
You can use all the quantitative data you can get, but you still have to distrust it and use your own intelligence and judgment. | ||
| --Alvin Toffler | ||
Most enterprises considering EAI look to data level EAI as their entry point, a decision that would allow moving data between data stores in order to share relevant business information among applications and, ultimately, stovepipes. An advantage of data level as an entry point for EAI is that a number of tools and techniques exist that allow the integration of information from database to database, adapting the information on the fly so it's represented correctly by the source and target applications. Further simplifying data-level EAI is the fact that accessing databases is a relatively easy task, which can be accomplished with few significant—if any—changes to the application logic or database structure.
However, the relative simplicity of data-level EAI should not give one the impression that it is simple. It is not. Migrating data from one database to another may sound simple and reasonable, but for data-level EAI to work, architects and developers need to understand the complex world of database technology as well as the way information flows throughout an enterprise (discussed in detail in Chapter 6).
In most enterprises, databases number in the thousands and represent a complex mosaic of various database technologies and models that provide data storage for applications. This reality makes integrating databases a difficult task, one that was virtually impossible before the introduction of powerful many-to-many EAI data movement and transformation tools and technologies.
Accessing data in the context of EAI requires an "end run" around application logic and user interfaces in order to extract or load data directly into the database through an interface (see Figure 2.1). Fortunately, most applications built in the past two decades or so decouple the database from the application and interface, making this a relatively simple task. However, many databases are tightly coupled with the application logic. It is impossible to deal with the database without dealing with the application logic as well. This, of course, is a much more difficult proposition. It may be reason enough to employ method-level EAI along with data-level EAI, or even consider using method-level EAI exclusively.

Figure 2.1. Within the context of EAI we sneak behind the application and extract or update data directly.
Data-level EAI provides simplicity and speed-to-market. These advantages are the result of the fact that the business logic rarely has to be altered (a cohesive and not coupled approach). As a result, there is no need to endure the seemingly countless testing cycles, or the risk and expense of implementing newer versions of an application within any enterprise. Indeed, most users and applications will remain ignorant of the fact that data is being shared at the back-end.
The numerous database-oriented middleware products that allow architects and developers to access and move information between databases simplify data-level EAI. These tools and technologies allow for the integration of various database brands, such as Oracle and Sybase. They also allow for the integration of different database models, such as object-oriented and relational, models that we will discuss later in the chapter.
The advent of EAI-specific technology, such as message brokers, EAI management layers, and simple data movement engines gives the enterprise the ability to move data from one place to another—from anywhere to anywhere—without altering the target application source. What's more, this can now be done in real time, within online transaction-processing environments.
The technology for moving data between two or more data stores is a known quantity, well tested in real applications. Unfortunately, these gains do not exempt the architect or the developer from understanding the data that is being moved or from understanding the flow and business rules that must be applied to that data.
To better understand data-level EAI, it's helpful to work through a simple EAI problem. Let's say that a company that manufactures copper wiring would like to hook up the inventory control system, a client/server system using PowerBuilder and Oracle, and the Enterprise Resource Planning (ERP) system by using a proprietary application and the Informix relational database.
Primarily because the data movement requirements are light to moderate, and changing the proprietary ERP application to bind its logic with the inventory control system is not an option (because there is no access to the source code of the ERP application), the company would like to solve this EAI problem using data-level EAI.
In order to move data from the Oracle database to Informix, the EAI architect and developer first need to understand the metadata for each database in order to select the data that will move from one database to the next. In our example, let's assume that only sales data must move from one database to the other. For example, when a sale is recorded in the ERP system, creating an event, the new information is copied over to the inventory control system for order-fulfillment operations.
Another decision to be made involves frequency of the data movement. Let's say real time is a requirement for this problem domain. The event to be captured must also be defined in order to signal when the data needs to be copied, such as a specific increment for time (e.g., every 5 seconds) or when a state changes (e.g., an update to a table occurs).
There are many technologies and techniques for moving the data from one database to the next, including database replication software, message brokers, and custom-built utilities. Each comes with its own advantages and disadvantages, advantages and disadvantages that will become apparent later in this book. For our purposes here, we'll go with a database replication and integration solution, or piece of software that runs between the databases that's able to extract information out of one database, say the Informix database, reformat the data (changing content and schema) if needed, and updating the Oracle database. While this is a one-to-one scenario, one-to-many works the same way, as does many-to-many, albeit with more splitting, combining, and reformatting going on.
Once the middle-tier database replication software is in place, the information is extracted, reformatted, and updated from the Oracle database to the Informix database, and back again. The data is replicated between the two databases when an update occurs at either end to the corresponding sales table.
Using this simple approach, the application logic is bypassed, with the data moving between the databases at the data level. As a result, changes to the application logic at the source, or the target systems as in this case, provide an EAI solution when an application cannot be changed, such as is the case with most ERP applications.
There are more complex problem domains that also make sense for data-level EAI, such as moving data between traditional mainframe, file-oriented databases and more modern relational databases, relational databases to object databases, multidimensional databases to mainframe databases, or any combination of these. Once again, database replication and translation software and message brokers provide the best solutions, able to cohesively tie all source and target databases without requiring changes to the connected databases or application logic. This is the real value of nonintrusive approaches such as data-level EAI.
There are two basic approaches to data-level EAI and its accompanying enabling technology: database-to-database EAI and federated database EAI.
Database-to-database EAI, like the point-to-point approach, is something we've been doing well for years. Database-to-database EAI means that we're simply sharing information at the database level and, by doing so, integrating applications. Database-to-database EAI can exist in one-to-one, one-to-many, or many-to-many configurations. We approach database-to-database EAI with traditional database middleware and database replication software, such as replication features built into many databases (e.g., Sybase), or through database integration software. Message brokers also work with database-to-database EAI, but in the absence of sharing methods cohesively or needing to access complex systems, such as ERP applications, they tend to be overkill.
There are two types of solutions here. First, the basic replication solution moves information between databases that maintain the same basic schema information on all source and target databases. The second solution is replication and transformation. Using these types of products, it is possible to move information between many different types of databases, including various brands (e.g., Sybase, Oracle, and Informix) and models (relational, object-oriented, and multidimensional), by transforming the data on the fly so it's represented correctly to the target database or databases receiving the data. Such is the case in the inventory control system example described previously.
The advantage of this EAI approach is the simplicity of it all. By dealing with application information at the data level, there is no need to change the source or target applications, generally speaking. This reduces the risk and cost of implementing EAI. In many applications, the downside to this approach is the fact that the application logic is bound to the data, and it's difficult to manipulate the database without going through the application, or at least the application interface. This is certainly the case with SAP R/3, where, in order to avoid integrity problems, updating the database generally demands using the SAP R/3 interface.
Federated database EAI also works at the database level, like database-to-database EAI. However, rather than simply replicating data across various databases, federated database software is leveraged to allow developers to access any number of databases, using various brands, models, and schemas, through a single "virtual" database model. This virtual database model exists only in software and is mapped to any number of connected physical databases. The developers use this virtual database as a single point of application integration, accessing data from any number of systems through the same single database interface.
The advantage of this approach is the reliance on middleware to share information between applications, and not a custom solution. Moreover, the middleware hides the differences in the integrated databases from the other applications that are using the integrated view of the databases. Unfortunately, this is really not a true integration approach; while there is a common view of many databases, a "unified model," there will still be the need to create the logic for integrating the applications with the databases.
In order to implement data-level EAI, you first must consider the sources of the data and the database technology that houses the data. There is both good and bad news here for those looking to implement EAI within their organizations. The good news is that the majority of databases in existence today use the homogeneous relational database model, making it relatively simple to "mix and match" data from various databases. The bad news is that there are still many exceptions that form the "minority" heterogeneous models.
Relational databases make up the significant portion of the new application development that has occurred during the past 10 to 15 years. Unfortunately, traditional databases, such as those found on legacy systems, still hold the lion's share of enterprise data. Implementing EAI will mean confronting such old "friends" as IDMS, IMS, VSAM, ISAM, and even COBOL-driven flat files. Most of these will be defined later in the chapter.
When dealing with databases it is important to understand the following:
The model that the database uses to store information
The nature of the database itself, and how the differences between the databases existing within enterprises also provide an opportunity for integration
Relational databases are the reigning monarchs of the database world, and there is precious little sign of a palace coup occurring anytime soon. While many have questioned the enduring strength of relational databases, the simplicity of the model stands as the most compelling reason for their popularity. We seem to think in the relational model already. And, we continue to use databases primarily as storage mechanisms for data versus a location for application processing. Relational databases meet that need nicely.
Other factors that contribute to the popularity of relational databases include the availability of the technology, the fact that they are understandable, and that they pose the least amount of risk for systems. Using nonrelational products (e.g., object-oriented and multidimensional databases) adds risk to enterprise application development projects due to the lack of support from the mainstream development market. Still, nonrelational databases do serve niches and make sense, depending upon the application. This could change, of course, in the near future. Relational database vendors such as Oracle, Sybase, and Informix provide universal databases (see "Being All Things to All Data—Universal Databases" above) that can pretend to be object-oriented, multidimensional, Web-ready (intranet as well), and capable of storing binary information such as video.
Relational databases organize data in dimensional tables—and nothing but tables—that are tied together using common attributes (known as keys). Each table has rows and columns (see Figure 2.2).
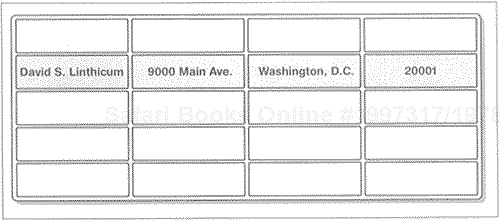
Rows contain an instance of the data. For example, an address would be a row in a customer table in the database of a local power company (see Figure 2.2). Therefore, each row represents a record.
Columns are named placeholders for data, defining the type of data the column is set up to contain. For example, the columns for the customer table may include:
Cust_Number
Cust_First_Name
Cust_Last_Name
Cust_Address
Cust_City
Cust_Zip
Cust_Birth_Day
While some columns may be set up to accept both text and numeric data, the Cust_Birth_Day column would be set up to accept only date-formatted information (e.g., 09/17/62), and the Cust_Number column would accept only numeric data.
As suggested previously, keys are columns common to two or more tables. Keys link rows to form groupings of data. Consider the previous example. While the customer table tracks information about power customers, there may be a billing table to track billing information. The columns in the billing table may include:
Cust_Number
Billing_Month
Billing_Amount
In this example, the Cust_Number column is common to both tables and acts as a key to link the two databases. And, while there may be only one row in the customer table, the billing table may contain many rows.
Soon after it was articulated, the object-oriented model was considered a real threat to the dominance of the relational model. While object-oriented databases are certainly more prevalent than they were, they are a long way from toppling Sybase, Oracle, Informix, and IBM. Still, they have exerted their influence. Most relational vendors include object-oriented capabilities within their existing relational database technology—"universal databases," as we've noted previously. Perhaps more to the point, growing interest in the Web is renewing interest in the object-oriented model for content and Web-aware data storage.
It is still very much a "relational world," but many OODBMSs are making inroads into organizations that find the object-oriented database model a better fit for certain applications, including persistent XML. OODBMSs meet the information storage requirements for mission-critical systems having complex information storage needs, such as applications requiring storage of complex data (repositories) or applications using binary data (audio, video, and images). Fortunately, the choice today needn't be an "either-or" one. In addition to universal servers, there exists the middleware necessary to make relational databases appear as object-oriented.
Those with experience in object-oriented programming languages (such as C++ or Smalltalk) already understand how objects contain both data and the methods to access that data. OODBMSs are nothing more than systems that use this model as the basis for storing information and thus support the object-oriented concepts of encapsulation and inheritance.
Data management illustrates the fundamental differences between traditional relational database technology and object-oriented database technology. In traditional relational databases, developers separate the methods (programs that act upon the data) from the data. By contrast, object-oriented databases combine data and method. This synergy between data and method poses a significant challenge for EAI, because data-level EAI presumes and works best when data and application are separate. In order to address this challenge within object-oriented databases, data-level and method-level EAI must be combined.
Multidimensional databases have evolved over the years and have been repackaged as databases that support online analytical processing (OLAP) or data mining—all wrapped up in a concept known as data warehousing. Currently, data warehousing is the focus of many MIS directors whose goal it is to turn thousands of gigabytes of company operational data into meaningful information for those who need it. Multidimensional databases are the tools that allow this goal to be realized.
Multidimensional databases manipulate data as if it resides in a giant cube. Each surface of the cube represents a dimension of the multidimensional database (see Figure 2.3). For example, while one side may represent sales, another may represent customers, and another, sales districts. The interior of the cube contains all the possible intersections of the dimensions, allowing the end user to examine every possible combination of the data by "slicing and dicing" his or her way through the cube with an OLAP tool that, for our purposes, must be understood to be joined "at the hip" with the multidimensional database.
OLAP products store data in one of two basic ways. The first is a true multidimensional database server, where the data is actually stored as a multidimensional array or, a "real cube." A second, more convenient way to employ OLAP is to maintain the data in relational databases but map that data so it appears as multidimensional data—in other words, a "virtual cube" where the illusion of a "real cube" exists at the metadata layer.

The power of multidimensional databases and OLAP is that the technology provides a multidimensional view of the database that closely resembles the way the end user understands the business. OLAP offers a natural, "drill-down" interface that allows users to move through layer after layer of data abstraction until they find the information they require. Once found, the data is easily graphed, printed, or imported into documents and spreadsheets.
While the models previously described capture the primary models and methods of data storage, the reality is that many other technologies and models are out there. Within the problem domain of EAI, it is possible to encounter older, but certainly workable, methods such as hierarchical, indexed sequential access method (ISAM), virtual sequential access method (VSAM), Conference on Data Systems Languages (CODASYL), and Adabas. There may also be simple flat files and proprietary data storage techniques devised within the confines of the enterprise or by a now-defunct vendor.
One should keep in mind that the only surprise in EAI is no surprises.
Databases subscribing to the hierarchical database model allow data representation in a set of one-to-many relationships. Each record in a hierarchy may have several offspring. IDMS, now part of Computer Associates, is an example of a hierarchical database model.
ISAM is a simple file organization providing sequential and direct access to records existing in a large file. ISAM is hardware dependent. VSAM is an updated version of ISAM and is also hardware dependent.
CODASYL is a standard created by an organization of database vendors to specify a method for data access for COBOL.
Adabas, or the Adaptable Database, is able to support a variety of database models within a single database. It provides a high-performance database environment primarily for mainframe environments. Adabas provides a nested relational structure. It supports the relational database model to an extent, as well as document storage and retrieval.
The difficulty with data-level EAI is the large scope of integrating various databases within the enterprise. The initial desire and tendency is to solve all the integration woes of an enterprise at the same time by integrating all databases that need to communicate. However, given the complexity and difficulty in accomplishing this desired end, it is better to move forward in a clear, paced manner. Attempting to accomplish the entire process at one time is a massive undertaking and, for most enterprises, too much change to tolerate.
Enterprises should consider taking "baby steps" toward the goal of data-level EAI—and EAI in general. It would be wise to integrate two or three databases at first, allowing them to become successful, before moving forward to bigger problem domains. Not only does this ease the burden on the EAI architects pushing a new concept of EAI and shouldering a huge workload, it also eases the burden on the users who have to test the systems and work through problems as they become integrated.