
I do not fear computers. I fear lack of them. | ||
| --Isaac Asimov | ||
This chapter builds on a working knowledge of method-level, data-level, application interface-level, and user interface-level EAI to suggest a high-level process, or methodology, that can be applied to most enterprise application integration projects. Naturally, we cannot present all possible answers here. Our goal is to provide a workable checklist of the issues that need to be considered within the context of any given EAI project. That said, we must add that every problem domain is unique and that the methodology approaches will vary greatly from project to project. For example, EAI projects that work exclusively at the data level must consider data-level activities such as data cataloging and enterprise metadata modeling, while projects working at the object model level will require composite applications. Still others may use both types of EAI, and therefore, the associated activities needed to get them there. Ultimately, the successful approach is the one that matches the processes or steps in a particular problem domain. The best way to achieve that success is to understand all the details of a problem domain, leaving no proverbial stone unturned.
By the time this book has gone to press, most professional service organizations will have instituted some form of EAI methodology that, they will claim, will assure ultimate EAI success. These methodologies are most often found in a series of binders (each at least six inches thick) and outline as many as a thousands steps before reaching EAI nirvana. That's all fine and good but a bit on the overkill side for most organizations. Most organizations don't need that kind of rigor to be successful with EAI. What they do need are some good architectural skills and a base of knowledge pertaining to state-of-the-art technology solutions.
The following activities should be considered when approaching EAI (which is not to say that these are the only steps in an EAI project). Our strategy relies on a practical approach to EAI. We reuse some of the activities we've learned with traditional database design, application design, and development. Many times, we use the same design patterns to bind applications together as we did to build them. After all, there is no need to reinvent the wheel if the result will only confuse an already complex process.
This pragmatic approach relies on familiar concepts and terms such as metadata, schemas, object-oriented modeling, object-oriented analysis and design (OOA/OOD), patterns, and "good old" requirements-gathering techniques. Our suggestion for integrating applications relies on a simple set of techniques, our own "12-step program":
Understanding the enterprise and problem domain
Making sense of the data
Making sense of the processes
Identifying any application interfaces
Identifying the business events
Identifying the data transformation scenarios
Mapping information movement
Applying technology
Testing, testing, testing
Considering performance
Defining the value
Creating maintenance procedures
In this chapter, we concentrate on steps 2 and 3 because it is at those steps where we begin to define the models that will serve as the basis for our EAI solution. These steps are also unique to our approach and to this book. The remaining steps will be discussed briefly as concepts. If you require more detailed information about the remaining steps, we suggest the tremendous amount of information available in other books and articles, some of which you'll find listed in the Bibliography.
Sounds simple, huh? Too bad this is the most complex and time-consuming part of the entire process. However, it is unavoidable. At some point, the problem domain must be studied, both freestanding and in the context of the enterprise. Understanding the problem domain requires working with many organization heads in order to get a handle on the structure and content of the various information systems, as well as the business requirements of each organization—how they do business, what's important, and, perhaps more importantly, what's not.
This process is a basic requirements-gathering problem. It requires interfacing with paper, people, and systems to determine the information that will allow the EAI problem to be defined correctly so that it can be analyzed, modeled, and refined. Only then can the appropriate solution set be employed.
The quality of the information gathering at this step leads directly to, and impacts the success of steps 2 and 3.
We begin with the data for a couple of reasons. First, most EAI projects exist only at the data level. This reality alone justifies the quest to understand what exists in the databases scattered throughout an enterprise. Second, even if the EAI project works at the method, application interface, and user interface levels, it is still necessary to understand the databases. Face it. There's no getting around this step.
Ultimately, the implementation of data-level EAI comes down to understanding where the data exists, gathering information about the data (e.g., schema information), and applying business principles to determine which data flows where, and why.
There are three basic steps that must be followed to prepare for implementing data-level EAI:
Identifying the data
Cataloging the data
Building the enterprise metadata model, which will be used as a master guide for integrating the various data stores that exist within the enterprise (see Figure 6.1)
In short, implementing an EAI solution demands more than the movement of data between databases and/or applications. A successful solution requires that the enterprise also define both how that information flows through it, and how it does business.
Unfortunately, there are no shortcuts to identifying data within an enterprise. All too often, information about the data, both business and technical, is scattered throughout the enterprise and of a quality that ranges from "somewhat useful" to "you've got to be kidding me!"
The first step in identifying and locating information about the data is to create a list of candidate systems. This list will make it possible to determine which databases exist in support of those candidate systems. The next step will require determining who owns the databases and where they are physically located, and it will include relevant design information and such basic information as brand, model, and revisions of the database technology.

Any technology that is able to reverse-engineer existing physical and logical database schemas will prove helpful in identifying data within the problem domains. However, while the schema and database model may give insight into the structure of the database or databases, they cannot determine how that information is used within the context of the application.
Detailed information can be culled by examining the data dictionaries (if they exist) linked to the data stores being analyzed. Such an examination may illuminate such important information as
The reason for the existence of particular data elements
Ownership
Format
Security parameters
The role within both the logical and physical data structure
While the concept of the data dictionary is fairly constant from database to database, the dictionaries themselves may vary widely in form and content. Some contain more information than others do. Some are open. Most are proprietary. Some don't even exist—which is often the case with less sophisticated software.
When analyzing databases for data-level EAI, integrity issues constantly crop up. In order to address these issues, it is important to understand the rules and regulations that were applied to the construction of the database. For example, will the application allow updating customer information in a customer table without first updating demographics information in the demographics table?
Most middleware fails to take into account the structure or rules built into the databases being connected. As a result, there exists the very real threat of damage to the integrity of target databases. While some databases do come with built-in integrity controls, such as stored procedures or triggers, most rely on the application logic to handle integrity issues on behalf of the database. Unfortunately, the faith implicit in this reliance is not always well placed. Indeed, all too often it is painfully naive.
The lack of integrity controls at the data level (or, in the case of existing integrity controls, bypassing the application logic to access the database directly) could result in profound problems. EAI architects and developers need to approach this danger cautiously, making sure not to compromise the databases' integrity in their zeal to achieve integration. Perhaps this is where a decision to use another EAI level as primary point-of-integration might be considered.
Data latency, the characteristic of the data that defines how current the information needs to be, is another property of the data that needs to be determined for the purposes of EAI. Such information will allow EAI architects to determine when the information should be copied, or moved, to another enterprise system and how fast.
While an argument can be made to support a number of different categories of data latency, for the purpose of EAI within the enterprise there are really only three:
Real time
Near time
One time
Real-time data is precisely what it sounds like it would be—information that is placed in the database as it occurs, with little or no latency. Monitoring stock price information through a real-time feed from Wall Street is an example of real-time data. Real-time data is updated as it enters the database, and that information is available immediately to anyone, or any application, requiring it for processing.
While zero latency real time is clearly the goal of EAI, achieving it represents a huge challenge. In order to achieve zero latency, EAI implementation requires constant returns to the database, application, or other resource to retrieve new and/or updated information. In the context of real-time updates, database performance also has to be considered—simultaneous to one process updating the database as quickly as possible, another process must be extracting the updated information.
The successful implementation of zero latency presents architects and developers with the opportunity to create such innovative solutions as method-level EAI, where business processes are integrated within the EAI solution. In many cases method-level EAI makes better sense than data level-only EAI solutions because it allows data and common business processes to be shared at the same time. The downside to method-level EAI is that it is also the most expensive to implement.
Near-time data refers to information that is updated at set intervals rather than instantaneously. Stock quotes posted on the Web are a good example of near-time data. They are typically delayed 20 minutes or more, because the Web sites distributing the quotes are generally unable to process real-time data. Near-time data can be thought of as "good-enough" latency data. In other words, data only as timely as needed.
Although near-time data is not updated constantly, providing it still means facing many of the same challenges encountered when providing real-time data, including overcoming performance and management issues.
One-time data is typically updated only once. Customer addresses or account numbers are examples of one-time information. Within the context of EAI, the intervals of data copy, or data movement, do not require the kind of aggressiveness needed to accomplish real-time or near-time data exchange.
The notion of data typing goes well beyond the classification of the data as real-time, near-time, or one-time. It is really a complex process of determining the properties of the data, including updates and edit increments, as well as the behavior of the data over time. What do the applications use the particular data for? How often do they use it? What happens with the data over time? These are questions that must be addressed in order to create the most effective EAI solution.
Another identifying component of data is data format. How information is structured, including the properties of the data elements existing within that structure, can be gleaned from knowledge of the data format. Likewise, length, data type (character or numeric), name of the data element, and what type of information stored (binary, text, spatial, and so on) are additional characteristics of the data that may be determined by its format.
Resolution of data format conflicts must be accomplished within such EAI technologies as message brokers and/or application servers. Different structures and schemas existing within the enterprise must be transformed as information is moved from one system to another. The need to resolve these conflicts in structure and schema makes knowing the structure of the data at both the source and target systems vital. (Our discussion of message broker technology in Chapter 18 will deal with how message brokers are able to adapt to differences in data formats found in different databases that exist within the enterprise. For now, it is enough to note that message brokers are able to transform a message or database schema from one format to another so that it makes sense both contextually and semantically to the application receiving the information—see Figure 6.2). This often needs to be accomplished without changing the source or target applications, or the database schemas. Message broker technology allows two systems with different data formats to communicate successfully.)
Once the logical and physical characteristics of the databases to be integrated are understood, it is time to do the "grunge" work—data cataloging. In the world of EAI, data cataloging is the process of gathering metadata and other data throughout the problem domain. Once accomplished, it is possible to create an enterprise-wide catalog of all data elements that may exist within the enterprise. The resulting catalog then becomes the basis of the understanding needed to create the enterprise metadata model—the foundation of data-level EAI.
For most medium- to large-sized enterprises, the creation of this data catalog is a massive undertaking. In essence, it demands the creation of the "mother of all data dictionaries," a data dictionary that includes not only the traditional data dictionary information, but also all the information that is of interest to EAI—system information, security information, ownership, connected processes, communications mechanisms, and integrity issues, along with such traditional metadata as format, name of attribute, description, and so on.
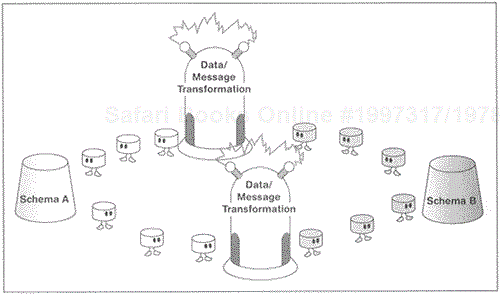
Figure 6.2. Message brokers are able to transform schemas and content, accounting for the differences in application semantics and database structure between applications and databases.
While there is no standard for cataloging data within EAI projects, the guiding principle is clear: the more information, the better. The catalog will become both the repository for the EAI engine to be built and the foundation to discover new business flows. It will also become a way to automate existing business flows within the enterprise.
While data catalogs can be made using index cards or paper, electronic spreadsheets (e.g., Microsoft Excel) or PC-based databases (e.g., Microsoft Access) provide more attractive alternatives. Remember that a data catalog is not the enterprise metadata. It is the foundation of the metadata. Therefore, there is no need to expand the data catalog into a full-blown metadata repository until it is completely populated.
It is an understatement to suggest that this catalog will be huge. Most enterprises will find tens of thousands of data elements to identify and catalog even while reducing redundancies among some of the data elements. In addition to being huge, the data catalog will be a dynamic structure. In a very real sense, it will never be complete. A person, or persons, will have to be assigned to maintain the data catalog over time, assuring that the information in the catalog remains correct and timely, and that the architects and developers have access to the catalog in order to create the EAI solution.
Once all the information about all the data in the enterprise is contained in the data catalog, it is time to focus on the enterprise metadata model. The difference between the two is sometimes subtle. It is best to think of the data catalog as the list of potential solutions to your EAI problem and to think of the metadata model as the data-level EAI solution. The metadata model defines not only all the data structures existing in the enterprise but also how those data structures will interact within the EAI solution domain.
Once constructed, the enterprise metadata model is the enterprise's database repository of sorts, the master directory for the EAI solution. In many cases, the repository will be hooked on to the messaging system (e.g., message brokers) and used as a reference point for locating not only the data but also the rules and logic that apply to that data. However, the repository is more than simply the storage of metadata information. It is the heart of the ultimate EAI solution, containing both data and business model information.
The metadata repository built using the process outlined in this chapter will not only solve the data-level EAI problem but will provide the basis for other types of EAI as well (e.g., method level, user interface level, application interface level). As in the world of client/server and data warehousing, the process builds up from the data to the application and from the application to the interface, if necessary. This "hierarchical" flow identifies data-level EAI as the foundation for the larger EAI solution.
Just as with traditional database design methods, the enterprise metadata model used for data-level EAI can be broken into two components: the logical and the physical. And, just as with the former, the same techniques apply to the latter. Creating the logical model is the process of creating an architecture for all data stores that are independent of a physical database model, development tool, or particular DBMS (e.g., Oracle, Sybase, Informix).
A logical model is a sound approach to an EAI project in that it will allow architects and developers the opportunity to make objective data-level EAI decisions, moving from high-level requirements to implementation details. The logical data model is an integrated view of business data throughout the application domain or of data pertinent to the EAI solution under construction. The primary difference between using a logical data model for EAI versus traditional database development is the information source. While traditional development, generally speaking, defines new databases based on business requirements, a logical data model arising from an EAI project is based on existing databases.
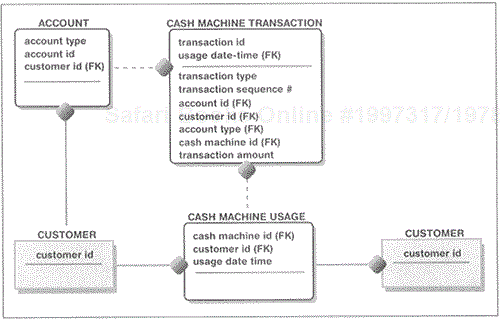
At the heart of the logical model is the Entity Relationship Diagram (ERD). An ERD is a graphical representation of data entities, attributes, and relationships between entities (see Figure 6.3) for all databases existing in the enterprise.
CASE (Computer Aided Software Engineering) technology is but one of the many tools to automate the logical database-modeling process. Not only do these tools provide an easy way to create logical database models, but they are also able to build logical database models into physical database models. They also create the physical schema on the target database(s) through standard middleware.
The myriad of database types in any given enterprise minimizes the importance of the physical enterprise model because, with so many database types, the physical model will rarely be used. The reason is clear—there is simply no clear way to create a physical model that maps down to object-oriented, multidimensional, hierarchical, flat files, and relational databases all at the same time. However, if those databases are to be integrated, some common physical representation must be selected. Only then can the model be transformed as required. (The necessity of the physical model is only for those times when it is possible to map the logical to the physical—that is, those times when an enterprise uses a homogeneous database approach, usually all relational. The input for the physical model is both the logical model and the data catalog. When accessing this information, consider the data dictionary, business rules, and other user-processing requirements.)
Before the logical, and sometimes physical, database is completed, it is desirable to normalize the model. This is a process of decomposing complex data structures into simple relations using a series of dependency rules. Normalization means reducing the amount of redundant data that will exist in the database or, in the case of EAI, in the enterprise. It is a good idea to do this in both the logical and physical database design, or the EAI redesign.
When considered within the context of EAI, the normalization process is very complex and risky. Because there can be no control over most of the databases that are being integrated, normalizing the logical enterprise metadata model often results in a new version of the model that has no chance of being implemented physically. This result violates an essential credo of EAI: Whenever possible, it is best to leave the applications and databases alone. Changes to databases inevitably translate into expense and risk. Furthermore, most enterprises employ a chaotic mosaic of database technology, making it technically unfeasible to accomplish such changes without rehosting the data. This is almost always completely out of the question.
The question remains, however, "Are changes to be made to source and target databases or not?" Generally, it is wise to normalize the logical enterprise metadata model to discover areas within the enterprise that may benefit from changes in their data structures. Changes to databases may allow the enterprise to reduce the amount of redundant data and thus increase the reliability of the integrated data. Remember, the notion of data-level EAI is to perceive all the databases within the enterprise as a single database and, in turn, to make that huge enterprise database as efficient as possible through processes such as normalization.
Once the enterprise data is understood, and baseline information such as the enterprise metadata model has been created, the decision must be made as to how to approach the enterprise business model. This decision will depend on how the particular EAI problem domain is addressed. This is a view of the enterprise at the process, or method level, understanding and documenting all business processes and how they relate to each other, as well as to the enterprise metadata model.
As with the database analysis procedures outlined previously, it is desirable to use traditional process-modeling techniques, such as object modeling (e.g., the Unified Modeling Language [UML]) to create business processes. What's more, instead of creating the business processes from a set of application requirements, it is preferable to document existing business processes and methods, to better understand what they do and, therefore, how to integrate them at the method level through a composite application.
We have already stated that identifying processes that exist within an enterprise is a difficult task, requiring the analysis of all the applications in the enterprise that exist in the EAI problem domain. The task is made even more difficult due to the possibility that many entities embrace numerous types of applications over a number of generations of technology.
Once the applications in the problem domain have been analyzed, the enabling technology employed by each application within the problem must be identified. With applications in the enterprise dating from as long ago as 30 years, this step will uncover everything from traditional centralized computing to the best-distributed computing solutions. Once this identification has been made, the next step is to determine ownership of the processes and, subsequently, develop insight into those processes—for example, why information is being processed in one manner versus another, or why multiple arrays are used to carry out a particular operation. In most cases, ownership will rest with the application manager who determines when the application is to be changed and for what reason(s).
Finally, the documentation for the application will need to be found. In a small number of instances, applications are not only well documented but have been updated as they have matured. The vast majority of the time, applications are poorly documented, or the documentation has not been updated to keep up with the maturation of the application. Proper documentation has a profound impact on method-level EAI. Therefore, even if documentation is nonexistent, it is imperative that baseline documentation be created as the EAI solution is put into place. This is an area of significant expense as applications are opened in order to be understood and their features documented.
Process identification is important to the method-level EAI project lifecycle. Without understanding the processes, moving forward is a lot like a guessing game or like playing blind man's bluff. There can never be real certainty that the enterprise is being accurately integrated. While data is relatively easy to identify and define, processes are much more complex and difficult.
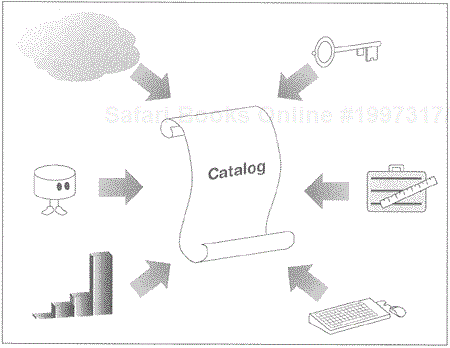
In the same way that data-level EAI requires a data-level catalog, method-level EAI requires a "process catalog"—a list of all business processes that exist within an enterprise or, at least, within the problem domain. For example, if an EAI architect needs to understand all the processes that exist within an inventory application, he or she will read either the documentation or the code to determine which processes are present. Then, the architect will not only enter the business processes into the catalog but will also determine the purpose of the process, who owns it, what exactly it does, and the technology it employs (e.g., Java, C++). In addition, the architect will need to know which database a particular business process interacts with as well as its links to the metadata model. The catalog will require other information as well, such as pseudocode, data flow diagrams, and state diagrams, which are able to define the logic flow for the particular process. In the world of traditional, structured programming, this would mean a flowchart, or pseudocode. However, in the world of object-oriented development, this refers to the object model. Thus, it is important not only to identify each process but also to understand how the logic flows within that process.
Other information may be maintained in the catalog as well, information which may include variables used within the processes, object schemas, security requirements, and/or performance characteristics. Each process catalog must maintain its own set of properties, custom built for each specific EAI problem domain (see Figure 6.4).
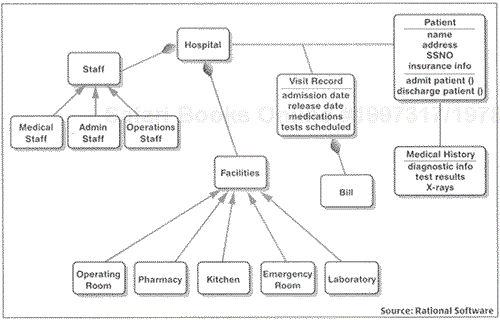
If the enterprise metadata model is the end state for data-level EAI analysis, then the common business model is the end state for method-level EAI. Simply put, the common business model is the aggregation and high-level model of all objects, methods, properties, procedural logic, batch processing, and everything else in the enterprise that processes information.
The common business model is assigned this name (and not the "object model") for one reason: In order for it to document and account for such a wide array of techniques and technologies, the model must remain, at least at first, an independent paradigm. Many of the applications written in the last ten years use the object-oriented paradigm for both programming and design. However, most traditional applications (those older than ten years) use a structured application-programming paradigm, as well as structured design. The common business model must remain independent of both (see Figure 6.5).

Figure 6.5. The common business model must remain independent of all programming paradigms in order to succeed with method-level EAI.
Having an independent paradigm results in a simplification of the business processes in the enterprise or the EAI problem domain. The common business model does not map out a complex, detail-oriented model, but rather a high-level understanding of the processes in the enterprise along with their functions and features—all with an eye toward those that may be combined or reused.
Business modeling is important for another reason as well. The ultimate goal of EAI is to move beyond the simple integration of applications to the much more complex integration of business process flow analysis and design. Thus, the business model provides the basis of understanding that allows for the creation of a proper business process flow necessary within the enterprise. To accomplish this, the current state and the desired state—along with a plan to get from one to the next—must be documented.
For the sake of clarity, EAI architects should use the Unified Modeling Language (UML) to define the common business model. Using UML affords EAI architects a twofold benefit. First, an abundance of tools is available to create and maintain UML. Second, a deep pool of information exists regarding leveraging UML for a variety of purposes (see Figure 6.6).
The real challenge to creating a common business model is scope. The temptation—and thus, the trap—to re-architect and redesign each source and target application is very real. However, creating a business model is not an application development problem. It is an application integration problem. The EAI architect must recognize that the purpose of the common business model is to document existing processes, not to change the source and target applications. While it is certainly possible to rewrite everything from scratch in order to integrate the enterprise, such an endeavor would largely outweigh the value of EAI.
Patterns are always interesting. More than interesting, they are useful in the context of method-level EAI. They enable the EAI architect to identify common business processes among the many business processes that already exist within the enterprise. Or they may be used to identify new processes in need of integration. Using patterns in this way is simply borrowing them from the world of application architecture, and applying them to the world of enterprise architecture—a perfect fit.
Patterns arise over and over during considerations of EAI architecture. Patterns formalize and streamline the idea of EAI—to build once at the application level and then reuse throughout the solution domain. Patterns describe recurring design problems that appear in certain design contexts. They describe generic schemes for the solution of the problems, solution schemes created by defining their components, responsibilities, and relationships.
A three-part schema is part of every pattern: context, problem, and solution. Context describes the circumstances of the situation where the problem arises or which have to be true for the pattern to be valid. For example, an object uses data from an external system. The problem is what is addressed by the pattern—and that which arises over and over in the context. The challenge for the architect or designer is to capture the essence of the problem or what design issues define the problem. For example, changing the state of the object means that the object and the external data are inconsistent. As a result, there is a need to synchronize the external data and the object. The resulting solution is the well-proven and consistent resolution of the problem.
All patterns are not created equal. There are types, or categories, of patterns to be used in specific situations in the EAI problem domain. For example, some patterns assist EAI architects in structuring a system into subsystems, while others allow the architect to refine the subsystems and applications and the ways in which they interact. Some patterns assist EAI architects in determining design aspects using pseudocode or a true programming language such as C++. Some address domain-independent subsystems or components or domain-dependent issues such as business logic. Clearly, the range of patterns makes it difficult to define neat categories for them. However, there are three useful, and generally accepted, categories: architectural patterns, design patterns, and idioms.
Architectural patterns are complex patterns that tend to link to particular domains. They provide EAI architects with the basic system structure—subsystems, behavior, and relationships. It would not be unfair to consider these architectural patterns as templates for EAI architecture, defining macro system structure properties. Design patterns are not as complex as architectural patterns. They tend to be problem domain independent. These patterns provide application architects with a means of refining the subsystems and components, and the relationships between them. The goal in using these patterns is to find a common structure that solves a particular problem. An idiom is a low-level pattern coupled with a specific programming language. It describes how to code the object at a low level.
Pattern descriptions, or micro-methods, provide specifications for deploying the pattern. They give application architects problem-independent analysis and design methods that are found in traditional, object-oriented analysis and design methodologies such as UML.
Patterns, as recurring phenomena, provide EAI architects with a methodology for defining and solving recurring problems. They allow application architects to create reusable solutions that can then be applied to multiple applications (see Figure 6.7). The ensuing information is too often kept "in the architect's head" where it is either forgotten or simply unavailable when the problem arises again. Unfortunately, EAI architects, even the good ones, tend to be poor documentation generators.

Figure 6.7. Patterns provide EAI architects with a methodology for defining and solving recurring problems.
Extending the previous concept, it becomes clear that patterns do a good job of recording design experience across a development group. They "level the playing field," providing every team member with access to this valuable information. EAI and application architects may create a database of architecture patterns—with search features and links to code and models. Patterns also provide a standard vocabulary and a base set of concepts for EAI and application architecture. For this reason, terms used to represent concepts should be chosen carefully. Thoughtful terminology results in greater efficiency because terms and concepts no longer have to be explained over and over. When endowed with a common terminology, patterns provide a natural mechanism for documenting application architectures. The vocabulary should be consistent across many projects. If this consistency is adhered to—and the patterns are accessible and understandable to all members of the application development teams—then patterns can be employed with striking success.
Patterns allow EAI and application architects to build complex architectures around predefined and proven solutions because they provide predefined components, relationships, and responsibilities. While patterns don't provide all the design detail necessary to solve a problem at hand, they do define a starting point. Moreover, they provide EAI architects with the skeleton of functionality.
Using patterns, EAI architects can manage software complexity because all patterns provide predefined methods to solve a problem. For example, if the problem is integrating an enterprise, there is no need to "reinvent the wheel." The task is simply to find the pattern that describes the problem and then to implement the solution. (This assumes that only sound patterns with working solutions are captured.)
Patterns add value to the EAI architecture and the software development life cycle. They have the potential to increase the quality of most system development and to provide effective integration without increasing cost. However, they are not necessarily the panacea for "all that ails" the system. Patterns should not be assumed to be a mechanism for replacing a sound methodology, or a sound process. Patterns are able to become part of each, and in many instances, some pattern-oriented enterprise architecture is already taking place. Patterns simply formalize the process, filling in the gaps and providing a consistent approach.
There are those who describe patterns as the "second coming" of enterprise architecture. As comforting as that assertion might be, there is no evidence to validate it. Patterns are, simply, another available tool to be used. What is more, patterns are valuable only if they are practiced consistently for all applications in the enterprise. Capturing patterns for a single application is hardly worth the effort. EAI architects need to establish the infrastructure for patterns, creating standard mechanisms to capture and maintain the patterns over the long haul, refining them when necessary.
Finally, patterns only provide an opportunity for reuse within the EAI problem domain. They are not a guarantee of success. Object-oriented analysis and design methodologies formalize the way reusable elements (objects) are implemented. Patterns define architectural and design solutions that can be reused. There is a difference. Patterns need not be linked to object-oriented analysis, design, or implementation languages. Nor do they need rigorous notation, a rigid process, or expensive tools. Patterns can be captured easily on 3x5 index cards or a word processor. The ideal way to capture patterns in the context of EAI is within the process catalog described previously. Doing so allows both process information and pattern information to be gathered at the same time.
Again, the concept of patterns is a very simple one. However, patterns, as described by the pattern community, are too often difficult to understand and use. The depth and range of academic double-speak regarding patterns has "spooked" many application architects. Hopefully, as with other technologies based on complex theory, patterns can be freed of the shackles of academia and be made available to the "masses" so that they can become a primary tool for integration at the method level.
In addition to seeking common methods and data to integrate, it is important as well to take note of the available application interfaces in support of application interface-level EAI, or integration with application interfaces and other EAI levels.
Interfaces are quirky. They differ greatly from application to application. What's more, many interfaces, despite what the application vendors or developers may claim, are not really interfaces at all. It is important to devote time validating assumptions about interfaces.
The best place to begin with interfaces is with the creation of an application interface directory. As with other directories, this is a repository for gathered information about available interfaces, along with the documentation for each interface. This directory is used, along with the common business model and the enterprise metadata model, to understand the points of integration within all systems of the EAI problem domain.
The application interface directory can be thought of as a list of business processes that are available from an application—packaged or custom made. It must, however, be a true application (database, business processes, or user interface) and not a database or simple middleware service. The application interface directory expands on the enterprise metadata model, tracking both data and methods that act on the data.
The first portion of the application interface directory is a list of application semantics. These establish the way and form in which the particular application refers to properties of the business process. For example, the very same customer number for one application may have a completely different value and meaning in another application. Understanding the semantics of an application guarantees that there will be no contradictory information when the application is integrated with other applications. Achieving consistent application semantics requires an EAI "Rosetta stone" and, as such, represents one of the major challenges to the EAI solution.
The first step in creating this "Rosetta stone" is to understand which terms mean what in which applications. Once that step is accomplished, that first very difficult step has been taken toward success.
Business processes are listings of functions or methods provided by the application. In some applications, such a listing is easy to determine because the business processes are well documented and easily found by invoking the user interface. However, in other applications, determining these processes requires a search through the source code to discover and understand the various methods and functions available.
As with application semantics, it is critical to understand all business processes that are available within a particular application. Once understood and documented in the application interface directory, it is possible to determine the particular combination of processes to invoke in order to carry out a specific integration requirement. For example, in an application that contains as many as 30 business processes for updating customer information, it is vital to know which process wants to invoke what and why.
The next step is the identification of all relevant business events that occur within an enterprise. This means when something happens—an event —then there is a resulting reaction. For example, a customer signing up for credit on an online Web store represents an "event." It may be desirable to capture this event and make something else happen, such as running an automatic credit check to assure that the customer is credit worthy. That consequence, of course, may kick off a chain of events at the credit bureau and return the credit status of the customer, which typically fires off still other events, such as notifying the customer through e-mail if the credit application is accepted or denied. These events are generally asynchronous in nature but can be synchronous in some instances.
This should make clear that in attempting to understand an EAI problem domain, a real attempt should be made to capture the business events that may take place within the domain. It is important to understand what invoked a business event, what takes place during the event, and any other events that may be invoked as a consequence of the initial event. The end result is a web of interrelated events, each dependent on the other. Currently, this web exists through automatic or manual processes. In the EAI solution set, all these events will be automated across systems, eliminating the manual processing entirely.
With an existing understanding of the data and application semantics that exist within an EAI problem domain, it is good to get an idea about how schema and content of the data moving between systems will be transformed. This is necessary for a couple of reasons. First, data existing in one system won't make sense to another until the data schema and content is reformatted to make sense to the target system. Second, it will assure the maintenance of consistent application semantics from system to system. (This subject will be discussed in more detail when we discuss message brokers in Chapter 18.)
Once the preceding steps have revealed all the information available, it is time to map the information movement from system to system—what data element or interface the information is moving from, and to where that information will ultimately move.
For example, the customer number from the sales databases needs to move to the credit-reporting system, ultimately residing in the customer table maintained by the credit system. This knowledge enables us to map the movement from the source systems, the sales system, to the credit system, or the target system. It should be noted where the information is physically located, what security may be present, what enabling technology exists (e.g., relational table), and how the information is extracted on one side to be placed on the other.
It is also necessary to note the event that's bound to the information movement. Or if no event is required, what other condition (such as time of data, real time, or state changes) causes the movement of information from the source to the target. (This process is typically more relevant to cohesive systems rather than coupled systems, because coupled systems are usually bound at the method level, which is where the data is shared rather than replicated. Mappings need to be adapted to the EAI level that is being used to integrate the systems.)
Now, finally, the "fun" part (not to mention the reason for the rest of the book): selecting the proper enabling technology to solve the EAI problem. Many technologies are available, including application servers, distributed objects, and message brokers. The choice of technology will likely be a mix of products and vendors that, together, meet the needs of the EAI solution. It is very rare for a single vendor to be able to solve all problems—not that that reality has ever kept vendors from making the claim that they can.
Technology selection is a difficult process, which requires a great deal of time and effort. Creating the criteria for technology and products, understanding available solutions, and then matching the criteria to those products is hardly a piece of cake. To be successful, this "marriage" of criteria and products often requires a pilot project to prove that the technology will work. The time it takes to select the right technologies could be as long as the actual development of the EAI solution. While this might seem daunting, consider the alternative—picking the wrong technology for the problem domain. A bad choice practically assures the failure of the EAI project.
Testing is expensive and time consuming. To make testing an even more "attractive" endeavor, it is also thankless. Still, if an EAI solution is not tested properly, then disaster looms large. For example, important data can be overwritten (and thus lost). Perhaps worse, erroneous information could appear within applications. Even without these dire eventualities, it is necessary to ensure that the solution will scale and handle the other rigors of day-to-day usage.
To insure proper testing, a test plan will have to be put in place. While a detailed discussion of a test plan is beyond the scope of this book, it is really just a step-by-step procedure detailing how the EAI solution will be tested when completed. A test plan is particularly important because of the difficulty in testing an EAI solution. Most source and target systems are business critical and therefore cannot be taken offline. As a result, testing these systems can be a bit tricky.
Performance is too often ignored until it's too late. A word of advice: Don't ignore performance! EAI systems that don't perform well are destined to fail. For example, if processing a credit report for a telephone customer takes 20 minutes during peak hours, then the EAI solution does not have business value.
While most EAI solutions won't provide zero latency with today's technology, the movement of information from system to system, or the invocation of common business processes, should provide response times under a second. What's more, the EAI solution should provide that same response time under an ever-increasing user and processing load. In short, the EAI solution will scale.
So, how do you build performance into a system? By designing for performance and by testing performance before going live. Remember, performance is something that can't be fixed once the EAI solution has been deployed. Performance must be designed "from the ground up." This means the architecture of the EAI solution needs to provide the infrastructure for performance, as well as the selected enabling technology. It is possible to make some adjustments before the solution is deployed using traditional performance models, such as those developed over the years within the world of distributed computing. Finally, it is necessary to run some performance tests to ensure that the system performs well under a variety of conditions. For example, how well does it perform at 100 users, 500 users, 1,000 users, and even 10,000 users? What about processing load? What happens to performance as you extend the EAI solution over time?
With the hard part out of the way, it's time to define the value of the EAI solution, to determine the business value of integrating systems. In this scenario, the method of determining value is generally evaluating the dollars that will be saved by a successful EAI solution. Two things should be considered here: the soft and hard dollar savings. Hard dollars, simply put, represent the value of the EAI solution easily defined by the ability for the solution to eliminate costly processes, such as automating manual processes, reducing error rates, or processing customer orders more quickly. In contrast, soft dollar savings are more difficult to define. These savings include increased productivity over time, retention rate increase due to the ability to make systems work together for the users, and customer satisfaction (based on ease of use) with an organization with integrated systems.
Of course, defining value in a particular system can be based on any criteria and will differ from problem domain to problem domain, and from business to business.
Last but not least, it is necessary to consider how an EAI solution will be maintained over time. Who will administer the message broker server? Who will manage security? Who will monitor system performance and solve problems?
In addressing the need for ongoing maintenance, a good idea is to document all of the maintenance activities that need to occur—and assign people to carry them out. Remember, an EAI solution represents the heart of an enterprise, moving vital information between mission-critical systems. As such, it is also a point of failure that could bring the entire enterprise to its knees.
With that happy thought in mind, this might also be a good time to consider disaster recovery issues, such as redundant servers and networks, as well as relocating the EAI solution should a disaster occur.
As we noted at the outset of this chapter, we have not (and could not) define everything that you must do in order to create a successful EAI project. Our goal here has been to outline the activities that may be necessary for your EAI project. Unlike traditional application development, where the database and application are designed, EAI solutions are as unique as snowflakes. When all is said and done, no two will be alike. However, as time goes on, common patterns emerge that allow us to share best practices in creating an EAI solution. We still need to travel further down the road before we can see the entire picture. But we're getting there. We're getting there.