
1. Introducing SCA
Service Component Architecture, or SCA, is a technology for creating services and assembling them into composite applications. SCA addresses the perennial question of how to build systems from a series of interconnected parts. In SCA, these parts interact by providing services that perform a specific function. Services may be implemented using different technologies and programming languages. For example, a service can be implemented in Java, C++, or in a specialized language such as Business Process Execution Language (BPEL). Services may also be collocated in the same operating system process or distributed across multiple processes running on different machines. SCA provides a framework for building these services, describing how they communicate and tying them together.
We once heard a witty definition of a technology framework that is appropriate to bring up in this context: A technology framework is something everyone wants to write but no one wants to use. Indeed, the industry is replete with frameworks and programming models promising to solve problems posed by application development in new and innovative ways. In the 1990s, the Distributed Computing Environment (DCE) was superceded by Common Object Request Broker Architecture (CORBA) and Distributed Component Object Model (DCOM). Java Enterprise Edition (Java EE) and .NET emerged as the two dominant frameworks in the early 2000s, supplanting the latter two. Open source has also been a center of innovation, with Spring and Ruby on Rails emerging as two of the more popular frameworks.
This raises the question of why SCA? What problems with existing programming models is SCA trying to solve? The sheer scope of SCA as a technology and the fact that it is supported by a diverse set of vendors invariably has led to a degree of confusion in this respect. SCA can be initially daunting to understand.
SCA addresses two key issues with existing approaches: complexity and reuse. First, SCA provides a simplified programming model for building distributed systems. The dominant programming models today have grown increasingly complex. For example, writing a Java EE application that exposes web services, performs some processing, and interfaces with a messaging system to integrate with other applications requires knowledge of the JAX-WS, JMS, and EJB APIs. This complexity has not been limited to Java EE: The .NET framework has been subject to the same trend. Writing an identical application using .NET 2.0 requires an understanding of the ASP .NET Web Services, Enterprise Services, and .NET Messaging APIs.
In contrast, as illustrated in Figure 1.1, SCA provides a unified way to build applications that communicate using a variety of protocols.
Figure 1.1 SCA provides a unified way to build distributed applications.

Perspective: SCA and .NET
In recent years, increasing complexity has not been limited to Java EE: The .NET framework has been subject to the same trend. Writing an identical application using .NET 2.0 requires an understanding of ASP .NET Web Services, Enterprise Services, and .NET Messaging APIs.
Microsoft has spent significant time addressing complexity in the .NET Framework. Starting with version 3.0, .NET incorporates a programming model that unifies web services, remote procedure calling, queued messaging, and transactions. SCA introduces a uniform way to perform distributed interactions. In SCA and Windows Communication Foundation (WCF), application logic is invoked the same way whether web services, a binary, or a messaging protocol is used (see Figure 1.2).
Figure 1.2 SCA and .NET architectures

Adapted from David Chappell, www.davidchappell.com.
This unified approach simplifies development by eliminating the need for application logic to resort to specialized, low-level APIs.
The second problem SCA addresses concerns reuse. There are two basic types of code reuse: within the same process (intra-process reuse) and across processes (inter-process reuse). Object-oriented programming languages introduced innovative features, including interfaces, classes, polymorphism, and inheritance that enabled applications to be decomposed into smaller units within the same process. By structuring applications in terms of classes, object-oriented code could be more easily accessed, reused, and managed than code written with procedural programming languages.
In the 1990s, distributed object technologies such as DCE, DCOM, CORBA, and EJB attempted to apply these same principles of reuse to applications spread across multiple processes. After numerous iterations, the industry learned from distributed object technologies that the principles of object-oriented design do not cleanly apply across remote boundaries. Distributed object technologies often resulted in application architectures that tightly coupled clients to service providers. This coupling made systems extremely fragile. Updating applications with a new version of a service provider frequently resulted in client incompatibilities. Moreover, these technologies failed to adequately address key differences in remote communications such as network latency, often leading to poor system performance.
However, despite the shortcomings of distributed objects, the idea behind inter-process reuse is still valid: There is far greater value in code that is organized into reusable units and accessible to multiple clients running in different processes. As we will explain in more detail, SCA provides a foundation for application resources and logic to be shared by multiple clients that builds on the lessons learned from distributed objects. Similar to the way object-oriented languages provide mechanisms for organizing and reusing in-process application logic, SCA provides a way to assemble, manage, and control distributed systems.
In order to achieve reuse, SCA defines services, components, and composites. In SCA, applications are organized into components that offer functionality to clients (typically other components) through services. Services may be reused by multiple clients. Components in turn may rely on other services. As we will see, SCA provides a mechanism to connect or “wire” components to these services. This is done through a composite, which is an XML file. Figure 1.3 shows a typical SCA application.

SCA and Enterprise Architectures
Unlike Java EE and .NET, SCA is not intended to be an all-encompassing technology platform. SCA does not specify mechanisms to persist data or a presentation-tier technology for building user interfaces. Rather, SCA integrates with other enterprise technologies such as JDBC and Java Persistence Architecture (JPA) for storing data in a database and the myriad of web-based UI frameworks that exist today (servlets and JSP, Struts, JavaServer Faces [JSFs], and Spring WebFlow, to name a few). Figure 1.4 illustrates a typical SCA architecture, which includes the use of presentation and persistence technologies.
Figure 1.4 Using persistence and presentation technologies with SCA

In Chapter 10, “Service-Based Development Using BPEL,” and Chapter 11, “Persistence,” we take a closer look at using SCA with some of the more popular persistence and presentation technologies.
The remainder of this chapter provides an overview of SCA, covering its key concepts. However, rather than stopping at the customary technical introduction, we attempt to shed light on the things not easily gleaned from reading the SCA specifications themselves. In particular, we consider how SCA relates to other technologies, including web services and Java EE. We also highlight the design principles and assumptions behind SCA, with particular attention to how they affect enterprise architecture.
As with any technology, SCA has benefits and trade-offs. It is an appropriate technology in many scenarios but it certainly is not in all cases. Our intention in this chapter, and ultimately with this book, is to equip readers with the understanding necessary to make intelligent choices about when and how to use SCA.
The Essentials
SCA is built on four key concepts: services, components, composites, and the domain. Understanding the role each plays is fundamental to understanding SCA. In this section, we provide an overview of these concepts before proceeding to a more detailed look at how applications are built using SCA.
Services
In SCA, applications are organized into a set of services that perform particular tasks such as accepting a loan application, performing a credit check, or executing an inventory lookup. The term service has been used in the industry to denote a variety of things. In SCA, a service has two primary attributes: a contract and an address.
Service Contract
A service contract specifies the set of operations available to a client, the requirements for the inputs, and the guarantees for the outputs. Service contracts can be defined through several mechanisms. In simple cases where a component is implemented using a Java class, an interface may define the service contract. Listing 1.1 is an example of a service contract with two operations defined by a Java interface. The only thing specific to SCA is the @Remotable annotation, which indicates that the service can be made available to remote clients (more on this later).
Listing 1.1 A Java-Based Service Contract

In more complex cases, service contracts may be declared upfront before code is written using a specialized interface description language, such as WSDL or IDL. This “top-down” or “contract-first” development provides a way for organizations to maintain tighter control over the interfaces services provide to clients.
The most common language for top-down development in SCA is the XML-based Web Services Description Language (WSDL). As its name indicates, WSDL is most commonly used to define web service contracts. SCA also makes use of WSDL to specify service contracts. Listing 1.2 presents the WSDL equivalent of the Calculator service contract.
Listing 1.2 A WSDL-Based Service Contract


In top-down development, after the service contract is defined, tooling is typically used to generate actual code artifacts. For example, tooling will use the Calculator WSDL as input to generate the previous Java interface shown in Listing 1.1.
Service Address
Having seen that service contracts may be defined using Java interfaces, it may be tempting to think of services as simply analogous to interfaces in object-oriented programming. This is true to the extent that services define the set of operations available to a client for a particular component. However, services also have addresses, which distinguishes them from interfaces. Clients obtain a reference to a particular service through a service address. Service addresses operate much like network addresses, uniquely identifying a particular machine on a network. Later in the chapter, we cover the mechanics of specifying service addresses and how applications use them. The important concept to bear in mind is that service addresses are fundamental to reuse: They provide a way for clients to uniquely identify and connect to application logic, whether it is co-located in the same process or hosted on a machine at some remote location.
Components
In SCA, a component is configured code that provides one or more services. A client connects to a service via an address and invokes operations on it. This concept is illustrated in Figure 1.5.
Figure 1.5 Components have one or more services.

Components may be written in a variety of programming languages, including Java and C++, and special purpose languages such as the BPEL.
Creating a component involves two things: writing an implementation and configuring it. Components written in Java are simple classes. In other words, they do not have any special requirements placed on them. Listing 1.3 demonstrates a simple calculator component.
Listing 1.3 A Java Component Implementation

When the preceding calculator component is deployed, it provides a single service defined by the Calculator interface. Clients connect to the Calculator service and invoke one or more of its operations.
Composites
The second step in creating a component is to configure it. Components are configured using an XML configuration file called a composite. This file can be created by hand or using graphical tooling. The XML vocabulary used to create composites is Service Component Definition Language (SCDL, pronounced “SKID-EL”). Listing 1.3 shows a composite that configures the calculator component using the implementation listed in Listing 1.4.

In Listing 1.4, the <component> element is used to define the calculator component. The <implementation.java> element identifies the component as being written in Java and the implementation class. The other important item to note is that both components and composites are assigned names, which are used to identify them. This makes it possible to have multiple components use the same component implementation—in this case, CalculatorComponent.
All but the most trivial applications will be composed of multiple components. A composite may be used to configure more than one component. Typically, it will make sense to configure related components together in a single composite (therefore the name composite, because it is used to “compose” components). Listing 1.5 lists a composite that configures two components: one that processes loan applications and another that performs credit scoring.
Listing 1.5 A Composite That Configures Multiple Components

As we will do frequently throughout the book, the preceding composite can be represented visually, as shown in Figure 1.6.
Figure 1.6 A graphical representation of a composite

In the previous example, both LoanComponent and CreditComponent were implemented in Java. It is also possible to configure components written in different languages in the same composite. For example, if the loan application process required workflow, it may be more convenient to implement LoanComponent using BPEL. In this case, the basic structure of the composite remains the same, as shown in Listing 1.6.
Listing 1.6 A Composite with Components Implemented in BPEL and Java

In changing to BPEL, the only difference is the use of the <implementation.bpel> element in place of <implementation.java> and pointing to the BPEL process as opposed to the Java class name.
The Domain
Composites are deployed into an environment running SCA middleware termed a domain. A domain consists of one or more cooperating SCA servers, or SCA runtimes, that host components in containers. The relationship between a domain, its runtimes, and component containers is shown in Figure 1.7.
Figure 1.7 SCA middleware: the domain, runtimes, and containers
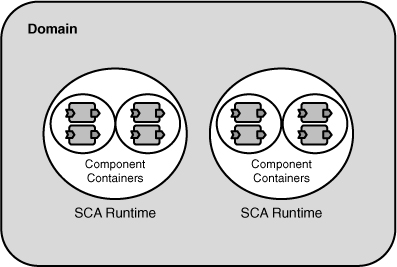
Figure 1.7 depicts a domain with multiple runtimes. In an enterprise environment, domains may span many runtimes across distributed data centers. But it is also possible for domains to be small. A domain may consist of a single SCA runtime (sometimes referred to as a “server”) or may even be confined to an embedded device.
When a composite is deployed to a domain with more than one runtime, its components may be hosted on different runtimes. For example, when the previous loan application composite is deployed, LoanComponent and CreditComponent may be hosted in processes on different runtimes (see Figure 1.8).
Figure 1.8 A deployed composite

The process of deploying a composite to one runtime or many is vendor-specific. Some SCA runtimes may require additional configuration information identifying target machines. Other runtimes may employ sophisticated provisioning algorithms that take into account factors such as machine load.
Although the capabilities offered by a domain will vary greatly by SCA vendor (or open source implementation), all domains have several common characteristics. Namely, domains provide management capabilities, policy framework, resource-sharing facilities, and communications infrastructure.
Management
Domains provide common management facilities for composites deployed to them. A domain, for example, is responsible for activating and deactivating components on runtimes as composites are deployed and removed. More sophisticated domain infrastructure may provide additional management features, such as access control, monitoring, and troubleshooting.
Policy
In enterprise systems, basic management needs are often augmented by the requirement to enforce various constraints on how code is executed. In SCA, constraints on the way code is executed may take a variety forms, such as security (“use encryption for remote invocations”), reliability (“provide guaranteed delivery of messages to a particular service”), or transactionality (“invoke this service in a transaction”). SCA domains contain rules that map these abstract constraints to concrete runtime behaviors.
These rules are termed policy. Traditional distributed system technologies typically leave the task of configuring policy to individual components or the application. In Java EE, for example, there is no standard way to specify constraints or expectations across systems, such as the type of security that must be enforced on services exposed outside a corporate firewall. Web services define a way to specify policy to external clients but require that each service be configured individually.
In contrast, a domain provides facilities for the global configuration of policies, which can then be applied to individual components, particular connections between components, or composites. In addition to fostering consistency across applications, global policy configuration simplifies component development. Policies are generally defined using complex specification languages such as WS-SecurityPolicy and WS-Reliability. Global policy configuration means this complex configuration can be done once by specialists—policy administrators—and reused across applications.
Resource and Artifact Sharing
Without a mechanism for sharing resources and artifacts, any reasonably sized distributed system would be unmanageable. A common type of shared resource in distributed systems is a service contract. As we saw earlier, service contracts can be defined using WSDLs or derived from language-specific means such as Java interfaces. In the case where one component is a client of another (the “service provider”) and they are deployed to runtimes on different machines, the service contract of the provider will typically need to be accessible to the client. In practice, if both components are implemented as Java classes, and the service contract is defined using a Java interface, the interface must be available to the client process. Components may share additional artifacts, such as schemas (XSDs) that define the structure of messages that are received as inputs to an operation on a service contract. Components may also rely on shared code, such as libraries. The domain serves as a repository for these artifacts, which, as we will see in more detail, are made accessible to components that require them.
Common Communication Infrastructure
Domains provide the communication infrastructure necessary for connecting components and performing remote service invocations. When a composite is deployed, the domain is responsible for provisioning its components to one or more runtimes and establishing communication channels between them (see Figure 1.9).
Figure 1.9 The domain communication infrastructure

To support distribution, a domain includes a proprietary communication layer. This communication layer varies by vendor but may be based on web services protocols, a binary protocol, or some other protocol altogether. In this respect, a domain is akin to message-oriented middleware (MOM) systems. Although MOM systems may adopt a standard API such as JMS, their underlying communication protocol remains proprietary.
One advantage that SCA’s communications infrastructure has over standardized protocols is that it is in control of both the client and service provider. As a result, users can be general in the way they specify requirements for a wire. This helps reduce complexity, as application code is not required to use low-level APIs.
For example, a user can specify that the wire should deliver messages reliably by marking the end of the wire as requiring reliability. As we will show in later chapters, this can be done via a Java annotation or in XML configuration. It is incumbent on the infrastructure to figure out how to do this. It could use a JMS queue or it could use web services with WS-ReliableMessaging. If the message sender and receiver are on the same machine and the receiver is ready to receive the message, the message can be delivered to the receiver in an optimized fashion.
Extensibility
SCA does not standardize a way to connect runtimes in a domain. Consequently, like messaging systems, domains are largely single-vendor. However, most SCA implementations define a proprietary extensibility mechanism that enables third-party runtimes to participate in a domain.
Is the single-vendor nature of a domain a bad thing? Perhaps, as it creates a “closed” middleware environment. The single-vendor nature of domains does, however, also have practical benefits. Having control over all endpoints in a system allows for communication optimizations. Also, if SCA had standardized a domain extension mechanism, its capabilities would likely have been significantly reduced due to the difficulty in achieving consensus among the different vendors.
The Extent of a Domain
Having covered the key characteristics of a domain and its role in SCA, we return to the question of what determines its scope. The number, shape, and size of domains may vary in an organization. An organization could choose to have one domain or many. Two key factors will inform this choice: how information technology (IT) assets are organized and managed, and which SCA implementation is used.
Because a domain is used to manage composites and their components, it is natural for the domain structure to reflect how an organization manages its technology assets. A small company may have one technology department responsible for managing all of its systems, in which case they would likely have a single domain. A large multinational corporation, on the other hand, may have multiple autonomous technology departments, each responsible for their own systems. In this case, the multinational would probably elect to have multiple domains under the control of each department.
A second factor in determining the size of a domain is the SCA implementation. SCA runtimes are not portable to any domain. That is, there is no standard way to create a domain consisting of multiple vendor runtimes. If an organization uses more than one SCA implementation because it has not standardized on one or it requires proprietary features for certain components, it will need to run multiple domains.
This is not to say that a component deployed to a domain will be unable to invoke a service provided by a component in another. As we will see later, SCA provides mechanisms for communicating across domains and with non-SCA services. It does mean, however, that both components will be managed and administered independently.
Implementing Components
SCA applications are best characterized as interconnected components assembled together in one or more composites, where the components may be implemented in a variety of programming languages. Clients, whether they are non-SCA code or other SCA components, interact with components through the services they offer. The implementation details of a particular component—what language it is written in, how it is configured, and what things it depends on—are hidden from clients. Having covered the external facts of a component, we now turn to its internal aspects using the SCA Java programming model.
The Component Implementation
Writing components using the Java programming model is straightforward—SCA does not mandate any special requirements. As the example in Listing 1.7 illustrates, components can be implemented by ordinary Java classes with a few optional annotations.
Listing 1.7 The Component Implementation
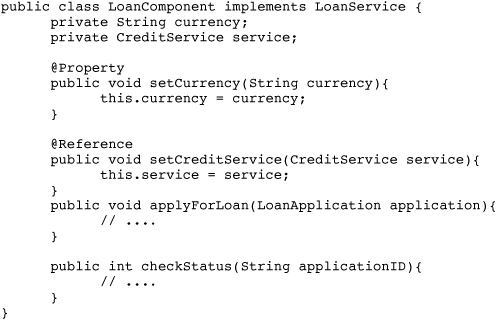
Now, let’s examine what the annotations in Listing 1.7 mean.
Properties
Properties define the ways in which a component can be configured (see Figure 1.10). As an example, a loan application component may have a property to calculate values in euros, U.S. dollars, pounds sterling, or yen.
Figure 1.10 Properties are used to configure components.

Properties are manifested differently depending on the implementation language used for components. In Java, a property is defined by placing an @Property annotation on a method; as we will see in following chapters, fields and constructor parameters may also be properties (see Listing 1.8).
Listing 1.8 A Component Property

The actual property values are specified in a composite file, typically as part of the component definition. When a component instance is created, the runtime it is hosted on will set all properties configured for it. For LoanComponent in Listing 1.8, the runtime will set the currency to a string specified in the composite, such as “USD” or “EUR.”
Properties assist with reuse but, more importantly, they allow certain decisions to be deferred from development to deployment. A typical case is components that must be configured differently in development, testing, staging, and production environments: For example, a component that is configured to connect to a database differently as it moves from development, testing, staging, and finally into production.
References
Components also have references. A reference is a dependency on another service, which the component connects to at runtime (see Figure 1.11). The loan component may have a reference to a service that returns a rate table stored in a database. The rate table service could be offered by another component whose purpose is to hide the intricacies of querying and updating the database.
Figure 1.11 A reference is a dependency on another service.

Similar to properties, references are manifested differently depending on the language in which the component is implemented. In Java, a reference is defined by placing an @Reference annotation on a method. (Fields and constructor parameters are also supported.) The type of the method parameter corresponds to the contract of the service requested, as shown in Listing 1.9.

Unlike tradition programming models, SCA component implementations do not look up their service dependencies using an API such as JNDI. The target of the reference—that is, which specific service it points to—is configured as part of the component definition in a composite file. References are made available to components the same way properties are: When a component instance is created, the SCA runtime will use dependency injection to set a proxy that is connected to the appropriate target services.
After the runtime has provided the component with a proxy to the reference’s target service, it can be invoked like any other object. The component can invoke one of its methods, passing in parameters and receiving a result, as demonstrated in Listing 1.10.
Listing 1.10 Invoking a Service Through a Wire in Java

References provide a level of power and sophistication that is difficult to achieve with earlier component technologies. References can be “rewired” to newer versions of a service at runtime. References can also be used to track dependencies in a system. A management tool that understands SCA metadata could analyze component dependencies in a system to assess the impact of upgrading a component that is used by many clients.
Assembling Composites
A composite file defines one or more components, sets their properties, and configures their references. Listing 1.11 provides the full listing of LoanComposite used in previous examples.

To recap, the meaning of the XML elements in the preceding composite is fairly straightforward, as follows:
• The <component> element defines a component and assigns it a name that is used to reference it at later points in the composite.
• The <implementation.java> element indicates that both components are implemented using the SCA Java programming model.
• The <property> elements configures the value of a component property.
The <reference> element warrants a more detailed explanation. Reference elements are used to configure target services for component references. In the preceding listing, LoanComponent has a reference configured to use CreditService provided by CreditComponent. When a component instance is created, the SCA runtime connects its references to the appropriate target services via proxies. In the listing, the runtime connects LoanComponent to CreditService provided by CreditComponent. This connection is called a wire. A wire is a communication channel between the client component and the target service (see Figure 1.12).
Figure 1.12 A wire is a communications channel.
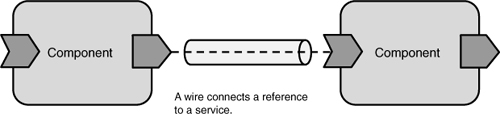
Because components can be co-located (in the same process) or hosted in separate runtimes, wires can be local or remote. From the perspective of the client component, however, a wire does not appear any different. In Java, a proxy backed by a wire will look like any other object.
In addition to configuring components and wiring them, composites serve several other important purposes. Developing applications routinely involves interfacing with external systems or services. Similarly, applications must often expose services to external clients. In many cases, these systems and clients will not be built using SCA. Composites provide mechanisms for making SCA services available to clients outside of a domain (for example, available to non-SCA code) and for accessing services outside the domain (for example, implemented by non-SCA code such as a .NET service). Publishing a service or accessing an external service from a component is done through configuration elements in the composite (SCDL file). The process of applying this configuration is termed “binding a service and reference.”
Binding Services and References
In SCA, bindings are used to configure communications into and out of a domain. Bindings are assigned to the services and references of a component in a composite file. For example, to expose a service as a web service endpoint to external clients, the web service binding is used. SCA defines bindings for web services, JMS, and JCA. Some SCA implementations also support additional bindings, including RMI, AMQP (a messaging protocol), and XML/HTTP.
Listing 1.12 shows a service configured with the web service binding.
Listing 1.12 Exposing a Service as a Web Service Endpoint

In the preceding composite, the <binding.ws> element instructs the SCA runtime to expose LoanService as a web service endpoint at the address specified by the uri attribute. When the composite is deployed to a domain, the SCA runtime activates the web service endpoint and forward incoming requests to LoanComponent.
Similarly, component references may be bound to communicate with external services, such as a .NET web service. The code in Listing 1.13 binds a reference to a web service.
Listing 1.13 Binding a Reference to a Web Service Endpoint

In the previous listing, the SCA runtime will ensure that the bound reference flows invocations using standard WS-* protocols to the target web service. How this is done is transparent to the component implementation. In Java, the component needs to invoke only a method on an object; transport-specific API calls (such as JAX-WS) are not needed (see Listing 1.14).
Listing 1.14 Invoking on a Bound Reference in Java

The key point about bindings is that they are handled through configuration in a composite file. This eliminates the need for components to use protocol-specific APIs. Besides simplifying component implementations, this has two important practical effects. First, it allows the actual protocol used to be changed at a later date without having to modify the component implementation. For example, JMS, or a binary protocol such as RMI, could be substituted for web services. Second, it allows services to be bound to multiple protocols. A service could be configured with binding entries for both web services and JMS, in which case it would be exposed to clients using either of those protocols.
Composites as a Unit of Deployment
Often, despite the fact that related components may be intended for deployment to different runtimes, it makes sense to manage them as a unit. Applications are typically subdivided into a set of components that depend on one another and cannot operate in isolation. In these cases, composites provide a means to group related components so that they may be treated atomically.
When a composite is deployed to a domain, its components will be started. Similarly, when a composite is undeployed, its components will be stopped. In distributed domains, components may be deployed to and undeployed from multiple runtimes. One way to think of a composite, then, is as a counterpart to a Java EE Enterprise Archive (EAR) or .NET Assembly.
A significant difference, however, between SCA and Java EE is that SCA applications are generally more modular than their Java EE counterparts. Experience with Java EE informed much of the design of SCA in this regard. In Java EE, applications are deployed in self-contained archives: EARs or Web Archives (WARs). Although this deployment model works for many applications, for many others it poses severe limitations, particularly when artifacts need to be shared across applications.
SCA applications may consist of multiple composites, thereby making their internal structure more loosely coupled. Each composite can be maintained and evolved independently, as opposed to being part of a single deployment archive. This modularity and loose coupling allow for greater flexibility in maintaining enterprise applications, which must stay in production for years. With SCA, it is possible to upgrade some composites without having to redeploy all the composites in an application.
Deploying to a Domain
Components rarely exist in isolation. In all but the most trivial applications, components rely on supporting artifacts, other code such as classes, and sometimes libraries. In SCA, composite files and component artifacts—for example, implementation classes, schemas, WSDLs, and libraries—are packaged as contributions. The standard contribution format is a ZIP archive, but an SCA implementation may support additional packaging types, such as a directory on a file system. Although not strictly required, a contribution archive may contain an sca-contribution.xml file in a META-INF directory under the root. Similar to a JAR MANIFEST.MF file, the purpose of the sca-contribution.xml is to provide the SCA implementation with processing instructions, such as a list of the deployable composites contained in the archive.
Prior to deployment, composites must be installed in a domain as part of a contribution. After a contribution has been installed, its contained composites may be deployed. How installation and deployment is done will depend on the environment. During development, this may involve copying a contribution archive to a deployment directory, where the SCA runtime will automatically install it and deploy contained composites. In a data center, where more rigorous processes are likely to be in place, a command-line tool or management console can be used to install the archive and subsequently deploy its composite (or composites, because a contribution may contain more than one).
Unlike Java EE EARs and WARs, contributions are not required to be self-contained. A contribution may refer to artifacts such as interfaces, classes, or WSDLs in other contributions by first exporting an artifact in a containing contribution and then importing it in another. Imports and exports are done via entries in the sca-contribution.xml manifest. For example, a manifest exports a WSDL for use in other contributions by specifying its fully qualified name or QName (see Listing 1.15).
Listing 1.15 A Contribution Export

The WSDL is then imported in another contribution by referring to its fully qualified name in an import entry, as shown in Listing 1.16.
Listing 1.16 A Contribution Import

When the composite in the second contribution is deployed, it is the job of the runtime to ensure that the WSDL and all other imported artifacts are available to its components.
The mechanics of how a domain resolves imports to actual contributions is (thankfully) transparent to developers and administrators: Contribution manifest entries are the only thing required. Typically, under the covers, an SCA implementation will use a repository to index, store, and resolve contribution artifacts, as pictured in Figure 1.13.
Figure 1.13 Storing a contribution in a domain repository

When a contribution is installed that imports an artifact, the SCA implementation will resolve it against the repository and make it available to the contribution.
The Deployment Process
What happens when a composite is deployed to a domain? A number of steps must take place prior to the point when its components become active. Although various SCA implementations will vary in specifics, we enumerate the general steps involved in deployment here.
Allocation
The loosely coupled nature of composites allows them to be distributed, possibly spanning geographic regions. A composite may contain components deployed in different data centers. When a composite is deployed, its components are allocated to a set of runtimes. In the case where there is only one runtime in the domain, this is straightforward: Components are always allocated to the same runtime. In the scenarios depicted previously, where there are multiple runtimes potentially spread across data centers, allocation will be more involved. A number of factors need to be taken into account by the domain. For example, is a particular runtime capable of hosting a component written in Java, C++, or BPEL? Other factors may come into play as well, such as co-locating two wired components in cases where performance is critical.
Wiring
As components are allocated, the domain must connect wires between them. When two components are allocated to different runtimes, the domain must establish a communication channel between the two. When no protocol is chosen by the user, it is up to the SCA implementation to decide how remote communication should be handled. Depending on the implementation, the actual protocol used could be web services (WS-*), RMI, JMS, or a proprietary technology. One important factor any implementation must account for when selecting a protocol is the policies associated with the wire. If transactions are specified on the wire, for example, the protocol must support transaction propagation. The domain may also select a communication protocol based on the requirements of the client component and target service. For example, when wiring two Java component implementations, the domain may choose RMI as the transport protocol. Or if the target were implemented in C++ as opposed to Java, web services may be selected based on interoperability requirements.
Exposing Bound Services as Endpoints
When the domain has allocated a composite to a runtime or set of runtimes, bound services must be made available as endpoints. For example, a service bound as a web service must be exposed as a web service endpoint. If a service is bound to JMS, the domain will attach the service as a listener to the appropriate message topic or queue (see Figure 1.14).
Figure 1.14 Binding a service as a message endpoint

It is also possible to bind a service multiple times to different protocols. A service could be exposed as both a web service endpoint and JMS listener. The mechanics of how the domain performs the actual endpoint binding are transparent to the developer and deployer.
Domain Constraints
Domains are designed to simplify the tasks of establishing remote communications, endpoint setup, and resource sharing that are left to developers and deployers in traditional programming models. However, with any technology, there are benefits and trade-offs. SCA is no different. Although domains provide a number of benefits, they also impose certain constraints.
The fact that domain infrastructure is single-vendor means that there is no interoperable way of constructing cross-implementation domains. In other words, a domain cannot be created from multiple vendor (or open source) SCA runtimes in any standard way (of course, vendors could agree to support interoperability in some nonstandard way). This imposes two important practical constraints. First, composites cannot be deployed across multiple-vendor SCA runtimes. The absence of domain interoperability also limits the size of a domain to the component types a particular vendor supports, either natively or through container extensions. If an alternative container is required to host a particular component implementation type, it must be deployed to a different domain capable of running it.
Contrast this lack of domain interoperability to a web services environment where each service is independent and is potentially hosted on entirely different vendor platforms. In this respect, SCA is closer to MOM; there is a one common infrastructure environment, as opposed to many autonomous, but interoperable, islands.
Are the trade-offs between simplicity and common management versus vendor lock-in worth it? There is no way to answer that question in general. However, individual projects can make an informed decision by understanding when SCA may be used effectively and when other technologies are more appropriate. Given the importance of web services, architects and developers will likely be confronted with designing systems using SCA or web services technologies directly.
SCA and Web Services
Both SCA and web services claim to be technologies for building multilanguage, loosely coupled services in a distributed environment. Why not just use web services exclusively to build applications? Recalling that SCA domains are built on single-vendor infrastructure, web services offer a key advantage. They limit vendor lock-in to individual service deployments, as opposed to wider subsystems.
To understand how SCA relates to web services, it is useful to divide web service technologies into a set of interoperable communication protocols (the WS-* specifications) and programming models for using those protocols (for example, in Java, JAX-RPC, and JAX-WS).
At the most basic level, web services deal with protocol-level interoperability. They define how application code communicates with other code in a language-neutral, interoperable manner. Web services make it possible for Java code to communicate with C#, PHP, or Ruby code. Web services achieve interoperability by specifying how service contracts are defined (WSDL) and how data is encoded over particular communications transports (for example, SOAP over HTTP, WS-ReliableMessaging, WS-Security, and so on).
Web services programming models such as JAX-WS define APIs and Java annotations for accessing other web services and making code available as an endpoint. These programming models are specific to web services; their goal is not to provide a communications API that abstracts the underlying transport.
Both at the protocol and programming model level, web services make an important assumption: They were designed for communicating between software that has nothing in common. Web service-based architectures consist of “islands of functionality” that interact with one another (see Figure 1.15).
Figure 1.15 Web service versus SCA architecture

This is not surprising given the array of vendors backing web services standards and their opposed worldviews. However, several consequences follow from this.
First, developing web services can be a complex, labor-intensive process. Sometimes this is necessary. In order to avoid problems with interoperability, top-down development is generally recommended where service contracts are designed upfront in WSDL. Dealing with WSDL is not trivial, notwithstanding tooling designed to alleviate many of the repetitive and error-prone tasks.
A second consequence of web services architecture is that any given service can only make minimal assumptions about the services it interacts with. This limits the degree of management and coordination that can effectively be done across services. It also limits any optimizations that may be done to increase communications performance.
Web service architectures certainly have their place when communicating with services from different companies or between autonomous divisions within a company. However, not every component has to integrate with other components as if another company hosted them. Often, components are not independent. They may share common resources, require common policies such as transactionality, or may be capable of using more efficient communications protocols than web services. In these cases, it is useful to have infrastructure that can provide these features and simplify the task of assembling components into applications. What SCA offers in relation to web services is simplicity, flexibility, and the ability to manage related software components.
Unlike many web services APIs, such as JAX-WS, the SCA programming model does not expose the transport binding used to communicate into or out of a component. As we show in ensuing chapters, SCA greatly simplifies the task of writing distributed code by removing the need for developers to use low-level APIs to invoke services. For those accustomed to low-level access, this may seem like a burdensome restriction, but for most developers, it frees them from having to pollute application code with potentially complex APIs.
Equally important to simplifying application code, SCA frees developers from having to configure policy (for example, security, transactions) and transport protocols for every service or component. Policies can be configured once and reused by multiple components with simple one-word declarations, such as require “confidentiality” on this wire. The intricate details of WSDL, WS-Policy, and the other WS-* technologies (if they are used at all) can be safely avoided by most SCA application code.
Using SCA has another important advantage: It is designed to be dynamic and handle change. Suppose a new security protocol needs to be introduced between two components. Or consider the case where a new version of a web services standard is introduced. If the components were written against lower-level web services APIs, such changes will likely involve code migration. With SCA, an administrator can adapt the components through configuration changes without affecting code.
A further advantage to using SCA is that it allows protocol swapping without requiring code changes. For example, RMI could be substituted for web services where communication performance between two Java-based components is the most important concern. If a component implementation were coded to a particular API such as JAX-WS, this may entail a near-complete rewrite. With SCA, protocol swapping amounts to a configuration change. In this sense, SCA is protocol-agnostic; it enables users to select the one most appropriate to the task at hand, be it web services, XML/HTTP, RMI, JMS, or some other technology.
Summary
Service Component Architecture (SCA) is quickly emerging as a foundation for building distributed systems with significant industry support. Although far-ranging in scope, SCA can be summarized by four core benefits, as follows:
• A simplified programming model for service development
• More efficient and flexible service reuse
• Better management and control of distributed systems
• Simplified policy configuration and enforcement across applications
Having covered how SCA fits into modern application architectures, including its relationship to web services and Java EE technologies, we begin a series of more detailed discussions of its core concepts supplemented with practical examples. Our goal is to provide solid grounding for making intelligent choices about where, when, and how best to employ SCA when building enterprise systems.