
All programmers are playwrights and all computers are lousy actors. | ||
| --Anonymous | ||
The first six chapters have been devoted to EAI approaches and implementation. In the following chapters, we will concentrate on the technology that makes EAI possible: middleware. This chapter provides an overview of middleware, setting the stage for the next several chapters that will describe several types of middleware technologies that may assist us in solving the EAI problem.
The evolution of middleware has created the opportunity to orchestrate an enterprise through the conduit of middleware, making it the primary enabling technology that can make EAI work.[1]
Middleware is not a magic bullet. It provides, quite simply, a mechanism that allows one entity (application or database) to communicate with another entity or entities. The notion that a middleware product can be installed within an enterprise, and information can suddenly—magically—be shared, is simply not based on reality. Even with a good middleware product, there remains a lot of work to be done, including the effort already outlined in Chapters 1 through 6.
Middleware is just another tool, nothing more. So, why use it? The answer is simple: because it really is the best and only solution that allows applications to communicate with one another. Middleware is able to hide the complexities of the source and target systems, thereby freeing developers from focusing on low-level APIs and network protocols and allowing them to concentrate on sharing information. For example, the same middleware API may be used across many different types of application development products, as well as many different platforms. This use of a common API hides the complexities of both the entities being connected and the platforms they reside on. That's the idea behind middleware.
Middleware is the best hope for moving information between applications and databases. Unfortunately, traditional middleware as it exists today does very little to solve the classic EAI problem. Point-to-point middleware, such as remote procedure calls (RPCs) and message-oriented middleware (MOM), can provide connections between applications, but in order to facilitate the use of the middleware, changes to the source and target applications must be made. What's more, as we demonstrated in Chapter 1, creating many point-to-point connections between many source and target systems quickly becomes unmanageable and inflexible. Thus, new types of middleware have come into play, including application servers and message brokers; however, we are bound to have even better solutions as EAI technology progresses over time.
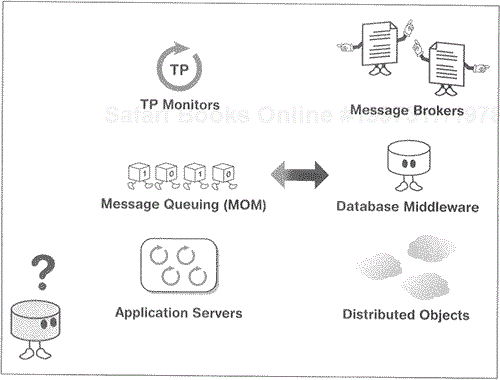
Although there are many definitions of middleware, middleware is basically any type of software that facilitates communications between two or more software systems. Granted, this is a broad definition, but it is certainly applicable as long as you bear in mind that middleware may be as simple as a raw communications pipe running between applications, such as Java's RMI (Remote Method Invocation) or as sophisticated as information-sharing and logic execution mechanisms, such as TP (Transaction Processing) monitors.
The evolution of middleware is bringing about a change in many of the identifying features that made categorizing middleware an easier task. As a result, placing middleware in categories is becoming ever more difficult. For example, many message queuing products now do publish and subscribe, provide transactional features, and host application logic. The challenge of categorizing such a product should be plainly evident.
Even so, several types of middleware solve particular types of problems. For the purposes of our EAI discussion, we will describe RPCs, MOM, distributed objects, database-oriented middleware, transactional middleware (including TP monitors and application servers), and message brokers (see Figure 7.1).
RPCs are the oldest type of middleware. They are also the easiest to understand and use. Basically, RPCs provide developers with the ability to invoke a function within one program and have that function actually execute within another program on another remote machine (see Figure 7.2). The fact that the function is actually being carried out on a remote computer is hidden. To the developer, the function is executing locally.
RPCs are synchronous (see the discussion of synchronous function in Synchronous versus Asynchronous later in this chapter). They stop the execution of the program in order to carry out a remote procedure call. Because of this, RPCs are known as blocking middleware. Because carrying out a remote procedure call requires so much "overhead," RPCs require more bandwidth than other types of middleware products.
RPCs have also become a commodity product. Most UNIX systems, for example, ship RPC development libraries and tools as part of the base operating system. While particular vendors, such as NobleNet, sell RPCs, the best known type of RPC is the Distributed Computing Environment (DCE) from the Open Software Foundation (OSF).
DCE provides a very sophisticated distributed RPC mechanism with many layers of services (such as security services, directory services, and the ability to maintain integrity between applications). Although DCE is a component of many other types of middleware products (such as COM and many application servers), it has been pretty much a failure due to the performance overhead of the product. In fact, most RPCs are not well-performing middleware products. Their advantage is their simplicity.
The major downside with RPCs is their requirement for a lot more processing power. In addition, many exchanges must take place across a network to carry out the request. As a result, they suck the life out of a network or a computer system. For example, a typical RPC call may require 24 distinct steps in completing the requests—that's in addition to several calls across the network. This kind of performance limits the advisability of making RPC calls across slower networks, such as the Internet.

RPCs require 10,000 to 15,000 instructions in order to process a remote request. That's several hundred times the cost of a local procedure call (a simple function call). As is the case with DCE, one of the most famous (or infamous) RPCs around, the RPC software also has to make requests to security services in order to control access to remote applications. There may be calls to naming services and translation services as well. All of this adds to the overhead of RPCs.
As we've noted, the advantages of RPCs are the sheer simplicity of the mechanism and the ease of programming. Again, these advantages must be weighed against RPCs' huge performance cost and their inability to scale well, unless combined with other middleware mechanisms, such as a TP monitor or message-queuing middleware.
Unfortunately, it is difficult to know when RPCs are in use because they are bundled into so many products and technologies. For example, CORBA-compliant distributed objects are simply another layer on top of an RPC. They thus rely on synchronous connections to communicate object to object (although they are now deploying messaging and transaction services as part of the standard). This additional layer translates to additional overhead when processing a request between two or more distributed objects. Ultimately, this is the reason why distributed objects, while architecturally elegant, typically don't scale or provide good performance. Given the benefits of RPCs, the Object Management Group (OMG), who is the consortium of vendors who created CORBA, and CORBA vendors are working to solve the performance problem.
MOM was created to address some shortcomings of RPCs through the use of messaging. Although any middleware product that uses messages can correctly be considered MOM, we've placed message brokers in their own category because they provide a different set of services than traditional MOM, and also because of their importance to the new world of EAI. Traditional MOM is typically queuing software, using messages as a mechanism to move information from point to point.
Because MOM uses the notion of messages to communicate between applications, direct coupling with the middleware mechanism and the application is not required. MOM products use an asynchronous paradigm. Decoupled from the application, they allow the application to function independently.
The asynchronous model allows the application to continue processing after making a middleware service request. The message is dispatched to a queue manager, which makes sure that the message is delivered to its final destination. Messages returning to the calling application are handled when the calling application finds the time (see Figure 7.3).
The asynchronous paradigm is much more convenient for developers and users because it does not block the application from processing, although the model is a bit more complex than the synchronous model. Moreover, MOM is able to ensure delivery of a message from one application to the next through several sophisticated mechanisms, such as message persistence.
The use of messages is an advantage as well. Because messages are little, byte-sized units of information that move between applications, developers find them easier to manage. Messages have a structure (a schema) and content (data). In a sense, they are little, one-record databases that move between applications through message-passing mechanisms.
While MOM is one of the newest players in the middleware world, it already possesses a mature technology with some performance and usability advantages over traditional RPCs. There are two models supported by MOM: point-to-point and message queuing (MQ)— the latter being our primary focus here.
MQ has several performance advantages over standard RPC. First, MQ lets each participating program proceed at its own pace without interruption from the middleware layer. Therefore, the calling program can post a message to a queue and then "get on with its life." If a response is required, it can get it from the queue later. Another benefit to MQ is that the program can broadcast the same message to many remote programs without waiting for the remote programs to be up and running.
Because the MQ software (e.g., IBM's MQSeries or Microsoft's MSMQ) manages the distribution of the message from one program to the next, the queue manager can take steps to optimize performance. Many performance enhancements come with these products, including prioritization, load balancing, and thread pooling.
There is little reason to be concerned that some messages may be lost during network or system failure. As mentioned previously, most MQ software lets the message be declared as persistent or stored to disk during a commit at certain intervals. This allows for recovery from such situations.
Distributed objects are also considered middleware because they facilitate interapplication communications. However, they are also mechanisms for application development (therein lies an example of the middleware paradox), providing enabling technology for enterprise-wide method sharing.
Distributed objects are really small application programs that use standard interfaces and protocols to communicate with one another (see Figure 7.4). For example, developers may create a CORBA-compliant distributed object that runs on a UNIX server and another CORBA-compliant distributed object that runs on an NT server. Because both objects are created using a standard (in this case, CORBA), and both objects use a standard communications protocol (in this case, Internet Inter-ORB Protocol—IIOP), then the objects should be able to exchange information and carry out application functions by invoking each other's methods.

Two types of distributed objects are on the market today: CORBA and COM. CORBA, created by the OMG in 1991, is really more of a standard than a technology. It provides specifications outlining the rules that developers should follow when creating a CORBA-compliant distributed object. CORBA is heterogeneous, with CORBA-compliant distributed objects available on most platforms.
COM is a distributed object standard promoted by Microsoft. Like CORBA, COM provides "the rules of the road" for developers when creating COM-enabled distributed objects. These rules include interface standards and communications protocols. While there are COM-enabled objects on non-Windows platforms, COM is really more native to the Windows operating environments and therefore more homogeneous in nature.
Database-oriented middleware is any middleware that facilitates communications with a database, whether from an application or between databases. Developers typically use database-oriented middleware as a mechanism to extract information from either local or remote databases. For example, to get information residing within an Oracle database, the developer may invoke database-oriented middleware to log onto the database, request information, and process the information that has been extracted from the database (see Figure 7.5).
Database-oriented middleware works with two basic database types: call-level interfaces (CLIs) and at-native database middleware.
While CLIs provide access to any number of databases through a well-defined common interface and are common APIs that span several types of database, they work most typically with relational databases. Such is the case with Microsoft's Open Database Connectivity (ODBC). ODBC exposes a single interface in order to facilitate access to a database and then uses drivers to allow for the differences between the databases. ODBC also provides simultaneous, multiple database access to the same interface—in the ODBC architecture, a driver manager can load and unload drivers to facilitate communications between the different databases (e.g., Oracle, Informix, and DB2).
Another example of a CLI is JavaSoft's JDBC. JDBC is an interface standard that uses a single set of Java methods to facilitate access to multiple databases. JDBC is very much like ODBC, providing access to any number of databases from most Java applets or servlets.
OLE DB from Microsoft is the future of Microsoft database middleware. OLE DB provides a standard mechanism to access any number of resources, including databases, as standard objects (e.g., COM objects, see Figure 7.6). OLE DB also provides access to resources other than databases, such as Excel spreadsheets and flat files. Again, this information is accessed as COM objects.
Native database middleware does not make use of a single, multidatabase API. Instead, it accesses the features and functions of a particular database, using only native mechanisms. The ability to communicate with only one type of database is the primary disadvantage of using native database middleware. The advantages of native database middleware include improved performance and access to all of the low features of a particular type of database.


Transactional middleware, such as TP monitors and application servers, do a pretty good job at coordinating information movement and method sharing between many different resources. However, while the transactional paradigm they employ provides an excellent mechanism for method sharing, it is not as effective when it comes to simple information sharing, the real goal of EAI. For instance, transactional middleware typically creates a tightly coupled EAI solution, where messaging solutions are more cohesive in nature. In addition, the source in target applications will have to be changed to take advantage of transactional middleware.
TP monitors are, in fact, first-generation application servers and a transactional middleware product. They provide a location for application logic in addition to a mechanism to facilitate the communications between two or more applications (see Figure 7.7). Examples of TP monitors include Tuxedo from BEA Systems, MTS from Microsoft, and CICS from IBM. These products have been around for some time now and are successfully processing billions of transaction a day.

TP monitors (and application servers for that matter) are based on the premise of a transaction. A transaction is a unit of work with a beginning and an end. The reasoning is that if application logic is encapsulated within a transaction, then the transaction either completes, or is rolled back completely. If the transaction has been updating remote resources, such as databases and queues, then they too will be rolled back if a problem occurs.
An advantage of using transactions is the ability to break an application into smaller portions and then invoke those transactions to carry out the bidding of the user or another connected system. Because transactions are small units of work, they are easy to manage and process within the TP monitor environment. By sharing the processing of these transactions among other, connected TP monitors, TP monitors provide enhanced scalability by relying on transactions. They can also perform scalability "tricks" such as thread and database connection pooling.
TP monitors provide connectors that allow them to connect to resources such as databases, other applications, and queues. These are typically low-level connectors that require some sophisticated application development in order to connect to these various resources. The resources are integrated into the transactions and leveraged as part of the transaction. As mentioned previously, they are also able to recover if a transaction fails.
TP monitors are unequaled when it comes to support for many clients and a high transaction-processing load. They perform such tricks as using queued input buffers to protect against peaks in the workload. If the load increases, the engine is able to press on without a loss in response time. TP monitors can also use priority scheduling to prioritize messages and support server threads, thus saving on the overhead of heavyweight processes. Finally, the load-balancing mechanisms of TP monitors guarantee that no single process takes on an excessive load.
When an application takes advantage of these features, it is able to provide performance as well as availability and scalability.
TP monitors provide queuing, routing, and messaging features, all of which enable distributed application developers to bypass the TP monitor's transactional features. As a result, priorities can be assigned to classes of messages, letting the higher priority messages receive server resources first.
TP monitors' real performance value is in their load-balancing feature, which allows them to respond gracefully to a barrage of transactions. A perfect example of this advantage is end-of-the-month processing. As demand increases, the transaction manager launches more server processes to handle the load and kills processes that are no longer required. In addition, the manager can spread the processing load among the processes as the transaction requests occur.
Application servers are really nothing new (certainly TP monitors should be considered application servers, and they share many common features). However, the fastest growing segment of the middleware marketplace is defined by the many new products calling themselves application servers. Most application servers are employed as Web-enabled middleware, processing transactions from Web-enabled applications. What's more, they employ modern languages such as Java, instead of traditional procedural languages such as C and COBOL (common with TP monitors).
Put simply, application servers are servers that not only provide for the sharing and processing of application logic, they also provide connections to back-end resources (see Figure 7.8). These resources include databases, ERP applications, and even traditional mainframe applications. Application servers also provide user interface development mechanisms. Additionally, they usually provide mechanisms to deploy the application to the platform of the Web. Examples of application servers include Netscape's Netscape Application Server (NAS) and Inprise's Application Server.
With vendors repositioning their application server products as a technology that solves EAI problems (some without the benefit of a technology that works), application servers, as well as TP monitors, will play a major role in the EAI domain. Many vendors are going so far as to incorporate features such as messaging, transformation, and intelligent routing, services currently native to message brokers. This area of middleware is one that will undergo something closer to a revolution than an evolution.
Message brokers represent the nirvana of EAI-enabled middleware, as you'll see in Chapter 18. At least, the potential of message brokers represents that nirvana. Message brokers can facilitate information movement between two or more resources (source or target applications) and can account for the differences in application semantics and platforms. As such, they are a perfect match for EAI. Message brokers can also join many applications using common rules and routing engines. They can transform the schema and content of the information as it flows between various applications and databases. However, they can't quite "do it all." Message brokers are not perfect … yet. Message brokers need to evolve some more before they are able to solve most of the problems in the EAI problem domain.

Message brokers, as we already discussed in the previous chapters, are servers that broker messages between two or more source or target applications. In addition to brokering messages, they transform message schemas and alter the content of the messages (see Figure 7.9). Message brokers are so important to EAI that we have dedicated Chapter 18 to a discussion of the technology.
The importance of message brokers is a function of their place within the enterprise. In general, message brokers are not an application development-enabling technology. Rather, they are a technology that allows many applications to communicate with one another and can do so without the applications actually understanding anything about the applications they are sharing information with. In short, they "broker" information.
It is useful to understand the general characteristics of each type of middleware in order to evaluate each technology and vendor. There are two types of middleware models: logical and physical.
The logical middleware model depicts how the information moves throughout the enterprise conceptually. In contrast, the physical middleware model depicts how the information actually moves and the technology it employs. This contrast is analogous to the logical and physical database designs presented in Chapter 6.
A discussion of the logical middleware model requires a discussion of one-to-one and many-to-many configurations, as well as synchronous versus asynchronous. An examination of the physical middleware model requires a discussion of several messaging models.
Middleware can work in a point-to-point, as well as many-to-many (including one-to-many) configurations. Each configuration has its advantages and disadvantages.
Point-to-point middleware is middleware that allows one application to link to one other application—application A links to application B by using a simple pipe. When application A desires to communicate with application B, they simply "shout down" the pipe using a procedure call or message (see Figure 7.10).

What limits point-to-point middleware compared to other types of middleware is its inability to properly bind together more than two applications. It also lacks any facility for middle-tier processing, such as the ability to house application logic or the ability to change messages as they flow over the pipe.
There are many examples of point-to-point middleware, including MOM products (such as MQSeries) and RPCs (such as DCE). The purpose of these products is to provide point-to-point solutions, primarily involving only a source and target application. Although it is now possible to link together more than two applications using traditional point-to-point middleware, doing so is generally not a good idea. Too many complexities are involved when dealing with more than two applications. In order to link together more than two applications using point-to-point middleware, it is almost always necessary to run point-to-point links between all of the applications involved (see Figure 7.11).

Because most EAI problem domains require linking many applications, this understanding of the general idea behind the point-to-point model should make it clear that point-to-point middleware does not represent an effective solution. Moreover, in order to share information in this scenario, applications have to be linked, and information has to be brokered through a shared, centralized server. In other words, sharing information requires a message broker or transactional middleware.
However, as with all things, there are both disadvantages and advantages. The great advantage of point-to-point middleware is its simplicity. Linking only one application to another frees the EAI architect and developer from dealing with the complexities of adapting to the differences between many source and target applications.
As its name implies, many-to-many middleware links many applications to many other applications. As such, it is the best fit for EAI. This is the trend in the middleware world. It is also the most powerful logical middleware model in that it provides both flexibility and applicability to the EAI problem domain.

There are many examples of many-to-many middleware, including message brokers, transactional middleware (application servers and TP monitors), and even distributed objects. Basically, any type of middleware that can deal with more than two source or target applications at a time is able to support this model (see Figure 7.12).
Just as the advantage to the point-to-point model is its simplicity, the disadvantage to the many-to-many model is the complexity of linking together so many systems. Although the current generation of middleware products are becoming better at handling many external resources, much work remains to be done. After all, struggling with this complexity falls primarily on the shoulders of the developer.
As noted previously, middleware employs two types of communication mechanisms: asynchronous and synchronous.
Asynchronous middleware is middleware that moves information between one or many applications in an asynchronous mode—that is, the middleware software is able to decouple itself from the source or target applications, and the applications are not dependent on the other connected applications for processing. The process that allows this to occur has the application(s) placing a message in a queue and then going about their business, waiting for the responses at some later time from the other application(s).

The primary advantage of the asynchronous model is that the middleware will not block the application for processing. Moreover, because the middleware is decoupled from the application, the application can always continue processing, regardless of the state of the other applications.
In contrast, synchronous middleware is tightly coupled to applications. In turn, the applications are dependent on the middleware to process one or more function calls at a remote application. As a result, the calling application must halt processing in order to wait for the remote application to respond. We refer to this middleware as a "blocking" type of middleware.
The disadvantage of the synchronous model rests with the coupling of the application to the middleware and the remote application. Because the application is dependent on the middleware, problems with middleware, such as network or remote server problems, stop the application from processing. In addition, synchronous middleware eats up bandwidth due to the fact that several calls must be made across the network in order to support a synchronous function call. This disadvantage and its implications make it clear that the asynchronous model is the better EAI solution.
Connection-oriented communications means that two parties connect, exchange messages, and then disconnect. Typically this is a synchronous process, but it can also be asynchronous. Connectionless communications means that the calling program does not enter into a connection with the target process. The receiving application simply acts on the request, responding if required.
In direct communications, the middleware layer accepts the message from the calling program and passes it directly to the remote program. While either direct or queued communications are used with synchronous processing, direct is usually synchronous in nature, and queued is usually asynchronous. Most RPC-enabled middleware uses the direct communications model.
Queued communications generally require a queue manager to place a message in a queue. The remote application then retrieves the message either shortly after it has been sent or at any time in the future (barring time-out restrictions). If the calling application requires a response (such as a verification message or data), the information flows back through the queuing mechanism. Most MOM products use queued communications.
The queuing communication model's advantage over direct communications rests with the fact that the remote program does not need to be active for the calling program to send a message to it. What's more, queuing communications middleware typically does not block either the calling or the remote programs from proceeding with processing.
Publish/subscribe (pub/sub) frees an application from the need to understand anything about the target application. All it has to do is send the information it desires to share to a destination contained within the pub/sub engine, or broker. The broker then redistributes the information to any interested applications. For example, if a financial application wishes to make all accounts receivable information available to other applications who want to see it, it would inform the pub/sub engine. The engine would then make it known that this information was available, and any application could subscribe to that topic in order to begin receiving accounts receivable information.
In this scenario, the publisher is the provider of the information. Publishers supply information about a topic, without needing to understand anything about the applications that are interested in the information (see Figure 7.13). The subscriber is the recipient, or consumer, of the information. The publisher specifies a topic when it publishes the information. The subscriber specifies a topic that it's interested in. As a result, the subscriber receives only the information it's interested in.

The request response model does exactly what its name implies. A request is made to an application using request response middleware, and it responds to the request. Examples of request and response middleware include any middleware that can facilitate a response from a request between applications, such as message brokers or application servers.
The fire and forget model allows the middleware user to "fire off" a message and then "forget" about it, without worrying about who receives it, or even if the message is ever received. This is another asynchronous approach. The purpose of fire and forget is to allow a source or target application to broadcast specific types of messages to multiple recipients, bypassing auditing and response features. It also allows central servers to fire off messages.
A primary advantage of conversational-mode middleware is its ability to host complex business logic in order to maintain state and negotiate transactions with the application. This middleware mode is particularly critical when integrating with transactional systems. Often the data elements required for brokering are deeply nested within subtransactions and can only be obtained by engaging in a "conversation" with the transactional system.
Ah, wouldn't life be wonderful if there were only one perfect middleware layer that provided all the features we need, coupled with unexcelled performance? Well, unfortunately, life may be wonderful, but it's almost never that easy. Before hooking your application to a middleware technology, you need to examine all the technologies and carefully weigh their advantages and disadvantages to your particular situation.
Although RPCs are slow, their blocking nature provides the best data integrity control. For example, while an asynchronous layer to access data may seem to be the best solution, there is no way to guarantee that an update occurs in a timely manner. It is not difficult to envision a scenario where an update to a customer database is sitting in a queue, waiting for the database to free up while a data entry clerk is creating a sales transaction using the older data. RPCs may be slow, but they would never allow this kind of situation to occur. When using RPCs, updates are always applied in the correct order. In other words, if data integrity is more important than performance, RPCs may still be the best bet.
MOM vendors contend that synchronous middleware cannot support today's event-driven applications. Programs just cannot wait for other programs to complete their work before proceeding. Yet RPCs could provide better performance than traditional store-and-forward messaging layers in some instances. Then again, messaging could provide better performance, because the queue manager offers sophisticated performance-enhancing features such as load balancing.
Middleware is something that's difficult to explain and use. Users typically never see middleware's plumbing, as they do with application development and database products. In the future, however, we are going to see more user interfaces and business layers included with middleware products, where once only application program interfaces existed. Such is the case with newer middleware technologies such as application servers and message brokers. The presence of easy-to-use interfaces will take the power of middleware—at one time the exclusive domain of the developer—and place it in the hands of the business user. Clearly this is where middleware is heading, and it is ultimately how we are going to solve the EAI problem.
[1] Middleware information is being discussed in the context of EAI and not as general-purpose technology.