
Chapter 2. Introduction to OpenCL
This chapter introduces the OpenCL specification, including both the host applications programming interface (API) and OpenCL C language. A full vector addition listing is provided and is referenced throughout the chapter to demonstrate host API calls.
Keywords Introduction, OpenCL
Introduction
This chapter introduces OpenCL, the programming fabric that will allow us to weave our application to execute concurrently. Programmers familiar with C and C++ should have little trouble understanding the OpenCL syntax. We begin by reviewing the OpenCL standard.
The OpenCL Standard
Open programming standards designers are tasked with a very challenging objective: arrive at a common set of programming standards that are acceptable to a range of competing needs and requirements. The Khronos consortium that manages the OpenCL standard has done a good job addressing these requirements. The consortium has developed an applications programming interface (API) that is general enough to run on significantly different architectures while being adaptable enough that each hardware platform can still obtain high performance. Using the core language and correctly following the specification, any program designed for one vendor can execute on another's hardware. The model set forth by OpenCL creates portable, vendor- and device-independent programs that are capable of being accelerated on many different hardware platforms.
The OpenCL API is a C with a C++ Wrapper API that is defined in terms of the C API. There are third-party bindings for many languages, including Java, Python, and .NET. The code that executes on an OpenCL device, which in general is not the same device as the host CPU, is written in the OpenCL C language. OpenCL C is a restricted version of the C99 language with extensions appropriate for executing data-parallel code on a variety of heterogeneous devices.
The OpenCL Specification
The OpenCL specification is defined in four parts, called models, that can be summarized as follows:
1. Platform model: Specifies that there is one processor coordinating execution (the host) and one or more processors capable of executing OpenCL C code (the devices). It defines an abstract hardware model that is used by programmers when writing OpenCL C functions (called kernels) that execute on the devices.
2. Execution model: Defines how the OpenCL environment is configured on the host and how kernels are executed on the device. This includes setting up an OpenCL context on the host, providing mechanisms for host–device interaction, and defining a concurrency model used for kernel execution on devices.
3. Memory model: Defines the abstract memory hierarchy that kernels use, regardless of the actual underlying memory architecture. The memory model closely resembles current GPU memory hierarchies, although this has not limited adoptability by other accelerators.
4. Programming model: Defines how the concurrency model is mapped to physical hardware.
In a typical scenario, we might observe an OpenCL implementation executing on a host x86 CPU, which is using a GPU device as an accelerator. The platform model defines this relationship between the host and device. The host sets up a kernel for the GPU to run and instantiates it with some specified degree of parallelism. This is the execution model. The data within the kernel is allocated by the programmer to specific parts of an abstract memory hierarchy. The runtime and driver will map these abstract memory spaces to the physical hierarchy. Finally, hardware thread contexts that execute the kernel must be created and mapped to actual GPU hardware units. This is done using the programming model. Throughout this chapter, these ideas are discussed in further detail.
This chapter begins by introducing how OpenCL kernels are written and the parallel execution model that they use. The OpenCL host API is then described and demonstrated using a running example--vector addition. The full listing of the vector addition example is given at the end of the chapter.
Kernels and the OpenCL Execution Model
Kernels are the parts of an OpenCL program that actually execute on a device. The OpenCL API enables an application to create a context for management of the execution of OpenCL commands, including those describing the movement of data between host and OpenCL memory structures and the execution of kernel code that processes this data to perform some meaningful task.
Like many CPU concurrency models, an OpenCL kernel is syntactically similar to a standard C function; the key difference is a set of additional keywords and the execution model that OpenCL kernels implement. When developing concurrent programs for a CPU using OS threading APIs or OpenMP, for example, the programmer considers the physical resources available (e.g., CPU cores) and the overhead of creating and switching between threads when their number substantially exceeds the resource availability. With OpenCL, the goal is often to represent parallelism programmatically at the finest granularity possible. The generalization of the OpenCL interface and the low-level kernel language allows efficient mapping to a wide range of hardware. The following discussion presents three versions of a function that performs an element-wise vector addition: a serial C implementation, a threaded C implementation, and an OpenCL implementation.
The code for a serial C implementation of the vector addition executes a loop with as many iterations as there are elements to compute. Each loop iteration adds the corresponding locations in the input arrays together and stores the result into the output array:
// Perform an element-wise addition of A and B and store in C.
// There are N elements per array.
void vecadd(int *C, int* A, int *B, int N) {
for(int i = 0; i < N; i++) {
C[i] = A[i] + B[i];
}
}
For a simple multi-core device, we could either use a low-level coarse-grained threading API, such as Win32 or POSIX threads, or use a data-parallel model such as OpenMP. Writing a coarse-grained multithreaded version of the same function would require dividing the work (i.e., loop iterations) between the threads. Because there may be a large number of loop iterations and the work per iteration is small, we would need to chunk the loop iterations into a larger granularity (a technique called strip mining, (Cooper and Torczon, 2011)). The code for the multithreaded version may look as follows:
// Perform and element-wise addition of A and B and store in C.
// There are N elements per array and NP CPU cores.
void vecadd(int *C, int* A, int *B, int N, int NP, int tid) {
int ept = N/NP; // elements per thread
for(int i = tid*ept; i < (tid+1)*ept; i++) {
C[i] = A[i] + B[i];
}
}
OpenCL is closer to OpenMP than the threading APIs of Win32 and POSIX, supporting data-parallel execution but retaining a low level of control. The unit of concurrent execution in OpenCL C is a work-item. As with the two previous examples, each work-item executes the kernel function body. Instead of manually strip mining the loop, we will often map a single iteration of the loop to a work-item. We tell the OpenCL runtime to generate as many work-items as elements in the input and output arrays and allow the runtime to map those work-items to the underlying hardware, and hence CPU or GPU cores, in whatever way it deems appropriate. Conceptually, this is very similar to the parallelism inherent in a functional “map” operation (c.f., mapReduce) or a data-parallel for loop in a model such as OpenMP. When an OpenCL device begins executing a kernel, it provides intrinsic functions that allow a work-item to identify itself. In the following code, the call to get_global_id(0) allows the programmer to make use of the position of the current work-item in the simple case to regain the loop counter:
// Perform an element-wise addition of A and B and store in C
// N work-items will be created to execute this kernel.
__kernel
void vecadd(__global int *C, __global int* A, __global int *B) {
int tid = get_global_id(0); // OpenCL intrinsic function
C[tid] = A[tid] + B[tid];
}
Given that OpenCL describes execution in fine-grained work-items and can dispatch vast numbers of work-items on architectures with hardware support for fine-grained threading, it is easy to have concerns about scalability. The hierarchical concurrency model implemented by OpenCL ensures that scalable execution can be achieved even while supporting a large number of work-items. When a kernel is executed, the programmer specifies the number of work-items that should be created as an n-dimensional range (NDRange). An NDRange is a one-, two-, or three-dimensional index space of work-items that will often map to the dimensions of either the input or the output data. The dimensions of the NDRange are specified as an N-element array of type size_t, where N represents the number of dimensions used to describe the work-items being created.
In the vector addition example, our data will be one-dimensional and, assuming that there are 1024 elements, the size can be specified as a one-, two-, or three-dimensional vector. The host code to specify an ND Range for 1024 elements is as follows:
size_t indexSpaceSize[3] = {1024, 1, 1};
Achieving scalability comes from dividing the work-items of an NDRange into smaller, equally sized workgroups (Figure 2.1). An index space with N dimensions requires workgroups to be specified using the same N dimensions; thus, a three-dimensional index space requires three-dimensional workgroups.

Work items within a workgroup have a special relationship with one another: They can perform barrier operations to synchronize and they have access to a shared memory address space. Because workgroup sizes are fixed, this communication does not have a need to scale and hence does not affect scalability of a large concurrent dispatch.
For the vector addition example, the workgroup size might be specified as
size_t workGroupSize[3] = {64, 1, 1};
If the total number of work-items per array is 1024, this results in creating 16 workgroups (1024 work-items/(64 work-items per workgroup) = 16 workgroups). Note that OpenCL requires that the index space sizes are evenly divisible by the workgroup sizes in each dimension. For hardware efficiency, the workgroup size is usually fixed to a favorable size, and we round up the index space size in each dimension to satisfy this divisibility requirement. In the kernel code, we can specify that extra work-items in each dimension simply return immediately without outputting any data.
For programs such as vector addition in which work-items behave independently (even within a workgroup), OpenCL allows the local workgroup size to be ignored by the programmer and generated automatically by the implementation; in this case, the developer will pass NULL instead.
Platform and devices
The OpenCL platform model defines the roles of the host and devices and provides an abstract hardware model for devices.
Host–Device Interaction
In the platform model, there is a single host that coordinates execution on one or more devices. Platforms can be thought of as vendor-specific implementations of the OpenCL API. The devices that a platform can target are thus limited to those with which a vendor knows how to interact. For example, if Company A's platform is chosen, it cannot communicate with Company B's GPU.
The platform model also presents an abstract device architecture that programmers target when writing OpenCL C code. Vendors map this abstract architecture to the physical hardware. With scalability in mind, the platform model defines a device as an array of compute units, with each compute unit functionally independent from the rest. Compute units are further divided into processing elements. Figure 2.2 illustrates this hierarchical model.

The platform device model closely corresponds to the hardware model of some GPUs. For example, the AMD Radeon 6970 graphics card comprises 24 SIMD cores (compute units), with each SIMD core containing 16 lanes (processing elements). Because each SIMD lane on the 6970 executes a four-way very long instruction word (VLIW) instruction, this OpenCL device allows us to schedule execution of up to 1536 instructions at a time.
The API function clGetPlatformIDs() is used to discover the set of available platforms for a given system:
cl_int
clGetPlatformIDs(cl_uint num_entries,
cl_platform_id *platforms,
cl_uint *num_platforms)
clGetPlatformIDs() will often be called twice by an application. The first call passes an unsigned int pointer as the num_platforms argument and NULL is passed as the platforms argument. The pointer is populated with the available number of platforms. The programmer can then allocate space to hold the platform information. For the second call, a cl_platform_id pointer is passed to the implementation with enough space allocated for num_entries platforms. After platforms have been discovered, the clGetPlatformInfo() call can be used to determine which implementation (vendor) the platform was defined by. Step 1 in the full source code listing at the end of the chapter demonstrates this process.
The clGetDeviceIDs() call works very similar to clGetPlatformIDs(). It takes the additional arguments of a platform and a device type but otherwise the same three-step process occurs. The device_type argument can be used to limit the devices to GPUs only (CL_DEVICE_TYPE_GPU), CPUs only (CL_DEVICE_TYPE_CPU), all devices (CL_DEVICE_TYPE_ALL), as well as other options. As with platforms, clGetDeviceInfo() is called to retrieve information such as name, type, and vendor from each device. Discovering devices is illustrated in step 2 in the full source code listing at the end of the chapter:
cl_int
clGetDeviceIDs(cl_platform_id platform,
cl_device_type device_type,
cl_uint num_entries,
cl_device_id *devices,
cl_uint *num_devices)
The CLInfo program in the AMD APP SDK uses the clGetPlatformInfo() and clGetDeviceInfo() commands to print detailed information about the OpenCL supported platforms and devices in a system. Hardware details such as memory sizes and bus widths are available using these commands. A snippet of the output from the CLInfo program is shown here:
$ ./CLInfo
Number of platforms:1
Platform Profile:FULL_PROFILE
Platform Version:OpenCL 1.1 AMD-APP-SDK-v2.4
Platform Name:AMD Accelerated Parallel Processing
Platform Vendor:Advanced Micro Devices, Inc.
Number of devices:2
Device Type:CL_DEVICE_TYPE_GPU
Name:Cypress
Max compute units:20
Address bits:32
Max memory allocation: 268435456
Global memory size:1073741824
Constant buffer size:65536
Local memory type:Scratchpad
Local memory size:32768
Device endianess:Little
Device Type:CL_DEVICE_TYPE_CPU
Max compute units:16
Name:AMD Phenom(tm) II X4 945 Processor
…
The execution environment
Before a host can request that a kernel be executed on a device, a context must be configured on the host that enables it to pass commands and data to the device.
Contexts
In OpenCL, a context is an abstract container that exists on the host. A context coordinates the mechanisms for host–device interaction, manages the memory objects that are available to the devices, and keeps track of the programs and kernels that are created for each device.
The API function to create a context is clCreateContext(). The properties argument is used to restrict the scope of the context. It may provide a specific platform, enable graphics interoperability, or enable other parameters in the future. Limiting the context to a given platform allows the programmer to provide contexts for multiple platforms and fully utilize a system comprising resources from a mixture of vendors. Next, the number and IDs of the devices that the programmer wants to associate with the context must be supplied. OpenCL allows user callbacks to be provided when creating a context that can be used to report additional error information that might be generated throughout its lifetime. Step 3 in the full source code listing at the end of the chapter demonstrates the creation of a context:
cl_context
clCreateContext (const cl_context_properties *properties,
cl_uint num_devices,
const cl_device_id *devices,
void (CL_CALLBACK *pfn_notify)(
const char *errinfo,
const void *private_info,
size_t cb,
void *user_data),
void *user_data,
cl_int *errcode_ret)
The OpenCL specification also provides an API call that alleviates the need to build a list of devices. clCreateContextFromType() allows a programmer to create a context that automatically includes all devices of the specified type (e.g., CPUs, GPUs, and all devices). After creating a context, the function clGetContextInfo() can be used to query information such as the number of devices present and the device structures.
In OpenCL, the process of discovering platforms and devices and setting up a context is tedious. However, after the code to perform these steps is written once, it can be reused for almost any project.
Command Queues
Communication with a device occurs by submitting commands to a command queue. The command queue is the mechanism that the host uses to request action by the device. Once the host decides which devices to work with and a context is created, one command queue needs to be created per device (i.e., each command queue is associated with only one device). Whenever the host needs an action to be performed by a device, it will submit commands to the proper command queue. The API clCreateCommandQueue() is used to create a command queue and associate it with a device:
cl_command_queue
clCreateCommandQueue(
cl_context context,
cl_device_id device,
cl_command_queue_properties properties,
cl_int* errcode_ret)
The properties parameter of clCreateCommandQueue() is a bit field that is used to enable profiling of commands (CL_QUEUE_PROFILING_ENABLE) and/or to allow out-of-order execution of commands (CL_QUEUE_OUT_OF_ORDER_EXEC_MODE_ENABLE). Profiling is discussed in Chapter 12. With an in-order command queue (the default), commands are pulled from the queue in the order they were received. Out-of-order queues allow the OpenCL implementation to search for commands that can possibly be rearranged to execute more efficiently. If out-of-order queues are used, it is up to the user to specify dependencies that enforce a correct execution order. Step 4 in the full source code listing at the end of the chapter creates a command queue.
Any API that specifies host–device interaction will always begin with clEnqueue and require a command queue as a parameter. For example, the clEnqueueReadBuffer() command requests that the device send data to the host, and clEnqueueNDRangeKernel() requests that a kernel is executed on the device. These calls are discussed later in this chapter.
Events
Any operation that enqueues a command into a command queue—that is, any API call that begins with clEnqueue—produces an event. Events have two main roles in OpenCL:
1. Representing dependencies
2. Providing a mechanism for profiling
In addition to producing event objects, API calls that begin with clEnqueue also take a “wait list” of events as a parameter. By generating an event for one API call and passing it as an argument to a successive call, OpenCL allows us to represent dependencies. A clEnqueue call will block until all events in its wait list have completed. Chapter 5 provides examples of representing dependencies using events.
OpenCL events can also be used to profile, using associated timers, commands enqueued. Chapter 12 describes how to use OpenCL events for profiling.
Memory Objects
OpenCL applications often work with large arrays or multidimensional matrices. This data needs to be physically present on a device before execution can begin. In order for data to be transferred to a device, it must first be encapsulated as a memory object. OpenCL defines two types of memory objects: buffers and images. Buffers are equivalent to arrays in C, created using malloc(), where data elements are stored contiguously in memory. Images, on the other hand, are designed as opaque objects, allowing for data padding and other optimizations that may improve performance on devices.
Whenever a memory object is created, it is valid only within a single context. Movement to and from specific devices is managed by the OpenCL runtime as necessary to satisfy data dependencies.
Buffers
Conceptually, it may help to visualize a memory object as a pointer that is valid on a device. This is similar to a call to malloc, in C, or a C++'s new operator. The API function clCreateBuffer() allocates the buffer and returns a memory object:
cl_mem clCreateBuffer(
cl_context context,
cl_mem_flags flags,
size_t size,
void *host_ptr,
cl_int *errcode_ret)
Creating a buffer requires supplying the size of the buffer and a context in which the buffer will be allocated; it is visible for all devices associated with the context. Optionally, the caller can supply flags that specify that the data is read-only, write-only, or read-write. Other flags also exist that specify additional options for creating and initializing a buffer. One simple option is to supply a host pointer with data used to initialize the buffer. Step 5 in the full source code listing at the end of the chapter demonstrates the creation of two input buffers and one output buffer.
Data contained in host memory is transferred to and from an OpenCL buffer using the commands clEnqueueWriteBuffer() and clEnqueueReadBuffer(), respectively. If a kernel that is dependent on such a buffer is executed on a discrete accelerator device such as a GPU, the buffer may be transferred to the device. The buffer is linked to a context, not a device, so it is the runtime that determines the precise time the data is moved.
The API calls for reading and writing to buffers are very similar. The signature for clEnqueueWriteBuffer() is
cl_int
clEnqueueWriteBuffer (
cl_command_queue command_queue,
cl_mem buffer,
cl_bool blocking_write,
size_t offset,
size_t cb,
const void *ptr,
cl_uint num_events_in_wait_list,
const cl_event *event_wait_list,
cl_event *event)
Similar to other enqueue operations, reading or writing a buffer requires a command queue to manage the execution schedule. In addition, the enqueue function requires the buffer, the number of bytes to transfer, and an offset within the buffer. The blocking_write option should be set to CL_TRUE if the transfer into an OpenCL buffer should complete before the function returns—that is, it will block until the operation has completed. Setting blocking_write to CL_FALSE allows clEnqueueWriteBuffer() to return before the write operation has completed. Step 6 in the full source code listing at the end of the chapter enqueues commands to write input data to buffers on a device, and step 12 reads the output data back to the host.
Images
Images are a type of OpenCL memory object that abstract the storage of physical data to allow for device-specific optimizations. They are not required to be supported by all OpenCL devices, and an application is required to check, using clGetDeviceInfo(), if they are supported or not; otherwise, behavior is undefined. Unlike buffers, images cannot be directly referenced as if they were arrays. Furthermore, adjacent data elements are not guaranteed to be stored contiguously in memory. The purpose of using images is to allow the hardware to take advantage of spatial locality and to utilize hardware acceleration available on many devices. The architectural design and trade-offs for images are discussed in detail in Chapter 5.
Images are an example of the OpenCL standard being dependent on the underlying hardware of a particular device, in this case the GPU, versus the other way around. The elements of an image are represented by a format descriptor (cl_image_format). The format descriptor specifies how the image elements are stored in memory based on the concept of channels. The channel order specifies the number of elements that make up an image element (up to four elements, based on the traditional use of RGBA pixels), and the channel type specifies the size of each element. These elements can be sized from 1 to 4 bytes and in various different formats (e.g., integer or floating point).
Creating an OpenCL image is done using the command clCreateImage2D() or clCreateImage3D(). Additional arguments are required when creating an image object versus those specified for creating a buffer. First, the height and width of the image must be given (and a depth for the three-dimensional case). In addition, an image pitch1 may be supplied if initialization data is provided.
cl_mem
clCreateImage2D(
cl_context context,
cl_mem_flags flags,
const cl_image_format *image_format,
size_t image_width,
size_t image_height,
size_t image_row_pitch,
void *host_ptr,
cl_int *errcode_ret)
There are also additional parameters when reading or writing an image. Read or write operations take a three-element origin (similar to the buffer offset) that defines the location within the image that the transfer will begin and another three-element region parameter that defines the extent of the data that will be transferred.
Within a kernel, images are accessed with built-in functions specific to the data type. For example, the function read_imagef() is used for reading floats and read_imageui() for unsigned integers. When data is read from an image, a sampler object is required. Samplers specify how out-of-bounds image accesses are handled, whether interpolation should be used, and if coordinates are normalized. Writing to a location in an image requires manual conversion to the proper storage data format (i.e., storing in the proper channel and with the proper size). Chapter 4 provides an example of an OpenCL program that uses images.
Flush and Finish
The flush and finish commands are two different types of barrier operations for a command queue. The clFinish() function blocks until all of the commands in a command queue have completed; its functionality is synonymous with a synchronization barrier. The clFlush() function blocks until all of the commands in a command queue have been removed from the queue. This means that the commands will definitely be in-flight but will not necessarily have completed.
cl_int clFlush(cl_command_queue command_queue);
cl_int clFinish(cl_command_queue command_queue);
Creating an OpenCL Program Object
OpenCL C code (written to run on an OpenCL device) is called a program. A program is a collection of functions called kernels, where kernels are units of execution that can be scheduled to run on a device.
OpenCL programs are compiled at runtime through a series of API calls. This runtime compilation gives the system an opportunity to optimize for a specific device. There is no need for an OpenCL application to have been prebuilt against the AMD, NVIDIA, or Intel runtimes, for example, if it is to run on devices produced by all of these vendors. OpenCL software links only to a common runtime layer (called the ICD); all platform-specific SDK activity is delegated to a vendor runtime through a dynamic library interface.
The process of creating a kernel is as follows:
1. The OpenCL C source code is stored in a character string. If the source code is stored in a file on a disk, it must be read into memory and stored as a character array.
2. The source code is turned into a program object, cl_program, by calling clCreateProgramWithSource().
3. The program object is then compiled, for one or more OpenCL devices, with clBuildProgram(). If there are compile errors, they will be reported here.
The precise binary representation used is very vendor specific. In the AMD runtime, there are two main classes of devices: x86 CPUs and GPUs. For x86 CPUs, clBuildProgram() generates x86 instructions that can be directly executed on the device. For the GPUs, it will create AMD's GPU intermediate language (IL), a high-level intermediate language that represents a single work-item but that will be just-in-time compiled for a specific GPU's architecture later, generating what is often known as ISA (i.e., code for a specific instruction set architecture). NVIDIA uses a similar approach, calling its intermediate representation PTX. The advantage of using such an IL is to allow the GPU ISA itself to change from one device or generation to another in what is still a very rapidly developing architectural space.
One additional feature of the build process is the ability to generate both the final binary format and various intermediate representations and serialize them (e.g., write them out to disk). As with most objects, OpenCL provides a function to return information about program objects, clGetProgramInfo(). One of the flags to this function is CL_PROGRAM_BINARIES, which returns a vendor-specific set of binary objects generated by clBuildProgram().
In addition to clCreateProgramWithSource(), OpenCL provides clCreateProgramWithBinary(), which takes a list of binaries that matches its device list.
The binaries are previously created using clGetProgramInfo().
The OpenCL Kernel
The final stage to obtain a cl_kernel object that can be used to execute kernels on a device is to extract the kernel from the cl_program. Extracting a kernel from a program is similar to obtaining an exported function from a dynamic library. The name of the kernel that the program exports is used to request it from the compiled program object. The name of the kernel is passed to clCreateKernel(), along with the program object, and the kernel object will be returned if the program object was valid and the particular kernel is found.
A few more steps are required before the kernel can actually be executed. Unlike calling functions in regular C programs, we cannot simply call a kernel by providing a list of arguments.
Executing a kernel requires dispatching it through an enqueue function. Due both to the syntax of the C language and to the fact that kernel arguments are persistent (and hence we need not repeatedly set them to construct the argument list for such a dispatch), we must specify each kernel argument individually using the function clSetKernelArg(). This function takes a kernel object, an index specifying the argument number, the size of the argument, and a pointer to the argument. When a kernel is executed, this information is used to transfer arguments to the device. The type information in the kernel parameter list is then used by the runtime to unbox (similar to casting) the data to its appropriate type. The process of setting kernel arguments is illustrated in step 9 in the full source code listing at the end of the chapter.
After any required memory objects are transferred to the device and the kernel arguments are set, the kernel is ready to be executed. Requesting that a device begin executing a kernel is done with a call to clEnqueueNDRangeKernel():
cl_int
clEnqueueNDRangeKernel(
cl_command_queue command_queue,
cl_kernel kernel,
cl_uint work_dim,
const size_t *global_work_offset,
const size_t *global_work_size,
const size_t *local_work_size,
cl_uint num_events_in_wait_list,
const cl_event *event_wait_list,
cl_event *event)
Look at the signature for the function. A command queue must be specified so the target device is known. Similarly, the kernel object identifies the code to be executed. Four fields are related to work-item creation. The work_dim parameter specifies the number of dimensions (one, two, or three) in which work-items will be created. The global_work_size parameter specifies the number of work-items in each dimension of the NDRange, and local_work_size specifies the number of work-items in each dimension of the workgroups. The parameter global_work_offset can be used to provide global IDs to the work-items that do not start at 0. As with all clEnqueue commands, an event_wait_list is provided, and for non-NULL values the runtime will guarantee that all corresponding events will have completed before the kernel begins execution. The clEnqueueNDRangeKernel() call is asynchronous: it will return immediately after the command is enqueued in the command queue and likely before the kernel has even started execution. Either clWaitForEvents() or clFinish() can be used to block execution on the host until the kernel completes. The code to configure the work-items for the vector addition kernel is shown in step 10 in the full source code listing at the end of the chapter, and the command to enqueue the vector addition kernel is shown in step 11.
At this point, we have presented all of the required host API commands needed to enable the reader to run a complete OpenCL program.
Memory model
In general, memory subsystems vary greatly between computing platforms. For example, all modern CPUs support automatic caching, although many GPUs do not. To support code portability, OpenCL's approach is to define an abstract memory model that programmers can target when writing code and vendors can map to their actual memory hardware. The memory spaces defined by OpenCL are discussed here and shown in Figure 2.3.

These memory spaces are relevant within OpenCL programs. The keywords associated with each space can be used to specify where a variable should be created or where the data that it points to resides.
Global memory is visible to all compute units on the device (similar to the main memory on a CPU-based host system). Whenever data is transferred from the host to the device, the data will reside in global memory. Any data that is to be transferred back from the device to the host must also reside in global memory. The keyword __global is added to a pointer declaration to specify that data referenced by the pointer resides in global memory. For example, in the OpenCL C code at the end of the chapter __global float* A, the data pointed to by A resides in global memory (although we will see that A actually resides in private memory).
Constant memory is not specifically designed for every type of read-only data but, rather, for data where each element is accessed simultaneously by all work-items. Variables whose values never change (e.g., a data variable holding the value of π) also fall into this category. Constant memory is modeled as a part of global memory, so memory objects that are transferred to global memory can be specified as constant. Data is mapped to constant memory by using the __constant keyword.
Local memory is a scratchpad memory whose address space is unique to each compute device. It is common for it to be implemented as on-chip memory, but there is no requirement that this be the case. Local memory is modeled as being shared by a workgroup. As such, accesses may have much shorter latency and much higher bandwidth than global memory. Calling clSetKernelArg() with a size, but no argument, allows local memory to be allocated at runtime, where a kernel parameter is defined as a __local pointer (e.g., __local float* sharedData). Alternatively, arrays can be statically declared in local memory by appending the keyword __local (e.g., __local float[64] sharedData), although this requires specifying the array size at compile time.
Private memory is memory that is unique to an individual work-item. Local variables and nonpointer kernel arguments are private by default. In practice, these variables are usually mapped to registers, although private arrays and any spilled registers are usually mapped to an off-chip (i.e., long-latency) memory.
The memory spaces of OpenCL closely model those of modern GPUs. Figure 2.4 details the relationship between OpenCL memory spaces and those found on an AMD 6970 GPU.
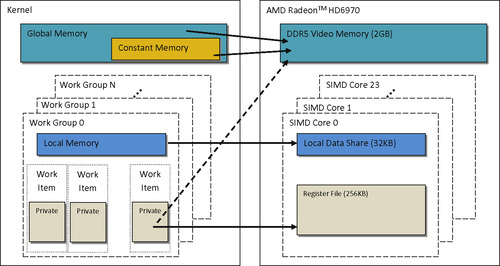
Writing kernels
As previously described, OpenCL C kernels are similar to C functions and can be thought of as instances of a parallel map operation. The function body, like the mapped function, will be executed once for every work-item created. We utilize the code for the OpenCL kernel cache kernel to illustrate how this mapping is accomplished.
Kernels begin with the keyword __kernel and must have a return type of void. The argument list is as for a C function with the additional requirement that the address space of any pointer must be specified. Buffers can be declared in global memory (__global) or constant memory (__constant). Images are assigned to global memory. Access qualifiers (__read_only, __write_only, and __read_write) can also be optionally specified because they may allow for compiler and hardware optimizations.
The __local qualifier is used to declare memory that is shared between all work-items in a workgroup. This concept is often one of the most confusing for new OpenCL programmers. When a local pointer is declared as a kernel parameter, such as __local float *sharedData, it is a pointer to an array shared by the entire workgroup. In other words, only one 64-element array will be created per workgroup, and all work-items in the workgroup can access it.
An alternative approach for declaring local memory allocations is to declare a variable at a kernel-scope level:
__kernel void aKernel(…){
// Shared by all work-items in the group
__local float sharedData[32];
…
}
This appears to have kernel textual scope, but the same named entity is shared by all work-items in an entire workgroup, just as is the __local parameter, and the approaches are equivalent. Although it is important to note that a __local parameter can be set to a different size for each dispatch, a __local declaration within a kernel is fixed at compilation time.
When programming for OpenCL devices, particularly GPUs, performance may increase by using local memory to cache data that will be used multiple times by a work-item or by multiple work-items in the same workgroup (i.e., data with temporal locality). When developing a kernel, we can achieve this with an explicit assignment from a global memory pointer to a local memory pointer, as shown in the following example code:
__kernel void cache(
__global float* data,
__local float* sharedData) {
int globalId = get_global_id(0);
int localId = get_local_id(0);
// Cache data to local memory
sharedData[localId] = data[globalId];
…
}
Once a work-item completes its execution, none of its state information or local memory storage is persistent. Any results that need to be kept must be transferred to global memory.
Full source code example for vector addition
The following example listing is the complete host code for implementing the vector addition example discussed in this chapter: 2
2Error checking has been omitted from this code for simplicity. For correctness, status should be checked after each call for CL_SUCCESS and any errors dealt with.
// This program implements a vector addition using OpenCL
// System includes
#include <stdio.h>
#include <stdlib.h>
// OpenCL includes
#include <CL/cl.h>
// OpenCL kernel to perform an element-wise
// add of two arrays
const char* programSource =
“__kernel
”
“void vecadd(__global int *A,
”
“__global int *B,
”
“__global int *C)
”
“{
”
“
”
“// Get the work-item's unique ID
”
“int idx = get_global_id(0);
”
“
”
“// Add the corresponding locations of
”
“// 'A' and 'B', and store the result in 'C'.
”
“C[idx] = A[idx] + B[idx];
”
“}
”
;
int main() {
// This code executes on the OpenCL host
// Host data
int *A = NULL; // Input array
int *B = NULL; // Input array
int *C = NULL; // Output array
// Elements in each array
const int elements = 2048;
// Compute the size of the data
size_t datasize = sizeof(int)*elements;
// Allocate space for input/output data
A = (int*)malloc(datasize);
B = (int*)malloc(datasize);
C = (int*)malloc(datasize);
// Initialize the input data
for(int i = 0; i < elements; i++) {
A[i] = i;
B[i] = i;
}
// Use this to check the output of each API call
cl_int status;
//-----------------------------------------------------
// STEP 1: Discover and initialize the platforms
//-----------------------------------------------------
cl_uint numPlatforms = 0;
cl_platform_id *platforms = NULL;
// Use clGetPlatformIDs() to retrieve the number of
// platforms
status = clGetPlatformIDs(0, NULL, &numPlatforms);
// Allocate enough space for each platform
platforms =
(cl_platform_id*)malloc(
numPlatforms*sizeof(cl_platform_id));
// Fill in platforms with clGetPlatformIDs()
status = clGetPlatformIDs(numPlatforms, platforms,
NULL);
//-----------------------------------------------------
// STEP 2: Discover and initialize the devices
//-----------------------------------------------------
cl_uint numDevices = 0;
cl_device_id *devices = NULL;
// Use clGetDeviceIDs() to retrieve the number of
// devices present
status = clGetDeviceIDs(
platforms[0],
CL_DEVICE_TYPE_ALL,
0,
NULL,
&numDevices);
// Allocate enough space for each device
devices =
(cl_device_id*)malloc(
numDevices*sizeof(cl_device_id));
// Fill in devices with clGetDeviceIDs()
status = clGetDeviceIDs(
platforms[0],
CL_DEVICE_TYPE_ALL,
numDevices,
devices,
NULL);
//-----------------------------------------------------
// STEP 3: Create a context
//-----------------------------------------------------
cl_context context = NULL;
// Create a context using clCreateContext() and
// associate it with the devices
context = clCreateContext(
NULL,
numDevices,
devices,
NULL,
NULL,
&status);
//-----------------------------------------------------
// STEP 4: Create a command queue
//-----------------------------------------------------
cl_command_queue cmdQueue;
// Create a command queue using clCreateCommandQueue(),
// and associate it with the device you want to execute
// on
cmdQueue = clCreateCommandQueue(
context,
devices[0],
0,
&status);
//-----------------------------------------------------
// STEP 5: Create device buffers
//-----------------------------------------------------
cl_mem bufferA; // Input array on the device
cl_mem bufferB; // Input array on the device
cl_mem bufferC; // Output array on the device
// Use clCreateBuffer() to create a buffer object (d_A)
// that will contain the data from the host array A
bufferA = clCreateBuffer(
context,
CL_MEM_READ_ONLY,
datasize,
NULL,
&status);
// Use clCreateBuffer() to create a buffer object (d_B)
// that will contain the data from the host array B
bufferB = clCreateBuffer(
context,
CL_MEM_READ_ONLY,
datasize,
NULL,
&status);
// Use clCreateBuffer() to create a buffer object (d_C)
// with enough space to hold the output data
bufferC = clCreateBuffer(
context,
CL_MEM_WRITE_ONLY,
datasize,
NULL,
&status);
//-----------------------------------------------------
// STEP 6: Write host data to device buffers
//-----------------------------------------------------
// Use clEnqueueWriteBuffer() to write input array A to
// the device buffer bufferA
status = clEnqueueWriteBuffer(
cmdQueue,
bufferA,
CL_FALSE,
0,
datasize,
A,
0,
NULL,
NULL);
// Use clEnqueueWriteBuffer() to write input array B to
// the device buffer bufferB
status = clEnqueueWriteBuffer(
cmdQueue,
bufferB,
CL_FALSE,
0,
datasize,
B,
0,
NULL,
NULL);
//-----------------------------------------------------
// STEP 7: Create and compile the program
//-----------------------------------------------------
// Create a program using clCreateProgramWithSource()
cl_program program = clCreateProgramWithSource(
context,
1,
(const char**)&programSource,
NULL,
&status);
// Build (compile) the program for the devices with
// clBuildProgram()
status = clBuildProgram(
program,
numDevices,
devices,
NULL,
NULL,
NULL);
//-----------------------------------------------------
// STEP 8: Create the kernel
//-----------------------------------------------------
cl_kernel kernel = NULL;
// Use clCreateKernel() to create a kernel from the
// vector addition function (named "vecadd")
kernel = clCreateKernel(program, "vecadd", &status);
//-----------------------------------------------------
// STEP 9: Set the kernel arguments
//-----------------------------------------------------
// Associate the input and output buffers with the
// kernel
// using clSetKernelArg()
status = clSetKernelArg(
kernel,
0,
sizeof(cl_mem),
&bufferA);
status |= clSetKernelArg(
kernel,
1,
sizeof(cl_mem),
&bufferB);
status |= clSetKernelArg(
kernel,
2,
sizeof(cl_mem),
&bufferC);
//-----------------------------------------------------
// STEP 10: Configure the work-item structure
//-----------------------------------------------------
// Define an index space (global work size) of work
// items for
// execution. A workgroup size (local work size) is not
// required,
// but can be used.
size_t globalWorkSize[1];
// There are 'elements' work-items
globalWorkSize[0] = elements;
//-----------------------------------------------------
// STEP 11: Enqueue the kernel for execution
//-----------------------------------------------------
// Execute the kernel by using
// clEnqueueNDRangeKernel().
// 'globalWorkSize' is the 1D dimension of the
// work-items
status = clEnqueueNDRangeKernel(
cmdQueue,
kernel,
1,
NULL,
globalWorkSize,
NULL,
0,
NULL,
NULL);
//-----------------------------------------------------
// STEP 12: Read the output buffer back to the host
//-----------------------------------------------------
// Use clEnqueueReadBuffer() to read the OpenCL output
// buffer (bufferC)
// to the host output array (C)
clEnqueueReadBuffer(
cmdQueue,
bufferC,
CL_TRUE,
0,
datasize,
C,
0,
NULL,
NULL);
// Verify the output
bool result = true;
for(int i = 0; i < elements; i++) {
if(C[i] != i+i) {
result = false;
break;
}
}
if(result) {
printf("Output is correct
");
} else {
printf("Output is incorrect
");
}
//-----------------------------------------------------
// STEP 13: Release OpenCL resources
//-----------------------------------------------------
// Free OpenCL resources
clReleaseKernel(kernel);
clReleaseProgram(program);
clReleaseCommandQueue(cmdQueue);
clReleaseMemObject(bufferA);
clReleaseMemObject(bufferB);
clReleaseMemObject(bufferC);
clReleaseContext(context);
// Free host resources
free(A);
free(B);
free(C);
free(platforms);
free(devices);
}
Summary
In this chapter, we provided an introduction to the basics of using the OpenCL standard when developing parallel programs. We described the four different abstraction models defined in the standard and presented examples of OpenCL implementations to place some of the abstraction in context.
In Chapter 3, we discuss OpenCL device architectures, including a range of instruction set styles, threading issues, and memory topics.
Reference
Cooper, K.; Torczon, L., Engineering a Compiler. (2011) Morgan Kaufmann, Burlington, MA.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.