
How does jug work? At the basic level, it's very simple. Task is a function plus its argument. Its arguments may be either values or other tasks. If a task takes other tasks, there is a dependency between the two tasks (and the second one cannot be run until the results of the first task are available).
Based on this, jug recursively computes a hash for each task. This hash value encodes the whole computation to get the result. When you run jug execute, for each task, there is a little loop that runs the logic, depicted in the following flowchart:
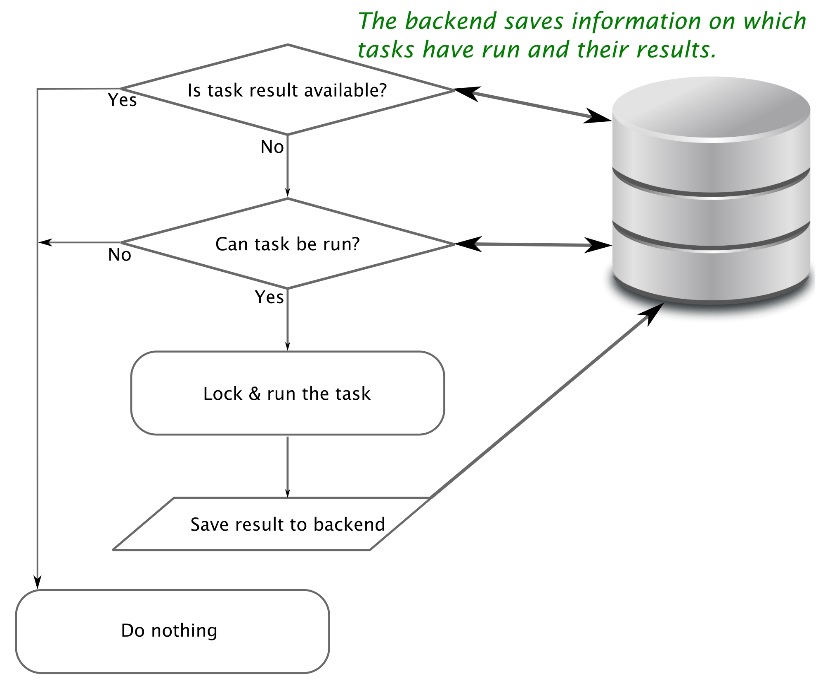
The default backend writes the file to disk (in this funny folder named jugfile.jugdata/). Another backend is available, which uses a Redis database. With proper locking, which jug takes care of, this also allows for many processes to execute tasks; each process will independently look at all the tasks and run the ones that have not run yet and then write them back to the shared backend. This works on either the same machine (using multicore processors) or in multiple machines as long as they all have access to the same backend (for example, using a network disk or the Redis databases). In the second half of this chapter, we will discuss computer clusters, but for now let's focus on multiple cores.
You can also understand why it's able to memoize intermediate results. If the backend already has the result of a task, it's not run again. On the other hand, if you change the task, even in minute ways (by altering one of the parameters), its hash will change. Therefore, it will be rerun. Furthermore, all tasks that depend on it will also have their hashes changed and they will be rerun as well.