
When I deployed GroupCal, the servlet-based group calendar discussed in Chapter 10, most people liked it. But BYTE’s editor-in-chief complained that it didn’t work on airplanes, where he spent a lot of his time. Like all web-based software, GroupCal assumes that its display engine—that is, the browser—connects over a network to an HTTP server.
How hard could it be, I wondered, to run the servlet locally on a disconnected client? Not very hard at all, I found. That discovery prompted me to write a contact manager based on a tiny web server written in Perl. These experiments showed me that web-based groupware—such as a calendar or a contact manager—needn’t depend on a network connection to a conventional HTTP server. Such applications, written in Java, Perl, or any other productive, socket-capable language, can also rely on lightweight, local HTTP servers implemented in these same languages. My two prototypes, one in Java and one in Perl, exhibited the following characteristics:
- Small footprint
Both weighed in at under a megabyte, so they could be delivered on a single floppy or by way of a reasonable download. That megabyte included the local web server, the application logic, and the data.
- Good performance
Both ran acceptably under Windows 95 on my aging 486-50, 16MB notebook PC.
- Simple configuration
Both could be installed by just unzipping the contents of a floppy, or equivalent download, into a single directory. One required a single environment variable, the other a single registry entry. That was it.
- Simple removal
In both cases, you could just nuke the directory. Remember when that used to work? It still can.
- Local/remote transparency
Both ran identically when connected to the Internet and talking to a remote HTTP server, or when disconnected and talking to the local server.
- Browser orientation
Both exploited the fact that the universal HTML/JavaScript client that’s already on every PC can frontend a vast number of useful applications, most as yet unwritten.
The principle at work here, best articulated in The Essential Distributed Objects Survival Guide, by Bob Orfali, Dan Harkey, and Jeri Edwards, is that the client/server architecture of today’s Web will inevitably evolve into a peer-to-peer architecture. Many of the nodes of the “intergalactic” network they envision will be able to function as both client and server. I always bought into this vision but didn’t see a practical way to apply it. Part of the answer, I think, is that servers needn’t be the complex beasts we usually make them out to be. They can in fact be much simpler than the behemoth client applications we routinely inflict on ourselves. In that simplicity lies great power.
I started with
tinyhttpd.pl, a classic Perl gem that implements
a simple web server in about 100 lines of code. I threw away the
file-serving and CGI-execution parts, leaving just a simple socket
server that could accept calls on port 80 and extract data sent using
the GET or POST methods. In
normal Perl CGI, a URL like:
/sfa_home?cmp_name=Netscape
causes the web server to launch the Perl interpreter against the
script named sfa_home, which script in turn
receives the data:
cmp_name=Netscape
by one of several means.
High-performance variants such as mod_ perl and
ISAPI Perl keep the Perl interpreter in memory. The same high
performance arises when Perl itself implements the web server. This
model doesn’t make sense for heavily trafficked public sites.
But it makes a great deal of sense for a local web server (or a
lightly loaded intranet server). In my Perl-based local web server,
called
dhttp
(for “distributed HTTP”),
the script name in a CGI-style URL becomes a function name with
arguments. For example, the server converts:
/sfa_home?cmp_name=Netscape
into the Perl function call:
&do_sfa_home('cmp_name=Netscape')Since the HTTP server is always running, there’s no process-creation or interpreter-spawning overhead; the URL frictionlessly becomes a scripted function call. You can see this same principle at work in Zope (http://www.zope.org/), a popular Web application server that is both written in Python and extensible using Python.
Here are the key things that these frictionless function calls can do in the Win32 desktop environment:
Dynamically generate HTML pages and forms
Interpolate values into those generated pages and forms
Access local (or remote) filesystem, SQL, and OLE resources
Issue HTTP redirections
These Perl capabilities, combined with some conventions for using HTML and JavaScript, yielded an application called SFA (which stands for “sales force automation”), shown in Figure 15.1
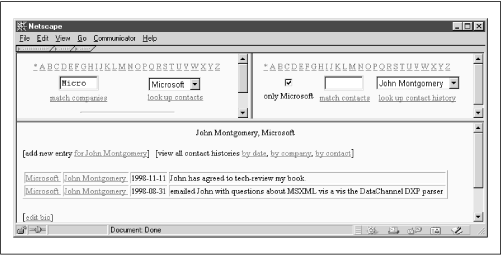
I don’t pretend you’ll want to dump Act in order to use this web-style contact manager. But it does exhibit the following interesting features:
- Namespace completion
Type
Min the match companies field and you’ll regenerate that pane with a list containing just the companies whose names begin with M. This feature relies on the local server’s ability to regenerate a form, using partial input in the match companies field to drive an SQL query that builds an HTML<select>statement.- Event bubbling
When you look up a company, the contacts picklist adjusts dynamically to display only contacts at the selected company. Then the contact info pane adjusts dynamically to display records for the first name in the contacts picklist. This feature relies on the JavaScript
onLoadevent. When the company pane loads, itsonLoadhandler specifies the URL that loads the contacts pane; likewise, the contacts pane controls the loading of the contact info pane.- Flexible bindings
By default the contacts pane binds to what’s selected in the company pane and displays an appropriately labeled checkbox. But if you uncheck that box, then type
Jin the match contacts field, and click that link, you’ll generate a list of all the J contacts at all companies. This feature relies on a combination of dynamically generated HTML (used to vary the widgets that appear on the form) and dynamically generated JavaScript (used to vary the handlers for those widgets).- Context-sensitive forms
When you select a company for which contacts exist, the contacts pane lists them. If none exist, the contacts pane invites you to enter a contact. Likewise, when you click match companies and your input selects one or more companies, the company pane lists them. If none match, the company pane invites you to enter a new company. And it prefills the name field with your attempted match. This feature also relies on a combination of dynamically generated HTML and JavaScript.
We expect these kinds of search, navigation, and data-entry idioms from applications written in FoxPro or Access. We don’t expect them from web-style applications that play to pure web clients. Should we? Does it make any sense to position the combination of an HTML/JavaScript browser, ODBC/JET, and a local-web-server-cum-script-engine as an application platform?
A number of factors weigh in favor of this approach. Perl is vastly more capable than the FoxPro or Access dialects typically used to script this kind of application. The resulting application is small and fast. It relies on an existing and familiar client. And it exhibits complete local/remote transparency.
There are also drawbacks. Browsers don’t yet offer strong
standardized support for data-entry idioms such as accelerator keys
and custom field-tabbing. JavaScript implementations can be flaky.
The methodology, an intricate tapestry of signals, substitutions, and
redirections involving Perl, SQL, HTML, and JavaScript, is complex.
However, these techniques aren’t exclusive to
dhttp. They’re also useful with a
conventional web server running Apache and mod_
perl, or IIS and ActivePerl. As we explore how
dhttp works, keep in mind that the techniques also
apply more generally to the construction of web-based software.
Developing for a local web server is basically the same as developing
for a conventional web server. This approach relies on, and extends,
familiar skills.
I’ve implemented dhttp in Perl, but the system is small enough and simple enough at this point so that it could easily be redone in Python or another versatile and socket-aware scripting language. What matters is not the language itself but the strategic position in which a dhttp system situates that language. From the perspective of a single dhttp node implemented on a standard Windows PC, the script language can transmute local file, SQL, and OLE resources into applications that play to local or remote web clients. In a dhttp network the script language is even more radically empowered. Replication of SQL data among the nodes of the network turns out to be a relatively easy problem to solve. Likewise replication of code. When I accomplished both of these things in the same day, I had to stop and take more than a few deep breaths. Could a system so simple really be this powerful? Perhaps so. But let’s first consider how a dhttp application works in standalone mode.
Figure 15.2 shows a high-level view of the dhttp architecture.
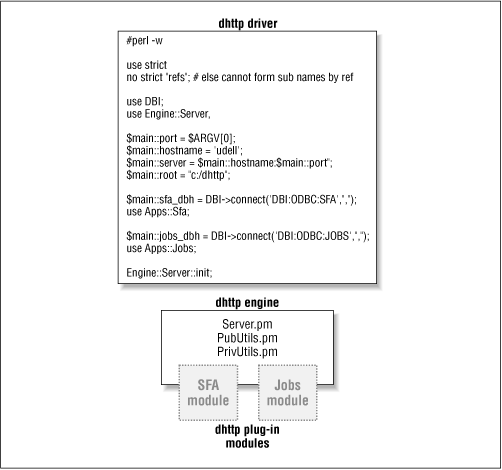
The engine divides into three modules—the server itself, a set
of public utilities, and a set of private utilities. A public
utility, in this context, is one that a web client can call by means
of a URL. A private utility, on the other hand, is visible only to
local dhttp components—either the server
itself or any of its plug-in apps. An example of a public server
utility is do_engine_serve_ file( ). It responds
to the URL:
/engine_serve_file?app=hd&file=home.htm
by dishing out the file home.htm from the
dhttp/lib/Apps/hd subdirectory. The prefix
“engine_” tells the server to form a reference to the
function Engine::PubUtils:: do_engine_serve_ file(
) and then call that function.
An example of a private engine function is upload_ file(
). It handles the HTTP file upload protocol—that is,
it can parse data posted from a web form that uses the
multipart/formdata encoding and return a list of parts. I wrote
upload_ file( ) for one particular
dhttp plug-in but placed it in the package
Engine::PrivUtils so that other plug-ins could use
it too.
An instance of dhttp hosts one or more plug-in apps, each implemented as a Perl module with its own namespace separate from other apps and from the server. Like the server, each app comprises public (that is, URL-accessible) as well as private functions. But in the case of an app, both kinds of functions are packaged into a single module. How does the engine tell them apart? The prefix “do_” signals that a function is public.
Example 15.1
shows the
serve_request routine at the core of
server.pm. Running inside a loop that accepts
inbound socket connections, it demonstrates two key points. HTTP
service stripped to its essentials is a very simple thing. And
it’s equally simple to connect URLs directly to functions
exported by script-language modules.
Example 15-1. The serve_request Method
sub serve_request
{
$_=<NS>; # read first line
my ($method, $url, $proto) = split; # GET /sfa_home HTTP/1.0
my ($args,$headers,$signal,$app,$fn);
while (<NS>) # read the headers
{
s/
|
//g; # trim cr and nl chars
/^Content-Length: (S*)/i &&($main::$content_length=$1); # save Content-Length
/^Content-Type: (S*)/i && ($main::$content_type=$1); # and Content-Type
/boundary=(.+)/ && ($main::http_upload_boundary='--'.$1); # and upload boundary
length || last; # empty line means end of header
}
if ( $method eq 'GET' ) # GET method
{
if ($url =~ s /^([^?]*)?//) # args follow the ?
{ $signal = $1; $args = $url; }
else # no args
{ $signal = $url; $args = ''; }
}
else # POST method
{
$signal = $url;
read(NS,$args,$content_length);
}
$signal =~ s#/##; # remove initial /
$signal =~ m#([^_]+)#; # isolate service name
$app = $1;
if ($app eq 'engine')
{ $fn = 'Engine::PubUtils::do_' . $signal; }
else
{ $fn = 'Apps::' . $app . '::do_' . $signal; }
if (defined &{$fn})
{ &{$fn}($args); } # dispatch the function
else
{ warn "(engine) undefined function $fn"; }
}To write the classic
“Hello, world” application in dhttp,
you’d create the file
/dhttp/lib/Apps/hello.pm with the following:
package Apps::hello;
use Engine::PrivUtils;
sub do_hello_world
{
transmit httpStandardHeader;
transmit "Hello, world";
}Then in dhttp/dhttp, the main driver, add the
line:
use Apps::hello;
Now the server will respond to the URL /hello_world by calling the function
Apps::hello::do_hello_world( ). Alternately you
could create the /dhttp/lib/Apps/hello
subdirectory and place a hello.html file in it.
In this case, dhttp will serve the file in
response to the URL /engine_serve_file?app=hello&file=hello.html.
So where’s the beef? A conventional server would just respond to the URL /hello.html. Why the extra gymnastics to serve a file with dhttp? The answer is that while it’s possible to make dhttp serve static files in the same way that normal web servers do, that’s the least interesting of its capabilities. Dynamic pages are dhttp’s forte. When you instantiate HTML/JavaScript templates and interpolate database extracts into those templates, you can achieve remarkable effects.
Conventional web servers, as installed, leave you far short of the
starting gate—at least as far as Perl-based web development is
concerned. Sure, they tell you how to map Perl to the
cgi-bin directory, but that’s just the
first step. What about low-latency script invocation? It’s up
to you to acquire and integrate the necessary stuff—either
ISAPI Perl on Win32 or mod_ perl on Unix. What
about low-latency database connections? Again it’s up to you to
piece together a solution. On Win32, this might involve ODBC
connection pooling in conjunction with ASP/PerlScript or
alternatively ActiveState’s PerlEx. On Unix, you’ll need
to figure out Apache::DBI.
Only some of the web developers who deploy Perl-based CGI are in a position to exploit low-latency script invocation. Of that subset, still fewer are able to exploit low-latency database connections. With dhttp you start with a Perl environment that already solves these two key problems. So while dhttp is indeed small and simple and fast, I don’t consider it minimal. It includes the essential ingredients that I always need to add to conventional Unix or NT web servers in order to prepare them to do useful work in Perl.
Every developer who uses Perl on a web server should be using it to
maximum advantage. For high-intensity applications,
dhttp doesn’t pretend to be a solution. In
these cases, you need to create a persistent and database-aware Perl
environment—using mod_ perl or PerlEx. The
effort invested to learn how these environments work will be repaid
many times over. Where dhttp shines is with
low-intensity applications. Scads of these could exist, and many more
would if the activation threshold for creating them were lower.
Scalability isn’t the issue in many cases; availability is.
Given the right environment, it’s easy to spin out lots of
useful, lightweight web applications.
A dhttp plug-in can create one or more persistent
connections to a SQL database. The example in Figure 15.2 uses Perl’s universal database
connector, DBI, along with the
DBD::ODBC module that maps between
DBI calls and ODBC data sources. Because
dhttp is a single-threaded system, it’s OK
to use the Jet (MS-Access-style) ODBC driver to work with local
.MDB files, although you can use any data source
that comes with an ODBC driver. The advantage of the
DBI and DBD::ODBC approach is
that it’s fully portable. If you run dhttp
on a Unix system, you can replace DBD::ODBC with,
for example, DBD::Solid or
DBD::Oracle.
An alternate method I’ve used with dhttp relies on a Windows-specific Perl module, Win32::ODBC. Why sacrifice DBI’s portability? The target for dhttp isn’t conventional server machines but rather the huge population of Windows-based desktop systems. Nowadays, these systems are often overpowered and underutilized. Windows 98 and MS Office can’t soak up all the cycles on a 500MHz Pentium-based box. If you want to recruit these machines as nodes of a distributed network, portability between Unix and Win32 may matter less than convenient installation in the Windows environment. In that respect, the Win32::ODBC approach is attractive. Its ODBC support runs deeper and wider than does that of DBD::ODBC. For example, you can use Win32::ODBC to conjure up a data source that hasn’t been defined using the ODBC Driver Manager, like this:
my $sfa_dbh = new ODBC("DBQ=$root/sfa.mdb;Driver={Microsoft Access Driver (*.mdb)};");The DBD::ODBC method expects that the file
sfa.mdb has been defined as an ODBC data source.
As such, dhttp apps that rely on that method
depend on registry entries. That in turn creates an extra
installation step and complicates deployment of
dhttp. The Win32::ODBC method,
which can create a data source on the fly, helps minimize the
installation footprint. Ideally you want zero impact on the client
machine; that’s the beauty of the web software model.
That’s not possible when you install client components, as
dhttp does, but it’s wise to make those
parts as unobtrusive and dependency-free as you can.
If you go the Win32::ODBC route, must you give up portability? Nope. It stands to reason that two different Perl ODBC modules will share a lot in common. Abstracting the differences between DBD::ODBC and Win32::ODBC, for the basic set of SQL functions needed by dhttp apps, is quite easy. The following is a Win32:: ODBC version of a function that runs an SQL query and returns the result set as a Perl list-of-lists.
sub dbSqlReturnAllRows # Win32::ODBC version
{
my ($dbh,$st) = @_; # input: db handle, and sql statement
my (@results);
$dbh->sql($st);
while ($dbh->FetchRow())
{
my (@row) = $dbh->Data($dbh->fieldnames);
push (@results, @row);
}
return @results;
}And here’s a DBD::ODBC version of the same routine:
sub dbSqlReturnAllRows # DBD::ODBC version
{
my ($dbh,$st) = @_; # input: db handle, and sql statement
my $sth = $dbh->prepare($st) or die ("prepare, $DBI::errstr");
$sth->execute or die ("returnAllRows, $DBI::errstr");
my (@row, @results);
while (@row = $sth->fetchrow)
{
my @data = @row;
push(@results, @data);
}
$sth->finish;
return @results;
}The dhttp apps I’ve written so far all work in terms of this abstraction layer, so they’re portable between DBI (which is now available on both Win32 and Unix) and Win32::ODBC (which is available only on Windows).
There are a variety of ways that web-server-based scripting languages
can cache database connections. Examples include Apache’s
mod_ perl with Apache::DBI,
IIS with Active Server Pages and any ActiveX script language, and
ActiveState’s mod_ perl work-alike,
PerlEx. In the dhttp system, this notion of a
persistent database handle reduces to its bare essentials: a variable
in the namespace of the main dhttp driver.
That variable, for example, $sfa_dbh in Figure 15.2, is set once when the engine loads the plug-in
app. Thereafter, methods that make database calls pass this handle to
the public engine methods that talk to the database.
How much time does it save to cache the handle? Here’s a do-nothing dhttp method:
sub do_sfa_nothing
{ print httpStandardHeader; }On my machine, a test script can invoke that method in a tight loop at the rate of about 33 calls per second. That’s pretty quick, by the way. IIS configured to spawn Perl once per call can do only 10 calls per second. IIS with ISAPI Perl—which eliminates the process-creation cost of spawning Perl—still yields only 22 calls per second. A do-nothing ASP PerlScript function does slightly better at 26 calls per second, but still short of the 33 calls per second I get with dhttp.
Now let’s connect to a DBD::ODBC data source, then disconnect from it:
sub do_sfa_connect_disconnect
{
my $dbh = DBI->connect("DBI:ODBC:sfa",'','')
or die ("connect, $DBI::errstr");
$dbh->disconnect;
print httpStandardHeader;
}A test script can only run this method about half as fast as the do-nothing method: at about 17 calls per second. Because they cache database handles at start-up, dhttp modules pay the connection penalty once only, at start-up. Now in reality, web applications don’t sit in tight loops making database calls, so caching the database handle isn’t really going to double perceived performance. But there’s no point in repeatedly creating and destroying a resource that need only be created once.
Idioms that we take for granted in conventional client/server database apps—such as data-bound widgets—aren’t often found in pure web-style apps. True, you can create these effects with Java applets, ActiveX controls, or DHTML scripts, but these techniques tend to compromise either speed or cross-browser compatibility. A system that exploits a powerful scripting language like Perl can express quite rich behavior in terms of the standard HTML/JavaScript client.
Consider the picklist in the company pane in Figure 15.1 (top left). Here’s a fragment of the form template that governs the picklist:
<td>
<input name=cmp_complete size=6 value="CMP_COMPLETE"
onChange="javascript:sfa_company_complete()">
</td>
<td>
<select name=cmp_name onChange="javascript:sfa_company_continue()">
COMPANY_LIST
</select>
</td>
<FONT_SPEC>LIST_TRUNCATEDWhen you send dhttp the URL /sfa_company?cmp_name=M, it decomposes the
URL into a function call:
do_sfa_company("cmp_name=M"). The function reads a
form template containing the previous fragment and sends back a
transformed version of it. One of the transformations replaces the
marker COMPANY_LIST with a set of
<OPTION> attributes that complete the
<SELECT> tag in the form template. In this
case, the completion string assigned to the variable
$cmp_name is M, so the list will display just the
companies whose names match that prefix. Here’s how
do_sfa_company( ) transforms the
COMPANY_LIST marker:
if ( m#COMPANY_LIST# )
{
my $prepared_cmp_name = prepareForDb($cmp_name);
$st = sprintf("select cmp_name from cmp where cmp_name like '%s'
order by cmp_name", $prepared_cmp_name . '%'),
($truncated,$picklist) = getPicklist($st,$cmp_name);
$form .= $picklist;
next;
}
if ( m#LIST_TRUNCATED# )
{
if ($truncated)
{ s/LIST_TRUNCATED/<br>(list truncated at
$picklist_limit,<br>try narrower selection)/; }
else
{ s/LIST_TRUNCATED//; }
next;
}And here’s the getPicklist( ) routine that
maps between the SQL statement and the corresponding set of HTML
<OPTION> tags:
sub getPicklist
{
my ($st,$selected) = @_;
my ($lref) = dbSqlReturnAllRows($sfa_dbh,$st); # process query into LoL
my ($rowref, $result);
my $count = 0;
foreach $rowref (@$lref)
{
last if ( $count++ > $picklist_limit );
my $key = $$rowref[0];
$result .= "<option value="$key""; # begin HTML fragment
if ($selected eq $key) # if current selection
{ $result .= " selected"; } # make it selected
$result .= ">$key</option>
";
}
my @ret = ( ($count > $picklist_limit), $result);
return @ret;
}If you call sfa_do_company( ) method without
arguments (i.e., using the bare URL /sfa_company), it dumps the whole
company-name column into the picklist—unless there are more
than specified in the package variable
$picklist_limit. A picklist with hundreds of
entries isn’t very useful, so if the list exceeds the limit,
getPicklist( ) truncates it and reports that it
did so. do_sfa_company( ), as it processes the
form template, can do two things with the
LIST_TRUNCATED marker. If the list is
within the limit, it removes the marker. If the list exceeds the
limit, it replaces the marker with a message that invites the user to
specify a narrower selection.
There are two ways to narrow the
selection. Both involve namespace completion, a feature that’s
prized by users of the
Emacs
text editor. The idea is that you can
constrain the set of values within some namespace by supplying
partial input. In Emacs, there are several
namespaces subject to completion. When you’re looking for a
file, Emacs completes partial input against the
filesystem namespace. It displays a list of only those files or
directories that match what you type, and it refines that list as you
expand the partial input. You can also complete against the namespace
of Emacs commands. On the editor’s command
line, you can type a? to enumerate all the
commands that start with a and ab? to enumerate the shorter list of
commands that start with ab.
The Netscape and Microsoft 4.x browsers do a kind of namespace completion but not as effectively as Emacs does. If you’ve visited the URL /sfa_home, and the string /sf is unique within the list of recently viewed URLs, both will complete /sfa_home as soon as you type /sf. But what if you’ve also recently visited the URL /sfa_home?cmp_name=Microsoft? In that case, both browsers will still complete /sfa_home as soon as you type /sf. This behavior is subtly but crucially different from that of Emacs. In Emacs, the user explicitly asks for namespace completion, provides a completion string, and gets back a view of a namespace that’s restricted appropriately. The 4.x browsers don’t restrict the list of recently visited URLs according to the completion. If /sfa_home?cmp_name=Microsoft was the result you wanted, completion of /sfa_home is a false and useless result. You still have to drop down the list of recently visited URLs, and there it’s no easier to pick out /sfa_home?cmp_name=Microsoft than it would have been without any completion.
Happily this problem was corrected in MSIE 5.0. You can use the Tab key to complete partial input on the browser’s command line, and it does correctly narrow the list of recently visited URLs.
While we’re on the subject, there’s another kind of
completion that browsers don’t get quite right. Dropdown lists
driven by the HTML SELECT widget support
completion but only on the first letter of input. Although most
people don’t realize it, in a list of U.S. states you can type
M to jump directly to the entry for Maine.
Even fewer people realize that you can navigate within the M states
by continuing to type M—for example,
after the fourth M you’ve selected Michigan. Almost nobody
realizes that you ought to be able to select Michigan (but cannot) by
simply typing MI. Do that, and you’ll
instead land in Idaho.
Within the constraints of the standard
HTML/JavaScript client, do_sfa_company( ) tries
to accomplish two things: make completion work properly, and gently
introduce users to the idea of namespace completion. That’s why
there are two ways to do completion. The first uses a tabbed index
that can perform any first-letter completion with a single click.
Because do_sfa_company( ) is a template
processor, it’s surprisingly easy to create that widget. The
form template has a marker, TAB_INDEX.
Here’s the Perl fragment that converts it into a row of links
that do first-letter completion:
if ( m#TAB_INDEX# )
{
my ($tab);
$form .= "<a href="javascript:sfa_company_index('')">*</a> "; # wildcard
foreach $tab ('A'..'Z')
{ $form .= "<a href="javascript:sfa_company_index('$tab')">$tab</a> "; }
next;
}Each of the links invokes the JavaScript function,
sfa_company_index( ), which is part of the same
form template:
function sfa_company_index (tab)
{
cmp_name = tab;
url = getServer() + '/sfa_company?cmp_name=&cmp_name=' + escape(cmp_name);
parent.frames[0].location = url;
}Note that there needn’t be a form template at all;
do_sfa_company( ) could simply emit everything
on the fly. It’s handy, though, to express the template as a
separate file. That way it’s easier to prototype and test the
pages that will be emitted dynamically and to visualize the
relationship between the HTML text and the JavaScript code on those
pages.
The
sfa_company_index( ) JavaScript function does
three simple things:
Collects the user’s selected first letter
Forms a URL that incorporates that partial input
Recycles that URL back into the engine
In this case, the URL reinvokes the do_sfa_company(
) method but qualifies it with an argument that carries
the completion letter; for example, /sfa_home?cmp_name=M. This process can
iterate indefinitely; each click on the tabbed index regenerates the
picklist for the selected tab. What if the picklist’s limit is
50, and there are more than 50 M companies? The second completion
mechanism—the input box labeled match
companies—can now come into play. There you can type
Mi or Micro to restrict
the picklist to just the companies whose names match these prefixes.
Here’s the template fragment for the input box:
<input name=cmp_complete size=6 value="CMP_COMPLETE" onChange="javascript:sfa_company_complete()"> <br><a href="javascript:sfa_company_complete()">match companies</a>
There are two ways to invoke the JavaScript function
sfa_company_complete( ). It’s the handler
for the input box’s onChange event, so if a
user enters text and tabs to the next widget in the form, completion
will run. It’s also wired to the match
companies link. Why the redundancy? For the usual reasons.
There’s more than one way to do it; different mechanisms make
sense to different people; it’s easy to accommodate many
styles. The onChange event is a subtle and
effective way to invoke completion. If you’re already typing in
the input box, the Tab key is handier than the mouse. A user who
knows that the ? key invokes completion in Emacs
might quickly learn that the Tab key is its analog in a family of
dhttp apps. Of course, most users of browser-based
software aren’t hardwired for Emacs, and
many never even think of using the keyboard for anything besides data
entry. So while it’s nice to provide a keyboard shortcut for a
minority of expert users, you should never omit the prominent
clickable link that most people expect.
The form template includes a marker,
CMP_COMPLETE, which
do_sfa_company( ) replaces when it emits the
form. The two completion functions share the use of this marker by
way of the cmp_name argument that
each function embeds in the URL it creates and invokes. For
tabbed-index completion, loading the selected first letter into the
input box documents the new state of the picklist. It’s also a
bridge to the input-box method. It helps the user to discover that if
a value of M yields a list of M companies when
you click the match companies link, a value of
Mi will yield a shorter list of Mi companies.
For input-box completion, the partial string is
“sticky”—that is, it persists across regenerations
of the frame, so you can see the effects of growing or shrinking the
partial input.
What happens if you click (or type) Q, but
there are no Q companies yet in the database? The app interprets this
as a request to add the first Q company, and it replaces the company
pane with an input form. Here’s how do_sfa_company(
) handles that case:
if ( length($picklist) == 0 ) # No companies match completion
{ # Invite user to add one.
transmit httpRedirectHeader
("$server_name/sfa_ave_company?mode=add&cmp_name=$$argref{cmp_name}");
}
else # One or more companies match
{ # completion. Emit the form.
transmit httpStandardHeader;
transmit $form;
}The application displays in a three-pane frameset, as shown in Figure 15.1. When the top-left company pane produces an empty list, the HTTP redirection sent back to the browser applies to that pane, and the add-company form appears there. The contact or contact-history panes are unaffected as yet. If the the user adds a new company, these panes will synchronize with it by means of the event-bubbling mechanism we’ll discuss shortly. If the user decides not to add a new company, though, these panes continue to supply context regarding the most recently selected company and access to functions that add and view contacts and contact histories.
The general strategy here is to build a stateful and context-preserving display from a sequence of inherently stateless HTTP transactions. There are two complementary ways to create the URLs that drive an application and that preserve context across HTTP transaction boundaries. The template processor that emits each piece of the display is one intelligent URL manipulator. The JavaScript code that can be embedded in each piece of the display is another. When these two mechanisms work together, you can achieve really powerful effects.
The contacts pane works like the
company pane. There’s a tabbed index for first-letter
completion and an input box for completion of longer bits of partial
input. If either of these completion functions produces an empty list
of contacts, the add-contact form appears in the contacts pane. The
company-name widget in the add-contact form is an example of what I
mean by a polymorphic HTML widget. Suppose the initial state is as
shown in Figure 15.1. The partial input
Micro in the company pane has regenerated the
picklist to include just matching companies—in this case, the
single entry Microsoft. It also regenerated the contacts pane,
constraining its picklist to just Microsoft contacts. Because John
Montgomery is the selected contact, the contact-history pane displays
associated contact records. In this context, if Paul Maritz
isn’t yet in the database as a Microsoft contact, clicking
P or typing Paul replaces
the contacts pane with the add-contact form shown in Figure 15.3.
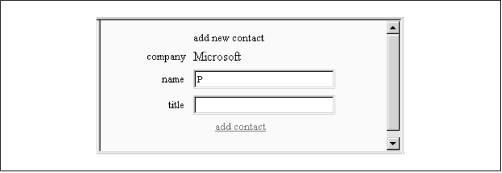
The only Microsoft checkbox shown in Figure 15.1 constrains the list of contacts to those at Microsoft. So the company-name widget on the add-contact form need not, and should not, accept input. It should merely report the company name that will be included in the new contact record, and it does so by printing the name on the surface of the form.
You can release that constraint by unchecking the checkbox. Why would
you? You ought to be able to look up any contact directly, without
having to know—and select—that person’s company. If
the database lists Pauls who are contacts at other, non-Microsoft
companies, clicking P or typing
Paul won’t produce an add-contact form;
it will constrain the contacts picklist to those other Pauls and
synchronize the contact-history pane to the first of them.
Now suppose you want create a new contact record for Paul Jones and,
at the same time, create a new company record for this Paul’s
company, JonesWare. After releasing the company constraint, you can
invoke an add-contact form by typing Paul Jones. If there aren’t yet any Paul Joneses in the
database, that produces the form shown in Figure 15.4.

The contact name carries over from the previous form, but now the
company-name widget is an input box. In this case, the user wants to
create a company record for JonesWare—but the user might also
want to look up an existing company other than the one to which the
contacts pane was originally constrained. To support that lookup,
completion works here too. Suppose JonesWare already exists in the
company table. If you type partial input into the company-name field,
perhaps Jo, and then tab to the next field,
the add-contact form regenerates with a picklist of Jo companies, as
shown in Figure 15.5.

In this case, the company-name widget has morphed into a picklist that helps the user distinguish between JonesWare and Jones Inc.
What if JonesWare weren’t yet in the database? In that case, the user can create a new company record for JonesWare and a new contact record for Paul Jones in a single go, by typing both names into the form shown in Figure 15.4. That’s a lot to do all at once, so to give the user a chance to confirm the creation of both records, the form morphs into yet another state. As shown in Figure 15.6, the link’s label documents that two operations will occur at once.

So how can a dumb HTML form widget polymorphically adapt itself,
depending on context, to appear as a label, an input box, or a
picklist? This effect requires collaboration between server-side and
client-side code. We already know, in general, how the server-side
part works. If the form template contains the marker
COMPANY_WIDGET, the method that handles
the add-contact form—do_sfa_add_contact(
)—can replace that marker with just text or with
HTML fragments that specify either an input box or a picklist. A
signal encoded in a URL and passed to the method as an argument will
supply the contextual clue that governs which flavor of widget to
emit.
From the perspective of the JavaScript code in the emitted form, though, there’s a problem. The JavaScript function wired to the add contact link needs to collect input, weave it into a URL, and send that URL back into the engine. In particular, it needs to get hold of the company name. But since the company-name widget is polymorphic, its value may reside in one of three different JavaScript objects. Table 15.1 lays out the different ways that these objects can extract the value.
Table 15-1. Modes of JavaScript Access to a Polymorphic HTML Widget
|
Widget Type |
Widget Name |
Value Accessor |
|---|---|---|
|
|
| |
|
input box |
|
|
|
picklist |
|
|
How
can the JavaScript function select among these access modes when it
builds the URL that it sends back into the engine? It needs a hint
from the server-side method that emitted the form. Example 15.2 shows the relevant piece of
do_sfa_add_contact( ).
Example 15-2. Server-Side Setup for Polymorphic HTML Widget
if ( m#CMP_WIDGET# ) # emit company-name widget
{
# case 1
if ($con_restrict eq 'on') # widget constrained to
{ # selected company
$form .= "<input type=hidden name=mode # tell JavaScript
value=plain>"; # the mode is "plain"
$form .= "<input type=hidden name=cmp_label # pass label in hidden field
value="$cmp_name">";
$form .= "$cmp_name"; # emit label
}
# case 2
if ( ($con_restrict ne 'on') and # widget not constrained to company
($cmp_name eq '' ) ) # no partial input supplied
{
$form .= "<input type=hidden name=mode # tell JavaScript the mode
value=input>"; # is "input"
$form .= "<input name=cmp_name # emit input box
onChange=sfa_add_contact_continue()>";
}
# case 3: name completion
if ( ($con_restrict ne 'on') and # widget not constrained to company
($cmp_name ne '' ) and # partial input supplied
($cmp_create ne 'on') ) # don't create a new company record
{
$form .= "<input type=hidden name=mode # tell JavaScript the mode is
value=picklist>"; # "picklist"
my $prepared_cmp_name = prepareForDb($cmp_name); # SQL-escape the supplied
# completion value
# construct query
$st = sprintf("select cmp_name from cmp where
cmp_name like '%s' order by cmp_name",
$prepared_cmp_name . '%'),
($truncated,$picklist) = getPicklist($st,'none'), # build the completion list
$form .= "<select name=cmp_name>"; # emit the picklist
$form .= $picklist;
$form .= "</select>";
}
# case 4
if ($cmp_create eq 'on') # do create a new company record
{
$form .= "<input type=hidden name=mode # tell JavaScript the mode is
value=create>"; # "create"
$form .= "<input type=hidden name=cmp_name # pass the value
value=$cmp_name>";
$form .= "$cmp_name"; # emit the value as a label
}
}
The
template processor emits, along with each variant of the polymorphic
widget, a signal in the hidden field mode that
tells the client-side code which variant it has received. Now the
client code can select the appropriate syntax to access the
widget’s value, as shown in Example 15.3.
Example 15-3. Client-Side Setup for Polymorphic HTML Widget
function sfa_add_contact_continue ()
{
mode = document.sfa_add_contact.mode.value; // identify the mode
cmp_create = '';
if (mode == 'plain') // company was a constrained value
{ // name was passed in hidden variable
cmp_name = document.sfa_add_contact.cmp_label.value;
}
if (mode == 'input') // company unrestricted
{
cmp_name =
document.sfa_add_contact.cmp_name.value; // name is in the input box
}
if (mode == 'picklist') // company-name completion
{ // value is selected item in list
cmp_name = document.sfa_add_contact.cmp_name.options
[document.sfa_add_contact.cmp_name.options.selectedIndex].text;
}
if (mode == 'create') // company record creation
{
cmp_create = 'on'; // tell the handler to create
cmp_name = // the company
document.sfa_add_contact.cmp_name.value; // name is in the input box
}
con_name = document.sfa_add_contact.con_name.value;
con_title = document.sfa_add_contact.con_title.value;
url = getServer() + '/sfa_handle_add_contact?cmp_name=' +
escape(cmp_name) + '&cmp_create=' + escape(cmp_create) +
'&con_name=' + escape(con_name) + '&con_select=' +
escape(con_name) + '&con_title=' + escape(con_title);
parent.frames[1].location = url;
}Is this technique really practical? I’ll admit that a complex scenario like this one is challenging to create and maintain. In theory you could specify these kinds of idioms more abstractly and write a code generator that would emit a combination of Perl, HTML, JavaScript, and SQL. In practice I’ve only done that in limited ways and haven’t yet come up with a general solution. Still, it’s instructive to see just how much UI richness can be achieved using only the standard basic building blocks of web software.
As always, the trick is to find the sweet spot that’s one step
short of the point of diminishing returns. Back in Chapter 6, for example, we saw (in Figure 6.4) a form that a manager can use to generate
another form that assigns a project to an analyst. The generated form
contains database-driven fields: analyst,
vendor, product. For the
manager who generates that form, data-bound polymorphic widgets that
support namespace completion will be a boon. Because the widgets are
bound to database columns, each of the namespaces can be managed as a
controlled vocabulary. Because the namespaces support completion,
large lists can be segmented dynamically for convenient use in HTML
picklists.
Internet groupware, as an information-management discipline, means weaving different kinds of data—email, web pages, SQL tables—into a coherent pattern. Web applications that use data-bound widgets to manage controlled vocabularies are one of the means to that end. Note that none of the polymorphic-HTML techniques we’ve seen here are specific to dhttp. You can do the same things using Perl (or another scripting language) on a conventional web server, and in many cases that’s the right way to do it. But a lightweight local web server like dhttp can be an attractive option.
The assignment-form generator, after all, is a tiny little application that might be used by only one person—the manager who issues assignment forms. Administrative policy surrounding a departmental or corporate intranet server can impede the deployment and maintenance of these kinds of ad hoc apps. Access to the server can be an issue as well. If the manager travels a lot or works from home without inbound access to the intranet server, local use of the app and its data—even while offline—will be crucial. I don’t argue that this approach is a better way to do web software, only that it’s a different—and complementary—way to do it.
The
three-pane viewer is an idea as old as the hills, or at least, as old
as Smalltalk-80. Here we’re exploring how to build that kind of
viewer using standard web tools and methods. The key ingredients are
frames—a sometimes dubious feature of HTML that in this case, I
argue, is appropriate—and JavaScript handlers for
onLoad events. Let’s take it from the top,
when the plug-in receives the /sfa_home URL. Example 15.4
shows the do_sfa_home(
)
method.
Example 15-4. The do_sfa_home( ) Method
sub do_sfa_home
{
my ($args) = @_;
my ($argref) = getArgs($args);
my $cmp_name = escape(getArgval($$argref{cmp_name}));
my $con_name = escape(getArgval($$argref{con_name}));
my $server_name = makeServerName();
transmit <<"EOT";
HTTP/1.0 200 OK
Content-type: text/html
<frameset rows=40%,*>
<frameset cols=50%,*>
<frame src="$server_name/sfa_company?cmp_name=$cmp_name&con_name=$con_name">
<frame src="$server_name/engine_null_frame">
</frameset>
<frame src="$server_name/engine_null_frame">
</frameset>
EOT
}The arguments are optional. When other parts of the app pass
arguments to this method, it just hands them along to the
company-pane handler, which, in turn, hands them along to the
contacts-pane handler. The top-level method’s job is just to
establish the three-pane frameset and invoke the /sfa_company URL to paint the company pane.
Why doesn’t it invoke handlers for the contacts and
contact-history panes? Event bubbling takes care of that. The
top-level method only needs to clear those panes, which it does using
the public method engine_null_ frame( ), which
emits an empty HTML body.
When you call the bare URL /sfa_home, no completion string constrains
the company picklist displayed in the company pane. So the whole
company table (subject to the specified limit) appears in the
picklist. If Apple Computer is the first company in the list, then
it’s the currently selected item. The form template for the
company pane uses that selection, in its onLoad
handler, to sync the contacts pane accordingly. Example 15.5 shows the onLoad handler.
Example 15-5. JavaScript onLoad Handler for the Company Pane
function sfa_company_load ()
{
cmp_name = document.sfa_company.cmp_name.options
[document.sfa_company.cmp_name.options.selectedIndex].text;
con_name = document.sfa_company.con_name.value;
con_select = document.sfa_company.con_select.value;
url = getServer() + '/sfa_contacts?cmp_name=' + escape(cmp_name) +
'&con_name=' + escape(con_name) + '&con_restrict=on';
parent.frames[1].location = url;
}When this handler runs, the company-name variable picks up the value
Apple Computer and weaves it into the /sfa_contacts URL that it builds.
If Apple Computer contacts are already in the database, the contacts
pane repeats the process. The first item of the
picklist—let’s say, Steve Jobs—is the default selection. The
onLoad handler for the contacts pane extracts that
value, and weaves it into the /sfa_history URL that drives the
contact-history pane. The handler for that pane uses the value to
constrain the list of entries to just those for Steve Jobs.
What if no Apple Computer contacts were in the database yet? In that
case, the do_sfa_contacts( ) method in the
server-side code issues a redirection to the
do_sfa_add_contact( ) method. It replaces the
contacts pane with the form we saw in Figure 15.3
through Figure 15.6. The value Apple Computer, which was originally the default picklist
selection in the company pane, propagates through and becomes the
text of the company-name widget on that form, in its incarnation as a
read-only label.