
Appendix B. Upcoming MLlib Pipelines API
The Spark project moves fast. When we started writing in August 2014, version 1.1.0 was nearing release. As this book goes to print in April 2015, Spark 1.2.1 is hot off the presses. In this version alone, almost 1,000 improvements and fixes were added.
The project carefully maintains binary and source compatibility for stable APIs in minor releases, and most of MLlib is considered stable. The examples in the book should therefore continue to work with Spark 1.3.0 and future 1.x releases; those implementations won’t be going anywhere. However, new releases often add or change experimental or developer-only APIs, which are still evolving.
Spark MLlib has, of course, featured prominently in these chapters, and a book covering Spark 1.2.1 would not be complete without mentioning a significant new direction for MLlib that appears, in part, as an experimental API: the “Pipelines” API.
It’s officially only a month or so old, subject to change, and not nearly complete, and so it has not been possible to build the book around it. However, it’s worth knowing about, having already seen what MLlib offers today.
This appendix will give a quick look at the new Pipelines API, the result of work discussed in SPARK-3530 in the Spark project issue tracker.
Beyond Mere Modeling
In purpose and scope, the current MLlib resembles other machine learning libraries.
It provides an implementation of machine learning algorithms, and just the core implementation.
Each takes preprocessed input as an RDD of LabeledPoint or Rating objects, for example,
and returns some representation of the resulting model. That’s all. This is quite useful,
but solving a real-world machine learning problem requires more than just running an algorithm.
You may have noticed that in each chapter of the book, most of the source code exists to prepare features from raw input, transform the features, and evaluate the model in some way. Calling an MLlib algorithm is just a small, easy part in the middle.
These additional tasks are common to just about any machine learning problem. In fact, a real production machine learning deployment probably involves many more tasks:
-
Parse raw data into features
-
Transform features into other features
-
Build a model
-
Evaluate a model
-
Tune model hyperparameters
-
Rebuild and deploy a model, continuously
-
Update a model in real time
-
Answer queries from the model in real time
Viewed this way, MLlib provides only a small part: #3. The new Pipelines API begins to expand MLlib so that it’s a framework for tackling tasks #1 through #5. These are the very tasks that we have had to complete by hand in different ways throughout the book.
The rest is important, but likely out of scope for MLlib. These aspects may be implemented with a combination of tools like Spark Streaming, JPMML, REST APIs, Apache Kafka, and so on.
The Pipelines API
The new Pipelines API encapsulates a simple, tidy view of these machine learning tasks: at each stage, data is turned into other data, and eventually turned into a model, which is itself an entity that just creates data (predictions) from other data too (input).
Data, here, is always represented by a specialized RDD borrowed from Spark SQL,
the org.apache.spark.sql.SchemaRDD class. As its name implies, it contains table-like data,
wherein each element is a Row. Each Row has the same “columns,” whose schema is known,
including name, type, and so on.
This enables convenient SQL-like operations to transform, project, filter, and join this data. Along with the rest of Spark’s APIs, this mostly answers task #1 in the previous list.
More importantly, the existence of schema information means that the machine learning algorithms
can more correctly and automatically distinguish between numeric and categorical features.
Input is no longer just an array of Double values, where the caller is responsible for
communicating which are actually categorical.
The rest of the new Pipelines API, or at least the portions already released for preview as
experimental APIs, lives under the org.apache.spark.ml package—compare with the
current stable APIs in the org.apache.spark.mllib package.
The Transformer abstraction represents
logic that can transform data into other data—a SchemaRDD into another SchemaRDD.
An Estimator represents logic that can build a machine learning model, or Model, from
a SchemaRDD. And a Model is itself a Transformer.
org.apache.spark.ml.feature contains some helpful implementations like HashingTF for computing
term frequencies in TF-IDF, or Tokenizer for simple parsing. In this way, the new API helps
support task #2.
The Pipeline abstraction then represents a series of Transformer and Estimator objects,
which may be applied in sequence to an input SchemaRDD in order to output a Model.
Pipeline itself is therefore an Estimator, because it produces a Model!
This design allows for some interesting combinations. Because a Pipeline may contain an
Estimator, it means it may internally build a Model, which is then used as a Transformer.
That is, the Pipeline may build and use the predictions of an algorithm internally as part of
a larger flow. In fact, this also means that Pipeline can contain other
Pipeline instances inside.
To answer task #3, there is already a simple implementation of at least one actual
model-building algorithm in this new experimental API,
org.apache.spark.ml.classification.LogisticRegression. While
it’s possible to wrap existing org.apache.spark.mllib implementations as an Estimator, the
new API already provides a rewritten implementation of logistic regression for us, for example.
The Evaluator abstraction supports evaluation of model predictions. It is in turn used in
the CrossValidator class in org.apache.spark.ml.tuning to create and evaluate many
Model instances from a SchemaRDD—so, it is also an Estimator. Supporting APIs in
org.apache.spark.ml.params define hyperparameters and grid search parameters for use
with CrossValidator. These packages help with tasks #4 and #5, then—evaluating and tuning
models as part of a larger pipeline.
Text Classification Example Walkthrough
The Spark Examples module contains a simple example of the new API in action, in the
org.apache.spark.examples.ml.SimpleTextClassificationPipeline class. Its action is illustrated in
Figure B-1.
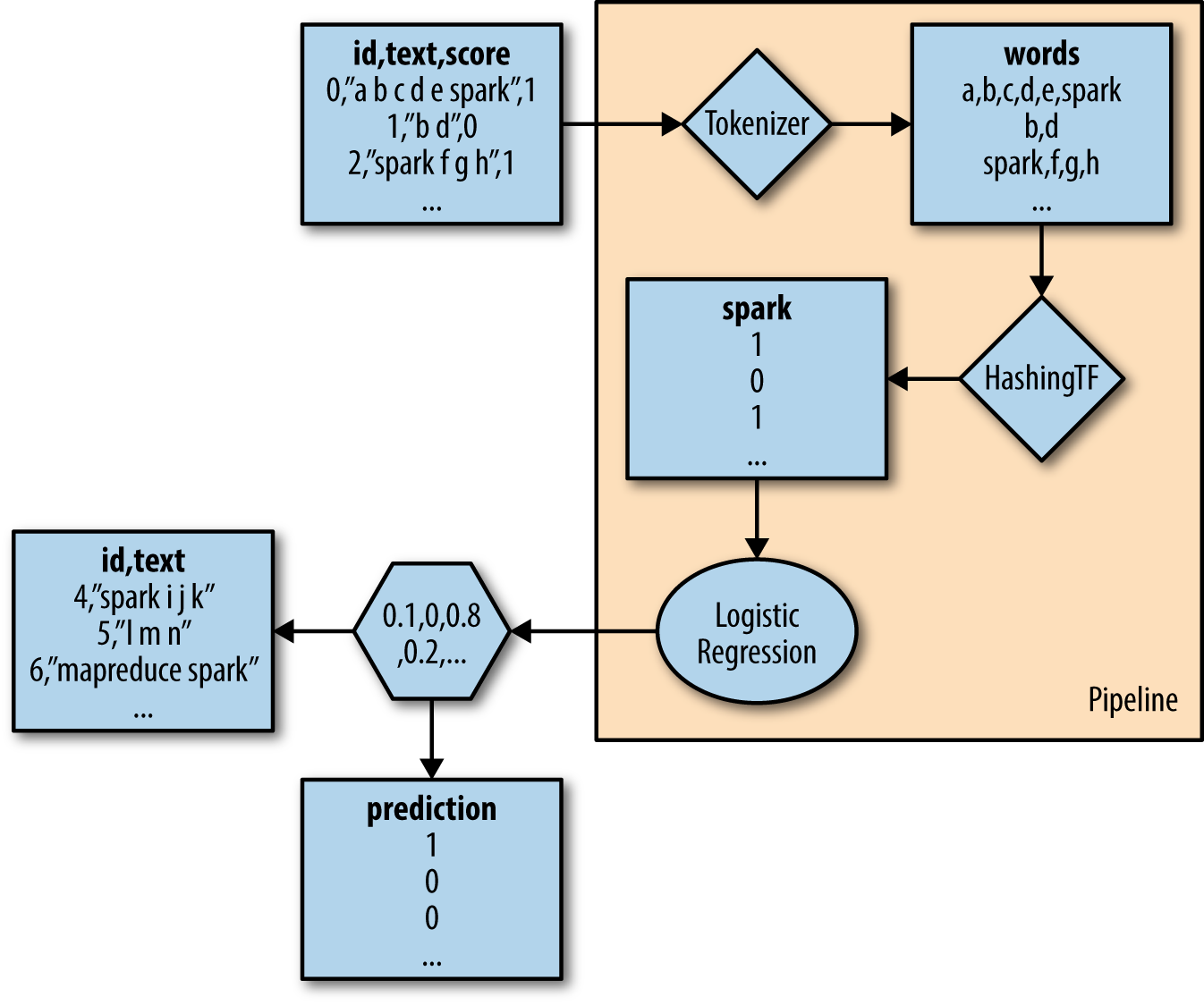
Figure B-1. A simple text classification Pipeline
The input are objects representing documents, with an ID, text, and
score (label). Although training is not a SchemaRDD, it will be implicitly
converted later:
valtraining=sparkContext.parallelize(Seq(LabeledDocument(0L,"a b c d e spark",1.0),LabeledDocument(1L,"b d",0.0),LabeledDocument(2L,"spark f g h",1.0),LabeledDocument(3L,"hadoop mapreduce",0.0)))
The Pipeline applies two Transformer implementations. First, Tokenizer
separates text into words by space. Then, HashingTF computes term frequencies for each
word. Finally, LogisticRegression creates a classifier using these term frequencies
as input features:
valtokenizer=newTokenizer().setInputCol("text").setOutputCol("words")valhashingTF=newHashingTF().setNumFeatures(1000).setInputCol(tokenizer.getOutputCol).setOutputCol("features")vallr=newLogisticRegression().setMaxIter(10).setRegParam(0.01)
These operations are combined into a Pipeline that actually creates a model
from the training input:
valpipeline=newPipeline().setStages(Array(tokenizer,hashingTF,lr))valmodel=pipeline.fit(training)

Implicit conversion to SchemaRDD
Finally, this model can be used to classify new documents. Note that model is really
a Pipeline containing all the transformation logic, not just a call to a
classifier model:
valtest=sparkContext.parallelize(Seq(Document(4L,"spark i j k"),Document(5L,"l m n"),Document(6L,"mapreduce spark"),Document(7L,"apache hadoop")))model.transform(test).select('id,'text,'score,'prediction).collect().foreach(println)
Not strings; syntax for Expressions
The code for an entire pipeline is simpler, better organized, and more reusable compared to the handwritten code that is currently necessary to implement the same functionality around MLlib.
Look forward to more additions, and change, in the new org.apache.spark.ml Pipeline API
in Spark 1.3.0 and beyond.