
Chapter 11: Exploring the Best Use Cases for ShardingSphere
You are approaching the end of this book – some might say that congratulations are in order. By now, you'll have developed a keen understanding of Apache ShardingSphere, its architecture, clients, and features, and even probably started trying it in your environment.
By all means, you could consider yourself ready to get to work by leveraging ShardingSphere. Nevertheless, we thought we would share this chapter with you. We have carefully selected some cases from real-world scenarios that a few Apache ShardingSphere users frequently deal with. These users include small and medium enterprises (SMEs) as well as large enterprises listed on the international stock markets.
These will help you better orient yourself among the numerous possibilities that ShardingSphere offers when paired with your databases. In this chapter, we're going to cover the following main topics:
- Recommended distributed database solution
- Recommended database security solution
- Recommended synthetic monitoring solution
- Recommended database gateway solution
Technical requirements
No hands-on experience in a specific language is required but it would be beneficial to have some experience in Java since ShardingSphere is coded in Java.
To run the practical examples in this chapter, you will need the following tools:
- A 2 cores 4 GB machine with Unix or Windows OS: ShardingSphere can be launched on most OSs.
- JRE or JDK 8+: This is the basic environment for all Java applications.
- Text editor (not mandatory): You can use Vim or VS Code to modify the YAML configuration files.
- A MySQL/PG client: You can use the default CLI or other SQL clients such as Navicat or DataGrip to execute SQL queries.
- 7-Zip or tar command: You can use these tools for Linux or macOS to decompress the proxy artifact.
You can find the complete code file here:
https://github.com/PacktPublishing/A-Definitive-Guide-to-Apache-ShardingSphere
Recommended distributed database solution
Standalone storage and query performance bottlenecks often occur in traditional relational databases. To solve these problems, Apache ShardingSphere proposes a lightweight distributed database solution and also achieves enhanced features such as data sharding, distributed transaction, and elastic scaling, based on the storage and computing capabilities of relational databases.
With the help of Apache ShardingSphere technologies, enterprises don't need to bear the technical risks brought by replacing storage engines. On the premise that their original relational databases are stable, enterprises can still have the scalability of distributed databases.
The architecture of the distributed database solution contains five core functions, as follows:
- Sharding
- Read/write splitting
- Distributed transactions
- High availability
- Elastic scaling
You can see these core functions in Figure 11.1:
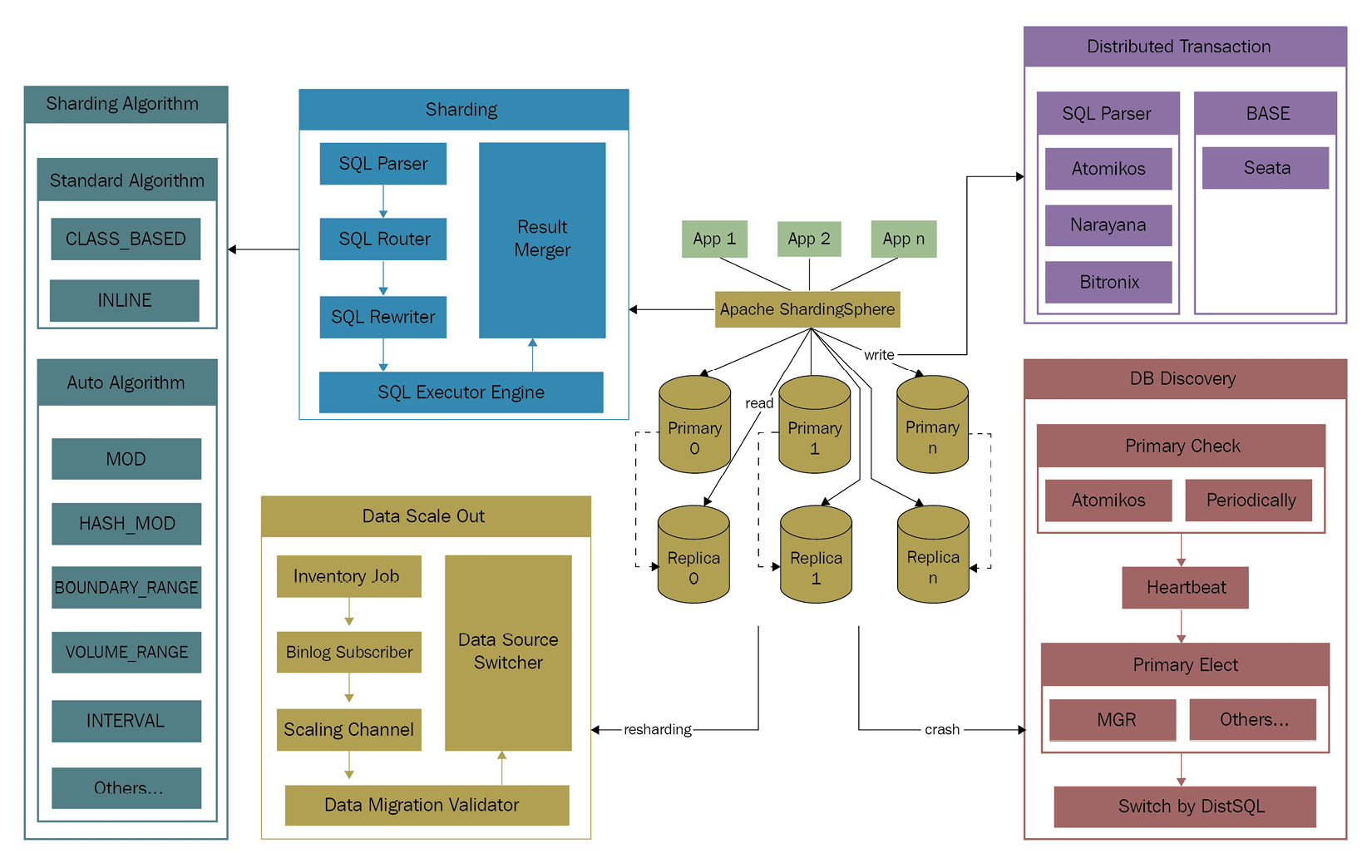
Figure 11.1 – ShardingSphere distributed database solution architecture
Data sharding allows users to define sharding rules to transparently process sharding. Apache ShardingSphere has multiple built-in sharding algorithms, such as standard sharding algorithms and auto-sharding algorithms. You can also leverage the extension point to define a custom sharding algorithm.
Based on the primary-secondary database architecture, read/write splitting can route write and read requests to the write database and read database respectively according to the user's SQL, to improve the database query performance. Concurrently, read/write splitting also eliminates the read/write lock, effectively enhancing write performance.
To manage the distributed transaction in distributed databases, Apache ShardingSphere has the built-in integration of eXtended Architecture (XA) transactions and Basically Available, Soft state, Eventually consistent (BASE) transactions. The former can meet the requirements for strong consistency, while the latter can ensure eventual consistency. By integrating the mainstream transaction solutions, ShardingSphere is enabled to meet the transaction management needs in various user scenarios.
Apache ShardingSphere's High Availability (HA) function not only utilizes the HA of the underlying database but also provides automated database discovery that can automatically sense changes in the primary and secondary database relationship, thereby correcting the connection of the computing node to the database and ensuring HA at the application layer.
Elastic scaling is the function used to scale out distributed databases. The function supports both homogeneous and heterogeneous databases, so users can directly manage scale-out with the help of DistSQL and trigger it by modifying sharding rules.
In the following sections, you will learn how to use the tools at your disposal to create your distributed databases, how to configure them, and how to use their features.
Two clients to choose from
Currently, Apache ShardingSphere's distributed database solution supports ShardingSphere-JDBC and ShardingSphere-Proxy, but it's planned to support cloud-native ShardingSphere-Sidecar in the future.
The access terminal of ShardingSphere-JDBC targets Java applications. Since its implementation complies with the Java database connectivity (JDBC) standards, it is compatible with mainstream object relation mapping (ORM) frameworks, such as MyBatis and Hibernate. Users can quickly integrate ShardingSphere-JDBC by installing its .jar packages.
Additionally, the architecture of ShardingSphere-JDBC is decentralized, so it shares resources with applications. ShardingSphere-JDBC is suitable for high-performance online transaction processing (OLTP) applications developed in Java. You can deploy ShardingSphere-JDBC in the standalone mode or the large-scale cluster mode together with the governance function to uniformly manage cluster configuration.
ShardingSphere-Proxy provides a centralized static entry, and it is suitable for heterogeneous languages and online analytical processing (OLAP) application scenarios. Figure 11.2 gives you an overview of how a deployment including both ShardingSphere-JDBC and ShardingSphere-Proxy is structured:

Figure 11.2 – Hybrid deployment example
ShardingSphere-JDBC and ShardingSphere-Proxy can be deployed independently, and hybrid deployment is also allowed. By adopting a unified registry center to centrally manage configurations, according to the characteristics of different access terminals, architects can build application systems suitable for all kinds of scenarios.
Your DBMS
So far, the distributed database solution of Apache ShardingSphere has supported some popular relational databases, such as MySQL, PostgreSQL, Oracle, SQLServer, and the relational databases adhering to the SQL-92 standard. Users can choose a database as the storage node of Apache ShardingSphere based on the current database infrastructure.
In the future, Apache ShardingSphere will continue to better support heterogeneous databases, including NoSQL, NewSQL, and so on. It will use the centralized database gateway as the entrance, and its internal SQL dialect converter to convert SQL into the SQL dialects of heterogeneous databases to centralize heterogeneous database management.
Sharding strategy
There are four built-in sharding strategies in Apache ShardingSphere: Standard, Complex, Hint, and None. A sharding strategy includes a sharding key and sharding algorithm, and accordingly, the user needs to specify the sharding key and sharding algorithm of the sharding strategy.
Take the Standard sharding strategy as an example. The usual configuration is shown as follows: shardingColumn is the sharding key, and shardingAlgorithmName is the sharding algorithm. The combination of the sharding key and sharding algorithm can implement sharding both at the database level and the table level:
YAML
rules:
- !SHARDING
tables:
t_order:
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database_inline
After this, you need to configure the sharding algorithms, according to the following script:
YAML
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: ds_${user_id % 2}Sometimes, your SQL might not contain the sharding key, but the sharding key actually exists in the external logic. In this scenario, you can use the Hint sharding strategy and code sharding conditions to realize flexible sharding routing. shardingAlgorithmName is used to specify the sharding algorithm, while the common configuration of the Hint sharding strategy can be broken down into simple steps. The following steps guide you through the configuration.
To get started, you could refer to the following script:
YAML
rules:
- !SHARDING
tables:
t_order:
databaseStrategy:
hint:
shardingAlgorithmName: database_hint
To configure the hint algorithm, you could refer to the following script:
YAML
shardingAlgorithms:
database_hint:
type: CLASS_BASED
props:
strategy: HINT
algorithmClassName: xxx
After the configuration is complete, you can utilize HintManager to set the database sharding key value and the table sharding key value. The following code snippet is an example of HintManager usage. addDatabaseShardingValue and addTableShardingValue are used to specify the sharding key value for the logical table. Additionally, since HintManager uses ThreadLocal to maintain the shard key value, you should use the close method to close it at the end, or use try with resource to close it automatically:
Java
try (HintManager hintManager = HintManager.getInstance();
Connection connection = dataSource.getConnection();
PreparedStatement preparedStatement = connection.prepareStatement(sql)){ hintManager.addDatabaseShardingValue("t_order", 2); try (ResultSet resultSet = preparedStatement.executeQuery()) { while (resultSet.next()) {}
}
}
The previous script can help you understand how HintManager works.
Distributed transaction
The distributed database solution also supports distributed transactions, including XA and BASE. Distributed transactions provide eventual consistency semantics. In XA mode, if the isolation level of the storage database is serializable, strong consistency semantics can be achieved. The following code snippet showcases how to use XA:
YAML
// Proxy server.yaml
rules:
- !AUTHORITY
users:
- root@%:root
- sharding@:sharding
- !TRANSACTION
defaultType: XA
providerType: Atomikos
To use the Narayana implementation, providerType will be configured as narayana and will add the narayana dependencies. The following script is the perfect example to refer to:
Plain Text
// shardingsphere/pom.xml Delete these item's scope
<dependency>
<groupId>org.jboss.narayana.jta</groupId>
<artifactId>jta</artifactId>
<version>${narayana.version}</version></dependency>
<dependency>
<groupId>org.jboss.narayana.jts</groupId>
<artifactId>narayana-jts-integration</artifactId>
<version>${narayana.version}</version></dependency>
<dependency>
<groupId>org.jboss</groupId>
<artifactId>jboss-transaction-spi</artifactId>
<version>${jboss-transaction-spi.version}</version></dependency>
<dependency>
<groupId>org.jboss.logging</groupId>
<artifactId>jboss-logging</artifactId>
<version>${jboss-logging.version}</version></dependency>
// shardingsphere/shardingsphere-kernel/shardingsphere-transaction/shardingsphere-transaction-type/shardingsphere-transaction-xa/shardingsphere-transaction-xa-core/pom.xml add dependencies
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-transaction-xa-narayana</artifactId>
<version>${project.version}</version></dependency>
You can directly package narayana for use by modifying the source code dependencies as shown in the preceding code.
HA and the read/write splitting strategy
The following is the YAML script to set the writeDataSourceName and readDataSourceNames parameters to specify the writer data source and reader data sourceto set the writeDataSourceName and readDataSourceNames parameters to specify the writer data source and reader data source.
Apply P-Code to text in bold:
YAML
rules:
- !READWRITE_SPLITTING
dataSources:
readwrite_ds:
writeDataSourceName: write_ds
readDataSourceNames: read_ds_0,read_ds_1
Dynamic read/write splitting is a type of read/write splitting jointly used with HA. HA can discover the primary-secondary relationship of the underlying databases and dynamically correct the connection between Apache ShardingSphere and the databases, further ensuring HA at the application layer. The configuration of dynamic read/write splitting is shown here:
YAML
rules:
- !DB_DISCOVERY
dataSources:
readwrite_ds:
dataSourceNames:
- ds_0
- ds_1
- ds_2
discoveryHeartbeatName: mgr-heartbeat
discoveryTypeName: mgr
As you can see, you do not need to specify the write data source and read data source in the configuration of read/write splitting because HA can automatically detect the writer and the reader.
The following step is to proceed to configure discoveryHeartbeats so that the system can know which resources are available for you to configure:
YAML
discoveryHeartbeats:
mgr-heartbeat:
props:
keep-alive-cron: '0/5 * * * * ?'
discoveryTypes:
mgr:
type: MGR
props:
group-name: 92504d5b-6dec-11e8-91ea-246e9612aaf1
The discoveryHeartbeats configuration step is followed by configuring read/write splitting:
YAML
- !READWRITE_SPLITTING
dataSources:
readwrite_ds:
autoAwareDataSourceName: readwrite_ds
Once done, you will have successfully configured your read/write splitting strategy with Apache ShardingSphere.
Elastic scaling
Elastic scaling usually involves sharding rule changes and so is closely related to data sharding. Moreover, elastic scaling is compatible with other core features, such as read/write splitting and HA. Therefore, when the system needs scale-out, regardless of what the current configuration is, elastic scaling can be enabled.
There are many elastic scaling configurations, for example, some for performance tuning, some for resource usage limitation, and some can be customized through a serial peripheral interface (SPI).
The common server.yaml configuration is as follows:
YAML
scaling:
blockQueueSize: 10000
workerThread: 40
clusterAutoSwitchAlgorithm:
type: IDLE
props:
incremental-task-idle-minute-threshold: 30
dataConsistencyCheckAlgorithm:
type: DEFAULT
mode:
type: Cluster
repository:
type: ZooKeeper
props:
namespace: governance_ds
server-lists: localhost:2181
retryIntervalMilliseconds: 500
timeToLiveSeconds: 60
maxRetries: 3
operationTimeoutMilliseconds: 500
overwrite: false
If you are planning on leveraging elastic scaling, the previous script will become fairly familiar to you.
Distributed governance
Apache ShardingSphere supports three operating modes, namely Memory, Standalone, and Cluster:
- In Memory mode, metadata is stored in the current process.
- In Standalone mode, metadata is stored in a file.
- For Cluster mode, the storage metadata and coordination of the state of each computing node occurs in the registry center.
Apache ShardingSphere integrates ZooKeeper and etcd internally, which enables it to use event notification of registry node changes to synchronize metadata between clusters and configuration information.
Next, we will show you how to configure the three modes of Apache ShardingSphere. Let's start with how to configure Memory mode. The first will be to specify the mode, as follows:
YAML
mode:
type: Memory
It is very simple to configure Memory mode, and as you will see in the following script, the same can be said about Standalone mode:
YAML
mode:
type: Standalone
repository:
type: File
overwrite: false
The remaining one, Cluster mode, requires a little more coding in the script:
YAML
mode:
type: Cluster
repository:
type: ZooKeeper
props:
namespace: governance_ds
server-lists: localhost:2181
retryIntervalMilliseconds: 500
timeToLiveSeconds: 60
maxRetries: 3
operationTimeoutMilliseconds: 500
overwrite: false
Although the script is a little longer, Cluster mode is nevertheless just as easy to configure, as you can see.
Now, we can jump to security-focused features. The next section will guide you through real-world examples for building your database security solution.
Recommended database security solution
In terms of data security, Apache ShardingSphere provides you with a reliable but easy data encryption solution along with authentication and privilege control.
Simply put, the encryption engine and built-in encryption algorithms provided by ShardingSphere can automatically encrypt and store the input information and decrypt it into plaintext when querying, and then send it back to the client. In this way, you won't have to worry about data encryption and decryption to secure data storage.
In the following sections, you will find real-world examples to implement ShardingSphere for your database security, the tools at your disposal, and how to configure them for data encryption, data migration with encryption, authentication, and SQL authority.
Implementing ShardingSphere for database security
The specific architecture diagram of the data security solution is presented in Figure 11.3. The solution consists of core components such as authentication, authority checker, encrypt engine, encryption algorithm, and online legacy unencrypted data processor:

Figure 11.3 – ShardingSphere's database security architecture
As you can see from the previous figure, ShardingSphere can help build a complete solution solving all of your database security concerns. You may be wondering what the key aspects are that you should be mindful of when it comes to database security and ShardingSphere, and the following list will help you answer this question.
Let's now learn more about the key elements of database security:
- Authentication – Currently, Apache ShardingSphere supports the password authentication protocols of MySQL (mysql_native_password) and PostgreSQL (md5). In the future, ShardingSphere will add more authentication methods.
- Privilege control – Apache ShardingSphere provides two levels of permission control policies, ALL_PRIVILEGES_PERMITTED and SCHEMA_PRIVILEGES_PERMITTED. You can choose to use one of them or implement an SPI for a custom extension.
- Encryption engine – Based on the encryption rules, the engine can parse the input SQL and automatically calculate and rewrite the content to be encrypted and store the ciphertext in the storage node. When you query encrypted data, ShardingSphere can decrypt and output the plaintext.
- Encryption algorithm – ShardingSphere's built-in encryption algorithms contain AES, RC4, and MD5, for example, and you can also customize other extensions through an SPI.
- Legacy unencrypted data processor (under development) – This function can convert the legacy plaintext data in databases into a ciphertext for storage to help you complete historical data migration and system upgrades.
The next section will guide you through the tools that are available to you for setting up your database security solution.
Two clients to choose from
Both ShardingSphere-JDBC and ShardingSphere-Proxy can access the encryption engine and encryption algorithms, and their performance is exactly the same.
However, centralized authentication and authority control are unique features of ShardingSphere-Proxy. For more details, please refer to the User authentication and the SQL authority sections in Chapter 4, Key Features and Use Cases – Focusing on Performance and Security.
In the future, the data processor will also be integrated into ShardingSphere-Proxy.
Applying a data security solution to your DBMS
Similar to the sharding solution, the data security solution is independent of the type of storage node and is implemented on the basis of standard SQL. Therefore, you can apply ShardingSphere to access MySQL, PostgreSQL, or any relational databases complying with the SQL-92 standard, and the user experience will be the same. In the future, the data security feature will support more heterogeneous scenarios, allowing you to meet your requirements.
Data encryption/data masking
Data encryption makes distributed databases even more secure. ShardingSphere frees you from the encryption process but enables you to directly use it. The following is an encryption configuration example:
YAML
rules:
- !ENCRYPT
encryptors:
aes_encryptor:
type: AES
props:
aes-key-value: 123456abc
tables:
t_encrypt:
columns:
user_id:
cipherColumn: user_cipher
encryptorName: aes_encryptor
In addition to the AES and MD5 encryption algorithms, ShardingSphere supports other encryption algorithms, such as SM3, SM4, and RC4. You can also load custom algorithms via the SPI. In terms of the configuration of encrypted fields, ShardingSphere also provides configurations of cipher fields, plaintext fields, cipher query assistant fields, and so on. You can choose an appropriate configuration method that fits your actual scenarios.
Data migration with encryption
The previous section described how to enable data encryption. Data encryption is only valid for new or updated data, while read-only legacy data cannot be encrypted. Currently, you would need to encrypt legacy data by yourself. To fix the issue and help improve efficiency, ShardingSphere is going to release the legacy data encryption feature soon.
Categorized by destination, there are two types of data migration with encryption: encrypt data migrated to a new cluster and encrypt data in the original cluster.
To achieve data migration to a new cluster with encryption, you need to know the implementation method and the steps. The steps for data migration with encryption are similar to the elastic scaling steps we introduced you to in the previous section. This method takes a relatively long time, so if you only need data encryption, we don't recommend this method. However, when you happen to want elastic scaling, you can consider this method and implement elastic scaling at the same time.
In terms of data encryption in the original cluster, only a small amount of data needs migrating, and only the new encryption-related columns need to be processed, which is not time-consuming at all. If you need data encryption, choose this method.
Authentication
We have already outlined how to implement user authentication in a distributed database in Chapter 4, Key Features and Use Cases – Focusing on Performance and Security. Here is the sample configuration provided by ShardingSphere:
YAML
rules:
- !AUTHORITY
users:
- root@%:root
- sharding@:sharding
This configuration shows how to define two different users, that is, root and sharding with the same password and username.
The user login addresses are not recruited, allowing them to connect to ShardingSphere from any host and log in.
When you or the administrator need to restrict a user login address, please refer to the following format:
YAML
rules:
- !AUTHORITY
users:
- root@%:root
- sharding@:sharding
- [email protected]:password1
- [email protected]:password2
In this way, user1 and user2 can only log in from a given IP and cannot connect to ShardingSphere from other addresses. This is a very important security control measure.
In production applications, it is recommended that users may choose to restrict login addresses if the network environment allows it.
SQL authority/privilege checking
In the SQL authority section in Chapter 4, Key Features and Use Cases – Focusing on Performance and Security, we talked about the two level-authority providers:
- ALL_PRIVILEGES_PERMITTED:
- All permissions are granted to users without any permission restrictions.
- Default and no configuration required.
- Suitable for testing and verification, or an application environment where you are absolutely trusted.
- SCHEMA_PRIVILEGES_PERMITTED:
- Grants user access to the specified schema.
- Requires specific configuration.
- Suitable for application environments where the scope of user access needs to be limited.
The administrator needs to choose one based on the real application environment.
The next section allows you to have the best use case reference for synthetic monitoring.
Recommended synthetic monitoring solution
Full-link stress testing is a complex and huge project because it requires the cooperation of various microservices and middleware. Apache ShardingSphere's database solution for full-link online stress testing scenarios is referred to as the stress testing shadow database function created to help you isolate stress testing data and avoid contaminating data.
Openness and cooperation have always been natural attributes of the open source community. Apache ShardingSphere, together with Apache APISIX and Apache SkyWalking, jointly launched the project CyborgFlow, a low-cost out-of-the-box (OOTB) full-link online stress testing solution capable of analyzing data traffic in a full link from a unified perspective.
As you can see from Figure 11.4, CyborgFlow is a complete stress testing and monitoring solution:
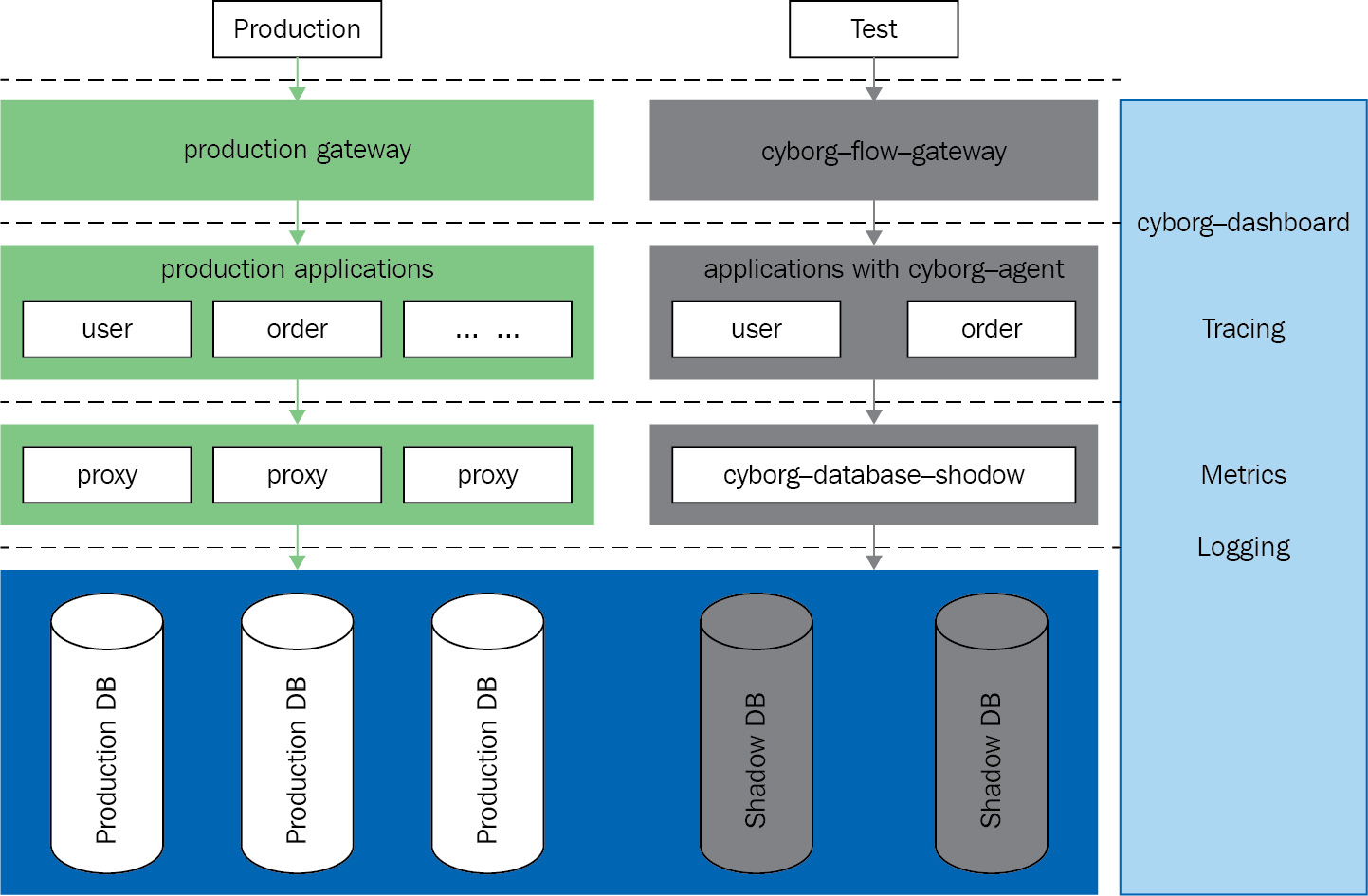
Figure 11.4 – CyborgFlow overview
Now that you have a visual overview of the synthetic monitoring solution, let's jump into the specifics in the following sections.
Flow gateway
To perform online pressure testing in a production environment, we need to enable the stress testing gateway layer to undertake the testing traffic.
The stress testing gateway plugin, cyborg-flow-gateway, is implemented by Apache APISIX in accordance with the SkyWalking protocol. According to user configuration, the gateway can encapsulate the specified traffic and pass it with the stress testing identifier to the context of the entire link call. The gateway supports authentication and authorization flow processing according to the needs of different services. After completion, users only need to release resources, making the process transparent to the production environment.
Application performance monitoring and Cyborg Agent
With Apache SkyWalking's Cyborg Dashboard, you can monitor changes in the stress testing environment from a centralized perspective, which facilitates reasonable intervention in the flow of stress testing and ensures smooth progress.
Cyborg Agent has the ability to transparently transmit stress testing markers across the link. When an application calls the shadow database, cyborg-database-shadow, it can intercept the SQL and append the stress testing identifier to it by means of annotations.
In addition, Cyborg Agent leverages the bytecode technology to free users from manually tracking events and the service deployment is stateless.
Database shield
Cyborg database shadow empowered by Apache ShardingSphere can isolate data based on stress testing identifiers.
The shadow database can parse SQL statements and find stress test identifiers in the annotation. Based on the user-configured HINT shadow algorithm, it can determine stress test identifiers. If it successfully finds the identifier in the SQL statement, the SQL is routed to the stress testing data source.
This concludes the synthetic monitoring solution section. The next section will introduce the best use cases for the database gateway solution.
Recommended database gateway solution
A database gateway is an entry for database cluster traffic. It shields complex connections between applications and database clusters, and therefore, upper-layer applications connected to the database gateway don't need to care about the real state of the underlying database cluster. Additionally, with certain configurations, other features, such as traffic redistribution and traffic governance, can be implemented.
Apache ShardingSphere built above databases can provide enhanced capabilities and manage the data traffic between the application and the database. Thereby, ShardingSphere naturally becomes a database gateway.
Overview and architecture
The overall architecture of the Apache ShardingSphere database gateway solution is shown in the following figure. The core components include read/write splitting and the registry center. Leveraging the distributed governance capabilities of the registry, ShardingSphere can flexibly manage the status and the traffic of computing nodes. The underlying database state of read/write splitting is also maintained in the registry center, and thus by disabling/enabling a read database, you can govern read/write splitting traffic:

Figure 11.5 – ShardingSphere's database gateway solution
Equipped with the overview provided in Figure 11.5, let's now dive into the specifics.
Database management
Database management is a form of ShardingSphere's database traffic governance. Database management consists of two parts:
- Managing ShardingSphere instances
- Managing real database nodes
In fact, database management is based on the distributed governance function of ShardingSphere. The ability provided by Cluster mode can ensure data consistency, state consistency, and service HA of the cluster when deploying online. ShardingSphere implements the distributed governance capabilities of ZooKeeper and etcd by default.
ShardingSphere instances and real database nodes are stored in the registry center as computing nodes and storage nodes, respectively. Their states can be managed through performing operations on the data in the registry center, and then results will be synchronized in real time to all computing nodes in the cluster. The storage structure of the registry center is as follows:
Bash
namespace
├──status
├ ├──compute_nodes
├ ├ ├──online
├ ├ ├ ├──${your_instance_ip_a}@${your_instance_port_x} ├ ├ ├ ├──${your_instance_ip_b}@${your_instance_port_y}├ ├ ├ ├──....
├ ├ ├──circuit_breaker
├ ├ ├ ├──${your_instance_ip_c}@${your_instance_port_v} ├ ├ ├ ├──${your_instance_ip_d}@${your_instance_port_w}├ ├ ├ ├──....
├ ├──storage_nodes
├ ├ ├──disable
├ ├ ├ ├──${schema_1.ds_0} ├ ├ ├ ├──${schema_1.ds_1}├ ├ ├ ├──....
├ ├ ├──primary
├ ├ ├ ├──${schema_2.ds_0} ├ ├ ├ ├──${schema_2.ds_1}├ ├ ├ ├──....
You can see that ShardingSphere provides the online status and circuit_breaker to manage computing nodes. The latter is used to temporarily shut down the traffic of ShardingSphere instances, and then the instances cannot provide external services until you change the status to online. The availability of both the online status and circuit_breaker makes it convenient to manage the state of computing nodes, that is, ShardingSphere instances:
- Write DISABLED (case-insensitive) in the IP address @PORT node to break the instance, and delete DISABLED to enable it.
The ZooKeeper command is as follows:
Bash
[zk: localhost:2181(CONNECTED) 0] set /${your_zk_namespace}/status/compute_nodes/circuit_breaker/${your_instance_ip_a}@${your_instance_port_x} DISABLED
- Use DistSQL to quickly manage the status of computing nodes:
Bash
[enable / disable] instance IP=xxx, PORT=xxx
Here is an example:
Apache
disable instance IP=127.0.0.1, PORT=3307
Note
Although DistSQL has no restrictions on it, it is still not recommended to break the ShardingSphere instances connected to the current client, because the operation may cause the client to become incapable of executing any commands. This issue has been fixed in the updated version 5.1.1 of ShardingSphere.
In terms of storage node management, ShardingSphere provides disable and primary: the former is used for data nodes while the latter is used to manage the primary database.
Storage node management is usually applied for managing the primary database and the secondary databases, also known as the write database and the read database in the read/write splitting scenario.
Similarly, ShardingSphere manages computing nodes to temporarily disable the traffic of a read database. After being disabled, the secondary database cannot allocate any read traffic. No matter which read/write splitting strategy is configured by the user, all Select requests from the application are undertaken by other read databases before the data node is re-enabled.
Let's look at an example implementation case. In the read/write splitting scenario, users can write DISABLED (case-insensitive) in the data source name's subnode to disable the secondary database's data source, and delete DISABLED or the node to enable it. Let's see the necessary steps to configure the read/write splitting scenario:
- The ZooKeeper command is as follows:
Bash
[zk: localhost:2181(CONNECTED) 0] set /${your_zk_namespace}/status/storage_nodes/disable/${your_schema_name.your_replica_datasource_name} DISABLED
- Use DistSQL to quickly manage the storage node status:
Bash
[enable / disable] readwrite_splitting read xxx [from schema]
Here is an example:
Bash
disable readwrite_splitting read resource_0
Read/write splitting
Read/write splitting is one of the typical application scenarios of data traffic governance in ShardingSphere. With the increasing access volume of application systems, the challenge to solve the throughput bottleneck is inevitable. The read/write splitting architecture is the mainstream solution at present; by splitting databases into primary databases and secondary databases, the former handles transactional addition, deletion, and modification operations, and the latter processes query operations. This method can effectively avoid row locks caused by data updates, and significantly improve the query performance of the entire system.
By configuring one primary database with multiple secondary databases, query requests can be evenly distributed to multiple data copies to further improve the processing capacity of the system. ShardingSphere supports the one primary with multiple secondary architecture well, and its YAML configuration is as follows:
YAML
schemaName: readwrite_splitting_db
dataSources:
primary_ds:
url: jdbc:postgresql://127.0.0.1:5432/demo_primary_ds
username: postgres
password: postgres
replica_ds_0:
# omitted data source config
replica_ds_1:
# omitted data source config
The rules necessary to complete the configuration are as follows:
rules:
- !READWRITE_SPLITTING
dataSources:
pr_ds:
writeDataSourceName: primary_ds
readDataSourceNames:
- replica_ds_0
- replica_ds_1
loadBalancerName: loadbalancer_pr_ds
While the necessary load balancers are as follows:
loadBalancers:
loadbalancer_pr_ds:
type: ROUND_ROBIN
In the preceding example, one write database is configured through writeDataSourceName, two read databases are configured through readDataSourceNames, and a load balancing algorithm named loadbalancer_pr_ds is configured as well. ShardingSphere has two built-in load balancing algorithms that users can configure directly:
- A polling algorithm with the ROUND_ROBIN configuration type
- A random algorithm with the RANDOM configuration type
ShardingSphere provides users with OOTB built-in algorithms that can meet most user scenarios. If the preceding two algorithms cannot meet your scenarios, you, or developers in general, can also define your own load balancing algorithms by implementing the ReplicaLoadBalanceAlgorithm algorithm interface. It's recommended to commit the algorithm to the Apache ShardingSphere community to help other developers with the same needs.
The read/write splitting configuration of ShardingSphere can be used independently or together with data sharding. To ensure consistency, all transactional read/write operations should use the write database.
In addition to custom read-database load balancing algorithms, ShardingSphere also provides Hint to force the routing of traffic to the write database.
In real application scenarios, you should pay attention to the following tips:
- ShardingSphere is not responsible for data synchronization between the write database and the read database, and users need to handle it based on the database type.
- Users need to deal with data inconsistency caused by delays in data synchronization of the primary database and the secondary database according to the database type.
- Currently, ShardingSphere does not support multiple primary databases.
This concludes our read/write splitting section. This is a mainstay feature of the ShardingSphere ecosystem, and if you are looking to apply the theory you have picked up for this feature, all you have to do is continue reading.
Summary
If this chapter has achieved the aim we set for it, you should be able to better strategize your ShardingSphere integration with your databases.
Being an ecosystem that has quickly grown to include not only multiple features but multiple clients and deployment possibilities as well, ShardingSphere may seem challenging at first.
While this is absolutely not the case, and while we built this project to simplify database management, the size of the project in itself merits clarification. Thanks to this chapter, we hope that you will be able to better plan your approach to integrating ShardingSphere and make informed decisions.
Nevertheless, at this point, we are still talking about theory, so you may be wondering about the last step of putting theory into practice.
You will find that the next chapter is perfectly tied in with the use cases you have encountered here. Starting with the first section, you will find real-world examples combining multiple features. You can base your future work on these examples, as we believe they will support you in getting things started.