
3
Data Wrangling Dynamics
Simarjit Kaur*, Anju Bala and Anupam Garg
Department of Computer Science and Engineering, Thapar Institute of Engineering and Technology, Patiala, India
Abstract
Data is one of the prerequisites for bringing transformation and novelty in the field of research and industry, but the data available is unstructured and diverse. With the advancement in technology, digital data availability is increasing enormously and the development of efficient tools and techniques becomes necessary to fetch meaningful patterns and abnormalities. Data analysts perform exhaustive and laborious tasks to make the data appropriate for the analysis and concrete decision making. With data wrangling techniques, high-quality data is extracted through cleaning, transforming, and merging data. Data wrangling is a fundamental task that is performed at the initial stage of data preparation, and it works on the content, structure, and quality of data. It combines automation with interactive visualizations to assist in data cleaning. It is the only way to construct useful data to further make intuitive decisions. This paper provides an overview of data wrangling and addresses challenges faced in performing the data wrangling. This paper also focused on the architecture and appropriate techniques available for data wrangling. As data wrangling is one of the major and initial phases in any of the processes, leading to its usability in different applications, which are also explored in this paper.
Keywords: Data acquisition, data wrangling, data cleaning, data transformation
3.1 Introduction
Organizations and researchers are focused on exploring the data to unfold hidden patterns for analysis and decision making. A huge amount of data has been generated every day, which organizations and researchers gather. Data gatheredor collected from different sources such as databases, sensors, surveys is heterogeneous in nature that contains multiple file formats. Initially, this data is raw and needs to be refined and transformed to make it applicable and serviceable. The data is said to be credible if it is recommended by data scientists and analysts and provides valuable insights [1]. Then the data scientist’s job starts, and several data refinement techniques and tools have been deployed to get meaningful data.
The process of data acquisition, merging, cleaning, and transformation is known as data wrangling [2]. The data wrangling process integrates, transforms, clean, and enrich the data and provides an enhanced quality dataset [3]. The main objective is to construct usable data, to convert it into a format that can be easily parsed and manipulated for further analysis. The usefulness of data has been assessed based on the data processing tools such as spreadsheets, statistics packages, and visualization tools. Eventually, the output should be the original representation of the dataset [4]. Future research direction should focus on preserving the data quality and providing efficient techniques to make data usable and reproducible. The subsequent section discusses the research done by several researchers in the field of data wrangling.
3.2 Related Work
As per the literature reviewed, many researchers proposed and implemented data wrangling techniques. Some of the relevant works done by researchers have been discussed here. Furche et al. [5] proposed an automated data wrangling architecture based on the concept of Extract, Transform and Load (ETL) techniques. Data wrangling research challenges and the need to propose techniques to clean and transform the data acquired from several sources. The researchers must provide cost-effective manipulations of big data. Kandel et al. [6] presented research challenges and practical problems faced by data analysts to create quality data. In this paper, several data visualization and transformation techniques have been discussed. The integration of visual interface and automated data wrangling algorithms provide better results.
Braun et al. [7] addressed the challenges organizational researchers face for the acquisition and wrangling of big data. Various sources of significant data acquisition have been discussed, and the authors have presented data wrangling operations applied for making data usable. In the future, data scientists must consider and identify how to acquire and wrangle big data efficiently. Bors et al. [8] proposed an approach for exploring data, and a visual analytics approach has been implemented to capture the data from data wrangling operations. It has been concluded that various data wrangling operations have a significant impact on data quality.
Barrejon et al. [9] has proposed a model based on sequential heterogeneous incomplete variational autoencoders for medical data wrangling operations. The experimentation has been performed on synthetic and real-time datasets to assess the model’s performance, and the proposed model has been concluded as a robust solution to handle missing data. Etati et al. [10] deployed data wrangling operations using power BI query editor for predictive analysis. Power query editor is a tool that has been used for the transformation of data. It can perform data cleaning, reshaping, and data modeling by writing R scripts. Data reshaping and normalization have been implemented.
Rattenbury et al. [11] have provided a framework containing different data wrangling operations to prepare the data for further and insightful analysis. It has covered all aspects of data preparation, starting from data acquisition, cleaning, transformation, and data optimization. Various tools have been available, but the main focus has been on three tools: SQL, Excel, and Trifacta Wrangler. Further, these data wrangling tools have been categorized based on the data size, infrastructure, and data structures supported. The tool selection has been made by analyzing the user’s requirement and the analysis to be performed on the data. However, several researchers have done much work, but still, there are challenges in data wrangling. The following section addresses the data wrangling challenges.
3.3 Challenges: Data Wrangling
Data wrangling is a repetitious process that consumes a significant amount of time. The time-intensive nature of data wrangling is the most challenging factor. Data scientists and analysts say that it takes almost 80% of the time of the whole analysis process [12]. The size of data is increasing rapidly with the growth of information and communication technology. Due to that, organizations have been hiring more technical employees and putting their maximum effort into data preparation, and the complex nature of data is a barrier to identify the hidden patterns present in data. Some of the challenges of data wrangling have been discussed as follows:
- The real time data acquisition is the primary challenge faced by data wrangling experts. The data entered manually may contain errors such as the unknown values at a particular instance of time can be entered wrongly. So the data collected should record accurate measurements that can be further utilized for analysis and decision making.
- Data collected from different sources is heterogeneous that contains different file formats, conventions, and data structures. The integration of such data is a critical task, so incompatible formats and inconsistencies must be fixed before performing data analysis.
- As the amount of data collected over time grows enormously, efficient data wrangling techniques could only process this big data. Also, it becomes difficult to visualize raw data to extract abnormalities and missing values.
- Many transformation tasks have been deployed on data, including extraction, splitting, integration, outlier elimination, and type conversion. The most challenging task is data reformatting and validating required by transformations. Hence data must be transformed into the attributes and features which can be utilized for analysis purposes.
- Some data sources have not provided direct access to data wranglers; due to that, most of the time has been wasted in applying instructions to fetch data.
- The data wrangling tools must be well understood to select appropriate tools from the available tools. Several factors such as data size, data structure, and type of infrastructure influence the data wrangling process. However, these challenges must be addressed and resolved to perform effective data wrangling operations. The subsequent section discusses the architecture of data wrangling.
3.4 Data Wrangling Architecture
Data wrangling is called the most important and tedious step in data analysis, but data analysts have ignored it. It is the process of transforming the data into usable and widely used file formats. Every element of data has been checked carefully or eliminated if it includes inconsistent dates, outdated information, and other technological factors. Finally, the data wrangling process addresses and extracts the most fruitful information present in the data. Data wrangling architecture has been shown in Figure 3.1, and the associated steps have been elaborated as follows:

Figure 3.1 Graphical depiction of the data wrangling architecture.
3.4.1 Data Sources
The initial location where the data has originated or been produced is known as the data source. Data collected from different sources contain heterogeneous data having other characteristics. The data source can be stored on a disk or a remote server in the form of reports, customer or product reviews, surveys, sensors data, web data, or streaming data. These data sources can be of different formats such as CSV, JSON, spreadsheet, or database files that other applications can utilize.
3.4.2 Auxiliary Data
The auxiliary data is the supporting data stored on the disk drive or secondary storage. It includes descriptions of files, sensors, data processing, or the other data relevant to the application. The additional data required can be the reference data, master data, or other domain-related data.
3.4.3 Data Extraction
Data extraction is the process of fetching or retrieving data from data sources. It also merges or consolidates different data files and stores them near the data wrangling application. This data can be further used for data wrangling operations.
3.4.4 Data Wrangling
The process of data wrangling involves collecting, sorting, cleaning, and restructuring data for analysis purposes in organizations. The data must be prepared before performing analysis, and the following steps have been taken in data wrangling:
3.4.4.1 Data Accessing
The first step in data wrangling is accessing the data from the source or sources. Sometimes, data access is invoked by assigning access rights or permissions on the use of the dataset. It involves handling the different locations and relationships among datasets. The data wrangler understands the dataset, what the dataset contains, and the additional features.
3.4.4.2 Data Structuring
The data collected from different sources has no definite shape and structure, so it needs to be transformed to prepare it for the data analytic process. Primarily data structuring includes aggregating and summarizing the attribute values. It seems a simple process that changes the order of attributes for a particular record or row. But on the other side, the complex operations change the order or structure of individual records, and the record fields have been further split into smaller components. Some of the data structuring operations transform and delete few records.
3.4.4.3 Data Cleaning
Data cleaning is also a transformation operation that resolves the quality and consistency of the dataset. Data cleaning includes the manipulation of every field value within records. The most fundamental operation is handling the missing values. Eventually, raw data contain many errors that should be sorted out before processing and passing the data to the next stage. Data cleaning also involves eliminating the outliers, doing corrections, or deleting abnormal data entirely.
3.4.4.4 Data Enriching
At this step, data wranglers become familiar with the data. The raw data can be embellished and augmented with other data. Fundamentally, data enriching adds new values from multiple datasets. Various transformations such as joins and unions have been deployed to combine and blend the records from multiple datasets. Another enriching transformation is adding metadata to the dataset and calculating new attributes from the existing ones.
3.4.4.5 Data Validation
Data validation is the process to verify the quality and authenticity of data. The data must be consistent after applying data-wrangling operation. Different transformations have been applied iteratively and the quality and authenticity of the data have been checked.
3.4.4.6 Data Publication
On the completion of the data validation process, data is ready to be published. It is the final result of data wrangling operations performed successfully. The data becomes available for everyone to perform analysis further.
3.5 Data Wrangling Tools
Several tools and techniques are available for data wrangling and can be chosen according to the requirement of data. There is no single tool or algorithm that suits different datasets. The organizations hire various data wrangling experts based on the knowledge of several statistical or programming languages or understanding of a specific set of tools and techniques. This section presents popular tools deployed for data wrangling:
3.5.1 Excel
Excel is the 30-year-old structuring tool for data refinement and preparation. It is a manual tool used for data wrangling. Excel is a powerful and self-service tool that enhances business intelligence exploration by providing data discovery and access. The following Figure 3.2 shows the missing values filled by using the random fill method in excel. The same column data is used as a random value to replace one or more missing data values in the corresponding column. After preparing the data, it can be deployed for training and testing any machine learning model to extract meaningful insights out of the data values.

Figure 3.2 Image of the Excel tool filling the missing values using the random fill method.
3.5.2 Altair Monarch
Altair Monarch is a desktop-based data wrangling tool having the capability to integrate the data from multiple sources [16]. Data cleaning and several transformation operations can be performed without coding, and this tool contains more than 80 prebuilt data preparation functions.
Altair provides graphical user interface and machine learning capabilities to recommend data enrichment and transformations. The above Figure 3.3 shows the initial steps to open a data file from different sources. First, click on Open Data to choose the data source and search the required file from the desktop or other locations in the memory or network. The data can also be download from the web page and drag it to the start page. Further, data wrangling operations can be performed on the selected data, and prepared data can be utilized for data analytics.
3.5.3 Anzo
Anzo is a graph-based approach offered by Cambridge Semantics for exploring and integrating data. Users can perform data cleaning, data blending operations by connecting internal and external data sources.

Figure 3.3 Image of the graphical user interface of Altair tool showing the initial screen to open a data file from different sources.
The user can add different data layers for data cleansing, transformation, semantic model alignment, relationship linking, and access control operation [19]. The data can be visualized for understanding and describing the data for organizations or to perform analysis. The features and advantages of Anzo Smart Data Lake have been depicted in the following Figure 3.4. It connects the data from different sources and performs data wrangling operations.
3.5.4 Tabula
Tabula is a tool for extracting the data tables out of PDF files as there is no way to copy and paste the data records from PDF files [17]. Researchers use it to convert PDF reports into Excel spreadsheets, CSVs, and JSON files, as shown in Figure 3.5, and further utilized in analysis and database applications.
3.5.5 Trifacta
Trifacta is a data wrangling tool that contains a suite of three iterations: Trifacta Wrangler, Wrangler Edge, and Wrangler Enterprise. It supports various data wrangling operations such as data cleaning, transformation without writing codes manually [14]. It makes data usable and accessible that suits to requirements of anyone. It can perform data structuring, transforming, enriching, and validation. The transformation operation is depicted in Figure 3.6. The users of Trifacta are facilitated with preparing and cleaning data; rather than mailing the excel sheets, the Trifacta platform provides collaboration and interactions among them.
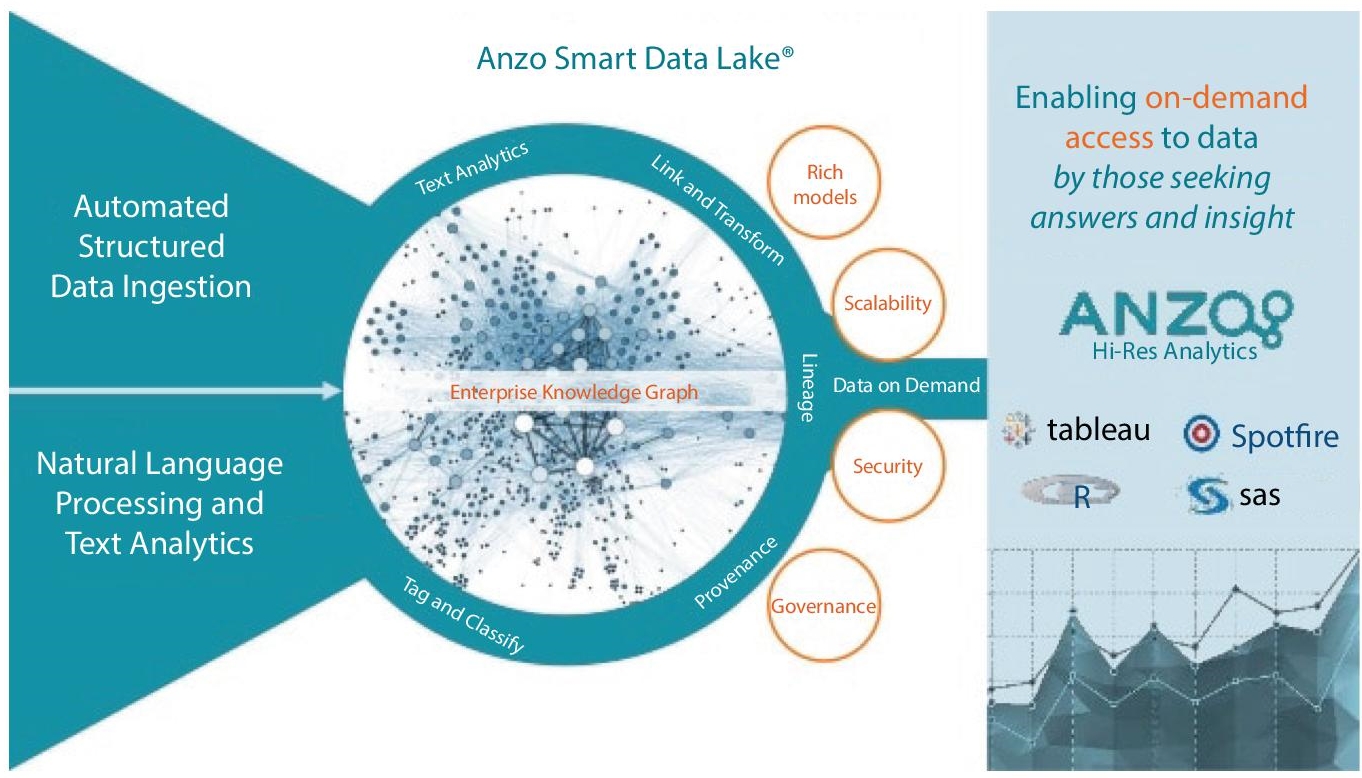
Figure 3.4 Pictorial representation of the features and advantages of Anzo Smart Data Lake tool.
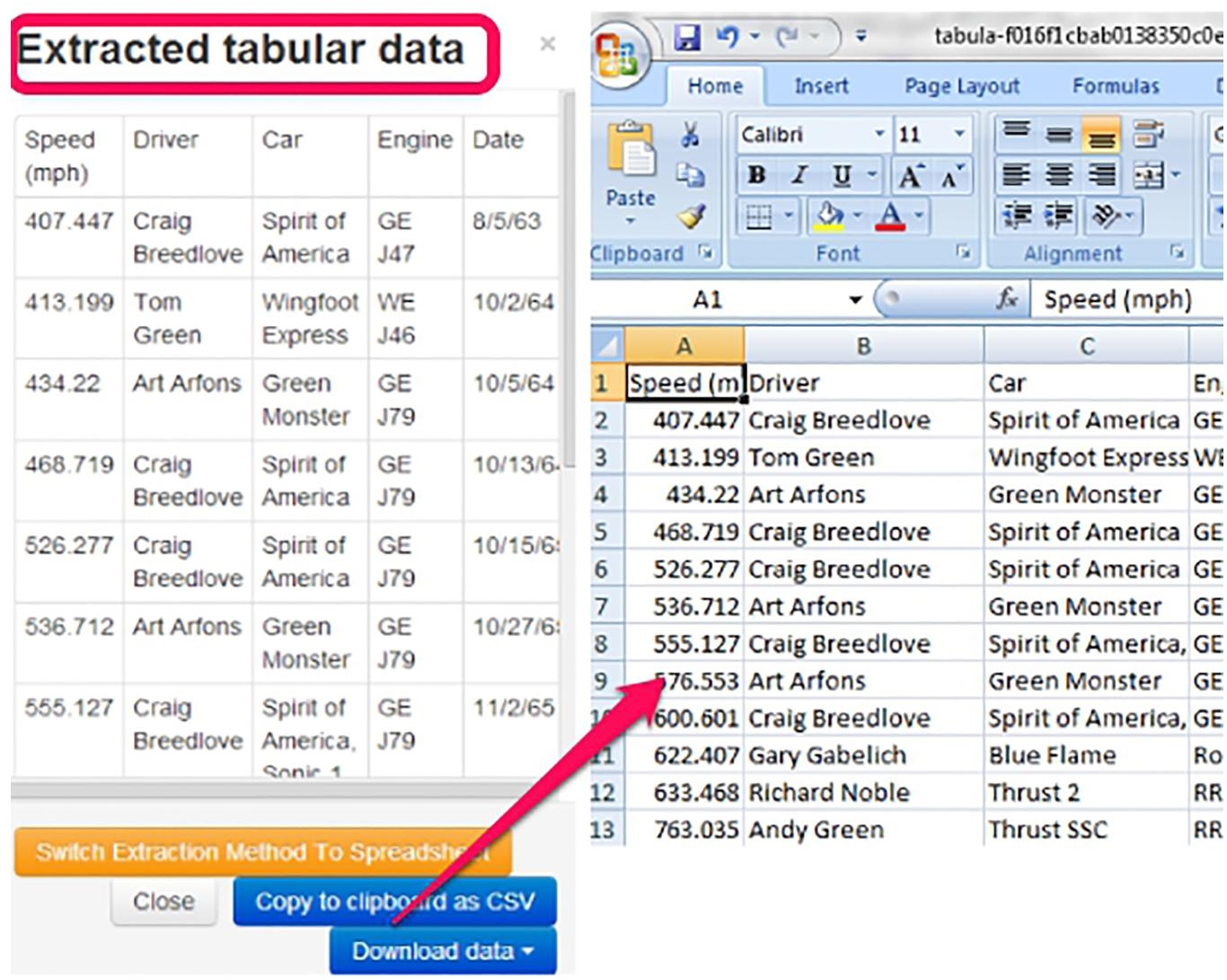
Figure 3.5 Image representing the interface to extract the data files in .pdf format to other formats, such as .xlsx, .csv.

Figure 3.6 Image representing the transformation operation in Trifacta tool.
3.5.6 Datameer
Datameer provides a data analytics and engineering platform that involves data preparation and wrangling tasks. It offers an intuitive and interactive spreadsheet-style interface that facilitates the user with functions like transform, merge and enrich the raw data to make it a readily used format [13]. Figure 3.7 represents how Datameer accepts input from heterogeneous data sources such as CSV, database files, excel files, and the data files from web services or apps. There is no need for coding for cleaning or transforming the data for analysis purposes.
3.5.7 Paxata
Paxata is a self-service data preparation tool that consists of an Adaptive Information Platform. It is a flexible product that can be deployed quickly and provides a visual user interface similar to spreadsheets [18]. Due to it, any user can utilize this tool without learning the tool entirely. Paxata is also enriched with Intelligence that provides machine learning-based suggestions on data wrangling. The graphical interface of Paxata is shown in Figure 3.8 given below, in which data append operation is performed on the particular column.

Figure 3.7 Graphical representation for accepting the input from various heterogeneous data sources and data files from web services and apps.

Figure 3.8 Image depicting the graphical user interface of Paxata tool performing the data append operation on a particular column.

Figure 3.9 Image depicting data preparation process using Talend tool where suggestions are displayed according to columns in the dataset.
3.5.8 Talend
Talend is a data preparation and visualization tool used for data wrangling operations. It has a user-friendly and easy-to-use interface means non-technical people can use it for data preparation [15]. Machine learning-based algorithms have been deployed for data preparation operations such as cleaning, merging, transforming, and standardization. It is an automated product that provides the user with the suggestion at the time of data wrangling. The following Figure 3.9 depicts the data preparation process using Talend, in which recommendations have been displayed according to columns in the dataset.
3.6 Data Wrangling Application Areas
It has been observed that data wrangling is one of the initial and essential phase in any of the framework for the process in order to make the messy and complex data more unified as discussed in the earlier sections. Due to these characteristics, data wrangling is used in various fields of data application such as medical data, different sectors of governmental data, educational data, financial data, etc. Some of the significant applications are discussed below.
A. Database Systems
The data wrangling is used in database systems for cleaning the erroneous data present in them. For industry functioning, high-quality information is one of the major requirements for making crucial decisions, but data quality issues are present in the database systems[25]. Those concerns that exist in the database systems are typing mistakes, non-availability of data, redundant data, inaccurate data, obsolete data, not maintained attributes. Such database system’s data quality is improved using data wrangling. Trifacta Wrangler (discussed in Section 3.5) is one of the tools used to pre-process the data before integrating it into the database [20]. In today’s time, numerous datasets are available publicly over the internet, but they do not have any standard format. So, MacAveny et al. [22] proposed a robust and lightweight tool, ir_datasets, to manage the datasets (textual datasets) available over the internet. It provides the Python and command line-based interface for the users to explore the required information from the documents through ID.
B. Open government data
There is an availability of many open government data that can be brought into effective use, but extracting the usable data in the required form is a hefty task. Konstantinou et al. [2] proposed a data wrangling framework known as value-added data system (VADA). This architecture focuses on all the components of the data wrangling process, automating the process with the use of the available application domain information, using the user feedback for the refinement of results by considering the user’s priorities. This proposed architecture is comparable to ETL and has been demonstrated on real estate data collected from web data and open government data specifying the properties for sale and areas for properties location respectively.
C. Traffic data
A number of domain-independent data wrangling tools have been constructed to overcome the problems of data quality in different applications. Sometimes, using generic data wrangling tools is a time-consuming process and also needs advanced IT skills for traffic analysts. One of the shortcomings for the traffic datasets consisting of data generated from the road sensors is the presence of redundant records of the same moving object. This redundancy can be removed with the use of multiple attributes, such as device MAC address, vehicle identifier, time, and location of vehicle [21]. Another issue present in the traffic datasets is the missing data due to the malfunction of sensors or bad weather conditions affecting the proper functioning of sensors. This can be removed with the use of data with temporal or the same spatial characteristics.
D. Medical data
The datasets available in real time is heterogeneous data that contain artifacts. Such scenarios are mainly functional with the medical datasets as they have information from numerous resources, such as doctor’s diagnosis, patient reports, monitoring sensors, etc. Therefore, to manage such dataset artifacts in medical datasets, Barrejón et al. [9] proposed the data wrangling tool using sequential variational autoencoders (VAEs) using the Shi-VAE methodology. This tool’s performance is analyzed on the intensive care unit and passive human monitoring datasets based on root mean square error (RMSE) metrics. Ceusters et al. [23] worked on the ontological datasets proposing the technique based on referent tracking. In this, a template is presented for each dataset applied to each tuple in it, leading to the generation of referent tracking tuples created based on the unique identifier.
E. Journalism data
Journalism is one field where the journalist uses a lot of data and computations to report the news. To extract the relevant and accurate information, data wrangling is one of the journalist’s significant tasks. Kasica et al. [24] have studied 50 publically available repositories and analysis code authored by 33 journalists. The authors have observed the extensive use of multiple tables in data wrangling on computational journalism. The framework is proposed for general mutitable data wrangling, which will support computational journalism and be used for general purposes.
In this section, the broad application areas have been explored, but the exploration can still not be made for the day-to-day wrangling processes.
3.7 Future Directions and Conclusion
In this technological era, having appropriate and accurate data is one of the prerequisites. To achieve this prerequisite, data analysts need to spend ample time producing quality data. Although data wrangling approaches are defined to achieve this target, data cleaning and integration are still one of the persistent issues present in the database community. This paper examines the basic terminology, challenges, architecture, tools available, and application areas of data wrangling.
Although the researchers highlighted the challenges, gaps, and potential solutions in the literature, there is still much room that can be explored in the future. There is a need to integrate the visual approaches with the existing techniques to extend the impact of the data wrangling process. The specification of the presence of errors and their fixation in the visual approaches should also be mentioned to better understand and edit operations through the user. The data analyst needs to be well expertise in the field of programming and the specific application area to utilize the relevant operations and tools for data wrangling to extract the meaningful insights of data.
References
- 1. Sutton, C., Hobson, T., Geddes, J., Caruana, R., Data diff: Interpretable, executable summaries of changes in distributions for data wrangling, in: Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 2279–2288, 2018.
- 2. Konstantinou, N., Koehler, M., Abel, E., Civili, C., Neumayr, B., Sallinger, E., The VADA architecture for cost-effective data wrangling, in: Proceedings of ACM International Conference on Management of Data, pp. 1599–1602, 2017.
- 3. Bogatu, A., Paton, N.W., Fernandes, A.A., Towards automatic data format transformations: Data wrangling at scale, in: British International Conference on Databases, pp. 36–48, 2017.
- 4. Koehler, M., Bogatu, A., Civili, C., Konstantinou, N., Abel, E., Fernandes, A.A., Paton, N.W., Data context informed data wrangling, in: 2017 IEEE International Conference on Big Data (Big Data), pp. 956–963, 2017.
- 5. Furche, T., Gottlob, G., Libkin, L., Orsi, G., Paton, N.W., Data wrangling for big data: Challenges and opportunities, in: EDBT, vol. 16, pp. 473–478, 2016.
- 6. Kandel, S., Heer, J., Plaisant, C., Kennedy, J., Van Ham, F., Riche, N.H., Buono, P., Research directions in data wrangling: Visualizations and transformations for usable and credible data. Inf. Vis., 10, 4, 271–288, 2011.
- 7. Braun, M.T., Kuljanin, G., DeShon, R.P., Special considerations for the acquisition and wrangling of big data. Organ. Res. Methods, 21, 3, 633–659, 2018.
- 8. Bors, C., Gschwandtner, T., Miksch, S., Capturing and visualizing provenance from data wrangling. IEEE Comput. Graph. Appl., 39, 6, 61–75, 2019.
- 9. Barrejón, D., Olmos, P. M., Artés-Rodríguez, A., Medical data wrangling with sequential variational autoencoders. IEEE J. Biomed. Health Inform., 2021.
- 10. Etaati, L., Data wrangling for predictive analysis, in: Machine Learning with Microsoft Technologies, Apress, Berkeley, CA, pp. 75–92, 2019.
- 11. Rattenbury, T., Hellerstein, J. M., Heer, J., Kandel, S., Carreras, C., Principles of data wrangling: Practical techniques for data preparation. O'Reilly Media, Inc., 2017.
- 12. Abedjan, Z., Morcos, J., Ilyas, I.F., Ouzzani, M., Papotti, P., Stonebraker, M., Dataxformer: A robust transformation discovery system, in: 2016 IEEE 32nd International Conference on Data Engineering (ICDE), pp. 1134–1145, 2016.
- 13. Datameer, Datameer spectrum, September 20, 2021. https://www.datameer.com/spectrum/.
- 14. Kosara, R., Trifacta wrangler for cleaning and reshaping data, September 29, 2021. https://eagereyes.org/blog/2015/trifacta-wrangler-for-cleaning-and-reshaping-data.
- 15. Zaharov, A., Datalytyx an overview of talend data preparation (beta), September 29, 2021. https://www.datalytyx.com/an-overview-of-talend-data-preparation-beta/.
- 16. Altair.com/Altair Monarch, Altair monarch self-service data preparation solution, September 29, 2021. https://www.altair.com/monarch.
- 17. Tabula.technology, Tabula: Extract tables from PDFs, September 29, 2021. https://tabula.technology/.
- 18. DataRobot | AI Cloud, Data preparation, September 29, 2021. https://www.paxata.com/self-service-data-prep/.
- 19. Cambridge Semantics, Anzo Smart Data Lake 4.0-A Data Lake Platform for the Enterprise Information Fabric [Slideshare], September 29, 2021, https://www.cambridgesemantics.com/anzo-smart-data-lake-4-0-data-lake-platform-enterprise-information-fabric-slideshare/.
- 20. Azeroual, O., Data wrangling in database systems: Purging of dirty data. Data, 5, 2, 50, 2020.
- 21. Sampaio, S., Aljubairah, M., Permana, H.A., Sampaio, P.A., Conceptual approach for supporting traffic data wrangling tasks. Comput. J., 62, 461– 480, 2019.
- 22. MacAvaney, S., Yates, A., Feldman, S., Downey, D., Cohan, A., Goharian, N., Simplified data wrangling with ir_datasets, Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2429–2436, 2021.
- 23. Ceusters, W., Hsu, C.Y., Smith, B., Clinical data wrangling using ontological realism and referent tracking, in: Proceedings of the Fifth International Conference on Biomedical Ontology (ICBO), pp. 27–32, 2014.
- 24. Kasica, S., Berret, C., Munzner, T., Table scraps: An actionable framework for multi-table data wrangling from an artifact study of computational journalism. IEEE Trans. Vis. Comput. Graph., 27, 2, 957–966, 2020.
- 25. Swetha, K.R., Niranjanamurthy, M., Amulya, M.P., Manu, Y.M., Prediction of pneumonia using big data, deep learning and machine learning techniques. 2021 6th International Conference on Communication and Electronics Systems (ICCES), pp. 1697–1700, 2021, doi: 10.1109/ICCES51350.2021.9489188.
Note
- *Corresponding author: [email protected]