
6
Annotation Frameworks and Principles of Argument Analysis
Research in linguistics mostly relies on empirical analyses to characterize or understand a discourse feature. Corpus analyses are particularly useful because they provide detailed and thorough information about peculiar discourse characteristics.
In computational linguistics, manual annotations of naturally occurring examples have been used as a source of training material. This task consists in annotators manually assigning an interpretation to texts.
Argumentation theorists carry out annotations of texts to detect, identify and evaluate arguments. This analytical task is necessary to understand and characterize facets of human reasoning. Manually annotating argumentative texts, indeed, allows the detection of argumentative components which may not be anticipated. It is also necessary to manually perform annotations prior to building systems that can automatically replicate them afterwards. Moreover, argument analyses can be used to provide examples and counterexamples of argument features in order to feed a program that will automatically detect them or to develop rules and grammars. In other words, annotated data are used as training sets to test and develop argument mining systems.
In this chapter, we describe some annotation frameworks (or models) that have been used to analyze arguments, with an emphasis on the different argument elements that can (or must) be identified and analyzed. We also emphasize the need for clearly defined guidelines to provide accurate analyses. Some annotation tools allowing the analysis of argument are also presented.
6.1. Principles of argument analysis
A set of theoretical frameworks has been developed for the description, analysis or evaluation of arguments. These theories are applied to annotate natural language argumentation. They do not all aim at examining the same characteristics of argumentation; however, most of them focus on the main argument elements, including those identified by Toulmin (see Chapter 2.2.1). Indeed, understanding arguments, and by extension automatically detecting argumentation, requires understanding different elements of discourse. Such elements are varied and bear their own complexity, as much for human annotators as for computational systems. We present here several such elements and show how they can help us understand argumentation.
Analyzing arguments in naturally occurring texts consists in two main tasks: first, raw texts must be segmented (usually to distinguish argumentative units from non-argumentative ones), then argumentative components must be assigned a type (usually predefined in the theoretical framework at stake). Thus, some approaches limit themselves to the identification of claims and possibly premises, while other theories classify components in finer-grained and specific classes. We intend in the following sections to give an account of the various classes and components that can be annotated with respect to argumentation.
Note that the final application of an argument mining system is decisive of the annotation process: the annotated components will be different based on what the system is trying to achieve. For instance, if the system aims at reconstructing the argument structure of a text, the annotation process will take into account argumentative elements that may not need to be analyzed if the system was developed to simply detect main claims.
6.1.1. Argumentative discourse units
When annotating a text to analyze arguments, it is necessary to first determine the text parts that bear an argumentative function. In the literature, these are called Argumentative Discourse Units (ADUs). As a matter of fact, in a text, not all sentences bear an argumentative function. See, for instance, the following sentence taken from a radio debate:
Our panel, Claire Fox from the Institute of Ideas, the former Conservative Cabinet Minister Michael Portillo, the Catholic writer Clifford Longley and the science historian Kenan Malik.1
In this example, the speaker (i.e. the moderator) introduces the panelists who will participate in the debate. Defining whether this move has an argumentative function or not is a tricky task. Intuitively, and without any context, this move does not seem to have an argumentative function since it does not help the speaker build an argument and it is not attacked. Although it would seem irrelevant and unreasonable to attack this move (i.e. to provide counterarguments), an opponent could, theoretically, disagree with the sentence, or parts of it. For instance, s/he could disagree that Kenan Malik is a science historian.
Nevertheless, determining whether a move plays a role in the argument cannot rely on intuition. Note that a proposition can be considered as a simple fact when it has no support or attack and if it does not contain an evaluative element. For instance, “Nice is a city in southern France” is not a claim, while “Nice is a sunny city” is a claim: sunny is a scalable evaluative element (see section 3.1) and, although no supporting claim is provided, one can imagine that the utterer may provide a premise or else a listener may attack it. Manually segmenting a text into ADUs may represent the first and most complex task of argument analysis. Let us now have a look at another example:
Vaccines have allowed reducing the number of deaths. Not just in Africa but worldwide.
This example is composed of two sentences. While it might seem logical to segment it into two parts (“vaccines have allowed reducing the number of deaths” and “not just in Africa but worldwide”), actually, the ADU is the entire example since it has one single propositional content “Vaccines have allowed reducing the number of deaths not just in Africa but worldwide”: both sentences are glued together. Therefore, one cannot necessarily rely on punctuation to segment a text into ADUs. Rather, it is common to consider that an argumentative segment must contain one single proposition whether it is composed of one sentence (in a grammatical sense) or more.
The problem of properly segmenting also arises when a proposition is interrupted by another proposition (particularly common in dialogical contexts, but not exclusively). Let us take the following example:
Speaker 1: Vaccines are essential. . .
Speaker 2: Sure.
Speaker 1: ...to prevent diseases.
In this example, Speaker 2 interrupts Speaker 1. However, the first ADU must contain Speaker 1’s both utterances: “vaccines are essential to prevent diseases”; then, the second ADU is “sure”.
Segmenting an argumentative text therefore is challenging: first, one has to delimit units, then one must determine whether each unit is argumentative or not. Some units, taken in isolation may not be (or seem) argumentative, but their argumentative character depends on other units. Note that “argumentative” does not equal “subjective” or “opinionated”, since some argument components are clearly factual. H. Wachsmuth et al. [WAC 17] state that “a comment should be seen as argumentative if you think that it explicitly or implicitly conveys the stance of the comment’s author on some possibly controversial issue.” Different methods (guidelines) exist to segment a text, depending on the analytical framework at stake; some examples are given in section 6.3.
6.1.2. Conclusions and premises
Also called main claims, conclusions are claims that must be defended (since this is where the principal controversy may lie). A way to defend a main claim is by providing supporting claims called premises. Broadly speaking, a claim originates two standpoints: the claim itself and its negation. Let us take the following example:
Vaccination campaigns are essential. They prevent the propagation of diseases.
The main claim here is the ADU “vaccination campaigns are essential” (one can negate this statement); it is supported by one premise (a second ADU) “they [vaccination campaigns] prevent the propagation of diseases”. A simple XML annotation of this argument would be:
<argument>
<conclusion> Vaccination campaigns are essential. </conclusion>
<premise> They prevent the propagation of diseases.</premise>
</argument>.
During the annotation process, guidelines and hints can be provided to ease the detection of main claims; these may include the consideration of:
- – discourse connectives like “in conclusion”, “therefore”;
- – the position in the document, mostly in the introduction or the conclusion;
- – the presence of verbs or nouns indicating stance or belief as “claim”, “believe”, etc.
Although these indicators may help the annotators, their utility is limited, in particular because they are not always frequent in texts; but in some domains or genres – like academic writing – the usage of discourse connectives is more frequent, more systematic and less ambiguous than in open-domain texts (see sections 3.1 and 3.2).
6.1.3. Warrants and backings
A warrant is a justification rule (a generally accepted truth, applying to most circumstances); it justifies the logical inference from the premise to the claim. A backing supports a warrant (it is a generalization rule such as a physical law); it is a set of information that assures the warrant trustworthiness. These elements are often implicit but can be reconstructed; as Toulmin says “data are appealed to explicitly, warrants implicitly” [TOU 03, p 92]. In the following example,
It’s freezing this morning: flowers will suffer.
the first ADU is “it’s freezing this morning” (a premise) and the second ADU (the main claim) is “flowers will suffer”. A possible warrant would be “flowers do not like freezing weather” and a possible backing would be a law of botany explaining why flowers do not like frost (see also section 2.2.1). If this reconstruction is chosen, a possible simple annotation would be:
<argument>
<premise> It’s freezing this morning: </premise>
<warrant> flowers do not like freezing weather </warrant>
<backing> a law of botany explains that flowers do not like frost </backing> <conclusion> flowers will suffer. </conclusion>
</argument>.
6.1.4. Qualifiers
A qualifier indicates the strength of the inferential link between a premise and a conclusion. In other words, it indicates the confidence of an utterer in her conclusion. In the following example (annotated below), the qualifier is the word “surely”. As an illustration, the qualifier has an attribute “strength” that represents its impact:
It’s freezing this morning: flowers will surely suffer.
<argument>
<premise> It’s freezing this morning: </premise>
<conclusion> flowers will <qualifier strength="high"> surely </qualifier> suffer. </conclusion>
</argument>.
Qualifiers are not always easily identified: in “Vaccines prevent most diseases”, the strength of the claim is lowered by the word most. Moreover, as many other argument components such as warrants and backings, qualifiers are not always explicit; hence, in [HAB 17], in spite of their use of Toulmin’s model in the annotation process, the authors decided not to analyze qualifiers because they found out that arguers rarely indicate the “degree of congency” (i.e. the probability/strength of their claims).
6.1.5. Argument schemes
Argument schemes are patterns of reasoning. A detailed (yet non-exhaustive) list of such patterns is provided by Walton et al. [WAL 08]. Argument schemes, indeed, are various ([WAL 08] provides a set of 60 argument schemes) and sometimes hard to distinguish (see sections 2.5 and 3.3, or [WAL 15b] for a classification). Argument schemes are non-textual elements, therefore they are implicit argument elements that have to be identified and reconstructed. As we will see later on, this is a challenge that scholars have tackled more or less successfully (see, for instance, [LAW 16]). Let us take the following example that may be analyzed as an argument from analogy (see section 2.5.3):
It has been shown that vaccinating against malaria can be useless in some cases; similarly the vaccine against Ebola is not recommended.
<argument ="argument from analogy">
<premise> It has been shown that vaccinating against malaria can be useless in some cases; </premise>
<conclusion> similarly, the vaccine against Ebola is not recommended. </conclusion>
</argument>.
6.1.6. Attack relations: rebuttals, refutations, undercutters
Arguments suppose a (sometimes implicit) opposition: all argument components can be attacked by providing new claims. Therefore, premises of an argument can be attacked as well as its conclusion. Note that, if we consider the dialectical nature of argumentation, proponents as well as opponents can provide supports for claims. As a result, when an opponent puts forward a claim attacking a proponent’s argument, s/he can provide support (premises) for this attacking claim, which creates a counterargument or rebuttal. In monological contexts, one can provide counterarguments for several reasons, including to anticipate an attack; a refutation is when this attack is then itself attacked. Let us take the following example (taken from the AIFdb Corpus Moral Maze British Empire2).
You say that Britain is non-inclusive, but I mean, relative to many other countries surely it’s an exemplar of inclusivity.
In this example, the speaker attacks what his opponent said previously in the dialogue, namely that Britain is non-inclusive: according to him, Britain is an exemplar of inclusivity.
In Toulmin’s model, rebuttals are conditions that may undermine an inference: they attack a qualifier. In other words, rebuttals present a situation in which a claim might be defeated. A possible rebuttal for the example presented in section 6.1.4 above would be “unless the flowers are protected”. Rebuttals can be explicitly stated in an argument in order to show exceptions to the defended claim or to anticipate an attack.
<argument>
<premise> It’s freezing this morning: </premise>
<conclusion> flowers will <qualifier strength="high"> surely </qualifier> suffer. </conclusion>
<rebuttal> unless the flowers are protected </rebuttal>
</argument>.
I. Habernal [HAB 14, p 27] proposes the following definition to detect rebuttals and refutations:
Rebuttal attacks the main claim by presenting an opponent’s view. In most cases, the rebuttal is again attacked by the author using refutation. Refutation thus supports the author’s stance expressed by the claim. So it can be confused with grounds, as both provide reasons for the claim. Refutation thus only takes place if it is meant as a reaction to the rebuttal. It follows the discussed matter and contradicts it. Such a discourse can be mainly expressed as: [rebuttal: On the other hand, some people say that my Claim is wrong.] [refutation: But this is not true, because of that and that.]
A way of attacking the strength of arguments is to provide a claim attacking the validity of an inference; in the literature such claims are called undercutters (for instance, [PEL 13]). Undercutters allow showing that the inferential link does not hold. For instance, J.L. Pollock [POL 95] considers the example of a red object: two premises to assert that “the object is red” are “the object looks red” and “things that look red are normally red”; a way of attacking this argument would be to claim that “the object is illuminated by a red light”: this claim attacks the link between “the object looks red and things that look red are normally red” (premises) and “this object is red” (conclusion).
Undercutters are somewhat difficult to represent in a language such as XML, which is basically linear or flat. We suggest below, but there are other possibilities, to include the undercutter as an attribute of the tag ‘argument’, which qualifies the nature of the relation between the premise and the conclusion and the potential difficulties associated with this relation:
<argument undercutter="the object is illuminated by a red light">
<conclusion> The object is red </conclusion>
<premise1> the object looks red </premise1>
<premise2> things that look red are normally red </premise2>
</argument>.
Attack relations in argumentation are therefore various and sometimes hard to distinguish (as shown in Habernal’s quote above). Moreover, they may not appear at all but one might want to consider them in an argument analysis.
6.1.7. Illocutionary forces, speech acts
Some works in argumentation are interested in determining the arguer’s intentions. According to Speech Act Theory (SAT), utterances (spoken or written) are thought to be propositional contents to which a force (the illocutionary force) is attached [SEA 69]. This force represents the intention (or position) of the utterer with regard to the propositional content. S/he can claim, question, challenge, reject, etc. SAT, therefore, offers a valuable framework in which utterances can be described and analyzed according to their force.
J.R. Searle and D. Vanderveken [SEA 85] classify illocutionary forces in five categories: assertives, commissives, directives, declaratives and expressives. These categories allow a first general distinction between locutors’ communicative intentions. Knowing what the speakers’ intentions are is crucial for understanding a particular discourse: if a speaker/writer claims something (assertive verb), this means that he (normally) believes what he says; if he uses an expressive verb (e.g. to apologize), he shows his attitude, rather than opinion, toward the propositional content. An approach that makes extensive use of SAT is pragma-dialectics [EEM 03]. In this theory, the analysis of discourse relies on a normative framework in which the speakers’ communicative intentions must always be analyzed.
A drawback of SAT is that it does not capture the interaction between utterances. The framework does not tell us anything about the discourse resulting from exchanges of utterances, which is crucial to understand dialogues. Moreover, despite the great value of SAT as a theoretical framework for studying language use, it is inadequate for the description of argumentation [EEM 82]. Inference Anchoring Theory (IAT) [BUD 11], an analytical framework for dialogical argumentation, is based on SAT: it allows the representation of the structure of argumentative dialogues by eliciting the illocutionary forces of locutions (e.g. [BUD 14c]). This framework tackles what SAT fails at capturing: the relationship between sequences of speech acts. With the representation of the argumentative structure as a final goal, IAT makes it possible to show how arguments are constructed through dialogical exchanges (see section 6.2.3 for more details). Let us take the following dialogue and its annotation taken from [BUD 14c]3:
Lawrence James: It was a ghastly aberration.
Clifford Longley: Or was it in fact typical? Was it the product of a policy that was unsustainable that could only be pursued by increasing repression?
<utterance speaker = "lj" illoc = "standard_assertion">
<textunit nb = "215"> it was a ghastly aberration </textunit></utterance>. <utterance speaker = "cl" illoc = "RQ">
<textunit nb = "216"> or was it in fact typical ? </textunit></utterance> . <utterance speaker = "cl" illoc = "RQ-AQ">
<textunit nb = "217"> was it the product of a policy that was unsustainable that could only be pursued by increasing repression? </textunit></utterance>.
6.1.8. Argument relations
Once all the argumentative components have been identified and classified according to their type (i.e. when each unit is given a label corresponding to its type, e.g. main claim, premise, rebuttal, conflict, argument scheme), it can be of interest to show the relationship between them. For instance, when two premises are identified, one can wonder whether they work independently (convergent arguments) or whether they function together to support the conclusion (linked arguments). Equally, one can wonder whether an attack points to a premise, a conclusion or an inferential link for instance.
Identifying the component to which another component is linked may be a very difficult task, because there may be long-distance relations between arguments, possibly spanning paragraphs, in particular for texts with a complex argumentative structure, like scientific papers or judgments. Finding relations between components is challenging, usually returning low interannotator agreement (IAA) results and poor performance in automated systems (see sections 6.3 and 7.3).
The primary inventory of relations is the attack/support distinction. These two relations capture the most basic role of components in an argument, that is, if the component is providing more strength (support) or undermining the strength (attack) of a given claim.
Representation of arguments as trees (as in Toulmin’s model) misses the ability to show multiple relations of argumentation. The presentation of argumentation relations as graphs is therefore more convenient as attack relations as well as supports and interconnections between argument components can also be represented. In such graphical representations, claims are usually represented as nodes and the relations between nodes take the form of directed arrows.
Figure 6.1, taken from [OKA 08, p. 4], shows an argument map realized with the Rationale argument analysis tool (see section 6.4.5 for more details); each node contains one claim, the top one being the main claim (conclusion) linked to the others via arrows: green ones represent supports and red ones attacks.

Figure 6.1. An argument map with Rationale. For a color version of this figure, see www.iste.co.uk/janier/argument.zip
Although most models follow similar rules for the graphical representation of argumentation analyses, some differences may appear as their purposes are not always akin. As an example, in Peldszus and Stede’s [PEL 13] model, claims uttered by a proponent appear in box nodes and attacks appear in circle nodes. Figure 6.2, taken from [PEL 13, p. 19], is the graphical argument structure of the manual analysis of the following text:
[The building is full of asbestos,]1 [so we should tear it down.]2 [In principle it is possible to clean it up,]3 [but according to the mayor that would be forbiddingly expensive.]4
In the manual analysis, the text has been segmented and four segments have been identified. The relationships between the segments are represented in Figure 6.2, where (1) the segments are represented by their corresponding numbers in the manual annotation above, (2) directed arrows show support links and (3) round-headed arrows show attacks.
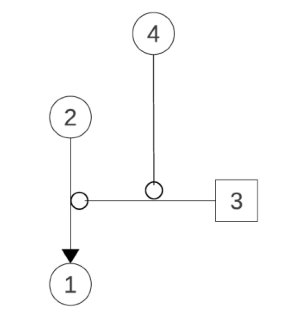
Figure 6.2. An argument diagram
Figure 6.3, taken from [BUD 16, p. 93], presents another type of argument graph. This graphical representation of the dialogue below relies on the IAT model (see sections 6.1.7 and 6.2).
Bob: p is the case.
Wilma: Why p?
Bob: q.
IAT being mostly used in dialogical contexts, speakers’ locutions are represented (on the right-hand side of the analysis) because the argumentative structure is derived from the analysis of dialogue dynamics. This type of analysis allows to show dialogical dynamics and their attached argumentative structures and explicit illocutionary connections. Here, the second speaker challenged the first speaker’s utterance that triggers argumentation (see the support relation, instantiated by the rule application node). As we will see later, other argument components can be annotated with IAT, such as additional illocutionary connections or attack relations among others.
Figures 6.1–6.3 show that annotating arguments can take various forms according to what the model is used for but they follow the same principles: eliciting argument relations in order to grasp the subtleties of reasoning in different contexts.
6.1.9. Implicit argument components and tailored annotation frameworks
We have just seen that many argumentative components (such as warrants, backings or illocutionary forces) are often left implicit. According to Habernal and Gurevych [HAB 17], even the main components of argumentation can be implicit: in their study of web discourse, the unrestricted environment (and their method) required the main claim (actually the stance toward a topic) to be inferred by annotators.
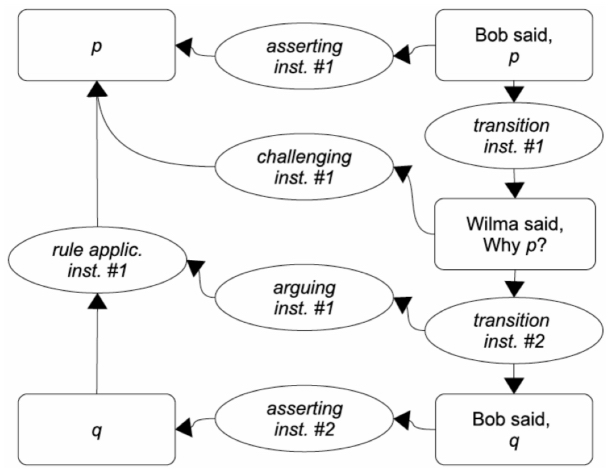
Figure 6.3. An IAT argument map
Some research is interested in identifying (and expliciting) implicit argument components. As a matter of fact, some works focus on evaluating argumentation rather than just analyzing it: some underlying characteristics of arguments must therefore be identified.
In order to enable the detection and analysis of argumentation – including implicit elements – and to address specific domains, genres or a specific application, many researchers have designed their own annotation frameworks. As a result, and as we have just seen in the different graphical representations, the analysis of some components mentioned in the sections above may be of no interest in a certain annotation effort, whereas, for others, more fine-grained annotation schemes may be required (i.e. more labels). As an example, S. Teufel et al. [TEU 99b] annotate elements such as background (general scientific background), other (neutral descriptions of other people’s work) or own (neutral description of the author’s new work) in scientific articles; similarly, K. Al-Khatib et al. [ALK 16] propose classes such as common ground (an accepted truth) or assumption (a general observation, possibly false) in newspapers editorials.
6.2. Examples of argument analysis frameworks
In this section, we propose a brief overview of some analytical frameworks in order to show the diversity of argument models.
6.2.1. Rhetorical Structure Theory
Rhetorical Structure Theory (RST) is a descriptive theory that aims at eliciting rhetorical relations in written texts [MAN 88]. RST allows revealing the structure of natural language texts by showing the different relations between text portions. A wide range of such relations has been identified (e.g. justification, elaboration and restatement), which allow a comprehensive analysis of the hierarchical structure of texts. In RST, the writer’s intention, i.e. what he intends to rhetorically achieve in his discourse, must be taken into account.
This model was not primarily developed for argumentation but for rhetorical relations. Despite the drawbacks that this represents, some works (such as [PEL 13]) have shown that arguments can, nevertheless, be analyzed since the writer/speaker’s intentions and changes in the reader/listener’s attitude/beliefs are at stake. For instance, RST’s scheme allows to elicit justification, evidence, motivation, antithesis or concession relations. RST analyses take the form of tree-like structures where arrows connect satellites to a nucleus. Two major limitations of the model is that (1) only adjacent segments can be analyzed and (2) no parts of the text must be left non-analyzed. M. Azar [AZA 99] uses RST as an annotation tool rather than a theoretical frameworks, shifting RST’s original purpose.
Although RST central idea of functional relations to describe discourse structure subsumes taking into account the writers’ rhetorical aims, the model is not interested in speech acts (or illocutionary forces), and misses the opportunity to describe their intentions. RST, primarily designed for written texts, has been expanded to be applied to dialogues. The model indeed fails to capture the structure of dialogues. As a response to this weakness, A. Stent [STE 00] has modified some RST guidelines and added annotation schemes that allow showing the hierarchical rhetorical structure between argumentative acts in task-oriented dialogues.
Figure 6.4 shows an RST analysis of the text below (both taken from [CAR 03, p. 91]). The different segments are represented by their corresponding numbers in the manual analysis and relations between components are elicited with arrows (from nucleus to satellite) and identified by labels (example, consequence, etc.).
[Still, analysts don’t expect the buy-back to significantly affect per-share earnings in the short term.]16 [The impact won’t be that great,]17[said Graeme Lidgerwood of First Boston Corp.]18 [This is in part because of the effect]19 [of having to average the number of shares outstanding,]20 [she said.]21 [In addition,]22 [Mrs. Lidgerwood said,]23 [Norfolk is likely to draw down its cash initially]24 [to finance the purchases]25 [and thus forfeit some interest income.]26

Figure 6.4. An RST analysis
6.2.2. Toulmin’s model
Many research works have relied on Toulmin’s vision of what an argument is, especially argument visualization frameworks. This model is therefore the cornerstone of many argumentation theories (e.g. [FRE 11, WAL 96]). Despite its high value as a theoretical model, Toulmin’s model often fails at accurately capturing argumentation (e.g. as argued in [NEW 91, HIT 06]). As a result, many researchers have modified the model to satisfy their needs. For instance, I. Habernal and I. Gurevych [HAB 17] propose a modified Toulmin model to annotate texts taken from the web. Indeed, the authors do not annotate qualifiers and warrants but add a category refutation to their tailored scheme. As a result, their analysis framework contains five elements: claim, grounds, backing, rebuttal and refutation. Figure 6.5 is an example of their manual analysis, and Figure 6.6 shows the graphical representation.

Figure 6.5. A manual analysis, taken from [HAB 17, p. 144]
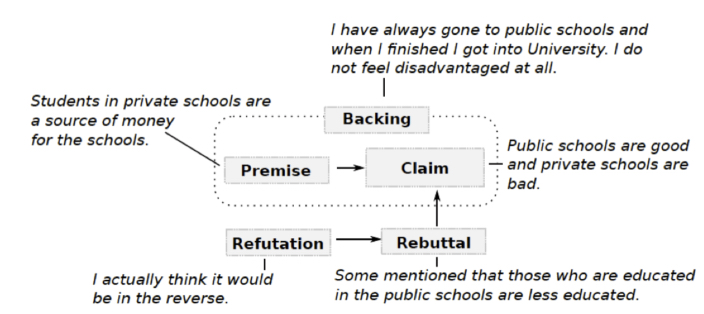
Figure 6.6. A graphical representation following Toulmin’s model, taken from [HAB 17, p. 144]
6.2.3. Inference Anchoring Theory
We have seen in sections 6.1.7 and 6.1.8 that Inference Anchoring Theory (IAT) [BUD 11] is an analytical framework for dialogues. It allows to represent the structure of argumentative dialogues by eliciting the illocutionary forces of locutions (e.g. [BUD 14c]). The expression “argumentative structure” cannot be separated from IAT: it has to be understood as “the shape of the discussion”, i.e. how the discussants’ moves in a dialogue work together to create argumentation. Grounded in SAT (see section 6.1.7), this framework tackles what SAT fails at capturing: the relationship between sequences of speech acts. With the representation of the argumentative structure as a final goal, IAT makes it possible to show how arguments are constructed through dialogical exchanges. Designed to allow incorporating a large variety of argumentation theories, it is flexible enough to be applied to any type of dialogue. Since IAT relies on a standardized representation of arguments and argumentative structures, any argumentation theory schemes can be used to refine the analyses, and the reusability, revision and exchange of the IAT-analyzed dialogues is hence ensured.
This model is a philosophically grounded counterpart to the Argument Interchange Format (AIF) [CHE 06]. The developers of the AIF have tackled the problem of the existence of a wide variety of argumentation theories by proposing a standard way of representing argument analyses. The proposed format allows various theories to make use of the same language in their argument visualization tools, enabling the efficient interchange of data between tools for argument visualization and manipulation (e.g. [REE 17]).
In the AIF, claims are represented by Information nodes (I nodes), and the relationship between claims by Scheme Nodes (S-nodes): inference relations are represented by RA nodes and relations of conflict by CA nodes. An adjunct ontology, AIF+, was later developed to handle the representation of dialogical argumentation, in which the format of the dialogue structure mirrors the one of the argumentation structure [REE 08b]. Locution nodes (L nodes) capture speech acts and speakers, whereas Transition nodes (TA nodes) capture the relationship between L nodes.
IAT has been developed to capture the missing link between argument structures and dialogue structures: by taking into account the illocutionary force of utterances, IAT allows the representation of illocutionary structures that link L nodes to I nodes. Moreover, given that some speakers’ communicative intentions cannot be determined without knowing the broader context of the dialogue – that is, what an utterance is responding to – IAT assumes that it is only by taking into account the relation between L nodes that some illocutionary forces can be inferred; as a result, these illocutionary schemes are anchored in TA nodes and can target I nodes or S nodes (to elicit inference or conflict relations between propositions) [BUD 16]. IAT is therefore a framework developed for the analysis of dialogues in order to elicit argumentative structures. By making the illocutionary forces of locutions apparent, the model allows identifying the argumentative dynamics generated by dialogical moves. The IAT graphical representations of dialogical structures and the attached illocutionary and argumentative structures represent a valuable framework for fine-grained analyses of discourse.
To sum up, an IAT analysis is composed of elements eliciting argument structures and dialogical dynamics via the representation of illocutionary connections, as summarized below:
- – The right-hand side of a graph displays the dialogical structure with:
- - L nodes: the content of the utterances preceded by the speaker’s identification;
- - TA nodes: the transitions between the locutions (or rules of dialogue)4.
- – The left-hand side of a graph displays the argumentative structure with:
- - I nodes: the propositional content of each locution (in front of the corresponding locution node);
- - relations of inference (RA nodes): they connect premises to conclusions;
- - relations of conflict (CA nodes): they connect conflicting information nodes;
- - relations of rephrase (MA nodes): when two information nodes mean the same despite different propositional contents or linguistic surface (see [KON 16]);
- – The relation between the dialogical and the argumentative structure:
- - illocutionary forces connecting a locution node to the corresponding information node (e.g. asserting, questioning and challenging);
- - illocutionary forces connecting a transition node to scheme node (i.e. that can only be derived from the transitions between locutions; e.g. arguing and disagreeing);
- - indexical illocutionary forces connecting a transition node to an information node (e.g. challenging and agreeing)5.
Let us consider the simple example below, taken from the MM2012c corpus6, and describe its IAT analysis in Figure 6.7. The dialogue below (transcribed from a Moral Maze episode) involves Melanie, a panelist, and Alexander, a witness, who are talking about the morality of letting the state interfere in dysfunctional families.
Alexander Brown: If you’re pointing to the phenomena of multiple or clustered disadvantage, if I were going to name one form of disadvantage as the key determiner it would be poverty, not lack of marriage.
Melanie Philips: Why?
Alexander Brown: Because evidence shows that those who are in poverty are more likely to be facing all of these other forms of disadvantage.
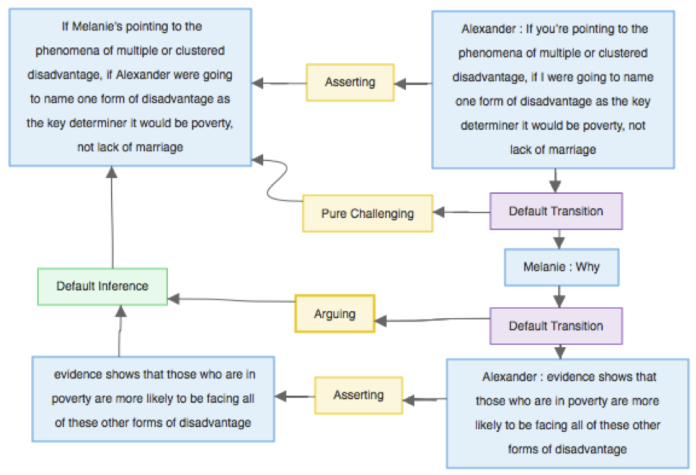
Figure 6.7. An IAT analysis. For a color version of this figure, see www.iste.co.uk/janier/argument.zip
On the right-hand side in Figure 6.7, one can see the dialogical structure, with the speakers’ locutions and the transitions between locutions that represent the dialogical relevance of moves, represented by Default Transition nodes.
The left-hand side of the figure represents the argumentative structure: the proposition if Melanie’s pointing to the phenomena of multiple or clustered disadvantage, if Alexander were going to name one form of disadvantage as the key determiner it would be poverty, not lack of marriage is inferentially related to evidence shows that those who are in poverty are more likely to be facing all of these other forms of disadvantage; this is represented by the Default Inference node. This means that the first proposition is the conclusion and it is supported by one premise.
6.2.4. Summary
The three models presented above show that argument annotation can take many different forms since they do not aim at studying the same aspects of argumentation. We consider these models as relevant and well-known frameworks, although many other models exist, which bear their own capacities and quality.
An important facet of argument annotation is that it is not only a complex task but it is overall time consuming: for instance, I. Habernal and I. Gurevych [HAB 17] explain that it took on average 35 h for each of their three analysts to annotate their data with five categories only. The reader can refer to [BUD 18] or [HAB 17] for detailed reports on annotation processes.
6.3. Guidelines for argument analysis
Keeping in mind that the annotation process is only a first step toward argument mining, the annotations must be consistent with what the argument mining system is designed to do. Moreover, in order to train a system for automatic argument mining, annotations must be reliable. To ensure accuracy and reliability, it is necessary to have several annotators analyzing the same text, but analyzing argumentation is a rather subjective task; variability between annotators is therefore common. This represents a major drawback since argument mining systems may infer patterns from contradictory evidence. To reduce subjectivity and ensure consistency, guidelines for annotators are needed. Different methodologies exist for the definition of guidelines, as we will show here.
6.3.1. Principles of annotation guidelines
In order to ensure the reproducibility of annotations by several annotators, the concepts involved need to be delimited, an annotation protocol needs to be established and human annotators must be trained. Annotation guidelines serve these purposes: they establish a method for the detection and annotation of argument structures and components. They can also be used as a documentation for the resulting annotated data: people who want to use these resources can read annotation guidelines to better understand the semantics of the annotations at stake. In other words, publicly releasing guidelines helps future annotators and readers of an argument analysis. Some researchers have therefore published their annotation handbooks; see, for instance, [STA 15, SAU 06, VIS 18]. Usually, the protocol for an annotation effort mainly consists of the following steps:
- 1) read and understand the text as a whole, to properly assess its communicative aims, to understand the context of each argument component;
- 2) identify the main claims of the argumentation;
- 3) identify claims, premises, attacks;
- 4) identify missing components (e.g. implicit claims, warrants, etc). This step can be skipped if the annotation aim is to analyze explicit argument components only;
- 5) label argument components according to the inventory for the annotation effort at stake;
- 6) identify relations between argument components or identify bigger argumentative structures integrating argument components.
Note that in annotation guidelines, it is important to include typical examples for each step in order to provide annotators with concrete instantiations.
6.3.2. Inter-annotator agreements
Since annotations correspond to annotators’ judgments, there is not an objective way of establishing the validity of an annotation. But a metric about how certain one is of the annotations must be provided; this is called the Inter-Annotator Agreement (IAA). An IAA indeed shows:
- – how easy it was to clearly delineate the categories: if the annotators make the same decision in almost all cases, then the annotation guidelines were very clear;
- – how trustworthy the annotation is: if the IAA is low, it is because the annotators found it difficult to agree on which items belong to which category;
- – how reliable the annotation is: annotations are reliable if annotators consistently make the same decisions; this proves the validity;
- – how stable the annotation is: the extent to which an annotator will produce the same classifications. Stability can be investigated by calculating agreement for the same annotator over time;
- – how reproducible the annotation is: the extent to which different annotators will produce the same classification; reproducibility can be investigated by calculating agreement for different annotators.
There are different ways and metrics for calculating the IAA; we provide some such metrics below. This evaluation step is mandatory to ensure that the annotations are accurate and reproducible.
- 1) The Measure of Observed Agreement gives the percentage of annotations on which the annotators agree:

This approach is seen as biased because it does not take into account the agreement that is due by chance (i.e. when annotators make random choices). Therefore, it is not a good measure of reliability.
- 2) Cohen’s kappa (κ) measures the agreement between two annotators who classify N items into C mutually exclusive categories.
Note that this κ measures agreement between two annotators only. Contrary to the Measure of Observed Agreement, Cohen’s kappa takes into account how often annotators are expected to agree if they make random choices.
The equation for Cohen’s κ is:
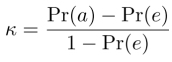
where Pr(a) is the relative observed agreement among annotators and Pr(e) is the hypothetical probability of chance agreement, using the observed data to calculate the probabilities of each observer randomly assigning each category. If the annotators are in complete agreement, then κ = 1. If there is no agreement among them other than what would be expected by chance (as defined by Pr(e)), then κ =0.
- 3) Fleiss’s kappa (κ) [FLE 71] is a statistical measure for assessing the reliability of agreement between a fixed number of annotators when assigning categories to a fixed number of items. This contrasts with other kappas such as Cohen’s κ, which only works when assessing the agreement between two annotators.
The kappa, κ, can be defined as,
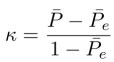
The factor 1 −
 e gives the degree of agreement that is attainable above chance, and − e gives the degree of agreement actually achieved above chance. If the annotators are in complete agreement, then κ = 1. If there is no agreement among the raters (other than what would be expected by chance), then κ ≤ 0.
e gives the degree of agreement that is attainable above chance, and − e gives the degree of agreement actually achieved above chance. If the annotators are in complete agreement, then κ = 1. If there is no agreement among the raters (other than what would be expected by chance), then κ ≤ 0. - 4) Krippendorff’s alpha (α) [KRI 04] is the most reliable, but the most difficult measure. Unlike Cohen’s and Fleiss’s statistics, which measure observed and expected agreement, Krippendorff’s equation measures observed and expected disagreement.
Krippendorff’s α is applicable to any number of coders, each assigning one value to one unit of analysis. Software for calculating Krippendorff’s α is available at http://web.asc.upenn.edu/usr/krippendorff/dogs.html.
6.3.3. Interpretation of IAA measures
Measuring the IAA allows to identify weaknesses in an annotation effort but also in a model or in the guidelines. Indeed, when disagreements are observed between annotators, it is possible to refine the guidelines to avoid discrepancies afterwards. It is unlikely, however, that annotators never disagree on an annotation despite clear and stable guidelines. As a result, the IAA results influence the decision to use analyzed data as a development or training corpus at the time of designing an argument mining system.
J.R. Landis and G.G. Koch [LAN 77] considered the agreement between more than two annotators in the context of a clinical diagnosis. They supplied no evidence to support their interpretation; instead it is based on personal opinion. Table 6.1 presents their interpretation.
Table 6.1. Interpretation of κ results, according to [LAN 77]
| Results Interpretations | |
| 0.0–0.2 | Slight |
| 0.2–0.4 | Fair |
| 0.4–0.6 | Moderate |
| 0.6–0.8 | Substantial |
| 0.8–1 | Perfect |
Following their interpretation, a κ ≥ 0.8 means that the annotations are stable, reliable and reproducible. Consequently, any annotation task resulting in an IAA inferior to 0.8 should not be considered as reliable; it would otherwise deliver poor results at the time of automatically reproducing the task via an argument mining system.
6.3.4. Some examples of IAAs
In order to prove the accuracy of their annotations, researchers can provide the results of the IAA. Generally, results tend to be higher when annotations are carried out on delimited domains, with detailed and specific guidelines. We provide here some results found in the literature:
- – [ALK 16] obtain Fleiss’s κ = 0.56 for the identification of argumentative components in a newspaper editorials corpus;
- – [BIR 11] obtain κ = 0.69 for the identification of justifications to claims in blogs threads. In this case, an intensive use of the structure of the blog, in the form of restrictions for classification, allowed to maintain a substantial agreement. However, the authors did not release annotation guidelines;
- – in [BUD 14b], two annotators analyzed argumentative dialogues with IAT (see section 6.2.3). They report a κ ranging from 0.75 for the detection of conflict relations to 0.9 for the analysis of illocutionary connections;
- – [FAU 14] report κ = 0.70 for three annotators who analyzed 8,179 sentences from student essays and had to decide whether a given sentence provided reasons for or against the essay’s major claim. In this annotation process, the author relied on Amazon Mechanical Turk;
- – [PAR 14] obtain κ = 0.73 for the classification of propositions in four classes for 10,000 sentences in a public platform to discuss regulations (1,047 documents). In this narrow domain, the authors have clearly defined classes, which trigger good IAA results;
- – [ROS 12] obtain κ = 0.50 for the detection of opinionated claims in 2,000 sentences of online discussions and κ = 0.56 for claims in 2,000 sentences from Wikipedia. Although classes are few, they are vaguely defined, and the domain allows for a wide range of variation;
- – [SCH 13] obtain κ = 0.48 for the detection of argument schemes in discussions of deletions in Wikipedia discussion pages. As the authors state, the targeted annotation (argument schemes) is very complex, which makes agreement difficult;
- – for their task of detecting argumentation (claims, major claims, premises and their relations) in 90 argumentative essays (ca. 30,000 tokens), in [STA 14], the authors report a Krippendorff’s αU = 0.72 for argument components and α = 0.81 for relations between components. In this project, annotation guidelines are highly detailed and annotators extensively trained;
- – [TEU 99b] obtains Fleiss’κ = 0.71 for an application to the domain of scientific articles. Here, classes are very specific and clearly defined by their function in the document.
6.3.5. Summary
We have seen that guidelines are used to train expert annotators. The sample of results presented in section 6.3.2 teaches us that, in order to end up with stable, valid and reproducible analyses, (1) guidelines for annotations must be clear and explicit, supported by definitions and examples and (2) analyses must be carried out by various annotators in order to discuss points on which consensus is not reached and improve guidelines. However, given that large amounts of data are needed to deliver a stable and efficient system, some have turned toward non-expert human annotators; see, for instance, [HAB 14, NGU 17]. Crowd-sourced annotations present an indisputable advantage; they allow the rapid gathering of large amounts of analyses. Nevertheless, crowd-sourcing also represents a massive drawback: non-experts, albeit provided with guidelines, tend to deliver poor results, as shown in [HAB 14]. It is therefore recommended to crowd-source annotations for tasks with clear and easy to understand guidelines.
As argued in [WAC 14], κ and α metrics do not show what parts of a text are easier or harder to annotate. Following their annotation work of ADUs in blog posts, they propose a new metrics: a clustering approach to quantify the agreement of annotators not only for the whole annotated text, but also for a given text segment. Equally, K. Budzynska et al. [BUD 18] created a corpus of annotated dialogical arguments without using a traditional method for IAA. Their project was to analyze a debate in a very constrained period of time which left no time for evaluation. Their method is built on two approaches: (1) the iterative enhancement, which consists in iterating annotations after semiautomatic techniques are applied to reveal inconsistencies and (2) the agile corpus creation, where annotations are carried out following a step-by-step process. To do so, they recruited eight experienced annotators (i.e. who had prior knowledge of the annotation scheme) and 10 non-expert annotators who have been trained on a very short time. For this, guidelines for the annotation were proposed and are publicly available7. Throughout the annotation process, experienced annotators discussed the analyses with non-expert ones in order to assess the quality of the annotations and quickly verified the analyses with a checklist referencing the most common mistakes.
In conclusion, annotations of argumentative texts take various forms and do not yield the same results depending on the annotation tasks. It is however necessary to have reliable annotated data to ensure a consistent argument mining system afterwards.
6.4. Annotation tools
Annotating arguments with the aim of providing with a consistent argument mining system requires the annotations to be computationally tractable. Hence, it is necessary to use computational or web-based tools for the annotation task.
Some such tools have not primarily been designed for argument annotations but can, nevertheless, be used for such a task. On the other hand, some annotation tools have specifically been developed for argument analyses. We present here several graphical interfaces that can be used for the annotation task, along with their advantages and drawbacks.
6.4.1. Brat
Brat is an online environment for collaborative text annotation. It is designed for structured annotations, which means that it is possible to annotate text spans and then to show and name the links between several units [STE 12].
Although Brat is not specifically designed for argument analysis, it has been used in several works for the annotation of arguments [LIE 16, TER 18]. Brat, indeed, enables users to add their own scheme set. It is available at http://brat.nlplab.org.

Figure 6.8. An argument analysis in Brat. For a color version of this figure, see www.iste.co.uk/janier/argument.zip
Figure 6.8 shows an argument analysis performed in Brat. In this analysis, ADUs have been assigned a category (claim or premise). Relationships between these units have been described too (support or attack), providing a detailed analysis.
Long-distance dependencies create complex analyses; the linear presentation of the analyses made with Brat represents a major drawback, hampering their readability in some contexts: the structure of the arguments is not always clearly visualized and the connections between argument elements is sometimes difficult to follow. Brat can however suit some annotators, in particular for small texts or when few labels are needed.
6.4.2. RST tool
RST tool is a graphical interface for the annotation of text structures [ODO 00]. As we have seen in section 6.2.1, RST was not initially intended for the analysis of arguments but several works rely on RST relational power for the analysis of argumentation. RST tool allows to manually segment and annotate the relation between segments of a text. As in Brat, new schemes can be added (such as relations other than the initial RST relations). An interesting feature of RST tool is the possibility to extract descriptive statistics from each analysis. The interface also allows users to save, load, reuse and share analyses. The tool and a user guide are freely available at http://wagsoft.com/RSTTool.
Figure 6.9 shows the analysis of the text below (both taken from [PEL 13, p. 16]). It shows, for instance, that the two segments We should tear the building down and because it is full of asbestos are linked by a relation of Evidence:
We should tear the building down, because it is full of asbestos. In principle, it is possible to clean it up, but according to the mayor that would be forbiddingly expensive.
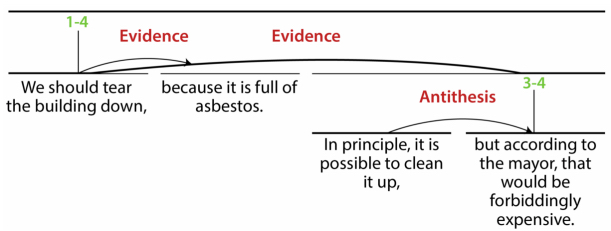
Figure 6.9. An argument analysis with RST tool. For a color version of this figure, see www.iste.co.uk/janier/argument.zip
6.4.3. AGORA-net
AGORA-net is a free computer-supported collaborative argument visualization tool (see http://agora.gatech.edu). It allows showing claims and premises as well as counterarguments. In an AGORA-net analysis, main claims are located on the top left of the map and premises on the right. AGORA-net has mainly been used in problem-solving contexts [HOF 15]. An example of argument analysis (taken from [HOF 14]) is given in Figure 6.10. It shows the main claim and the premises (in blue) as well as a counterargument (here objection in orange).
6.4.4. Araucaria
Araucaria is a free software tool for annotating arguments [REE 04]8. This diagramming tool supports convergent and linked arguments, enthymemes and refutations. As in Brat, new annotation schemes can be added to suit annotators. It also supports argumentation schemes. Arguments analyzed in Araucaria can be saved in the portable format “Argument Markup Language” (AML), which is a flexible language allowing, for instance, to populate a database.
In Araucaria, analyzed claims are represented by nodes and links between them can also be drawn (to show premise–conclusion relationships). Implicit elements can be added to the analyses, such as missing premises, the degree of confidence in a premise or the strength of the inference.

Figure 6.10. An argument map with AGORA-net. For a color version of this figure, see www.iste.co.uk/janier/argument.zip
Araucaria has been used in several works of research [MOE 07, MOC 09], in particular for the analysis of legal texts. Figure 6.11, taken from [REE 08a, p. 93], presents an analysis made in Araucaria. We can see that the tool allows showing premises and conclusions (plain nodes linked by arrows) and unexpressed claims (dashed nodes) as well as argument schemes.
6.4.5. Rationale
Rationale (http://rationaleonline.com) allows building argument maps in order to elicit argumentative structures. It has been developed to support students’ critical thinking and writing skills. Rationale has extensively been used in the legal domain.
Figure 6.12, taken from [VAN 07, p. 26], shows an argument map created with Rationale. It shows the main claim (at the top) and the different premises (in green) and attacks (in red).

Figure 6.11. An argument analysis in Araucaria. For a color version of this figure, see www.iste.co.uk/janier/argument.zip
6.4.6. OVA+
OVA+ (Online Visualization of Argument) is an interface for the analysis of arguments online and is accessible from any web browser at http://ova.arg-tech.org. The tool was built as a response to the AIF [CHE 06]: it is a tool allowing what the AIF has advocated for, i.e. the representation of arguments and the possibility to exchange, share and reuse the argument maps. The system relies on IAT, a philosophically and linguistically grounded counterpart to the AIF [BUD 11] (see also section 6.2). The schemes provided allow for a graphical representation of the argumentative structure of a text, and more interestingly, dialogues [JAN 14].
At the end of the analysis, OVA+ permits saving the work on the user’s computer as an image file. But the most interesting feature is the possibility of saving the analyses in the AIF format either locally or to AIFdb [LAW 12] and adding them to a dedicated corpus (created beforehand) in the AIFdb Corpora9 (see section 6.5 for more details). Thus, the analyses can be reused via AIFdb or loaded in OVA+ for consultation or correction.
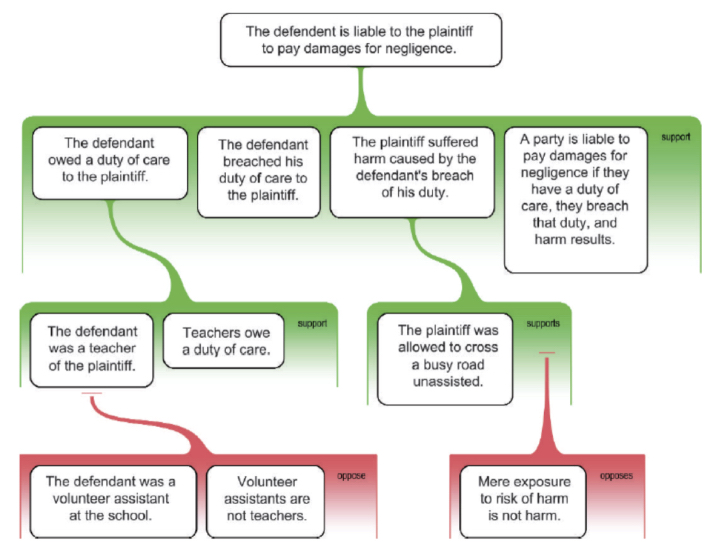
Figure 6.12. An argument map with Rationale. For a color version of this figure, see www.iste.co.uk/janier/argument.zip
Figure 6.13, taken from [REE 17, p. 146], is the analysis of an argumentative dialogue. It allows showing the dialogical dynamics (right-hand side of the figure) and the corresponding argumentative structure (on the left) via the analysis of illocutionary forces (here, asserting, challenging and arguing). OVA+ mainly relies on the IAT framework, therefore conflicts as well as rephrases can also be analyzed and represented.
Contrary to Brat for instance, OVA+, just like Araucaria, has been specifically designed for the analysis of argumentation, which makes the visualization of argumentative structures easier.
6.4.7. Summary
The six tools presented above have been designed for different purposes; as a result, they possess their own features, qualities and drawbacks. They are only a small sample of the various existing annotation tools. Other tools for annotating arguments in text exist, presenting different graphical representations, features or schemes; see, for instance, Dedoose (http://dedoose.com), Lite Map – previously Cohere (http://litemap.net) or Compendium (http://compendiuminstitute.org), to name just a few.

Figure 6.13. An argument analysis in OVA+. For a color version of this figure, see www.iste.co.uk/janier/argument.zip
6.5. Argument corpora
As argued in [HAB 17], the argumentation community lacks data for designing, training and evaluating argument mining algorithms. Scholars may need to build their own corpus, which can be challenging, in particular if the domain at stake involves sensitive data or ethical matters (see, for instance, [JAN 16]).
In order to illustrate their work but also to save others from the burden of finding and gathering texts to create a corpus, some researchers have gathered their analyzed data and made them available. However, they do not all contain the same type of data since they have been used for different objectives. As a result, already available corpora may not suit all argument annotation tasks and aims10. We propose here a sample of argument corpora, which have been built and shared by the community, along with some of their characteristics.
6.5.1. COMARG
The COMARG corpus was not built for argument mining but for opinion mining [BOL 14]: the argument structure is not what the authors intended to highlight; rather, their goal was to elicit the arguments used to support an opinion. The dataset comes from two discussion websites covering controversial topics. Each argument has been labeled by three trained annotators as either for or against the topic. The authors report a Cohen’s κ = 0.49.
6.5.2. A news editorial corpus
K. Al-Khatib et al.[ALK 16] developed a corpus of 300 news editorials from online news portals annotated with domain-dependent units that synthesize the role of a portion of text within the document as a whole (e.g. common ground, assumption or anecdote). Each editorial was annotated by three annotators, with an overall IAA of Fleiss’s κ = 0.56.
6.5.3. THF Airport ArgMining corpus
This corpus, which has been used to train an argument mining system, gathers annotations of contributions to an online discussion platform in German. The analyses have been performed in Brat (see section 6.4.1) for the detection of major positions, claims and premises [LIE 16]. The reader can visit http://dbs.cs.uni-duesseldorf.de/datasets/argmining to consult the THF Airport ArgMining corpus.
6.5.4. A Wikipedia articles corpus
E. Aharoni et al. [AHA 14] propose a corpus of annotated claims and their corresponding evidence of 586 Wikipedia articles. The authors report a Cohen’s κ = 0.39 and κ = 0.40 for the analyses of claims and evidence, respectively. The corpus is available upon request.
6.5.5. AraucariaDB
The Araucaria corpus [REE 06] is a corpus of annotated texts (from a variety of sources and domains), realized in the Araucaria software (see section 6.4.4) and presenting argument structures and, more interestingly, argument schemes. Despite the relative subjectivity involved in differentiating argument schemes (see section 6.1.5), C. Reed [REE 06] notes that some argumentation schemes occur frequently in the corpus. Thus, the Araucaria corpus has been used as a proof-of-concept for argument mining systems that aim to detect argumentation schemes (see [MOC 09, FEN 11]). Unfortunately, annotation guidelines and IAAs have not been reported.
6.5.6. An annotated essays corpus
In their general purpose corpus, Stab and Gurevych [STA 14] have identified claims, premises, support and attack relations, with a κ = 0.72 for argument components and κ = 0.81 for relations. The domain of the corpus being quite general (argumentative essays), the argumentative strategies found in this kind of text are very general and it can be expected that they can be ported to other domains with little effort.
6.5.7. A written dialogs corpus
In [BIR 11], O. Biran and O. Rambow annotated claims and justifications in LiveJournal blog threads and Wikipedia pages. They do not provide guidelines but report a κ = 0.69.
6.5.8. A web discourse corpus
I. Habernal and I. Gurevych [HAB 17] claim to have built the largest corpus for argument mining purposes: it contains approximately 90,000 tokens from 340 documents. Additionally to various target domains (e.g. homeschooling or single-sex education), their corpus covers different genres such as online article comments, discussion forum posts or professional newswire articles. The reader can see section 6.2.2 for more details on the annotations.
6.5.9. Argument Interchange Format Database
AIFdb 11 is one of the largest datasets of annotated arguments12. In order to group argument maps and enable the search for maps that are related to each other, J. Lawrence et al. [LAW 15] propose the AIFdb Corpora interface13, which allows users to create and share their corpora. AIFdb Corpora is closely related with OVA+ (see section 6.4.6); the interface therefore allows the creation of large corpora compliant with both AIF and IAT (see section 6.2.3). The argument maps thus elicit argument and dialogue structures, argument schemes, illocutionary connections, among others (see sections 6.4.6 and 6.2.3 for an overview of the analytical framework).
AIFdb Corpora is actually a corpus of several corpora, coming from a wide range of sources (e.g. radio debates, mediation sessions, public consultations and political debates). Although this repository contains already analyzed argument structures (i.e. non-argumentative units are not presented), in some cases the original texts they are extracted from are also given. The tool also allows a user to share a link to their corpus and to view and download the corpus contents in different formats (SVG, PNG, DOT, JSON, RDF-XML, Prolog, as well as the format of the Carneades [BEX 12] and Rationale (see section 6.4.5) tools, or as an archive file containing JSON format representations of each argument map). It is also possible to view, evaluate and edit the argument maps contained within the corpus via OVA+.
Another interesting feature provided by the interface is its link to http://analytics.arg.tech; this offers statistics and insight into the size and structure of corpora, and allows comparison between them (for measuring a κ for instance) [REE 17].
6.5.10. Summary
Unsurprisingly, most corpora constructed so far concern the English language but a few other languages have also been considered. For instance, in AIFdb 11 languages are represented [LAW 15]; C. Houy et al. [HOU 13] and A. Peldszus [PEL 14] propose different corpora of German texts, whereas C. Sardianos et al. [SAR 15] and P. Reisert et al. [REI 14] present corpora of texts in Greek and Japanese languages, respectively.
This brief presentation of some corpora that have been built and shared is only a small sample of the different corpora used for argument annotations. This overview shows that data for argument detection and analysis are various: each corpus has its own characteristics and suits a specific aim. Despite a predominance of ad hoc corpora (meaning that they have been constructed for one particular purpose and, often, for one precise domain), some have been used to test models other than the one they had been built for in the first place. This shows that different frameworks and datasets can be valuable to different purposes. As an example, M. Lippi and P. Torroni [LIP 15] propose different corpora of German texts, including C. Stab and I. Gurevych’s [STA 15] corpus, to test their model for argument detection. Unfortunately, some corpora have not been made public, impeding their sharing and use by others.
6.6. Conclusion
In this chapter, we have seen that argument annotation is a very challenging task. Although it relies on the same principle (i.e. the identification and analysis of argumentative components), not all existing frameworks for argument annotations focus on the same elements. We have also seen that precise guidelines are necessary to reach acceptable annotations, and the different tools that have been designed for argument analyses further demonstrate that the analysis of arguments can take various forms and not all argument analysis frameworks focus on the same facets of argumentation.
However, one can find, adapt or design the existing tools and frameworks to suit her needs. Moreover, the large range of corpora proposed in the literature shows that the diverse datasets for argument analysis have their own characteristics and each may suit upcoming research threads. Nevertheless, it can be argued that a reference corpus for argument mining would relieve scholars of the burden of building, annotating and evaluating such textual data, and would unify approaches. It must be kept in mind, however, that such a corpus would require a clear and detailed scheme along with reliable annotations. In the following chapter, we will show how manual analyses help building argument mining systems.
- 1 This example is extracted from a BBC radio program The Moral Maze, a moderated debate in which panelists and witnesses are invited to discuss social, political and economical current issues.
- 2 http://corpora.aifdb.org/britishempire.
- 3 A complete argument map is available at http://corpora.aifdb.org/mm2012; it shows that the relationship between the first and second ADUs is one of counterargument (or disagreement), while the second and third ADUs form an argument. More details on these annotations are given in section 6.2.3.
- 4 In a dialogue, locutions are the moves that speakers make. The rules of the dialogue should constrain speakers to advance certain types of moves and prevent them to advance others at some point in the dialogue. Transition nodes capture the concept of rules of dialogue by eliciting the relationship between locutions, that is, which rule has been triggered that allows a speaker to respond to another speaker, for example. This concept of rule of dialogue is visible in dialectical games, in which rules explicitly define the rights and obligations of speakers.
- 5 IAT can also handle reported speech by unpacking the propositional content of a reported speech and the propositional content of a reporting speech.
- 6 More details about this corpus are given in section 6.5.9.
- 7 http://arg-tech.org/IAT-guidelines.
- 8 See http://araucaria.computing.dundee.ac.uk/doku.php.
- 9 http://corpora.aifdb.org.
- 10 The annotation process being a highly demanding task, corpora to be annotated are sometimes preprocessed, for instance to presegment the text or simply to verify whether argumentation is present (see, for instance, [HAB 17]).
- 11 http://aifdb.org.
- 12 In 2015, AIFdb contained over 4,000 argument maps [LAW 15].
- 13 http://corpora.aifdb.org.