
Chapter 3: Delta – The Foundation Block for Big Data
In the previous chapters, we looked at the trends in big data processing and how to model data. In this chapter, we will look at the need to break down data silos and consolidate all types of data in a centralized data lake to get holistic insights. First, we will understand the importance of the Delta protocol and the specific problems that it helps address. Data products have certain repeatable patterns and we will apply Delta in each situation to analyze the before and after scenarios. Then, we will look at the underlying file format and the components that are used to build Delta, its genesis, and the high-level features that make Delta the go-to file format for all types of big data workloads. It makes not only the data engineer's job easier, but also other data personas including ML practitioners and BI analysts benefit from the additional reliability and consistency that Delta brings. It is no wonder that it is poised to serve as a foundational block for all big data processing.
In this chapter, we will cover the following topics:
- Motivation for Delta
- Demystifying Delta
- The main features of Delta
- Life with and without Delta
Technical requirements
The following GitHub link will help you get started with Delta: https://github.com/delta-io/delta. Here, you will find the Delta Lake documentation and QuickStart guide to help you set up your environment and become familiar with the necessary APIs.
To follow along this chapter, make sure you have the code and instructions as detailed in this GitHub location: https://github.com/PacktPublishing/Simplifying-Data-Engineering-and-Analytics-with-Delta/tree/main/Chapter03
Examples in this book cover some Databricks specific features to provide a complete view of capabilities. Newer features continue to be ported from Databricks to the Open Source Delta. (https://github.com/delta-io/delta/issues/920)
Let's start by examining the main challenges plaguing traditional data lakes.
Motivation for Delta
Data lakes have been in existence for a while now, so their need is no longer questioned. What is more relevant is the specifics of the solution's implementation. Consolidating all the siloed data by itself does not constitute a data lake. However, it is a starting point. Layering in governance makes the data consumable and is a step toward a curated data lake. Big data systems provide scale out of the box but force us to make some accommodations for data quality. Age-old aspects of transactional integrity were compromised on a distributed system because it was very hard to maintain ACID compliance. Due to this, BASE properties were favored. All of this was moving the needle in the wrong direction and from pristine data lakes we were moving toward data swamps, where the data could not be trusted and hence insights that were generated on the data could not be trusted either. So, what is the point of building a data lake?
Let's consider a few common scenarios that are increasingly hard to resolve on any big data system:
- Multiple jobs read and write to the same table concurrently. Consumers build reports based on the same data and do not wish to see partial, incomplete, or bad data at any time.
- Recovering from a data pipeline failure on account of any reason, including human error, transient infrastructure glitches, insufficient resources, or changing business needs. It is easy to fix and retry the job, but it is much harder to clean up the mess that's created to a consistent state so that the retry can proceed.
- Lots of small files are produced, say, from a streaming workload, causing performance issues.
- A few big files can cause data skew and jobs to fall behind their expected schedules.
- A carefully selected and reviewed schema has been left tainted, leading to data corruption and unreadable data.
- Big data systems are designed to work with large datasets, but there is an occasional need to do fine-grained deletes and updates or merges. This needle in a haystack scenario is very prevalent in GDPR use cases, for instance.
- Recovering from a data pipeline failure, such as an error in the pipeline being detected, may require a rollback to a few days prior instantly so that new ingestions can proceed.
Different data types need to be handled differently, which is how different types of data platforms came into existence. For example, an ML platform's requirements are very different from a streaming platform's. In the next section, we will look at the primary ones and see if we can generalize towards a unified data platform.
A case of too many is too little
Data needs over the years have evolved. Many companies/organizations start with a data warehouse, then invest in a data lake, then need a machine learning platform, and then use a separate system to handle streaming needs. Very soon, this complexity gets out of hand, and stitching these fragile systems increases the end-to-end latency, which means that the quality of the data suffers as it is moved around multiple times. Here, the company/organization needs to be on a single platform that can handle a majority of these data needs and must resort to a specialized system in rare cases when it is truly warranted.
Being on a next-generation data platform means that all your data personas can be accommodated with their choice of tools and preferences – these personas include data engineers, data scientists, data analysts, and DevOps personnel. They typically work in one of the following three areas at various levels of sophistication:
- BI reporting and dashboarding
- Exploratory data analysis and interactive querying
- Machine learning at various levels of sophistication
The following diagram shows an example of a utopian data platform that accommodates the needs of all data personas and every use case that they work on:

Figure 3.1 – Unified data platform
Platforms are shells on top of data formats and data query engines. The better the data format, the more performant the engine that's built on top will be and the more robust the platform housing it. So, it suffices to say that the underlying data protocol and format is an important consideration. Wouldn't it be nice to have a single data format in the open protocol that can support an organization's needs for batch, streaming, reporting, and machine learning needs?
Data silos to data swamps
Data lakes help avoid the need for data silos. However, inadequate governance can turn them into data swamps. The following diagram is a perfect analogy of the swings where we may start with a data silo. If we swing too hard, we may find ourselves in a data swamp, which is just as bad, if not worse:

Figure 3.2 – Data silos can easily turn into data swamps
A data silo is an isolated source of data that is only accessible to a single line of business (LOB) or department. It leads to inefficiencies, wasted resources, and obstacles in the form of incomplete data profiles and the inability to construct deep insights. Let's examine the reasons why data silos are created in the first place as it is important to understand what to avoid:
- Structural: An app built for a specific purpose where data sharing is not a core requirement.
- Political: A sense of proprietorship over a system's data so that it is not readily shared with others, either on account of the data being sensitive or the team being possessive.
- Growth: Newer technology that is incompatible with existing systems and datasets, leading to siloed systems.
- Vendor Lock-In: Technology vendors gate data access to customers, so once you've invested in the technology of that vendor, it is very difficult to wiggle free and the technical baggage carries over.
On the other hand, a data swamp is a large body of data that is ungoverned and unreliable. It is hard to find data and even harder to use it, which is why it's often used out of context. This is the opposite of data silos in the sense that the data is there and has been brought together, but because it has been done without adequate process and policy, it is as good as not being there. That would be a wasted investment. So, how can we ensure our data silos evolve into data lakes and instead of ending up as data swamps, blossom into data reservoirs?
Characteristics of curated data lakes
Curated data lakes build upon four pillars that have a direct impact on insight generation. They are as follows:
- Reliability: Data consistency accelerates the pace of innovation as data personas have more time to focus on the use case instead of grappling with data reconciliation and quality issues.
- Performance: A performant system translates directly into a lower total cost of ownership (TCO) with a simple architecture that is easy to develop and maintain.
- Governance: Access to data based on privileges is necessary for regulatory compliance because a single security breach can cause permanent long-term credibility damage.
- Quality: Improving data quality improves the quality of insights.
In the previous chapter, we explored various file formats and concluded that binary formats with good compression and flexible schema handling are ideal candidates for big data systems. Parquet is an established format and Apache Spark operations are optimized on it. However, there are several inadequacies for which complex solutions have been built on top of Parquet that are both difficult to develop and maintain. Let's look at some of these inadequacies in the context of the following concepts:
- DDL and DML operations
- Schema evolution
- Unifying batch and streaming workloads
- Time travel
- Performance
We will take up the challenges that arise in each of these areas when we discuss the main features of Delta. But first, let's look at its DDL and DML capabilities and understand the underlying format to appreciate the thought process that inspired its creation.
DDL commands
The data definition language (DDL) includes commands that allow you to create and drop a database or table. Let's take a look.
CREATE
With Parquet, you must run the REPAIR TABLE command to force statistics to be computed before the ingested data can be made visible via SELECT queries. This is not needed for Delta. The following example shows this action when using a Parquet table:
- Load data into a Parquet table from a given path:

- Read the data right after the ingestion shows 0 records in the table:
SELECT COUNT(*) FROM some_parquet_table
Let's understand why the count shows 0 records right after ingestion. There are two paths to be aware of – one is the data path that's identified by dataPath and the other is the metastore path for some_parquet_table. This has to do with a strategy called schema on read, which was popularized by Hadoop and other NoSQL databases to make the ingestion process super flexible, allowing any schema to be written. Here, the onus of sorting the mess was pushed downstream to the consumers. This is in sharp contrast to most of the traditional relational database technologies, where the schemas were strictly enforced and followed the schema on write paradigm. The schema is checked when the data is written, so if there is a discrepancy, it throws an error and it is detected right at the source during the ingestion process.
MetaStore ChecK (MSCK) helps update the metastore datapaths with the counts so that subsequent queries will see the right number of records. The following steps show how to run the MSCK command:
- Run the REPAIR TABLE command to update the metastore data:
MSCK REPAIR TABLE some_parquet_table
- The following SELECT query will now show the correct record count:
SELECT COUNT(*) FROM some_parquet_table
There is no need to run the REPAIR TABLE command when you're working with the Delta format. So, here, you get the benefit of schema on read, which is additional schema flexibility, thus allowing the schema to evolve and grow over time. It helps support the ELT path, where you keep the original data as-is and load the data before fully comprehending all the fields or are forced to drop fields to comply with predefined schemas. This is especially important for semi and unstructured data types. So, performing the preceding steps in Delta looks as follows:

This helps you avoid issues when developers forget to run MSCK and see incorrect data counts, which means you spend less time debugging. Delta takes that pain away by giving you correct counts right away and eliminates the need for you to use administrative commands such as MSCK to repair the table. In the next section, we will examine Delta in the context of DML commands.
DML commands
DML stands for data manipulation language. Operations such as UPDATE, DELETE, and others qualify as DML statements.
APPEND
The same repair table problem is encountered when appending data. The counts of the new records will require similar treatment. This applies to partition names as well since they are also a part of the metadata. Let's see how seamless this would be with Delta:

Using append operations is a strong pattern in big data on account of new information constantly being added. Although updates are less common, they are also an important pattern and need to be handled efficiently to satisfy common CRUD operations when existing data needs to be updated, corrected, or deleted altogether.
UPDATE
Update operations are crucial to CRUD operations when you need to perform basic data manipulation commands but are not supported in Parquet format. It is supported on Delta. The following code snippet demonstrates an error scenario where non-Delta tables are being used:
UPDATE parquet_table SET field1 = 'val1' WHERE key = 'key1'
This will throw an error that states Error in SQL statement: AnalysisException: UPDATE destination only supports Delta sources.
Now, let's try the same query but this time on a Delta table:
UPDATE delta_table SET field1 = 'val1' WHERE key = 'key1'
Similar to the previous query, this query is honored and the number of rows that have been affected is returned as num_affected_rows.
DELETE
Like UPDATE, delete operations are not supported in Parquet but they are supported in Delta. This simple operation has several applications and it is especially critical for GDPR compliance, where as an organization, you are expected to respond swiftly to a customer's request to delete all their personal information across all tables over the entire time range that you have been collecting information in the data lake. The following code snippet demonstrates the error scenario when non-Delta tables are used:
DELETE FROM parquet_table WHERE key = 'key1'
This preceding code will throw an error that states Error in SQL statement: AssertionError: assertion failed: No plan for DeleteFromTable. The same operation, when performed on a Delta table, will be honored:
DELETE FROM delta_table WHERE key = 'key1'
Here, the same query that we used previously is honored and the number of rows affected is returned as num_affected_rows.
MERGE
More complex data operations include handling MERGE commands as a single step as opposed to multiple steps. A merge operation is sometimes referred to as an upsert, which is a combination of an update and an insert in a single operation. This is especially useful for handling slowly changing dimensions (SCD) operations where the dimension table data is either overwritten or maintained with history. Merging involves a target table and an incoming source table where the two are joined on a match key. Depending on the match result, records can be added, updated, or deleted in the target table. There can be any number of WHEN MATCHED and WHEN NOT MATCHED clauses, as shown in the following snippet:

In this section, we looked at all the data operations that would not only benefit from using Delta but also be greatly simplified. For example, there is no need to remember to run MSCK commands, nor worry about an occasional fat finger operation that corrupts data in one pipeline and destroys the pristine quality of the target data lake that several stakeholders read from. Delta allows us to maintain a single pipeline, so there is no need to maintain separate batch and streaming pipelines, nor worry about schemas growing out of control. In the next section, we will look under the covers to see what components go into creating the Delta protocol and give it its superpowers.
Demystifying Delta
The Delta protocol is based on Parquet and has several components. Let's look at its composition. The transaction log is the secret sauce that supports key features such as ACID compliance, schema evolution, and time travel and unlocks the power of Delta. It is an ordered record of every change that's been made to the table by users and can be regarded as the single source of truth. The following diagram shows the sub-components that are broadly regarded as part of a Delta table:
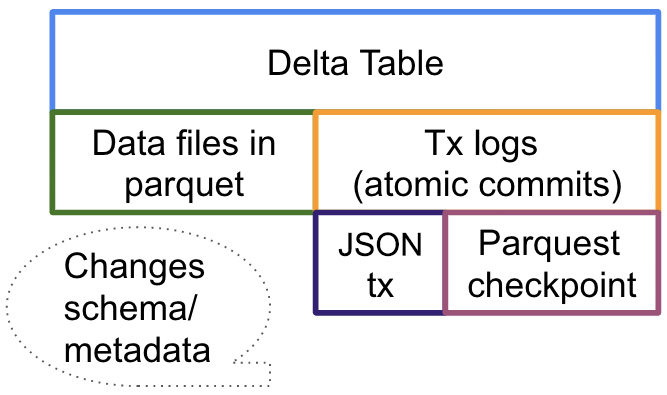
Figure 3.3 – Delta protocol components
The main point to highlight is that metadata lies alongside data in the transaction logs. Before this, all the metadata was in the metastore. However, when the data is changing frequently, it would be too much information to store in a metastore, and storing just the last state means lineage and history will be lost. In the context of big data, the transaction history and metadata changes are also big data by themselves. A metastore still holds some basic metadata details but most of the meaty details are in the transaction log.
Format layout on disk
Both the data and the metadata are persisted on disk. Let's look at their formats more closely:
- Data remains in open Parquet format. This binary columnar format is excellent for analytic workloads:
- If data is partitioned, each partition appears as a folder.
- Transaction details are in a _delta_log directory and provide ACID transactions:
The following diagram shows what a table that's been partitioned on the partition1 column would look like if it happened to be a Delta table:

Figure 3.4 – Delta file layout on disk
If you are examining the files on disk, one quick way to check if a data path or table is Delta or not is to look for the presence of a _delta_log folder underneath the main data path. A non-Delta table does not have this folder.
In this section, we examined the components that comprise Delta. In the next section, we will look at the main reusable macro features that aid the creation of robust data pipelines. These features can be viewed as design blueprints. Only if the underlying format and protocol support them can they be leveraged as-is. Other systems that do not support Delta will have to write additional code to ensure these capabilities are created; in Delta, they come out of the box.
The main features of Delta
The features we will define in this section are equivalent to weapons in an arsenal that Delta provides so that you can create data products and services. These will help ensure that your pipelines are built around sound principles of reliability and performance to maximize the effectiveness of the use cases built on top of these pipelines. Without any more preamble, let's dive right in.
ACID transaction support
In a cloud ecosystem, even the most robust and well-tested pipelines can fail on account of temporary glitches, reinforcing the fact that a chain is as strong as its weakest link and it doesn't matter that a long-running job failed in the first few minutes or the last few minutes. Cleaning up the subsequent mess in a distributed system would be an arduous task. Worse still is the fact that partial data has now been exposed to consumers who may use it in their dashboards or models to arrive at wrong insights and trigger incorrect alarms. Thankfully, Delta, with its ACID properties, comes to the rescue. This capability refers to the fact that either the entire job succeeds or it fails, leaving no debris behind.
Delta does this using Reader Writer isolation capabilities. This means that while an ingest is happening, the partial data is not yet visible to any consumer. So, if that workload fails, no damage is done and the job can be retried. This also has other benefits. For example, multiple writers could be running workloads writing to the same table independently. Here, a hiccup in one of them wouldn't corrupt all the data in that table, nor would it affect the other workloads.
There is no special construct specification. This capability comes out of the box and helps ensure data quality so that the insights that are generated on top of them are sound as well.
Schema evolution
In the previous chapter, we emphasized the need to undergo a data modeling exercise to fully understand the data before rushing to implement your use case on top of it. As part of this exercise, the underlying schema is established and data pipelines are constructed around it. These well-defined and well-curated schemas will evolve. Some fields will get added, others modified, and yet others dropped. We do want to accept and adapt to some of these changes, especially early on in the pipeline, and we may want to have a stricter lockdown further down the pipeline. This requires having different knobs to turn at different points in the pipeline. In the early landing stages, you want to be more flexible and in the curated zones, you want the schema to be specified explicitly to prevent it from breaking your data contracts with your consumers.
This is where Delta's mergeSchema property comes in handy. By default, it is off, so making changes to the existing schema will throw an error. You can turn it on so that it's more flexible:
option("mergeSchema", "true")or
spark.databricks.delta.schema.autoMerge.enabled
It allows you to make compatible changes, such as redefining an INT field as a STRING field, upcasting a field, adding new fields, and more. However, it does not allow incompatible changes to be made, such as turning a text field into a float.
Another check that helps with data governance is the concept of enforcing constraints. This automatically verifies the quality and integrity of new data that's been added to a Delta table:
- The NOT NULL constraint ensures that those specific columns always contain data.
- The CHECK constraint ensures that the Boolean expression evaluates to true for each row:
ALTER TABLE <table> ADD CONSTRAINT validDate CHECK (dt > '2022-01-01');
Running DESCRIBE DETAIL or SHOW TBLPROPERTIES on the Delta table will list all the constraints. The DROP CONSTRAINT command can be used to drop an existing constraint.
Databricks Delta has built an edge feature called Delta Live Tables, where you can declaratively build a pipeline. The expect operator is used to expose the expectations on these constraints so that actions can be taken, such as dropping data or failing the pipeline.
Unifying batch and streaming workloads
The Lambda architecture advocates managing two streams of workloads – one batch and the other streaming. This has its fair share of challenges concerning data reconciliation. The Kappa architecture challenges the need to maintain two pipelines and instead proposes maintaining a single streaming pipeline where batch is a special case of streaming. Delta adopts this stance and unifies both batch and streaming pipelines. Some people may argue that their need is batch, so why venture into streaming?
Note that business owners have an increasing appetite for real-time insights and the number of streaming workloads continues to rise. The tunable processing trigger dial allows you to easily transition, for example, from a 24-hour interval to a 5-minute interval. This way, the workload is designed only once and maintained as a single set instead of two. There are some bookkeeping activities that structured streaming constructs automatically take care of that can benefit a batch operation. For example, keeping track of the processed files using a checkpoint location takes the onus from the data engineer to the platform.
Time travel
There are times when we need to create a snapshot of a dataset to run a repeatable workload and this can either be a data engineering or a machine learning workload. We end up making copies of copies and then forgetting what the source was, which leads to unnecessary storage and wasted cycles recreating the lineage. At times, a processing change or human error may occur that causes bad data to enter production tables. Here, we need a quick way to identify the affected records and roll them back so that data can be reprocessed correctly. In a big data system, it is very hard to do this.
Thankfully, Delta provides a time travel capability out of the box to do just this. Every batch or micro-batch operation that's performed on the data is automatically given a version and a timestamp. So, instead of maintaining multiple copies of the data in different tables, you can use the same table and provide a version number or timestamp to reference the relevant dataset. So, if multiple people are building models to compare, they all have the same view of the data and hence the model comparison is consistent.
The following code demonstrates using the time travel capabilities of Delta using the TIMESTAMP AS OF, VERSION AS OF constructs in both SQL and the DataFrame API commands:

All of these are additional value features that Delta brings to the table out of the box. However, if these are not executed in a performant manner, then the value will not be fully realized in a big data ecosystem. In the next section, we will look at the additional performance benefits that accompany Delta.
Performance
All the data reliability features we mentioned previously will not be as useful if access to them is not performant. Delta enjoys all the advantages of Parquet and several more features such as data skipping, Z-Order, and delta cache. Unlike RDBMS systems, there are no secondary indices in big data systems, which primarily rely on partitions to reduce large data scans. However, a table cannot have too many partitions; at most, it can have around three because each partition works as a sub-folder. This works well for date and categorical fields, but it is not well suited for high cardinality columns such as ZIP codes.
Data skipping
The data skipping feature comes out of the box with Delta and is orthogonal to partition pruning and can work alongside it. It can be applied to query scenarios of the column op literal format. It is sometimes referred to as I/O pruning and works by maintaining column-level statistics. All the data operations that are applied to the table use these statistics during query planning time to skip files and avoid wasted I/O.
Z-Order clustering
Currently, this is a Databricks Delta feature. Z-Order involves using a clustering approach and can be layered on top of data skipping to make it even more effective. Data in Delta tables can be physically altered using a built-in command called OPTIMIZE. It can be applied to the entire table or certain portions, as specified in a WHERE clause. For example, if there is a rolling duration of 2 months that users query, there is no need to optimize the entire table. This is effective when the workload consists of equally frequently related single-column predicates on different columns. The Z-Order syntax is as follows:
OPTIMIZE <table> [WHERE <partition_filter>]
ZORDER BY (<column>[, …])
Delta cache
Currently, this is a Databricks Delta feature. In Spark, caching is done at the RDD or DataFrame level by calling cache() or persist().
Delta offers file-based caching for Parquet files. This means that a remote file, once fetched, can be cached on the worker nodes (provided it supports NVMe/SSD) for faster access. The results of the query are cached as well. The following three configurations are handy in this regard:
- spark.databricks.io.cache.maxDiskUsage: This specifies the reserved disk space in bytes per node for cached data.
- spark.databricks.io.cache.maxMetaDataCache: This specifies the reserved disk space in bytes per node for cached metadata.
- spark.databricks.io.cache.compression.enabled: This is used if the cached data is stored in a compressed format.
Caching can be turned on and off and can be controlled explicitly for SELECT queries:
CACHE SELECT column_name[, column_name, ...] FROM [db_name.]table_name [ WHERE boolean_expression ]
Now that we have established the benefits of Delta, let's look at how easy it is to convert your existing workloads into Delta.
Life with and without Delta
The tech landscape is changing rapidly, with the whole industry innovating faster today than ever before. A complex system is hard to change and is not agile enough to take advantage of the pace of innovation, especially in the open source world. Delta is an open source protocol that facilitates flexible analytic platforms as it comes prepackaged with a lot of features that benefit all kinds of data personas. With its support for ACID transactions and full compatibility with Apache Spark APIs, it is a no-brainer to adopt it for all your data use cases. This helps simplify the architecture both during development as well as during subsequent maintenance phases. Features such as the unification of batch and streaming, schema inference, and evolution take the burden off DevOps and data engineer personnel, allowing them to focus on the core use cases to keep the business competitive.
It is very easy to create a Delta table, store data in Delta format, or convert it from Parquet into Delta in place. For non-Parquet formats such as CSV or ORC, a two-step process needs to take place. This consists of converting the data into Parquet format and then into Delta, as follows:

The following table demonstrates the ease of creating a Delta table by comparing it with the standard way of using the Parquet format:

Table 3.1 – Creating a Delta table compared to using Parquet
If you have existing Parquet tables, they can be converted in place into Delta format, as shown here:

Table 3.2 – Converting existing Parquet tables into Delta tables
At the beginning of this chapter, we introduced a few problematic scenarios. Let's revisit them to see how Delta addresses each one:
- Multiple jobs read and write to the same table concurrently. Consumers build reports on the same data and do not wish to see partial, incomplete, or bad data at any time:
- Delta provides Reader Writer isolation, which means that until a write is completely done, no consumer sees any of the partial data and if one of the ingestion pipelines fails, it does not affect the other pipelines. This means that multiple pipelines can write to a single table concurrently and not step on each other.
- Recovering from a data pipeline failure on account of any reason, including human error, infrastructure transient glitches, insufficient resources, or changing business needs. It is easy to fix and retry the job, but it is much harder to clean up the mess that's created to a consistent state so that the retry can proceed:
- Delta's ACID transactions ensure that either everything succeeds or nothing gets through. This ensures there is no mess to clean up afterward.
- Lots of small files produced, say, from a streaming workload, causing performance issues:
- Operations such as OPTIMIZE help with file compaction.
- A few big files can cause data skew and jobs to fall behind their expected schedules:
- Splitable file formats and repartitioning strategies help with large file issues.
- A carefully selected and reviewed schema left tainted, leading to data corruption and unreadable data:
- Disciplined schema evolution controls help determine when to allow or disallow changes to the underlying schema, allowing only the benign and necessary merges while controlling the undesirable ones from corrupting consumption layer tables.
- Big data systems are designed to work with large datasets, but there is an occasional need to do fine-grained deletes and updates or merges. This needle in a haystack scenario is very prevalent in GDPR use cases, for instance:
- Updates, deletes, and merges are provided as atomic operations in the Delta format, allowing for painless modifications to be made to data at scale.
- Recovering from a data pipeline failure, such as an error in the pipeline being detected, may require a rollback to a few days prior instantly so that new ingestions can proceed:
- Time travel allows you to easily roll back the dataset using either a timestamp or a version number to control where to rewind to.
In the next section, we will look at the role of Delta as a foundational piece for the Lakehouse architecture, which promotes diverse use cases on top of a single view of data in an open format, allowing multiple tools of the ecosystem to consume it.
Lakehouse
Lakehouse is a new architecture and data storage paradigm that combines the characteristics of both data warehouses and data lakes to create a unified basis for all types of use cases to be built on top of it. There is no need to move data around. Data is curated and remains in an open format and serves as the single source of truth (SSOT) for all the consumption layers. A modern data platform has needs that span traditional data warehouses, data lakes, machine learning systems, and streaming systems and there is some overlap among these systems. A Lakehouse offers features that span all four systems, as shown in the following diagram:
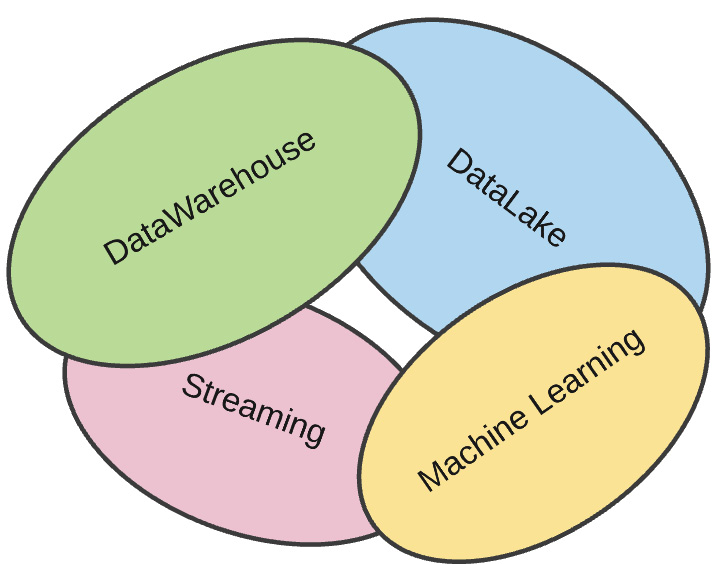
Figure 3.5 – The common use cases in a Lakehouse borrow the leading characteristics from disparate data systems
It imbibes the structure and governance that's inherent to data warehouses, the flexibility and cost-effectiveness of data lakes, the low latency and high resiliency of streaming systems, and the ability to run different ML tools and frameworks. Sometimes, the streaming and ML components are considered to be part of the data lake, so it is usually termed as the best of breed of data lakes and data warehouses.
The following diagram captures the high-level characteristics of a Lakehouse architecture and shows how the data stack is built up:

Figure 3.6 – Delta is the foundational block for a Lakehouse
A data lake can help break a data silo, but by itself, it is not a Lakehouse. Delta is the most important ingredient as it forms the foundational layer that allows each of these characteristics. Together with security and governance, the full potential of the architecture is unleashed.
Characteristics of a Lakehouse
The following diagram summarizes the essential characteristics of a Lakehouse architecture and how the various components stack up, with each layer adding a critical feature to support the layer on top. For example, the bottom-cloud storage layer offers scalability and affordability that the data format layer, with its transactional capabilities, is layered on. The execution engine is the driver for high performance and feature execution and is what the security and governance layers rely on. The topmost layer is where the applications of diverse workloads are brought to fruition. The primary characteristics of a Lakehouse are as follows:
- Transaction support
- Schema enforcement and governance
- BI support
- Storage is decoupled from compute
- Openness
- Support for diverse data types ranging from unstructured to structured data
- Support for diverse workloads
- End-to-end streaming:

Figure 3.7 – Lakehouse example
The Databricks platform is an example of a Lakehouse architecture – the bottom-most layer represents cloud storage, where data resides in Parquet format; right beside it is the Delta protocol; the Delta Execution engine brings in the optimizations, governance is achieved via the Unity catalog; secure data sharing is achieved via Delta sharing; and the diverse workloads are built right on top, covering all the aspects of data engineering, data science, BI, and AI.
By eliminating the need to maintain both a data warehouse and a data lake, there are efficiencies in resource utilization and a direct cost reduction. Some of the immediate benefits of a Lakehouse architecture are the unification of BI and AI use cases. BI tools can now connect directly to all the data in the data lake by pointing the query engine at it. There is reduced data and governance redundancy by eliminating the operational overhead of managing data governance on multiple tools.
However, there are a few notes of caution:
- What should we do with existing data warehouses? In Chapter 7, Delta for Data Warehouse Use Cases, we will look at this in detail as we compare and contrast the use cases that are built on these different data platforms.
- Are the tools mature and unified? Hundreds of enterprises are using this as part of their production architecture, thereby proving it is ready for prime time.
- Are we moving toward a monolith again? Not really – this is a paradigm and can be used as a blueprint for different lines of business to create a data mesh of lakes or hub and spoke models with the central hub offering core capabilities and the spoke refining their definitions, thereby reusing administrative and governance definitions of the hub with the flexibility to refine their business-specific implementations.
The following diagram captures the challenges of traditional data lakes in four categories – that is, reliability, performance, governance, and quality:
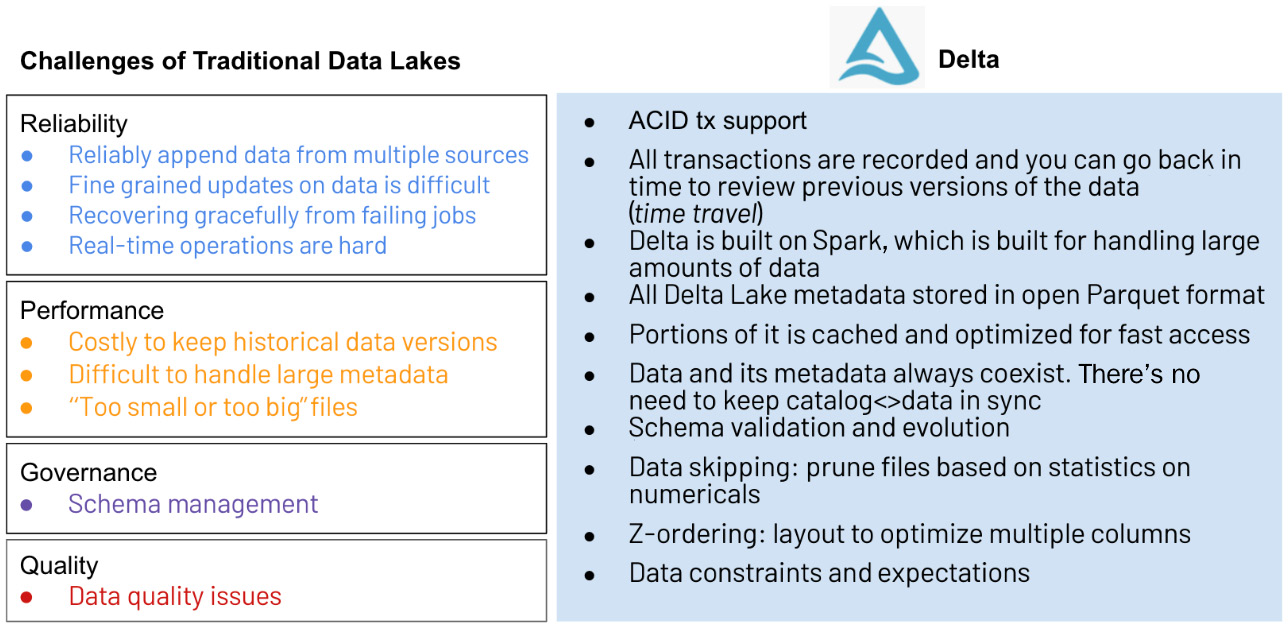
Figure 3.8 – Challenges of traditional data lakes that Delta addresses
The right-hand side of the preceding diagram lists the characteristics of the Delta protocol that help address these gaps and pave the path toward simplification and innovation, all while keeping the openness of the format and API to avoid getting into a vendor lock-in trap. In the following chapters, we will examine each in more detail.
Summary
Delta helps address the inherent challenges of traditional data lakes and is the foundational piece of the Lakehouse paradigm, which makes it a clear choice in big data projects.
In this chapter, we examined the Delta protocol, its main features, contrasted the before and after scenarios, and concluded that not only do the features work out of the box but it is very easy to transition to Delta and start reaping the benefits instead of spending time, resources, and effort solving infrastructure problems over and over again.
There is great value when applying Delta to real-world big data use cases, especially those involving fine-grained updates and deletes as in the GDPR scenario, enforcing schema evolution, or going back in time using its time travel capabilities.
In the next chapter, we will look at examples of ETL pipelines involving both batch and streaming to see how Delta helps unify them to simplify not only creating but maintaining them.