning system is presented in Moore andJaffe (2002), resulting in sub-millimeter bathymetric maps with a transect coverage of 1.35 m. The authors report good results in using the system for characterization of the spatial variability and temporal evolution of the seafloor.
4.4 Acoustic Imaging Techniques
Given the limitations of optical devices, underwater operations have long relied on sonar technology. Acoustic waves are significantly less affected by water attenuation, facilitating operation at greater ranges and allowing work in turbidity conditions, thanks to longer wavelengths. Thus, sonar devices address the main shortcomings of optical sensors although at the expense of providing, in general, noisy data of lower resolution and more difficult interpretation.
Sonars delivering range measurements, such as single-beam echosounders, profiling sonars, or multibeam echosounders, have been successfully employed for obstacle avoidance, navigation, localization, and mapping (Fairfield et al. 2007; Kinsey et al. 2006; Leonard et al. 1998; Roman and Singh 2005), the latter being especially popular for the creation of seafloor bathymetric charts. Imaging sonars, such as mechanically scanning sonars or side-scan sonars, have also been widely used in obstacle avoidance, in localization, and particularly in mapping applications (Aulinas et al. 2010; Mallios et al. 2014; Ribas et al. 2008; Tena et al. 2003), thanks to its ability to represent the returning acoustic intensities from an insonified area. Recently, a new generation of imaging sonars (Blu 2015a; Sou 2015; Tri 2015), namely the 2D forward-looking sonar (FLS), are emerging as a strong alternative for those environments with reduced visibility given their capabilities of delivering high-quality acoustic images at a near-video frame rate. FLS provides significant advantages over other imaging sonars, thanks to the use of advanced transducer arrays that allow simultaneous sampling of multiple acoustic returns and render them in a 2D image. By directly providing a 2D image, they offer a closer rendition of what the eye naturally sees and minimize the required level of processing and interpretation when compared to other sonar modalities. Thus, they can be regarded as the analogous tool of optical cameras for turbid waters (see Figure 4.9). However, due to the inherent differences between optical and acoustic cues, issues arise in trying to leverage the techniques used on optical images, and often different approaches are required.

Figure 4.9 Sample 2D FLS image of a chain in turbid waters

Figure 4.10 FLS operation. The sonar emits an acoustic wave spanning its beam width in the azimuth ( ) and elevation (
) and elevation ( ) directions. Returned sound energy is sampled as a function of (
) directions. Returned sound energy is sampled as a function of ( ) and can be interpreted as the mapping of 3D points onto the zero-elevation plane (shown in red)
) and can be interpreted as the mapping of 3D points onto the zero-elevation plane (shown in red)
4.4.1 Image Formation
Two-dimensional FLSs, sometimes also referred to as acoustic cameras, provide high-definition acoustic imagery at a fast refresh rate. Although the specifications regarding operating frequency, acoustic beam width, frame rate, and the internal beam-forming technology depend on the specific sonar model and manufacturer, the principle of operation is the same for all of them. The sonar insonifies the scene with an acoustic wave, spanning its field of view in the azimuth ![]() and elevation
and elevation ![]() directions (see Figure 4.10). Then, the intensity of the acoustic return is sampled by an array of transducers as a function of range and bearing in a polar image. Therefore, the dimensions of a raw frame correspond to the number of beams in the angular direction and the number of range samples in the range axes. This representation is then converted to the final 2D image in the Cartesian coordinates for an easier interpretation. It is worth noting that this process produces images with nonuniform resolution as one pixel in polar domain is mapped onto multiple pixels with the same intensity in the Cartesian coordinates as the range increases.
directions (see Figure 4.10). Then, the intensity of the acoustic return is sampled by an array of transducers as a function of range and bearing in a polar image. Therefore, the dimensions of a raw frame correspond to the number of beams in the angular direction and the number of range samples in the range axes. This representation is then converted to the final 2D image in the Cartesian coordinates for an easier interpretation. It is worth noting that this process produces images with nonuniform resolution as one pixel in polar domain is mapped onto multiple pixels with the same intensity in the Cartesian coordinates as the range increases.
Because of the sonar construction, it is not possible to disambiguate the elevation angle of the acoustic return originating at a particular range and bearing. In other words, the reflected echo could have originated anywhere along the corresponding elevation arc. Therefore, the 3D information is lost in the projection into a 2D image.
According to this principle of operation, a 3D point ![]() with spherical coordinates
with spherical coordinates ![]() is projected in a point
is projected in a point ![]() on the image plane
on the image plane ![]() following a nonlinear model that depends on the elevation angle (see Figure 4.11).
following a nonlinear model that depends on the elevation angle (see Figure 4.11).

Figure 4.11 Sonar projection geometry. A 3D point  is mapped onto a point
is mapped onto a point  on the image plane along the arc defined by the elevation angle. Considering an orthographic approximation, the point
on the image plane along the arc defined by the elevation angle. Considering an orthographic approximation, the point  is mapped onto
is mapped onto  , which is equivalent to considering that all scene points rest on the plane
, which is equivalent to considering that all scene points rest on the plane  (in red)
(in red)
Hence, the homography relating two images becomes an affine homography whose elements vary across the image depending on the range and the unknown elevation angles (Negahdaripour 2012b). Therefore, this geometry model requires the estimation of the sonar elevation angles by using surface normals computed either from the imaging configuration (Negahdaripour 2012a) or from object–shadow pairs identified in the images (Aykin and Negahdaripour 2013). An easier approach to describe the FLS imaging geometry is to consider the narrow elevation angle that typically characterizes FLS devices (around 7-10 deg). Approximating this narrow elevation to the limit (i.e., considering only the zero-elevation plane), leads to a linear model in which the sonar can be seen as an orthographic camera (Johannsson et al. 2010). Hence, the projection ![]() of a 3D point
of a 3D point ![]() is approximated by the orthogonal projection
is approximated by the orthogonal projection ![]() , and the motion between two sonar frames can be related by a 2D rigid transformation comprising the
, and the motion between two sonar frames can be related by a 2D rigid transformation comprising the ![]() and
and ![]() translations (
translations (![]() ) and the plane rotation
) and the plane rotation ![]() .
.
Analogously to the parallax problem in optical imaging, this approximation holds as long as the relief of the scene in the elevation direction is negligible compared to the range. The imaging geometry under a typical operation scenario falls within this consideration since the sonar device is usually tilted to a small grazing angle to cover a large portion of the scene.
4.4.2 Online Techniques for Acoustic Processing
Some of the computer vision techniques described in the previous section (e.g., visual odometry, SLAM) can be applied on acoustic FLS images so that they can be performed regardless of the water visibility conditions. However, due to the different nature of the image formation, these techniques require alternative processing methodologies. Two of the most characteristic and differentiated processing techniques are described later.
4.4.2.1 FLS Image Registration
Techniques such as SLAM, visual odometry, or mosaicing approaches, similar to the techniques described in Chapter 7, often require to address a previous and fundamental step: the registration of sonar images (i.e., finding the spatial transformation that relates one sonar frame with another). Although registration is a broadly studied field in other modalities, notably the optical one (Zitova and Flusser 2003), it is still a premature field with regard to sonar data. The particularities of FLS imagery, such as low resolution, low signal-to-noise ratio (SNR), and intensity alterations due to viewpoint changes, pose serious challenges to the feature-based registration techniques that have proved very effective at aligning optical images.
Some feature-based approaches have been applied to the pairwise registration ofspatially close acoustic images, in particular Harris corner detector (Harris and Stephens 1988) has been used by several researchers to extract corner-like features in FLS images (Kim et al. 2005 2006; Negahdaripour et al. 2005). These features are later matched by cross-correlation of local patches and once correspondences are established, the transformation estimation is performed with a RANSAC-like method to reject outliers. Negahdaripour et al. (2011) have also highlighted the difficulties of registering FLS frames from a natural environment by using the popular SIFT detector and descriptor (Lowe 2004). In general, due to the inherent characteristics of sonar data, pixel-level features extracted in sonar images suffer from low repeatability rates (Hurtós et al. 2013b). Consequently, extracted features lack stability and are prone to originate erroneous matches and yield wrong transformation estimations. Moreover, the difficulties in accurately extracting and matching stable features are exacerbated when dealing with spatially or temporally distant sonar images.
In view of these difficulties, other researchers have proposed alternatives involving features at regional level rather than at pixel scale, which are presumably more stable. Johannsson et al. (2010) proposed the extraction of features in local regions located on sharp intensity transitions (i.e., changes from strong- to low-signal returns as in the boundaries of object–shadow transitions). Feature alignment is formulated as an optimization problem based on the normal distribution transform (NDT) algorithm (Biber and Straßer 2003), which adjusts the clustered regions in grid cells, thus removing the need to get exact correspondences between points and allowing for possible intensity variations. A similar approach has been recently presented in Aykin and Negahdaripour (2013). The authors propose to extract blob features comprising high-intensity values and negative vertical gradients (that ensure object–shadow transitions). As an alternative to the NDT algorithm, Aykin and Negahdaripour (2013) used an adaptive scheme where a Gaussian distribution is fitted to each blob feature. Afterwards, an optimization is formulated to seek the motion that best fits the blob projections from one Gaussian map to the other.
To overcome the instability and parameter sensitivity of feature-based registration approaches, and at the same time mitigate the requirement of prominent features in the environment, Hurtós et al. proposed to use a Fourier-based registration methodology (Hurtós et al. 2014b). Instead of using sparse feature information, they take into account all image content for the registration, thus offering more robustness to noise and the different intensity artifacts characteristic of the sonar image formation. By assuming a simplified imaging geometry, a global area technique can be used to perform 2D FLS registration, thus estimating a translation and rotation that relates two given frames. The method takes advantage of the phase-correlation principle that estimates translational displacements, thanks to the disassociation of the energy content from the structure shift in the frequency domain. The phase-correlation algorithm is adapted to cope with the multiple noise sources thatcan jeopardize the registration, introducing a specific masking procedure to cope with the spectral leakage caused by the sonar fan-shaped footprint edges and an adaptive frequency filtering to conform to the different amounts of noise of the phase-correlation matrix. The rotation estimation between frames is computed by also applying phase correlation, but in this case directly on the polar sonar images. Given that rotation is not decoupled from translational motions in the polar domain, this is regarded as an approximation. However, it has shown better behavior on the low SNR sonar images than other popular global rotation estimation approaches. Figure 4.12 shows the outline of the Fourier-based registration of FLS images. A further advantage of the Fourier-based registration is that given an image size the computation time is constant, while in feature-based methods computation time fluctuates depending on the number of features found. Moreover, the availability of efficient fast Fourier transform (FFT) implementations together with the method's resilience to noise, which alleviates the need of pre-processing the images, makes it suitable for real-time applications.

Figure 4.12 Overall Fourier-based registration pipeline
4.4.2.2 FLS Image Blending
Another common processing applied on underwater optical images is the fusion of the content of two overlapping frames to achieve a visually pleasant composition (Prados et al. 2012). Regardless of the particular techniques, optical blending generally deals with a low number of images at a given position (most of the times pairwise) and treats only their intersecting region. This prevents direct leverage from blending techniques designed for video images since blending acoustic images requires dealing with multiple overlapping frames involving high overlap percentages. High overlap is usual in FLS data because of the high frame rate of the FLS sensors; in addition, when acquiring images in an across-range manner, high overlap is a must to achieve good coverage due to the sonar fan-shaped footprint. Moreover, presuming that transformations between images are known with accuracy, it is of interest to keep as much of overlapping images as possible to be able to improve the SNR of the final image. This is again opposed to other approaches typically adopted on optical mosaicing, such as trying to select only the best image portion for a given location. Therefore, to blend FLS mosaics it is necessary to deal with not only the seam areas but also the whole image content.
In addition to this main divergence of the blending approach, there are some sonar-specific photometric irregularities that can also have a strong impact on the blending process (inhomogeneous insonification, nonuniform illumination, blind areas, seams along tracklines, etc.). The state of the art does not include precise solutions to cope with all these factors and, in fact, little work can be found in the literature regarding sonar image blending. In Kim et al. (2008), a probabilistic approach was proposed in the context of a super-resolution technique for FLS frames. The blending problem of fusing a low-resolution sonar image into a high-resolution image is modeled in terms of a conditional distribution with constraints imposed by the illumination profile of the observed frames so as to maximize the SNR of the resulting image. Hurtós et al. (2013a) proposed a compendium of pre-processing strategies that are targeted to address each of the photometric irregularities that can be present when blending FLS images. However, this kind of treatment is intended for offline use, as often all the images are required to estimate the correction for a given artifact. For the online blending of FLS images, a simple but effective strategy is to perform an average of the intensities that are mapped onto the same pixel location. Assuming that a correct image alignment has been found, averaging the overlapping image intensities yields the denoising of the final image. Thus, the resulting image will have a better SNR compared to a single image frame (see Figure 4.13).

Figure 4.13 Example of the denoising effect obtained by intensity averaging. (a) Single frame gathered with a DIDSON sonar (Sou 2015) operating at its lower frequency (1.1 Mhz). (b) Fifty registered frames from the same sequence blended by averaging the overlapping intensities. See how the SNR increases and small details pop-out.
Data courtesy of Sound Metrics Corp
4.5 Concluding Remarks
Mapping and navigation are difficult tasks due to the complexity of the environment and the lack of absolute positioning systems such as GPS. Moreover, in this chapter, we have seen that underwater imaging is a difficult endeavor due to the transmission properties of the medium. Light is absorbed and scattered by water, producing images with limited range, blurring, color shift, sunflicker or marine snow, among other effects. As a result, mapping using standard computer vision techniques tends to fail in underwater imaging due to these very specific peculiarities of the medium. However, with the adequate processing pipeline, vision can be a powerful tool for underwater robots to explore the ocean. Careful image enhancement can effectively improve image visibility, partially restore color, and remove haze. These techniques, in combination with robust SLAM techniques, are able to yield accurate mapping and navigation, improving remote operations and enabling autonomous tasks in underwater robotics. Mapping by means of laser systems can drastically improve the mapping capabilities, particularly when accurate 3D mapping is required. Complementary to optical sensing, acoustic sensors can drastically increase the mapping range and coverage of underwater vehicles, especially in underwater environments with low visibility.
Acknowledgments
László Neumann is thankful to ICREA, Barcelona, Spain. Ramon Hegedüs is grateful to the Alexander von Humboldt Foundation and acknowledges the support through his fellowship for experienced researchers.