
Chapter 7
Getting Your Data into the Computer
In This Chapter
![]() Understanding levels of measurement (nominal, ordinal, interval, and ratio)
Understanding levels of measurement (nominal, ordinal, interval, and ratio)
![]() Defining and entering different kinds of data into your research database
Defining and entering different kinds of data into your research database
![]() Making sure your data is accurate
Making sure your data is accurate
![]() Creating a data dictionary to describe the data in your database
Creating a data dictionary to describe the data in your database
Before you can analyze data, you have to collect it and get it into the computer in a form that’s suitable for analysis. Chapter 5 describes this process as a series of steps — figuring out what data you need and how it’s structured, creating the case report forms (CRFs) and computer files to hold your data, and entering and validating your data.
In this chapter, I describe a crucially important component of that process — storing the data properly in your research data base. Different kinds of data can be represented in the computer in different ways. At the most basic level, there are numbers and categories, and most of us can immediately tell the two apart — you don’t have to be a math genius to recognize age as numerical data and gender as categorical info.
So why am I devoting a whole chapter to describing, entering, and checking different types of data? It turns out that the topic of data type is not quite as trivial as it may seem at first — there are some subtleties you should be aware of; otherwise, you may wind up collecting your data the wrong way and finding out too late that you can’t run the appropriate analysis on it. Or you may use the wrong statistical technique and get incorrect or misleading results. This chapter explains the different levels of measurements, shows how to define and enter different types of data, suggests ways to check your data for errors, and shows how to formally describe your database so that others are able to work with it if you’re not around.
Looking at Levels of Measurement
Around the middle of the 20th century, the idea of levels of measurement caught the attention of biological and social-science researchers, and, in particular, psychologists. One classification scheme, which has become very widely used (at least in statistics textbooks), recognizes four different levels at which variables can be measured: nominal, ordinal, interval, and ratio:
![]() Nominal variables are expressed as mutually exclusive categories, like gender (male or female), race (white, black, Asian, and so forth), and type of bacteria (such as coccus, bacillus, rickettsia, mycoplasma, or spirillum), where the sequence in which you list a variable’s different categories is purely arbitrary. For example, listing a choice of races as black, asian, and white is no more or less “natural” than listing them as white, black, and asian.
Nominal variables are expressed as mutually exclusive categories, like gender (male or female), race (white, black, Asian, and so forth), and type of bacteria (such as coccus, bacillus, rickettsia, mycoplasma, or spirillum), where the sequence in which you list a variable’s different categories is purely arbitrary. For example, listing a choice of races as black, asian, and white is no more or less “natural” than listing them as white, black, and asian.
![]() Ordinal data has categorical values (or levels) that fall naturally into a logical sequence, like the severity of an adverse event (slight, moderate, or severe), or an agreement scale (strongly disagree, disagree, no opinion, agree, or strongly agree), often called a Likert scale. Note that the levels are not necessarily “equally spaced” with respect to the conceptual difference between levels.
Ordinal data has categorical values (or levels) that fall naturally into a logical sequence, like the severity of an adverse event (slight, moderate, or severe), or an agreement scale (strongly disagree, disagree, no opinion, agree, or strongly agree), often called a Likert scale. Note that the levels are not necessarily “equally spaced” with respect to the conceptual difference between levels.
![]() Interval data is a numerical measurement where, unlike ordinal data, the difference (or interval) between two numbers is a meaningful measure of the amount of difference in what the variable represents, but the zero point is completely arbitrary and does not denote the complete absence of what you’re measuring. An example of this concept is the metric Celsius temperature scale. A change from 20 to 25 degrees Celsius represents the same amount of temperature increase as a change from 120 to 125 degrees Celsius. But 0 degrees Celsius is purely arbitrary — it does not represent the total absence of temperature; it’s simply the temperature at which water freezes (or, if you prefer, ice melts).
Interval data is a numerical measurement where, unlike ordinal data, the difference (or interval) between two numbers is a meaningful measure of the amount of difference in what the variable represents, but the zero point is completely arbitrary and does not denote the complete absence of what you’re measuring. An example of this concept is the metric Celsius temperature scale. A change from 20 to 25 degrees Celsius represents the same amount of temperature increase as a change from 120 to 125 degrees Celsius. But 0 degrees Celsius is purely arbitrary — it does not represent the total absence of temperature; it’s simply the temperature at which water freezes (or, if you prefer, ice melts).
![]() Ratio data, unlike interval data, does have a true zero point. The numerical value of a ratio variable is directly proportional to how much there is of what you’re measuring, and a value of zero means there’s nothing at all. Mass is a ratio measurement, as is the Kelvin temperature scale — it starts at the absolute zero of temperature (about 273 degrees below zero on the Celsius scale), where there is no thermal energy at all.
Ratio data, unlike interval data, does have a true zero point. The numerical value of a ratio variable is directly proportional to how much there is of what you’re measuring, and a value of zero means there’s nothing at all. Mass is a ratio measurement, as is the Kelvin temperature scale — it starts at the absolute zero of temperature (about 273 degrees below zero on the Celsius scale), where there is no thermal energy at all.
 Statisticians tend to beat this topic to death — they love to point out cases that don’t fall neatly into one of the four levels and to bring up various counterexamples. But you need to be aware of the concepts and terminology in the preceding list because you’ll see them in statistics textbooks and articles, and because teachers love to include them on tests. And, more practically, knowing the level of measurement of a variable can help you choose the most appropriate way to analyze that variable. I make reference to these four levels — nominal, ordinal, interval, and ratio — at various times in this chapter and in the rest of this book.
Statisticians tend to beat this topic to death — they love to point out cases that don’t fall neatly into one of the four levels and to bring up various counterexamples. But you need to be aware of the concepts and terminology in the preceding list because you’ll see them in statistics textbooks and articles, and because teachers love to include them on tests. And, more practically, knowing the level of measurement of a variable can help you choose the most appropriate way to analyze that variable. I make reference to these four levels — nominal, ordinal, interval, and ratio — at various times in this chapter and in the rest of this book.
Classifying and Recording Different Kinds of Data
Although you should be aware of the four levels of measurement described in the preceding section, you also need to be able to classify and deal with data in a more pragmatic way. The following sections describe various common types of data you’re likely to encounter in the course of biological or clinical research. I point out some things you need to think through before you start collecting your data.
 Few things can mess up a research database, and quite possibly doom a study to eventual failure, more surely than bad decisions (or no decisions) about how to represent the data elements that make up the database. If you collect data the wrong way, it may take an enormous amount of additional effort to go back and get it the right way, if you can retrieve the right data at all.
Few things can mess up a research database, and quite possibly doom a study to eventual failure, more surely than bad decisions (or no decisions) about how to represent the data elements that make up the database. If you collect data the wrong way, it may take an enormous amount of additional effort to go back and get it the right way, if you can retrieve the right data at all.
Dealing with free-text data
It’s best to limit free-text variables to things like subject comments or write-in fields for Other choices in a questionnaire — basically, only those things where you need to record verbatim what someone said or wrote. Don’t use free-text fields as a lazy-person’s substitute for what should be precisely defined categorical data (which I discuss later in this chapter). Doing any meaningful statistical analysis of free-text fields is generally very difficult, if not impossible.
You should also be aware that most software has field-length limitations for text fields. Current versions of Excel, SPSS, SAS, and so on have very high limits, but other programs (or earlier versions of these programs) may have much lower limits (perhaps 63, 255, or 1,023 characters). Flip to Chapter 4 for an introduction to statistical software.
Assigning subject identification (ID) numbers
Every subject in your study should have a unique Subject Identifier (or ID), which is used for recording information, for labeling specimens sent to labs for analysis, and for collecting all a subject’s information in the database. In a single-site study (one that is carried out at only one geographical location), this ID can usually be a simple number, two to four digits long. It doesn’t have to start at 1; it can start at 100 if you want all the ID numbers to be three digits long without leading zeros. In multi-site studies (those carried out at several locations, such as different institutions, different clinics, different doctors’ offices, and so on), the number often has two parts — a site number and a subject-within-site number, separated by a hyphen, such as 03-104.
Organizing name and address data
 A research database usually doesn’t need to have the full name or the address of the subject, and sometimes these data elements are prohibited for privacy reasons. But if you do need to store a name (if you anticipate generating mailings like appointment reminders or follow-up letters, for example), use one of the following formats so that you can easily sort subjects into alphabetical order:
A research database usually doesn’t need to have the full name or the address of the subject, and sometimes these data elements are prohibited for privacy reasons. But if you do need to store a name (if you anticipate generating mailings like appointment reminders or follow-up letters, for example), use one of the following formats so that you can easily sort subjects into alphabetical order:
![]() A single variable: Last, First Middle (like Smith, John A)
A single variable: Last, First Middle (like Smith, John A)
![]() Two columns: One for Last, another for First and Middle
Two columns: One for Last, another for First and Middle
You may also want to include separate fields to hold prefixes (Mr., Mrs., Dr., and so on) and suffixes (Jr., III, PhD, and so forth).
Addresses should be stored in separate fields for street, city, state (or province), ZIP code (or comparable postal code), and perhaps country.
Collecting categorical data
Setting up your data collection forms and database tables for categorical data requires more thought than you may expect. Everyone assumes he knows how to record and enter categorical data — you just type what that data is (for example, Male, White, Diabetes, or Headache), right? Bad assumption! The following sections look at some of the issues you have to deal with.
Carefully coding categories
The first issue is how to “code” the categories (how to represent them in the database). Do you want to enter Gender as Male/Female, M/F, 1 (if male) or 2 (if female), or in some other manner? Most modern statistical software can analyze categorical data with any of these representations, but some older software needs the categories coded as consecutive numbers: 1, 2, 3, and so on. Some software lets you specify a correspondence between number and text (1=Male, 2=Female, for instance); then you can type it in either way, and you can choose to display it in either the numeric or textual form.
Nothing is worse than having to deal with a data set in which Gender has been coded as 1 or 2, with no indication of which is which, when the person who created the file is long gone. So it’s probably best to enter the category values as short, meaningful text abbreviations like M or F, or Male or Female, which are self-evident and, therefore, self-documenting.
Excel doesn’t care what you type in, and this characteristic is one of its biggest drawbacks when it’s used as a data repository. You can enter Gender as M for the first subject, Male for the second, male for the third, 2 for the fourth, and m for the fifth, and Excel couldn’t care less. But most statistics programs consider each of these to be a completely different category! Even worse, you may inadvertently type one or more blank spaces before and/or after the text. You may never notice it, but some statistics programs consider M~ to be different from ~M, ~M~, and M~~. (I use ~ to stand for a blank space.) Therefore, in Excel, it’s a good idea to enable AutoComplete for cell values (in the Advanced section of the Options dialog box, located in the File menu). Then when you start typing something in a cell, it suggests something that’s already present in that column and begins with the same letter or letters that you typed.
Dealing with more than two levels in a category
When a categorical variable has more than two levels (like the bacteria type or Likert agreement scale examples I describe in the earlier section Looking at Levels of Measurement), things get even more interesting. First, you have to ask yourself, “Is this variable a Choose only one or Choose all that apply variable?” The coding is completely different for these two kinds of multiple-choice variables.
You handle the Choose only one situation just as I describe for Gender in the preceding section — you establish a short, meaningful alphabetic code for each alternative. For the Likert scale example, you could have a categorical variable called Attitude, with five possible values: SD (strongly disagree), D (disagree), NO (no opinion), A (agree), and SA (strongly agree). And for the bacteria type example, if only one kind of bacteria is allowed to be chosen, you can have a categorical variable called BacType, with five possible values: coccus, bacillus, rickettsia, mycoplasma, and spirillum. (Or even better, to reduce the chance of misspellings, you can use short abbreviations such as: coc, bac, ric, myc, and spi.)
But things are quite different if the variable is Choose all that apply. For the bacteria types example, if several types of bacteria can be present in the same specimen, you have to set up your database differently. Define separate variables in the database (separate columns in Excel) — one for each possible category value. So you have five variables, perhaps called BTcoc, BTbac, BTric, BTmyc, and BTspi (the BT stands for bacteria type). Each variable is a two-value category (perhaps with values Pres/Abs — which stand for present and absent — or Yes/No, or 1 or 0). So, if Subject 101’s specimen has coccus, Subject 102’s specimen has bacillus and mycoplasma, and Subject 103’s specimen has no bacteria at all, the information can be coded as shown in the following table.
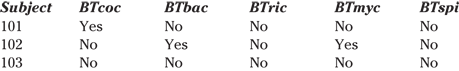
You can handle missing values by leaving the cell blank, but an even better way is to add a category called Missing to the regular categories of that variable. If you need several different flavors of Missing (like not collected yet, don’t know, other, refused to answer, or not applicable), just add them to the set of permissible levels for that categorical variable. The idea is to make sure that you can always enter something for that variable.
Never try to cram multiple choices into one column — don’t enter coc,bac into a cell in the BacType column. If you do, the resulting column will be almost impossible to analyze statistically, and you’ll have to take the time later to painstakingly split your single multi-valued column into separate yes/no columns as I describe earlier. So why not do it right the first time?
Recording numerical data
For numerical data, the main question is how much precision to record. Recording a numerical variable to as many decimals as you have available is usually best. For example, if a scale can measure body weight to the nearest 1/10 of a kilogram, record it in the database to that degree of precision. You can always round off to the nearest kilogram later if you want, but you can never “unround” a number to recover digits you didn’t record. Just don’t go overboard in this direction — don’t record a person’s weight as 85.648832 kilograms, even if a digital scale shows it to such ridiculous precision.
Along the same lines, don’t group numerical data into intervals when recording it. Don’t record Age in 10-year intervals (0 to 9, 10 to 19, and so on) if you know the age to the nearest year. You can always have the computer do that kind of grouping later, but you can never recover the age in years if all you record is the decade.
Some programs let you choose between several ways of storing the number in the computer. The program may refer to these different storage modes using arcane terms for short, long, or very long integers (whole numbers) or single-precision (short) or double-precision (long) floating point (fractional) numbers. Each type has its own limits, which may vary from one program to another or from one kind of computer to another. For example, a short integer might be able to represent only whole numbers within the range from –32,768 to +32,767, whereas a double-precision floating-point number could easily handle a number like 1.23456789012345 × 10250. In the old days, the judicious choice of storage modes for your variables could produce smaller files and let the program work with more subjects or more variables. Nowadays, storage is much less of an issue than it used to be, so pinching pennies this way offers little benefit. Go for the most general numeric representation available — usually double-precision floating point, which can represent just about any number you may ever encounter in your research.
Here are a couple things to watch out for with numerical variables in Excel:
![]() Don’t put two numbers (such as a blood pressure reading of 135/85 mmHg) into one column of data. Excel won’t complain about it, but it will treat it as text because of the embedded “/”, rather than as numerical data. Instead, create two separate variables — such as the systolic and diastolic pressures (perhaps called BPS for blood pressure systolic and BPD for blood pressure diastolic) — and enter each number into the appropriate variable.
Don’t put two numbers (such as a blood pressure reading of 135/85 mmHg) into one column of data. Excel won’t complain about it, but it will treat it as text because of the embedded “/”, rather than as numerical data. Instead, create two separate variables — such as the systolic and diastolic pressures (perhaps called BPS for blood pressure systolic and BPD for blood pressure diastolic) — and enter each number into the appropriate variable.
![]() In an obstetrical database, don’t enter 6w2d for a gestational age of 6 weeks and 2 days; even worse, don’t enter it as 6.2, which the computer would interpret as 6.2 weeks. Either enter it as 44 days, or create two variables (perhaps GAwks for gestational age weeks and GAdays for gestational age days), to hold the values 6 and 2, respectively. The computer can easily combine them later into the number of days or the number of weeks (and fractions of a week).
In an obstetrical database, don’t enter 6w2d for a gestational age of 6 weeks and 2 days; even worse, don’t enter it as 6.2, which the computer would interpret as 6.2 weeks. Either enter it as 44 days, or create two variables (perhaps GAwks for gestational age weeks and GAdays for gestational age days), to hold the values 6 and 2, respectively. The computer can easily combine them later into the number of days or the number of weeks (and fractions of a week).
Missing numerical data requires a little more thought than missing categorical data. Some researchers use 99 (or 999, or 9999) to indicate a missing value. If you use that technique, all your analyses will have to ignore those values. Fortunately, many statistics programs let you specify what the missing value indicator is for each variable, and the programs exclude those values from all analyses. But can you really be sure you’ll never have that value pop up as a real value for some very atypical subject? (Some people are 99 years old, and some people can have a blood glucose value of 999 mg/dL). Simply leaving the cell blank may be best; almost all programs treat blank cells as missing data.
Entering date and time data
Now I’m going to tell you something that sounds like I’m contradicting the advice I just gave you (but, of course, I’m not!). Most statistical software can represent dates and times as a single variable (an “instant” on a continuous timeline), so take advantage of that if you can — enter the date and time as one variable (for example, 07/15/2010 08:23), not as a date variable and a time variable. This method is especially useful when dealing with events that take place over a short time interval (like events occurring during labor and delivery).
 Most statistical programs store date and time internally as a number, specifying the number of days (and fractions of days) from some arbitrary “zero date.” Here are the zero dates for a few common programs:
Most statistical programs store date and time internally as a number, specifying the number of days (and fractions of days) from some arbitrary “zero date.” Here are the zero dates for a few common programs:
![]() Excel: Midnight at the start of December 31, 1899 (this is also the earliest date that Excel can store). So November 21, 2012, at 6:00 p.m., is stored internally as 41,234.75 (the .75 is because 6 p.m. is 3/4 of the way through that day).
Excel: Midnight at the start of December 31, 1899 (this is also the earliest date that Excel can store). So November 21, 2012, at 6:00 p.m., is stored internally as 41,234.75 (the .75 is because 6 p.m. is 3/4 of the way through that day).
![]() SPSS: October 14, 1582 (the date the Gregorian calendar was adopted to replace the Julian calendar).
SPSS: October 14, 1582 (the date the Gregorian calendar was adopted to replace the Julian calendar).
![]() SAS: 01/01/1960 (a totally arbitrary date).
SAS: 01/01/1960 (a totally arbitrary date).
Some programs may store a date and time as a Julian Date, whose zero occured at noon, Greenwich mean time, on Jan. 1, 4713 BC. (Nothing happened on that date; it's purely a numerical convenience. See www.magma.ca/~scarlisl/DRACO/julian_d.html for an interesting account of this.)
What if you don’t know the day of the month? This happens a lot with medical history items; you hear something like “I got the flu in September 2004.” Most software insists that a date variable be a complete date and won’t accept just a month and a year. In this case, an argument can be made for setting the day to 15 (around mid-month), on the grounds that the error is equally likely to be on either side and therefore tends to cancel out, on average. Similarly, if both the month and day are missing, you can set them to June 30 or July 1 (around mid-year) to achieve the same kind of average error cancellation. If only some records have partial dates, you may want to create another variable to indicate whether the date is complete or partial, so you can tell, if you need to, whether 09/15/2004 really means September 15, 2004, or just September 2004.
Completely missing dates should usually just be left blank; most statistical software treats blank cells as missing data.
Because of the way most statistics programs store dates and times, they can easily calculate intervals between any two points in time by simple subtraction. So it’s usually easier and safer to enter dates and times and let the computer calculate the intervals than to calculate them yourself. For example, if you create variables for date of birth (DOB) and a visit date (VisDt) in Excel, you can often calculate a very accurate age at the time of the visit with this formula:
Age = (VisDt – DOB)/365.25
Similarly, in cancer studies, you can easily and accurately calculate intervals from diagnosis or treatment to remission and recurrence, as well as total survival time, from the dates of the corresponding events.
Checking Your Entered Data for Errors
After you’ve entered all your data into the computer, there are a few things you can do to check for errors:
![]() Examine the smallest and largest values: Have the software show you the smallest and largest values for each variable. This check can often catch decimal-point errors (such as a hemoglobin value of 125 g/dL instead of 12.5 g/dL) or transposition errors (for example, a weight of 517 pounds instead of 157 pounds).
Examine the smallest and largest values: Have the software show you the smallest and largest values for each variable. This check can often catch decimal-point errors (such as a hemoglobin value of 125 g/dL instead of 12.5 g/dL) or transposition errors (for example, a weight of 517 pounds instead of 157 pounds).
![]() Sort the values of variables: If your program can show you a sorted list of all the values for a variable, that’s even better — it often shows misspelled categories as well as numerical outliers.
Sort the values of variables: If your program can show you a sorted list of all the values for a variable, that’s even better — it often shows misspelled categories as well as numerical outliers.
![]() Search for blanks and commas: You can have Excel search for blanks in category values that shouldn’t have blanks or for commas in numeric variables. Make sure the “Match entire cell contents” option is deselected in the Find and Replace dialog box (you may have to click the Options button to see the check box).
Search for blanks and commas: You can have Excel search for blanks in category values that shouldn’t have blanks or for commas in numeric variables. Make sure the “Match entire cell contents” option is deselected in the Find and Replace dialog box (you may have to click the Options button to see the check box).
![]() Tabulate categorical variables: You can have your statistics program tabulate each categorical variable (showing you how many times each different category occurred in your data). This check usually finds misspelled categories.
Tabulate categorical variables: You can have your statistics program tabulate each categorical variable (showing you how many times each different category occurred in your data). This check usually finds misspelled categories.
![]() Shrink a spreadsheet’s cells: If you have the PopTools add-in installed in Excel (see Chapter 4), you can use the “Make a map of current sheet” feature, which creates a new worksheet with a miniature view of your data sheet. Each cell in the map sheet is shrunk down to a small square and is color-coded to indicate the type of data in the cell — character, numeric, formula, or blank. With this view, you can often spot typing errors that have turned a numeric variable into text (like a comma instead of a decimal point, or two decimal points).
Shrink a spreadsheet’s cells: If you have the PopTools add-in installed in Excel (see Chapter 4), you can use the “Make a map of current sheet” feature, which creates a new worksheet with a miniature view of your data sheet. Each cell in the map sheet is shrunk down to a small square and is color-coded to indicate the type of data in the cell — character, numeric, formula, or blank. With this view, you can often spot typing errors that have turned a numeric variable into text (like a comma instead of a decimal point, or two decimal points).
Chapter 8 describes some other ways you can check for unreasonable data.
Creating a File that Describes Your Data File
Every research database, large or small, simple or complicated, should be accompanied by a data dictionary that describes the variables contained in the database. It will be invaluable if the person who created the database is no longer around. A data dictionary is, itself, a data file, containing one record for every variable in the database. For each variable, the dictionary should contain most of the following information (sometimes referred to as metadata, which means “data about data”):
![]() A short variable name (usually no more than eight or ten characters) that’s used when telling the software what variables you want it to use in an analysis
A short variable name (usually no more than eight or ten characters) that’s used when telling the software what variables you want it to use in an analysis
![]() A longer verbal description of the variable (up to 50 or 100 characters)
A longer verbal description of the variable (up to 50 or 100 characters)
![]() The type of data (text, categorical, numerical, date/time, and so on)
The type of data (text, categorical, numerical, date/time, and so on)
• If numeric: Information about how that number is displayed (how many digits are before and after the decimal point)
• If date/time: How it’s formatted (for example, 12/25/13 10:50pm or 25Dec2013 22:50)
• If categorical: What the permissible categories are
![]() How missing values are represented in the database (99, 999, “NA,” and so on)
How missing values are represented in the database (99, 999, “NA,” and so on)
Many statistical packages allow (or require) you to specify this information when you’re creating the file anyway, so they can generate the data dictionary for you automatically. But Excel lets you enter anything anywhere, without formally defining variables, so you need to create the dictionary yourself (perhaps as another worksheet — which you can call “Data Dictionary” — in the same Excel file that has the data, so that the data dictionary always stays with the data).