
We now explore these ideas in detail. Readers who do not care about some of the mathematical aspects should feel free to skip directly to the next section on how to use regularized regression in scikit-learn.
The problem, in general, is that we are given a matrix X of training data (rows are observations, and each column is a different feature), and a vector y of output values. The goal is to obtain a vector of weights, which we will call b*. The ordinary least squares regression is given by the following formula:

That is, we find vector b, which minimizes the squared distance to the target y. In these equations, we ignore the issue of setting an intercept by assuming that the training data has been preprocessed so that the mean of y is zero.
Adding a penalty or a regularization means that we do not simply consider the best fit on the training data, but also how vector 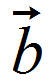 is composed. There are two types of penalties that are typically used for regression: L1 and L2 penalties. An L1 penalty means that we penalize the regression by the sum of the absolute values of the coefficients, while an L2 penalty penalizes by the sum of squares.
is composed. There are two types of penalties that are typically used for regression: L1 and L2 penalties. An L1 penalty means that we penalize the regression by the sum of the absolute values of the coefficients, while an L2 penalty penalizes by the sum of squares.
When we add an L1 penalty, instead of the preceding equation, we instead optimize the following:

Here, we are trying to simultaneously make the error small, but also make the values of the coefficients small (in absolute terms). Using an L2 penalty means that we use the following formula:

The difference is rather subtle: we now penalize by the square of the coefficient rather than their absolute value. However, the difference in the results is dramatic.
These penalized models often go by rather interesting names. The L1 penalized model is often called the Lasso, while an L2 penalized one is known as Ridge regression. When using both, we call this an ElasticNet model.
Both the Lasso and the Ridge result in smaller coefficients than unpenalized regression (smaller in absolute value, ignoring the sign). However, the Lasso has an additional property: it results in many coefficients being set to exactly zero! This means that the final model does not even use some of its input features; the model is sparse. This is often a very desirable property as the model performs both feature selection and regression in a single step.
You will notice that whenever we add a penalty, we also add a weight α, which governs how much penalization we want. When α is close to zero, we are very close to unpenalized regression (in fact, if you set α to zero, you will simply perform OLS), and when α is large, we have a model that is very different from the unpenalized one.
The Ridge model is older as the Lasso is hard to compute with pen and paper. However, with modern computers, we can use the Lasso as easily as Ridge, or even combine them to form ElasticNets. An ElasticNet has two penalties, one for the absolute value and the other for the squares, and it solves the following equation:

This formula is a combination of the two previous ones, with two parameters, α1 and α2. Later in this chapter, we will discuss how to choose a good value for parameters.