
Chapter 8: Apache ShardingSphere Advanced Usage – Database Plus and Plugin Platform
This chapter will take your understanding of, and capability in leveraging, ShardingSphere to the next level. After covering the basic features and configurations, you will learn how to customize ShardingSphere according to your requirement, to get the most out of your system.
We will cover the following topics in this chapter:
- Plugin platform introduction and SPI
- User-defined functions and strategies – SQL parser, sharding, read/write splitting, and distributed transactions
- User-defined functions and strategies – data encryption, SQL authority, user authentication, SQL authority, shadow DB, and distributed governance
- ShardingSphere-Proxy – tuning properties and user scenarios
By the end of this chapter, you will be able to create, configure, and run a custom version of ShardingSphere for distributed transactions, read/write splitting, and other features.
Technical requirements
No hands-on experience in a specific language is required but it would be beneficial to have some experience in Java since ShardingSphere is coded in Java.
To run the practical examples in this chapter, you will need the following tools:
- JRE or JDK 8+: This is the basic environment for all Java applications.
- Text editor (not mandatory): You can use Vim or VS Code to modify the YAML configuration files.
- An IDE: You can use tools such as Eclipse or IntelliJ IDEA for coding.
- A MySQL/PG client: You can use the default CLI or other SQL clients such as Navicat or DataGrip to execute SQL.
- A 2 cores 4 GB machine with a Unix OS or Windows OS: ShardingSphere can be launched on most OSs.
You can find the complete code file here:
https://github.com/PacktPublishing/A-Definitive-Guide-to-Apache-ShardingSphere
Important Note
The Introducing Database Plus section is an extract from an excellent article written by Zhang Liang (one of the authors of this book) that explains what Database Plus is all about. You can read the complete article here: https://faun.pub/whats-the-database-plus-concepand-what-challenges-can-it-solve-715920ba65aa (License: CC0).
Introducing Database Plus
Database Plus is our community's design concept for distributed database systems, designed to build an ecosystem on top of fragmented heterogeneous databases. With this concept, our goal is to provide globally scalable and enhanced computing capabilities, while at the same time maximizing the original database computing capabilities.
With the introduction of this concept, the interaction between applications and databases is oriented toward the Database Plus standard, which means that the impact of database fragmentation is greatly minimized when it comes to upper-layer services. We set out to pursue this concept with the three keywords that define it: Connect, Enhance, and Pluggable.
ShardingSphere's pursuit of Database Plus
To understand how we have leveraged these three keywords to formulate our development concept, we thought that an introduction to each one of them would be helpful to you. Let us dive deeper into each one.
Connect – building upper-level standards for databases
Rather than providing an entirely new standard, Database Plus provides an intermediate layer that can be adapted to a variety of SQL dialects and database access protocols. This implies that an open interface to connect to various databases is provided by ShardingSphere.
Thanks to the implementation of the database access protocol, Database Plus provides the same experience as a database and can support any development language, and database access client.
Moreover, Database Plus supports maximum conversion between SQL dialects. An AST (abstract syntax tree) that parses SQL can be used to regenerate SQL according to the rules of other database dialects. The SQL dialect conversion makes it possible for heterogeneous databases to access each other. This way, users can use any SQL dialect to access heterogeneous underlying databases.
ShardingSphere's database gateway is the best interpretation of Connect. It is the prerequisite for Database Plus to provide a solution for database fragmentation. This is done by building a common open docking layer positioned in the upper layer of the database, to pool all the access traffic of the fragmented databases.
Enhance – database computing enhancement engine
Following decades of development, databases now boast their own query optimizer, transaction engine, storage engine, and other time-tested storage and computing capabilities and design models. With the advent of the distributed and cloud-native era, the original computing and storage capabilities of the database will be scattered and woven into a distributed and cloud-native level of new capabilities.
Database Plus adopts a design philosophy that emphasizes traditional database practices, while at the same time adapting to the new generation of distributed databases. Whether centralized or distributed, Database Plus can repurpose and enhance the storage and native computing capabilities of a database.
The capabilities enhancement mainly refers to three aspects: distributed, data control, and traffic control.
Data fragmentation, elastic scaling, high availability, read/write splitting, distributed transactions, and heterogeneous database federated queries based on the vertical split are all capabilities that Database Plus can provide at the global level for distributed heterogeneous databases. It doesn't focus on the database itself, but on the top of the fragmented database, focusing on the global collaboration between multiple databases.
In addition to distributed enhancement, data control and traffic control enhancements are both in the silo structure. Incremental capabilities for data control include data encryption, data desensitization, data watermarking, data traceability, SQL audit etc.
Incremental capabilities for traffic control include shadow library, gray release, SQL firewall, blacklist and whitelist, circuit-breaker and rate-limiting, and so on. They are all provided by the database ecosystem layer. However, owing to database fragmentation, it is a huge amount of work to provide full enhancement capability for each database, and there is no unified standard. Database Plus provides users like you with the permutation and combination of supported database types and enhancements by providing a fulcrum.
Pluggable – building a database-oriented functional ecosystem
The Database Plus common layer could become bloated due to docking with an increasing number of database types, and additional enhancement capability. The pluggability borne out of Connect and Enhance is not only the foundation of Database Plus' common layer but also the effective guarantee of infinite ecosystem expansion possibilities.
The pluggable architecture enables Database Plus to truly build a database-oriented functional ecosystem, unifying and managing the global capabilities of heterogeneous databases. It is not only for the distribution of centralized databases but also for the silo function integration of distributed databases.
Microkernel design and pluggable architecture are core values of the Database Plus concept, which is oriented towards a common platform layer rather than a specific function.
Database Plus is the development concept driving ShardingSphere, and ShardingSphere is the best practitioner of the Database Plus concept.
The next sections of this chapter will guide you through the ecosystem's plugin platform that we developed following the Database Plus concept, as well as a few user-defined functions and strategies.
Plugin platform introduction and SPI
Apache ShardingSphere is designed based on a pluggable architecture, where the system provides a variety of plugins that you can choose from to customize your unique system.
The pluggable architecture makes Apache ShardingSphere extremely scalable, allowing you to extend the system based on extension points without changing the core code, making it a developer-oriented design architecture. Developers can easily participate in code development without worrying about the impact on other modules, which also stimulates the open source community and ensures high-quality project development.
The pluggable architecture of Apache ShardingSphere
Apache ShardingSphere is highly scalable through its SPI mechanism, which allows many functional implementations to be loaded into the system. SPI is an API provided by Java, to be implemented or extended by third parties, allowing you to replace and extend Apache ShardingSphere's features in the SPI way. The following diagram illustrates ShardingSphere's pluggable architecture design:
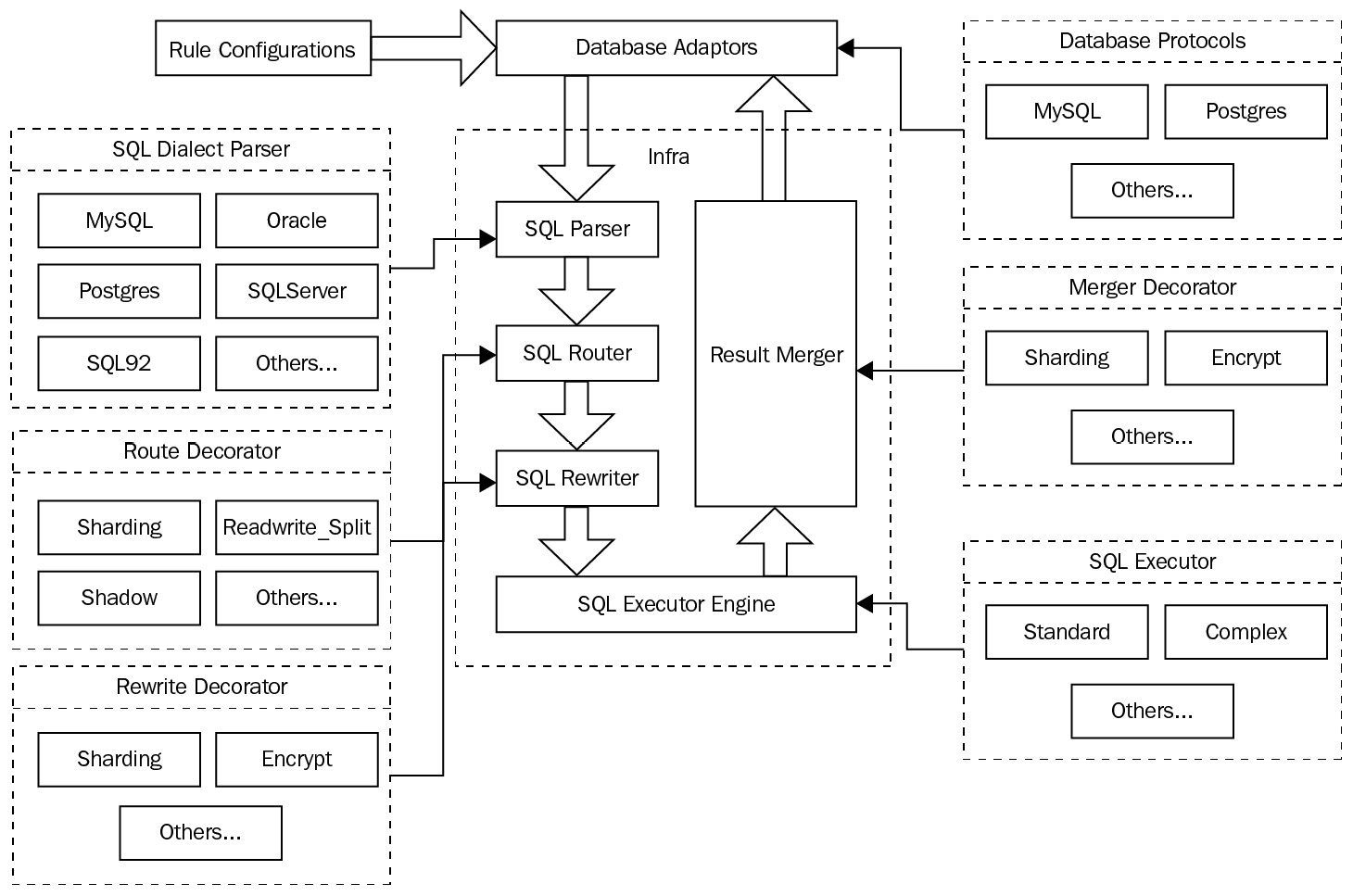
Figure 8.1 – ShardingSphere's pluggable architecture design
As you can see, the pluggable architecture of Apache ShardingSphere consists of a kernel layer, a functional layer, and an ecosystem layer:
- The kernel layer is the foundation of the database and contains all the basic capabilities of the database. Based on a plugin-oriented design concept, these functions are abstracted and their implementation can be replaced with pluggable means. Its main capabilities include the query optimizer, distributed transaction engine, distributed execution engine, permission engine, and scheduling engine.
- The functional layer mainly provides incremental capabilities for the database. Its main capabilities include data sharding, read/write splitting, database high availability, data encryption, and shadow libraries.
These features are isolated from each other, and you can choose any combination of features to be used in an overlay. Additionally, you can develop extensions based on the existing extension points, without modifying the kernel code.
- The ecosystem layer consists of database protocols, a SQL parser, and a storage adaptor. This layer is used to adapt to and interface with the existing database ecosystem. The database protocol is used to accommodate and serve various dialects of database protocols, the SQL parser is used to interface with various database dialects, and the storage adaptor is used to interface with the database type of the storage node.
These three layers, together with the SPI loading mechanism, constitute a highly scalable and pluggable architecture.
Extensible algorithms and interfaces
This section will provide you with a very useful reference that you will find yourself coming back to quite often in the future.
In the following lists, we will show the SPI for every mode, configuration, kernel, data source, and more. As you can see, for each section (mode, configuration, kernel, and data source) you will be presented with two columns: the left column provides you with the SPI, while the right column provides you with a useful and quick description of what the SPI does:
- Operation mode: As you may recall, ShardingSphere operates in three modes – memory mode, standalone mode, and cluster mode. You may choose the one that best fits your scenario's requirements:
- Configuration: ShardingSphere's rule configuration includes multiple SPI interfaces, such as RuleBuilder for building rules and YamlRuleConfigurationSwapper and ShardingSphereYamlConstruct for converting rules:
- Kernel: The kernel of Apache ShardingSphere offers multiple SPI portals, such as SQLRouter and SQLRewriteContextDecorator:
- Data sources: DataSource is a data source in ShardingSphere and allows you to manage data sources and the related SPI interfaces for metadata loading:
- SQL parsing: ShardingSphere's SQL parsing engine is responsible for parsing different database dialects. You can implement the SPI interface to add new database dialect parsing:
- Proxy side: The proxy access end includes the database protocol SPI interface, DatabaseProtocolFrontendEngine, and the authority SPI interface, AuthorityProvideAlgorithm, for granting permissions:
- Data sharding: Data sharding is the sharding feature of ShardingSphere. The feature internally provides SPI interfaces such as ShardingAlgorithm and KeyGenerateAlgorithm:
- Read/write splitting: ReadWriteSplitting is the read/write splitting feature of ShardingSphere, which provides SPI interfaces such as ReplicaLoadBalanceAlgorithm:
- High Availability (HA): Based on the HA solution, you can achieve high availability of database services by dynamically monitoring changes in the storage nodes:
- Distributed transactions: The distributed transaction feature of ShardingSphere provides a solution for data consistency in distributed scenarios, with multiple built-in extensible SPI interfaces:
- ShardingSphereTransactionManager: Distributed transaction manager
- XATransactionManagerProvider: XA distributed transaction manager
- XADataSourceDefinition: Automatically converts non-XA data sources into XA data sources
- DataSourcePropertyProvider: For obtaining the standard properties of data source connection pools
- Auto scaling: Scaling supports scaling up and scaling down capabilities in distributed database clusters while considering the user's fast-growing business:
- SQL checking: SQL checking is used to check SQL, and currently implements AuthorityChecker:
- SQLChecker: SQL checker
- Data encryption: ShardingSphere's data encryption and decryption feature provides the EncryptAlgorithm and QueryAssistedEncryptAlgorithm SPI interfaces:
- Shadow library: Shadow is the shadow library feature of ShardingSphere, which can meet your needs for online pressure testing. This feature provides the ShadowAlgorithm SPI interface:
- Observability: Observability is responsible for collecting, storing, and analyzing system observability data, monitoring, and diagnosing system performance. By default, it provides support for SkyWalking, Zipkin, Jaeger, and OpenTelemetry:
This completes the SPI configurations. Now, let's look at the functions and strategies that you can customize by yourself.
User-defined functions and strategies – SQL parser, sharding, read/write splitting, distributed transactions
In this section, you will learn how to create and configure custom functions. We will start with the SQL parser before looking at data sharding, read/write splitting, and, finally, distributed transactions. The examples and steps you will find in the following sections will empower you to make Apache ShardingSphere truly yours.
Customizing your SQL parser
This section will describe how to use the SQL parser engine, which is compatible with different database dialects. By parsing SQL statements to a message that can be understood by Apache ShardingSphere, enhanced database features can be achieved. Various dialect parsers that are part of the SQL parser are loaded through the SPI method. Therefore, you can handily develop or enrich database dialects.
Implementation
Let's review the necessary code to get started. In this section, you will learn how to parse SQL into a statement and how to format SQL.
First, let's parse SQL into a statement:
Java
CacheOption cacheOption = new CacheOption(128, 1024L, 4);
SQLParserEngine parserEngine = new SQLParserEngine("MySQL", cacheOption, false);ParseContext parseContext = parserEngine.parse("SELECT t.id, t.name, t.age FROM table1 AS t ORDER BY t.id DESC;", false);SQLVisitorEngine visitorEngine = new SQLVisitorEngine("MySQL", "STATEMENT", new Properties());MySQLStatement sqlStatement = visitorEngine.visit(parseContext);
System.out.println(sqlStatement.toString());
Java
Properties props = new Properties();
props.setProperty("parameterized", "false");CacheOption cacheOption = new CacheOption(128, 1024L, 4);
SQLParserEngine parserEngine = new SQLParserEngine("MySQL", cacheOption, false);ParseContext parseContext = parserEngine.parse("SELECT age AS b, name AS n FROM table1 JOIN table2 WHERE id = 1 AND name = 'lu';", false);SQLVisitorEngine visitorEngine = new SQLVisitorEngine("MySQL", "FORMAT", props);String result = visitorEngine.visit(parseContext);
System.out.println(result);
Now, let's review the extensible algorithms at your disposal.
Extensible algorithms
As we mentioned previously, we are going to provide you with extensible algorithms. This will be the format we will follow throughout this chapter – first, you will review the implementation, and then move on to the extensible algorithms for each feature.
ShardingSphere provides the following extensible access for its parsing engine, making it convenient to parse other SQL dialects:
- Configure lexical and syntactic parsers for the SQL parser interface:
CSS
org.apache.shardingsphere.sql.parser.spi.DatabaseTypedSQLParserFacade
- Configure the SQL syntax tree visitor interface:
CSS
The next section will introduce you to the extensible algorithms of ShardingSphere's original feature: data sharding.
Customizing the data sharding feature
The sharding function can horizontally divide user data, improve system performance and usability, and slash operation and maintenance costs. The sharding function also provides rich extensibility. You can expand the sharding algorithm and distributed sequence algorithm based on the SPI mechanism.
The following sections will show you how to implement a sharding algorithm by following a simple two-step process.
Implementation
- STANDARD, COMPLEX, and HINT are supported for implementing their corresponding algorithms. Here, we will use STANDARD as an example:
public class MyDBRangeShardingAlgorithm implementsStandardShardingAlgorithm<Integer> {
@Override
public String doSharding(final Collection<String> availableTargetNames, finalPreciseShardingValue<Integer> shardingValue) {
return null;
}
@Override
public String getType() {
return "CLASS_BASED";
}
- Add SPIconfiguration, as follows (please refer to the Java standard SPI loading method):
CSS
org.apache.shardingsphere.sharding.spi.ShardingAlgorithm
- Next, let's apply the algorithm to implement a user-defined distributed sequence algorithm:
TypeScript
public final class IncrementKeyGenerateAlgorithm implements KeyGenerateAlgorithm {
private final AtomicInteger count = new AtomicInteger();
@Override
public Comparable<?> generateKey() {
return count.incrementAndGet();
}
@Override
public String getType() {
return "INCREMENT";
}
}
- Add the SPI configuration (please refer to the Java standard SPI loading method):
Extensible algorithms
ShardingSphere provides you with extensible access to user-defined sharding algorithms and distributed sequence algorithms.
Use the following code to gain user-defined sharding algorithm access:
org.apache.shardingsphere.sharding.spi.ShardingAlgorithm
Use the following code to gain user-defined distributed sequence algorithm access:
The next section will guide you through the read/write splitting implementation and its extensible algorithms.
Read/write splitting
Read/writing splitting refers to a splitting architecture that divides a database into a primary database and a secondary database. The primary database is in charge of adding, deleting, and modifying transactions, while the secondary database queries operations.
Read/write splitting can effectively improve the throughput and usability of the system. Apache ShardingSphere's read/write splitting functionality provides an extensible SPI for the read database load balancing algorithm. This section will mainly discuss how to use the user-defined load balancing algorithm.
Implementation
The following code shows how to access the read database load balancing algorithm:
TypeScript
@Getter
@Setter
public final class TestReplicaLoadBalanceAlgorithm implements ReplicaLoadBalanceAlgorithm {private Properties props = new Properties();
@Override
public String getDataSource(final String name, final String writeDataSourceName, final List<String> readDataSourceNames) {return null;
}
@Override
public String getType() {return "TEST";
}
}
You can add the SPI configuration as follows (please refer to the Java standard SPI loading method):
Extensible algorithms
The user-defined load balancing algorithm can be extended through the following access:
org.apache.shardingsphere.readwritesplitting.spi.ReplicaLoadBalanceAlgorithm
In the next section, you will learn how to customize distributed transactions with your strategy.
Distributed transactions
Distributed transactions ensure that the transaction semantics of multiple storage databases are managed by ShardingSphere. Choosing ShardingSphere will feel just like using a traditional database, with common functions such as begin, commit, rollback, and set autocommit.
Implementation
You should start by configuring the server.yaml transaction configuration according to the following code example:
YAML
-- XA provides consistent semantics
rules:
- !TRANSACTION
defaultType: XA
providerType: Narayana
Once you have configured the server.yaml transaction configuration, you can configure the table's structure and its initial data:
SQL
create table account (
id int primary key,
balance int
);
insert into account values(1,0),(2,100);
If you're using Java code, please refer to this option for low-level MySQL. The configuration for PostgreSQL is the same except that jdbcurl needs to be modified:
public void test() {Connection connection = null;
try { connection = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3307/test", "root", "root");connection.setAutoCommit(false);
......
connection.commit();
} catch (Exception e) {connection.rollback();
} finally {......
}
}
If you're using a MySQL client, please refer to this option for low-level MySQL. The configuration for PostgreSQL is the same:
-- Start transaction and commit
mysql> BEGIN;
mysql> UPDATE account SET balance=1 WHERE id=1;
mysql> SELECT * FROM account;
mysql> UPDATE account SET balance=99 WHERE id=2;
mysql> SELECT * FROM account;
mysql> COMMIT;
mysql> SELECT * FROM account;
-- Start transaction and rollback
mysql> BEGIN;
mysql> SELECT * FROM account;
mysql> UPDATE account SET balance=0 WHERE id=1;
mysql> SELECT * FROM account;
mysql> UPDATE account SET balance=100 WHERE id=2;
mysql> ROLLBACK;
mysql> SELECT * FROM account;
Extensible algorithms
Distributed transactions provide integration with Narayana, Atomikos, and Base. If you are looking to customize TM, you can achieve expansion by providing the following access:
org.apache.shardingsphere.transaction.spi.ShardingSphereTransactionManager
Now, let's learn how to implement and configure functions and strategies.
User-defined functions and strategies – encryption, SQL authority, user authentication, shadow DB, distributed governance
In the following sections, you will learn how to configure data encryption, SQL parsing, SQL authority, user authentication, shadow DB, and distributed governance. We will follow the same format we used previously – that is, starting with the implementation, then looking at the extensible algorithms.
Data encryption
Data encryption is a way to ensure data security by data transformation. The Apache ShardingSphere data encryption feature provides significant extensibility, allowing you to extend the data encryption algorithm and query-assisted column data encryption algorithm based on the SPI mechanism.
Implementing your encryption algorithm
- You can implement the EncryptAlgorithm interface using the following code:
public final class NormalEncryptAlgorithmFixture implements EncryptAlgorithm<Object, String> {
@Override
public String encrypt(final Object plainValue) {
return "encrypt_" + plainValue;
}
@Override
public Object decrypt(final String cipherValue) {
return cipherValue.replaceAll("encrypt_", "");
}
- Add the SPI configuration (please refer to the Java standard SPI loading method):
org.apache.shardingsphere.encrypt.spi.EncryptAlgorithm
- You can implement the user-defined QueryAssistedEncryptAlgorithm interface for column data as per the following code:
public final class QueryAssistedEncryptAlgorithmFixture implementsQueryAssistedEncryptAlgorithm<Object, String> {
@Override
public String queryAssistedEncrypt(final Object plainValue) {
return "assisted_query_" + plainValue;
}
- Add the SPI configuration (please refer to the Java standard SPI loading method).
Since QueryAssistedEncryptAlgorithm inherited the EncryptAlgorithm access, the SPI file is named after it – that is, EncryptAlgorithm:
org.apache.shardingsphere.encrypt.spi.EncryptAlgorithm
Extensible algorithms
ShardingSphere provides you with user-defined extensible access to encryption and decryption algorithms:
org.apache.shardingsphere.encrypt.spi.EncryptAlgorithm
In the next section, you will learn how to customize the user authentication feature.
User authentication
As we mentioned in Chapter 4, Key Features and Use Cases – Focusing on Performance and Security, Apache ShardingSphere supports handshakes and authentication for various database connection protocols through its Authentication Engine.
Implementation
Generally, you won't need to be concerned with ShardingSphere's internal implementation. Similar to using MySQL and PostgreSQL, you only have to create a connection with ShardingSphere via a terminal or visualization client. Once done, you only have to enter or configure the proper username and password.
On the other hand, if you'd like to configure a new database authentication type or use a customized authentication method (such as a user-defined password verification algorithm), you should know how to extend Authentication Engine. The next section will show you how to do that.
Extensible algorithms
AuthenticationEngine is an adaptor. Its definition is as follows:
Java
public interface AuthenticationEngine {/**
* Handshake.
*/
int handshake(ChannelHandlerContext context);
/**
* Authenticate.
*/
AuthenticationResult authenticate(ChannelHandlerContext context, PacketPayload payload);
}
Judging from its definition, we can tell that the AuthenticationEngine access is very neat. It follows these two methods:
- A handshake is used to respond to a handshake demand from the client's end.
- authenticate is responsible for verifying the client's username and password.
At the time of writing, Apache ShardingSphere provides three ways of implementing AuthenticationEngine. The following list specifies the name and compatible database type:
- MySQLAuthenticationEngine: MySQL
- PostgreSQLAuthenticationEngine: PostgreSQL
- OpenGaussAuthenticationEngine: OpenGauss
If you need ShardingSphere to be compatible with a new type of database, such as Oracle, you can add another AuthenticationEngine access. If you're only hoping to adjust user password verification rules, you can customize authenticate access as per your needs.
In the future, as ShardingSphere supports more databases and verification methods, the implementation of AuthenticationEngine will be expanded, and its functions will be improved.
Remaining on the theme of database security, in the next section, you will learn how to customize the SQL authority feature.
SQL authority
When we refer to SQL authority, we mean that after receiving SQL commands entered by users, Apache ShardingSphere will check whether they have related authorities according to the operation types and data scopes of their commands, and permit or decline said operations.
For more concepts and background information about SQL authority, please refer to Chapter 4, Key Features and Use Cases – Focusing on Performance and Security.
Implementation
In ShardingSphere, you can choose different types of authority providers to achieve authority controls at different levels. The authority provider needs to be configured in server.yaml. The format is as follows:
YAML
rules:
- !AUTHORITY
users:
- root@%:root
- sharding@:sharding
provider:
type: ALL_PRIVILEGES_PERMITTED
Here, the input options are ALL_PRIVILEGES_PERMITTED and SCHEMA_PRIVILEGES_PERMITTED:
- ALL_PRIVILEGES_PERMITTED: Using this provider means that the user has access to all privileges. This means that in ShardingSphere, the user can perform all operations on all tables and databases. When no provider type is designated, this provider will be used by default.
- SCHEMA_PRIVILEGES_PERMITTED: This refers to controlling user authority at the schema level. For detailed usage, please refer to the introduction in Chapter 4, Key Features and Use Cases – Focusing on Performance and Security.
Extensible algorithms
From the previous section, we know that Apache ShardingSphere achieves authority controls at different levels by using different authority providers. All authority providers achieve SPI access via AuthorityProvideAlgorithm. Its definition is as follows:
Java
public interface AuthorityProvideAlgorithm extends ShardingSphereAlgorithm {/**
* Initialize authority.
*/
void init(Map<String, ShardingSphereMetaData> metaDataMap, Collection<ShardingSphereUser> users);
/**
* Refresh authority.
*/
void refresh(Map<String, ShardingSphereMetaData> metaDataMap, Collection<ShardingSphereUser> users);
/**
* Find Privileges.
*/
Optional<ShardingSpherePrivileges> findPrivileges(Grantee grantee);
}
Let's learn more about the terms used in the preceding code:
- init is used to initialize the provider – for instance, parsing the configuration of props into the necessary format.
- refresh is for refreshing information that will be used when you're dynamically updating the user and its authority.
- findPrivileges is for finding the privilege list of target users. It will return to a collection of ShardingSpherePrivileges.
How does ShardingSphere determine a user's privileges on a specific subject? It is determined by ShardingSpherePrivileges access. The ShardingSpherePrivileges access definition is as follows:
· Java
public interface ShardingSpherePrivileges {/**
* Set super privilege.
*/
void setSuperPrivilege();
/**
* Has privileges of schema.
*/
boolean hasPrivileges(String schema);
/**
* Has specified privileges.
*/
boolean hasPrivileges(Collection<PrivilegeType> privileges);
/**
* Has specified privileges of subject.
*/
boolean hasPrivileges(AccessSubject accessSubject, Collection<PrivilegeType> privileges);
}
ShardingSpherePrivileges access has four methods, as follows:
- The setSuperPrivilege method is used to set super privileges for users.
- The other three hasPrivilege methods are used to check whether a user has the privilege of a specific operation or object.
In this section, you learned that the access ShardingSphere provides for SQL authority is standard and neat. If you want a customized authority method, you can make one by extending the access of AuthorityProvideAlgorithm and ShardingSpherePrivileges.
In the next section, you will learn how to customize the shadow DB feature according to your preference.
Shadow DB
Apache ShardingSphere's shadow DB is quite extensible: based on the SPI mechanism being used, it supports the extending column shadow algorithm and the HINT shadow algorithm.
Implementation
Configuring the shadow DB feature will come very easily to you, thanks to ShardingSphere's user-friendliness. Follow these steps:
- Let's start by configuring a user-defined ColumnShadowAlgorithm:
Java
public class CustomizeColumnMatchShadowAlgorithm implements ColumnShadowAlgorithm<Comparable<?>> {
@Override
public void init() {
}
@Override
public boolean isShadow(final PreciseColumnShadowValue<Comparable<?>> preciseColumnShadowValue) {
// TODO Custom Shadow Algorithm Judgment
return true/false;
}
@Override
public String getType() {
return "CUSTOMIZE_COLUMN";
}
}
The default method is set up as isShadow:PreciseColumnShadowValue: PreciseColumnShadowValue:
Java
public final class PreciseColumnShadowValue<T extends Comparable<?>> implements ShadowValue {
private final String logicTableName;
private final ShadowOperationType shadowOperationType;
private final String columnName;
private final T value
- Next, let's configure the user-defined HintShadowAlgorithm:
Java
public final class CustomizeHintShadowAlgorithm implements HintShadowAlgorithm<String> {
@Override
public void init() {
}
@Override
public boolean isShadow(final Collection<String> relatedShadowTables, final PreciseHintShadowValue<String> preciseHintShadowValue) {
// TODO Custom Shadow Algorithm Judgment
return true/false;
}
@Override
public String getType() {
return "CUSTOMIZE_HINT";
}
}
Once you have included a custom strategy, as we did in Step 2, if you query the system, you will be able to see the difference in the Shadow strategy, as follows:
- relatedShadowTables: Shadow tables configured in configuration files
- preciseHintShadowValue: A precise HINT shadow value
Let's query the code to see this difference:
Java
public final class PreciseHintShadowValue<T extends Comparable<?>> implements ShadowValue {
private final String logicTableName;
private final ShadowOperationType shadowOperationType;
private final T value;
}
As we can see, the HINT shadow algorithm's value type is String.
- Add the SPI configuration (please refer to the standard loading method of the Java Service Provider Interface (SPI)):
org.apache.shardingsphere.shadow.spi.ShadowAlgorithm
Extensible algorithms
At the time of writing, Apache ShardingSphere provides the Shadow Algorithm SPI with three different implementations:
- ColumnValueMatchShadowAlgorithm: Shadow algorithm matching column value
- ColumnRegexMatchShadowAlgorithm: Shadow algorithm matching column regex
- SimpleHintShadowAlgorithm: Simple HINT shadow algorithm
Now that you have a reference, you can come back to this section when you're customizing your shadow DB feature. Now, let's learn how to customize the distributed governance feature.
Distributed governance
Apache ShardingSphere leverages the third-party Zookeeper and etcd components to implement distributed governance. It can flexibly integrate with other components to meet your needs for different stacks or in different scenarios. This section will show you how to integrate with other components to extend ShardingSphere's distributed governance capability.
Implementation
Distributed governance is available in ShardingSphere's cluster mode. You need to configure the cluster mode and define a distributed storage strategy in server.yaml to use the user-defined distributed governance function. The configuration method is shown here:
YAML
mode:
type: Cluster
repository:
type: CustomRepository # custom repository type
props: # custom properties
custom-time-out-: 30
custom-max-retries: 5
overwrite: false
To enable the aforementioned configuration in ShardingSphere, follow these steps:
- Implement the Distributed Persist Strategy SPI and define the implementation type as CustomRepository:
Java
org.apache.shardingsphere.mode.repository.cluster.ClusterPersistRepository
The following is a referential implementation class:
Java
public final class CustomPersistRepository implements ClusterPersistRepository{
@Override
public String get(final String key) {
return null;
}
@Override
public List<String> getChildrenKeys(final String key) {
return null;
}
@Override
public void persist(final String key, final String value) {
}
@Override
public void delete(final String key) {
}
@Override
public void close() {
}
@Override
public void init(final ClusterPersistRepositoryConfiguration config) {
}
@Override
public void persistEphemeral(final String key, final String value) {
}
@Override
public String getSequentialId(final String key, final String value) {
return null;
}
@Override
public void watch(final String key, final DataChangedEventListener listener) {
}
@Override
public boolean tryLock(final String key, final long time, final TimeUnit unit) {
return false;
}
@Override
public void releaseLock(final String key) {
}
@Override
public String getType() {
return "CustomRepository";
}
}
- Add the SPI configuration (please refer to the standard loading method of the Java Service Provider Interface).
- To parse the following user-defined configuration items (CIs), you need to implement the SPI for mapping CIs:
YAML
props: # custom properties
custom-time-out: 30
custom-max-retries: 5
The following code shows the CI mapping's SPI abstract class:
Java
org.apache.shardingsphere.infra.properties.TypedPropertyKey
The following code shows a referential implementation class:
Java
@RequiredArgsConstructor
@Getter
public enum CustomPropertyKey implements TypedPropertyKey {
CUSTOM_TIME_OUT("customTimeOut", String.valueOf(30), long.class),
CUSTOM_MAX_RETRIES("customMaxRetries", String.valueOf(3), int.class)
;
private final String key;
private final String defaultValue;
private final Class<?> type;
}
- Transforming the Inherit-config property of the SPI abstract class is used to get the user-defined configurations in YAML:
Java
org.apache.shardingsphere.infra.properties.TypedProperties
The following code shows a referential implementation class:
Scala
public final class CustomProperties extends TypedProperties<CustomPropertyKey> {
public CustomProperties(final Properties props) {
super(CustomPropertyKey.class, props);
}
}
Among the user-defined distributed storage strategy implementation classes, you can use the init method to get the user-defined configurations and initialize them:
Java
@Override
public void init(final ClusterPersistRepositoryConfiguration config) {
CustomProperties properties = new CustomProperties(config.getProps());
long customTimeOut = properties.getValue(CustomPropertyKey.CUSTOM_TIME_OUT);
long customMaxRetries = properties.getValue(CustomPropertyKey.CUSTOM_MAX_RETRIES);
}
Extensible algorithms
The following code shows the user-defined configuration item mapping interface:
Java
org.apache.shardingsphere.infra.properties.TypedPropertyKey
The following code shows the user-defined configuration item parsing interface:
Java
org.apache.shardingsphere.infra.properties.TypedProperties
The following code shows the user-defined distributed persist strategy interface:
Java
In the next section, you will learn how to customize the scaling feature.
Scaling
As per the design concept of Apache ShardingSphere, scaling also provides rich extensibility, allowing you to configure most of its parts. If there is an existing implementation that fails to meet your requirements, you can leverage SPI to make extensions by yourself, such as the data consistency checker.
Implementing the data consistency checker algorithm
The main SPI algorithm that we use is DataConsistencyCheckAlgorithm.
Generally, most methods provide algorithm metadata information. When you leverage DistSQL to manually trigger the data consistency checker, you can specify the algorithm's type (concurrently, there is a DistSQL statement that lists all algorithms).
The core getSingleTableDataCalculator method is based on the algorithm's type and database's type and obtains the right single table data of SingleTableDataCalculator to calculate the SPI implementation:
Java
public interface DataConsistencyCheckAlgorithm extends ShardingSphereAlgorithm, ShardingSphereAlgorithmPostProcessor, SingletonSPI {/**
* Get algorithm description.
*
* @return algorithm description
*/
String getDescription();
/**
* Get supported database types.
*
* @return supported database types
*/
Collection<String> getSupportedDatabaseTypes();
/**
* Get algorithm provider.
*
* @return algorithm provider
*/
String getProvider();
/**
* Get single table data calculator.
*
* @param supportedDatabaseType supported database type
* @return single table data calculator
SingleTableDataCalculator getSingleTableDataCalculator(String supportedDatabaseType);
}
The next sub-algorithm SPI we will look at is SingleTableDataCalculator.
The SingleTableDataCalculator algorithm provides single table data calculation capabilities for the main DataConsistencyCheckAlgorithm algorithm SPI. check and checksum are usually used for calculation.
Based on different algorithm types and database types, the implementation of this interface supports heterogeneous database migration, and can perform calculations on the source and target ends separately:
Java
public interface SingleTableDataCalculator {/**
* Get algorithm type.
*
* @return algorithm type
*/
String getAlgorithmType();
/**
* Get database type.
*
* @return database type
*/
String getDatabaseType();
/**
* Calculate table data, usually checksum.
*
* @param dataSourceConfig data source configuration
* @param logicTableName logic table name
* @param columnNames column names
* @return calculated result, it will be used to check equality.
*/
Object dataCalculate(ScalingDataSourceConfiguration dataSourceConfig, String logicTableName, Collection<String> columnNames);
}
Extensible algorithms
Now, let's look at the extensible algorithms. The following list provides you with a useful and quick description of what the algorithm does:
- For the ScalingDataConsistencyCheckAlgorithm algorithm, we have the ScalingDefaultDataConsistencyCheckAlgorithm implementation class, a consistency check algorithm based on CRC32 matching.
- For the SingleTableDataCalculator algorithm, we have the DefaultMySQLSingleTableDataCalculator implementation class, a single table data calculation algorithm based on CRC32 matching (only applicable for MySQL).
Now that we've looked at feature customization, let's learn how to fine-tune ShardingSphere-Proxy's properties.
ShardingSphere-Proxy – tuning properties and user scenarios
In this section, we will look at the property parameters of ShardingSphere-Proxy. In the props section of the server.yaml configuration file, some parameters are related to functions, while some parameters are related to performance.
Adjusting performance-oriented parameters in specific scenarios can improve the performance of ShardingSphere-Proxy as much as possible when environment resources are limited. Next, we will describe the parameters of props.
Properties introduction
Let's review the performance-oriented parameters of ShardingSphere-Proxy. In this section, you will find each of these performance-oriented parameters, along with a brief description of what they do.
max-connections-size-per-query
The default value of the max-connections-size-per-query parameter is 1.
When using ShardingSphere to execute a line of SQL, this parameter mainly controls the maximum connections that are allowed to be fetched from each data source. In the data sharding scenario, when a line of logic SQL is routed to multiple shards, increasing the parameter can raise the concurrency of actual SQL and reduce the time consumption of the query.
kernel-executor-size
The default value of the kernel-executor-size parameter is 0.
This parameter mainly controls the internal part of ShardingSphere and the size of thread pools that are used to execute SQLs. The default value is 0. Using java.util.concurrent.Executors#newCachedThreadPool means that there's no limit for threads. This parameter is mainly used in data sharding.
Normally, without special adjustment, the thread pool will create or delete threads according to your needs. You can set a fixed value to reduce the consumption of thread creation or limit resource consumption.
sql-show
The default value of the sql-show parameter is false.
When this parameter is on, SQL (actual SQL) that's been processed by the original SQL (logic SQL) and the kernel will be output to a log. Since log output has a significant influence on performance, it is advised to only enable this when necessary.
sql-simple
The default value of the sql-simple parameter is false.
It only works when sql-show is set to true. If the parameter is set to true, the log will not output detailed parameters regarding the placeholders in Prepared Statement.
show-process-list-enabled
The default value of the show-process-list-enabled parameter is false.
This parameter controls whether the showprocesslist function is enabled. It only works in Cluster mode. This function is similar to MySQL's showprocesslist. At the time of writing, it only works for DDL and DML statements.
check-table-metadata-enabled
The default value of the check-table-metadata-enabled parameter is false.
It allows a sharding table metadata information check to be performed. If the parameter is true, the metadata of all the tables will be loaded when the sharding table metadata is loaded, and their consistency will be checked.
check-duplicate-table-enabled
The default value of the check-duplicate-table-enabled parameter is false.
It checks duplicate tables. If the parameter is true, when initializing a single table, the existence of duplicate tables will be checked. If there is a duplicate table, the output will be abnormal.
sql-federation-enabled
The default value of the sql-federation-enabled parameter is false.
It enables the SQL Federation execution engine. If the parameter is true, SQL Federation can be used to execute an engine that supports inter-database distributed queries. At the time of writing, when the table data amount is large, using the Federation execution engine may cause ShardingSphere-Proxy to consume more CPU and memory.
proxy-opentracing-enabled
The default value of the proxy-opentracing-enabled parameter is false. This parameter enables or disables OpenTracing-related functions.
proxy-hint-enabled
The default value of the proxy-hint-enabled parameter is false.
This parameter controls whether the hint function of ShardingSphere-Proxy should be enabled. When the hint function is enabled, requests that have been sent to ShardingSphere-Proxy MySQL will be processed by the exclusive thread of each client end, which may compromise ShardingSphere-Proxy's performance.
proxy-frontend-flush-threshold
The default value of the proxy-frontend-flush-threshold parameter is 128.
This parameter mainly controls the frequency of the flush operation in the buffer zone when ShardingSphere-Proxy sends query results to the client's end. For instance, if there are 1,000 lines of query results and the flush threshold is set to 100, ShardingSphere-Proxy will perform one flush operation every 100 lines of data it sends to the client end.
Properly reducing the parameter may make it faster for the client end to receive response data and a lower SQL response time. However, frequent flush operations may increase the network load.
proxy-backend-query-fetch-size
The default value of the proxy-backend-query-fetch-size parameter is -1.
It only works when ConnectionMode is Memory Strictly. When ShardingSphere-Proxy uses JDBC to execute select statements in databases, this parameter can control the minimum lines of data that ShardingSphere-Proxy fetches. It is similar to cursor. The default value of this parameter is -1, which means minimizing the fetch size.
Setting a relatively small fetch size may reduce the memory occupation of ShardingSphere-Proxy. However, it may increase the interactions between ShardingSphere-Proxy and the database, resulting in a longer SQL response and vice versa.
proxy-frontend-executor-size
The default value of the proxy-frontend-executor-size parameter is 0.
ShardingSphere-Proxy uses Netty to implement database protocols and communication with the client end. This parameter mainly controls the thread size of EventLoopGroup, which is used by ShardingSphere-Proxy. Its default value is 0, which means that Netty determines the thread size of EventLoopGroup. Normally, it is twice the size of the available CPU.
proxy-backend-executor-suitable
The available options for the proxy-backend-executor-suitable parameter are OLAP (default) and OLTP.
When the number of client ends that connect with ShardingSphere-Proxy is rather small (less than proxy-frontend-executor-size) and the client ends are not required to execute time-consuming SQL, using OLTP may reduce SQL execution time consumption at the ShardingSphere-Proxy layer. If you are unsure whether using OLTP can improve performance, you're advised to use the default value – that is, OLAP.
This configuration influences ShardingSphere-Proxy when it's used to execute SQL's thread pool choice. When using OLAP, ShardingSphere-Proxy will use an independent thread pool to run logic, such as SQL routing, rewriting, interacting with databases, and certain thread switches that may exist.
If OLTP is being used, ShardingSphere-Proxy will directly use Netty's EventLoop thread, and the logic that's been requested to be processed on one client end, such as SQL routing, rewriting, and interaction with databases, will be executed in one thread. Compared to OLAP, this may reduce SQL time consumption at the ShardingSphere-Proxy layer.
OLTP can also be used since the inherently synchronous JDBC is used when ShardingSphere-Proxy interacts with a database. If Netty's EventLoop were accidentally obstructed due to slow SQL execution or lengthened interaction between ShardingSphere-Proxy and the database for other reasons, the response of other client ends connected to ShardingSphere-Proxy would be extended.
proxy-frontend-max-connections
The default value of the proxy-frontend-max-connections parameter is 0.
This configuration controls the minimum TCP connections that client ends are allowed to create with ShardingSphere-Proxy. It is similar to MySQL's max_connections configuration. The default value is 0. A value less than or equal to 0 means no limit on connections.
Extensible algorithms
We will start this section by covering some testing scenarios. Here, we will showcase how to adjust ShardingSphere-Proxy's attribute parameters in specific scenarios to maximize ShardingSphere-Proxy's resource usage and improve its performance in case of limited resources.
Case 1 – Using ShardingSphere-Proxy's PostgreSQL to test performance with a sharding rule in BenchmarkSQL 5.0
In this section, we will use ShardingSphere-Proxy's PostgreSQL to perform a TPC-C benchmark test while implementing the data sharding scenario. Here, you will learn how to adjust the parameters of ShardingSphere-Proxy and the client to greatly improve test results.
Requirement: In the data sharding scenario, each logic SQL needs to match its unique actual SQL.
In the BenchmarkSQL 5.0 PostgreSQL JDBC URL configuration file, you need to configure the following two parameters:
- The following is the first parameter we will look into:
defaultRowFetchSize=100
The suggested value is 100 but you should still adjust it based on the actual test situation. BenchmarkSQL only fetches one row of data from ResultSet in most queries, and sometimes fetches multiple rows in a few queries.
By default, PostgreSQL JDBC may fetch 1,000 rows of data from proxy every time, but the actual test logic only requires a small amount of data. It's necessary to adjust the defaultRowFetchSize value of PostgreSQL JDBC to reduce its interactions with ShardingSphere-Proxy as much as possible on the premise that the BenchmarkSQL logic is still satisfied.
- The following is the second parameter that we will look into:
reWriteBatchedInserts=true
By rewriting the Insert statement to combine multiple sets of parameters into the values of the same Insert statement, this option can reduce interactions between BenchmarkSQL and ShardingSphere-Proxy when you're initializing data and the New Order business. Then, it can reduce network transmission time that, in most cases, takes a relatively high proportion of total SQL execution time.
The following code can be used as a reference for configuring BenchmarkSQL 5.0:
Makefile
db=postgres
driver=org.postgresql.Driver
conn=jdbc:postgresql://localhost:5432/postgres?defaultRow FetchSize=100&reWriteBatchedInserts=true
Configuring server.yaml is recommended. In terms of other parameters, you can use the default values or adjust them:
YAML
props:
proxy-backend-query-fetch-size: 1000
# According to the actual stress test results, concurrently enable or remove the following two parameters
proxy-backend-executor-suitable: OLTP # Disable it during data initialization and enable it during stress tests
proxy-frontend-executor-size: 200 # Keep consistent with Terminals
- Next, we have the proxy-backend-query-fetch-size parameter.
The following is a SQL statement that queries the Delivery property of BenchmarkSQL:
SQL
SELECT no_o_id
FROM bmsql_new_order
WHERE no_w_id = ? AND no_d_id = ?
ORDER BY no_o_id ASC
In terms of the query, its results may exceed 1,000 rows. BenchmarkSQL gets query results with a fetch size of 1000 from ShardingSphere-Proxy. ShardingSphere-Proxy's ConnectionMode is Memory Strictly and proxy-backend-query-fetch-size is set as the default value (this amounts to a fetch size of 1). This means that every time BenchmarkSQL executes one SQL query, ShardingSphere-Proxy needs to fetch more than 1,000 times from the database, which results in a long SQL execution time and lower performance test results.
- Now, let's look at the proxy-backend-executor-suitable and proxy-frontend-executor-size parameters.
In the BenchmarkSQL 5.0 testing scenarios, there is no long-time SQL execution, so users can try to enable the OLTP option of proxy-backend-executor-suitable to reduce the cross-thread overhead of frontend and backend logic.
You should use the OLTP option and the proxy-frontend-executor-size option together. It is suggested to set the parameter value to Terminals.
Case 2 – ShardingSphere kernel parameter tuning scenario
ShardingSphere's kernel-related adjustable parameters include check-table-metadata-enabled, kernel-executor-size, and max-connections-size-per-query. Let's look at their usage scenarios and provide some useful tips:
- The check-table-metadata-enabled parameter is used to enable/disable sharding table metadata information verification. If its value is true, when you load the metadata of the sharding table, the metadata of all the tables is loaded, and a metadata consistency check is performed. The metadata checker needs different amounts of time to complete consistency verification and its duration is dependent on the number of actual tables. If the user can ensure that the structure of all actual tables is consistent, then they can set this parameter to false to speed up ShardingSphere's bootup time.
- The kernel-executor-size parameter is used to control the internal part of ShardingSphere and the size of the thread pools that are used to execute SQLs. To set the parameter, users need to consider the amount of SQL to be executed in the data sharding scenario and choose a fixed value that covers multiple scenarios. This will reduce the overhead of thread creation and restrict resource usage.
- The max-connections-size-per-query parameter manages the maximum number of connections that are allowed for each data source when ShardingSphere is used to execute a SQL statement. Taking the following t_order table configuration as an example, let's look at the functionality of max-connections-size-per-query:
YAML
rules:
- !SHARDING
tables:
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1}
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database_inline
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_inline
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: ds_${user_id % 2}
t_order_inline:
type: INLINE
props:
algorithm-expression: t_order_${order_id % 2}
In the sharding configuration file, t_order is divided into four shards, namely ds_0.t_order_0, ds_0.t_order_1, ds_1.t_order_0, and ds_1.t_order_1. We can use the PREVIEW statement to view the routing results (shown in the following code block) of SELECT * FROM t_order ORDER BY order_id:
SQL
PREVIEW SELECT * FROM t_order ORDER BY order_id;
+------------------+-------------------------------------------+
| data_source_name | sql |
+------------------+-------------------------------------------+
| ds_0 | SELECT * FROM t_order_0 ORDER BY order_id |
| ds_0 | SELECT * FROM t_order_1 ORDER BY order_id |
| ds_1 | SELECT * FROM t_order_0 ORDER BY order_id |
| ds_1 | SELECT * FROM t_order_1 ORDER BY order_id |
+------------------+-------------------------------------------+
The original query statement has been rewritten into the actual executable query statement, which is routed to the ds_0 and ds_1 data sources for execution. According to the grouping of the data sources, the execution statements are divided into two groups. So, in terms of the execution statements for the same data source, how many connections do we need to open to execute a query? The max-connections-size-per-query parameter is used to control the maximum number of connections that are allowed on the same data source.
When the configured value of max-connections-size-per-query is greater than or equal to the number of all SQLs that need to be executed under the data source, ShardingSphere enables its Limited Memory mode. This mode allows you to stream SQL queries to limit memory usage. However, when this parameter value is less than the number of all SQLs that need to be executed under the data source, ShardingSphere enables its Limited Connection mode and creates a unique connection for execution. Due to this, the query result set is loaded into memory to avoid consuming too many database connections. The following diagram provides an overview in the form of an equation for this reasoning:
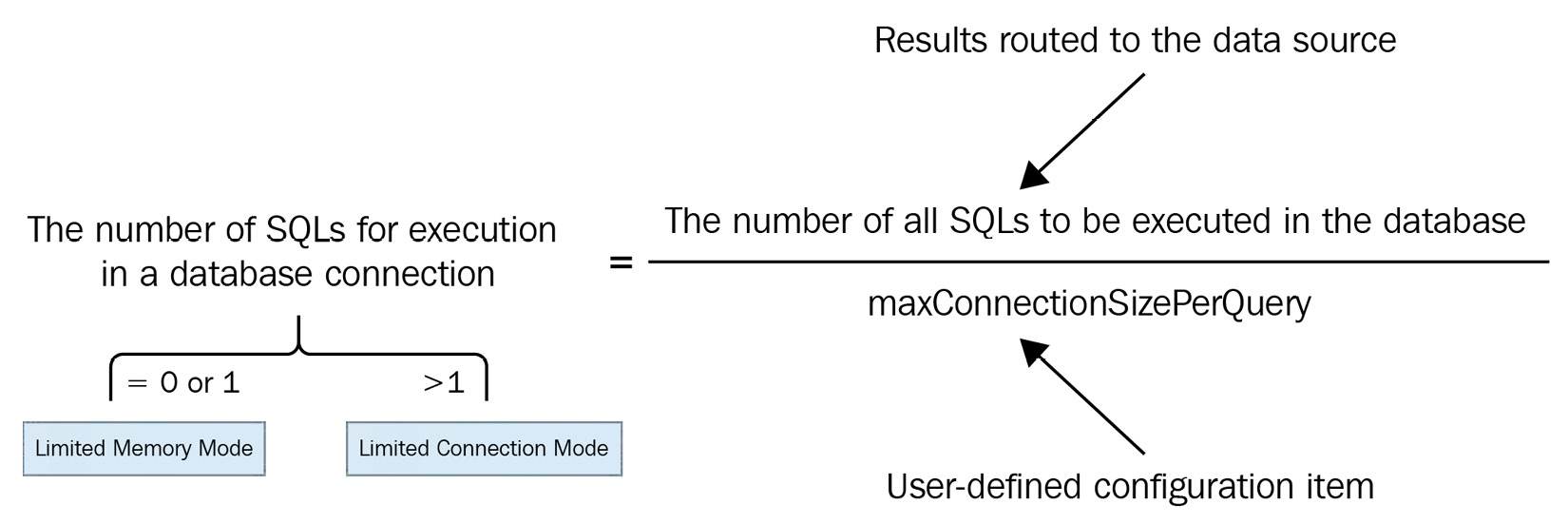
Figure 8.2 – SQL tuning
In most Online Transactional Processing (OLTP) scenarios, shard keys are used to ensure routing to the data node, so the value of max-connections-size-per-query is set to 1 to strictly control database connections and ensure that database resources can be used by more applications. However, in terms of Online Analytical Processing (OLAP) scenarios, users can configure a relatively high value of the max-connections-size-per-query parameter to improve system throughput.
Summary
After reading this chapter, you should be able to not only customize strategies for ShardingSphere's most notable features but also tune the proxy's performance. Feel free to apply the knowledge you have gathered so far, coupled with the examples offered in this chapter, to customize ShardingSphere. The examples we have provided you with are generalizable, which means that you can come back to them at any time.
If you'd like to test yourself even further, once you have completed the remaining chapters of this book, you can join the ShardingSphere developer community on GitHub, where you'll find new strategies constantly being shared by other users like you.
Plugin platform introduction and SPI
Plugin platform introduction and SPI
User-defined functions and strategies – SQL parser, sharding, read/write splitting, distributed transactions
User-defined functions and strategies – SQL parser, sharding, read/write splitting, distributed transactions
User-defined functions and strategies – SQL parser, sharding, read/write splitting, distributed transactions
User-defined functions and strategies – SQL parser, sharding, read/write splitting, distributed transactions
User-defined functions and strategies – encryption, SQL authority, user authentication, shadow DB, distributed governance
User-defined functions and strategies – encryption, SQL authority, user authentication, shadow DB, distributed governance
User-defined functions and strategies – encryption, SQL authority, user authentication, shadow DB, distributed governance
User-defined functions and strategies – encryption, SQL authority, user authentication, shadow DB, distributed governance
User-defined functions and strategies – encryption, SQL authority, user authentication, shadow DB, distributed governance
User-defined functions and strategies – encryption, SQL authority, user authentication, shadow DB, distributed governance
User-defined functions and strategies – encryption, SQL authority, user authentication, shadow DB, distributed governance
User-defined functions and strategies – encryption, SQL authority, user authentication, shadow DB, distributed governance