
Chapter 9
Software and Hardware Development Security
Software ranging from customer-facing applications and services to smaller programs, down to the smallest custom scripts written to support business needs, is everywhere in our organizations. That software runs on hardware that brings its own security requirements and risks. Ensuring that that software and hardware is secure is an important part of a security professional's skillset.
The process of designing, creating, supporting, and maintaining that software is known as the software development life cycle (SDLC). As a security practitioner, you need to understand the SDLC and its security implications to ensure that the software your organization uses is well written and secure throughout its lifespan.
In this chapter you will learn about major SDLC models and the reasons for choosing them, as well as the architectures they are implemented to support. You will learn about secure coding best practices and tools, and software assessment methods and techniques. As part of this, you will see how software is tested and reviewed and how these processes fit into the SDLC. You will learn about code review and inspection methodologies like pair programming and over-the-shoulder code reviews as well as Fagan inspection that can help ensure that the code your organization puts into production is ready to face both users and attackers.
In addition, you will learn about hardware assurance best practices ranging from trusted foundries and supply chain security to secure processing and specific hardware security concepts and techniques.
Software Assurance Best Practices
Building, deploying, and maintaining software requires security involvement throughout the software's life cycle. The CySA+ exam objectives focus on the software development life cycle, software assessment methods and tools, coding practices, platforms, and architectures.
The Software Development Life Cycle
The software development life cycle (SDLC) describes the steps in a model for software development throughout its life. As shown in Figure 9.1, it maps software creation from an idea to requirements gathering and analysis to design, coding, testing, and rollout. Once software is in production, it also includes user training, maintenance, and decommissioning at the end of the software package's useful life.
Software development does not always follow a formal model, but most enterprise development for major applications does follow most, if not all, of these phases. In some cases, developers may even use elements of an SDLC model without realizing it!
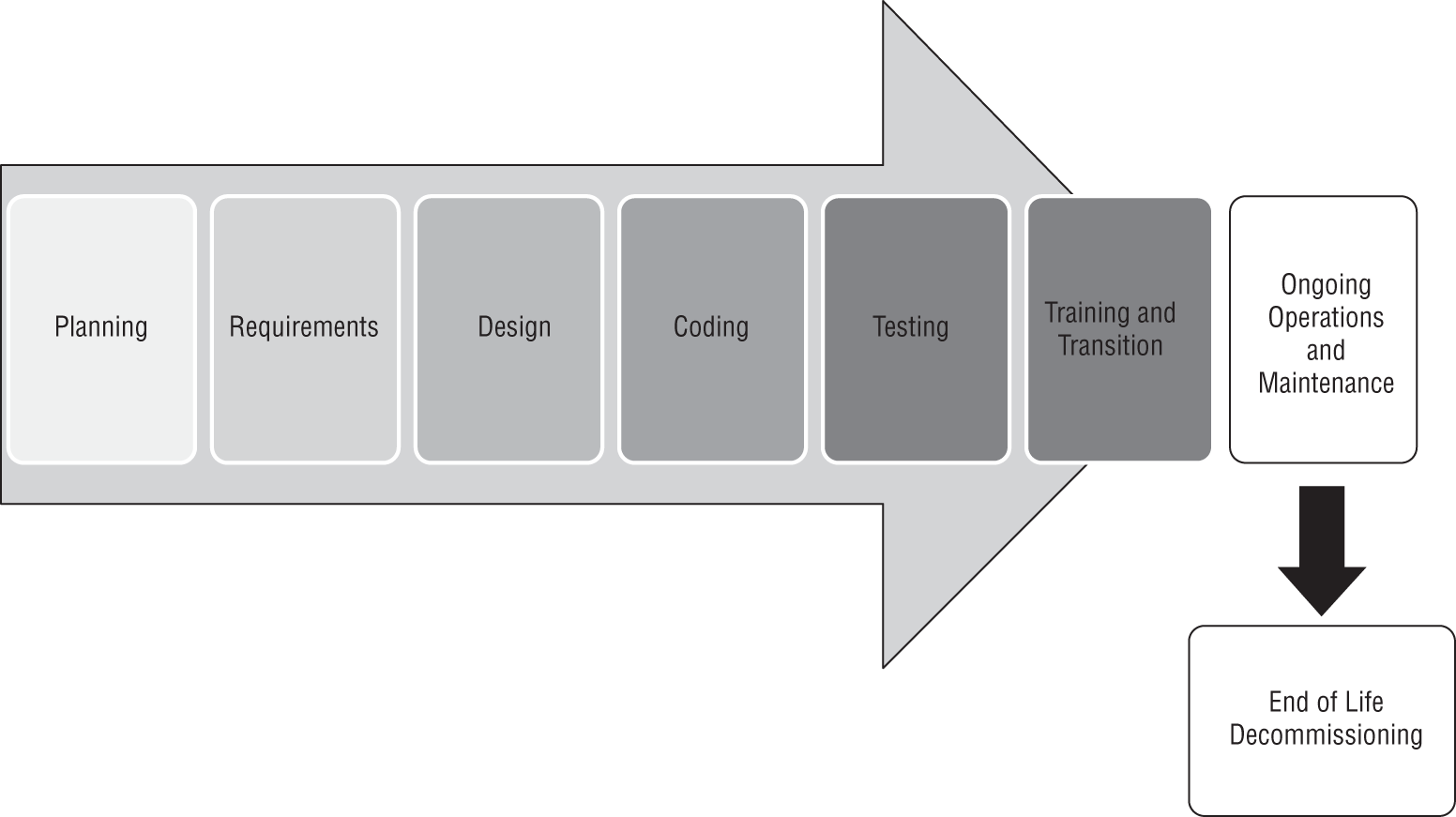
FIGURE 9.1 High-level SDLC view
The SDLC is useful for organizations and for developers because it provides a consistent framework to structure workflow and to provide planning for the development process. Despite these advantages, simply picking an SDLC model to implement may not always be the best choice. Each SDLC model has certain types of work and projects that it fits better than others, making choosing an SDLC model that fits the work an important part of the process.
Software Development Phases
Regardless of which SDLC or process is chosen by your organization, a few phases appear in most SDLC models:
- The feasibility phase is where initial investigations into whether the effort should occur are conducted. Feasibility also looks at alternative solutions and high-level costs for each solution proposed. It results in a recommendation with a plan to move forward.
- Once an effort has been deemed feasible, it will typically go through an analysis and requirements definition phase. In this phase customer input is sought to determine what the desired functionality is, what the current system or application currently does and doesn't do, and what improvements are desired. Requirements may be ranked to determine which are most critical to the success of the project.
- The design phase includes design for functionality, architecture, integration points and techniques, dataflows, business processes, and any other elements that require design consideration.
- The actual coding of the application occurs during the development phase. This phase may involve testing of parts of the software, including unit testing (testing of small components individually to ensure they function properly) and code analysis.
- Although some testing is likely to occur in the development phase, formal testing with customers or others outside of the development team occurs in the testing and integration phase. Individual units or software components are integrated and then tested to ensure proper functionality. In addition, connections to outside services, data sources, and other integration may occur during this phase. During this phase user acceptance testing (UAT) occurs to ensure that the users of the software are satisfied with its functionality.
- The important task of ensuring that the end users are trained on the software and that the software has entered general use occurs in the training and transition phase. This phase is sometimes called the acceptance, installation, and deployment phase.
- Once a project reaches completion, the application or service will enter what is usually the longest phase: ongoing operations and maintenance. This phase includes patching, updating, minor modifications, and other work that goes into daily support.
- The disposition phase occurs when a product or system reaches the end of its life. Although disposition is often ignored in the excitement of developing new products, it is an important phase for a number of reasons: shutting down old products can produce cost savings, replacing existing tools may require specific knowledge or additional effort, and data and systems may need to be preserved or properly disposed of.
The order of the phases may vary, with some progressing in a simple linear fashion and others taking an iterative or parallel approach. You will still see some form of each of these phases in successful software life cycles.
Software Development Models
The SDLC can be approached in many ways, and over time a number of formal models have been created to help provide a common framework for development. While formal SDLC models can be very detailed, with specific practices, procedures, and documentation, many organizations choose the elements of one or more models that best fit their organizational style, workflow, and requirements.
Waterfall
The Waterfall methodology is a sequential model in which each phase is followed by the next phase. Phases do not overlap, and each logically leads to the next. A typical six-phase Waterfall process is shown in Figure 9.2. In Phase 1, requirements are gathered and documented. Phase 2 involves analysis intended to build business rules and models. In Phase 3, a software architecture is designed, and coding and integration of the software occurs in Phase 4. Once the software is complete, Phase 5 occurs, with testing and debugging being completed in this phase. Finally the software enters an operational phase, with support, maintenance, and other operational activities happening on an ongoing basis.

FIGURE 9.2 The Waterfall SDLC model
Waterfall has been replaced in many organizations because it is seen as relatively inflexible, but it remains in use for complex systems. Since Waterfall is not highly responsive to changes and does not account for internal iterative work, it is typically recommended for development efforts that involve a fixed scope and a known timeframe for delivery and that are using a stable, well-understood technology platform.
Spiral
The Spiral model uses the linear development concepts from the Waterfall model and adds an iterative process that revisits four phases multiple times during the development life cycle to gather more detailed requirements, design functionality guided by the requirements, and build based on the design. In addition, the Spiral model puts significant emphasis on risk assessment as part of the SDLC, reviewing risks multiple times during the development process.
The Spiral model shown in Figure 9.3 uses four phases, which it repeatedly visits throughout the development life cycle:
- Identification, or requirements gathering, which initially gathers business requirements, system requirements, and more detailed requirements for subsystems or modules as the process continues.
- Design, conceptual, architectural, logical, and sometimes physical or final design.
- Build, which produces an initial proof of concept and then further development releases until the final production build is produced.
- Evaluation, which involves risk analysis for the development project intended to monitor the feasibility of delivering the software from a technical and managerial viewpoint. As the development cycle continues, this phase also involves customer testing and feedback to ensure customer acceptance.

FIGURE 9.3 The Spiral SDLC model
The Spiral model provides greater flexibility to handle changes in requirements as well as external influences such as availability of customer feedback and development staff. It also allows the software development life cycle to start earlier in the process than Waterfall does. Because Spiral revisits its process, it is possible for this model to result in rework or to identify design requirements later in the process that require a significant design change due to more detailed requirements coming to light.
Agile
Agile software development is an iterative and incremental process, rather than the linear processes that Waterfall and Spiral use. Agile is rooted in the Manifesto for Agile Software Development, a document that has four basic premises:
- Individuals and interactions are more important than processes and tools.
- Working software is preferable to comprehensive documentation.
- Customer collaboration replaces contract negotiation.
- Responding to change is key, rather than following a plan.
If you are used to a Waterfall or Spiral development process, Agile is a significant departure from the planning, design, and documentation-centric approaches that Agile's predecessors use. Agile methods tend to break work up into smaller units, allowing work to be done more quickly and with less up-front planning. It focuses on adapting to needs, rather than predicting them, with major milestones identified early in the process but subject to change as the project continues to develop.
Work is typically broken up into short working sessions, called sprints, that can last days to a few weeks. Figure 9.4 shows a simplified view of an Agile project methodology with multiple sprints conducted. When the developers and customer agree that the task is done or when the time allocated for the sprints is complete, the development effort is completed.
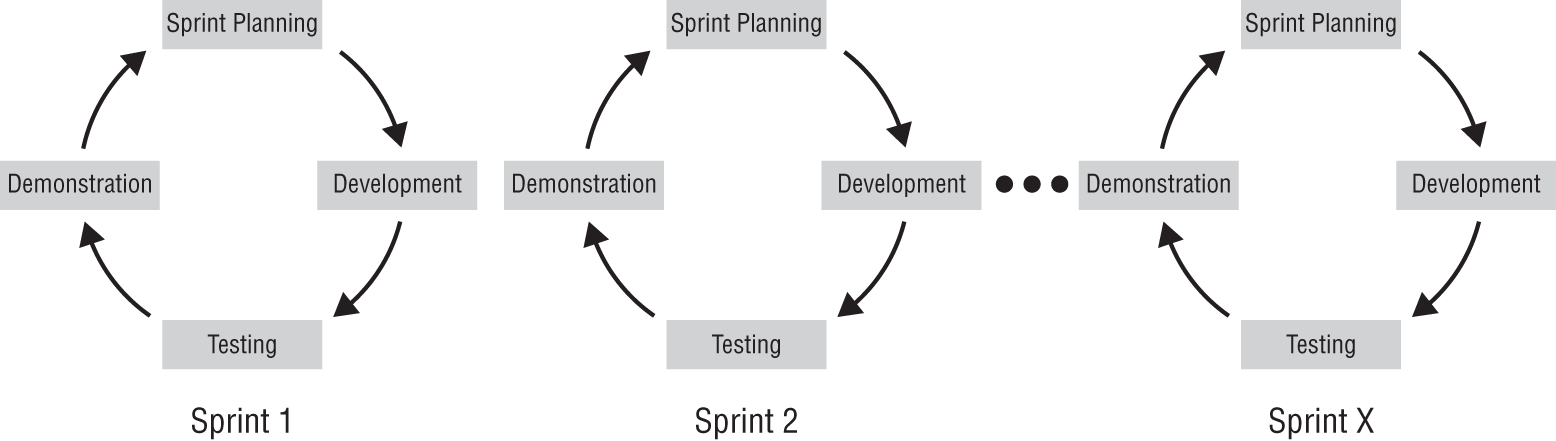
FIGURE 9.4 Agile sprints
The Agile methodology is based on 12 principles:
- Ensure customer satisfaction via early and continuous delivery of the software.
- Welcome changing requirements, even late in the development process.
- Deliver working software frequently (in weeks rather than months).
- Ensure daily cooperation between developers and businesspeople.
- Projects should be built around motivated individuals who get the support, trust, and environment they need to succeed.
- Face-to-face conversations are the most efficient way to convey information inside the development team.
- Progress is measured by having working software.
- Development should be done at a sustainable pace that can be maintained on an ongoing basis.
- Pay continuous attention to technical excellence and good design.
- Simplicity—the art of maximizing the amount of work not done—is essential.
- The best architectures, requirements, and designs emerge from self-organizing teams.
- Teams should reflect on how to become more effective and then implement that behavior at regular intervals.
These principles drive an SDLC process that is less formally structured than Spiral or Waterfall but that has many opportunities for customer feedback and revision. It can react more nimbly to problems and will typically allow faster customer feedback—an advantage when security issues are discovered.
Agile development uses a number of specialized terms:
- Backlogs are lists of features or tasks that are required to complete a project.
- Planning poker is a tool for estimation and planning used in Agile development processes. Estimators are given cards with values for the amount of work required for a task. Estimators are asked to estimate, and each reveals their “bid” on the task. This is done until agreement is reached, with the goal to have estimators reach the same estimate through discussion.
- Timeboxing, a term that describes the use of timeboxes. Timeboxes are a previously agreed-on time that a person or team uses to work on a specific goal. This limits the time to work on a goal to the timeboxed time, rather than allowing work until completion. Once a timebox is over, the completed work is assessed to determine what needs to occur next.
- User stories are collected to describe high-level user requirements. A user story might be “Users can change their password via the mobile app,” which would provide direction for estimation and planning for an Agile work session.
- Velocity tracking is conducted by adding up the estimates for the current sprint's effort and then comparing that to what was completed. This tells the team whether they are on track, faster, or slower than expected.
Rapid Application Development
The RAD (Rapid Application Development) model is an iterative process that relies on building prototypes. Unlike many other methods, there is no planning phase; instead, planning is done as the software is written. RAD relies on functional components of the code being developed in parallel and then integrated to produce the finished product. Much like Agile, RAD can provide a highly responsive development environment.
RAD involves five phases, as shown in Figure 9.5.
- Business modeling, which focuses on the business model, including what information is important, how it is processed, and what the business process should involve.
- Data modeling, including gathering and analyzing all datasets and objects needed for the effort and defining their attributes and relationships.
- Process modeling for dataflows based on the business model, as well as process descriptions for how data is handled.
- Application generation through coding and use of automated tools to convert data and process models into prototypes.
- Testing and turnover, which focuses on the dataflow and interfaces between components since prototypes are tested at each iteration for functionality.

FIGURE 9.5 Rapid Application Development prototypes
Other Models
While we have discussed some of the most common models for software development, others exist, including the following:
- The V model, which is an extension of the Waterfall model that pairs a testing phase with each development stage. Each phase starts only after the testing for the previous phase is done. Thus, at the requirements phase the requirements are reviewed (or tested), and at design phase, a test phase for the system design is completed before starting coding.
- The Big Bang SDLC model relies on no planning or process. Instead, it focuses on making resources available and simply starting coding based on requirements as they are revealed. Obviously the Big Bang model doesn't scale, but it is a common model for individual developers working on their own code.
New SDLC models spread quickly and often influence existing models with new ideas and workflows. Understanding the benefits and drawbacks of each SDLC model can help you provide input at the right times to ensure that the software that is written meets the security requirements of your organization.
DevSecOps and DevOps
DevOps combines software development and IT operations with the goal of optimizing the SDLC. This is done by using collections of tools called toolchains to improve the coding, building and test, packaging, release, configuration and configuration management, and monitoring elements of a software development life cycle.
Of course, DevOps should have security baked into it as well. The term DevSecOps describes security as part of the DevOps model. In this model, security is a shared responsibility that is part of the entire development and operations cycle. That means integrating security into the design, development, testing, and operational work done to produce applications and services.
The role of security practitioners in a DevSecOps model includes threat analysis and communications, planning, testing, providing feedback, and of course ongoing improvement and awareness responsibilities. To do this requires a strong understanding of the organization's risk tolerance, as well as awareness of what the others involved in the DevSecOps environment are doing and when they are doing it. DevOps and DevSecOps are often combined with continuous integration and continuous deployment methodologies where they can rely on automated security testing, and integrated security tooling including scanning, updates, and configuration management tools to help ensure security.
Continuous Integration and Continuous Deployment
Continuous integration (CI) is a development practice that checks code into a shared repository on a consistent ongoing basis. In continuous integration environments, this can range from a few times a day to a very frequent process of check-ins and automated builds.
Since continuous integration relies on an automated build process, it also requires automated testing. It is also often paired with continuous deployment (CD) (sometimes called continuous delivery), which rolls out tested changes into production automatically as soon as they have been tested.
Figure 9.6 shows a view of the continuous integration/continuous deployment pipeline.

FIGURE 9.6 The CI/CD pipeline
Using continuous integration and continuous deployment methods requires building automated security testing into the pipeline testing process. It can result in new vulnerabilities being deployed into production, and could allow an untrusted or rogue developer to insert flaws into code that is deployed, then remove the code as part of a deployment in the next cycle. This means that logging, reporting, and monitoring must all be designed to fit the CI/CD process.
Designing and Coding for Security
Participating in the SDLC as a security professional provides significant opportunities to improve the security of applications. The first chance to help with software security is in the requirements gathering and design phases when security can be built in as part of the requirements and then designed in based on those requirements. Later, during the development process, secure coding techniques, code review, and testing can improve the quality and security of the code that is developed.
During the testing phase, fully integrated software can be tested using tools like web application security scanners or penetration testing techniques. This also provides the foundation for ongoing security operations by building the baseline for future security scans and regression testing during patching and updates. Throughout these steps, it helps to understand the common security issues that developers face, create, and discover.
Common Software Development Security Issues
A multitude of development styles, languages, frameworks, and other variables may be involved in the creation of an application, but many of the same security issues are the same regardless of which you use. In fact, despite many development frameworks and languages providing security features, the same security problems continue to appear in applications all the time! Fortunately, a number of common best practices are available that you can use to help ensure software security for your organization.
There are many software flaws that you may encounter as a security practitioner, but the CySA+ exam focuses on some of the most common, such as the following:
- Improper error handling, which often results in error messages that shouldn't be exposed outside of a secure environment being accessible to attackers or the general public. Since errors often include detailed information about what is going on at the moment the error occurs, attackers can use them to learn about the application, databases, or even to get stack trace information providing significant detail they can leverage in further attacks. Errors that don't appear to provide detailed information can still allow attackers to learn more about the application, as differing responses can give attackers clues about how successful their efforts are. As a security practitioner, you should pay careful attention to application vulnerability reports that show accessible error messages, as well as the content of those messages.
- Dereferencing issues are often due to null pointer dereferences. This means that a pointer with a value of NULL (in other words, one that isn't set) is used as though it contains an expected value. This type of error almost always leads to a crash unless caught by an error handler. Race conditions, like those mentioned in a moment, are also a common place to find a dereferencing issue.
- Insecure object references occur when applications expose information about internal objects, allowing attackers to see how the object is identified and stored in a backend storage system. Once an attacker knows that, they may be able to leverage the information to gain further access, or to make assumptions about other data objects that they cannot view in this way.
- Race conditions rely on timing. An application that needs to take action on an object may be sensitive to what is occurring or has occurred to that object. Although race conditions are not always reliable, they can be very powerful, and repeated attacks against a race condition can result in attackers succeeding.
- Broken authentication is exactly what it sounds like. Improperly implemented authentication may allow attackers who are not logged in, or who are not logged in as a user with the correct rights, access to resources. Implementing a strong and reliable authentication (and authorization!) system is an important part of application coding.
- Sensitive data exposure may occur when any of a number of flaws are exploited. The simplest version of this is when the application does not properly protect sensitive data, allowing attackers to access it.
- Insecure components include a broad range of issues introduced when a component of an application or service is vulnerable and thus it introduces that vulnerability to the application. Understanding all of the components and modules that make up an application is critical to determining whether it may have known vulnerabilities that exist due to those components.
- Insufficient logging and monitoring will result in being unable to determine what occurred when something does go wrong. Part of a strong security design is determining what should be logged and monitored, ensuring that it is appropriately captured, and then building processes and systems to handle those logs and events so that the right thing happens when they occur.
- Weak or default configurations are common when applications and services are not properly set up or when default settings are used. One common example of this is using a default password for a service or database connection. Many application vulnerability scanners look for these default configurations, making it even easier for attackers to find them.
- Use of insecure functions can make it much harder to secure code. Functions like
strcpy, which don't have critical security features built in, can result in code that is easier for attackers to target. In fact, strcpy is the only specific function that the CySA+ objectives call out, likely because of how commonly it is used for buffer overflow attacks in applications written in C.strcpyallows data to be copied without caring whether the source is bigger than the destination. If this occurs, attackers can place arbitrary data in memory locations past the original destination, possibly allowing a buffer overflow attack to succeed.
Security Implications of Target Platforms
There are many factors that need to be taken into account when looking at software development security. The language that is used, the modules and frameworks that are part of the development process, how testing and validation are done, and of course, the underlying platform that the code will run on are all important. The platform helps to determine what tools you can use, which security capabilities are built in, and many other conditions that impact the software development process.
Mobile platforms have their own operating systems, and their own platform security controls. They also have their own security tools like the iOS Keychain and Face ID. They store data in ways that can be specific to the device, with Android devices often offering both on-board storage and storage via microSD cards, which can make tampering easier for attackers. Most of the common issues for mobile platforms, however, are similar to those found in other platforms. As of this writing, OWASP's most recent mobile vulnerability list includes insecure communication, insecure authentication and authorization, insufficient cryptography, code quality, and reverse engineering—all issues with other platforms.
Embedded systems, or computer systems that are part of a larger system with a small number of dedicated functions, and system-on-chip (SOC) systems, which embed a complete computer in a chip, can provide additional security because they're not as accessible, but that often comes with less frequent updates or an inability to update them easily. Both embedded systems and SOC devices may have hardware, firmware, and software vulnerabilities, and their pervasive nature means that broadly deployed systems are attractive targets for attackers who find them built into the Internet of Things (IoT) or the control planes of utilities, factories, and other infrastructure or critical targets.
One of the most common platforms for applications is the client-server application model. In this model, clients (web browsers, applications, or other clients) communicate with one or more servers that provide information to them. Web applications work this way, and security practitioners need to understand that attacks may be conducted against the clients, against the network, against the traffic sent between the client and server, and against the server itself. Thus, the attack surface of a client-server application is broad, and appropriate security measures must be implemented for each component.
The final platform that the CySA+ 2.2 exam objectives consider is firmware. Firmware is the embedded software used by a computer or hardware device. Firmware flaws can be hard to fix, since not all devices are designed to update their firmware. Attackers who want to target firmware will often seek to acquire a copy of the firmware, either by directly connecting to the device and downloading it or by acquiring the firmware itself from a download site or other means. After that, standard reverse engineering and other software exploitation techniques can be applied to it to identify flaws that may be worth exploiting.
Secure Coding Best Practices
The best practices for producing secure code will vary depending on the application, its infrastructure and backend design, and what framework or language it is written in. Despite that, many of the same development, implementation, and design best practices apply to most applications. These include the following:
- Have a secure coding policy to serve as a foundation for secure development practices and standards.
- Risk assessment is important to understand what risks the application faces and how to prioritize remediation of those issues. Continuous assessment is recommended for applications using regularly scheduled testing tools that can inform the application risk assessment process.
- Input validation helps prevent a wide range of problems, from cross-site scripting (XSS) to SQL injection attacks.
- Output encoding translates special characters into an equivalent but safe version before a target application or interpreter reads it. This helps to prevent XSS attacks by preventing special characters from being inserted that cause the target application to perform an action.
- Web application firewalls (WAFs) can prevent attacks against vulnerable applications and offer a line of defense for applications that don't have an available patch or that cannot be taken offline for patching.
- Error message management, particularly ensuring that error messages do not leak information, is important to ensure that attackers can't use error messages to learn about your applications or systems.
- Database security at both the application and database can help ensure that data leaks don't occur.
- Using parameterized queries, which are precompiled SQL that takes input variables before it is executed. This helps prevent SQL injection attacks.
- Securing sensitive information by encrypting it or storing it using appropriate secure mechanisms (like password hashes for passwords) helps ensure that a breach of a system does not result in broader issues. The CySA+ exam calls this data protection.
- Ensuring availability by performing load and stress testing and designing the application infrastructure to be scalable can prevent outages and may limit the impact of denial-of-service attacks.
- Monitoring and logging should be enabled, centralized, and set to identify both application and security issues.
- Authentication limits access to applications to only authenticated users or systems.
- Use multifactor authentication to help limit the impact of credential compromises.
- Use secure session management to ensure that attackers cannot hijack user sessions or that session issues don't cause confusion among users.
- Cookie management is important for web applications that rely on cookie-based information.
- Secure all network traffic. Encryption of all traffic is a viable option with modern hardware, and it prevents network-based attacks from easily capturing data that could be sensitive.
One of the best resources for secure coding practices is the Open Web Application Security Project (OWASP). OWASP is the home of a broad community of developers and security practitioners, and it hosts many community-developed standards, guides, and best practice documents, as well as a multitude of open source tools. OWASP provides a regularly updated list of proactive controls that is useful to review not only as a set of useful best practices, but also as a way to see how web application security threats change from year to year.
Here are OWASP's current top proactive controls (updated in 2018) with brief descriptions:
- Define Security Requirements Document what security the software needs and how it should be implemented.
- Leverage Security Frameworks and Libraries Use existing security tools to make it easier to develop securely.
- Secure Database Access Databases contain most of the important data in modern applications, making database security a key concern.
- Encode and Escape Data Ensure that attackers can't embed code or special characters in ways that will be executed or otherwise may cause harm to the application.
- Validate All Inputs Treat user input as untrusted and filter appropriately.
- Implement Digital Identity Identity is a core security layer, including things like using multifactor authentication, secure password storage and recovery, and session handling.
- Enforce Access Controls Require all requests to go through access control checks, deny by default, and apply the principle of least privilege.
- Protect Data Everywhere Use encryption in transit and at rest.
- Implement Security Logging and Monitoring This helps detect problems and allows investigation after the fact.
- Handle All Errors and Exceptions Errors should not provide sensitive data, and applications should be tested to ensure that they handle problems gracefully.
You can find OWASP's Proactive Controls list at www.owasp.org/index.php/OWASP_Proactive_Controls, and a useful quick reference guide to secure coding practices is available at www.owasp.org/index.php/OWASP_Secure_Coding_Practices_-_Quick_Reference_Guide.
In addition to the resources provided by OWASP, SANS maintains a list of the top 25 software errors in three categories:
- Insecure Interaction Between Components, which includes issues like SQL and operating system command injection, file upload path issues, cross-site request forgery, and cross-site scripting.
- Risky Resource Management problems, which deal with buffer overflows, path traversal attacks, and other ways that software fails to properly guard system resources.
- Porous Defenses, including not using or misusing defensive techniques like overly permissive rights, hard-coded credentials, missing authorization and authentication, and use of unsalted hashes.
Top listings of common controls and problems are useful as a reminder, but understanding the set of controls that are appropriate to your environment is critical. A thorough assessment with developers and other experts who understand not only the business requirements and process but also the development language or framework will help keep your organization secure.
API Security
Application programming interfaces (APIs) are interfaces between clients and servers or applications and operating systems that define how the client should ask for information from the server and how the server will respond. This definition means that programs written in any language can implement the API and make requests.
APIs are tremendously useful for building interfaces between systems, but they can also be a point of vulnerability if they are not properly secured. API security relies on authentication, authorization, proper data scoping to ensure that too much data isn't released, rate limiting, input filtering, and appropriate monitoring and logging to remain secure. Of course, securing the underlying systems, configuring the API endpoint server or service, and providing normal network layer security to protect the service are also important.
Many security tools and servers provide APIs, and security professionals are often asked to write scripts or programs that can access an API to pull data. In fact, the TAXII and STIX protocol and language we described in Chapter 2, “Using Threat Intelligence,” are a great example of an interface that might be accessed via an API call.
Service-Oriented Architectures
Service-oriented architecture (SOA) is a software design that provides services to components of a system or service via communication protocols on a network. The intent of a SOA design is to allow loosely coupled components to communicate in a standardized way, allowing them to consume and provide data to other components. Developers abstract the service, hiding the complexity of the service and its inner workings, instead providing ways to access the data. Typical components of a service-oriented architecture include service providers, service registries or service brokers that provide listings and information about service providers, and consumers who access the services.
SOAP (Simple Object Access Protocol) is an XML-based messaging protocol that was frequently used for web services. SOAP defines how messages should be formatted and exchanged, how transport of the messages occurs, as well as models for processing them. Like other XML-based protocols, SOAP is extensible, so it can be customized as needed.
RESTful HTTP (REST stands for Representational State Transfer) has largely supplanted SOAP in many use cases because of its greater flexibility. REST APIs follow six architectural constraints: they use a uniform interface, they separate clients and servers, they are stateless (in other words they don't use server-side sessions), they mark whether server responses are cacheable, they are designed to allow layering of services between clients and servers, and they may include client executable code in their responses.
Both REST and SOAP allow developers to create their own APIs, but unlike SOAP, REST is not a protocol—instead, it defines how a RESTful architecture should be designed and built.
As a security professional, you need to know that public and private APIs exist and may be built using various technologies, frameworks, and protocols, including these. The APIs may themselves be vulnerable, and the underlying services, servers, and protocols may be part of the attack surface you need to assess.
Application Testing
Application testing can be conducted in one of four ways: as a scan using a tool, via an automated vulnerability scanner, through manual penetration testing, or via code review. OWASP's Code Review guide notes that code reviews provide the best insight into all the common issues that applications face: availability, business logic, compliance, privacy, and vulnerabilities. Combining code review with a penetration test based on the code review's output (which then drives further code review, known as a 360 review) can provide even more insight into an application's security.
Information Security and the SDLC
Software defects can have a significant impact on security, but creating secure software requires more than just security scans and reviewing code when it is complete. Information security needs to be involved at each part of the SDLC process.
- During the Feasibility phase security practitioners may be asked to participate in initial assessments or cost evaluations.
- The Analysis and Requirements Definition phase should include security requirements and planning for requirements like authentication, data security, and technical security needs.
- Security artifacts created during the Design phase often include security architecture documentation, dataflow diagrams, and other useful information.
- The Development (Implementation) phase involves security testing of the code, code review, and other development-centric security operations.
- Testing and Integration phase tasks include vulnerability testing and additional code review of the completed product. This also occurs when testing of a completely integrated solution can be conducted to ensure that no security issues show up once components are integrated.
- While it may not be immediately evident, there is a security aspect to the Training and Transition phase as well. User training is part of the security posture of an application, and proper training can help ensure that both the users and administrators of an application are using it correctly.
- Operations and Maintenance activities require ongoing scans, patching, and regression testing when upgrades occur.
- Disposition of the systems and data that the application used when its life is over ensures that the end of operations for the application is not the start of a data breach.
Implementing security controls through the software development life cycle can help ensure that the applications that enter production are properly secured and maintained throughout their life cycle. Being fully involved in the SDLC requires security professionals to learn about the tools, techniques, and processes that development teams use, so be ready to learn about how software is created in your organization.
Version Control and Source Code Management
Once the SDLC reaches the development phase, code starts to be generated. That means that the ability to control the version of the software or component that your team is working on, combined with check-in/check-out functionality and revision histories, is a necessary and powerful tool when developing software. Fortunately, version control and source control management tools fill that role.
A strong SDLC requires the ability to determine that the code that is being deployed or tested is the correct version and that fixes that were previously applied have not been dropped from the release that is under development. Popular version control systems include Git, Subversion, and CVS, but there are dozens of different tools in use.
Code Review Models
Reviewing the code that is written for an application provides a number of advantages. It helps to share knowledge of the code, and the experience gained by writing is better than simple documentation alone since it provides personal understanding of the code and its functions. It also helps detect problems while enforcing coding best practices and standards by exposing the code to review during its development cycle. Finally, it ensures that multiple members of a team are aware of what the code is supposed to do and how it accomplishes its task.
There are a number of common code review processes, including both formal and Agile processes like pair programming, over-the-shoulder, and Fagan code reviews.
Pair Programming
Pair programming is an Agile software development technique that places two developers at one workstation. One developer writes code, while the other developer reviews their code as they write it. This is intended to provide real-time code review, and it ensures that multiple developers are familiar with the code that is written. In most pair programming environments, the developers are expected to change roles frequently, allowing both of them to spend time thinking about the code while at the keyboard and to consider the design and any issues in the code while reviewing it.
Pair programming adds additional cost to development since it requires two full-time developers. At the same time, it provides additional opportunities for review and analysis of the code and directly applies more experience to coding problems, potentially increasing the quality of the code.
Over-the-Shoulder
Over-the-shoulder code review also relies on a pair of developers, but rather than requiring constant interaction and hand-offs, over-the-shoulder requires the developer who wrote the code to explain the code to the other developer. This allows peer review of code and can also assist developers in understanding how the code works, without the relatively high cost of pair programming.
Pass-Around Code Reviews
Pass-around code review, sometimes known as email pass-around code review, is a form of manual peer review done by sending completed code to reviewers who check the code for issues. Pass-around reviews may involve more than one reviewer, allowing reviewers with different expertise and experience to contribute their expertise. Although pass-around reviews allow more flexibility in when they occur than an over-the-shoulder review, they don't provide the same easy opportunity to learn about the code from the developer who wrote it that over-the-shoulder and pair programming offer, making documentation more important.
Tool-Assisted Reviews
Tool-assisted code reviews rely on formal or informal software-based tools to conduct code reviews. Tools like Atlassian's Crucible collaborative code review tool, Codacy's static code review tool, and Phabricator's Differential code review tool are all designed to improve the code review process. The wide variety of tools used for code review reflects not only the multitude of software development life cycle options but also how organizations set up their design and review processes.
Choosing a Review Method
Table 9.1 compares the four informal code review methods and formal code review. Specific implementations may vary, but these comparisons will generally hold true between each type of code review. In addition, the theory behind each method may not always reflect the reality of how an organization will use it. For example, pair programming is intended to provide the same speed of development as two developers working on their own while increasing the quality of the code. This may be true for experienced programmers who work well together, but lack of training, personality differences, and variation in work styles can make pair programming less effective than expected.
TABLE 9.1 Code review method comparison
| Cost | When does review happen | Ability to explain the code | Skill required | |
| Pair programming | Medium | Real time | High | Users must know how to pair program |
| Over-the-shoulder | Medium | Real time | High | No additional skill |
| Pass-around code review | Low/Medium | Asynchronous | Low | No additional skill |
| Tool assisted review | Medium | Tool/process dependent | Typically low | Training to use the tool may be required |
| Formal code review | High | Asynchronous | Typically low | Code review process training |
When code requires more in-depth review than the relatively lightweight Agile processes like pass-around and over-the-shoulder reviews, formal code review processes are sometimes used. As you might imagine from the name, formal code reviews are an in-depth, often time-consuming process intended to fully review code using a team of experts. The primary form of formal code review is Fagan inspection.
Fagan Inspection
Fagan inspection is a form of structured, formal code review intended to find a variety of problems during the development process. Fagan inspection specifies entry and exit criteria for processes, ensuring that a process is not started before appropriate diligence has been performed, and also making sure that there are known criteria for moving to the next phase.
The Fagan inspection process in Figure 9.7 shows the six typical phases:
- Planning, including preparation of materials, attendees, and location
- Overview, which prepares the team by reviewing the materials and assigning roles such as coder, reader, reviewer, and moderator
- Preparation, which involves reviewing the code or other item being inspected and documents any issues or questions they may have
- Meeting to identify defects based on the notes from the preparation phase
- Rework to resolve issues
- Follow-up by the moderator to ensure that all issues identified have been found and that no new defects were created during the resolution process

FIGURE 9.7 Fagan code review
Software Security Testing
No matter how talented the development team for an application is, there will be some form of flaws in the code. Veracode's 2019 metrics for applications based on their testing showed that 83 percent of the 1.4 million applications they scanned had at least one security flaw in the initial scan. That number points to a massive need for software security testing to continue to be better integrated into the software development life cycle.
A broad variety of manual and automatic testing tools and methods are available to security professionals and developers. Fortunately, automated tools have continued to improve, providing an easier way to verify that code is more secure. Over the next few pages, we will review some of the critical software security testing methods and tools.
Software Assessment: Testing and Analyzing Code
The source code that is the basis of every application and program can contain a variety of bugs and flaws, from programming and syntax errors to problems with business logic, error handling, and integration with other services and systems. It is important to be able to analyze the code to understand what it does, how it performs that task, and where flaws may occur in the program itself. This is often done via static or dynamic code analysis, along with testing methods like fuzzing, fault injection, mutation testing, and stress testing. Once changes are made to code and it is deployed, it must be regression tested to ensure that the fixes put in place didn't create new security issues.
Static Code Analysis
Static code analysis (sometimes called source code analysis) is conducted by reviewing the code for an application. Since static analysis uses the source code for an application, it can be seen as a type of white-box testing with full visibility to the testers. This can allow testers to find problems that other tests might miss, either because the logic is not exposed to other testing methods or because of internal business logic problems.
Unlike many other methods, static analysis does not run the program; instead, it focuses on understanding how the program is written and what the code is intended to do. Static code analysis can be conducted using automated tools or manually by reviewing the code—a process sometimes called “code understanding.” Automated static code analysis can be very effective at finding known issues, and manual static code analysis helps identify programmer-induced errors.
Dynamic Code Analysis
Dynamic code analysis relies on execution of the code while providing it with input to test the software. Much like static code analysis, dynamic code analysis may be done via automated tools or manually, but there is a strong preference for automated testing due to the volume of tests that need to be conducted in most dynamic code testing processes.
Fuzzing
Fuzz testing, or fuzzing, involves sending invalid or random data to an application to test its ability to handle unexpected data. The application is monitored to determine if it crashes, fails, or responds in an incorrect manner. Because of the large amount of data that a fuzz test involves, fuzzing is typically automated, and it is particularly useful for detecting input validation and logic issues as well as memory leaks and error handling. Unfortunately, fuzzing tends to identify only simple problems; it does not account for complex logic or business process issues and may not provide complete code coverage if its progress is not monitored.
Fault Injection
Unlike fuzzing, fault injection directly inserts faults into error handling paths, particularly error handling mechanisms that are rarely used or might otherwise be missed during normal testing. Fault injection may be done in one of three ways:
- Compile-time injection, which inserts faults by modifying the source code of the application
- Protocol software fault injection, which uses fuzzing techniques to send unexpected or protocol noncompliant data to an application or service that expects protocol-compliant input
- Runtime injection of data into the running program, either by inserting it into the running memory of the program or by injecting the faults in a way that causes the program to deal with them
Fault injection is typically done using automated tools due to the potential for human error in the fault injection process.
Mutation Testing
Mutation testing is related to fuzzing and fault injection, but rather than changing the inputs to the program or introducing faults to it, mutation testing makes small modifications to the program itself. The altered versions, or mutants, are then tested and rejected if they cause failures. The mutations themselves are guided by rules that are intended to create common errors as well as to replicate the types of errors that developers might introduce during their normal programing process. Much like fault injection, mutation testing helps identify issues with code that is infrequently used, but it can also help identify problems with test data and scripts by finding places where the scripts do not fully test for possible issues.
Stress Testing and Load Testing
Performance testing for applications is as important as testing for code flaws. Ensuring that applications and the systems that support them can stand up to the full production load they are anticipated to need is part of a typical SDLC process. When an application is ready to be tested, stress test applications and load testing tools are used to simulate a full application load, and in the case of stress testing, to go beyond any normal level of load to see how the application or system will respond when tested to the breaking point.
Stress testing can also be conducted against individual components of an application to ensure that they are capable of handling load conditions. During integration and component testing, fault injection may also be used to ensure that problems during heavy load are properly handled by the application.
Security Regression Testing
Regression testing focuses on testing to ensure that changes that have been made do not create new issues. From a security perspective, this often comes into play when patches are installed or when new updates are applied to a system or application. Security regression testing is performed to ensure that no new vulnerabilities, misconfigurations, or other issues have been introduced.
Automated testing using tools like web application vulnerability scanners and other vulnerability scanning tools are often used as part of an automated or semiautomated regression testing process. Reports are generated to review the state of the application (and its underlying server and services) before and after changes are made to ensure that it remains secure.
User Acceptance Testing
In addition to the many types of security testing, user acceptance testing (UAT) is an important element in the testing cycle. Once all of the functional and security testing is completed for an application or program, users are asked to validate whether it meets the business needs and usability requirements. Since developers rarely know or perform all of the business functions that the applications they write will perform, this stage is particularly important to validate that things work like they should in normal use.
Ideally UAT should have a formal test plan that involves examples of all of the common business processes that the users of the application will perform. This should be paired with acceptance criteria that indicate what requirements must be satisfied to consider the work acceptable and thus ready to move into production.
Web Application Vulnerability Scanning
Many of the applications our organizations use today are web-based applications, and they offer unique opportunities for testing because of the relative standardization of HTML-based web interfaces. In Chapters 3 and 4 we looked at vulnerability scanning tools like Nessus, Nexpose, and OpenVAS, which scan for known vulnerabilities in systems, services, and, to a limited extent, web applications. Dedicated web application vulnerability scanners provide an even broader toolset specifically designed to identify problems with applications and their underlying web servers, databases, and infrastructure.
Dozens of web application vulnerability scanners are available. Some of the most popular are Acunetix WVS, Arachni, Burp Suite, HCL AppScan, Micro Focus's WebInspect, Netsparker, Qualys's Web Application Scanner, and W3AF.
Web application scanners can be directly run against an application and may also be guided through the application to ensure that they find all the components that you want to test. Like traditional vulnerability scanners, web application scanning tools provide a report of the issues they discovered when they are done. Additional details, including where the issue was found and remediation guidance, is also typically available by drilling down on the report item.
In addition to automated web application vulnerability scanners, manual scanning is frequently conducted to identify issues that automated scanners may not. Manual testing may be fully manual, with inputs inserted by hand, but testers typically use tools called interception proxies that allow them to capture communication between a browser and the web server. Once the proxy captures the information, the tester can modify the data that is sent and received.
A web browser plug-in proxy like Tamper Data for Firefox can allow you to modify session values during a live connection, as shown in Figure 9.8. Using an interception proxy to crawl through an application provides insight into both what data the web application uses and how you could attack the application.
There are a number of popular proxy tools ranging from browser-specific plug-ins like Tamper Data and HttpFox to browser-agnostic tools like Fiddler (which runs as a dedicated proxy). In addition, tools like Burp Suite provide a range of capabilities, including application proxies, spiders, web application scanning, and other advanced tools intended to make web application penetration testing easier.
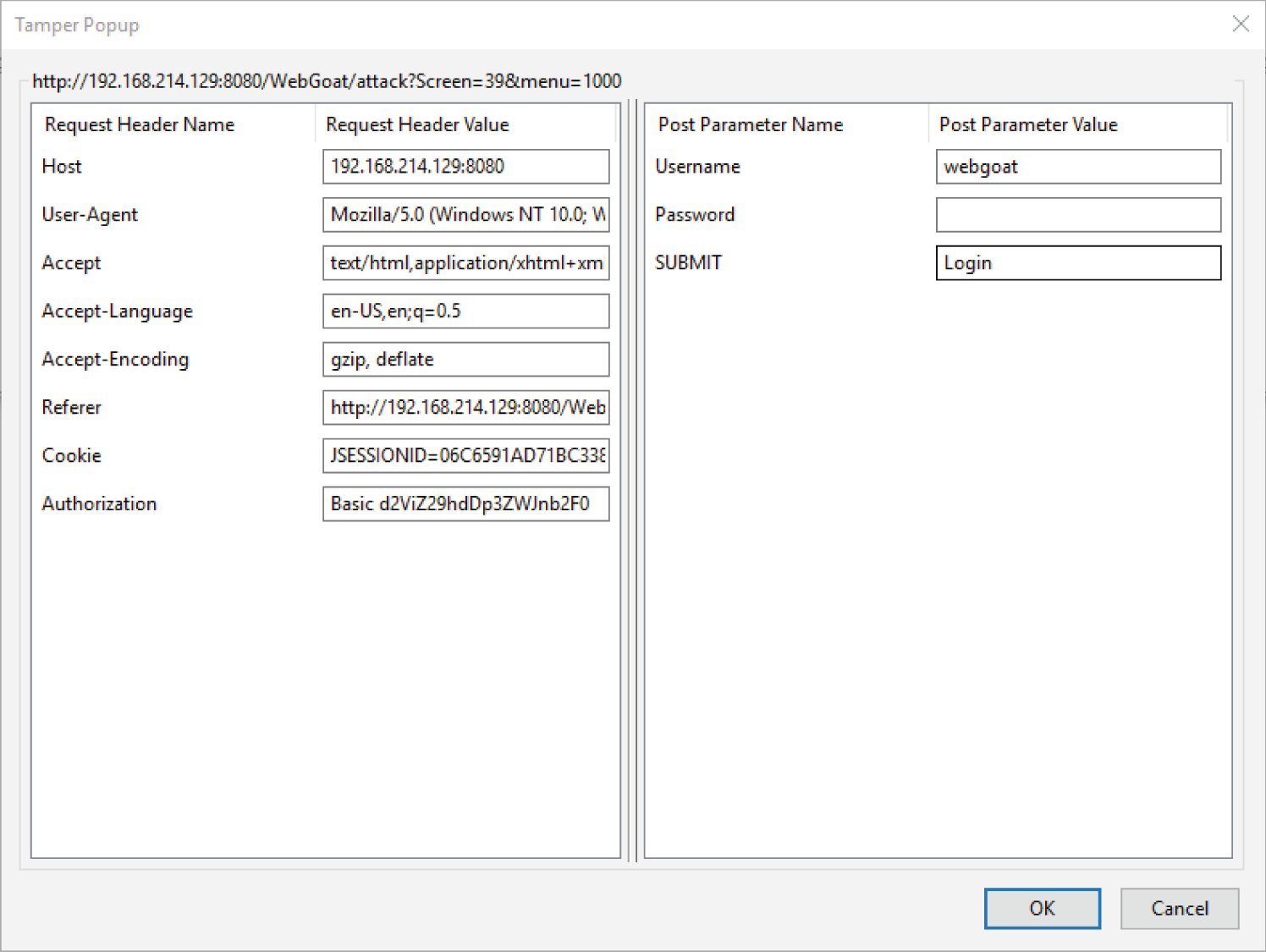
FIGURE 9.8 Tamper Data session showing login data
Hardware Assurance Best Practices
While we often think about software security, the security of the underlying hardware can also be a concern. Checking the individual components built into every device in your organization is likely beyond the capabilities that you will have, but you should know the concepts behind hardware assurance and what to look for if you need to have high assurance levels for your devices and systems.
Cryptographic Hardware
Modern hardware assurance often begins with the hardware root of trust. The hardware root of trust for a system contains the cryptographic keys that secure the boot process. This means that the system or device inherently trusts the hardware root of trust, and that it needs to be secure! One common implementation of a hardware root of trust is the Trusted Platform Module (TPM) chip built into many computers. TPM chips are frequently used to provide built-in encryption, and they provide three major functions:
- Remote attestation, allowing hardware and software configurations to be verified
- Binding, which encrypts data
- Sealing, which encrypts data and sets requirements for the state of the TPM chip before decryption
While TPM chips are one common solution, others include serial numbers that cannot be modified or cloned, and physically unclonable functions (PUFs), which are unique to the specific hardware device that provides a unique identifier or digital fingerprint for the device.
An additional security feature intended to help prevent boot-level malware is measured boot. Measured boot processes measure each component, starting with the firmware and ending with the boot start drivers. The data gathered is stored in a TPM module, and the logs can be validated remotely to let security administrators know the boot state of the system. This allows comparison against known good states, and administrators can take action if the measured boot shows a difference from the accepted or secure known state.
A related technology is hardware security modules (HSMs). Hardware security modules are typically external devices or plug-in cards used to create, store, and manage digital keys for cryptographic functions and authentication, as well as to offload cryptographic processing. HSMs are often used in high-security environments and are normally certified to meet standards like FIPS 140 or Common Criteria standards.
Firmware Security
Other defensive technologies can also help to secure systems. IBM's eFuse technology has a number of uses that can help with tuning performance or responding to system degradation, but it also has some interesting security applications. For example, an eFuse can be set at the chip level to monitor firmware levels. This is implemented in the Nintendo Switch, which uses eFuse checking to validate whether the firmware that is being installed is older than the currently installed firmware, preventing downgrading of firmware. When newer firmware is installed, eFuses are “burned,” indicating the new firmware level that is installed.
Most modern computers use a version of the Unified Extensible Firmware Interface (UEFI). UEFI provides for the ability to secure boot, which will load only drivers and operating system loaders that have been signed using an accepted digital signature. Since these keys have to be loaded into the UEFI firmware, UEFI security has been somewhat contentious, particularly with the open source community. UEFI remains one way to provide additional security if your organization needs to have a greater level of trust in the software a system is loading.
If you rely on firmware to provide security, you also need a method to ensure that the firmware is secure and that updates to the firmware are secure. Trusted firmware updates can help, with validation done using methods like checksum validation, cryptographic signing, and similar techniques. This technique is frequently used to validate updates like those for network devices, motherboards, phones, printers, and other hardware that receives firmware updates.
Hardware Security
Securing hardware can start at the supply chain level. The U.S. government started the Trusted Foundry Program to validate microelectronic suppliers throughout the supply chain. The program assesses the integrity and processes of the companies, staff, distribution chain, and other factors involved in the delivery of microelectronics components and devices. This provides a chain of custody for classified and unclassified integrated circuits, and helps to ensure that reasonable threats to the supply chain are prevented such as tampering, reverse engineering, or modification. You can read about the DMEA and its role with trusted foundry accreditation at https://www.dmea.osd.mil/TrustedIC.aspx
The security of hardware is also done at the underlying design level. A number of these concepts are part of the CySA+:
- Secure processing can mean a number of things, but in the context of hardware security it typically refers to trusted execution environments. Much like other low-level hardware protections, secure processing often starts with boot processes and may include monitoring, privileged execution management, and other protections. Secure processing can leverage or allow access to a trusted execution environment.
- Processor security extensions exist in many different CPUs, including ARM, Intel, and AMD CPUs. They provide security-related functions implemented in the CPU hardware. Extensions typically recognize secure and nonsecure states and have memory allocated as secure memory, but implementations may vary.
- Atomic execution describes a type of operation during which a processor both reads and writes a location during the same bus operation. Since this happens in the same operation, it prevents other processors or devices from accessing or modifying the location during the operation, helping to ensure the integrity of the operation.
- Secure enclaves in modern Apple mobile devices are hardware components that provide cryptographic operations and user authentication, and are designed to remain secure even if the operating system is compromised. They run their own micro-kernel, and their own secure boot process, allowing secure processing separate from the rest of the operating system and CPU. Secure enclaves on Apple devices generate an encryption key at boot, then pair it with a userID to encrypt, validate, and use the secure enclave's portion of system memory. The secure enclave also handles things like Face ID, allowing authentication to be handled in a secure partition.
Finally, there are a number of techniques that can help to protect devices. The CySA+ exam outline calls out a few that you may encounter:
- Anti-tamper protection comes in many varieties from mechanical means like anti-tamper screws and holographic stickers to electronic detection methods. Tamper-proofing microprocessors often takes the form of encasing electronics or otherwise securing them, while attackers use techniques like physically probing or modifying them, freezing devices, and applying out-of-spec power or signals.
- Self-encrypting drives (SEDs) provide built-in encryption capabilities. When the drive needs to be accessed, the user must present a cryptographic key. Once the key is provided, the drive is unlocked and accessible, transparently encrypting and decrypting data as it is needed. This means that if the drive is removed or the key is not available, all of the contents of the drive will remain encrypted and secure.
- Bus encryption is used to protect data traveling inside as system or device. Bus encryption relies on built-in cryptographic processing capabilities to secure information as it flows from one component to another, often from the CPU to other elements of the device. Using an encrypted bus can protect data that is being processed and help to prevent reverse engineering efforts conducted against the hardware or CPU.
Summary
The software development life cycle describes the path that software takes from planning and requirements gathering to design, coding, testing, training, and deployment. Once software is operational, it also covers the ongoing maintenance and eventual decommissioning of the software. That means that participating in the SDLC as a security professional can have a significant impact on organizational software security.
There are many SDLC models, including the linear Waterfall method, Spiral's iterative process-based design, and Agile methodologies that focus on sprints with timeboxed working sessions and greater flexibility to meet changing customer needs. Other models include Rapid Application Development's iterative prototype-based cycles, the V model with parallel test cycles for each stage, and the Big Bang model, a model without real planning or process. Each SDLC model offers advantages and disadvantages, meaning that a single model may not fit every project.
Coding for information security requires an understanding of common software coding best practices. These include performing risk assessments, validating all user input to applications, ensuring that error messages don't reveal internal information, and securing sessions, traffic, and cookies if they are used. OWASP and other organizations provide up-to-date guidance on common issues as well as current best practices, allowing security professionals and developers to stay up to date.
Security testing and code review can help to improve an application's security and code quality. Pair programming, over-the-shoulder code review, pass-around code reviews, and tool-assisted code reviews are all common, but for formal review Fagan inspection remains the primary, but time-intensive, solution. Security testing may involve static or dynamic code analysis, fuzzing, fault injection, mutation testing, stress or load testing, or regression testing, with each providing specific functionality that can help ensure the security of an application.
Finally, web application security testing is conducted using both automated scanners known as web application vulnerability scanners, and by penetration testers and web application security testing professionals. Much like vulnerability scanning, using application-scanning tools provides a recurring view of the application's security profile and monitors for changes due to patches, configuration changes, or other new issues.
Exam Essentials
Be familiar with the software development life cycle (SDLC). SDLC models include Waterfall, Spiral, Agile, and RAD. Each model covers phases like feasibility, requirements gathering, design, development, testing and integration, deployment and training, operations, and eventual decommissioning, although they may not always occur in the same order or at the same time.
Explain how designing information security into applications occurs in each phase of the SDLC. Coding best practices and understanding common software issues are important to prevent security flaws. Version control helps to prevent issues that exist in older code versions from reappearing in new code. Code review models like over-the-shoulder and pair programming, as well as formal review using Fagan inspection, are used to validate the quality and security of code.
Define the purpose of security testing. The majority of code has critical flaws, making testing a necessity. Static testing targets source code, whereas dynamic testing tests the application itself. Fuzzing, fault injection, mutation testing, stress and load testing, as well as security regression testing are all common testing methods. Web applications are tested using web application vulnerability scanners as well as via manual methods to ensure that they are secure and that no new vulnerabilities have been added by configuration changes or patches.
Know how hardware security interacts with software to provide a trusted computing environment. Hardware trust starts at the foundry or manufacturer. Hardware modules like HSM and TPM modules can provide cryptographic and other security services to help systems remain secure. Firmware and hardware security features like eFuse, trusted execution environments, and secure enclaves provide ways for hardware and software developers to leverage security features.
Lab Exercises
Activity 9.1: Review an Application Using the OWASP Application Security Architecture Cheat Sheet
In this exercise you will use the Acunetix web vulnerability scanner to scan a sample site and then review the data generated.
Part 1: Download and install the Acunetix scanner
Acunetix provides their Web Vulnerability scanner as a 14-day limited term trial download. You can download it at www.acunetix.com/vulnerability-scanner/download/.
Part 2: Select an application and scan it
When you download the Acunetix scanner, you will receive an email listing Acunetix-hosted vulnerable sites. Select one of these sites and use the vulnerability scanner to scan it. Once it is complete, review the report that was generated by the scan.
Part 3: Analyze the scan results
Review the scan results and answer the following questions.
- What is the most critical vulnerability? How can it be remediated?
- What is the most common vulnerability (which occurs most often)? Is there a coding change you would recommend to the developers of this application to prevent it?
- How would you protect this application if you were not able to change the code?
Activity 9.2: Learn About Web Application Exploits from WebGoat
OWASP in partnership with Mandiant provides the OWASP Broken Web Applications project virtual machine. This VM includes very vulnerable web applications as a VMware VM, including WebGoat, OWASP's web application vulnerability learning environment.
Step 1: Download the VMware VM
Step 2: Run the VMware VM and start WebGoat
- Run the virtual machine using VMware —you can use the free vSphere Hypervisor from
www.vmware.com/products/vsphere-hypervisor.html, or the 30-day demo of Workstation Player fromwww.vmware.com/products/player/playerpro-evaluation.html. - Once the VM starts, log in as root with the password owaspbwa and run
ifconfigto determine your system's IP address.
Step 3: Succeed with an attack
- WebGoat includes a multitude of vulnerable web application modules. Select one (or more!) and follow the instructions to attack the application. If you need help, review the WebGoat lesson plans and solutions at
https://github.com/WebGoat/WebGoat/wiki/(Almost)-Fully-Documented-Solution-(en), or visit YouTube, where you'll find numerous videos that show step-by-step guides to the solutions.
Activity 9.3: SDLC Terminology
Match each of the following terms to the correct description.
| Subversion | The first SDLC model, replaced in many organizations but still used for very complex systems |
| Agile | A formal code review process that relies on specified entry and exit criteria for each phase |
| Dynamic code analysis | An Agile term that describes the list of features needed to complete a project |
| Fuzzing | A source control management tool |
| Fagan inspection | A code review process that requires one developer to explain their code to another developer |
| Over-the-shoulder | An SDLC model that relies on sprints to accomplish tasks based on user stories |
| Waterfall | A code analysis done using a running application that relies on sending unexpected data to see if the application fails |
| Backlog | A code analysis that is done using a running application |
Review Questions
- What term describes a chip that is built into a computer that stores encryption keys specific to the system that is used for hardware authentication?
- Trusted foundry
- TPM
- HSM
- SED
- During a Fagan code inspection, which process can redirect to the planning stage?
- Overview
- Preparation
- Meeting
- Rework
- Adam is conducting software testing by reviewing the source code of the application. What type of code testing is Adam conducting?
- Mutation testing
- Static code analysis
- Dynamic code analysis
- Fuzzing
- After a major patch is released for the web application that he is responsible for, Sam proceeds to run his web application security scanner against the web application to verify that it is still secure. What is the term for the process Sam is conducting?
- Code review
- Regression testing
- Stress testing
- Whiffing
- During testing, Tiffany slowly increases the number of connections to an application until it fails. What is she doing?
- Regression testing
- Unit testing
- Stress testing
- Fagan testing
- Charles is worried about users conducting SQL injection attacks. Which of the following solutions will best address his concerns?
- Using secure session management
- Enabling logging on the database
- Performing user input validation
- Implementing TLS
- Susan's team has been writing code for a major project for a year and recently released their third version of the code. During a postimplementation regression test, an issue that was originally seen in version 1 reappeared. What type of tool should Susan implement to help avoid this issue in the future?
- Stress testing
- A WAF
- Pair programming
- Source control management
- Precompiled SQL statements that only require variables to be input are an example of what type of application security control?
- Parameterized queries
- Encoding data
- Input validation
- Appropriate access controls
- What process checks to ensure that functionality meets customer needs?
- CNA
- Stress testing
- UAT
- Unit testing
- Matt wants to prevent attackers from capturing data by directly connecting to the hardware communications components of a device he is building. What should he use to make sure that communications between the processor and other chips are not vulnerable?
- Bus encryption
- A HSM
- A TPM module
- LAMP encryption
- Using TLS to protect application traffic helps satisfy which of the OWASP best practices?
- Parameterize queries
- Encode data
- Validate all inputs
- Protect data
- Kristen wants to implement a code review but has a distributed team that works at various times during the day. She also does not want to create any additional support load for her team with new development environment applications. What type of review process will work best for her needs?
- Pair programming
- Pass-around
- Over-the-shoulder
- Tool-assisted
- What type of attack is typically associated with the
strcpyfunction?- Pointer dereferencing
- A race condition
- SQL injection
- Buffer overflow
- Kathleen wants to build a public API for a modern service-oriented architecture. What model is likely her best choice?
- REST
- SOAP
- SAML
- RAD
- During a web application test, Ben discovers that the application shows SQL code as part of an error provided to application users. What should he note in his report?
- Improper error handling
- Code exposure
- SQL injection
- A default configuration issue
- What process is used to ensure that an application can handle very high numbers of concurrent users or sessions?
- Fuzzing
- Fault injection
- Mutation testing
- Load testing
- Gabby wants to insert data into the response from her browser to a web application. What type of tool should she use if she wants to easily make manual changes in what her browser sends out as she interacts with the website?
- An interception proxy
- A fuzzer
- A WAF
- A sniffer
- What type of testing focuses on inserting problems into the error handling processes and paths in an application?
- Fuzzing
- Stress testing
- Dynamic code analysis
- Fault injection
- The application that Scott is writing has a flaw that occurs when two operations are attempted at the same time, resulting in unexpected results when the two actions do not occur in the expected order. What type of flaw does the application have?
- Dereferencing
- A race condition
- An insecure function
- Improper error handling
- Every time Susan checks code into her organization's code repository it is tested, validated, then if accepted it is immediately put into production. What is the term for this?
- Continuous integration
- Continuous delivery
- A security nightmare
- Agile development