
11. Persistence
SCA is not intended to be a platform technology. By “platform technology,” we mean a technology such as Java EE and .NET designed to cover all application development needs, from the user interface (or interfaces) to long-term data storage. Rather, SCA is concerned with what is typically referred to as the “middle-tier”: the code that comprises the bulk of an application’s processing logic.
All but the most trivial applications require some form of persistence, most commonly to a relational database; many applications also require some form of user interface. SCA does not offer its own set of solutions for the presentation and persistence tiers. Instead, the goal of the SCA authors was to make it easy to integrate with existing and emerging technologies in these areas.
Seen in this light, although covering significant ground, SCA is less ambitious than Java EE and .NET. A benefit of this approach is that developers don’t need to learn a completely new set of technologies when working with SCA. However, a major downside is that with SCA, there is no clear consensus or one way to handle presentation and persistence needs.
Indeed, a number of approaches have been taken by vendors and open source SCA implementations. In the next chapter, we take a look at how Java EE web applications can front-end SCA services. In this chapter, we focus on persistence, and in particular, how components can use JDBC and the Java Persistence API (JPA) to transactionally write data to a relational database.
Of the various ways to persist data in Java, we chose JDBC because it is ubiquitous. Our choice of JPA, however, is based on slightly different reasons. First, JPA is emerging as the primary way Java-based enterprise applications access data in a relational database. Enterprise application developers are likely to already be familiar with JPA. In addition, it is our conviction that JPA is one of the best persistence solutions available to Java developers. JPA is a standard and, more important, is widely viewed as providing an efficient and flexible approach to persistence.
Given that SCA does not provide its own persistence API, various SCA runtimes may adopt different approaches. In this chapter, we cover how to use JDBC and JPA with Fabric3. You should be aware that some SCA runtimes might not support JDBC or JPA or do so in a slightly different way. Consequently, if application portability to different runtimes is a requirement, you will need to plan carefully. To assist with this, we note throughout the chapter when a proprietary Fabric3 feature is being used. We also begin the chapter with architectural suggestions for increasing portability in the sidebar, “Architecting for Portability.”
Architecting for Portability
One of the major selling points of Java EE is application portability: Assuming a Java EE application did not use vendor-proprietary APIs, it could be deployed to any Java EE-compliant application server.
Despite the claims of avoiding “vendor lock-in,” the reality has been that Java EE has had mixed success with application portability. Vendors have often interpreted the Java EE specifications differently, resulting in different runtime behaviors. Also, despite its mandate as an enterprise technology platform, long features such as clustering are not covered by Java EE. This has resulted in vendors introducing proprietary extensions in their runtimes that hinder application portability.
To be sure, over the years Java EE has improved with respect to application portability. More features are covered and the specifications have been made clearer, thereby reducing the possibility of different interpretations. However, despite these advances, Java EE application portability still requires significant effort.
In previous chapters, we mentioned that SCA goals for portability were less ambitious. Specifically, a pragmatic decision was made to focus on skills, as opposed to application portability. SCA would initially provide a reduced level of application portability but would standardize enough so that developers would be on familiar ground when working with different SCA runtimes.
Because SCA does not standardize a persistence API, persistence is an area that presents one of the biggest challenges with respect to application portability. One strategy for dealing with this is to not use runtime-provided persistence facilities at all. In this approach, the application manages its persistence needs, perhaps by using a third-party library directly such as Hibernate or the basic JDBC facilities bundled in the JDK. The major drawback to this approach is that in enterprise scenarios, the application must handle a number of complex infrastructure concerns: for example, bootstrapping the persistence technology, connection pooling, and transactional behavior.
As an alternative, we recommend isolating the use of persistence APIs with a combination of SCA composition and the Data Access Object (DAO) pattern. When an application is ported to a different SCA runtime, these isolated areas can be replaced with another runtime-specific implementation.
A Data Access Object hides persistence details from clients and presents an interface to clients consisting of operations for querying, saving, modifying, and deleting application data. As is evident from the “object” reference in its name, the DAO pattern has been a widely used pattern in object-oriented languages. In SCA, a DAO would most likely be implemented as a local service because operations are typically fine-grained. The following example illustrates a local service that persists LoanApplication data:

The component implementation for the LoanApplicationDao could use JPA, JDBC, or some other means to persist a LoanApplication instance. A portable application would potentially have multiple implementations that were used in different SCA runtimes.
Often, applications will include multiple DAOs to handle persistence for the various data types an application may use. These DAOs can be organized into a composite or set of composites that provide persistence services to various parts of an application. The following demonstrates a composite that promotes a LoanApplicationDao and a ApplicantDao:

The previous composite configures two JPA DAOs and can be used by LoanComposite:

Besides providing a way to clean separate persistence concerns from other component configurations in the LoanComposite, creating a separate persistence composite enables the JPA-based implementation to be easily replaced if the loan application needs to be ported to an SCA runtime that does not support JPA.
Using JDBC
In this section, we cover using JDBC to access relational data. The javax.sql.DataSource API is the primary way to obtain a database connection and perform SQL operations using JDBC. In SCA runtimes such as Fabric3 that provide JDBC support, a DataSource is obtained through injection. However, instead of annotating a setter method or field with @Reference or @Property, @Resource is used. The @Resource annotation belongs to the javax.annotation package and is defined as part of the JSR-250 specification, “Common Annotations for the Java Platform.” The @Resource annotation is used by SCA to declare a reference to a resource provided by the runtime—in this case, a DataSource. Listing 11.1 shows how to inject a DataSource on a component setter method.
Listing 11.1 Injecting a DataSource Using @Resource

In the preceding example, the name attribute specified on the @Resource annotation instructs the SCA runtime to inject the DataSource named "loanDB". This DataSource is configured in a runtime-specific manner.
If the name attribute is not specified, the DataSource name will be inferred from the field or setter method according to the same rules that apply for properties and references. For example, if the name attribute were not specified in Listing 11.1, the inferred name would be "dataSource".
DataSources and Transaction Policy
Before obtaining and using a database connection object from an injected DataSource, it is necessary to take into account the transaction policy in effect for a given component. If you have used JDBC with a Java EE application server, this will be familiar. Recall in Chapter 6, “Policy,” we covered the different transaction policies that can be applied to a component implementation:
• Global managed transaction—This is the most common transaction policy associated with a component implementation. When applied to a component implementation, the SCA runtime will ensure that a global transaction is present before dispatching to a method on the component. In doing so, the SCA runtime will use a transaction propagated from the invoking client or begin a new transaction depending on whether the service implemented by the component propagates or suspends transactions. If multiple resources such as DataSources associated with different databases are used during an invocation, they will be coordinated as part of a single transaction. Consequently, all work done will either be atomically committed or rolled back as part of the transaction. This process is often referred to as a two-phase commit, or 2PC, transaction.
• Local managed transaction—When a component is configured to run with this policy, the SCA runtime will suspend any active transaction context and execute the component within its own local transaction context. Upon completion of an operation, the SCA runtime will coordinate with resources used by the component to individually commit or roll back work. This means that work involving different resources will either fail or complete independently. For example, updates to two DataSources will be performed individually: They may fail or succeed independent of one another.
• No managed transaction—Components that use this transaction policy are responsible for managing transactions. In this case, the component implementation uses the JDBC APIs to manually control when a transaction commits or rolls back. This is done using the Connection.setAutoCommit(boolean), Connection.commit(), and Connecton.rollback() methods.
Global and Local Managed Transactions
Let’s return to the DAO that persists loan application data from previous examples. In Listing 11.2, if the DAO is configured to run as part of a global managed transaction or local managed transaction, the SCA runtime will either commit or roll back changes when the update operation completes.
Listing 11.2 Using a DataSource in the Context of a Global Transaction

Because the DAO runs as part of a global transaction, it must not call Connection.commit() or Connection.rollback() because the runtime will handle that when the update operation completes successfully or throws an exception. Before returning, the only thing the DAO must do is ensure that connections are properly closed using a try...finally block.
The main differences between using DataSources in the context of local and global transactions become apparent in two cases: when multiple DataSources are used by the same component and when multiple DAOs are used by a client. We examine both cases in turn.
Consider the code in Listing 11.3, where two DataSources are accessed by the LoanApplicationJDBCDao.
Listing 11.3 Using Multiple DataSources in the Context of a Global Transaction

Because the implementation in Listing 11.3 is configured to use a global transaction, the update to the loan database done using the loanConn connection will be performed in the same transaction as the audit record insert done with the auditConn connection. Consequently, the update and insert will succeed together or be rolled back. On the other hand, if the LoanApplicationJDBCDao were annotated with @LocalManagedTransaction, the update and insert would be performed individually. In other words, they would succeed or fail independently. In this case, it would be possible for the loan application update to commit while the audit record insert is rolled back by the runtime due to an exception.
Another case where the differences between global and local managed transactions become apparent is when a client accesses two DAOs that use the same DataSource. Suppose the BigBank application has two DAOs: a LoanApplicationJDBCDao to persist loan application data and an ApplicantJDBCDao responsible for persisting applicant information. Both DAOs use the same DataSource and are invoked by LoanComponent, which is configured to use a global managed transaction, as shown in Listing 11.4.
Listing 11.4 Invoking Multiple DAOs in the Context of a Global Managed Transaction

If the LoanApplicationJDBCDao and ApplicantJDBCDao implementations are configured to use a global managed transaction, the calls to loanApplicationDao.save(..) and applicantDao.save(..) in Listing 11.4 will be performed in the same transaction context. That is, they will succeed or fail together. If, however, the DAO implementations are configured to use local managed transactions, each call will be performed independently. Figure 11.1 illustrates the difference.
Figure 11.1 Global versus local managed transactions

How does an SCA runtime guarantee “atomicity” across DataSources and components when a global managed transaction is in effect? In other words, how does it ensure that persistence operations are handled as a single unit? An SCA runtime enforces atomicity by associating a database connection object with the transaction context through the use of a transaction manager. If a global transaction is in effect, the SCA runtime will associate the JDBC Connection object returned from the first call to DataSource.getConnection() with the active transaction. Subsequent calls to DataSource.getConnection()—whether from the same component instance or other components—will return the same Connection object as long as the transaction is active. In addition, when the Connection object is returned, the runtime will enlist it with a transaction manager. If multiple DataSources are used during a transaction, their Connection objects will be enlisted with the transaction manager. Upon completion of the transaction, the transaction manager will coordinate commits across all enlisted connections, known more generally as “resources.” If an exception is encountered, the transaction manager will coordinate rollbacks across the enlisted resources. Fortunately, this work is handled transparently by the runtime. Application code does not need to worry about connection management, resource enlistment, or performing coordination.
No Managed Transaction
Component implementations may also be configured to run without a managed transaction. In this case, the implementation is responsible for managing its own transaction demarcations boundaries. This involves either setting Connection.setAutoCommit(boolean) to true, which results in all SQL statements being executed and committed as individual transactions. Otherwise, application code must explicitly call Connection.setAutoCommit(false) followed by Connection.commit() or Connection.rollback(), as shown in Listing 11.5.
Listing 11.5 Manually Managing Transaction Boundaries with a DataSource

As seen in Listing 11.5, given the added complexity associated with application managed transaction boundaries, it is generally advisable to use either globally or locally managed transactions.
Using JPA
Having covered the lower-level JDBC API, we now turn to how to use JPA with SCA components. Even though JPA was developed in response to the deficiencies of EJB Entity Beans, its object/relational mapping (O/R) approach to persistence is particularly effective in building loosely coupled, service-based architectures. Instead of JDBC’s result set model where data is presented in rows and columns, JPA deals directly with Java objects and provides facilities for mapping them to relational database tables. Although we assume some familiarity with JPA, we list its main benefits here:
• Less code—By working with objects and automating much of the mapping process to relational tables, JPA results in less application code than JDBC.
• Less complexity—JPA handles tasks such as unique ID generation, versioning (that is, guarding against overlapping updates of the same data by different clients), and entity relationships that typically require complex application code with JDBC.
• Portability—Most JPA implementations have built-in features for handling the idiosyncrasies of various databases, making code more portable.
• Performance gains—Despite the “mapping overhead,” JPA implementations can actually improve performance by supporting advanced optimizations, such as delayed flushing and operation batching, that would require complex manual coding if done using JDBC.
In this section, we will not delve into the intricacies of working with JPA. Rather, we concentrate on the specifics of using JPA with SCA, and in particular stateless services, transaction policy, and conversational interactions.
The Basics: Object Lifecycles and the Persistence Context
In JPA, an object that is persisted to a database such as a LoanApplication is referred to as an “entity.” The EntityManager API provides operations for querying, saving, updating, and deleting entities. Similar to a DataSource, an EntityManager is injected on a component instance. However, instead of using the @Resource annotation, the @PersistenceContext annotation from the javax.persistence package is used. (Why it is called “PersistenceContext” will become apparent later.)
Listing 11.6 demonstrates how the LoanComponent uses an EntityManager to persist a new LoanApplication, resulting in a database insert.
Listing 11.6 Using the EntityManager API to Persist a LoanApplication

EntityManager instances are associated with a persistence context, which is essentially an in-memory cache of changes before they are written to the database. When a component adds, modifies, or removes an entity, the entity is tracked as part of a persistence context before the changes are written to the database.
Entities can be in one of four states: new, managed, removed, or detached. A new entity is an object that has been instantiated (using the Java new operator) but has not been persisted; in other words, it exists only in memory and has not been inserted into the database. A managed entity is one that has been associated with a persistence context, typically by invoking EntityManager.persist() or retrieving it into memory via a query. A removed entity is one that is scheduled for deletion in the database. Finally, a detached entity is one that is disassociated from a persistence context.
How does an entity become detached? Consider the case of LoanComponent. When a LoanRequest is received, the component instantiates a new LoanApplication and populates its fields with values from LoanRequest. At this point, LoanApplication is considered to be in the new state. After the component invokes EntityManager.persist(), LoanApplication is associated with a persistence context and placed in the managed state. After the component has finished operating on LoanApplication and the unit of work has completed, the persistence context is closed and LoanApplication is placed in the detached state. The component may still access and manipulate the LoanApplication object, but its data is not guaranteed to be synchronized with the database. Later, the LoanApplication object may become associated with a new persistence context using the EntityManager.merge() operation. When changes tracked by the new persistence context are sent to the database, updates made to the LoanApplication object while in the detached state will be written as well.
Entity detachment and reattachment are illustrated in Figure 11.2.
Figure 11.2 Detachment and merging

Detachment occurs when either EntityManager.close() is explicitly called or a transaction completes. In JPA, this is referred to as a “transaction-scoped” persistence context. Fabric3 also supports extended persistence contexts that remain active for the duration of a conversation.
Transaction-Scoped Persistence Contexts
When injecting EntityManager, the default behavior of an SCA runtime is to associate it with a persistence context for the current transaction, commonly referred to as a “transaction-scoped” persistence context. This has two main effects. First, in the case where a client invokes local services in the context of a global transaction that is propagated, the local service providers will share a persistence context. Second, the persistence context will be flushed (that is, changes written to the database) and closed when the transaction completes. At that point, entities will be detached.
To see how this works, let’s return to the LoanComponent example. Suppose it uses two JPA-based DAOs to persist LoanApplication and LoanApplicant information. Because the DAOs abstract the use of JPA, the LoanComponent implementation remains unchanged from Listing 11.4. It uses a global transaction and invokes each DAO in turn. The implementation is listed again in Listing 11.7 for convenience.
Listing 11.7 The LoanComponent Remains Unchanged When Using JPA-Based DAOs

The main change will be in the two DAOs, which use injected EntityManagers (see Listing 11.8).
Listing 11.8 The Two JPA-Based DAOs

Because a global transaction is propagated from LoanComponent to the DAOs, the runtime will associate the same persistence context with each injected EntityManager. Changes made by one DAO will be visible to others sharing the same persistence context. Assuming the global transaction begins when LoanComponent.apply() is invoked and ends when the operation completes, the persistence context will be flushed and changes written to the database after the method returns.
Another item to note is that because the SCA runtime manages EntityManagers, application code must take care not to call JPA APIs for transaction demarcation—in particular, EntityManager.getTransaction() or any of the methods on javax.persistence.EntityTransaction.
The Persistence Context and Remotable Services
The examples thus far have dealt with interactions between local services. This is because persistence contexts are not propagated across remotable service boundaries. Persistence contexts are only shared between local services participating in the same global transaction.
Although it is possible to marshal detached entities across remote boundaries and merge them into another persistence context, this often has the effect of introducing undesired coupling between remotable services as it exposes the internal domain model (that is, the set of entities). Moreover, entities are best designed as fine-grained Java objects, which in many cases do not translate well into interoperable data types, in particular XML schema. For example, it is common to create entities that model one-to-many relationships using Java generics, as shown in Listing 11.9.

Unfortunately, Java generics, as shown in Listing 11.9, do not map well to XML schema types. This may lead to problems with interoperability if the LoanService provided by the LoanComponent is exposed as a web service endpoint. To avoid these mapping and coupling issues, entities should be translated into a format more appropriate for remote marshalling—for example, JAXB types.
JPA and Conversational Services
Using JPA with conversational services is only slightly different than with nonconversational ones. When doing so, it is important to account for detached entities. Remember, as shown back in the first listing in the sidebar “Architecting for Portability,” a persistence context is closed and associated entities detached when a transaction completes. Depending on how transaction boundaries are defined, a conversation may start and end within the span of a single transaction, or (the common case) it may be longer-lived and exist over multiple transactions. Figure 11.3 and Figure 11.4 depict short- and long-lived conversations.
Figure 11.3 A short-lived conversation

Figure 11.4 A long-lived conversation
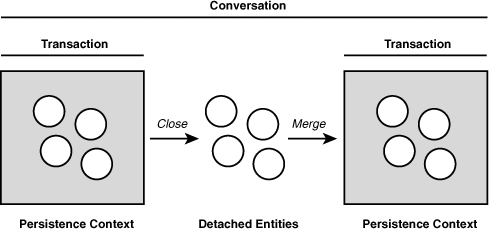
In short-lived conversations that do not span a transaction, the persistence context outlives the conversation lifetime. Consequently, component implementations need to handle detached entities.
However, with longer-lived conversations, component implementations have to take special care to reattach entities to a new persistence context. Suppose LoanService was conversational, with apply and updateContactInfo operations. Further, for illustration purposes, assume LoanComponent implementing the service persists LoanApplication entities using JPA directly instead of DAOs. If each operation was called in the context of a different transaction, LoanComponent must ensure that LoanApplication was merged with the persistence context, as shown in Listing 11.10.
Listing 11.10 Merging Persistence Entities

After apply is called, entityManager will be flushed and changes (that is, the new loan application) applied to the database. In addition, the persistence context will be closed and the application object detached. Subsequent calls to updateContact will therefore need to reattach the application object by calling EntityManager.merge(). When updateContact returns, the runtime will flush and close the persistence context.
Extended Persistence Contexts
In conversational interactions, it is often desirable to extend the scope of the persistence and have it remain active for the duration of a conversation, as opposed to the lifetime of a transaction. Persistence contexts tied to the lifetime of a conversation are termed “extended persistence contexts.” Figure 11.5 depicts an extended persistence context.
Figure 11.5 Merging persistence entities
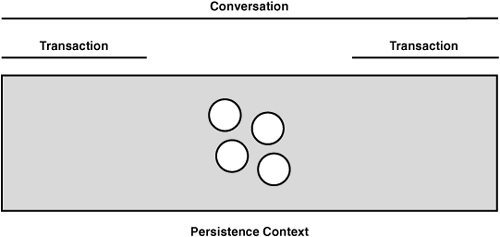
The main benefit of extended persistence contexts is that reattachment does not need to be done. This simplifies code and saves the expense of a merge operation. Extended persistence contexts are specified by setting the type attribute of @PersistenceContext to javax.persistence.PersistenceContextType.EXTENDED. Listing 11.11 shows how this is done. Note also that the call to EntityManager.merge() from Listing 11.10 has been removed because it is no longer needed.
Listing 11.11 An Extended Persistence Context

If each operation (for example, apply and updateContactInfo) were invoked in different transaction contexts, the persistence context would be flushed multiple times as each transaction completed. However, the persistence context would remain open. Assuming the end operation was annotated with @Ends Conversation, the extended persistence context would be closed only when it was invoked.
Accessing the EntityManagerFactory
To access EntityManagerFactory instead of an EntityManager, a component implementation can use the @PersistenceUnit annotation. For example, the LoanApplicationJPADao can be rewritten to use the EntityManagerFactory, as shown in Listing 11.12.
Listing 11.12 Injecting an EntityManagerFactory

Accessing the Hibernate API with Fabric3
At times, it is useful to be able to access the proprietary APIs of a JPA provider. As an alternative to EntityManager, Fabric3 provides access to the Hibernate org.hibernate.Session object. To utilize it, use the @PersistenceContext annotation, substituting Session for EntityManager.getDelegate(), as shown in the following excerpt:

Summary
This chapter has dealt with one of the most important aspects of application development: persistence. In particular, we have covered how to effectively use JDBC and JPA with SCA. The next chapter completes this application development picture by explaining how SCA integrates with Java EE web technologies, specifically servlets and JSPs.