
4
Advanced Features of Argumentation for Argument Mining
This chapter addresses a few complex challenges for argument mining and for argumentation more generally. It is not crucial to develop a simple argument mining system. It should however draw the attention of the reader interested in undertaking some research in this area.
In this chapter, we first develop a few tricky situations where opposite claims can be supported by the same justification, and where opposite justifications can support the same claim. The aim is to show that argument mining needs to cope with complex cognitive realities. Then, we discuss two topics that are crucial in argument mining: first, the need for knowledge and inference to bind a claim with an attack or a support when they are not adjacent, and second, the need to present a synthesis of the arguments that have been mined. These may be numerous and with various forms of overlap and relevance. In that case, readability is a real challenge. In this chapter, we can only report preliminary experiments and solutions since research has not reached further at the moment.
4.1. Managing incoherent claims and justifications
Argument mining reflects the complexity of human thinking. It is possible for a justification to be given for a claim and its opposite (the two standpoints involved), while still being deemed perfectly acceptable in both cases. Conversely, contradictory justifications can be mined for a given claim.
4.1.1. The case of justifications supporting opposite claims
Let us first consider the case of a justification that supports two opposite claims. In opinion analysis, which is an area where argumentation is highly developed, it is possible to mine the two following arguments:
A1: This hotel is very nice because it is close to bars and cinemas.
A2: This hotel is terrible because it is close to bars and cinemas.
The claim C2 this hotel is terrible contradicts the claim C1 this hotel is very nice because of the adjectives “very nice” and “terrible”, which are antonyms in this domain. However, these two arguments are perfectly acceptable with the same justification close to bars and cinemas.
If we consider again Toulmin’s model given in section 2.2.1, this apparent contradiction can be justified by considering two different warrant and backing systems. Argument A1 is based, for example, on the following informally formulated warrant W1 and backing B1:
W1: it is pleasant to stay close to social and cultural activities;
B1: humans generally live in a dense social context where they have a high feeling of satisfaction and fulfillment.
A possible rebuttal R1 can be formulated as follows:
unless the environment generates too many problems (noise, insecurity).
Argument A2 is based, for example, on the following informally formulated warrant W2 and backing B2 and possibly B3 since several backings can be advocated in such a model:
W2: public places with bars and cinemas are very noisy, dangerous and unsafe;
B2: humans generally prefer safe and stable places;
B3: large human concentrations usually generate trouble and danger.
A rebuttal can be:
R2: unless there is a very strict police control.
Note however that A2 is not equivalent to A3:
This hotel is very nice because it is far from noisy places such as bars and cinemas.
The divergences between A1 and A2 can be explained in terms of value system or preferences where some warrants may have higher weights than others for specific categories of persons. Rebuttal R1 shows restrictions that are in fact close to W2 and B2. It is also worth noting that the warrants and backings given here are not inconsistent: they simply relate two different facets of the situation advocated in the arguments A1 and A2.
4.1.2. The case of opposite justifications justifying the same claim
Two opposite justifications can support the same claim. Consider, for example:
A3: This film must be banished because it is politically incorrect
A4: This film must be banished because it is not politically incorrect.
Similarly as above, there is a divergence in warrants and backings, for example for A3 we may have, informally:
W3: only politically correct ideas must be developed in public;
B3: the public must be educated according to moral principles.
A rebuttal can be:
R3: unless the goal is to educate people by means of counterexamples.
For A4, we may have, informally:
W4: it is good to criticize standard education to promote the evolution of minds;
B4: in education it is crucial to develop critical thinking;
R4: unless some historical aspect is developed.
Similarly to the previous section, the warrants and backings produced for A3 and A4 are not incompatible. They correspond to different views or facets of a complex situation. Therefore, A3 and A4 are acceptable and correspond to different priorities, preferences of value systems of their utterer. A justification and its opposite may therefore support the same claim with the same strength. Extensions to Toulmin’s standard model can be developed to accommodate these observations.
4.2. Relating claims and justifications: the need for knowledge and reasoning
One of the challenges in argument mining is to establish that a statement can be interpreted as justification of a given claim, in particular when these two statements are not adjacent, possibly not in the same text or dialog turn. Two conditions must be satisfied: this statement must be semantically and pragmatically related to that claim and it must formulate a position, often under the form of an evaluative expression. We report here an experimentation carried out by [SAI 16a], which shows the importance of knowledge and inferences in the analysis of relatedness.
4.2.1. Investigating relatedness via corpus analysis
To explore and characterize the forms of knowledge that are required to investigate the problem of relatedness in argument mining, four corpora were constructed and annotated based on four independent controversial issues. These corpora are relatively small, they are designed to explore the needs in terms of knowledge, knowledge organization and reasoning schemes. An annotation scheme is proposed to guide this identification.
For this experiment, the four following claims are considered, which involve very different types of arguments, forms of knowledge (concrete or relatively abstract) and language realizations:
- 1) Ebola vaccination is necessary;
- 2) the conditions of women has improved in India;
- 3) the development of nuclear plants is necessary;
- 4) organic agriculture is the future.
Texts were collected on the web, considering claims as web queries. The text fragments that were selected are extracted from various sources in which these claims are discussed, in particular newspaper articles and blogs from associations. These are documents accessible to a large public, with no professional consideration, they can therefore be understood by almost every reader.
A large number of texts were collected for each claim. For each text, the task was to manually identify justifications related to the claim at stake. The unit considered for justifications is the sentence. These units are tagged <argument>. As a preliminary step, all the supports and attacks related to each claim were identified. In a second stage, supports or attacks judged by the annotator to be similar or redundant were eliminated and a single utterance, judged to be the most representative in terms of content and structure, is kept. The goals of this preliminary investigation were (1) to gradually develop relevant annotation guidelines, as is the case for most argument annotation projects (see Chapter 6), (2) to evaluate the impact of knowledge in argument mining processes and (3) to suggest which forms of knowledge and inferences are needed.
For each of these issues, the corpus characteristics and the different attacks and supports found are summarized in Table 4.1. In this table, the number of words in column 2 represents the total size of the text portions that were considered for this task, i.e. paragraphs that contain at least one attack or support.
This corpus shows that the diversity of attacks and supports per claim is not very large. A relatively high overlap rate was observed: while there are original statements, authors tend to borrow quite a lot of material from each other. For example, for claim (1) an average redundancy rate of 4.7 was observed, i.e. the same statement was found 4.7 times on average in different texts. This overlap rate is somewhat subjective since it depends on the annotator’s analysis and on the size of the corpus. In spite of this subjectivity, this rate gives an interesting approximate redundancy level. With a large corpus, this overlap rate would likely increase, while the number of new arguments would gradually decrease. A more detailed analysis of those repetitions would be of much interest from a rhetorical and sociological perspective.
Table 4.1. Corpus characteristics
| Claim number | Corpus size | No. of different attacks or supports | Overlap rate (number of similar arguments) |
| (1) | 16 texts, 8,300 words | 50 | 4.7 |
| (2) | 10 texts, 4,800 words | 27 | 4.5 |
| (3) | 7 texts, 5,800 words | 31 | 3.3 |
| (4) | 23 texts, 6,200 words | 22 | 3.8 |
| Total | 56 texts, 25,100 words | 130 | 4.07 |
The last step in the analysis of the corpus consists in manually tagging the discourse structures found in those sentences identified as supports or attacks (called statements in the annotations). For that purpose, the TextCoop platform we developed [SAI 12] is used with an accuracy of about 90%, since sentences are relatively simple. Discourse structures that are identified are those usually found associated with arguments. They express conditions, circumstances, causes, goal and purpose expressions, contrasts and concessions. The goal is to identify the kernel of the statement (tagged <kernel>), which is in general the main proposition of the sentence, and its sentential modifiers. In addition, the discourse structures may give useful indications on the argumentation strategy that is used. Here is an example of the tagging, at this stage, for a statement that could be related to claim (1):
<statement>
<concession> Even if the vaccine seems 100% efficient and without any side effects on the tested population, </concession>
<kernel> it is necessary to wait for more conclusive data before making large vaccination campaigns </kernel>
<elaboration> The national authority of Guinea has approved the continuation of the tests on targeted populations.</elaboration>
</statement>.
4.2.2. A corpus analysis of the knowledge involved
The next step is to define a set of preliminary tags appropriate for analyzing the impact and the types of knowledge involved in argument mining. Discourse analysis tags are kept as described above and new tags are introduced, with the goal to identify the need for knowledge in argument mining. Tags mark the structure of the supports and attacks that have been manually identified for each claim, and include:
- – the text span involved and its identifier, which are, respectively, a sentence and a number;
- – the discourse relations associated with the statement being considered: these are annotated using the tags defined in the TextCoop platform as described above;
- – the polarity of the statement with respect to the claim with one of the following values: support or attack. Weaker values such as concession or attack can also be used;
- – the strength of the statement, which is mainly related to linguistic factors. It must be contrasted with persuasion effects that depend on the context and on the listener. It has the following values: strong, average, moderate;
- – the conceptual relation to the claim: informal specification of why it is an attack or a support based on the terms used in the claim or in the “knowledge involved” attribute;
- – the knowledge involved: list of the main concepts used to identify relatedness between a claim and a statement. These elements preferably come from a predefined domain ontology, or from the annotator’s intuitions and personal knowledge, if no ontology is available. This list may be quite informal, but it nevertheless contributes to the characterization of the nature of the knowledge involved in identifying relatedness.
A statement that attacks issue (1) is then tagged as follows:
<statement nb= 11, polarity= attack, strength= moderate, relationToIssue= limited proof of efficiency, limited safety of vaccination, conceptsInvolved= efficiency measure, safety measures, evaluation methods> <concession> Even if the vaccine seems 100% efficient and without any side effects on the tested population, </concession>
<kernel> it is necessary to wait for more conclusive data before making large vaccination campaigns </kernel>
<elaboration> The national authority of Guinea has approved the continuation of the tests on targeted populations.</elaboration>
</statement>.
Claims (1)–(4) (section 4.2.1) involve different types of analyses that show the different facets of the knowledge needs. While claims (1) and (4) involve relatively concrete and simple concepts, claim (2) is much more abstract. It involves abstract concepts related to education, the family and human rights. Finally, claim (3) involves fuzzier arguments, which are essentially comparisons with other sources of energy. This panel of claims, even if it is far from comprehensive, provides a first analysis of the types of knowledge used to characterize relatedness.
Dealing with knowledge remains a very difficult issue in general that is difficult to formally characterize. Knowledge representation is a vast area in artificial intelligence and in linguistics. This area involves a large diversity of forms, from linguistic knowledge (e.g. semantic types assigned to concepts, roles played by predicate arguments) to forms involving inferences (presuppositions, implicit data) via domain and general purpose knowledge, contextual knowledge, etc. Each of these aspects of knowledge requires different representation formalisms, with associated inferential patterns. They also often involve complex acquisition procedures. The notion of concept that is used in this section corresponds to the notion of concept in a domain ontology, where they can be either terminal (basic notions) or relational.
For the purpose of illustration, let us focus on claim (1). Arguments mainly attack or support salient features of the main concepts of the claim or closely related ones by means of various forms of evaluative expressions. Samples of supports and attacks associated with claim (1) are as follows:
Supports: vaccine protection is very good; Ebola is a dangerous disease; high contamination risks; vaccine has limited side effects; no medical alternative to vaccine, etc.;
Attacks: limited number of cases and deaths compared to other diseases; limited risks of contamination, ignorance of contamination forms; competent staff and P4 lab difficult to develop; vaccine toxicity and high rate of side effects;
Weaker forms: some side effects; high production and development costs; vaccine not yet available; ethical and personal liberties problems.
For claim (1), the term vaccine is the central concept. The concepts used to express supports or attacks for or against that claim can be structured as follows, from this central concept vaccine:
- 1) concepts which are parts of a vaccine: the adjuvant and the active principle. For example, a part of the vaccine, the adjuvant, is said to be toxic for humans;
- 2) concepts associated with vaccine super types: a vaccine is a type of or an instance of the concept medicine; it therefore inherits the properties of “medicine” (e.g. an argument says the vaccine has a high rate of side effects) unless property inheritance is blocked;
- 3) concepts that describe the purposes, functions, goals and consequences of a vaccine, and how it is created, i.e. developed, tested and sold. These concepts are the most frequently advocated in arguments for or against issue (1). For example, the concept of contamination is related to one of the purposes of a vaccine, namely to avoid that other people get the disease via contamination, and therefore on a larger scale, the purpose of a vaccine is to prevent disease dissemination. Finally, production costs are related to the creation and development of any product, including medicines and vaccines.
Without knowing that a vaccine protects humans from getting a disease, it is not possible, for example, to say that prevents high contamination risks is a support for claim (1) and to explain why. Similarly, without knowing that the active principle of a vaccine is diluted into an adjuvant that is also injected, it is not possible to analyze the adjuvant is toxic as an attack. Without this knowledge, this statement could be, for example, purely neutral or irrelevant to the issue.
The conceptual categories used in this short analysis, namely purpose, functions, goals, properties, creation and development, etc., are foundational aspects of the structure of a concept. They allow an accurate identification of statements related to a claim and what facet they exactly attack or support in the issue and how. This is also useful to automatically construct various types of argument synthesis.
The concepts used in attacks and supports related to claim (2) concentrate on facets of humans in society and in the family and evaluates them for women. For example, improving literacy means better education, better jobs and therefore more independence and social recognition, which are typical of the improvement of living conditions. Roughly, the concepts used in statements supporting or attacking claim (2) can be classified into two categories:
- – those related to the services provided by society to individuals: education, safety, health, nutrition, human rights, etc. These statements evaluate the quality of these services for women;
- – those related to the roles or functions humans can play in society: job and economy development, family development, cultural and social involvement, etc. These statements evaluate if and how women play these roles and functions.
Each of these concepts needs to be structured, as above for the notion of vaccine, to allow an accurate analysis of relatedness. The aim is to identify what facet of women’s living conditions these statements support or attack and how. The number of concepts involved may be very large, however, our observations tend to indicate that most arguments concentrate on a few prototypical ones, which are the most striking.
4.2.3. Observation synthesis
A synthesis of attacks or supports where the need for knowledge is required to establish relatedness is given in Table 4.2. For example, for claim (1), 44 statements out of a total of 50 (88%) require knowledge to be identified as related to the claim. For these 44 statements, 54 different concepts are required to establish that they are related to claim (1).
From the corpus observations, it turns out that the types of knowledge involved in relating an attack or a support to a claim are based on the existence of relations pertaining to lexical semantics between the concepts of the main terms of the claim and the attack or support. These relations typically include:
- – concepts related via paradigmatic relations: these include in particular the concepts derived from the head terms of the issue that are either parts or more generic or more specific concepts (hyponyms or hyperonyms) of these head terms. For example, the concept of adjuvant is part of the concept vaccine, and the notion of side effect is a part of the generic concept medicine. Iteratively, parts of more generic concepts or subparts of parts are also candidates. The notion of part covers various types of parts, from physical to functional ones [CRU 86]. Transitivity is only valid between parts of the same type. [CRU 86] also addresses a number of methodological problems when defining parts, hyponyms or hyperonyms. To a lesser extent, antonyms have been observed for issues (2) and (3) (e.g. literacy/lack of education). These allow to develop attacks between a statement and a claim;
- – concepts related via generic functional relations: these relations mainly include two classes: (1) those related to the functions, uses, purposes and goals of the concepts in the claim, and (2) those related to the development, construction or creation of the entities represented by the concepts in the claim. The concepts involved in these relations are relatively straightforward for claims that are concrete, such as vaccination, but they are much more complex to specify for more abstract claims, such as claim (2);
- – concepts related via a combination of paradigmatic and functional relations: the relation between a claim and an attack or a support can be, for example, the purpose of one of the parts of the main concept of the claim. For example, the notion of industrial independence associated with claim (3) involves in a more generic concept (a plant, an industrial sector) the functional relation of goal (independence with respect to other countries).
Table 4.2. Evidence for knowledge
| Claim number | Need for knowledge No. of cases (rate) | Total number of concepts involved (rough estimate) |
| (1) | 44 (88%) | 54 |
| (2) | 21 (77%) | 24 |
| (3) | 18 (58%) | 19 |
| (4) | 17 (77%) | 27 |
| Total | 100 (77%) | 124 |
The paradigmatic and specific functional relations presented above cover a large majority of the relations between issues and their related arguments, estimated to about 80% of the total. There are obviously other types of relations, which are more difficult to characterize (e.g. vaccination prevents bioterrorism), but of much interest for argument mining.
The figures in Table 4.2 show that for about 77% of the statements identified as either attacks or supports, some form of knowledge is involved to establish an argumentative relation with a claim. An important result is that the number of concepts involved is not very large: 124 concepts for 100 statements over four domains. Even if the notion of concept remains vague, these results are, nevertheless, interesting to develop large argument mining systems.
The conceptual organization described in the above analysis tends to suggest that the type of conceptual categorization offered by the Qualia structure, in particular in its last development in Generative Lexicon (GL) [PUS 86], with some extensions to the formalism, is an adequate representation framework to deal with knowledge-based argument mining.
The main other approaches in lexical semantics such as FrameNet or VerbNet mainly concentrate on predicate argument structure for verbs and their adjuncts: they characterize the roles that these elements (NPs, PPs and S) play in the meaning of the verb and the proposition. According to our observations, these are not central features for knowledge-based argument mining, although they may be useful to develop lexical resources (synonyms, antonyms) and argument mining templates as shown in [SAI 16a].
The GL is a model that organizes concept descriptions via structures called roles. Roles describe the purposes and goals of an object or an action, its origin and its uses. These are the main features that are supported or attacked in arguments. These, to the best of our knowledge, are specific features of the GL Qualia structure, in particular the telic and agentive roles. The main limitation is however that the GL has very few resources available. The notions used in the GL Qualia structure are not new: the roles postulated in the Qualia structure are derived from the Aristotelian class of causes, namely constitutive for material, formal for formal, telic for final and agentive for efficient. These roles do not overlap with the notions of grammatical roles or semantic roles. They are much more powerful from the point of view of semantics and knowledge representation.
4.3. Argument synthesis in natural language
A synthesis of the propositions that support or attack a claim is a necessary component of any argument mining system. By synthesis, we mean a structured set of propositions, possibly eliminating redundancies or close-by propositions. In different types of texts and media, it is frequent to mine more than 100 supports or attacks of a given claim, with various strengths and dealing with various facets of the claim. A number of these supports and attacks may largely overlap. It is then difficult and time consuming for users of an argument mining system to read long lists of unstructured propositions where some essential points may not be easily visible due to the amount of data. Looking at how users of argument synthesis proceed, it turns out than even simple forms of synthesis via, for example, clustering techniques could be very useful to make the statements for or against a claim really accessible.
4.3.1. Features of a synthesis
So far, very few efforts have been devoted to this aspect of argument mining. Designing an argument synthesis is a delicate task that requires taking into account users’ profiles, for example, the type of information that is useful to them, the features which are the most prominent, and the level of granularity they expect. A synthesis must be simple: complex graphs must be avoided since they are rarely legible and understood by users. Carrying out a well-organized synthesis requires the same type of knowledge and conceptual organization as for mining arguments. A synthesis should indeed be closely related to the way arguments are understood.
In natural language generation, the main projects on argumentation generation were developed as early as 2000 by I. Zukerman et al. [ZUK 00] and then by A. Fiedler and H. Horacek [FIE 07]. The focus was on the production and the organization of arguments from an abstract semantic representation via some forms of macroplanning, an essential component of natural language generation of texts. A synthesis, and in particular an argument synthesis, is a much simpler operation than the generation of arguments: it consists in grouping already existing propositions related to a claim on the basis of their similarity in order to enhance the reader’s understanding and to provide a simple overview. Planning consists in using a hierarchy of concepts so that the most central supports or attacks appear first. A synthesis is therefore more superficial than the generation of arguments.
While there are currently several research efforts to develop argument mining, very little has been done recently to produce a synthesis of the mined arguments that is readable, synthetic enough and relevant for various types of users. This includes identifying the main features for or against a controversial issue, but also eliminating redundancies and various types of fallacies that are less relevant in a synthesis that is aimed at being as neutral as possible. This synthesis may have the form of a short text, possibly including navigation links, or it may take the form of a graphical representation that organizes the reasons or justifications for or against an issue. The major problems are readability, granularity and conceptual adequacy with respect to readers.
In [SAI 16b], it is shown how statements for or against a claim that have been mined can be organized in hierarchically structured clusters, according to the conceptual organization proposed by the GL [PUS 86], so that readers can navigate over and within sets of related statements. This approach turned out not to be synthetic enough, since over 100 reasons can be mined for a given issue, making the perception of the main attacks and supports quite difficult. Nevertheless, this initial approach allows the construction of an argument database with respect to an issue, which is useful to readers who wish to access the exact form of arguments that have been mined. This is illustrated in Figure 4.1, where the relation of each concept to the claim (part of, purpose, etc.) is specified in order to enhance the structure of the description. This figure simply shows a form of synthesis readers would like to have, independently of any knowledge representation consideration.
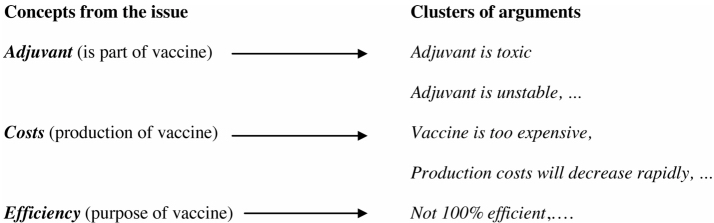
Figure 4.1. Illustration of a synthesis
It is possible to go one step further. A synthesis can also be viewed as a form of summarization (see section 7.1.2). Various forms of summarization tasks are developed in [MAN 01]. The production of a synthesis that is short and efficient must be carried out at a conceptual level. For example, the concepts present in domain ontologies (as in most opinion analysis systems) or in the GL Qualia structures can be used to abstract over sets of propositions that support or attack an issue at stake. The structure of clusters of propositions is kept and made accessible via links from this synthesis. From that perspective, this work could be viewed as a preliminary step to a summarization procedure. A real summarization task would involve identifying prototypical arguments and themes, and then constructing summaries for each group of related arguments, but this is beyond the state of the art. These concepts can be used as entry points to the cluster system and as a measure of the relevance of a proposition with respect to the issue at stake. A challenging point is that these concepts and their internal organization must correspond as much as possible to the user’s perception of the domain to which the issue belongs, otherwise the synthesis may not be so useful.
4.3.2. Structure of an argumentation synthesis
Let us now characterize the form of a synthesis, as it can be derived from the examples given in section 4.2.1. Such a synthesis can be organized as follows, starting with the concepts that appear in the claim and then considering those, more remote, which are derived from the concepts of the claim, for example, the properties of the adjuvant are derived concepts, since the adjuvant is a part of a vaccine.
To make the synthesis readable and informative, the total number of occurrences of arguments mined in texts for that concept is given between parentheses, as an indication. The goal is to outline strengths, recurrences and tendencies. This, however, remains informal because occurrence frequencies are very much dependent on how many texts have been processed and how many attacks or supports have been mined. This number is also used as a link that points to the statements that have been mined in their original textual form. For each line, the positive facet is presented first, followed by the negative one when it exists, independently of the occurrence frequency, in order to preserve a certain homogeneity in the reading:
Vaccine protection is good (3), bad (5).
Vaccine avoids (5), does not avoid (3) dissemination. Vaccine is difficult (3) to develop.
Vaccine is expensive (4).
Vaccine is not (1) available.
Ebola is (5) a dangerous disease.
Humans may die (1) from Ebola.
Tests of the vaccine show no (2) high (4) side effects.
Other arguments (4).
Each line of the synthesis can be produced via a predefined language pattern [SAI 17]. The comprehensive list of supports and attacks is stored in clusters as described above. They are accessible via navigation links, represented in this synthesis by means of underlined numbers.
An alternative synthesis approach would have been to select for each concept a support or an attack that is prototypical, with a link to the other statements related to the same concept. This approach sounds less artificial than the generation of abstract sentences, but (1) it is difficult to characterize what a prototypical statement is and (2) the formulation proposed above is a priori shorter, more neutral and more standardized. However, we feel that exploring other forms of synthesis, in close cooperation with users, should be investigated. For example, forms of rhetoric could be incorporated for non-neutral synthesis where, for example, some emphasis must be put on certain points. Introductions to these aspects can be found, among many others, in [PER 77] and in [AMO 10] who develops specific cases related to news editorials.