
Chapter 1. The Database Environment
Can you think of a business that doesn't have a database that's stored on a computer? Maybe you can't, but I know of one: a small used paperback bookstore. A customer brings in used paperbacks and receives credit for them based on their condition and, in some cases, the subject matter of the books. That credit can be applied to purchasing books from the store at approximately twice what the store pays to acquire the books. The books are shelved by general type (for example, mystery, romance, and nonfiction), but otherwise they are not categorized. The store doesn't have a precise inventory of what is on its shelves.
To keep track of customer credits, the store has a 4 × 6 card for each customer on which employees write a date and an amount of credit. The credit amount is incremented or decremented, based on a customer's transactions. The cards themselves are stored in two long steel drawers that sit on a counter. (The cabinet from which the drawers were taken is nowhere in evidence.) Sales slips are written by hand, and cash is kept in a drawer. (Credit card transactions are processed by a stand-alone terminal that uses a phone line to dial up the processing bank for card approval.) The business is small, and their system seems to work, but it certainly is an exception.
Although this bookstore doesn't have a computer or a database, it does have data. In fact, like a majority of businesses today, it relies on data as the foundation of what it does. The bookstore's operations require the customer credit data; it couldn't function without it.
Data form the basis of just about everything an organization that deals with money does. (It's possible to operate a business using bartering and not keep any data, but that certainly is a rarity.) Even a Girl Scout troop selling cookies must store and manipulate data. The troop needs to keep track of how many boxes of each type of cookie have been ordered and by whom. They also need to manage data about money: payments received, payments owed, amount kept by the troop, amount sent to the national organization. The data may be kept on paper, but they still exist, and manipulation of those data is central to the group's functioning. In fact, just about the only business that doesn't deal with data is a lemonade stand that gets its supplies from Mom's kitchen and never has to pay Mom back. The kids take the entire gross income of the lemonade stand without having to worry about how much is profit.
Data have always been part of businesses. Until the mid-twentieth century, those data were processed manually. Because they were stored on paper, retrieving data was difficult, especially if the volume of data was large. In addition, paper documents tended to deteriorate with age. Computers changed that picture significantly, making it possible to store data in much less space, to retrieve data more easily, and, usually, to store it more permanently.
The downside to the change to automated data storage and retrieval was the need for specialized knowledge on the part of those who set up the computer systems. In addition, it costs more to purchase the equipment needed for electronic data manipulation than it does to purchase some file folders and file cabinets. Nonetheless, the ease of data access and manipulation that computing has brought to business has outweighed most other considerations.
Defining a Database
Nearly 30 years ago, when I first started working with databases, I would begin a college course I was teaching in database management with the sentence “There is no term more misunderstood and misused in all of business computing than database.” Unfortunately, that is still true to some extent, and we can still lay much of the blame on commercial software developers. In this section we’ll explore why that is so and provide a complete definition for a database.
Lists and Files
A portion of the data used in a business is represented by lists of things. For example, most of us have a contact list that contains names, addresses, and phone numbers. Businesspeople also commonly work with planners that list appointments. In our daily lives, we have shopping lists of all kinds, as well as “to do” lists. For many years, we handled these lists manually, using paper, day planners, and a pen. It made sense to many people to migrate these lists from paper to their PCs.
Software that helps us maintain simple lists stores those lists in files, generally one list per physical file. The software that manages the list typically lets you create a form for data entry, provides a method of querying the data based on logical criteria, and lets you design output formats. List management software can be found not only on desktop and laptop computers but also on our handheld computing devices. Unfortunately, list management software has been marketed under the name “database” since the advent of PCs. People have therefore come to think of anything that stores and manipulates data as database software. Nonetheless, a list handled by a manager is not a database.
Note: For a more in-depth discussion of the preceding issue, see the first section of Appendix A.
Databases
There is a fundamental concept behind all databases: There are things in a business environment, about which we need to store data, and those things are related to one another in a variety of ways. In fact, to be considered a database, the place where data are stored must contain not only the data but also information about the relationships between those data. We might, for example, need to relate our customers to the orders they place with us and our inventory items to orders for those items.
The idea behind a database is that the user—either a person working interactively or an application program—has no need to worry about how data are physically stored on disk. The user phrases data manipulation requests in terms of data relationships. A piece of software known as a database management system (DBMS) then translates between the user's request for data and the physical data storage.
Why, then, don't the simple “database” software packages (the list managers) produce true databases? Because they can't represent relationships between data, much less use such relationships to retrieve data. The problem is that list management software has been marketed for years as “database” software, and many purchasers do not understand exactly what they are purchasing. Making the problem worse is that a rectangular area of a spreadsheet is also called a “database.” As you will see later in this book, a group of cells in a spreadsheet is even less of a database than a stand-alone list. Because this problem of terminology remains, confusion about exactly what a database happens to be remains as well.
Data “Ownership”
Who “owns” the data in your organization? Departments? IT? How many databases are there? Are there departmental databases, or is there a centralized, integrated database that serves the entire organization? The answers to these questions can determine the effectiveness of a company's database management.
The idea of data ownership has some important implications. To see them, we must consider the human side of owning data. People consider exclusive access to information a privilege and are often proud of their access: “I know something you don't know.” In organizations where small databases have cropped up over the years, the data in a given database are often held in individual departments that are reluctant to share that data with other organizational units.
One problem with these small databases is that they may contain duplicated data that are inconsistent. A customer might be identified as “John J. Smith” in the marketing database but as “John Jacob Smith” in the sales database. It also can be technologically difficult to obtain data stored in multiple databases. For example, one database may store a customer number as text, while another stores it as an integer. An application will be unable to match customer numbers between the two databases. In addition, attempts to integrate the data into a single, shared data store may run into resistance from the data “owners,” who are reluctant to give up control of their data.
In yet other organizations, data are held by the IT department, which carefully doles out access to those data as needed. IT requires supervisor signatures on requests for accounts and limits access to as little data as possible, often stating requirements for system security. Data users feel as if they are at the mercy of IT, even though the data are essential to corporate functioning.
The important psychological change that needs to occur in either of the preceding situations is that data belong to the organization and that they must be shared as needed throughout the organization without unnecessary roadblocks to access. This does not mean that an organization should ignore security concerns but that, where appropriate, data should be shared readily within the organization.
Service-Oriented Architecture
One way to organize a company's entire information systems functions is service-oriented architecture (SOA). In an SOA environment, all information systems components are viewed as services that are provided to the organization. The services are designed so they interact smoothly, sharing data easily when needed.
An organization must make a commitment to implement SOA. Because services need to be able to integrate smoothly, information systems must be designed from the top down. (In contrast, organizations with many departmental databases and applications have grown from the bottom up.) In many cases, this may mean replacing most of an organization's existing information systems.
SOA certainly changes the role of a database in an organization in that the database becomes a service provided to the organization. To serve that role, a database must be designed to integrate with a variety of departmental applications. The only way for this to happen is for the structure of the database to be well documented, usually in some form of data dictionary. For example, if a department needs an application program that uses a customer's telephone number, application programmers first consult the data dictionary to find out that a telephone number is stored with the area code separate from the rest of the phone number. Every application that accesses the database must use the same telephone number format. The result is services that can easily exchange data because all services are using the same data formats.
Shared data also place restrictions on how changes to the data dictionary are handled. Changes to a departmental database affect only that department's applications, but changes to a database service may affect many other services that use the data. An organization must therefore have procedures in place for notifying all users of data when changes are proposed, giving the users a chance to respond to the proposed change and deciding whether the proposed change is warranted. As an example, consider the effect of a change from a five- to nine-digit zip code for a bank. The CFO believes that there will be a significant savings in postage if the change is implemented. However, the transparent windows in the envelopes used to mail paper account statements are too narrow to show the entire nine-digit zip code. Envelopes with wider windows are very expensive, so expensive that making the change will actually cost more than leaving the zip codes at five digits. The CFO was not aware of the cost of the envelopes; the cost was noticed by someone in the purchasing department.
SOA works best for large organizations. It is expensive to introduce because typically organizations have accumulated a significant number of independent programs and data stores that will need to be replaced. Just determining where all the data are stored, who controls the data, which data are stored, and how those data are formatted can be daunting tasks. It is also a psychological change for those employees who are used to owning and controlling data.
Organizations undertake the change to SOA because in the long run it makes information systems easier to modify as corporate needs change. It does not change the process for designing and maintaining a database, but it does change how applications programs and users interact with it.
Database Software: DBMSs
A wide range of DBMS software is available today. Some, such as Microsoft Access1 (part of the Windows Microsoft Office suite), are designed for single users only. 2 The largest proportion of today's DBMSs, however, are multiuser, intended for concurrent use by many users. A few of those DBMSs are intended for small organizations, such as FileMaker Pro3 (cross-platform, multiuser) and Helix4 (Macintosh multiuser). Most, however, are intended for enterprise use. You may have heard of DB25 or Oracle, 6 both of which have versions for small businesses but are primarily intended for large installations using mainframes. As an alternative to these commercial products, many businesses have chosen to use open source products such as MySQL. 7
2It is possible to “share” an Access database with multiple users, but Microsoft never intended the product to be used in that way. Sharing an Access database is known to cause regular file corruption. A database administrator working in such an environment once told me that she had to rebuild the file “only once every two or three days.”
7Seewww.mysql.com. The “community” version of the product is free but does not include any technical support; an enterprise version includes technical support and therefore is fee-based.
For the most part, enterprise-strength DBMSs are large, expensive pieces of software. (The exception to the preceding sentence, of course, is open-source products.) They require significant training and expertise on the part of whoever will be implementing the database. It is not unusual for a large organization to employ one or more people to handle the physical implementation of the database along with a team (or teams) of people to develop the logical structure of the database. Yet more teams may be responsible for developing application programs that interact with the database and provide an interface for those who cannot, or should not, interact with the database directly.
Regardless of the database product you choose, you should expect to find the following capabilities:
▪ A DBMS must provide facilities for creating the structure of the database. Developers must be able to define the logical structure of the data to be stored, including the relationships among data.
▪ A DBMS must provide some way to enter, modify, and delete data. Small DBMSs typically focus on form-based interfaces; enterprise-level products begin with a command-line interface. The most commonly used language for interacting with a relational database (the type we are discussing in this book) is SQL (originally called Structured Query Language), which has been accepted throughout much of the world as a standard data manipulation language for relational databases.
▪ A DBMS must also provide a way to retrieve data. In particular, users must be able to formulate queries based on the logical relationships among the data. Smaller products support form-based querying, while enterprise-level products support SQL. A DBMS should support complex query statements using Boolean algebra (the AND, OR, and NOT operators) and should also be able to perform at least basic calculations (for example, computing totals and subtotals) on data retrieved by a query.
▪ Although it is possible to interact with a DBMS either with basic forms (for a smaller product) or at the SQL command line (for enterprise-level products), doing so requires some measure of specialized training. A business usually has employees who must manipulate data but don't have the necessary expertise, can't or don't want to gain the necessary expertise, or shouldn't have direct access to the database for security reasons. Application developers therefore create programs that simplify access to the database for such users. Most DBMSs designed for business use provide some way to develop such applications. The larger the DBMS, the more likely it is that application development requires traditional programming skills. Smaller products support graphic tools for “drawing” forms and report layouts.
▪ A DBMS should provide methods for restricting access to data. Such methods often include creating user names and passwords specific to the database and tying access to data items to the user name. Security provided by the DBMS is in addition to security in place to protect an organization's network.
Database Hardware Architecture
Because databases are almost always designed for concurrent access by multiple users, database access has always involved some type of computer network. The hardware architecture of these networks has matured along with more general computing networks.
Centralized
Originally network architecture was centralized, with all processing done on a mainframe. Remote users—who were almost always located within the same building or at least the same office park—worked with dumb terminals that could accept input and display output but had no processing power of their own. The terminals were hard-wired to the mainframe (usually through some type of specialized controller) using coaxial cable, as in Figure 1.1. During the time that the classic centralized architecture was in wide use, network security also was not a major issue. The Internet was not publicly available, the World Wide Web did not exist, and security threats were predominantly internal.

Centralized database architecture in the sense we have been describing is rarely found today. Instead, those organizations that maintain a centralized database typically have both local and remote users connecting using PCs, LANs, and a WAN of some kind. As you look at Figure 1.2, keep in mind that although the terminals have been replaced with PCs, the PCs are not using their own processing power when interacting with the database. All processing is still done on the mainframe.

From the point of view of an IT department, the centralized architecture has one major advantage: control. All the computing is done on one computer to which only IT has direct access. Software management is easier because all software resides and executes on one machine. Security efforts can be concentrated on a single point of vulnerability. In addition, mainframes have the significant processing power to handle data-intensive operations.
One drawback to a centralized database architecture is network performance. Because the terminals (or PCs acting as terminals) do not do any processing on their own, all processing must be done on the mainframe. The database needs to send formatted output to the terminals, which consumes more network bandwidth than would sending only the data.
A second drawback to centralized architecture is reliability. If the database goes down, the entire organization is prevented from doing any data processing.
The mainframes are not gone, but their role has changed as client/server architecture has become popular.
Client/Server
Client/server architecture shares the data processing chores between a server—typically a high-end workstation—and clients, which are usually PCs. PCs have significant processing power and are therefore capable of taking raw data returned by the server and formatting it for output. Application programs are stored and executed on the PCs. Network traffic is reduced to data manipulation requests sent from the PC to the database server and raw data returned as a result of that request. The result is significantly less network traffic and theoretically better performance.
Today's client/server architectures exchange messages over local area networks (LANs). Although a few older Token Ring LANs are still in use, most of today's LANs are based on Ethernet standards. As an example, take a look at the small network in Figure 1-3. The database runs on its on server (the database server), using additional disk space on the network attached storage device. Access to the database is controlled not only by the DBMS itself but by the authentication server.

A client/server architecture is similar to the traditional centralized architecture in that the DBMS resides on a single computer. In fact, many of today's mainframes actually function as large, fast servers. The need to handle large data sets still exists, although the location of some of the processing has changed.
Because a client/server architecture uses a centralized database server, it suffers from the same reliability problems as the traditional centralized architecture: If the server goes down, data access is cut off. However, because the “terminals” are PCs, any data downloaded to a PC can be processed without access to the server.
Distributed
Not long after centralized databases became common—and before the introduction of client/server architecture—large organizations began experimenting with placing portions of their databases at different locations, with each site running a DBMS against part of the entire data set. This architecture is known as a distributed database. (For an example, see Figure 1-4.) It is different from the WAN-using centralized database in Figure 1-2 in that there is a DBMS and part of the database at each site as opposed to having one computer doing all of the processing and data storage.

A distributed database architecture has several advantages:
▪ The hardware and software placed at each site can be tailored to the needs of the site. If a mainframe is warranted, then the organization uses a mainframe. If smaller servers will provide enough capacity, then the organization can save money by not needing to install excess hardware. Software, too, can be adapted to the needs of the specific site. Most current distributed DBMS software will accept data manipulation requests from any DBMS that uses SQL. Therefore, the DBMSs at each site can be different.
▪ Each site keeps that portion of the database that contains the data that it uses most frequently. As a result, network traffic is reduced because most queries stay on a site's LAN rather than having to use the organization's WAN.
▪ Distributed databases are more reliable than centralized systems. If the WAN goes down, each site can continue processing using its own portion of the database. Only those data manipulation operations that require data not on site will be delayed. If one site goes down, the other sites can continue to process using their local data.
Despite the advantages, there are reasons why distributed databases are not widely implemented:
▪ Although performance of queries involving locally stored data is enhanced, queries that require data from another site are relatively slow.
▪ Maintenance of the data dictionary (the catalog of the structure of the database) becomes an issue: Should there be a single data dictionary or a copy of it at each site? If the organization keeps a single data dictionary, then any changes made to it will be available to the entire database. However, each time a remote site needs to access the data dictionary, it must send a query over the WAN, increasing network traffic and slowing down performance. If a copy of the data dictionary is stored at each site, then changes to the data dictionary must be sent to each site. There is a significant chance that at times the copies of the data dictionary will become out of sync.
▪ Some of the data in the database will exist at more than one site. This introduces a number of problems in terms of ensuring that the duplicated copies remain consistent, some of which may be serious enough to prevent an organization from using a distributed architecture. (You will read more about this problem in Chapter 15.)
▪ Because data are traveling over network media not owned by the company (the WAN), security risks are increased.
The Web
The need for Web sites to interact with database data has introduced yet another alternative database architecture. The Web server that needs the data must query the database, accept the results, and format the result with HTML tags for transmission to the end user and display by the user's Web browser. Complicating the picture is the need to keep the database secure from Internet intruders.
Figure 1-5 provides an example of how a Web server affects the hardware on a network when the Web server must communicate with a database server. For most installations, the overriding concern is security. The Web server is isolated from the internal LAN, and a special firewall is placed between the Web server and the database server. The only traffic allowed through that firewall is traffic to the database server from the Web server and from the database server to the Web server.
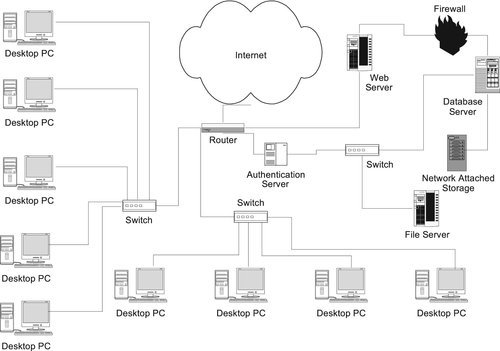 |
| ▪ Figure 1-5 |
Some organizations prefer to isolate an internal database server from a database server that interacts with a Web server. This usually means that there will be two database servers. The database server that interacts with the Web server is a copy of the internal database that is inaccessible from the internal LAN. Although more secure than the architecture in Figure 1-5, keeping two copies of the database means that those copies must be reconciled at regular intervals. The database server for Web use will become out of date as soon as changes are made to the internal database, and there is the chance that changes to the internal database will make portions of the Web-accessible database invalid or inaccurate. Retail organizations that need live, integrated inventory for both physical and Web sales cannot use the duplicated architecture. You will see an example of such an organization in Chapter 14.
Remote Access
Adding to whatever architecture we’ve chosen for our database hardware, we often have to accommodate remote users. Salespeople, agents in the field, telecommuters, executives on vacation—all may have the need to access a database that is usually available only over a LAN. Initially, remote access involved using a phone line and a modem to dial into the office network. Today, however, the Internet (usually with the help of a VPN—a virtual private network) provides cheaper and faster access, along with serious security concerns.
As you can see in Figure 1-6, the VPN creates a secure encrypted tunnel between the business's internal network and the remote user. 8 The remote user must also pass through an authentication server before being granted access to the internal LAN. Once authenticated, the remote user has the same access to the internal LAN—including the database server—as if he or she were present in the organization's offices.

Other Factors in the Database Environment
Choosing hardware and software to maintain a database and then designing and implementing the database itself was once enough to establish a database environment. Today, however, security concerns loom large, coupled with government regulations on the privacy of data. In addition, a new database is unlikely to be the first database in an organization that has been in business for a while; the new database may need to interact with an existing database that cannot be merged into the new database. In this section, we’ll briefly consider how those factors influence database planning.
Security
Before the Internet, database management was fairly simple in that we were rarely concerned about security. A user name and password were enough to secure access to a centralized database. The most significant security threats were internal—from employees who either corrupted data by accident or purposely exceeded their authorized access.
Most DBMSs provide some type of internal security mechanism. However, that layer of security is not enough today. Adding a database server to a network that has a full-time connection to the Internet means that database planning must also involve network design. Authentication servers, firewalls, and other security measures therefore need to be included in the plans for a database system.
There is little benefit to the need for added security. The planning time and additional hardware and software increase the cost of implementing the database. The cost of maintaining the database also increases as network traffic must be monitored far more than when we had classic centralized architectures. Unfortunately, there is no alternative. Data is the lifeblood of almost every modern organization, and it must be protected.
The cost of a database security breach can be devastating to a business. The loss of trade secrets, the release of confidential customer information—even if the unauthorized disclosure of data doesn't cause any problems, security breaches can be a public relations nightmare, causing customers to lose confidence in the organization and convincing them to take their business elsewhere.
Note: Because database security is so vitally important, Chapter 16 is devoted entirely to this topic.
Government Regulations and Privacy
Until the past 10 years or so, decisions about what data must be secured to maintain privacy has been left up to the organization storing the data. In the United States, however, that is no longer the case for many types of data. Government regulations determine who can access the data and what they may access. The following are some of the U.S. laws that may affect owners of databases.
▪ Health Insurance Portability and Accountability Act (HIPAA): HIPAA is intended to safeguard the privacy of medical records. It restricts the release of medical records to the patient alone (or the parent/guardian in the case of those under 18) or to those the patient has authorized in writing to retrieve records. It also requires the standardization of the formats of patient records so they can be transferred easily among insurance companies and the use of unique identifiers for patients. (The Social Security number may not be used.) Most importantly for database administrators, the law requires that security measures be in place to protect the privacy of medical records.
▪ Family Educational Rights and Privacy Act (FERPA): FERPA is designed to safeguard the privacy of educational records. Although the U.S. federal government has no direct authority over private schools, it does wield considerable power over funds that are allocated to schools. Therefore, FERPA denies federal funds to those schools that don't meet the requirements of the law. It states that parents have a right to view the records of children under 18 and that the records of older students (those 18 and over) cannot be released to anyone but the student without the written permission of the student. Schools therefore have the responsibility to ensure that student records are not disclosed to unauthorized people, increasing the need for secure information systems that store student information.
▪ Children's Online Privacy Protection Act: Provisions of this law govern which data can be requested from children (those under 13) and which of those data can be stored by a site operator. It applies to Web sites, “pen pal services,” e-mail, message boards, and chat rooms. In general, the law aims to restrict the soliciting and disclosure of any information that can be used to identify a child—beyond information required for interacting with the Web site—without approval of a parent or guardian. Covered information includes first and last name, any part of a home address, e-mail address, telephone number, Social Security number, or any combination of the preceding. If covered information is necessary for interaction with a Web site—for example, registering a user—the Web site must collect only the minimally required amount of information, ensure the security of that information, and not disclose it unless required to do so by law.
Legacy Databases
Many businesses keep their data “forever.” They never throw anything out, nor do they delete electronically stored data. For a business that has been using computing since the 1960s or 1970s, this typically means that old database applications are still in use. We refer to such databases that use pre-relational data models as legacy databases. The presence of legacy databases presents several challenges to an organization, depending on the need to access and integrate the older data.
If legacy data are needed primarily as an archive (either for occasional access or retention required by law), then a company may choose to leave the database and its applications as they stand. The challenge in this situation occurs when the hardware on which the DBMS and application programs run breaks down and cannot be repaired. The only alternative may be to recover as much of the data as possible and convert it to be compatible with newer software.
Businesses that need legacy data integrated with more recent data must answer the question “Should the data be converted for storage in the current database, or should intermediate software be used to move data between the old and the new as needed?” Because we are typically talking about large databases running on mainframes, neither solution is inexpensive.
The seemingly most logical alternative is to convert legacy data for storage in the current database. The data must be taken from the legacy database and reformatted for loading into the new database. An organization can hire one of a number of companies that specialize in data conversion, or it can perform the transfer itself. In both cases, a major component of the transfer process is a program that reads data from the legacy database, reformats them as necessary so that they match the requirements of the new database, and then loads them into the new database. Because the structure of legacy databases varies so much among organizations, the transfer program is usually custom-written for the business using it.
Just reading the procedure makes it seem fairly simple, but keep in mind that because legacy databases are old, they often contain “bad data” (data that are incorrect in some way). Once bad data get into a database, it is very difficult to get rid of them. Somehow, the problem data must be located and corrected. If there is a pattern to the bad data, that pattern must be identified to prevent any more bad data from getting into the database. The process of cleaning the data can therefore be the most time-consuming part of data conversion. Nonetheless, it is still far better to spend the time cleaning the data as they come out of the legacy database than attempting to find and correct the data once they get into the new database.
The bad data problem can be compounded by missing mandatory data. If the new database requires that data be present (for example, requiring a zip code for every order placed in the United States) and some of the legacy data are missing the required values, there must be some way to “fill in the blanks” and provide acceptable values. Supplying values for missing data can be handled by conversion software, but application programs that use the data must then be modified to identify and handle the instances of missing data.
Data migration projects also include the modification of application programs that ran solely using the legacy data. In particular, it is likely that the data manipulation language used by the legacy database is not the same as that used by the new database.
Some very large organizations have determined that it is not cost effective to convert data from a legacy database. Instead, they choose to use some type of middleware that moves data to and from the legacy database in real time as needed. An organization that has a widely used legacy database can usually find middleware. IBM markets software that translates and transfers data between IMS (the legacy product) and DB2 (the current, relational product). When such an application does not exist, it will need to be custom-written for the organization.
Note: One commonly used format for transferring data from one database to another is XML, which you will read more about in Chapter 18.
For Further Reading
Berson, Alex, Client/Server Architecture. 2nd ed (1996) McGraw-Hill.
Chong, Raul F.; Wang, Xiamei; Dang, Michael; Snow, Dwaine R., Understanding DB2: Learning Visually with Examples. 2nd ed (2008) IBM Press.
Erl, Thomas, SOA Principles of Service Design. (2007) Prentice Hall.
Feller, Jesse, FileMaker Pro 10 in Depth. (2009) Que.
Greenwald, Rick; Stackowiak, Robert; Stern, Jonathan, Oracle Essentials: Oracle Database 11g. (2007) O’Reilly Media.
Kofler, Michael, The Definitive Guide to MySQL 5. 3rd ed (2005) Apress.
McDonald, Matthew, Access 2007: The Missing Manual. (2006) Pogue Press.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.