
Chapter 1
Computer Vision in Vehicles
Reinhard Klette
School of Engineering, Computer and Mathematical Sciences, Auckland University of Technology, Auckland, New Zealand
This chapter is a brief introduction to academic aspects of computer vision in vehicles. It briefly summarizes basic notation and definitions used in computer vision. The chapter discusses a few visual tasks as of relevance for vehicle control and environment understanding.
1.1 Adaptive Computer Vision for Vehicles
Computer vision designs solutions for understanding the real world by using cameras. See Rosenfeld (1969), Horn (1986), Hartley and Zisserman (2003), or Klette (2014) for examples of monographs or textbooks on computer vision.
Computer vision operates today in vehicles including cars, trucks, airplanes, unmanned aerial vehicles (UAVs) such as multi-copters (see Figure 1.1 for a quadcopter), satellites, or even autonomous driving rovers on the Moon or Mars.

Figure 1.1 (a) Quadcopter. (b) Corners detected from a flying quadcopter using a modified FAST feature detector.
Courtesy of Konstantin Schauwecker
In our context, the ego-vehicle is that vehicle where the computer vision system operates in; ego-motion describes the ego-vehicle's motion in the real world.
1.1.1 Applications
Computer vision solutions are today in use in manned vehicles for improved safety or comfort, in autonomous vehicles (e.g., robots) for supporting motion or action control, and also for misusing UAVs for killing people remotely. The UAV technology has also good potentials for helping to save lives, to create three-dimensional (3D) models of the environment, and so forth. Underwater robots and unmanned sea-surface vehicles are further important applications of vision-augmented vehicles.
1.1.2 Traffic Safety and Comfort
Traffic safety is a dominant application area for computer vision in vehicles. Currently, about 1.24 million people die annually worldwide due to traffic accidents (WHO 2013), this is, on average, 2.4 people die per minute in traffic accidents. How does this compare to the numbers Western politicians are using for obtaining support for their “war on terrorism?” Computer vision can play a major role in solving the true real-world problems (see Figure 1.2). Traffic-accident fatalities can be reduced by controlling traffic flow (e.g., by triggering automated warning signals at pedestrian crossings or intersections with bicycle lanes) using stationary cameras, or by having cameras installed in vehicles (e.g., for detecting safe distances and adjusting speed accordingly, or by detecting obstacles and constraining trajectories).

Figure 1.2 The 10 leading causes of death in the world. Chart provided online by the World Health Organization (WHO). Road injury ranked number 9 in 2011
Computer vision is also introduced into modern cars for improving driving comfort. Surveillance of blind spots, automated distance control, or compensation of unevenness of the road are just three examples for a wide spectrum of opportunities provided by computer vision for enhancing driving comfort.
1.1.3 Strengths of (Computer) Vision
Computer vision is an important component of intelligent systems for vehicle control (e.g., in modern cars, or in robots). The Mars rovers “Curiosity” and “Opportunity” operate based on computer vision; “Opportunity” has already operated on Mars for more than ten years. The visual system of human beings provides a proof of existence that vision alone can deliver nearly all of the information required for steering a vehicle. Computer vision aims at creating comparable automated solutions for vehicles, enabling them to navigate safely in the real world. Additionally, computer vision can also work constantly “at the same level of attention,” applying the same rules or programs; a human is not able to do so due to becoming tired or distracted.
A human applies accumulated knowledge and experience (e.g., supporting intuition), and it is a challenging task to embed a computer vision solution into a system able to have, for example, intuition. Computer vision offers many more opportunities for future developments in a vehicle context.
1.1.4 Generic and Specific Tasks
There are generic visual tasks such as calculating distance or motion, measuring brightness, or detecting corners in an image (see Figure 1.1b). In contrast, there are specific visual tasks such as detecting a pedestrian, understanding ego-motion, or calculating the free space a vehicle may move in safely in the next few seconds. The borderline between generic and specific tasks is not well defined.
Solutions for generic tasks typically aim at creating one self-contained module for potential integration into a complex computer vision system. But there is no general-purpose corner detector and also no general-purpose stereo matcher. Adaptation to given circumstances appears to be the general way for an optimized use of given modules for generic tasks.
Solutions for specific tasks are typically structured into multiple modules that interact in a complex system.
1.1.5 Multi-module Solutions
Designing a multi-module solution for a given task does not need to be more difficult than designing a single-module solution. In fact, finding solutions for some single modules (e.g., for motion analysis) can be very challenging. Designing a multi-module solution requires:
- 1. that modular solutions are available and known,
- 2. tools for evaluating those solutions in dependency of a given situation (or scenario; see Klette et al. (2011) for a discussion of scenarios) for being able to select (or adapt) solutions,
- 3. conceptual thinking for designing and controlling an appropriate multi-module system,
- 4. a system optimization including a more extensive testing on various scenarios than for a single module (due to the increase in combinatorial complexity of multi-module interactions), and
- 5. multiple modules require control (e.g., when many designers separately insert processors for controlling various operations in a vehicle, no control engineer should be surprised if the vehicle becomes unstable).
1.1.6 Accuracy, Precision, and Robustness
Solutions can be characterized as being accurate, precise, or robust. Accuracy means a systematic closeness to the true values for a given scenario. Precision also considers the occurrence of random errors; a precise solution should lead to about the same results under comparable conditions. Robustness means approximate correctness for a set of scenarios that includes particularly challenging ones: in such cases, it would be appropriate to specify the defining scenarios accurately, for example, by using video descriptors (Briassouli and Kompatsiaris 2010) or data measures (Suaste et al. 2013). Ideally, robustness should address any possible scenario in the real world for a given task.
1.1.7 Comparative Performance Evaluation
An efficient way for a comparative performance analysis of solutions for one task is by having different authors testing their own programs on identical benchmark data. But we not only need to evaluate the programs, we also need to evaluate the benchmark data used (Haeusler and Klette 2010 2012) for identifying their challenges or relevance.
Benchmarks need to come with measures for quantifying performance such that we can compare accuracy on individual data or robustness across a diversity of different input data.
Figure 1.4 illustrates two possible ways for generating benchmarks, one by using computer graphics for rendering sequences with accurately known ground truth,1 and the other one by using high-end sensors (in the illustrated case, ground truth is provided by the use of a laser range-finder).2

Figure 1.4 Examples of benchmark data available for a comparative analysis of computer vision algorithms for motion and distance calculations. (a) Image from a synthetic sequence provided on EISATS with accurate ground truth. (b) Image of a real-world sequence provided on KITTI with approximate ground truth
But those evaluations need to be considered with care since everything is not comparable. Evaluations depend on the benchmark data used; having a few summarizing numbers may not be really of relevance for particular scenarios possibly occurring in the real world. For some input data we simply can not answer how a solution performs; for example, in the middle of a large road intersection, we cannot answer which lane border detection algorithm performs best for this scenario.
1.1.8 There Are Many Winners
We are not so naive to expect an all-time “winner” when comparatively evaluating computer vision solutions. Vehicles operate in the real world (whether on Earth, the Moon, or on Mars), which is so diverse that not all of the possible event occurrences can be modeled in underlying constraints for a designed program. Particular solutions perform differently for different scenarios, and a winning program for one scenario may fail for another. We can only evaluate how particular solutions perform for particular scenarios. At the end, this might support an optimization strategy by adaptation to a current scenario that a vehicle experiences at a time.
1.2 Notation and Basic Definitions
The following basic notations and definitions (Klette 2014) are provided.
1.2.1 Images and Videos
An image ![]() is defined on a set
is defined on a set
of pairs of integers (pixel locations), called the image carrier, where ![]() and
and ![]() define the number of columns and rows, respectively. We assume a left-hand coordinate system with the coordinate origin in the upper-left corner of the image, the
define the number of columns and rows, respectively. We assume a left-hand coordinate system with the coordinate origin in the upper-left corner of the image, the ![]() -axis to the right, and the
-axis to the right, and the ![]() -axis downward. A pixel of an image
-axis downward. A pixel of an image ![]() combines a location
combines a location ![]() in the carrier
in the carrier ![]() with the value
with the value ![]() of
of ![]() at this location.
at this location.
A scalar image ![]() takes values in a set
takes values in a set ![]() , typically with
, typically with ![]() ,
, ![]() , or
, or ![]() . A vector-valued image
. A vector-valued image ![]() has scalar values in a finite number of channels or bands. A video or image sequence consists of frames
has scalar values in a finite number of channels or bands. A video or image sequence consists of frames ![]() , for
, for ![]() , all being images on the same carrier
, all being images on the same carrier ![]() .
.
1.2.1.1 Gauss Function
The zero-mean Gauss function is defined as follows:

A convolution of an image ![]() with the Gauss function produces smoothed images
with the Gauss function produces smoothed images
also known as Gaussians, for ![]() . (We stay with symbol
. (We stay with symbol ![]() here as introduced by Lindeberg (1994) for “layer”; a given context will prevent confusion with the left image
here as introduced by Lindeberg (1994) for “layer”; a given context will prevent confusion with the left image ![]() of a stereo pair.)
of a stereo pair.)
1.2.1.2 Edges
Step-edges in images are detected based on first- or second-order derivatives, such as values of the gradient ![]() or the Laplacian
or the Laplacian ![]() given by
given by

Local maxima of ![]() - or
- or ![]() -magnitudes
-magnitudes ![]() or
or ![]() , or zero-crossings of values
, or zero-crossings of values ![]() are taken as an indication for a step-edge. The gradient or Laplacian is commonly preceded by smoothing, using a convolution with the zero-mean Gauss function.
are taken as an indication for a step-edge. The gradient or Laplacian is commonly preceded by smoothing, using a convolution with the zero-mean Gauss function.
Alternatively, Phase-congruency edges in images are detected based on local frequency-space representations (Kovesi 1993).
1.2.1.3 Corners
Let ![]() ,
, ![]() ,
, ![]() , and
, and ![]() denote the second-order derivatives of image
denote the second-order derivatives of image ![]() . Corners in images are localized based on high curvature of intensity values, to be identified by two large eigenvalues of the Hessian matrix
. Corners in images are localized based on high curvature of intensity values, to be identified by two large eigenvalues of the Hessian matrix
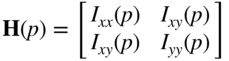
at a pixel location ![]() in a scalar image
in a scalar image ![]() (see Harris and Stephens (1988)). Figure 1.1 shows the corners detected by FAST. Corner detection is often preceded by smoothing using a convolution with the zero-mean Gauss function.
(see Harris and Stephens (1988)). Figure 1.1 shows the corners detected by FAST. Corner detection is often preceded by smoothing using a convolution with the zero-mean Gauss function.
1.2.1.4 Scale Space and Key Points
Key points or interest points are commonly detected as maxima or minima in a ![]() subset of the scale space of a given image (Crowley and Sanderson 1987; Lindeberg 1994). A finite set of differences of Gaussians
subset of the scale space of a given image (Crowley and Sanderson 1987; Lindeberg 1994). A finite set of differences of Gaussians
produces a DoG scale space. These differences are approximations to Laplacians of increasingly smoothed versions of an image (see Figure 1.5 for an example of such Laplacians forming an LoG scale space).

Figure 1.5 Laplacians of smoothed copies of the same image using cv::GaussianBlur and cv::Laplacian in OpenCV, with values 0.5, 1, 2, and 4, for parameter  for smoothing. Linear scaling is used for better visibility of the resulting Laplacians.
for smoothing. Linear scaling is used for better visibility of the resulting Laplacians.
Courtesy of Sandino Morales
1.2.1.5 Features
An image feature is finally a location (an interest point), defined by a key point, edge, corner, and so on, together with a descriptor, usually given as a data vector (e.g., in case of scale-invariant feature transform (SIFT) of length 128 representing local gradients), but possibly also in other formats such as a graph. For example, the descriptor of a step-edge can be mean and variance of gradient values along the edge, and the descriptor of a corner can be defined by the eigenvalues of the Hessian matrix.
1.2.2 Cameras
We have an ![]() world coordinate system, which is not defined by a particular camera or other sensor, and a camera coordinate system
world coordinate system, which is not defined by a particular camera or other sensor, and a camera coordinate system ![]() (index “s” for “sensor”), which is described with respect to the chosen world coordinates by means of an affine transform, defined by a rotation matrix
(index “s” for “sensor”), which is described with respect to the chosen world coordinates by means of an affine transform, defined by a rotation matrix ![]() and a translation vector
and a translation vector ![]() .
.
A point in 3D space is given as ![]() in world coordinates or as
in world coordinates or as ![]() in camera coordinates. In addition to the coordinate notation for points, we also use vector notation, such as
in camera coordinates. In addition to the coordinate notation for points, we also use vector notation, such as ![]() for point
for point ![]() .
.
1.2.2.1 Pinhole-type Camera
The ![]() -axis models the optical axis. Assuming an ideal pinhole-type camera, we can ignore radial distortion and can have undistorted projected points in the image plane with coordinates
-axis models the optical axis. Assuming an ideal pinhole-type camera, we can ignore radial distortion and can have undistorted projected points in the image plane with coordinates ![]() and
and ![]() . The distance
. The distance ![]() between the
between the ![]() image plane and the projection center is the focal length.
image plane and the projection center is the focal length.
A visible point ![]() in the world is mapped by central projection into pixel location
in the world is mapped by central projection into pixel location ![]() in the undistorted image plane:
in the undistorted image plane:

with the origin of ![]() image coordinates at the intersection point of the
image coordinates at the intersection point of the ![]() -axis with the image plane.
-axis with the image plane.
The intersection point ![]() of the optical axis with the image plane in
of the optical axis with the image plane in ![]() coordinates is called the principal point. It follows that
coordinates is called the principal point. It follows that ![]() . A pixel location
. A pixel location ![]() in the 2D
in the 2D ![]() image coordinate system has 3D coordinates
image coordinate system has 3D coordinates  in the
in the ![]() camera coordinate system.
camera coordinate system.
1.2.2.2 Intrinsic and Extrinsic Parameters
Assuming multiple cameras ![]() , for some indices
, for some indices ![]() (e.g., just
(e.g., just ![]() and
and ![]() for binocular stereo), camera calibration specifies intrinsic parameters such as edge lengths
for binocular stereo), camera calibration specifies intrinsic parameters such as edge lengths ![]() and
and ![]() of camera sensor cells (defining the aspect ratio), a skew parameter
of camera sensor cells (defining the aspect ratio), a skew parameter ![]() , coordinates of the principal point
, coordinates of the principal point ![]() where optic axis of camera
where optic axis of camera ![]() and image plane intersect, the focal length
and image plane intersect, the focal length ![]() , possibly refined as
, possibly refined as ![]() and
and ![]() , and lens distortion parameters starting with
, and lens distortion parameters starting with ![]() and
and ![]() . In general, it can be assumed that lens distortion has been calibrated before and does not need to be included anymore in the set of intrinsic parameters. Extrinsic parameters are defined by rotation matrices and translation vectors, for example, matrix
. In general, it can be assumed that lens distortion has been calibrated before and does not need to be included anymore in the set of intrinsic parameters. Extrinsic parameters are defined by rotation matrices and translation vectors, for example, matrix ![]() and vector
and vector ![]() for the affine transform between camera coordinate systems
for the affine transform between camera coordinate systems ![]() and
and ![]() , or matrix
, or matrix ![]() and vector
and vector ![]() for the affine transform between camera coordinate system
for the affine transform between camera coordinate system ![]() and
and ![]() .
.
1.2.2.3 Single-Camera Projection Equation
The camera projection equation in homogeneous coordinates, mapping a 3D point ![]() into image coordinates
into image coordinates ![]() of the
of the ![]() th camera, is as follows:
th camera, is as follows:

where ![]() is a scaling factor. This defines a
is a scaling factor. This defines a ![]() matrix
matrix ![]() of intrinsic camera parameters and a
of intrinsic camera parameters and a ![]() matrix
matrix ![]() of extrinsic parameters (of the affine transform) of camera
of extrinsic parameters (of the affine transform) of camera ![]() . The
. The ![]() camera matrix
camera matrix ![]() is defined by 11 parameters if we allow for an arbitrary scaling of parameters; otherwise it is 12.
is defined by 11 parameters if we allow for an arbitrary scaling of parameters; otherwise it is 12.
1.2.3 Optimization
We specify one popular optimization strategy that has various applications in computer vision. In an abstract sense, we assign to each pixel a label ![]() (e.g., an optical flow vector
(e.g., an optical flow vector ![]() , a disparity
, a disparity ![]() , a segment identifier, or a surface gradient) out of a set
, a segment identifier, or a surface gradient) out of a set ![]() of possible labels (e.g., all vectors pointing from a pixel
of possible labels (e.g., all vectors pointing from a pixel ![]() to points in a Euclidean distance to
to points in a Euclidean distance to ![]() of less than a given threshold). Labels
of less than a given threshold). Labels ![]() are thus in the 2D continuous plane.
are thus in the 2D continuous plane.
1.2.3.1 Optimizing a Labeling Function
Labels are assigned to all the pixels in the carrier ![]() by a labeling function
by a labeling function ![]() . Solving a labeling problem means to identify a labeling
. Solving a labeling problem means to identify a labeling ![]() that approximates somehow an optimum of a defined error or energy
that approximates somehow an optimum of a defined error or energy
where ![]() is a weight. Here,
is a weight. Here, ![]() is the data-cost term and
is the data-cost term and ![]() is the smoothness-cost term. A decrease in
is the smoothness-cost term. A decrease in ![]() works toward reduced smoothing of calculated labels. Ideally, we search for an optimal (i.e., of minimal total error)
works toward reduced smoothing of calculated labels. Ideally, we search for an optimal (i.e., of minimal total error) ![]() in the set of all possible labelings, which defines a total variation (TV).
in the set of all possible labelings, which defines a total variation (TV).
We detail Eq. (1.10) by adding costs at pixels. In a current image, label ![]() is assigned by the value of labeling function
is assigned by the value of labeling function ![]() at pixel position
at pixel position ![]() . Then we have that
. Then we have that

where ![]() is an adjacency relation between pixel locations.
is an adjacency relation between pixel locations.
In optical flow or stereo vision, label ![]() (i.e., optical flow vector or disparity) defines a pixel
(i.e., optical flow vector or disparity) defines a pixel ![]() in another image (i.e., in the following image, or in the left or right image of a stereo pair); in this case, we can also write
in another image (i.e., in the following image, or in the left or right image of a stereo pair); in this case, we can also write ![]() instead of
instead of ![]() .
.
1.2.3.2 Invalidity of the Intensity Constancy Assumption
Data-cost terms are defined for windows that are centered at the considered pixel locations. The data in both windows, around the start pixel location ![]() , and around the pixel location
, and around the pixel location ![]() in the other image, are compared for understanding “data similarity.”
in the other image, are compared for understanding “data similarity.”
For example, in the case of stereo matching, we have ![]() in the right image
in the right image ![]() and
and ![]() in the left image
in the left image ![]() , for disparity
, for disparity ![]() , and the data in both
, and the data in both ![]() windows are identical if and only if the data-cost measure
windows are identical if and only if the data-cost measure
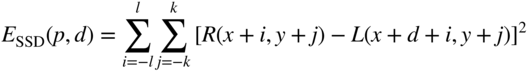
results in value 0, where SSD stands for sum of squared differences.
The use of such a data-cost term would be based on the intensity constancy assumption (ICA), that is, intensity values around corresponding pixel locations ![]() and
and ![]() are (basically) identical within a window of specified size. However, the ICA is invalid for real-world recording. Intensity values at corresponding pixels and in their neighborhoods are typically impacted by lighting variations, or just by image noise. There are also impacts of differences in local surface reflectance, differences in cameras when comparing images recorded by different cameras, or effects of perspective distortion (the local neighborhood around a surface point is differently projected into different cameras). Thus, energy optimization needs to apply better data measures compared to SSD, or other measures are also defined based on the ICA.
are (basically) identical within a window of specified size. However, the ICA is invalid for real-world recording. Intensity values at corresponding pixels and in their neighborhoods are typically impacted by lighting variations, or just by image noise. There are also impacts of differences in local surface reflectance, differences in cameras when comparing images recorded by different cameras, or effects of perspective distortion (the local neighborhood around a surface point is differently projected into different cameras). Thus, energy optimization needs to apply better data measures compared to SSD, or other measures are also defined based on the ICA.
1.2.3.3 Census Data-Cost Term
The census-cost function has been identified as being able to compensate successfully bright variations in input images of a recorded video (Hermann and Klette 2009; Hirschmüller and Scharstein 2009). The mean-normalized census-cost function is defined by comparing a ![]() window centered at pixel location
window centered at pixel location ![]() in frame
in frame ![]() with a window of the same size centered at a pixel location
with a window of the same size centered at a pixel location ![]() in frame
in frame ![]() . Let
. Let ![]() be the mean of the window around
be the mean of the window around ![]() for
for ![]() or
or ![]() . Then we have that
. Then we have that

with

Note that value 0 corresponds to consistency in both comparisons. If the comparisons are performed with respect to values ![]() and
and ![]() , rather than the means
, rather than the means ![]() and
and ![]() , then we have the census-cost function
, then we have the census-cost function ![]() as a candidate for a data-cost term.
as a candidate for a data-cost term.
Let ![]() be the vector listing results
be the vector listing results ![]() in a left-to-right, top-to-bottom order (with respect to the applied
in a left-to-right, top-to-bottom order (with respect to the applied ![]() window), where
window), where ![]() is the signum function;
is the signum function; ![]() lists values
lists values ![]() . The mean-normalized census data-cost
. The mean-normalized census data-cost ![]() equals the Hamming distance between vectors
equals the Hamming distance between vectors ![]() and
and ![]() .
.
1.3 Visual Tasks
This section briefly outlines some of the visual tasks that need to be solved by computer vision in vehicles.
1.3.1 Distance
Laser range-finders are increasingly used for estimating distance mainly based on the time-of-flight principle. Assuming sensor arrays of larger density in the nearfuture, laser range-finders will become a standard option for cost-efficient accurate distance calculations. Combining stereo vision with distance data provided by laser range-finders is a promising multi-module approach toward distance calculations.
Stereo vision is the dominant approach in computer vision for calculating distances. Corresponding pixels are here defined by projections of the same surface point in the scene into the left and right images of a stereo pair. After having recorded stereo pairs rectified into canonical stereo geometry, one-dimensional (1D) correspondence search can be limited to identical image rows.
1.3.1.1 Stereo Vision
We address the detection of corresponding points in a stereo image ![]() , a basic task for distance calculation in vehicles using binocular stereo.
, a basic task for distance calculation in vehicles using binocular stereo.
Corresponding pixels define a disparity, which is mapped based on camera parameters into distance or depth. There are already very accurate solutions for stereo matching, but challenging input data (rain, snow, dust, sunstroke, running wipers, and so forth) still pose unsolved problems (see Figure 1.6 for an example of a depth map).

Figure 1.6 (a) Image of a stereo pair (from a test sequence available on EISATS). (b) Visualization of a depth map using the color key shown at the top for assigning distances in meters to particular colors. A pixel is shown in gray if there was low confidence for the calculated disparity value at this pixel.
Courtesy of Simon Hermann
1.3.1.2 Binocular Stereo Vision
After camera calibration, we have two virtually identical cameras ![]() and
and ![]() , which are perfectly aligned defining canonical stereo geometry. In this geometry, we have an identical copy of the camera on the left translated by base distance
, which are perfectly aligned defining canonical stereo geometry. In this geometry, we have an identical copy of the camera on the left translated by base distance ![]() along the
along the ![]() -axis of the
-axis of the ![]() camera coordinate system of the left camera. The projection center of the left camera is at
camera coordinate system of the left camera. The projection center of the left camera is at ![]() and the projection center of the cloned right camera is at
and the projection center of the cloned right camera is at ![]() . A 3D point
. A 3D point ![]() is mapped into undistorted image points
is mapped into undistorted image points


in the left and right image planes, respectively. Considering ![]() and
and ![]() in homogeneous coordinates, we have that
in homogeneous coordinates, we have that
for the 3 ![]() 3 bifocal tensor
3 bifocal tensor ![]() , defined by the configuration of the two cameras. The dot product
, defined by the configuration of the two cameras. The dot product ![]() defines an epipolar line in the image plane of the right camera; any stereo point corresponding to
defines an epipolar line in the image plane of the right camera; any stereo point corresponding to ![]() needs to be on that line.
needs to be on that line.
1.3.1.3 Binocular Stereo Matching
Let ![]() be the base image and
be the base image and ![]() be the match image. We calculate corresponding pixels
be the match image. We calculate corresponding pixels ![]() and
and ![]() in the
in the ![]() image coordinates of carrier
image coordinates of carrier ![]() following the optimization approach as expressed by Eq. (1.11). A labeling function
following the optimization approach as expressed by Eq. (1.11). A labeling function ![]() assigns a disparity
assigns a disparity ![]() to pixel location
to pixel location ![]() , which specifies a corresponding pixel
, which specifies a corresponding pixel ![]() .
.
For example, we can use the census data-cost term ![]() as defined in Eq. (1.13), and for the smoothness-cost term, either the Potts model, linear truncated cost, or quadratic truncated costs is used (see Chapter 5 in Klette (2014)). Chapter 6 of Klette (2014) discusses also different algorithms for stereo matching, including belief-propagation matching (BPM) (Sun et al. 2003) and dynamic-programming stereo matching (DPSM). DPSM can be based on scanning along the epipolar line only using either an ordering or a smoothness constraint, or it can be based (for symmetry?) on scanning along multiple scanlines using a smoothness constraint along those lines; the latter case is known as semi-global matching (SGM) if multiple scanlines are used for error minimization (Hirschmüller, 2005). A variant of SGM is used in Daimler's stereo vision system, available since March 2013 in their Mercedes cars (see also Chapter 2 by U. Franke in this book).
as defined in Eq. (1.13), and for the smoothness-cost term, either the Potts model, linear truncated cost, or quadratic truncated costs is used (see Chapter 5 in Klette (2014)). Chapter 6 of Klette (2014) discusses also different algorithms for stereo matching, including belief-propagation matching (BPM) (Sun et al. 2003) and dynamic-programming stereo matching (DPSM). DPSM can be based on scanning along the epipolar line only using either an ordering or a smoothness constraint, or it can be based (for symmetry?) on scanning along multiple scanlines using a smoothness constraint along those lines; the latter case is known as semi-global matching (SGM) if multiple scanlines are used for error minimization (Hirschmüller, 2005). A variant of SGM is used in Daimler's stereo vision system, available since March 2013 in their Mercedes cars (see also Chapter 2 by U. Franke in this book).
Iterative SGM (iSGM) is an example for a modification of baseline SGM; for example, error minimization along the horizontal scanline should in general contribute more to the final result than optimization along other scanlines (Hermann and Klette, 2012). Figure 1.7 also addresses confidence measurement; for a comparative discussion of confidence measures, see Haeusler and Klette (2012). Linear BPM (linBPM) applies the MCEN data-cost term and the linear truncated smoothness-cost term (Khan et al. 2013).

Figure 1.7 Resulting disparity maps for stereo data when using only one scanline for DPSM with the SGM smoothness constraint and a  MCEN data-cost function. From top to bottom and left to right: Left-to-right horizontal scanline, and lower-left to upper-right diagonal scanline, top-to-bottom vertical scanline, and upper-left to lower-right diagonal scanline. Pink pixels are for low-confidence locations (here identified by inhomogeneous disparity locations).
MCEN data-cost function. From top to bottom and left to right: Left-to-right horizontal scanline, and lower-left to upper-right diagonal scanline, top-to-bottom vertical scanline, and upper-left to lower-right diagonal scanline. Pink pixels are for low-confidence locations (here identified by inhomogeneous disparity locations).
Courtesy of Simon Hermann; the input data have been provided by Daimler A.G.
1.3.1.4 Performance Evaluation of Stereo Vision Solutions
Figure 1.8 provides a comparison of iSGM to linBPM on four frame sequences each of 400 frames length. It illustrates that iSGM performs better (with respect to the used measure, see the following section for its definition) on the bridge sequence that is characterized by many structural details in the scene, but not as good as linBPM on the other three sequences. For sequences dusk and midday, both performances are highly correlated, but not for the other two sequences. Of course, evaluating on only a few sequences of 400 frames each is insufficient for making substantial evaluations, but it does illustrate performance.

Figure 1.8 Normalized cross-correlation results when applying the third-eye technology for stereo matchers iSGM and linBPM for four real-world trinocular sequences of Set 9 of EISATS.
Courtesy of Waqar Khan, Veronica Suaste, and Diego Caudillo
The diagrams in Figure 1.8 are defined by the normalized cross-correlation (NCC) between a recorded third-frame sequence and a virtual sequence calculated based on the stereo matching results of two other frame sequences. This third-eye technology (Morales and R 2009) also uses masks such that only image values are compared which are close to step-edges (e.g., see Figure 1.5 for detected edges at bright pixels in LoG scale space) in the third frame. It enables us to evaluate performance on any calibrated trinocular frame sequence recorded in the real world.
1.3.2 Motion
A sequence of video frames ![]() , all defined on the same carrier
, all defined on the same carrier ![]() , is recorded with a time difference
, is recorded with a time difference ![]() between two subsequent frames; frame
between two subsequent frames; frame ![]() is recorded at time
is recorded at time ![]() counted from the start of the recording.
counted from the start of the recording.
The projection of a static or moving surface point into pixel ![]() in frame
in frame ![]() and into pixel
and into pixel ![]() in frame
in frame ![]() defines a pair of corresponding pixels represented by a motion vector
defines a pair of corresponding pixels represented by a motion vector ![]() from
from ![]() to
to ![]() in
in ![]() .
.
1.3.2.1 Dense or Sparse Motion Analysis
Dense motion analysis aims at calculating approximately correct motion vectors for “basically” every pixel location ![]() in frame
in frame ![]() (see Figure 1.10 for an example). Sparse motion analysis is designed for having accurate motion vectors at a few selected pixel locations.
(see Figure 1.10 for an example). Sparse motion analysis is designed for having accurate motion vectors at a few selected pixel locations.

Figure 1.10 Visualization of optical flow using the color key shown around the border of the image for assigning a direction to particular colors; the length of the flow vector is represented by saturation, where value “white” (i.e., undefined saturation) corresponds to “no motion.” (a) Calculated optical flow using the original Horn–Schunck algorithm. (b) Ground truth for the image shown in Figure 1.4a.
Courtesy of Tobi Vaudrey
Motion analysis is a difficult 2D correspondence problem, and it might become easier by having recorded high-resolution images at a higher frame rate in future. For example, motion analysis is approached by a single-module solution by optical flow calculation, or as a multi-module solution when combining image segmentation with subsequent estimations of motion vectors for image segments.
1.3.2.2 Optical Flow
Optical flow ![]() is the result of dense motion analysis. It represents motion vectors between corresponding pixels
is the result of dense motion analysis. It represents motion vectors between corresponding pixels ![]() in frames
in frames ![]() and
and ![]() . Figure 1.10 shows the visualization of an optical flow map.
. Figure 1.10 shows the visualization of an optical flow map.
1.3.2.3 Optical Flow Equation and Image Constancy Assumption
The derivation of the optical flow equation (Horn and Schunck 1981)
for ![]() and first-order derivatives
and first-order derivatives ![]() ,
, ![]() , and
, and ![]() follows from the ICA, that is, by assuming that corresponding 3D world points are represented in frame
follows from the ICA, that is, by assuming that corresponding 3D world points are represented in frame ![]() and
and ![]() by the same intensity. This is actually not true for computer vision in vehicles. Light intensities change frequently due to lighting artifacts (e.g., driving below trees), changing angles to the Sun, or simply due to sensor noise. However, the optical flow equation is often used as a data-cost term in an optimization approach (minimizing energy as defined in Eq. (1.10)) for solving the optical flow problem.
by the same intensity. This is actually not true for computer vision in vehicles. Light intensities change frequently due to lighting artifacts (e.g., driving below trees), changing angles to the Sun, or simply due to sensor noise. However, the optical flow equation is often used as a data-cost term in an optimization approach (minimizing energy as defined in Eq. (1.10)) for solving the optical flow problem.
1.3.2.4 Examples of Data and Smoothness Costs
If we accept Eq. (1.18)due to Horn and Schunck (and thus the validity of the ICA) as data constraint, then we derive

as a possible data-cost term for any given time ![]() .
.
We introduced above the zero-mean-normalized census-cost function ![]() . The sum
. The sum ![]() can replace
can replace ![]() in an optimization approach as defined by Eq. (1.10) (see Hermann and Werner (2013)). This corresponds to the invalidity of the ICA for video data recorded in the real world.
in an optimization approach as defined by Eq. (1.10) (see Hermann and Werner (2013)). This corresponds to the invalidity of the ICA for video data recorded in the real world.
For the smoothness-error term, we may use

This smoothness-error term applies squared penalties to first-order derivatives in the ![]() sense. Applying a smoothness term in an approximate
sense. Applying a smoothness term in an approximate ![]() sense reduces the impact of outliers (Brox et al. 2004).
sense reduces the impact of outliers (Brox et al. 2004).
Terms ![]() and
and ![]() define the
define the ![]() optimization problem as originally considered by Horn and Schunck (1981).
optimization problem as originally considered by Horn and Schunck (1981).
1.3.2.5 Performance Evaluation of Optical Flow Solutions
Apart from using data with provided ground truth (see EISATS and KITTI and Figure 1.4), there is also a way for evaluating calculated flow vectors on recorded real-world video assuming that the recording speed is sufficiently large; for calculated flow vectors for frames ![]() and
and ![]() , we calculate an image “half-way” using the mean of image values at corresponding pixels and we compare this calculated image with frame
, we calculate an image “half-way” using the mean of image values at corresponding pixels and we compare this calculated image with frame ![]() (see Szeliski (1999)). Limitations for recording frequencies of current cameras make this technique not yet practically appropriate, but it is certainly appropriate for fundamental research.
(see Szeliski (1999)). Limitations for recording frequencies of current cameras make this technique not yet practically appropriate, but it is certainly appropriate for fundamental research.
1.3.3 Object Detection and Tracking
In general, an object detector is defined by applying a classifier for an object detection problem. We assume that any decision made can be evaluated as being either correct or false.
1.3.3.1 Measures for Object Detection
Let tp or fp denote the numbers of true-positives or false-positives, respectively. Analogously we define tn and fn for the negatives; tn is not a common entry for performance measures.
Precision (PR) is the ratio of true-positives compared to all detections. Recall (RC) (or sensitivity) is the ratio of true-positives compared to all potentially possible detections (i.e., to the number of all visible objects):

The miss rate (MR) is the ratio of false-negatives compared to all objects in an image. False-positives per image (FPPI) is the ratio of false-positives compared to all detected objects in an image:

In case of multiple images, the mean of measures can be used (i.e., averaged over all the processed images).
How to decide whether a detected object is true-positive? Assume that objects in images have been locally identified manually by bounding boxes, serving as the ground truth. All detected objects are matched with these ground-truth boxes by calculating ratios of areas of overlapping regions

where ![]() denotes the area of a region in an image,
denotes the area of a region in an image, ![]() is the detected bounding box of the object, and
is the detected bounding box of the object, and ![]() is the area of the bounding box of the matched ground-truth box. If
is the area of the bounding box of the matched ground-truth box. If ![]() is larger than a threshold
is larger than a threshold ![]() , say
, say ![]() , then the detected object is taken as a true-positive.
, then the detected object is taken as a true-positive.
1.3.3.2 Object Tracking
Object tracking is an important task for understanding the motion of a mobile platform or of other objects in a dynamic environment. The mobile platform with the installed system is also called the ego-vehicle whose ego-motion needs to be calculated for understanding the movement of the installed sensors in the three-dimensional (3D) world.
Calculated features in subsequent frames ![]() can be tracked (e.g., by using RANSAC for identifying an affine transform between feature points) and then used for estimating ego-motion based on bundle adjustment. This can also be combined with another module using nonvisual sensor data such as GPS or of an inertial measurement unit (IMU). For example, see Geng et al. (2015) for an integration of GPS data.
can be tracked (e.g., by using RANSAC for identifying an affine transform between feature points) and then used for estimating ego-motion based on bundle adjustment. This can also be combined with another module using nonvisual sensor data such as GPS or of an inertial measurement unit (IMU). For example, see Geng et al. (2015) for an integration of GPS data.
Other moving objects in the scene can be tracked using repeated detections or by following a detected object in frame ![]() to frame
to frame ![]() . A Kalman filter (e.g., linear, general, or unscented) can be used for building a model for the motion as well as for involved noise. A particle filter can also be used based on extracted weights for potential moves of a particle in particle space. Kalman and particle filters are introduced, with references to related original sources, in Klette (2014).
. A Kalman filter (e.g., linear, general, or unscented) can be used for building a model for the motion as well as for involved noise. A particle filter can also be used based on extracted weights for potential moves of a particle in particle space. Kalman and particle filters are introduced, with references to related original sources, in Klette (2014).
1.3.4 Semantic Segmentation
When segmenting a scene, ideally obtained segments should correspond to defined objects in the scene, such as a house, a person, or a car in a road scene. These segments define semantic segmentation. Segmentation for vehicle technology aims at semantic segmentation (Floros and Leibe 2012; Ohlich et al. 2012) with temporal consistency along a recorded video sequence. Appearance is an important concept for semantic segmentation (Mohan 2014). The concept of super pixels (see, e.g., Liu et al. (2012)) might be useful for achieving semantic segmentation. Temporal consistency requires tracking of segments and similarity calculations between tracked segments.
1.3.4.1 Environment Analysis
There are static (i.e., fixed with respect to the Earth) or dynamic objects in a scenario which need to be detected, understood, and possibly further analyzed.
A flying helicopter (or just multi-copter) should be able to detect power lines or other potential objects defining a hazard. Detecting traffic signs or traffic lights, or understanding lane borders of highways or suburban roads are examples for driving vehicles. Boats need to detect buoys and beacons.
Pedestrian detection became a common subject for road-analysis projects. After detecting a pedestrian on a pathway next to an inner-city road, it would be helpful to understand whether this pedestrian intends to step onto the road in the next few seconds.
After detecting more and more objects, we may have the opportunity to model and understand a given environment.
1.3.4.2 Performance Evaluation of Semantic Segmentation
There is a lack of provided ground truth for semantic segmentations in traffic sequences. Work reported in current publications on semantic segmentation, such as Floros and Leibe (2012) and Ohlich et al. (2012), can be used for creating test databases. There is also current progress in available online data; see www.cvlibs.net/datasets/kitti/eval_road.php, www.cityscapes-dataset.net, and (Ros et al. 2015) for a study for such data.
Barth et al. (2010) proposed a method for segmentation, which is based on evaluating pixel probabilities of whether they are in motion in the real world or not (using scene flow and ego-motion). Barth et al. (2010) also provides ground truth for image segmentation in Set 7 of EISATS, illustrated by Figure 1.12. Figure 1.12 also shows resulting SGM stereo maps andsegments obtained when following the multi-module approach briefly sketched earlier.

Figure 1.12 Two examples for Set 7 of EISATS illustrated by preprocessed depth maps following the described method (Steps 1 and 2). Ground truth for segments is provided by Barth et al. (2010) and shown on top in both cases. Resulting segments using the described method are shown below in both cases;
courtesy of Simon Hermann
Modifications in the involved modules for stereo matching and optical flow calculation influence the final result. There might be dependencies between performances of contributing programs.
1.4 Concluding Remarks
The vehicle industry worldwide has assigned major research and development resources for offering competitive solutions for vision-based components for vehicles. Research at academic institutions needs to address future or fundamental tasks, challenges that are not of immediate interest for the vehicle industry, for being able to continue to contribute to this area.
The chapter introduced basic notation and selected visual tasks. It reviewed work in the field of computer vision in vehicles. There are countless open questions in this area, often related to
- 1. adding further alternatives to only a few existing robust solutions for one generic or specific task,
- 2. a comparative evaluation of such solutions,
- 3. ways of analyzing benchmarks for their particular challenges,
- 4. the design of more complex systems, and
- 5. ways to test such complex systems.
Specifying and solving a specific task might be a good strategy to define fundamental research, ahead of currently extremely intense industrial research and development within the area of computer vision for vehicles. Aiming at robustness including challenging scenarios and understanding interactions in dynamic scenes between multiple moving objects are certainly examples where further research is required.
Computer vision can help to solve true problems in society or industry, thus contributing to the prevention of social harms or atrocities; it is a fundamental ethical obligation of researchers in this field not to contribute to those, for example, by designing computer vision solutions for the use in UAVs for killing people. Academics identify ethics in research often with subjects such as plagiarism, competence, or objectivity, and a main principle is also social responsibility. Computer vision in road vehicles can play, for example, a major role in reducingcasualties in traffic accidents, which are counted by hundreds of thousands of people worldwide each year; it is a very satisfying task for a researcher to contribute to improved road safety.
Acknowledgments
The author thanks Simon Hermann, Mahdi Rezaei, Konstantin Schauwecker, Junli Tao, and Garry Tee for comments on drafts of this chapter.