
3. Service-Based Development Using Java
SCA is designed to support applications assembled from services written in multiple programming languages. This chapter provides the background and understanding necessary to implement services in arguably the most important of those languages for enterprise development: Java.
SCA includes a full-featured programming model for implementing services in Java. The primary goal of this programming model is to provide the capabilities necessary in Java to build loosely coupled services. Moreover, it attempts to do so in a way that is simpler to use than existing Java-based alternatives, including EJB and Spring.
This chapter focuses on the basics of loosely coupled services, including service contract design, asynchronous communications, and component life cycle. Specifically, this chapter covers the following:
• Designing service contracts
• Implementing asynchronous interactions and callback patterns
• Managing component life cycle, state, and concurrency
After completing this chapter, you will have a solid grounding in implementing Java-based services and an understanding of best practices to apply when designing those services.
Service-Based Development
As we discussed in the first chapter, a key goal of SCA is reuse: Application functionality and code that can be shared by multiple clients is more valuable than functionality and code that cannot.
This goal is far from novel. Many technologies claim to promote code reuse. Arguably, the most successful technologies in this respect have been object-oriented languages, which did much to promote intra-process reuse, or calls between code hosted in the same process. By organizing code into classes and interfaces, object-oriented languages allowed complex applications to be assembled from smaller, reusable units that are easier to maintain and evolve.
Yet code would be even more valuable if reuse were not limited to a process or application. In other words, if clients could connect remotely with existing or separately deployed code, the code would be even more valuable. In the 1990s and early 2000s, DCE, CORBA, DCOM, and Java EE attempted to replicate the success of object-oriented technology in distributed applications by applying many of the same principles to remote communications. In particular, these technologies were built around the concept of “distributed objects”: units of code that could be invoked remotely to perform a task. The goal of these frameworks was to enable objects to be invoked across process boundaries similar to the way that object-oriented enabled objects could be invoked locally.
Unfortunately, practical experience highlighted a number of problems with this approach. The most important of these was that local and remote invocations are different and those differences cannot be managed away by middleware. Remote communication introduces latency that affects application performance. This is compounded when additional qualities of service are required, such as transactions and security. One of the key lessons learned from distributed objects is that applications must be carefully designed not to introduce bottlenecks by making too many remote calls or by placing unnecessary requirements on them, such as transactionality.
SCA rejects the notion that object-oriented principles are to be employed at all levels of application design. A core tenet of SCA is that development of remote services is unique. For remote communications, developers rely on the techniques of loose coupling that we describe in this chapter.
Most applications, however, cannot be restricted to remote invocations. In order to achieve scalability, performance, and avoid unnecessary complexity, application code will need to make many more local calls than remote ones. In these cases, SCA stipulates that developers apply principles of good object-oriented design. In addition to loosely coupled remote services, we also detail the facilities provided by the SCA Java programming model for creating services intended for use in a single process, which follow traditional object-oriented patterns.
Protocol Abstraction and Location Transparency
Protocol abstraction and location transparency are commonly confused. Understanding the distinction between the two is fundamental to understanding the SCA programming model. SCA simplifies development by handling the intricacies of remote communications. What it doesn’t do is oversimplify the nature of those communications and the impact they have on application code.
Protocol abstraction involves separating the specifics of how remote invocations are performed from application code by requiring the hosting container to manage communications. For example, the following service invocation could be made using web services or an alternative protocol such as RMI—the host container handles the specifics of flowing calls while the code remains unchanged (see Listing 3.1).
Listing 3.1 Invoking a Remote Service

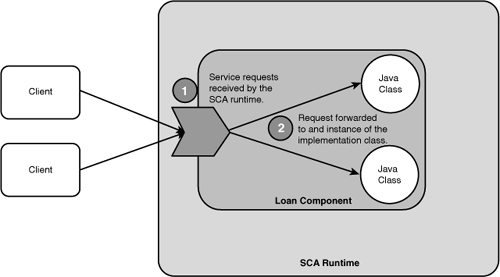
In contrast, location transparency allows code to treat local and remote invocations as if they were the same. Protocol abstraction does not mean that client code can be written in the same way irrespective of whether it is making a local or remote call. Consider the example in Figure 3.1 again where the LoanComponent invokes the remote CreditService. Because the invocation is remote, the client—in this case, the LoanComponent—will need to account for a number of additional factors. Perhaps the most important is network latency, which may result in the call not completing immediately. Second, network interruptions may result in the CreditService being temporarily unavailable. In these cases, the SCA runtime may throw an unchecked org.osoa.sca.ServiceUnavailableException, and the client must decide whether to retry, ignore the exception and let it propagate up the call stack, or perform some other action. In the example, the client allows the exception to propagate (it’s unchecked, so it does not need to be declared in a throws clause) and be handled by its caller. If the operation had required a degree of reliability, the LoanComponent could have caught the exception and attempted to retry the call.
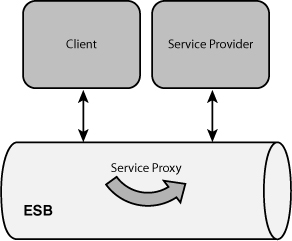
Figure 3.1 A service bus mediates the communications between a client and service provider.
So, protocol abstraction does not imply location transparency. It’s also important to note that the converse is also true: Location transparency does not imply protocol abstraction. Programming models that provide location transparency do not necessarily allow communications protocols to be changed. CORBA and DCOM serve as good examples. Both attempt to treat remote and in-process communications in the same manner but support only a single remote protocol. CORBA remains tied to the IIOP protocol. Similarly, DCOM is dependent on its own proprietary binary protocol.
Having established that the SCA programming model is based on the goal of protocol abstraction rather than location transparency, let’s look more closely at what is involved in building remotable services.
Designing Remotable Services
In SCA, remotable services are made available to multiple clients across process boundaries. These clients may be components in the same domain or, if the service is exposed over a binding, another system altogether.
Although the specific qualities of well-architected SCA applications will vary, a common indicator of good design is that an application will have only a few remotable services that expose a set of general operations. Examples of general operations include “apply for loan,” “get credit rating,” “inventory check,” and “place back-order.” Think of remotable services as an API. As with a good API, remotable services should be concise, easy to understand, and limited. Moreover, they should have the following attributes:
• Remotable services account for the network—Remotable services should account for the realities of the physical network they are called over, particularly latency and connectivity interruptions. In particular, they should limit the number of exchanges required between a client and service provider.
• Remotable service contracts take versioning into account—Remotable service contracts should be evolvable. Rarely do APIs “get it right” in the first iteration. Furthermore, new requirements often arise after an application has gone into production. Barring fundamental changes, it should be possible to version services without breaking compatibility with existing clients.
• Remotable services limit the assumptions made about clients—Remotable services should limit the assumptions they make about clients. Most important, they should not assume that clients will be written in the same language they are written in.
To achieve these qualities, SCA relies on techniques of loose coupling developed by integration technologies—in particular, message-oriented middleware (MOM). Loose coupling can take a variety of forms. The two most important forms of loose coupling in SCA are coarse-grained services and asynchronous communications. We deal with designing coarse-grained service contracts in the next section, followed by a detailed discussion of how SCA allows for asynchronous communications via non-blocking operations and callbacks in subsequent sections.
Perspective: How Loosely Coupled Should Services Be?
A common question that arises when designing service-based applications is how loosely coupled remote communications should be. One school of thought says that services should be as loosely coupled as possible and, in order to achieve this, an Enterprise Service Bus (ESB) should be used to route messages between all clients and providers.
ESBs offer the following forms of loose coupling:
• Target abstraction—The capability to dynamically route service requests to service providers based on message content or type.
• Protocol translation—The capability to transform a service request from a client over one protocol into the protocol supported by the service provider.
These capabilities are provided through a “service bus” that is placed between the client and service provider (see Figure 3.1).
When clients are targeted at the bus instead of the actual service provider, it is possible to change the provider by simply changing the bus configuration. This can usually be done without any programming, typically through an administration console. This gives the added flexibility of allowing the bus to use a different protocol to call the service provider than is used to communicate with the client.
SCA takes a different approach to loose coupling by asserting that services should be no more loosely coupled than necessary. Loosely coupled systems are generally more difficult to write and complex to manage. Moreover, introducing mediation can result in an unnecessary and potentially expensive invocation hop. As shown in Figure 3.2, in an ESB, a message is sent from the client to an intermediary and on to the target service, creating three hops.
Figure 3.2 ESBs introduce an additional hop.

In contrast, with SCA, the decision to introduce mediation can be deferred until after an application has gone into production (see Figure 3.3). This avoids introducing the performance penalty associated with an extra hop until mediation is needed. If a service contract changes, an SCA runtime can introduce an intermediary in the wire between the client and service provider dynamically that transforms the request to the new format.
Figure 3.3 SCA and late mediation

Because SCA abstracts the mechanics of remote calls from application code, mediation can be introduced in much later stages of an application life cycle without forcing code modifications.
One area where an ESB has an advantage over an SCA runtime is in target abstraction. SCA provides no mechanism for performing content-based routing where a service provider is selected dynamically based on parameter values. To effect content-based routing in SCA, a client would need to be wired to a component that made routing decisions and forwarded the request to the appropriate service provider.
Coarse-Grained Services
In SCA, remotable service contracts should have coarse-grained operations that take document-centric parameters. Let’s examine what this means. Coarse-grained operations combine a number of steps that might otherwise be divided into separate methods. To better understand how coarse granularity is achieved in practice, we start with a counter-example. Listing 3.2 shows a version of the LoanService using fine-grained operations.
Listing 3.2 An Example of a Fine-Grained Service Contract

In the preceding fine-grained version, applying for a loan is done through a series of requests to the LoanService.
Although a fine-grained design seemingly allows for more flexibility (clients can supply the required information in stages), it can potentially introduce serious performance bottlenecks. Back to Figure 3.2, each invocation of the LoanService—apply, supplyCreditInfo, and getResult—entails a separate network roundtrip. This can be extremely expensive, as parameter data needs to be marshaled and unmarshaled when the invocation travels across the network.
In contrast, the LoanService version used in the last chapter processes a request using one operation by requiring that all required data be provided upfront (see Listing 3.3).
Listing 3.3 An Example of a Coarse-Grained Service Contract

The most important characteristic of the coarse-grained version in Figure 3.6 is that it optimizes network roundtrips, eliminating a potentially costly bottleneck. Instead of the three roundtrips required by the fine-grained version, the coarse-grained LoanService requires only one.
Another important difference between fine- and coarse-grained interfaces is the number of parameters operations take. With fine-grained interfaces, operations commonly take multiple parameters. In contrast, coarse-grained operations are usually document-centric, which means they take one parameter that encapsulates related data. The LoanResult.apply(LoanRequest request) operation shown previously in Listing 3.3 is document-centric because it takes a single parameter of type LoanRequest.
Document-centric contracts are recommended for remotable services because they are easier to evolve while maintaining compatibility with existing clients. For example, if BigBank decided to collect additional optional loan information that would be used to offer interest rate discounts, it could do so by adding additional fields to the LoanRequest type. Existing clients would continue to function because the additional fields would simply be ignored. In contrast, the fine-grained contract would more likely require modifications to the operation signature, breaking existing clients.
Using coarse-grained operations that take document-centric parameters decreases the amount of inter-process communication in an application. This not only improves performance by limiting network traffic, it also makes writing robust applications easier because developers are required to handle issues related to service unavailability and versioning at fewer places in the application.
However, there is also a disadvantage to the coarse-grained approach—error handling can be much more difficult. In the coarse-grained version of the LoanService, applicant-related data is contained in the LoanApplication class, which is passed to the former as one parameter. This makes the source of errors in part of the data more difficult to identify and respond to. For example, an invalid ZIP code (postal code) may occur in the applicant’s or property address. This requires a mechanism for reporting the source of errors. In addition, the application could have a number of problems with it, requiring a way to aggregate and report them in an exception or result data. Handling errors in this way is more complicated than it is with the fine-grained contracts, but the advantages of loose coupling outweigh the added complexity.
Using WSDL for Service Contracts
Remotable services should be loosely coupled with their clients by making limited assumptions about them. This entails not assuming clients will be written in Java. When defining remotable service contracts, it is therefore good practice to design for language interoperability. One of the key pitfalls in doing so is the translation of data types across languages. In particular, operation parameter types may not map cleanly or at all in different languages. Simple types such as strings and numerics generally do not present difficulties. However, user defined-types, especially complex types such as classes, often pose challenges. To achieve interoperability, it may be necessary to create a language-neutral representation of the service contract that also defines operation parameter types.
As we have seen in Chapter 2, “Assembling and Deploying a Composite,” the most common way to do this today is through WSDL. A WSDL document describes a service or set of services and their operations. SCA runtimes and IDEs typically provide tooling that makes it easier to work with WSDL. For example, some tools allow the service contract to be written in Java first as an interface and a WSDL generated from it. This is usually the easiest approach, at least for Java developers. However, some organizations prefer a top-down approach where service contracts are crafted directly in WSDL. This approach, although more time-consuming and potentially difficult, has the advantage of better accommodating interoperability because the contract is defined in a language-neutral way. When starting top-down, Java interfaces that application code uses are created based on the WSDL contract. Fortunately, many tools automate this process by generating the interfaces from WSDL.
Service Contracts and Data Binding
All SCA runtimes must support a mechanism for serializing parameter types remotely. This mechanism is commonly referred to as “data binding.” An SCA runtime may support one or several data-binding technologies, depending on the remote communication protocol used. For example, an SCA runtime may support one data-binding technology for serializing parameter values as XML and another for binary protocols. Some data-binding technologies place special requirements on parameter types that you may need to take into account when designing service contracts. Again, because data-binding technologies are vendor-specific, different SCA runtimes may vary in their approach. Books have been written on the subject of data binding, and we will not cover it in depth here other than to discuss where it fits into remotable service design.
The most prevalent data-binding technologies when working with XML today are XML Schema-based, including JAXB (part of JDK since version 6), Service Data Objects (SDO), and XmlBeans. Despite their differences, JAXB, SDO, and XmlBeans (and most other data-binding technologies) use XML Schema as the way of defining types for XML in order to map from Java types (for example, classes and primitives) to XML and vice versa (see Figure 3.4).
Figure 3.4 JAXB, SDO, and XmlBeans use XML Schema to map between Java and XML.

JAXB, SDO, and XmlBeans specify rules for mapping from schema to Java types and vice versa. These type mappings are used to convert data between XML and Java—for example, mapping java.lang.String to the schema type xs:string.
An SCA runtime uses a data-binding technology to translate data sent as XML from a client (often written in a language other than Java) to a service. To do so, it uses its schema-based mapping rules to translate the XML data into its Java representation (see Figure 3.5).
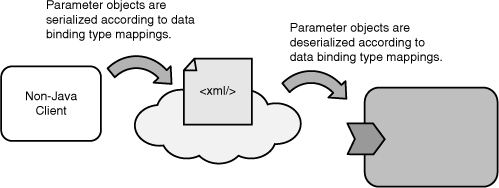
Similarly, an SCA runtime uses a data-binding technology to serialize data to XML when a call is made to a remote service.
Fortunately, although data-binding discussions can become complex and esoteric, XML data-binding technologies are relatively easy to use. JAXB, SDO, and XmlBeans all support the “start-from-schema” approach where a combination of WSDL and XML Schema are used to define the service contract and its operation parameters. In this approach, Java classes are derived from WSDL and XML Schema. An SCA runtime or an IDE may provide tooling that automates this process by generating Java classes.
Some data-binding technologies also support “start-with-Java.” In this approach, rather than having to deal with the complexity of XML, developers can define their interfaces in Java and have WSDL and XML Schema generated. An SCA runtime may use one of these data-binding technologies to enable developers to write service contracts entirely in Java. Fabric3, for example, uses JAXB.
JAXB is arguably one of the easiest “start-from-Java” data-binding technologies. Being part of the JDK since version 6, it certainly is the most prevalent. JAXB does a good job of specifying default mappings so developers don’t have to. JAXB makes heavy use of annotations to map from Java to XML. For example, to bind the LoanApplication type to XML using JAXB, @XmlRootElement is added as an annotation to the class (see Listing 3.4).
Listing 3.4 A JAXB Complex Type

Perspective: Which Data Binding Should You Choose?
A common misperception is that SCA requires or mandates SDO as its data-binding technology. In fact, SCA is data binding-agnostic and is intended to work equally well with JAXB, XmlBeans, and other like technologies. Selecting a data-binding solution will often be constrained by the runtime, which may support only one or a limited number. In cases where there is a choice, selection should be based on the requirements of an application.
JAXB is particularly well-suited for interacting with data in a strongly typed fashion, namely as Java types. This is perhaps the most common development scenario, as component implementations are generally aware of the data types they will be manipulating in advance. Other major advantages of JAXB are its relative simplicity and its capability to use plain Java Objects (POJOs) without the need to generate special marshaling classes. When combined with SCA, JAXB provides a fairly transparent solution for marshaling data to and from XML. For example, in the following extract, the JAXB LoanRequest and LoanResult objects can be unmarshaled and marshaled transparently by the SCA runtime:

A major disadvantage of JAXB is that although it provides strong support for “start-from-Java” and “start-from-schema” development scenarios (that is, generating a schema for existing Java classes and generating Java classes from an existing schema, respectively), it does not handle “meet-in-the-middle” well. The latter is important in situations where existing schemas must be reconciled with existing Java types.
Another feature lacking in JAXB is support for an API to dynamically access XML data. In situations where a component may not statically know about the data types it will manipulate, SDO and XMLBeans provide a dynamic API for introspecting and accessing data.
A significant downside of SDO and XmlBeans is their current lack of support for starting with Java. Both data-binding technologies require Java types to be generated from pre-existing schemas. This introduces another step in the development process (generating the Java types) and slightly complicates application code as SDO and XmlBeans require generated types to be instantiated via factories.
In many cases, JAXB is a reasonable choice given its simplicity and reliance on POJOs. However, application requirements may vary where SDO, XmlBeans, or an alternative technology are more appropriate. Fortunately, SCA is not tied to a particular data-binding solution and can accommodate a number of different approaches to working with XML.
Pass-By-Value Parameters
An important characteristic of remotable services is that operation parameters are pass-by-value, as opposed to pass-by-reference. The main difference between the two types concerns visibility of operation parameters. When pass-by-value parameters are modified by the component providing a service, they are not visible to the client. When pass-by-reference parameters are modified by a component providing a service, they are visible to the client. In Java, pass-by-reference means a reference to the same parameter object is shared by the client and service provider. Pass-by-value generally entails copying parameters or enforcing a copy-on-write scheme—that is, lazily copying when data is modified. For example, the following example demonstrates the difference between pass-by-value and pass-by-reference:
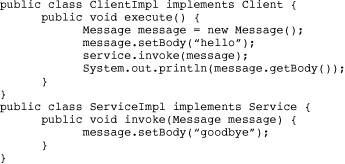
In the preceding example, assume ServiceImpl takes enough time processing the message that the call to Message.setBody(..) in Client is made before the call to System.out.println(..) in ServiceImpl. If the Service interface is marked with @Remotable, ServiceImpl will output: Message is hello. However, if the Service interface is not marked with @Remotable, ServiceImpl will output: Message is goodbye.
In the case where ClientImpl and ServiceImpl are located in processes on different machines, pass-by-value is enforced as the parameters are marshaled from one process to the other (see Figure 3.6).
Figure 3.6 A pass-by-value invocation

When both the client and provider are in the same address space, an SCA runtime must also ensure these same semantics. Otherwise, the interaction between two components can drastically change based on how they are deployed, leading to unpredictable results. In order to ensure consistency and pass-by-value, an SCA runtime will typically copy parameters as a remotable service is invoked (see Figure 3.7). This ensures that neither the client nor the service provider is accidentally depending on by-reference semantics.
Figure 3.7 A pass-by-value invocation between co-located components

When a client and provider are co-located in the same process, parameter copying may introduce significant overhead. If parameters are immutable types—for example, Java strings or primitives—the SCA runtime may perform an optimization by avoiding copying because the parameters cannot be modified. However, because parameters are often mutable, it is important to think carefully about the performance impact of defining a service as remotable. Because the LoanService must be accessible to remote clients, we are willing to accept the performance penalty associated with pass-by-value parameters.
@AllowsPassByReference
When the client and remote service are co-located, the SCA runtime typically ensures pass-by-value semantics by making a copy of the parameter data prior to invoking the service. If the service implementation does not modify parameters, this can result in significant and unnecessary overhead.
SCA provides a mechanism, the @AllowsPassByReference annotation, which allows runtimes to avoid unnecessary parameter copying when an invocation is made between two co-located components. This annotation is specified on a component implementation class or operation to indicate that parameters will not modified by application code. The implementation in Listing 3.5 uses the annotation on the interface, allowing the runtime to optimize all operations when the component is co-located with a client:
Listing 3.5 Using @AllowsPassByReference

Generally, @AllowsPassByReference is used on an interface. However, if a service contains multiple operations, some of which modify parameters, the annotation may be used on a per-operation basis.
Asynchronous Interactions
Calls to remotable services that take place over a network are typically orders of magnitude slower than in-process invocations. In addition, a particular service invocation may take a significant amount of time to complete; perhaps hours, days, or even months. This makes it impractical for clients to wait on a response or to hold a network connection open for an extended period of time. In these cases, SCA provides the ability to specify non-blocking operations. When a client makes a non-blocking invocation, the SCA runtime returns control immediately to it and performs the call on another thread. This allows clients to continue performing work without waiting on a call to complete.
Asynchronous communications have a long history in MOM technologies and differ substantially from the synchronous communication styles adopted by technologies including RMI, EJB, DCOM, and .NET Remoting. A downside to asynchronous interactions is that they tend to be more complex to code than synchronous invocations. However, asynchronous communications are more loosely coupled then synchronous variants and provide a number of benefits that outweigh the additional complexity in many situations. Because a client does not wait on a non-blocking call, the SCA runtime can perform multiple retries if a target service is not available without blocking the client. This is particularly important for remote communications where service providers may be rendered temporarily unavailable due to network interruptions.
Asynchronous interactions have an additional advantage in that they generally improve application scalability. They do this by enabling clients to perform other tasks while a call is outstanding. Non-blocking operations also let clients make a series of parallel invocations, potentially reducing the amount of time required to complete a request as operations do not need to be performed serially. In addition, particularly in cases where an operation may take a long time to complete, non-blocking operations allow runtimes to hold network resources for shorter periods of time and not have to wait on a response.
To summarize, the advantages of asynchronous interactions include the following:
• They are more loosely coupled.
• They tend to be more scalable.
• Fewer network resources are held for long periods of time.
Although there is no hard-and-fast-rule, non-blocking operations should be used for remotable services when possible. To see how this is done, we will modify the CreditService.checkCredit() operation to be non-blocking. Calculating a credit rating may be time-consuming, and by performing this operation asynchronously, the LoanComponent component can continue with other tasks. In addition, BigBank may decide in the future to use multiple CreditService implementations that rely on different credit bureaus. Making the service asynchronous will allow the LoanComponent to issue multiple calls in succession without having to wait for each to complete.
Specifying a non-blocking operation using Java is straightforward: Mark a method on an interface with the @OneWay annotation. Listing 3.6 demonstrates a service contract with a non-blocking operation:
Listing 3.6 Defining a Non-Blocking Operation

It is important to note that SCA places two restrictions on non-blocking operations. First, they must have a void return type. (We cover how to return responses using callbacks in the next section.) Non-blocking operations must also not throw exceptions.
Listing 3.7 shows how the CreditService is called from a client:
Listing 3.7 Calling a Non-Blocking Operation

In the previous example, when the call to CreditService.checkCredit() is made, the runtime will return control immediately to the LoanComponent without waiting for the call to the CreditService to complete.
How does an SCA runtime implement non-blocking behavior? This depends in part on whether the client and service provider are co-located or hosted in different processes. For a local call (that is, between a co-located client and provider), the runtime will execute the invocation on a different thread. If the call is remote, the runtime will ensure that the underlying communications infrastructure uses asynchronous (one-way) delivery. This can be trivial with some communications mechanisms such as JMS, which are inherently asynchronous. However, it may be more involved with others that are synchronous, such as RMI/IIOP. In these cases, the runtime may need to take extra steps (such as using a different thread) to ensure that the calls are sent in a non-blocking manner.
Reliability
One issue that often comes up with non-blocking invocations is reliability. Namely, given that the invocation is performed asynchronously and there is no return value, how does a client know if the target service successfully received the invocation? Reliable delivery is often achieved via the underlying communications channel. For example, an SCA runtime could use JMS or messaging middleware to send an invocation to a target service. As we cover at length in Chapter 7, “Wires,” a client can place requirements such as reliable delivery on its communications with other services through the use of policy.
Exception Handling
Because one-way invocations return immediately without waiting for the service provider to complete processing an invocation, exceptions cannot be thrown and returned to the client. Instead, exceptions should be passed back to a client via a callback, the subject of the next section. After we have covered callbacks, we will return to a discussion on how to use them for error handling with non-blocking invocations.
Callbacks
In the previous example, we modified the CreditService.checkCredit() to be non-blocking. This poses a seeming problem: Because SCA requires non-blocking operations to have a void return type, how does the checkCredit operation return the credit score to a client? After all, the CreditService would be fairly useless if it did not return a credit rating.
SCA allows services with non-blocking operations to return responses to clients through a callback. A callback is essentially a proxy to the client given to the service provider when an invocation is made. This proxy can be used to invoke operations on the client—for example, to provide status updates or return a result. In SCA, service providers that callback their clients are said to offer bidirectional services. That’s because the service provider communicates with its client through a callback service. Callback services are just like regular service contracts. The only restriction SCA places on bidirectional services is that both the forward and callback service must either be remotable or local; it is not possible to mix service types.
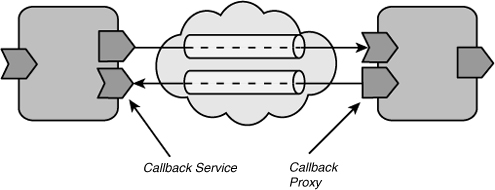
When a client component wired to a component offering a bidirectional service is deployed, the runtime establishes two communications channels: one for the forward service and one for the callback (see Figure 3.8).
Figure 3.8 Two communication channels are established for the forward service and a callback.
A callback is initiated by the service provider when it has finished processing a request or wants to update the client at a certain point in time. Callbacks are useful for implementing potentially long-running interactions in an efficient and scalable manner. A callback can be made in response to an invocation after a period of months. When used in conjunction with non-blocking operations, this allows a runtime to hold a network connection only for the time it takes to marshal the forward and callback invocations as opposed to the time spent processing.
To use a callback in Java, the service contract declares a callback interface that must be provided by the client. This is done via the @Callback annotation. Listing 3.8 lists the CreditService modified to specify a callback interface, CreditCallback.
Listing 3.8 Specifying a Callback Interface

The CreditCallback interface is defined in Listing 3.9.
Listing 3.9 The Callback Interface

Using a callback in a component implementation is straightforward. The component uses the @Callback annotation to instruct the runtime to inject a proxy to the callback service. This is shown in Listing 3.10.
Listing 3.10 Injecting and Invoking a Callback Proxy

Callback injection follows the same rules as reference and property injection: Public setter methods and fields, protected fields, and constructor parameters may be marked with the @Callback annotation.
In the composite, the LoanComponent and CreditComponent are wired as before. In other words, there is no special wiring information required for the callback. Listing 3.11 lists the composite.
Listing 3.11 No Special Wiring Information Is Needed in a Composite for Bidirectional Services

The SCA runtime will be able to figure out from the annotations on the interface contracts that forward and callback communications channels need to be established between the LoanComponent and CreditComponent.
In the previous example, the callback interface specified only one operation, which returned the credit rating result. In many cases, a client and service provider will have a series of interactions. For example, a service provider may want to provide status updates to a client. Or the service provider may notify a client of different results for different forward operations. To do so, the callback interface may define multiple operations. For example, the CreditCallback could define a callback operation for status updates. As with regular services, callback services can be invoked multiple times.
Exception Handling, Non-Blocking Operations, and Callbacks
When we discussed non-blocking operations, we mentioned that exceptions encountered by a service provider cannot be thrown back to the client because the original invocation will likely have returned prior to processing. Instead, callbacks should be used to report error conditions back to the client. This can be done by adding operations to the callback interface, as shown in Listing 3.12.
Listing 3.12 Reporting Service Provider Errors Using a Callback

Instead of throwing an error, the service provider invokes the callback, passing an error object containing information detailing the nature of the exception.
Designing Local Services
Simple SCA applications may have just a few remotable services implemented by isolated classes. However, applications of any complexity will have remotable services implemented by components that rely on multiple classes to perform their task. One implementation strategy is for a component to directly instantiate the classes it needs. With this approach, each component is responsible for configuring the classes it needs.
The SCA authors believed that requiring individual components to manually assemble local objects would lead to brittle, difficult-to-maintain applications. As an application increases in complexity, having components instantiate classes directly makes configuration more difficult and inhibits sharing between components. Why not apply the same assembly techniques to local objects, making them components as well?
Local services are used to assemble finer-grained components hosted in the same process. These components interact to process a request made via a remotable service, as displayed in Figure 3.9.
Figure 3.9 Local service assembly

Why are local services important in distributed applications? The simple answer is they enable developers to avoid having to make all services in an application remotable if they want to use the assembly capabilities of SCA.
Local services are much more performant than remotable services because they avoid network calls and having to pass parameters by value, which involves the expense of copying. (We explained pass-by-value in Chapter 2.) Local services also reduce application complexity, as clients do not need to account for service interruptions and latency when they are invoked. Perhaps most important, local services provide application-level encapsulation by enabling developers to restrict access to services that should not be exposed remote clients. Returning to our API analogy for remotable services, local services enable developers to provide cleaner interfaces by restricting access to parts of an application.
Local services should be designed using object-oriented principals instead of service-based principals. Because local services are co-located, they do not need to account for network latency or unreliability. Further, because all calls to local services are in-process, parameters are passed by-reference as opposed to by-value. (That is, no copy is made.) By dispensing with the degree of loose-coupling demanded by remotable services, application code can be greatly simplified. At the outset of the chapter, we stated SCA rejected the notion that object-oriented techniques should be applied to distributed components. In this context, it is also true that SCA rejects the notion that service-based techniques should be applied to local components.
In contrast to remotable services, local service contracts should be fine-grained and perform very specific tasks. Finer-grained operations are generally easier for clients to use and provide more flexibility because processing can be broken down into a series of invocations. Finer-grained service contracts also tend to make applications more maintainable because components that implement them perform specific tasks. This allows applications to be organized better as discrete units. This has the added benefit of making testing easier.
Implementing a component that offers a local service is straightforward. The implementation can be a plain Java class with no other requirements. It may have properties and references like any other component. Although not strictly required, the class should implement an interface that defines the service contract. Listing 3.13 illustrates a basic component implementation with one local service.
Listing 3.13 A Local Service Implementation

In a complete implementation, the class in Listing 3.13 would use a persistence technology such as JDBC or Java Persistence Architecture (JPA) to access the database. Chapter 11, “Persistence,” covers persistence in detail, in particular using JDBC and JPA with SCA.
Component Scopes
Up to this point, we have discussed component life cycle only briefly. Although some applications may be composed entirely of stateless components, it is often the case that components need to preserve state across a number of requests. Components can maintain state manually—for example, by persisting it to a database. However, using a database is a fairly heavyweight solution. There are also cases where component initialization is expensive and it is appropriate to have one instance of a component handle multiple requests. To accommodate these cases, the SCA programming model allows component implementations to specify their life cycle, or scope. A scope defines the life cycle contract a component implementation has with the SCA runtime.
Component Implementation Instances
In order to understand scopes, it is necessary to briefly explain how an SCA runtime dispatches a request to a component implemented in Java. Figure 3.10 illustrates how an SCA runtime forwards a request to a component.
Figure 3.10 Dispatching to a component implementation instance

When a request is received, the runtime forwards the request to an instance of the component implementation.
Because an SCA runtime commonly handles multiple simultaneous requests, many instances of the component implementation class may be active at any given time. The SCA runtime is responsible for dispatching those requests to individual instances, as depicted in Figure 3.11.
Figure 3.11 Dispatching to multiple component implementation instances
Scopes are used by component implementations to instruct the SCA runtime how to dispatch requests to implementation instances. Scopes are specified using the @Scope annotation on the implementation class. Because scopes determine how requests are dispatched, they control the visibility of an implementation instance to clients. SCA defines three scopes: stateless, composite, and conversation. In this chapter, we cover the first two; conversation scope is the subject of Chapter 4, “Conversational Interactions Using Java.”
Stateless-Scoped Components
By default, components are stateless. For stateless components, the SCA runtime guarantees that requests are not dispatched simultaneously to the same implementation instance. This means that an instance will process only one request at a time. To handle simultaneous requests, an SCA runtime will instantiate a number of instances to process the requests concurrently. Further, if a client makes a series of requests to a stateless implementation, there is no guarantee that the requests will be dispatched to the same instance. (They likely will not.) Typically, a runtime will either create a new instance for every request or pull an instance from a pool.
Note that a component with a stateless scope is not necessarily devoid of state. The stateless scope means that only the SCA infrastructure will not maintain any state on the component’s behalf. The component may manage state manually through a database or some other storage mechanism, such as a cache.
Composite-Scoped Components
For components that are thread-safe and take a long time to initialize, having multiple implementation instances may result in unnecessary overhead. Sometimes only one implementation instance for a component should be active in a domain. In these cases, SCA allows implementations to be declared as composite-scoped by using the @Scope("COMPOSITE") annotation, as demonstrated in Listing 3.14.
Listing 3.14 A Composite-Scoped Component Implementation

Composite-scoped implementations are similar to servlets: One instance in a domain concurrently handles all requests. Consequently, like servlets, composite-scoped implementations must be thread-safe. However, unlike servlets, the component implementation may store state in its fields and expect that every use of the component will have access to that state.
Officially, the lifetime of a composite-scoped instance is defined as extending from the time of its first use (that is, when the first request arrives or the component is initialized—more on this later) to the time its parent composite expires. During this period, the SCA runtime will create only one instance and route all requests to it. Note that some SCA runtimes may provide fault tolerance for composite-scoped components. In these cases, if the process hosting a composite-scoped component crashes, the runtime will guarantee that failover occurs to another process without losing data associated with the component.
Using Stateless Components
By default, components are stateless. Every invocation to a service offered by a stateless component may be dispatched by the SCA runtime to a different instance of the implementation class. In a distributed environment, stateless instances afford the domain flexibility in scaling an application. This is because state does not need to be maintained by the runtime between requests. Consequently, when a stateless component is deployed, it can be hosted in multiple runtime instances.
To understand how a component’s scope affects scaling, consider the case where two components are clients to a service offered by a third component. If the two clients are deployed to separate processes, copies of the stateless service provider component may be co-located with the clients (see Figure 3.12).
Figure 3.12 Co-locating three stateless components

Co-locating copies of the service provider component can be done because state is not managed by the runtime, allowing it to be replicated throughout the domain. This has the effect of improving application performance because requests from the two clients are not sent over the network. It also provides better fault tolerance because a failure affecting one runtime will affect only a single client.
Conversation-Scoped Components
SCA provides the ability to have the runtime manage state between a client and a component over a series of interactions known as a “conversation” by using conversation-scoped implementations. We provide an in-depth discussion of conversational services and conversation-scoped components in Chapter 4.
Initialization and Destruction Notifications
Component implementations can receive life cycle notifications by annotating public, zero-argument methods with the @Init and @Destroy annotations. A method annotated with @Init will be called by the SCA runtime when the implementation instance is created. Similarly, a method annotated with @Destroy will be called as the implementation scope expires and the component instance is released. Initialization and destruction callbacks can be used by implementations to set up and clean up resources. The following demonstrates initialization and destruction methods on a composite-scoped implementation. The initializer method will be called when the implementation instance is first created and all of its dependencies have been injected. If the class uses any setter-based or field-based injection, the constructor of the class isn’t a very useful place to put initialization logic, so a method that is marked with @Init should be used. If only constructor injection is used, the constructor may also be used as the initializer.
The component’s destructor will be invoked when the parent composite is removed from the runtime, causing the component to expire (see Listing 3.15).
Listing 3.15 Using @Init and @Destroy

Eager Initialization
By default, composite-scoped implementations are lazily instantiated by the SCA runtime—that is, they are instantiated as the first service request is received. In some cases, particularly when initialization is time-consuming, it is useful to perform instantiation upfront as the composite is activated in the domain. Composite-scoped implementations can be set to eagerly initialize through use of the @EagerInit annotation, as shown in Listing 3.16.
Listing 3.16 An Implementation Marked to Eagerly Initialize

The preceding implementation will be instantiated as soon as the component is activated in the domain, prior to receiving requests. As part of the instantiation process, the init method will also be invoked by the SCA runtime. (The implementation could have omitted an initializer if it were not required.)
Testing Components
We conclude this chapter with a note on testing. A common question that arises when writing SCA components is how best to test them. In recent years, a wide range of testing methodologies has emerged, some of which have engendered a great deal of controversy. Choosing the right methodology, whether it is Test Driven Development (TDD) or a more traditional code-first approach, is a personal choice and depends on the requirements of a particular project. However, whatever approach to testing is adopted, SCA’s reliance on inversion of control makes this process much easier.
How a programming model facilitates testing is of critical importance given the impact it has on project costs. As was learned with EJB, programming models that require complex test setup can be one of the primary impediments to developer productivity. Tests that are unnecessarily time-consuming to set up take away from development time and hinder the code-test-refactor process that is key to producing good software.
Moreover, complex setup often leads to poor test coverage, resulting in higher costs later in a project’s life cycle. If tests are too complex to write and set up, developers will either avoid doing so or not be able to create ones that are fine-grained enough to exercise all parts of an application. Poor test coverage will inevitably result in more expensive bug fixing after an application has gone into production.
As an application enters maintenance mode, poor tests will continue to incur significant costs. Changes and upgrades will be difficult to verify and take longer to verify—all of which is to say that contrary to being relegated to an afterthought, testing strategy should be at the forefront of project planning. Further, the extent to which a programming model facilitates or hinders testing will have a direct impact on how successful it is in fostering productivity and cost savings.
A comprehensive and cost-effective testing strategy will include unit, integration, and functional testing. To broadly categorize, unit testing involves verifying small “units” of code, in isolation or with a few collaborating objects. In object-oriented languages, a unit of code is commonly a class, which may rely on a few other classes (collaborating objects). Unit tests are run on a developer’s machine and periodically on dedicated testing servers. Integration testing involves verifying the interaction of various application “subsystems” and is therefore conducted at a coarser-grained level. Integration tests are typically run on dedicated testing servers and not part of the developer build. Functional testing entails an even broader scope, verifying application behavior based on end-user scenarios. Like integration tests, functional tests are typically run on separate testing servers.
In the days of CORBA and EJB 2.0, even unit testing typically required deploying and running the components in a container, often with complex harnesses for setting up required infrastructure. This quickly proved to be unwieldy as time-consuming testing hindered fast, iterative development. The difficulty of conducting efficient testing became one of the major drags on developer productivity with these earlier frameworks and a hidden source of significant project cost.
Having learned from this, SCA follows in the footsteps of other IoC frameworks, most notably Spring, in its approach to unit testing. By avoiding the use of APIs in all but exceptional circumstances, unit testing SCA components is trivial: Pick your favorite test harness, such as JUnit or TestNG, and instantiate them. In other words, verifying behavior is as simple as:

Unit testing becomes slightly more involved when collaborating objects are required. Take the LoanComponent from the example presented in this chapter: It requires a CreditService. One solution would be to simply instantiate a CreditComponent, as shown previously, and pass it to the LoanComponent. This, however, can quickly become unmanageable if the CreditComponent requires other services, which themselves depend on additional services, and so on.
A better solution is to introduce a “mock” for the CreditService. Mock objects, as they are referred to, mimic specific behavior of real objects and generally have trivial implementations. A mock CreditService implementation, for example, would always return a good or bad score. Mocks are manually set on component implementations by the unit test. Components then call mocks as if they were reference proxies to real service providers.
Mock Objects and EasyMock
Writing mock objects by hand can be tedious, particularly if only one method is required for a particular test case. Several mock object generation frameworks have emerged that automate much of this process. We recommend EasyMock (http://www.easymock.org) for testing SCA components. The following example demonstrates testing the LoanComponent using a mock CreditService:

EasyMock works by first creating a mock, recording behavior (that is, the methods that will be called on it, including parameter and return values), and setting the mock into replay state before using it. In the previous example:
![]()
creates the mock service. The expected behavior, a call to the CreditService.scoreApplicant() with a return value of 700, is then recorded:
![]()
Finally, the mock service is placed in replay state:
EasyMock.replay(creditService);
after which it can be passed to the LoanComponent and invoked like the actual CreditService implementation. At the end of the test run, the unit test can verify that the mock service has been properly called by through the verify operation:
EasyMock.verify(creditService);
The efficiencies of using mocks with SCA are most evident when dealing with remotable services. When deployed to production, the LoanComponent and CreditComponent could be hosted on separate JVMs, where the SCA runtime would handle setting up the appropriate remote communications infrastructure (for example, web services). In a unit test environment, on a developer machine, deploying these components to separate containers and setting up remote communications is cumbersome. It is also unnecessary: The goal of unit testing the LoanComponent should be to ensure that it functions properly according to business requirements, not that it can communicate over a remote protocol to the CreditService. (The latter would be a goal of integration testing, which verifies that parts of a system work together.)
Investing upfront in a good testing strategy reduces overall project costs. Building on the lessons learned with CORBA and EJB, SCA was designed to facilitate efficient testing, particularly at the unit test level. When unit testing SCA components, keep three things in mind. First, don’t use a container; instantiate component implementation directly in the test case. Second, use mocks to test component implementations in isolation. And if you cannot do one and two easily, refactor your component implementation because it is generally a sign of bad design.
Summary
This chapter covered the basics of developing loosely coupled services using the SCA Java programming model. These included service contract design, asynchronous communications, and component life cycle. Many of these features—particularly asynchronous communications—have their antecedents in integration and messaging software. The SCA Java programming model provides an arguably more unified and simpler approach to distributed applications than its predecessors. In the next chapter, we extend this discussion to creating conversational services using the Java programming model.