
Synchronization
This section describes how Sun Cluster 3.0 architecture handles the complex synchronization problems and issues including those presented in “Data Synchronization”.
Only applications that are crash tolerant can benefit from running on a Sun Cluster 3.0 system. Crash tolerant means the application can recover data or state consistency after a system or application crash without operator intervention. RDBMS such as Oracle, Sybase, Informix, and IBM DB2 are primary examples of applications that are crash tolerant. Their use of log files to track committed transactions enables them to synchronize the data files automatically after a server or software crash.
Applications that simply write data to a file system with the expectation that the data is guaranteed to be on disk generally do not benefit. The reason is that Sun Cluster 3.0 does not introduce any new interfaces that change the way in which an application interacts with the operating system. In fact, a primary goal of the design of Sun Cluster 3.0 is to maintain compatibility with existing Solaris operating environment and POSIX interfaces to enable applications to run unchanged, unaware that they are now running on a cluster. Therefore, if the failure of a server that is hosting such an application requires administrator intervention to recover its integrity, the same is true on a clustered system.
Data Services and Application Agents
A data service is an application running on a cluster and made highly available through a collection of scripts and programs that provide start, stop, and monitoring capabilities. Sun Cluster 3.0 supports three types of data service: failover, parallel, and scalable. Scalable data services rely on the new global networking and file system functions introduced in Sun Cluster 3.0.
Sun Cluster 3.0 supports a growing list of data services from Sun and independent software vendors. Currently, these data services include:
Apache Web Server
Apache Proxy Server
Domain Name Service (DNS)
IBM DB2 Enterprise Edition and Extended Enterprise Edition
IBM Informix Dynamic Server
iPlanet Directory Server
iPlanet Mail Server
iPlanet Web Server
Netscape Directory Server (LDAP)
Network File System (NFS)
Oracle Server (standard and enterprise editions)
Oracle 8i OPS
Oracle 9i RAC
SAP R/3
Sybase ASE
Agent Application Program Interfaces
Off-the-shelf Sun Cluster 3.0 agents are not available for every application. To enable you to create your own resource types, Sun supplies two APIs with Sun Cluster 3.0: the Resource Management API (RM-API) in the SUNWscsev package) and the higher-level Data Service Development Library (DSDL in the SUNWscsdk package). RM-API provides low-level C and callable shell script interfaces to basic data service operations. DSDL provides a library for accessing information about the cluster. This library enables you to avoid repetitive and error-prone coding.
The SunPlex agent builder, scdsbuilder(1HA), enables customers, professional service staff, and system integrators to build simple application agents very quickly. Accessed through a GUI, the agent builder directs the back-end code generator programs to output C or ksh routines for the resource type being constructed with the DSDL.
Data Service Constructs
Sun Cluster 3.0 takes an object-oriented approach to the creation of the components needed to build highly available and scalable data services. The three main constructs used are the resource type, the resource, and the resource group. The following sections describe the details of each of these constructs.
Resource Types
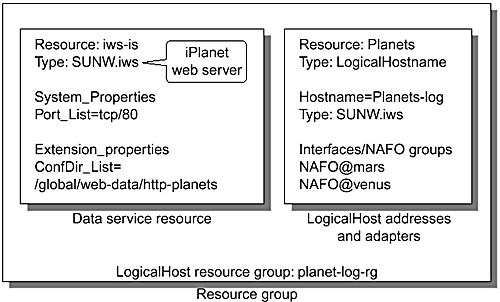
The basic building block for all data services is the resource type package, which Sun Cluster 3.0 also refers to as agents. Sun Cluster 3.0 ships with three standard resource types: SUNW.LogicalHostname, SUNW.SharedAddress, and SUNW.HAStorage.
SUNW.LogicalHostname is the resource type that provides the logical IP address for failover services, such as Oracle or failover web services. This address resource is placed in a failover resource group that is instantiated on one cluster node at any one time. The logical IP address can, for example, be configured on hme0:2. Consequently, the logical IP address is only available to applications that are located on the same cluster node.
SUNW.SharedAddress is the resource type that provides the logical IP address for scalable services, such as the iPlanet and Apache web servers. This address resource is placed in a failover resource group that is instantiated on one cluster node at a time. The logical IP address itself, for example, can be configured on hme0:2 but it is also configured on the loopback interfaces (lo0) of cluster nodes running scalable services that depend on this address.
SUNW.HAStorage is a resource type that enables application resources that depend on global devices or CFS paths to synchronize their startup with the availability of the storage resources upon which they depend. A SUNW.HAStorage resource is placed in an application failover resource group and subsequent application resource definitions are made dependent on it. The relevant devices and path names are specified as extension properties of the SUNW.HAStorage resource.
Assuming you have a license to use additional agents, you can load the Sun resource types from the Sun Cluster agent media by using the scinstall(1M) command, and you can register them in the cluster framework by using scrgadm(1M). If you do not register the resource type, any attempt to create a resource of that type fails and returns an error.
The Solaris package that contains a resource type has all of the methods (programs or shell scripts) needed to start, stop, and monitor the application. In addition, a resource type registration (RTR) file provides the path to methods, the names of the methods, settings for any standard resource properties, and definitions of specific resource extension properties. Registering the resource type with the cluster framework with scrgadm(1M) enables the resource group manager daemon (see “Resource Group Manager Daemon”) to locate the methods necessary to control applications and start them with the right parameter settings. Thus, a general resource type can be written for use by multiple applications, rather than a specific instance of an application.
TABLE 3-3 lists the resource type properties that define all the possible callback methods that can be used to control and monitor a target application. At a minimum, you only need to define the start and stop properties unless you use the prenet or postnet method. The methods can be either compiled programs or shell scripts.
Resources
Resources are instantiations of specific resource types. They inherit all of the methods registered for the resource type with the cluster framework. The definition of a resource will provide specific settings for standard and required extension properties, as defined in the RTR file. These settings can include path names to application configuration files, any TCP/IP ports they listen on, timeout settings, and so on. Multiple resources of a particular resource type can exist within the cluster without modifying the original programs or shell scripts.
Initially, without the application running, the resource is offline. The rgmd calls the application start methods when the resource group that contains the resource goes online.
When one resource relies on another, for example, when an NFS share relies on a running network interface, Sun Cluster 3.0 provides two types of dependency—strong and weak. When other resources, rsB, rsC, and rsD, must be online before a resource, rsA, can start successfully, you can set the resource_dependencies property for rsA to ensure that the resource group manager daemon honors these relationships.
When the dependency is weaker, the resource_dependencies_weak property ensures that rgmd calls the start methods of these resources before that of the dependent resource; that is rsB, rsC, rsD, and then rsA. However, in this case, there is no requirement for the start method to complete before rgmd calls the start method of rsA. To use a mathematical term, the resource dependencies form a directed acyclic graph. The RGM does not permit any cycles (loops) in the overall set of resource dependencies. The start and stop methods for a resource must ensure that the application actually starts or stops before returning control to the calling program.
You can then take resources online and offline individually with the scswitch(1M) command. If any attempt is made to disable a resource on which others depend, the command fails. The scswitch(1M) command is more often used to put whole resource groups online and or to take them offline. See “Resource Groups”. You can also disable monitoring of a specific resource, using the -M flag on the scswitch(1M) command.
Sun Cluster 3.0 supports both failover and scalable resources. A failover resource is one in which a particular invocation of an application can only occur on one node at any one time. A standard HA-Oracle database is a good example of such an application. A scalable resource differs from a failover resource in that it enables a specific instance of an application to run on more than one node at once. Both iPlanet and Apache web servers can be run in a scalable fashion. Today, all the other Sun-supported applications run in failover mode.
Applications must be relatively stateless to run as a scalable resource. This means that instances must not be required to share any state or locking information between them. Because web servers simply serve web pages to a user population, they are ideal candidates for this approach. Currently, no generic mechanism exists to enable state-based applications to coordinate their data access and enable them to run as scalable services. Sun Cluster 3.0 provides the RSM-API, but this API is reserved for use by the Oracle 8i OPS and Oracle 9i RAC products.
For details, see [PL01] at:
http://www.sun.com/software/whitepapers.html#cluster.
For resource types that can be run as a scalable service, you should set the FAILOVER property in the RTR file to false. This setting enables you to set values for maximum_primaries and desired_primaries resource group properties to values greater than one. By changing these values, you can dynamically vary application capacity and resilience in response to user load and business needs.
Resource Groups
Resource groups form the logical container for one or more of the resources described previously. The resources contained in an invocation of a single resource group are all constrained to run on the same node. The rgmd must put a resource group online or offline on one or more nodes. Then, the rgmd on the appropriate cluster nodes calls the methods for the resources in the resource group to start or stop them as appropriate. You can place a resource group in an unmanaged state so the rgmd does not attempt to move it or bring it online when a reconfiguration occurs.
FIGURE 3-15 is an example of a failover resource group configuration.
Figure 3-15. Failover Resource Group Configuration—Example
The rgmd can initiate a resource group migration in response to a scswitch(1M) command request to move a service, or in response to the failure of a node that is currently hosting one or more resource groups.
A failover resource group is only online on one node at a time, and that node hosts all of the resources in that group. In contrast, a scalable resource group can be online on more than one node at a time.
Resource groups also have a dependency property, RG_dependency. This property indicates a preferred order for putting other groups online or offline on the same node. It has no effect if the groups are put online on different nodes.
Resource groups have a number of standard and extension properties that enable fine-grained control of data services on a service-by-service basis. Your system administrator can change these properties while the cluster is running, to enable customers to manage the load on the cluster nodes.
When running multiple data services, you should configure each unrelated service into its own resource group. To maintain optimal performance, each data service should rely, when possible, on separate device groups for their cluster file systems and global device services. This enables you to colocate the primary I/O path with the data service at all times. Multiple instances of an Oracle database server are a good example. When data services depend on one another, they generally benefit from being in the same resource group.
Resource Group Manager Daemon
The rgmd is the user-level program that synchronizes the control of resource groups and resources within the cluster. It uses the cluster configuration repository to discover which user-level programs it must call to enact the relevant resource methods.
When the rgmd must put a resource group online or offline on a given node, it calls the methods for the resources in the resource group to start or stop them as appropriate.
Whenever the cluster membership changes, the kernel cluster membership monitor drives the resource group manager daemon. In turn, rgmd uses the “fork-exec” daemon, rpc.fed, to fork and execute data-service-method programs. These daemons communicate by using local SunRPC calls on each node. The rpc.fed daemon is a multithreaded program that blocks the RPC call until the execution of the program completes or times out, then returns exit status to the caller.
When moving a resource group between nodes, the rgmd must be absolutely certain that a resource has stopped on one node before it restarts the resource on another node. See “Multiple Instances”. If this rule is not strictly enforced, a nonscalable application could be run on more than one node simultaneously and, therefore, corrupt its data. If the rgmd cannot be certain that it stopped the application, it sets a STOP_FAILED flag on the appropriate resource. You must clear this flag manually before the application can be restarted. You can then ensure that the application is actually down before you clear the flag to restart the resource.
The rgmd also enables considerable flexibility in the management of resource and resource group properties without requiring you to take down applications or the cluster. For example, you can add extra nodes to a two-node cluster running a scalable web service. Then, you can modify the scalable web resource group to allow it to run on the new node without stopping the existing web services. Similarly, if a web service is already running three HTTPD instances across a four-node cluster, you can decrease this to two or increase it to four without interrupting service.
Parallel Services
Parallel applications such as Oracle 8i OPS or Oracle 9i RAC are considered special and, as such, are outside the control of the resource group manager. These applications differ from standard Oracle, running in a failover mode, by having multiple instances of Oracle, running on multiple nodes and sharing a common set of data files. Although IBM DB2 is a parallel database, it does not perform concurrent I/O from multiple nodes to the same raw device, a shared disk architecture. Instead it uses a shared-nothing architecture, moving functions and data between nodes to satisfy queries.
Under normal circumstances, Oracle caches data from its data files or tablespaces in its system global area (SGA). Numerous in-memory latches or locks maintain the integrity of SGA by ensuring that multiple users on that server do not corrupt the data through uncontrolled simultaneous access. The latches effectively synchronize the access of users to the underlying data. When the parallel version of Oracle is running, a distributed lock manager (DLM) must keep the data in multiple SGAs coherent and synchronized. This action ensures that data cache integrity is maintained for multiuser access across multiple nodes. The DLM communicates between the nodes through the private interconnect, the implementation of which ensures resilient internode communication.
Unlike the global file service, the Oracle parallel implementations require concurrent local access to the underlying disks from each of the nodes on which it is running. This means that regular disk I/O is not being proxied across the interconnect, as is the case in which a service runs remotely from the primary I/O path. However, when the SGA on one node must share a data block that is currently cached on another, the data is passed between the nodes through the private interconnect. Oracle calls this technology cache fusion. Cache fusion is a new feature in Oracle 9i RAC.