
Chapter 3. Access Control Models
This chapter covers the following topics:
• Information Security Principles
• Subject and Object Definition
• Information Security Roles and Responsibilities
• Identity and Access Control Implementation
One of the foundational topics of information security is access controls. Access controls is a broad term used to define the administrative, physical, and technical controls that regulate the interaction between a subject and an object. More simply, access controls help with defining and enforcing policy for who is authorized to access what and in which way.
“Do I Know This Already?” Quiz
The “Do I Know This Already?” quiz allows you to assess whether you should read this entire chapter thoroughly or jump to the “Exam Preparation Tasks” section. If you are in doubt about your answers to these questions or your own assessment of your knowledge of the topics, read the entire chapter. Table 3-1 lists the major headings in this chapter and their corresponding “Do I Know This Already?” quiz questions. You can find the answers in Appendix A, “Answers to the ‘Do I Know This Already?’ Quizzes and Review Questions.”
Table 3-1 “Do I Know This Already?" Section-to-Question Mapping

Caution
The goal of self-assessment is to gauge your mastery of the topics in this chapter. If you do not know the answer to a question or are only partially sure of the answer, you should mark that question as wrong for purposes of the self-assessment. Giving yourself credit for an answer you incorrectly guess skews your self-assessment results and might provide you with a false sense of security.
1. Which of the following ensures that only authorized users can modify the state of a resource?
a. Integrity
b. Availability
c. Confidentiality
d. Non-repudiation
2. What entity requests access to a resource?
a. Object
b. Subject
c. File
d. Database
3. In which phase of access control does a user need to prove his or her identity?
a. Identification
b. Authentication
c. Authorization
d. Accounting
4. Which of the following authentication methods can be considered examples of authentication by knowledge? (Select all that apply.)
a. Password
b. Token
c. PIN
d. Fingerprint
5. When a biometric authentication system rejects a valid user, which type of error is generated?
a. True positive
b. False positive
c. False rejection
d. Crossover error
6. In military and governmental organizations, what is the classification for an asset that, if compromised, would cause severe damage to the organization?
a. Top Secret
b. Secret
c. Confidential
d. Unclassified
7. What is a common way to protect “data at rest”?
a. Encryption
b. Transport Layer Security
c. Fingerprint
d. IPsec
8. Who is ultimately responsible for security control of an asset?
a. Senior management
b. Data custodian
c. User
d. System administrator
9. Which types of access controls are used to protect an asset before a breach occurs? (Select all that apply.)
a. Preventive
b. Deterrent
c. Corrective
d. Recovery
10. Which access control model uses environmental information to make an access decision?
a. Discretionary access control
b. Attribute-based access control
c. Role-based access control
d. Mandatory access control
11. What is the main advantage of using a mandatory access control (MAC) model instead of a discretionary access control (DAC) model?
a. MAC is more secure because the operating system ensures security policy compliance.
b. MAC is more secure because the data owner can decide which user can get access, thus providing more granular access.
c. MAC is more secure because permissions are assigned based on roles.
d. MAC is better because it is easier to implement.
12. Which of the following are part of a security label used in the mandatory access control model? (Select all that apply.)
a. Classification
b. Category
c. Role
d. Location
13. Which access control model uses the function of a subject in an organization?
a. Discretionary access control
b. Attribute-based access control
c. Role-based access control
d. Mandatory access control
14. Which of the following is the easiest way to implement a DAC-based system?
a. Deploying an IPS
b. Deploying a DLP system
c. Deploying a cloud-access broker
d. An access control list
15. Which IDS system can detect attacks using encryption?
a. Network IDS deployed in inline mode
b. Network IDS deployed in promiscuous mode
c. Host-based IDS
d. Network IPS deployed in inline mode
16. Which of the following is not a disadvantage of host-based antimalware?
a. It requires updating multiple endpoints.
b. It does not have visibility into encrypted traffic.
c. It does not have visibility of all events happening in the network.
d. It may require working with different operating systems.
17. Which type of access list works better when implementing RBAC?
a. Layer 2 access list
b. MAC access list
c. VLAN map
d. Security group access control list
18. Which of the following is not a true statement about TACACS+?
a. It offers command-level authorization.
b. It is proprietary to Cisco.
c. It encrypts the TACACS+ header.
d. It works over TCP.
19. What is used in the Cisco TrustSec architecture to provide link-level encryption?
a. MACsec
b. IPsec
c. TLS
d. EAP
Foundation Topics
Information Security Principles
Before we delve into access control fundamentals, processes, and mechanisms, it is important to revisit the concepts of confidentiality, integrity, and availability, which were explored in Chapter 1, “Cybersecurity Fundamentals,” and understand their relationship with access controls:
• Confidentiality: Access controls are used to ensure that only authorized users can access resources. An example of such control would be a process that ensures that only authorized people in an engineering department are able to read the source code of a product under development. Attacks to access controls that protect the confidentiality of a resource would typically aim at stealing sensitive or confidential information.
• Integrity: Access controls are used to ensure that only authorized users can modify the state of a resource. An example of this control would be a process that allows only authorized people in an engineering department to change the source code of a product under development. Attacks to access controls that protect the integrity of a resource would typically aim at changing information. In some cases, when the changes are disruptive, the same attack would also have an impact on the availability of the resource. For example, an attack that causes the deletion of a user from a database would have an impact on the integrity but also a secondary impact on the availability because that user would not be able to access the system.
• Availability: Access controls would typically ensure that the resource is available to users who are authorized to access it in a reasonable amount of time. Attacks that would affect the availability typically aim at disabling access to a resource. Denial-of-service (DoS) attacks are simple examples of attacks against the availability of a resource.
Subject and Object Definition
As stated earlier, access controls is a broad term used to define the administrative, physical, and technical controls that regulate the interaction between a subject and an object. A subject is defined as any active entity that requests access to a resource (also called an object). The subject usually performs the request on behalf of a principal. An object is defined as the passive entity that is, or contains, the information needed by the subject.
The role of the subject or object is purely determined on the entity that requests the access. The same entity could be considered a subject or an object, depending on the situation. For example, a web application could be considered a subject when a user, the principal, runs the browser program (the subject requesting information). The web application, however, would need to query an internal database before being able to provide the requested information. In this latter case, the web application would be the subject, and the database would be considered the object in the transaction.
Access controls are any types of controls that regulate and make authorization decisions based on the access rights assigned to a subject for a specific object. The goal of an access control is to grant, prevent, or revoke access to a given object.
The following list highlights the key concepts about subject and object definition:
![]()
• A subject is the active entity that requests access to a resource.
• An object is the passive entity that is (or contains) the information needed by the subject and for which access is requested.
• Access controls are used in the process of granting, preventing, or revoking access to an object.
Figure 3-1 shows how the subject, object, and access control interact.

Figure 3-1 Interaction Between a Subject, Object, and Access Control
Access Control Fundamentals
Tip
Identity should not be considered secret.
Access controls help in defining and enforcing policies that regulate who can access a resource and what can be done with that resource once accessed. Four building blocks or processes characterize access controls: identification, authentication, authorization, and accounting. Although these have similar definitions and applicability, each uniquely defines a specific requirement of an access control system.
Identification
Identification is the process of providing the identity of a subject or user. This is the first step in the authentication, authorization, and accounting process. Providing a username, a passport, an IP address, or even pronouncing your name is a form of identification. A secure identity should be unique in the sense that two users should be able to identify themselves unequivocally. This is particularly important in the context of accounting and monitoring. Duplication of identity is possible if the authentication systems are not connected. For example, a user can use the same user ID for a corporate account and for a personal email account. A secure identity should also be nondescriptive so that information about the user’s identity cannot be inferred. For example, using “Administrator” as the user ID is generally not recommended. An identity should also be issued in a secure way. This includes all processes and steps in requesting and approving an identity request. This property is usually referred as secure issuance.
Tip
Identification and authentication are often performed together; however, it is important to understand that they are two different operations. Identification is about establishing who you are, whereas authentication is about proving you are the entity you claim to be.
The following list highlights the key concepts of identification.
![]()
• Secure identities should be unique. Two users with the same identity should not be allowed.
• Secure identities should be nondescriptive. It should not be possible to infer the role or function of the user. For example, a user called admin or omar represents a descriptive identity, whereas a user called c3214268 represents a nondescriptive identity.
• Secure identities should be securely issued. A secure process for issuing an identity to a user needs to be established.
Authentication
Authentication is the process of proving the identity of a subject or user. Once a subject has identified itself in the identification step, the enforcer has to validate the identity—that is, be sure that the subject (or user) is the one it is claiming to be. This is done by requesting that the subject (or user) provide something that is unique to the requestor. This could be something known only by the user, usually referred to as authentication by knowledge, or owned only by the user, usually referred to as authentication by ownership, or it could be something specific to the user, usually referred to as authentication by characteristic.
Authentication by Knowledge
In authentication by knowledge, the user provides a secret that is known only by him or her. An example of authentication by knowledge would be a user providing a password, entering a personal identification number (PIN) code, or answering security questions.
The disadvantage of using this method is that once the information is lost or stolen (for example, if a user’s password is stolen), an attacker would be able to successfully authenticate.
Authentication by Ownership
With authentication by ownership, the user is asked to provide proof that he or she owns something specific—for example, a system might require an employee to use a badge to access a facility. Another example of authentication by ownership is the use of a token or smart card.
Similar to the previous method, if an attacker is able to steal the object used for authentication from the user, the attacker would be able to successfully access the system.
Authentication by Characteristic
A system that uses authentication by characteristic authenticates the user based on some physical or behavioral characteristic, sometimes referred to as a biometric attribute. Here are the most-used physical or physiological characteristics:
• Fingerprints
• Facial recognition
• Retina and iris
• Palm and hand geometry
• Blood and vascular information
• Voice
Here are examples of behavioral characteristics:
• Signature dynamic
• Keystroke dynamic/pattern
The drawback of a system based on this type of authentication is that it’s prone to accuracy errors. For example, a signature-dynamic-based system would authenticate a user by requesting the user to write his or her signature and then comparing the signature pattern to a record in the system. Given that the way a person signs his or her name differs slightly every time, the system should be designed so that the user can still authenticate even if the signature and pattern are not exactly the one in the system. However, the system should also not be too loose and thus authenticate an unauthorized user attempting to mimic the pattern.
Two types of errors are associated with the accuracy of a biometric system:
• A Type I error, also called false rejection rate (FRR), happens when the system rejects a valid user who should have been authenticated.
• A Type II error, also called false acceptance rate (FAR), happens when the system accepts a user who should have been rejected (for example, an attacker trying to impersonate a valid user).
The crossover error rate (CER), also called the equal error rate (EER), is the point where FFR and FAR are equal. This is generally accepted as an indicator of the accuracy (and hence the quality) of a biometric system.
Table 3-2 lists the three authentication methods described in this section and provides a short description and examples of each.
![]()
Table 3-2 Authentication Methods

Multifactor Authentication
![]()
An authentication system may use more than one of the methods outlined in Table 3-2 (for example, a password and a badge). The system is said to use one-, two-, or three-factor authentication depending on how many authentication methods are requested. The higher the number of factors, the stronger the authentication system is. An authentication system is considered strong if it uses at least two different authentication methods.
Authorization
Authorization is the process of granting a subject access to an object or resource. This typically happens after the subject has completed the authentication process. A policy or rule needs to be established to describe in which cases a subject should be able to access the resource.
Additionally, when granting access, the authorization process would check the permissions associated with the subject/object pair so that the correct access right is provided. The object owner and management usually decide (or give input on) the permission and authorization policy that governs the authorization process.
The authorization policy and rule should take various attributes in consideration, such as the identity of the subject, the location from where the subject is requesting access, the subject’s role within the organization, and so on. Access control models, which are described in more detail later in this chapter, provide the framework for the authorization policy implementation.
An authorization policy should implement two concepts:
• Implicit deny: If no rule is specified for the transaction of the subject/object, the authorization policy should deny the transaction.
• Need to know: A subject should be granted access to an object only if the access is needed to carry out the job of the subject.
The permission could be abstract, such as “open the door,” or more formal, such as read, write, or execute a specific resource.
Accounting
Accounting is the process of auditing and monitoring what a user does once a specific resource is accessed. This process is sometimes overlooked; however, as a security professional, you need to be aware of accounting and to advocate that it be implemented due to the great help it provides during detection and investigation of cybersecurity breaches.
When accounting is implemented, an audit trail log is created and stored that details when the user has accessed the resource, what the user did with that resource, and when the user stopped using the resource. Given the potential sensitive information included in the auditing logs, special care should be taken in protecting them from unauthorized access.
Access Control Fundamentals: Summary
The following example summarizes the four-step process described in this section. In this example, a user wants to withdraw some money from an automated teller machine (ATM).
Step 1. When the user approaches the machine and inserts her bank card, she is identifying herself to the system.
Step 2. Once the user is identified, the system will ask her to confirm her identity, usually requesting a PIN code. This is the authentication step, and it’s performed by using authentication by knowledge.
Step 3. Once the user is authenticated, she is allowed to withdraw money from her account. She does not have the right, however, to withdraw more than $500. This is controlled by the authorization process, which will not authorize transactions larger than $500.
Step 4. After the user has withdrawn the money, the ATM system will log the information about the transaction, which includes information about the user, the location of the ATM and identification number, the user’s account number, the amount withdrawn, the date and time, and so on.
Table 3-3 summarizes the four phases of access control and includes examples of each phase.
![]()
Table 3-3 Access Control Process Phases

The following list highlights the key concepts of identification, authentication, authorization, and accounting:
• Identification is the process of providing identity.
• Authentication is the process of proving the identity.
• Authorization is the process of providing access to a resource with specific access rights.
• Accounting is the process of auditing and monitoring user operations on a resource.
Access Control Process
As described in the previous sections, the access control process governs the granting, preventing, or revoking of access to a resource. The core of an access control process is the establishment of an access control policy or rule that determines which type of access to assign and when.
To determine an access control policy, the policy owner needs an evaluation of the asset or data; that is, the owner needs to understand the importance of an organization’s asset so that adequate controls can be established. Then, the asset should be properly marked so that its classification is clear to everyone, and a disposal policy needs to be established for a time when the access is not needed anymore.
The following list highlights the key terminology related to the access control process:
![]()
• Asset or data classification is the process of classifying data based on the risk for the organization related to a breach on the confidentiality, integrity, and availability of the data.
• Asset marking is the process of marking or labeling assets or data so that its classification is clear to the user.
• Access policy definition is the process of defining policies and rules to govern access to an asset.
• Data disposal is the process of disposing or eliminating an asset or data.
Asset Classification
To protect an asset, an organization first needs to understand how important that asset is. For example, the unauthorized disclosure of the source code of a product might be more impactful on an organization than the disclosure of a public configuration guide. The first step in implementing an access control process is to classify assets or data based on the potential damage a breach to the confidentiality, integrity, or availability of that asset or data could cause.
This process is called asset or data classification, and there are several ways to classify assets. For example, military and governmental organizations commonly use the following classification definitions:
• Top Secret: Unauthorized access to top-secret information would cause grave damage to national security.
• Secret: Unauthorized access to secret information would cause severe damage to national security.
• Confidential: Unauthorized access to confidential information would cause damage to national security.
• Unclassified: Unauthorized access to unclassified information would cause no damage to national security.
The commercial sector has more variety in the way data classification is done—more specifically, to the label used in the classification. Here are some commonly used classification labels in the commercial sector:
• Confidential or Proprietary: Unauthorized access to confidential or proprietary information could cause grave damage to the organization. Examples of information or assets that could receive this type of classification include source code and trade secrets.
• Private: Unauthorized access to private information could cause severe damage to the organization. Examples of information or assets that could receive this type of classification are human resource information (for example, employee salaries), medical records, and so on.
• Sensitive: Unauthorized access to sensitive information could cause some damage to the organization. Examples of information or assets that could receive this type of classification are internal team email, financial information, and so on.
• Public: Unauthorized access to public information does not cause any significant damage.
Although the classification schema will differ from one company to another, it is important that all departments within a company use the schema consistently. For each label there should be a clear definition of when that label should be applied and what damage would be caused by unauthorized access. Because the classification of data may also be related to specific times or other contextual factors, the asset-classification process should include information on how to change data classification.
Table 3-4 summarizes the typical classification schemas for the two types of organizations discussed in this section.
Table 3-4 Classification Schema

Asset Marking
Once an asset has been classified with a specific category, a mark or label needs to be applied to the asset itself so that the classification level is clear to the user accessing the asset. Putting a stamp on a document with the label “Top Secret” and watermarking a digital document with the label “Confidential” are examples of the marking process.
Each asset should have a unique identifier. The most significant identifier is the device or program name. Although you may assume that the name is obvious, you’ll often find that different users, departments, and audiences refer to the same information, system, or device differently. Best practices dictate that the organization chooses a naming convention for its assets and apply the standard consistently. The naming convention may include the location, vendor, instance, and date of service. For example, a Microsoft Exchange server located in New York City and connected to the Internet may be named MS_EX_NYC_1. A SQL database containing inventory records of women’s shoes might be named SQL_SHOES_W. The name should also be clearly labeled physically on the device. The key is to be consistent so that the names themselves become pieces of information. This is, however, a double-edged sword. We risk exposing asset information to the public if our devices are accessible or advertise them in any way. We need to protect this information consistent with all other valuable information assets.
An asset description should indicate what the asset is used for. For example, devices may be identified as computers, connectivity, or infrastructure. Categories can (and should) be subdivided. Computers can be broken down into domain controllers, application servers, database servers, web servers, proxy servers’ workstations, laptops, tablets, smartphones, and smart devices. Connectivity equipment might include IDS/IPSs, firewalls, routers, satellites, and switches. Infrastructure might include HVAC, utility, and physical security equipment.
For hardware devices, the manufacturer name, model number, part number, serial number, and host name or alias can be recorded. The physical and logical addresses should also be documented. The physical address refers to the geographic location of the device itself or the device that houses the information.
Software should be recorded by publisher or developer, version number, revision, the department or business that purchased or paid for the asset number, and, if applicable, patch level. Software vendors often assign a serial number or “software key,” which should be included in the record.
Last but not least, the controlling entity should be recorded. The controlling entity is the department or business that purchased or paid for the asset and/or is responsible for the ongoing maintenance and upkeep expense. The controlling entity’s capital expenditures and expenses are reflected in its budgets, balance sheets, and profit and loss statements.
There are many tools in the market that can accelerate and automate asset inventory. Some of these tools and solutions can be cloud-based or installed on-premise. Asset management software and solutions help you monitor the complete asset life cycle from procurement to disposal. Some of these solutions support the automated discovery and management of all hardware and software inventory deployed in your network. Some also allow you to categorize and group your assets so that you can understand the context easily. These asset management solutions can also help you keep track of all your software assets and licenses so you can remain compliant. The following are a few examples of asset management solutions:
• ServiceNOW
• SolarWinds Web Help Desk
• InvGate Assets
• ManageEngine AssetExplorer
Access Control Policy
The next step of an access control process is to establish the access control policy for each asset or data. This is based on the label the asset received in the classification and marking steps described in the preceding sections. The access control policy should include information on who can access the asset or data, when, and in which mode. The access control policy also describes how the access should be protected, depending on its state, which could be any of the following:
• Data at rest refers to data that resides in a storage device such as a hard drive, CD or DVD, or magnetic drive. Data is in this state most of its lifetime. Data at rest is usually protected by using strong access controls and encryption.
• Data in motion refers to data moving between two parties, meaning it is in transit. When in this state, the data is subject to higher risk because it goes outside of the security perimeter where the data owner might not have control. End-to-end encryption and VPN technologies are usually used to protect data in motion.
• Data in use refers to data being processed by applications or programs and stored in a temporary or volatile memory such as random-access memory (RAM), a CPU register, and so on.
Data Disposal
An access control process should include information on how to dispose of an asset or data when it is not needed anymore, as defined by the organization’s data retention policy.
Data disposal may take several steps and use different technology. In fact, having a strong process for disposing data is equally important as setting up a process to protect the data when still in use. For example, one type of technique malicious actors use is called dumpster diving. In simple terms, dumpster divers try to find useful information for an attack by looking in the trash, hoping to find useful documents, network diagrams, and even passwords to access systems.
Depending on the classification level, data may be subject to sanitization before it can be disposed. Sanitization methods include the following:
• Clearing: This technique should ensure protection against simple and noninvasive data-recovery techniques.
• Purging: This technique should ensure protection against recovery attempts using state-of-the-art laboratory techniques.
• Destroying: This technique should ensure protection against recovery attempts using state-of-the-art laboratory techniques and should also make the storage media unusable.
Information Security Roles and Responsibilities
The previous section described the pillars of an access control process and emphasized the importance of correctly classifying data and assets. Who decides whether a set of data should be considered confidential? Who is ultimately responsible in the case of unauthorized disclosure of such data?
Because data is handled by several people at different stages, it is important that an organization build a clear role and responsibility plan. By doing so, accountability and responsibility are maintained within the organization, reducing confusion and ensuring that security requirements are balanced with the achievement of business objectives.
Regardless of the user’s role, one of the fundamental principles in security is that maintaining the safekeeping of information is the responsibility of everyone.
The following list highlights the key concepts related to security roles and responsibilities:
![]()
• The definition of roles is needed to maintain clear responsibility and accountability.
• Protecting the security of information and assets is everyone’s responsibility.
The following roles are commonly used within an organization, although they might be called something different, depending on the organization. Additionally, depending on the size of the organization, an individual might be assigned more than one role.
• Executives and senior management: They have the ultimate responsibility over the security of data and asset. They should be involved in and approve access control policies.
• Data owner: The data owner, also called the information owner, is usually part of the management team and maintains ownership of and responsibility over a specific piece or subset of data. Part of the responsibility of this role is to determine the appropriate classification of the information, ensure that the information is protected with controls, to periodically review classification and access rights, and to understand the risk associated with the information.
• Data custodian: The data custodian is the individual who performs day-to-day tasks on behalf of the data owner. The main responsibility of this role is to ensure that the information is available to the end user and that security policies, standards, and guidelines are followed.
• System owner: The system owner is responsible for the security of the systems that handle and process information owned by different data owners. The responsibility of this role is to ensure that the data is secure while it is being processed by the system that is owned. The system owner works closely with the data owner to determine the appropriate controls to apply to data.
• Security administrator: The security administrator manages the process for granting access rights to information. This includes assigning privileges, granting access, and monitoring and maintaining records of access.
• End user: This role is for the final users of the information. They contribute to the security of the information by adhering to the organization’s security policy.
Besides these roles, several others could be seen in larger organization, including the following:
• Security officer: This role is in charge of the design, implementation, management, and review of security policies and organizing and coordinating information security activities
• Information system security professional: This role is responsible for drafting policies, creating standards and guidelines related to information security, and providing guidance on new and existing threats
• Auditor: This role is responsible for determining whether owners, custodians, and systems are compliant with the organization’s security policies and providing independent assurance to senior management.
Tip
The National Institute of Standards and Technology (NIST) created a framework called the NICE Cybersecurity Workforce Framework. The NICE Framework, originally documented in NIST Special Publication 800-181, is a national-focused resource that categorizes and describes cybersecurity work. The NICE Framework is designed to provide guidance on how to identify, recruit, develop, and retain cybersecurity talent. According to NIST, “it is a resource from which organizations or sectors can develop additional publications or tools that meet their needs to define or provide guidance on different aspects of workforce development, planning, training, and education.” Details about the NICE Cybersecurity Workforce Framework can be obtained at the NIST Special Publication 800-181, https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-181.pdf, and at the NICE Framework website at www.nist.gov/itl/applied-cybersecurity/nice.
Access Control Types
There are several types of access controls. For example, a policy that provides information on who is authorized to access a resource and an access list implemented on a firewall to limit access to a resource are two types of access controls. In this case, the policy would be an administrative access control, whereas the access list would be a technical or logical access control.
Controls can be classified into three main categories:
![]()
• Administrative controls: Sometimes called management controls, these include the policies, procedures around the definition of access controls, definitions of information classifications, roles and responsibilities, and in general anything that is needed to manage access control from the administrative point of view. Administrative controls are usually directly overseen by senior management. Administrative controls include the following subcategories:
• Operational and security policies and procedures: These could include policies about change control, vulnerability management, information classification, product lifecycle management, and so on.
• Policies around personnel or employee security: These could include the level of clearance needed to access specific information, background checks on new hires, and so on. Generally, this category includes policies on all the controls that need to be in place before access is granted to a resource.
• Security education and training: This subcategory includes all the policies and efforts needed to implement end-user training and education.
• Auditing and monitoring policies: These might include policy on how to perform employee monitoring, system and compliance auditing, and so on.
• Physical controls: This type of control is aimed at protecting the physical boundaries and ensuring employee safety. These types of controls are usually deployed in various layers in accordance to the concept of defense in depth. Examples of these controls are the fence at the entrance of the building, fire alarms, surveillance systems, and security guards. Physical access controls are usually designed by defining security zones (for example, data center) and implementing physical controls, depending on the classification of the assets. For example, entering the data center area may require additional privileges versus entering the building facilities.
• Technical controls: These controls, also called logical controls, are all the logical and technological systems in place to implement and enforce the controls included in the security policy and, in general, dictated by the administrative controls. A firewall, an intrusion detection system, a remote access server, an identity management system, and encryption are all examples of technical controls.
Besides the administrative, physical, and technical classifications, access controls can also be classified based on their purpose. Access controls can be categorized as having preventive, detective, corrective, deterrent, recovery, and compensating capacities, as detailed in the following list. Both classification approaches can work at the same time. For example, encrypting data when it is at rest is a technical control aimed at preventing unauthorized access to the data itself.
![]()
• Preventive controls enforce security policy and should prevent incidents from happening. The only way to bypass a preventive control is to find a flaw in its implementation or logic. These controls are usually not optional. Examples of preventive controls are access lists, passwords, and fences.
• Deterrent controls are similar to preventive controls in the sense that the primary objective is to prevent an incident from occurring. Unlike preventive controls, however, the rationale behind deterrent controls is to discourage an attacker from proceeding just because a control is in place. For example, a system banner warning that any unauthorized attempt to log in will be monitored and punished is a type of deterrent control. In fact, it would probably discourage a casual user from attempting to access the system; however, it might not block a determined attacker from trying to log in to the system.
• Detective controls aim at monitoring and detecting any unauthorized behavior or hazard. These types of controls are generally used to alert a failure in other types of controls such as preventive, deterrent, and compensating controls. Detective controls are very powerful while an attack is taking place, and they are useful in the postmortem analysis to understand what has happened. Audit logs, intrusion detection systems, motion detection, and security information and event management are examples of detective controls.
• Corrective controls include all the controls used during an incident to correct the problem. Quarantining an infected computer, sending a guard to block an intruder, and terminating an employee for not having followed the security policy are all examples of corrective controls.
• Recovery controls are used after the environment or system has been modified because of an unauthorized access or due to other reasons; they’re aimed at restoring the initial behavior. Performing a backup, implementing a redundant system, and creating a disaster recovery plan are all examples of recovery controls.
• Compensating controls complement or offer an alternative to the primary control. These types of controls are generally used as temporary measures until the primary control is implemented, or to increase the efficacy of the primary control. Overall, the goal of compensating controls is to reduce the risk to an acceptable level. For example, a security guard checking your badge because the badge reader is temporarily out of order would be an example of a compensating control.
It is sometimes hard to properly classify a control. For example, an access list could be classified as preventive; however, it might also be a deterrent, because if you know that your access is blocked, you would probably not attempt to access a resource. An access list could also be used as a detective control if it is implemented in a way that permits traffic and logs when someone has actually accessed a resource.
Generally, it is important to get information about the context in which the control is used, but you should also think of the main purpose of the control itself. For example, an access list should probably be classified as preventive rather than as a deterrent.
Figure 3-2 shows how each type of control maps to the Cisco Attack Continuum. Preventive and deterrent controls can be used before an attack occurs to harden and avoid an attack. Detective and corrective controls are used during an attack to detect the attack and mitigate its impact. Recovery controls are used after the attack to return to a normal situation. Compensating controls span the attack continuum and can be used before, during, and after an attack.

Figure 3-2 Mapping Access Controls to the Cisco Attack Continuum
Access Control Models
An access control model is a conceptual framework that describes how the access control should be designed (that is, how a subject interacts with an object). There are several access control models; for example, access controls that authorize access to resources based on the identity of the subject are called identity-based access controls (IBACs).
However, any access controls can usually be categorized as discretionary access controls and nondiscretionary access controls. The key differentiator between the two is based on the entity that decides how to enforce a policy. With discretionary access controls, the object owner has the right to decide who can access an object. Nondiscretionary access control is a broad category that includes all types of access control models where the authorization is decided by a central administrator, not by the object owner.
Access controls are configured and managed by users with administrative or elevated privileges. Although this is necessary, the concentration of power can be dangerous. Mitigating controls include segregation of duties and dual controls. Segregation of duties requires that tasks be assigned to individuals in such a manner that no one individual can control a process from start to finish. Dual control requires that two individuals must both complete their half of a specific task.
Oversight of user and administrator access reflects best practices and, in many cases, a regulatory requirement. At a minimum, three categories of user access should be logged and analyzed: successful access, failed access, and privileged access. It is incumbent on the organization to institute a log review process as well as incident-responsive procedures for at-risk or suspicious activity.
Access control management policies include Authentication Policy, Access Control Authorization Policy, Network Segmentation Policy, Border Device Security Policy, Remote Access Security Policy, Teleworking Policy, User Access Control and Authorization Policy, Administrative and Privileged Account Policy, and Monitoring System Access and Use Policy.
In this section, we discuss in detail the following access control models:
• Discretionary access control (DAC)
• Mandatory access control (MAC)
• Role-based access control (RBAC)
• Attribute-based access control (ABAC)
Table 3-5 provides an overview of the access control models described in this section.
![]()
Table 3-5 Overview of Access Control Models

Table 3-6 summarizes the pros and cons of each access control model.
![]()
Table 3-6 Pros and Cons of Access Control Models

Discretionary Access Control
In a DAC model, each resource has a clearly identified owner. For example, a user creating a file becomes the owner of that file. The owner of a resource can decide at his discretion to allow other users or subjects access to that resource. The owner discretion is the main characteristic of DAC. In fact, when assigning permission, the owner should comply with the organization’s security policy; however, security policy compliance is not enforced by the operating system. When the owner allows access to a different user, he would also set access permission (for example, read, write, or execute) for the resource specific to the user.
Tip
Discretionary access controls are defined by the owner of the object. Role-based access controls(also called nondiscretionary) are access permissions based on a specific role or function. In a rule-based access controls environment, access is based on criteria that are independent of the user or group account, such as time of day or location.
In a DAC model, users can also be organized in groups. The owner can grant access to a resource to the entire group instead of the individual user. Also, permission attributes are assigned to a resource for the specific group. A simple way to implement the DAC model is to use an access control list (ACL) that is associated with each object. Most of the commercial operating systems in use today implement a form the DAC model.
One of the drawbacks of using a DAC model is that the security policy is left to the discretion of the data owner, and the security administrator has limited control over it. Additionally, with the number of subjects (users, processes, programs, and so on) accessing a large number of objects, maintaining permissions by respecting the need-to-know and least-privileges concepts becomes a complex administrative task. Authorization creep or privilege creep describes an issue that’s common in large organizations of privileges being assigned to a user and never being revoked when the user does not need them anymore, which goes against the need-to-know and least-privileges principles.
Tip
Privilege creep, which happens more often in organizations using discretionary access controls, is not specific to this control model and may very well happen in organizations using nondiscretionary access controls. The best way to avoid privilege creep is to adopt strong account life cycle and management practices. These are explored more in depth in Chapter 7, “Introduction to Security Operations Management.”
The following list highlights the key concepts related to the DAC model:
![]()
• With discretionary access controls, authorization is decided by the owner of the object.
• In a DAC system, access permissions are associated with the object.
• Access control is usually enforced with access control lists.
Figure 3-3 shows an example of DAC implemented via an access control list associated with a resource. In this example, the user Derek tries to both read and write the file named file_a.txt (the resource).

Figure 3-3 DAC Implementation
Mandatory Access Control
In a MAC model, the access authorization is provided by the operating system itself, and the owner has no control over who can access the resource. Each resource receives a sensitivity or security label that is determined during the classification steps outlined in the previous sections and includes two components: the security classification of the object and the compartment or category to which the object belongs. For example, a file can be given the security classification “Top Secret” and be associated with the categories Engineering, ProjectA, and TopicB.
A label is also attached to each subject and indicates the clearance level of that subject.
As noted previously, examples of security classifications are Top Secret, Secret, Confidential, and Unclassified for military and governmental environment, and Confidential, Private, Sensitive, and Public for the commercial sector. Categories, on the other hand, can be anything that is meaningful for the organization. These can be workgroups, projects, business units, and so on.
The system using a MAC model would authorize access to an object only if a subject has a label that is equal to or, for hierarchical systems, superior to the label attached to the object. In a hierarchical system, a label is superior if it has the same or higher classification and includes all categories included in the object’s security label.
Systems based on a MAC model are considered more secure than systems based on a DAC model because the policy is enforced at the operating system, thus reducing the risk of mishandled permissions. The drawback of a MAC-based system, however, is that it does not offer the same degree of flexibility offered by a DAC-based system.
Due to the issues of less flexibility and more complicated administration, MAC systems have historically been used in environments where high security is needed, such as in a military environment. Regardless, MAC-based systems are being used increasingly in the commercial sector. SELinux is an example of an operating system that implements the MAC model. Enforcement rules in SELinux and AppArmor mandatory access control frameworks restrict control over what processes are started, spawned by other applications, or allowed to inject code into the system. These implementations can control what programs can read and write to the file system.
Tip
Additional information about the SELinux project and related tools can be found at the SELinux Project GitHub repository at https://github.com/SELinuxProject.
The following list highlights the key concepts related to the mandatory access control model:
![]()
• With mandatory access controls, the operating system or policy enforcer decides on whether to grant access.
• The owner does not have control and cannot decide to grant access to a resource.
• The security policy is enforced by using security labels.
Figure 3-4 shows an example of a MAC-based system. Security labels are associated with the users Derek and Hannah and with file_a.txt, which is the resource the users are attempting to access. In this example, Derek has the clearance level and category matching the classification and category of file_a.txt, so access is granted. The second user (Hannah) does not have the clearance necessary to access file_a.txt, so access is denied.

Figure 3-4 MAC Implementation
Role-Based Access Control
The RBAC model uses a subject role to make authorization decisions. Each subject needs to be assigned to a role; however, the assignment is done by the system administrator. This is called user assignment (UA). Each role is then assigned permission over an object. This is called permission assignment (PA).
The RBAC model greatly improves scalability and simplifies administration because a subject can just be assigned to a role without the permission over an object needing to be changed. For example, when a user changes jobs or roles, that user is simply removed from that role, instead of having permissions removed for all the objects that the user was interacting with before the change.
A subject can be assigned to several roles, and a role can include multiple subjects. In the same way, a role can have multiple permissions, and the same permissions can be assigned to multiple roles. This creates a many-to-many relationship. The RBAC model supports the principles of least privileges, separation of duties, and data abstraction.
The least-privileges principle is provided by configuring the RBAC system to assign only the privileges that are needed to execute a specific task to a role. Separation of duties is obtained by configuring the system so that two roles that are mutually exclusive are needed to finish a task. Data abstraction is achieved by using abstract permissions (for example, open and close if the object is a lock instead of the typical read, write, and execute).
According to the RBAC standard proposed by NIST, the RBAC model has three components:
• Core RBAC: This is the fundamental component of the RBAC model, and it implements the basic authorization based on the user roles. A session in the context of RBAC is the way a subject or user activates a subset of roles. For example, if a user is assigned to two roles (guest and administrator), then using a session as guest will activate only the permission given to the guest role. Using a session as administrator will give the user permission based on the administrator role.
• Hierarchical RBAC: This component introduces hierarchy within the RBAC model and is added on top of the core RBAC. This component facilitates the mapping to an organization, which is usually structured in a hierarchical way. In simple terms, hierarchical RBAC allows permission inheritance from one role to the other. For example, the head of multiple business units may inherit all the permissions assigned to each business unit, plus have the permission assigned to the “head of business units” role itself.
• Constraint RBAC: This component introduces the concept of separation of duties. The main goal of this component is to avoid collusion and fraud by making sure that more than one role is needed to complete a specific task. It comes in two subcomponents:
• Static Separation of Duty (SSoD): This subcomponent puts constraints on the assignment of a user to a role. For example, the same user whose role is to implement the code of a product should not also be part of the auditor or assurance role. If this component is built on top of a hierarchical RBAC, it will take permission inheritance in consideration when the constraint is formulated.
• Dynamic Separation of Duty (DSoD): This subcomponent also limits the subject or user access to certain permissions; however, it does so in a dynamic way during a user session rather than forbidding a user/role relationship. That is, it uses a session to regulate which permissions are available to a user. For example, a user could be in the role of code implementer and the role of code auditor, but will not be able to get permission as code auditor for code that the user implemented herself.
Although the RBAC model offers higher scalability than a DAC-based system, in complex organizations the RBAC model would lead to a great expansion of roles, which would increase the administration and management burden. This is one of the drawbacks of this model.
The following list highlights the key concepts related to the role-based access control model:
![]()
• With role-based access controls, the access decision is based on the role or function of the subject.
• The role assignment is not discretionary, so users get assigned to a role based on the organization’s policies.
• Permissions are connected to the roles, not directly to the users.
Figure 3-5 shows an example of an RBAC system. Users can map to multiple roles, and vice versa. Each role has permissions assigned, which are sets of operations that can be executed on resources (objects).

Figure 3-5 RBAC Implementation
Attribute-Based Access Control
ABAC is a further evolution in access control models that takes into consideration factors besides identity or role. These factors could include the location of access, time or temporal constraints, the level of risk or threat, and so on.
With the ABAC model, the authorization decision is based on attributes assigned to subjects and objects, environmental conditions, and a set of policies linked to these attributes and condition. Attributes are defined as characteristics that belong to a subject (user), object (resource), or environment. For example, a subject attribute could be name, nationality, organization, role, ID, security clearance, and so on. Examples of object attributes are name, owner, data creation, and so on.
Environment conditions are contextual information associated with the access request. Location of the access, time of the access, and the threat level are all examples of environment attributes. Every object should also be associated with at least one policy that regulates which operations a subject with certain attributes, given some environmental constraints, can perform on the object. For example, a policy could be formulated as “all Engineers who work in the Security Business Unit and are assigned to the Next-Gen Firewall Project are allowed to Read and Write all the Design Documents in the Next-Gen Firewall Project folder when connecting from Building A.”
In this example, being an engineer, belonging to the security business unit, and being assigned to the next-gen firewall project are all attributes that could be assigned to a subject. Being a design document within the next-gen firewall project folder is an attribute that could be assigned to the object (the document). Read and write are the operations allowed by the subject over the object. Building A is an environment condition.
Because roles and identities could be considered attributes, RBAC and IBAC systems could be considered instances of an ABAC system. One of the best-known standards that implement the ABAC model is the Extensible Access Control Markup Language (XACML).
Another model that can be considered a special case of ABAC is called rule-based access control. In reality, this is not a well-defined model and includes any access control model that implements some sort of rule that governs the access to a resource. Usually, rule-based access controls are used in the context of access list implementation to access network resources, for example, where the rule is to provide access only to certain IP addresses or only at certain hours of the day. In this case, the IP addresses are attributes of the subject and object, and the time of day is part of the environment attribute evaluation.
The following list highlights the key concepts related to the ABAC model:
![]()
• With attribute-based access controls, the access decision is based on the attributes associated with subjects, objects, or the environment.
• Attributes are characteristics that belong to a subject (user), object (resource), or environment.
• User role, identity, and security classification can be considered attributes.
Figure 3-6 shows an example of ABAC. User A has several attributes, including a role, a business unit, and assigned projects. File A also has several attributes, including the file category and the project folder. An environmental attribute (the user location) is also considered in this scenario.

Figure 3-6 ABAC Implementation
The access control rule is defined as follows:
All Engineers who work in the Security Business Unit and are assigned to the Next-Gen Firewall Project are allowed to Read and Write all the Design Documents in the Next-Gen Firewall Project folder when connecting from Building A.
In this example, the conditions are satisfied and access is granted. In Figure 3-7 and Figure 3-8, however, access is denied because User B’s attributes and the environmental condition, respectively, do not satisfy the access rule.

Figure 3-7 ABAC Implementation: Access Denied Due to User Attributes

Figure 3-8 ABAC Implementation: Access Denied Due to User Environmental Condition
Access Control Mechanisms
An access control mechanism is, in simple terms, a method for implementing various access control models. A system may implement multiple access control mechanisms. In some modern systems, this notion of access control mechanism may be considered obsolete because the complexity of the system calls for more advanced mechanisms. Nevertheless, here are some of the best-known methods:
• Access control list: This is the simplest way to implement a DAC-based system. The key characteristic of an access control list is that it is assigned to the object that it is protecting. An access control list, when applied to an object, will include all the subjects that can access the object and their specific permissions. Figure 3-9 shows an example of an ACL applied to a file.

Figure 3-9 ACL Applied to a File
• Capability table: This is a collection of objects that a subject can access, together with the granted permissions. The key characteristic of a capability table is that it’s subject centric instead of being object centric, like in the case of an access control list. Figure 3-10 shows a user capability table.

Figure 3-10 User Capability Table
• Access control matrix (ACM): This is an access control mechanism that is usually associated with a DAC-based system. An ACM includes three elements: the subject, the object, and the set of permissions. Each row of an ACM is assigned to a subject, while each column represents an object. The cell that identifies a subject/object pair includes the permission that subject has on the object. An ACM could be seen as a collection of access control lists or a collection of capabilities table, depending on how you want to read it. Figure 3-11 shows an example of access controls using an ACM.

Figure 3-11 Access Controls Using an ACM
Tip
A database view could also be considered a type of restricted interface because the available information is restricted depending on the identity of the user.
• Restricted interface: This type of control limits the operations a subject can perform on an object by not providing that option on the interface that the subject uses to access the object. Typical examples of this type of control are menus, shells, physical constraint interfaces, and so on. For example, a menu could offer more options if a user is a system administrator, and fewer options if the user is a guest.
• Content-dependent access control: This type of control uses the information (content) within a resource to make an authorization decision. This type of control is generally used in database access controls. A typical example is a database view.
• Context-dependent access control: This type of control uses contextual information to make an access decision, together with other information such as the identity of the subject. For example, a system implementing a context-dependent control may look at events preceding an access request to make an authorization decision. A typical system that uses this type of control is a stateful firewall, such as Cisco ASA or Cisco IOS configured with the zone-based firewall feature, where a packet is allowed or denied based on the information related to the session the packet belongs to.
Identity and Access Control Implementation
Several methods, technologies, and protocols can be used to implement identity and access technical controls. This section explores some of the most common ones that are relevant to the Understanding Cisco Cybersecurity Operations Fundamentals (200-201 CBROPS) exam.
Authentication, Authorization, and Accounting Protocols
Several protocols are used to grant access to networks or systems, provide information about access rights, and provide capabilities used to monitor, audit, and account for user actions once authenticated and authorized. These protocols are called authentication, authorization, and accounting (AAA) protocols.
The most well-known AAA protocols are RADIUS, TACACS+, and Diameter. The sections that follow provide some background information about each.
RADIUS
The Remote Authentication Dial-In User Service (RADIUS) is an AAA protocol mainly used to provide network access services. Due to its flexibility, it has been adopted in other scenarios as well. The authentication and authorization parts are specified in RFC 2865, while the accounting part is specified in RFC 2866.
RADIUS is a client/server protocol. In the context of RADIUS, the client is the access server, which is the entity to which a user sends the access request. The server is usually a machine running RADIUS and that provides authentication and authorization responses containing all the information used by the access server to provide service to the user.
The RADIUS server can act as proxy for other RADIUS servers or other authentication systems. Also, RADIUS can support several types of authentication mechanisms, such as PPP PAP, CHAP, and EAP. It also allows protocol extension via the attribute field. For example, vendors can use the attribute “vendor-specific” (type 26) to pass vendor-specific information.
Figure 3-12 shows a typical deployment of a RADIUS server.

Figure 3-12 RADIUS Server Implementation
RADIUS operates in most cases over UDP protocol port 1812 for authentication and authorization, and port 1813 for accounting, which are the officially assigned ports for this service. In earlier implementations, RADIUS operated over UDP port 1645 for authentication and authorization, and port 1646 for accounting. The authentication and authorization phase consists of two messages:
1. A wireless user (Jeannette) tries to join the wireless network. The wireless router (RADIUS client) is configured with 802.1x.
2. The wireless router sends an ACCESS-REQUEST to the RADIUS server that includes the user identity, the password, and other information about the requestor of the access (for example, the IP address).
3. The RADIUS server may reply with one of three different messages:
a. ACCESS-ACCEPT if the user is authenticated. This message will also include in the Attribute field authorization information and specific vendor information used by the access server to provide services.
b. ACCESS-REJECT if access for the user is rejected.
c. ACCESS-CHALLENGE if the RADIUS server needs to send an additional challenge to the access server before authenticating the user. The ACCESS-CHALLENGE will be followed by a new ACCESS-REQUEST message.
Figure 3-13 shows an example of a RADIUS exchange for authentication and authorization.

Figure 3-13 RADIUS Exchange for Authentication/Authorization
The accounting exchange consists of two messages: ACCOUNTING-REQUEST and ACCOUNTING-RESPONSE. Accounting can be used, for example, to specify how long a user has been connected to the network (the start and stop of a session).
The RADIUS exchange is authenticated by using a shared secret key between the access server and the RADIUS server. Only the user password information in the ACCESS-REQUEST is encrypted; the rest of the packets are sent in plaintext.
TACACS+
Terminal Access Controller Access Control System Plus (TACACS+) is a proprietary protocol developed by Cisco. It also uses a client/server model, where the TACACS+ client is the access server and the TACACS+ server is the machine providing TACACS+ services (that is, authentication, authorization, and accounting).
Similar to RADIUS, TACACS+ also supports protocol extension by allowing vendor-specific attributes and several types of authentication protocols. TACACS+ uses TCP as the transport protocol, and the TACACS+ server listens on port 49. Using TCP ensures a more reliable connection and fault tolerance.
TACACS+ has the authentication, authorization, and accounting processes as three separate steps. This allows the user of a different protocol (for example, RADIUS) for authentication or accounting. Additionally, the authorization and accounting capabilities are more granular than in RADIUS (for example, allowing specific authorization of commands). This makes TACACS+ the preferred protocol for authorization services for remote device administration.
The TACACS+ exchange requires several packets; however, mainly two types of packets with different codes are exchanged:
• REQUEST packets, which are sent from the access server to the TACACS+ server
• RESPONSE packets, which are sent from the TACACS+ server to the access server
The following is an example of an authentication exchange:
1. The access server sends a REQUEST packet, including the START statement.
2. The TACACS+ server sends an acknowledgment to the access server.
3. The access server sends a CONTINUE with the username.
4. The TACACS+ server sends a reply to acknowledge the message and ask for the password.
5. The access server sends a CONTINUE with the password.
6. The TACACS+ server sends a reply with authentication response (pass or fail).
Figure 3-14 shows an example of a TACACS+ message exchange for authentication.

Figure 3-14 TACACS+ Message Exchange for Authentication
TACACS+ offers better security protection compared to RADIUS. For example, the full body of the packet may be encrypted.
Table 3-7 summarizes the main differences between RADIUS and TACACS+.
![]()
Table 3-7 RADIUS vs. TACACS+ Comparison

Diameter
RADIUS and TACACS+ were created with the aim of providing AAA services to network access via dial-up protocols or terminal access. Due to their success and flexibility, they have been used in several other scopes. To respond to newer access requirements and protocols, the IETF introduced a new protocol called Diameter (defined in RFC 6733 and then updated in RFC 7075 and RFC 8553).
Diameter has been built with the following functionality in mind:
• Failover: Diameter implements application-level acknowledgment and failover algorithms.
• Transmission-level security: Diameter protects the exchange of messages by using TLS or DTLS.
• Reliable transport: Diameter uses TCP or STCP as the transport protocol.
• Agent support: Diameter specifies the roles of different agents such as proxy, relay, redirect, and translation agents.
• Server-initiated messages: Diameter makes mandatory the implementation of server-initiated messages. This enables capabilities such as on-demand reauthentication and reauthorization.
• Transition support: Diameter allows compatibility with systems using RADIUS.
• Capability negotiation: Diameter includes capability negotiations such as error handling as well as mandatory and nonmandatory attribute/value pairs (AVP).
• Peer discovery: Diameter enables dynamic peer discovery via DNS.
The main reason for the introduction of the Diameter protocol is the capability to work with applications that enable protocol extension. The main Diameter application is called Diameter base, and it implements the core of the Diameter protocol. Other applications are Mobile IPv4 Application, Network Access Server Application, Diameter Credit-Control Application, and so on. Each application specifies the content of the information exchange in Diameter packets. For example, to use Diameter as an AAA protocol for network access, the Diameter peers will use the Diameter Base Application and the Diameter Network Access Server Application.
The Diameter header field Application ID indicates the ID of the application. Each application, including the Diameter Base application, uses command code to identify specific application actions. Diameter is a peer-to-peer protocol, and entities in a Diameter context are called Diameter nodes. A Diameter node is defined as a host that implements the Diameter protocol.
The protocol is based on two main messages: a REQUEST, which is identified by setting the R bit in the header, and an ANSWER, which is identified by unsetting the R bit. Each message will include a series of attribute/value pairs (AVPs) that include application-specific information.
In its basic protocol flow, after the transport layer connection is created, the Diameter initiator peer sends a Capability-Exchange-Request (CER) to the other peer that will respond with a Capability-Exchange-Answer (CEA). The CER can include several AVPs, depending on whether the application is requesting a connection. Once the capabilities are exchanged, the Diameter applications can start sending information.
Diameter also implements a keep-alive mechanism by using a Device-Watchdog-Request (DWR), which needs to be acknowledged with a Device-Watchdog-Answer (DWA). The communication is terminated by using a Disconnect-Peer-Request (DPR) and Disconnect-Peer-Answer (DPA). Both the Device-Watchdog and Disconnect-Peer can be initiated by both parties.
Figure 3-15 shows an example of a Diameter capability exchange and communication termination.

Figure 3-15 Diameter Capability Exchange/Communication Termination
The following is an example of protocol flows where Diameter is used to provide user authentication service for network access (as defined in the Network Access Server Application RFC 7155):
1. The initiator peer, the access server, sends a CER message with the Auth-Application-Id AVP set to 1, meaning that it supports authentication capabilities.
2. The Diameter server sends a CEA back to the access server with Auth-Application-Id AVP set to 1.
3. The access server sends an AA-Request (AAR) to the Diameter server that includes information about the user authentication, such as username and password.
4. The access server will reply with an AA-Answer (AAA) message including the authentication results.
Figure 3-16 shows an example of a Diameter exchange for network access services.
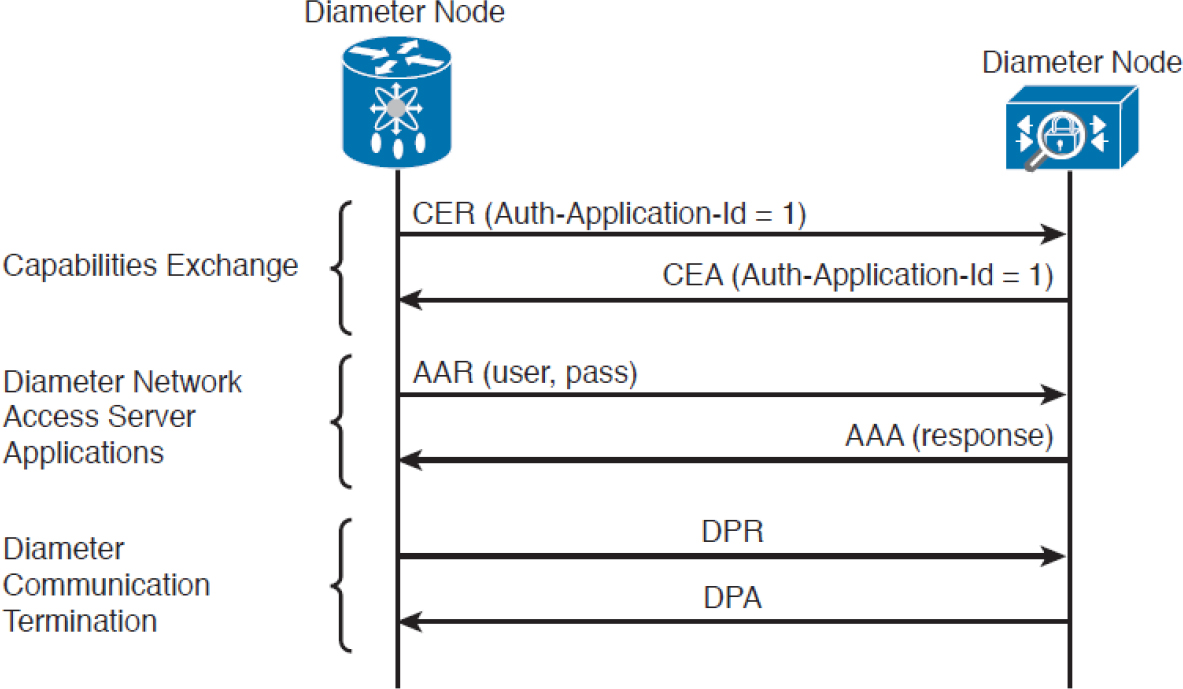
Figure 3-16 Diameter Exchange for Network Access Services
Diameter is a much more complex protocol and is used mainly in a mobile service provider environment.
Port-Based Access Control
Port-based access controls are associated with a specific access port, such an access layer switch port, for example. The idea behind this type of control is to allow or deny a device that is physically connected to a network port with access to a specific resource. In this section, we discuss two types of port-based access control implemented in Cisco devices: port security and 802.1x. Both types of access controls are based on the ABAC model (sometimes also described as identity-based or rule-based access control).
Port Security
Port security is a security feature present in most of Cisco routers and switches, and it is used to provide access control by restricting the Media Access Control (MAC) addresses that can be connected to a given port. This differs from a MAC access list because it works only on the source MAC address without matching the MAC destination.
Tip
The Media Access Control (MAC) address should not be confused with the mandatory access control (MAC) model. The former is the address of the Ethernet card. The latter is a type of access control model and is discussed in the “Mandatory Access Control” section earlier in this chapter.
Port security works by defining a pool of MAC addresses that are allowed to transmit on a device port. The pool can be statically defined or dynamically learned. Compared to a MAC access control list, which would need to be implemented on each port and have static entries, the dynamically learned method reduces the administrative overhead related to the port access control implementation.
When a frame is received on the port, the port security feature checks the source MAC address of the frame. If it matches an allowed MAC address, the frame will be forwarded; otherwise, the frame will be dropped.
In addition to the drop frame coming from an unauthorized MAC address, port security will raise a security violation. A security violation is raised under the following circumstances:
• If a MAC address that is configured or dynamically learned on one port is seen on a different port in the same virtual local-area network (VLAN). This is referred as a MAC move.
• If the maximum number of MAC addresses allowed for a port is reached and the incoming MAC is different from the one already learned.
802.1x
802.1x is an IEEE standard that is used to implement port-based access control. In simple terms, an 802.1x access device will allow traffic on the port only after the device has been authenticated and authorized.
Figure 3-17 shows an example of traffic allowed before and after 802.1x authentication and authorization.

Figure 3-17 Traffic Allowed Before and After 802.1x Authentication and Authorization
In an 802.1x-enabled network, three main roles are defined:
• Authentication server: This entity provides an authentication service to an authenticator. The authentication server determines whether the supplicant is authorized to access the service. This is sometimes referred as the Policy Decision Point (PdP). Cisco ACS and Cisco ISE are examples of an authentication server.
• Supplicant: This entity seeks to be authenticated by an authenticator. For example, this could be a client laptop connected to a switch port.
• Authenticator: This entity facilitates authentication of other entities attached to the same LAN. This is sometimes referred as the Policy Enforcement Point (PeP). Cisco switches and access points are example of authenticators.
Other components, such as an identity database or a PKI infrastructure, may be required for a correct deployment.
Figure 3-18 shows an example of an authentication server, supplicant, and authenticator. The supplicant is connected to the switch port via a wired connection.

Figure 3-18 Authentication Server, Supplicant, and Authenticator Topology
802.1x uses the following protocols:
• EAP over LAN (EAPoL): This encapsulation defined in 802.1X is used to encapsulate EAP packets to be transmitted from the supplicant to the authentication server.
• Extensible Authentication Protocol (EAP): This authentication protocol is used between the supplicant and the authentication server to transmit authentication information.
• RADIUS or Diameter: This AAA protocol is used for communication between the authenticator and authentication server.
The 802.1x port-based access control includes four phases (in this example, RADIUS is used as the protocol and a Cisco switch as the authenticator):
1. Session initiation: The session can be initiated either by the authenticator with an EAP-Request-Identity message or by the supplicant with an EAPoL-Start message. Before the supplicant is authenticated and the session authorized, only EAPoL, Cisco Discovery Protocol (CDP), and Spanning Tree Protocol (STP) traffic is allowed on the port from the authenticator.
2. Session authentication: The authenticator extracts the EAP message from the EAPoL frame and sends a RADIUS Access-Request to the authentication server, adding the EAP information in the AV pair of the RADIUS request. The authenticator and the supplicant will use EAP to agree on the authentication method (for example, EAP-TLS).
Depending on the authentication method negotiated, the supplicant may provide a password, a certificate, a token, and so on.
3. Session authorization: If the authentication server can authenticate the supplicant, it will send a RADIUS Access-Accept to the authenticator that includes additional authorization information such as VLAN, downloadable access control list (dACL), and so on.
The authenticator will send an EAP Success message to the supplicant, and the supplicant can start sending traffic.
4. Session accounting: This represents the exchange of accounting RADIUS packets between the authenticator and the authentication server.
Figure 3-19 shows an example of 802.1x port access control exchange.

Figure 3-19 802.1x Port Access Control Exchange
In addition to these four phases, it is also important that the session is correctly terminated. The supplicant sends an EAPoL-Logoff message when it terminates the connection.
Network Access Control List and Firewalling
The most basic implementation of an access control is an access control list . When an ACL is applied to network traffic, it is called a network ACL. Cisco networking devices such as routers, switches, and firewalls include network ACL capabilities to control access to network resources. As for port-based access controls, network ACLs and firewalling are usually seen as special cases of the ABAC model and also sometimes classified as identify-based or rule-based access control because they base the control decision on attributes such as IP or MAC addresses or Layer 4 information. Security group ACLs, on the other hand, are access lists based on the role of the subject trying to access a resource, and they implement role-based access control.
Network ACLs can be implemented at various levels of the OSI model:
• A Layer 2 ACL operates at the data link layer and implements filters based on Layer 2 information. An example of this type of access list is a MAC access list, which uses information about the MAC address to create the filter.
• A Layer 3 ACL operates at the networking layer. Cisco devices usually allow Layer 3 ACLs for different Layer 3 protocols, including the most-used ones nowadays—IPv4 and IPv6. In addition to selecting the Layer 3 protocol, a Layer 3 ACL allows the configuration of filtering for a protocol using raw IP, such as OSPF or ESP.
• A Layer 4 ACL operates at the transport layer. An example of a Layer 4 ACL is a TCP- or UDP-based ACL. Typically, a Layer 4 ACL includes the source and destination. This allows filtering of specific upper-layer packets.
VLAN Map
VLAN ACLs, also called VLAN maps, are not specifically Layer 2 ACLs; however, they are used to limit the traffic within a specific VLAN. A VLAN map can apply a MAC access list, a Layer 3 ACL, and a Layer 4 ACL to the inbound direction of a VLAN to provide access control.
Security Group-Based ACL
A security group-based ACL (SGACL) is an ACL that implements access control based on the security group assigned to a user (for example, based on that user’s role within the organization) and the destination resources. SGACLs are implemented as part of Cisco TrustSec policy enforcement. Cisco TrustSec is described in a bit more detail in the sections that follow. The enforced ACL may include both Layer 3 and Layer 4 access control entries (ACEs).
Figure 3-20 shows an example of SGACL.

Figure 3-20 SGACL Deployment
Downloadable ACL
A downloadable ACL (dACL), also called a per-user ACL, is an ACL that can be applied dynamically to a port. The term downloadable stems from the fact that these ACLs are pushed from the authenticator server (for example, from a Cisco ISE) during the authorization phase.
When a client authenticates to the port (for example, by using 802.1x), the authentication server can send a dACL that will be applied to the port and that will limit the resources the client can access over the network.
Firewalling
ACLs are stateless access controls because they do not maintain the state of a session or a connection. A more advanced implementation of access control is provided by stateful firewalls, which are able to implement access control based on the state of a connection. Cisco offers several firewalling solutions, including the Cisco Adaptive Security Appliance (ASA), the Cisco Firepower Threat Defense (FTD), and the Cisco Zone-based Firewall that can be deployed in Cisco routers.
Firewalls often implement inspection capabilities that enforce application layer protocol conformance and dynamic access control based on the state of the upper-layer protocol.
Next-generation firewalls go one step further and implement context-aware controls, where not only the IP address or specific application information is taken into account, but other contextual information—such as the location, the type of device requesting access, and the sequence of events—is taken into consideration when allowing or denying a packet.
Identity Management and Profiling
Cisco offers a number of managements products that help security administrators implement identity management and access control enforcement:
• Cisco Secure Access Control Server: Cisco Secure Access Control Server (ACS) is AAA and policy enforcement software running on Cisco Secure Network Server or as a virtual appliance. It offers RADIUS and TACACS+ services and can be integrated with other back-end identity databases such as Microsoft Active Directory and RSA SecureID. It supports the most-used authentication protocols, both for wired and wireless access, and includes the ability to pass authorization policies such as downloadable ACLs or VLAN assignment to the enforcer device (for example, a Cisco switch).
• Cisco Identity Service Engine: Cisco Identity Service Engine (ISE) is a comprehensive secure identity management solution designed to function as a policy decision point for network access. It allows security administrators to collect real-time contextual information from a network, its users, and devices. Cisco ISE is the central policy management platform in the Cisco TrustSec solution. It supports a comprehensive set of authentication, authorization, and accounting (AAA), posture, and network profiler features in a single device. Cisco ISE is described in more detail in Chapter 1.
• Cisco Prime Access Registrar: Cisco Prime Access Registrar is software that provides RADIUS- and Diameter-based AAA services for a wide range of network access implementation, including Wi-Fi (SP Wi-Fi), Vo-Wi-Fi, femtocell, Connected Grid, LTE, DSL, Code Division Multiple Access (CDMA), General Packet Radio Service (GPRS), Universal Mobile Telecommunications Service (UMTS), WLAN, and WiMAX.
Network Segmentation
Network segmentation is a technique that is used in access controls design to separate resources either physically or logically. Logical network segmentation can be implemented in several ways. For example, a careful choice of IP addressing schema is one way to implement network segmentation. Network segmentation by itself does not provide access control functionality but does facilitate the enforcement of access control policy at the ingress/egress points.
Network Segmentation Through VLAN
A VLAN is a Layer 2 broadcast domain. A careful plan of how ports or users are assigned to a specific VLAN can allow network segmentation and facilitate the implementation of access policy (for example, via network ACLs for traffic that needs to be routed across VLAN segments).
VLAN ACLs, also called VLAN maps, are not specifically Layer 2 ACLs; however, they work to limit traffic within a specific VLAN. VLAN maps can apply MAC access lists or Layer 3 and Layer 4 access lists to the inbound direction of a VLAN to provide access control.
A private VLAN can also be used to implement VLAN partitioning and control the communication among ports belonging to the same VLAN. A private VLAN includes three types of ports:
• Promiscuous: Devices attached to a promiscuous port can communicate with all ports within the switch, including isolated and community ports.
• Isolated: Devices attached to an isolated port can only communicate with the promiscuous port.
• Community: Devices attached to a community port can communicate with the promiscuous port and with other device in the same community.
Figure 3-21 shows how the communication happens between various types of ports.

Figure 3-21 Communication Between Ports in a VLAN Environment
Firewall DMZ
Firewalls can be configured to separate multiple network segments (or zones), usually called demilitarized zones (DMZs). These zones provide security to the systems that reside within them with different security levels and policies between them. DMZs can have several purposes; for example, they can serve as segments on which a web server farm resides or as extranet connections to a business partner. DMZs and firewalls are described in more detail in Chapter 1.
Cisco TrustSec
Cisco TrustSec is a security architecture that allows network segmentation and enables access controls primarily based on a role or attribute of the user requesting access to the network. The Cisco TrustSec architecture includes three key concepts:
• Authenticated networking infrastructure: Each networking device in a TrustSec environment is authenticated by its peers. This creates a trusted domain.
• Security group-based access control: The access control does not happen, as with a normal ACL, based on the IP addresses of the source and destination, but based on the role of the source and destination. This is done by assigning a security group tag (SGT) to sources and destinations.
• Encrypted communication: Communication on each link is encrypted by using 802.1AE Media Access Control Security (MACSec).
Similar to 802.1x, Cisco TrustSec defines the roles of supplicant, authentication server, and authenticator. Before a supplicant can send packets to the network, it needs to join the TrustSec domain. This involves the following steps:
1. The supplicant authenticates by using 802.1x with the authentication server. In the authentication phase, the authentication server authenticates both the supplicant and authenticator. Both the supplicant device and user may need to be authenticated.
2. The authentication server sends authorization information to the authenticator and supplicant. The information includes the SGT to be assigned to the supplicant traffic.
3. The security association is negotiated, and link encryption is established between the supplicant and the authenticator (the rest of the domain already has link encryption set up as part of the network device enrollment).
Figure 3-22 shows how an SGT is embedded within a Layer 2 frame.

Figure 3-22 Embedding an SGT Within a Layer 2 Frame
The access control is provided by ingress tagging and egress enforcement. This means that a packet is tagged based on its source once it enters the Cisco TrustSec domain, and the access control happens at the egress point based on the destination. The access decision is based on SGACL implemented at the egress point.
The following example, shown in Figure 3-23, explains the ingress tagging and egress enforcement:
1. A host sends packets to a destination (the web server).
2. The TrustSec authenticator (the ingress switch to the TrustSec domain) modifies the packet and adds an SGT—for example, Engineering (3).
3. The packet travels through the TrustSec domain and reaches the egress point. The egress point will check the SGACL to see whether Engineering group (3) is authorized to access the web server, which also receives an SGT (4).
4. If the packet is allowed to pass, the egress point will remove the SGT and transmit to the destination.

Figure 3-23 Ingress Tagging and Egress Enforcement
Adding the SGT requires the ingress point to have hardware enabled for TrustSec. Although most of the latest Cisco devices are enabled for TrustSec, in legacy environments there may be some issues with adopting TrustSec.
The SGT Exchange Protocol (SXP) allows software-enabled devices to still participate in the TrustSec architecture and expand the applicability of Cisco TrustSec. It uses an IP-address-to-SGT method to forward information about the SGT to the first Cisco TrustSec-enabled hardware on the path to the destination. Once the packet reaches that point, the device will tag the packet in “hardware,” which will then continue its trip to the destination.
Figure 3-24 shows how SXP can be used to exchange SGT between an access device with only Cisco TrustSec capability in software and a device with Cisco TrustSec hardware support.

Figure 3-24 Use of SXP
Intrusion Detection and Prevention
Intrusion detection and intrusion prevention controls can be administrative, physical, or technical. This section discusses the technical types of controls.
Intrusion detection systems (IDSs) and intrusion prevention systems (IPSs) implement detection and prevention capabilities for unauthorized access to the network or to an information system. IDSs focus more on detection, whereas IPSs focus on threat or unauthorized access prevention. The main difference between an IDS and IPS is the deployment mode. IDS usually works on a copy of the packet and is mainly used to detect an issue or anomaly and alert the security analyst. This is called promiscuous mode. An IDS may also include capabilities to enforce corrective action through other devices (for example, a firewall or a router that works as an enforcement point).
For example, an IDS can communicate with a firewall device and ask the firewall to reset a connection. Because the IDS does not intercept the real packet, the response time to block a threat is lower than in an IPS system; thus, some malicious packets may enter the network.
An IPS, on the other hand, is deployed inline, which means it has visibility of the packets or threats as they flow through the device. Because of that, it is able to block a threat as soon as it is detected—for example, by dropping a malicious packet. The drawback of having an IPS inline is that it adds additional latency due to the packet processing, and it may drop legitimate traffic in the case of a false positive.
Figure 3-25 and Figure 3-26 show examples of IDS and IPS deployment.

Figure 3-25 IDS Deployment

Figure 3-26 IPS Deployment
![]()
The following lists summarize the key topics regarding intrusion detection and prevention systems:
IDS:
• Works on a copy of the packet (promiscuous mode).
• Does not introduce delay due to packet inspection.
• Cannot stop a packet directly but can work with other devices, such as firewalls, to drop malicious packets.
• Some malicious packets may pass through even if they are flagged as malicious.
IPS:
• Intercepts and processes real traffic (inline mode).
• Introduces delay due to packet processing and inspection.
• Can stop packets as they come through.
• Packets that are recognized to be malicious can be dropped right away.
Table 3-8 summarizes the differences between an IDS and IPS.
![]()
Table 3-8 IDS vs. IPS Comparison

The basic purpose of any intrusion detection or prevention system is to produce an event based on something that is observed. When an event is triggered, the system is configured to produce an action (for example, create an alert or drop a packet).
Different types of events can be generated by an IPS or IDS:
![]()
• False positive: Happens when the system raises an event against legitimate traffic that is not malicious. The IPS or IDS administrator’s goal is to minimize false positive events because these types of the events can cause unneeded investigation.
• False negative: Happens when the system fails to recognize a malicious event. This is usually very dangerous because it would allow malicious events to reach the target unnoticed.
• True positive: Refers to the correct behavior of the system when an actual threat has been detected.
• True negative: Refers to the correct behavior of the system when no event is triggered for legitimate traffic.
Another relevant distinction is done based on where an IDS or IPS is deployed. They can be installed on the network or on a host system.
Network-Based Intrusion Detection and Protection System
Network IDSs and IPSs (NIDSs and NIPSs) are specialized networking devices deployed at important network segments and have visibility on all traffic entering or exiting a segment. Network-based IDSs and IPSs use several detection methodologies, such as the following:
![]()
• Pattern matching and stateful pattern-matching recognition
• Protocol analysis
• Heuristic-based analysis
• Anomaly-based analysis
• Global threat correlation capabilities
NIDS and NIPS capabilities and detection methodologies are discussed in detail in Chapter 1.
Host-Based Intrusion Detection and Prevention
![]()
A host-based IDS (HIDS) or IPS (HIPS) is specialized software that interacts with the host operating system to provide access control and threat protection. In most cases, it also includes network detection and protection capabilities on the host network interface cards. Additionally, HIDS and HIPS are used for end-host security policy enforcement and for compliance and audit control.
In its basic capabilities, an HIDS or HIPS usually inserts itself between the application and the operating system kernel functionality and monitors the application calls to the kernel. It adopts most of the detection techniques mentioned for an NIDS/NIPS, such as anomaly based, heuristic based, and so on.
HIDS and HIPS are able to check for file integrity, registry monitoring, log analysis, and malware detection. The main advantages of HIDS compared to NIDS are that it will have visibility on all traffic on a specific host and can determine and alert on whether an attack was successful. It also works on attacks that employ encryption or fragmentation to evade network-based detection.
A disadvantage of a host-based system is that it has visibility only on traffic or attacks hitting the host and ignores anything else that happens in the network. Many commercial products, however, offer management control facilities and integration to network-based intrusion systems to overcome this limitation. Additionally, a host-based system adds latency on the CPU and packet processing on the host where it is installed. Most of security architecture will adopt both network-based and host-based solutions.
Table 3-9 summarizes the differences between a network-based solution and a host-based solution.
![]()
Table 3-9 Network-Based vs. Host-Based Detection/Prevention Systems

Antivirus and Antimalware
The terms antivirus and antimalware are generally used interchangeably to indicate software that can be used to detect and prevent the installation of computer malware and in some cases quarantine affected computers or eradicate the malware and restore the operation of the system.
In its initial concept, antivirus was signature-based software that scanned a system or a downloaded file looking for a match on the signature database. The signature usually resided on the host itself, and the user was required to download new signatures to keep up the protection. Most modern antimalware integrates the initial functionality of antivirus and expands it to cope with most modern attack techniques and malware.
The signature-based functionality has been kept and expanded with cloud-based monitoring, where the antimalware checks with a cloud-based system on the security reputation of a given file. Most antimalware also includes heuristic-based and anomaly-based detection, which are similar to the intrusion detection and prevention systems discussed in the previous section.
Similar to IDS and IPS, antimalware technologies can be implemented in two modes: host based and network based. Host-based and network-based antimalware share most of the same benefits and limitations of HIDS and NIDS. For example, network-based antimalware might not be able to determine whether malware actually reached an endpoint, whereas host-based antimalware might be able to block the malware only on the system where it is installed. In a well-planned security design, the two technologies are deployed together to maximize protection and apply the concept of layered security.
Network-based antimalware can be integrated with other functional devices such as email gateways, web proxies, or intrusion prevention systems. For example, Cisco ESA, Cisco WSA, and Cisco FirePower Next-Gen IPS all include antimalware features.
Cisco Advanced Malware Protection (AMP) comes as host-based antimalware, known as AMP for Endpoints, and network-based antimalware, known as AMP for Networks. Both use cloud-based signature detection, heuristic-based detection, and machine-learning methodologies to protect the host.
An example of a network-based antivirus and antimalware solution that is integrated into other devices is the antivirus scanning offered on the Cisco Email Security Appliance (ESA), which integrates the antivirus engines from known antivirus vendors such as McAfee and Sophos. In the context of an email gateway, the antivirus engine is used to scan the content of email to prevent the delivery of a virus sent via email. Without this solution, the user would have to rely on the host-based antivirus solution. Refer to Chapter 1 for additional information about Cisco AMP and Cisco ESA.
Table 3-10 summarizes the differences between a network-based antimalware solution and a host-based one.
![]()
Table 3-10 Network-Based vs. Host-Based Antivirus/Antimalware Systems

Exam Preparation Tasks
Review All Key Topics
Review the most important topics in the chapter, noted with the Key Topic icon in the outer margin of the page. Table 3-11 lists these key topics and the page numbers on which each is found.
![]()
Table 3-11 Key Topics for Chapter 3

Define Key Terms
Define the following key terms from this chapter, and check your answers in the glossary:
access controls
attribute-based access control
network-based intrusion prevention
host-based intrusion prevention
Review Questions
The answers to these questions appear in Appendix A, “Answers to the ‘Do I Know This Already?’ Quizzes and Review Questions.” For more practice with exam format questions, use the exam engine on the website.
1. In which phase of access control is access granted to a resource with specific privileges?
2. What are characteristics of a secure identity?
3. What authentication method is considered strong?
4. Who assigns a security classification to an asset?
5. What technique ensures protection against simple and noninvasive data-recovery techniques.
6. What type of control includes security training?
7. What type of control best describes an IPS dropping a malicious packet?
8. What types of controls best describe a fence?
9. What is included in a capability table?
10. Where does the RADIUS exchange happen?
11. What AAA protocol allows for capabilities exchange?
12. What port access control technology allows dynamic authorization policy to be downloaded from the authentication server?
13. Where is EAPoL traffic seen?
14. What is the SGT Exchange (SXP) protocol used for?
15. A host on an isolated port can communicate with ________.
16. What is a disadvantage of using an IPS compared to an IDS?
17. What is an advantage of network-based antimalware compared to a host-based solution?
18. According to the attribute-based access control (ABAC) model, what is the subject location considered?
19. What access control models use security labels to make access decisions?
20. What is one of the advantages of the mandatory access control (MAC) model?
21. In a discretionary access control (DAC) model, who can authorize access to an object?