
Nevertheless, using these linguistic features in isolation without the words themselves will not take us very far. Therefore, we have to combine the TfidfVectorizer parameter with the linguistic features. This can be done with scikit-learn's FeatureUnion class. It is initialized in the same manner as Pipeline; however, instead of evaluating the estimators in a sequence, each passing the output of the previous one to the next one, FeatureUnion does it in parallel and joins the output vectors afterward:
def create_union_model(params=None):
def preprocessor(tweet):
tweet = tweet.lower()
for k in emo_repl_order:
tweet = tweet.replace(k, emo_repl[k])
for r, repl in re_repl.items():
tweet = re.sub(r, repl, tweet)
return tweet.replace("-", " ").replace("_", " ")
tfidf_ngrams = TfidfVectorizer(preprocessor=preprocessor,
analyzer="word")
ling_stats = LinguisticVectorizer()
all_features = FeatureUnion([('ling', ling_stats),
('tfidf', tfidf_ngrams)])
clf = MultinomialNB()
pipeline = Pipeline([('all', all_features), ('clf', clf)])
if params:
pipeline.set_params(**params)
return pipeline
Training and testing on the combined featurizers, however, is a bit disappointing. We improve by 1% in the positive versus rest part but lose everywhere else:
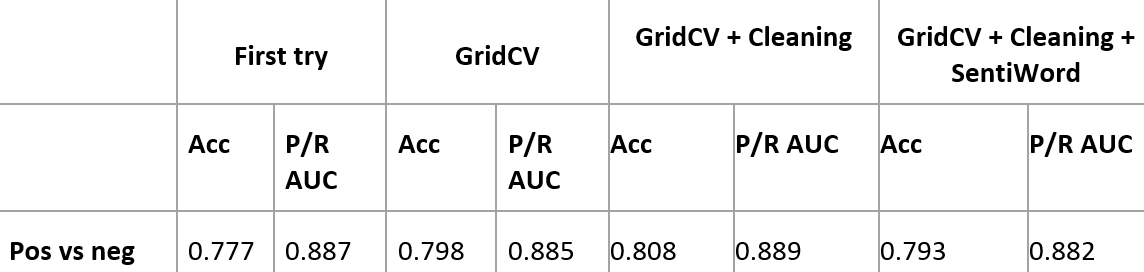
With these results, we probably do not want to pay the price of the much costlier SentiWord approach, if we don't get a significant post in P/R AUC. Instead, we'll probably choose the GridCV + Cleaning approach, and first use the classifier that determines whether the tweet contains a sentiment at all (pos/neg versus irrelevant/neutral), and then in case it does, use the positive-versus-negative classifier to determine the actual sentiment.