
SharePoint 2010 is built on a comprehensive object model, supplying powerful features to access and manipulate internal data. This chapter introduces the SharePoint object model. The remaining chapters contain many useful scenarios and examples of what can be achieved via the object model—principally by extending, or customizing, the default behavior to suit your needs.
There are several quite diverse approaches to programming SharePoint, depending on your project's requirements, which we will explore.
Visual Studio 2010 with SharePoint 2010 has greatly improved the support for testing and debugging. We introduce the new features and show how to handle basic and more advanced everyday tasks.
At a glance, this chapter contains
An architectural overview
An introduction to the object model and its hierarchical view
The technical integration with ASP.NET
The building blocks, their design, and integration with the SharePoint platform
The administrative model
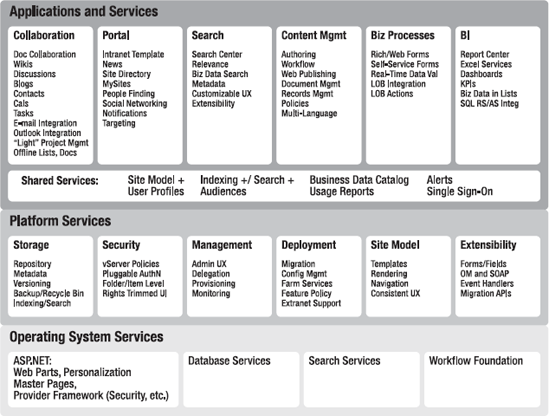
SharePoint consists of an amazing number of tools, functions, and modules (see Figure 2-1).
Because SharePoint is a set of products and technologies, we call it a platform. Its main function is the creation, organization, and rapid retrieval of information in the form of data and documents. Its presentation mode of web sites and pages is commonly used to build intranet and extranet portals. With particular support for team sites and public-facing Internet sites (plus many more predefined sets of web pages), it's a great platform for web-based applications. The close integration with the Microsoft Office System expands the handling of everyday tasks.
With SharePoint 2010 we see a stable, mature, scalable, well-supported product that is easy to integrate with other systems. For example, it integrates well with Outlook and all the other Office products, and with instant messaging via Office Communications Server. The refurbished data access layer can easily connect to line-of-business (LOB) applications, provided from companies such as SAP (www.sap.com).
With a few exceptions, this book focuses on SharePoint Foundation—the platform on which all SharePoint products and SharePoint-enabled products are built. The foundation, formerly called Windows SharePoint Services, extends Windows Server System with a set of features for team collaboration and knowledge distribution. The foundation is built on ASP.NET 3.5 and is the basis for both a powerful application programming interface (API) and a highly scalable and reliable platform.
Note
In this book we use the simple term SharePoint. By this we mean both SharePoint Foundation and SharePoint Server (see the following discussion). If we describe a feature available exclusively in SharePoint Server, we express this explicitly. Because SharePoint Foundation is a subset of SharePoint Server, we usually do not explicitly talk about SharePoint Foundation.
We treat SharePoint as a platform and framework. As you know, you can do many things just by configuring the server and activating whatever you need. A big feature of SharePoint is enabling ordinary people to build and maintain a complex web site without programming knowledge. However, this limitation is eventually reached. Each SharePoint site typically includes libraries, lists, calendars, tasks, announcements, and the like. Each of these is simply a highly customized instance of a basic list. Each list has its own distinct set of columns and views to create the UI. Events are used to launch actions when a specified condition is met. Organizing data is based on the concept of content types, which allows you to store different kinds of documents in the same library while keeping some structure. It is a bridge and partially a compromise between the typically unstructured world and highly structured storage, such as a relational database.
SharePoint Server comes in two flavors: Standard and Enterprise. The Enterprise edition includes extra features for enterprises, such as web content management functions (including publishing), single sign-on (SSO) to integrate with other portals, and record management—supporting storage of sensitive documents with an emphasis on security and audit trails.
Rendering InfoPath forms as HTML extends the forms environment to the Web. Accessing LOB applications integrates external data into the portal. Many new site templates have been added, enabling administrators to create common sites for their companies with ease.
With all this power, it seems unlikely that you would ever need to extend the platform to add more features. However, our experience says you will. While SharePoint has so many features, the result is that people accomplish far more than they had ever expected with the product. The confidence this instills results in more people trying more things with the platform, some of which are not natively supported. This is the nature of all software systems created to be a platform or framework. They handle the common functionality (with a little configuration), but do not do everything. The advantage is that you get 80 percent of the solution done with minimal effort, and the remaining 20 percent can be built to suit the customer's requirements.
In this book we focus on the "20 percent" and demonstrate how to work with the API and its counterparts to achieve it. The amazing thing is that the platform extensibility is endless. Even books with thousands of pages will not be able to describe SharePoint completely. (We have tried, and yet this is still scratching the surface!) We describe many real-world examples from our experience, demonstrating specific strengths of SharePoint. Our aims are to broaden your expectations of SharePoint's capabilities and empower you to do more with less.
Before learning to customize SharePoint, first you need a basic understanding of its internals. SharePoint is built on top of ASP.NET and Internet Information Services (IIS). It makes heavy use of the ASP.NET extensibility model to customize the default behavior. It not only reveals the power of ASP.NET, but it also adds a new level of web programming to ASP.NET.
IIS also plays a key role. The performance, reliability, and security of each SharePoint page are the responsibility of IIS.
When you see IIS mentioned in this book, we're referring to IIS 7 running on Windows Server 2008 or later. IIS 7 provides tight integration with ASP.NET to maximize performance. To explore this further, let's start with ASP.NET.
In general terms, ASP.NET is a request-processing engine. It takes an incoming request and passes it through its internal pipeline to an endpoint, where you as a developer can attach code to process that request. This engine is completely separate from the HTTP runtime and the web server. In fact, the HTTP runtime is a component that you can host in your own applications outside of IIS or any other server-side application. The integrated development server within Visual Studio is a good example of an implementation that is independent of and unrelated to IIS. (SharePoint, on the other hand, runs on top of both IIS and ASP.NET.)
The HTTP runtime is responsible for routing requests through the ASP.NET pipeline. The pipeline includes several interrelated objects that can be customized via subclassing or through interfaces, making ASP.NET highly adaptable. Most of the extensibility points are exploited by SharePoint—demonstrating that there are very few limits when using ASP.NET.
Through the extensibility mechanism, it's possible to hook into such low-level interfaces as authentication, authorization, and caching.
The Internet Services API (ISAPI) is a common API. The ASP.NET engine interfaces with IIS through an ISAPI extension. On x64 Windows it is 64 bit, but it can run in mixed mode using the WoW64 (Windows-32-on-Windows-64) technique. Regarding SharePoint, you don't need to worry about the bits—it is 64 bit–only either way.
The ISAPI extension hosts .NET through the ASP.NET runtime. The ASP.NET engine is written entirely in managed code, and all of the extensibility functionality is provided via managed code extensions. The impressive part of ASP.NET is that it is very powerful but simple to work with. Despite its breadth and complexity, accomplishing your desired outcomes is easy. ASP.NET enables you to perform tasks that were previously the domain of ISAPI extensions and filters on IIS. ISAPI is a low-level API that has a very spartan interface. Typical .NET developers would find it difficult to develop anything on top of this interface. Writing ISAPI filters in C++ is not included in most current application-level development. However, since ISAPI is low level, it is fast. Thus, for some time ISAPI development has been largely relegated to providing bridge interfaces to other applications or platforms. But ISAPI did not become obsolete with the appearance of ASP.NET.
ISAPI provides the core interface from the web server, and ASP.NET uses the unmanaged ISAPI code to retrieve input and send output back to the client. The content that ISAPI provides is passed using common objects, such as HttpRequest and HttpResponse, that expose the unmanaged data as managed objects. Back in the .NET world, it is very easy to use these objects in your own code. Regarding SharePoint, you should know that it already extends ASP.NET in several ways. Changing the behavior or adding more extensibility code can work, but quite possibly it will disturb the internal behavior and make things worse. Here is where the SharePoint object model comes into focus, as it will protect you from doing foolish things with the flow of data.
The purpose of ISAPI is to access a web server such as IIS at a very low level. The interface is optimized for performance, but it's also very straightforward. ISAPI is the layer on which the ASP.NET engine is built. Understanding the relationship between ISAPI and ASP.NET aids in getting the most out of ASP.NET and subsequently your SharePoint applications. For ASP.NET the ISAPI level is just acting as a routing layer. The heavy lifting, such as processing and request management, occurs inside the ASP.NET engine and is mostly performed in managed code. Hence, SharePoint has a strong influence on how things proceed up and down the pipeline.
You can think of ISAPI as a type of protocol. This protocol supports two flavors: ISAPI extensions and ISAPI filters. Extensions act as a transaction interface; they handle the flow of data into and out of the web server. Each request coming down the pipeline passes through the extensions, and the code decides how the request is treated. As you might imagine, ASP.NET is one such extension. ASP.NET has several ways to give you as much control as possible to hook into this extension and modify the default behavior. The low-level ISAPI interfaces are now available as high-level .NET interfaces, named IHttpHandler and IHttpModule. This is very powerful while still providing good performance, because it's a well-written balance between lean access to the lower level and an easy-to-use high-level API.
As with any other ISAPI extension, the code is provided as a DLL and is hooked into the IIS management. You can find this DLL at <.NET FrameworkDir>aspnet_isapi.dll.
SharePoint 2010 is not built on ASP.NET 4.0. Rather, the DLLs are built against the .NET Framework 3.5. It is important to note that the ASP.NET version number does not necessarily match the development cycle of the .NET Framework. While ASP.NET 3.0 and 3.5 were released with the corresponding framework, the DLLs and modules they consist of remained at version 2, at least regarding ASP.NET. ASP.NET 3.x was only a 2.0 revival with many new features supplied as add-ons. SharePoint 2010 now uses the Ajax features provided by the .NET Framework 3.5. The new assemblies providing Ajax features have internal version numbering schema beginning with 3.5. This sounds confusing, and it actually is a mess, but it is as it is.
The IIS 7 integrated pipeline is a unified request-processing pipeline. Each incoming request is handled by this pipeline and routed through the internals of IIS. The pipeline supports both managed and native code modules. You may already know about creating managed modules based on the IHttpModule interface. Once implemented and hooked into the pipeline, such a module receives all events used to interact with the request passing through the pipe.
But what does the term unified request-processing pipeline mean? IIS 6 provided two different pipelines: one for native code, and on top of it, one for managed code. This was for historical reasons, because the managed code world arrived after IIS was first designed. In IIS 7, both pipelines are combined to become the unified request-processing pipeline.
For ASP.NET developers, this has several benefits:
The integrated pipeline raises all exposed events, enabling existing ASP.NET modules to work in the integrated mode.
Both native and managed code modules can be configured at the web server, web site, or web application level.
Managed code modules can be invoked at certain stages in the pipeline.
Modules are registered and enabled or disabled through an application's
web.configfile.
The configuration of modules includes the built-in ASP.NET managed code modules for session state, forms authentication, profiles, and role management. Furthermore, managed code modules can be enabled or disabled for all requests, regardless of whether the request is for an ASP.NET resource such as an ASPX file or a static file like an image.
Invoking modules at any stage means that this may happen before any server processing occurs for the request, after all server processing has occurred, or anytime in between.
IIS 7 and its architecture are crucial for SharePoint. A thorough understanding of the basic functions provided by IIS is a requirement for serious developers. One of these basic concepts is the relationship between sites and virtual directories.
Sites
IIS 7 has a formal concept of sites, applications, and virtual directories. Applications and virtual directories are separate objects, and they exist in a hierarchical relationship. It's a simple top-down approach. A site contains one or more applications, and each application contains one or more virtual directories. An application can be something running in IIS or something that extends IIS. Managed code applications form an -application domain that spans all virtual directories in it.
An IIS (web) site is an entry point into the server. The site is an endpoint that consists of an address, a protocol, and a handler that handles the request. The handler can be recognized as a path to an application. The protocol used by the endpoint is HTTP. The address is the configured IP address in conjunction with a defined port. For a web server, the standard port is 80. A site is bound to some sort of protocol. In IIS 7, bindings can apply to any protocol. The Windows Process Activation Service (WAS) is the service that makes it possible to use additional protocols. WAS removes the dependency on HTTP from the activation architecture. This is useful for technologies that provide application-to-application communication in web services over standard protocols. The Windows Communication Foundation (WCF) programming model is one such technology that can enable communication over the standard protocols of Transmission Control Protocol (TCP), Microsoft Message Queuing (MSMQ), and Named Pipes. This lets applications that use communication protocols take advantage of IIS features, such as process recycling, rapid fail protection, and configurations that were previously only available to HTTP-based applications.
Behind the scenes, the DNS (Domain Name System) protocol acts as a resolver to convert a human-readable address (such as www.apress.com) into a machine-level IP address (such as 66.211.109.45).
Note
We strongly recommend investigating how DNS works for simple requests made from a browser to a server. However, this is beyond the scope of this book. Wikipedia has a very good explanation.
The DNS is able to forward the human-readable address to the endpoint. IIS can use the human-friendly hostname to resolve the address directly to the application. This technique is referred to as using a host header. To explain this with an example, consider two web sites, such as intranet.apress.com and extranet.apress.com. If the same server is configured to handle both sites and only one IP address is available on the network card, the DNS can't completely resolve incoming requests for both web sites. In that situation you can configure IIS to handle those addresses as host headers. The request containing the address as a header is forwarded and used to reach the right target. SharePoint uses this to provide multiple webs. Ports map in SharePoint to applications while host headers resolve this to the outside world. Host headers inform IIS what full server name is used (e.g., http://app1.mydomain.com or http://app2.mydomain.com). Both domains running on the same IIS server share the same IP address and port. The host header (app1 or app2) is forwarded to the IIS server, which resolves this by routing the request to different applications.
Applications
An application is a group of files that delivers content or provides services over protocols, such as HTTP. When you create an application in IIS, the application's physical path becomes part of the site's URL. In IIS 7, each site must have at least a root application. However, a site can have more than one application. In addition to belonging to a site, an application belongs to an application pool, which isolates the application from applications in other application pools on the server. In the case of managed code applications, each application pool is running the .NET Framework version that your application requires.
No matter whether a port number, an IP address, a combination of both, or a host header is used, at the end of the day the request is forwarded to a URL space. This is like a pool for all incoming requests of a specific type. A complete URL consists of the protocol moniker, the address portion, and the path to a resource (e.g., http://intranet.apress.com:12683/Default.aspx). To access resources, each such entry point maps to a physical folder on the file system of the server. In the most basic scenario—which applies if SharePoint is not yet involved—IIS simply reads the resource file from disk and delivers it to the client. If this fails, the common HTTP error 404 is returned. Delivering a resource means that the content is loaded into memory and streamed to the client.
IIS is responsible for authentication, too. The options are anonymous access, Basic authentication, and Windows authentication based on NTLM (NT Lan Manager) or Kerberos. Each web site can be configured differently. This is done by a stack of modules that handle incoming requests.
In addition to the direct mapping of an endpoint's address to a physical path to a file, IIS has the concept of virtual directories.
Virtual Directories
A virtual directory is a directory name (a sequence of which is better known as path) that you specify in IIS and map to a physical directory on a server. The directory name then becomes part of the application's URL. Users can request the URL from a browser to access content in the physical directory, such as your SharePoint application. If you specify a different name for the virtual directory than the physical directory, it is more difficult for users to discover the actual physical file structure. Moreover, SharePoint creates a complete virtual structure of paths that don't exist physically anymore.
In IIS 7, each application must have a virtual directory, which is called the root virtual directory, and which maps the application to the physical directory that contains the application's content. Regarding SharePoint, this is the directory you find in the C:inetpubwwwrootwssVirtualDirectories folder. However, an application can have more than one virtual directory. By default, IIS uses configuration from web.config files in the physical directory to which the virtual directory is mapped, as well as in any child directories within.
That means a virtual directory is always a child instance of an already defined URL space. It extends the root address, such as in http://intranet.apress.com:12683/mysites/Default.aspx.
In this address, the /mysites portion could be a virtual directory. Each virtual directory can be configured to point to a different physical path from the one defined for the root web site. In doing this, you hide the physical structure behind the undisclosed mapping between URL addresses and actual file locations. Since ASP.NET is tightly integrated with IIS, there are several options to extend this behavior. One approach is the Virtual Path Provider (see the "Virtual Path Provider" section later in the chapter). This provider is an abstract layer between physical storage of files and the virtual path to the resources. Using this feature, SharePoint stores the resources in a database while IIS behaves as if the files are still in the file system.
When a request arrives, IIS checks for the file extension mapping and routes the request to the associated extension. In the case of ASP.NET, we assume that the request is something like default.aspx, so it's routed to aspnet_isapi.dll (see Figure 2-2).
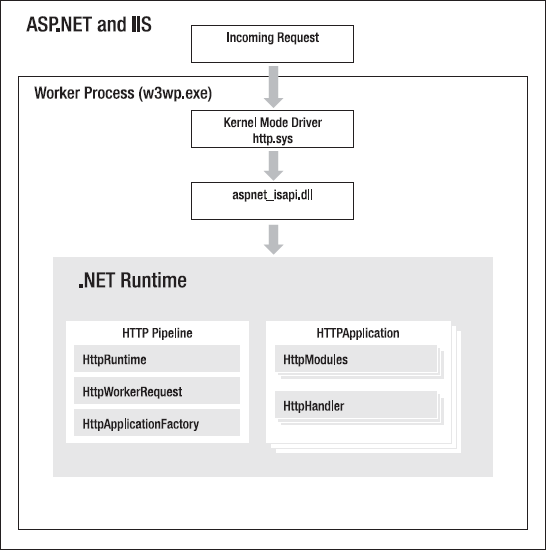
We assume that you have already worked with and configured the application pool. The application pool was introduced with IIS 6 to allow the complete isolation of applications from each other. This means that IIS is able to completely separate things happening in one application from those in another. Keeping applications together in one pool can still make sense, because another pool creates its own worker process, and (as shown in Figure 2-2) will use more resources.
Separate applications make the web server more reliable. If one application hangs, consumes too much CPU time, or behaves unpredictably, it affects its entire pool. Other application pools (and the applications within them) will continue to run. In addition, the application pools are highly configurable. You've already learned that the .NET Framework version can be different for each pool, which is very useful for migration scenarios. You can configure the security environment by choosing the impersonation level and customizing the rights given to a web application. Application pools are executables that run just like any other program. This makes them easy to monitor and configure.
Although this does not sound very low level, application pools are highly optimized to talk directly to the kernel mode driver, http.sys. Incoming requests are directly routed to the pool attached to the application. At this point you may wonder where InetInfo is gone. It is still there, but it is basically just an administration and configuration service. The flow of data through IIS is as direct as possible, straight from http.sys to the application pools. http.sys is the basic driver that represents the TCP/IP protocol stack. This is one reason why IIS 7 is much faster and more reliable than any preceding version.
An IIS 7 application pool also has intrinsic knowledge of ASP.NET, and in turn ASP.NET can communicate with the new low-level APIs that allow direct access to the HTTP cache APIs. This can offload caching from the ASP.NET level directly into the web server's cache, which also dramatically improves performance.
In IIS 7, ISAPI extensions run in the application pool's worker process. The .NET runtime also runs in this same process, and thus communication between the ISAPI extension and the .NET runtime runs in-process, which is inherently more efficient.
ASP.NET's extensibility is the means by which SharePoint adds its own features. Extensibility is handled at several levels. This section provides a brief introduction.
Tip
To read more about the extensibility model, we recommend the book ASP.NET Extensibility, by Jörg Krause (Apress, 2009).
IIS 7 web server features fit into one of two categories:
Similar to the ISAPI filter in previous IIS versions, a module participates in the processing of each request. Its role is to change or add content to the request. Examples of some out-of-the-box modules in IIS 7 include authentication modules, compression modules, and logging modules.
A module is a .NET class that implements the System.Web.IHttpModule interface and uses APIs in the System.Web namespace to participate in one or more of ASP.NET's request-processing stages. We explained the stages of this pipeline in Chapter 1.
By contrast, a handler, similar to the ISAPI extension in previous IIS versions, is responsible for handling requests and creating responses for specific content types. The main difference between modules and handlers is that handlers are typically mapped to a particular request path or extension, whereas modules treat every incoming request. They also support the processing of a specific resource to which that path or extension corresponds. Handlers provided with IIS 7 include ASP.NET's PageHandlerFactory, which processes ASPX pages, among others. This kind of handler is a .NET class that implements the ASP.NET System.Web.IHttpHandler or System.Web.IHttpAsyncHandler interface. It uses APIs in the System.Web namespace to produce an HTTP response for the specific content it creates.
Modules
ASP.NET is tightly integrated with IIS 7. Even though it's possible to run ASP.NET with any host, thanks to its modular architecture, you should keep in mind that IIS is the best platform by design. Extending and customizing ASP.NET is only possible with a good understanding of IIS and its parts.
Microsoft changed large parts of the architecture of IIS 7 compared to previous versions. One of the major changes was the greatly enhanced extensibility. Instead of a powerful but monolithic web server, with IIS 7 there is now a web server engine to which you can add or remove components. These components are called modules.
Modules build the features offered by the web server. All modules have one primary task—processing a request. This can become complicated, however, as a request isn't just a call for a static resource. Rather, it can also include authentication of client credentials, compression and decompression, and cache management.
IIS comes with two module types:
Native Modules
Native modules perform all the basic tasks of a web server. However, not all modules manage common requests. It depends on your installation and configuration as to whether a module is available and running. Inside IIS 7 are
HTTP modules
Security modules
Content modules
Compression modules
Caching modules
Logging and diagnosing modules
Integration of managed modules
Managed Modules
Several managed modules are available in IIS if ASP.NET is installed. They include modules for authorization, authentication, and mapping, and service modules that support the data services.
Handlers
While modules are low level and run against every inbound request to the ASP.NET application, HTTP handlers focus more on a specific request mapping. This is usually a mapping of a file extension.
HTTP handler implementations are very simple in concept, but having access to the HttpContext object enables enormous versatility. Handlers are implemented through the IHttpHandler interface, or its asynchronous counterpart, IHttpAsyncHandler. The interface consists of a single method, ProcessRequest, and a single property, IsReusable. The asynchronous version has a pair of methods (BeginProcessRequest and EndProcessRequest) and the same IsReusable property. The vital ingredient is ProcessRequest, which receives an instance of the HttpContext object. This single method is responsible for handling a web request from start to finish.
However, simple does not imply simplistic. As you may know, the regular page-processing code and the web service–processing code are implemented as handlers. Both are anything but simple. Their power originates from the HttpContext object, which has access to both the request information and the response data. This means that, like a web server, a handler can control the whole process on its own. Whatever you want to implement on the level of specific mapping is achievable using handlers.
Providers are software modules built on top of interfaces or abstract classes that define the façade for the application. The interfaces constitute seams in the architecture, which allow you to replace providers without affecting other modules. For instance, the data access provider enables access to any kind of data storage, including databases from different vendors. Hence, the provider model encapsulates the functionality and isolates it from the rest of the application.
Because almost all the major parts of ASP.NET are built using providers, there are multiple ways of modifying the internal behavior. Providers are responsible for the extensibility of ASP.NET. Creating your own providers gives you the ability to construct a sophisticated architecture that others might use—and to alter its behavior without disturbing internal processing. Consider an application such as SharePoint 2010, which is an ASP.NET application and a framework that others use as a foundation for their applications. A similar extensibility concept is supplied on this level. Providers build the core technology on which all of this is based.
When you work with providers for the first time, you may find that writing or extending a provider can be a complicated task. Due to the constraints of compatibility and transparency toward other modules, there is often no other option but to extend an internal interface. You may still need to decide whether or not to write your own provider model. This section gives you the information you need for making that decision.
Recall what the provider model was designed for:
It makes ASP.NET both flexible and extensible.
It's robust and well documented.
It provides a common and modern architecture for your application.
It's part of a multitier architecture.
The provider model does not consist only of simple provider modules. At the top level of the model are services. Services, in ASP.NET, is a generic term for separate modules, such as Membership, Site Maps, and Profiles. Almost all of them are replaced in SharePoint to achieve the specific functions. These are all high-level components, which make your life as a developer easier. Almost all of these services need some kind of data storage or at least a communication channel. From the perspective of a multitier application, the service should be independent of the particulars of data persistence.
The provider sits between the service layer and the data store layer (Figure 2-3). Modifying the provider allows the service to use a different data store or communication channel without changing the service functionality. From the perspective of the user, this architecture is transparent.

In addition, the provider is a readily configurable module. You can usually change the provider by editing the web.config file or by setting properties in base classes.
The extensibility of parts of the web.config file is not limited to configuring providers. Using the base classes within the System.Configuration namespace, you can create custom sections and handle them directly. If the settings defined in <AppSettings> are too limited for your application's needs, you can extend them.
The first step is to add a reference to the System.Configuration.dll assembly and the System.Configuration namespace. Creating a new project of the class library type for the new configuration definition is not required, but is recommended. This makes the code reusable and easier to test and deploy. Before you create a section like this, it's worth examining the anatomy of a configuration section.
The configuration section is based on the implementation of two abstract classes, ConfigurationSection and ConfigurationElement. ConfigurationSection is a parent of ConfigurationElement that makes it easy to create hierarchies of sections that contain elements on each level. The concrete ConfigurationSection is defined at the top of the web.config file:
<configSections>
<sectionGroup name="system.web.extensions" type="...">
<sectionGroup name="scripting" type="...">
<section name="scriptResourceHandler" type="..."
requirePermission="false" allowDefinition="MachineToApplication"/>
<sectionGroup name="webServices" type="...">
<section name="jsonSerialization" type="..." requirePermission="false"
allowDefinition="Everywhere" />
<section name="profileService" type="..." requirePermission="false"
allowDefinition="MachineToApplication" />
<section name="..." requirePermission="false"
allowDefinition="MachineToApplication" />
<section name="roleService" type="..." requirePermission="false"
allowDefinition="MachineToApplication" />
</sectionGroup>
</sectionGroup>
</sectionGroup>
</configSections>The type attributes are empty for the sake of clarity. They contain the fully qualified assembly names of the type that holds the configuration definition. The top-level element, <sectionGroup>, defines in which group the new element appears:
<sectionGroup name="system.web.extensions">
The section <system.web.extensions> is thus defined as the location for all subsequent groups or elements, or any combinations of groups and elements. You can define exactly what appears there simply by implementing the base classes mentioned previously.
Complex sites with hundreds of pages are difficult to maintain. For some sections, a file structure with static data seems to be more productive, whereas other sections are composed dynamically from databases. This difference should be indiscernible to regular users and search engines alike. Search engines follow each link on a page and find the navigation paths through a site, indexing the content of each page on the way. Users bookmark pages and return directly to them later. However, neither of these behaviors are what developers are expecting when creating pages.
The Virtual Path Provider is designed to separate the internal and external structures. Like any other provider, it works transparently, using a pluggable approach. The difference is that the Virtual Path Provider does not access a database by default, and internally it's different from all the providers described so far. However, to implement a Virtual Path Provider, you'll have to inherit and implement an abstract base class—VirtualPathProvider.
A custom implementation usually uses the provider model. In this case it's rather different. There is no default provider, which means that each page is handled at its physical location. Implementing a Virtual Path Provider is all about changing the default behavior of the path resolution for a web site. SharePoint makes heavy use of this technique, because the pages that are at least partially stored in the database require a distinct way to pull them out at the right time.
The Virtual Path Provider is responsible for answering a request for a resource that ASP.NET assumes to be somewhere in the file system. Usually it is. However, the response consists not of a physical path, but of a stream of bytes (that make up the requested content). ASP.NET does not care about the source of the bytes. All files handled through the page's life cycle, including master pages and user controls, are loaded through a Virtual Path Provider.
After the introduction of ASP.NET as the basic layer, which SharePoint is based on, you'll find that there are a lot of extensions and customization. Quite often you'll find that SharePoint and its API provide neat solutions for common tasks. To program against the API, it's important to know when and why SharePoint has implemented its own features.
SharePoint integrates with ASP.NET at the level of an IIS web site. What SharePoint calls a web application is actually an IIS web site. Within Central Administration you'll find several ways to create, extend, or delete a web application. The connection between an IIS web site and a SharePoint web application is very close. It's not only for naming purposes, of course. SharePoint needs to route all incoming requests to its own runtime to handle them. However, that's not all it's about. SharePoint is a highly scalable and manageable platform. Creating a SharePoint web application means it can spread over several servers that constitute a web farm. That involves several instances of IIS running on these servers, and all of them need to be managed from one single point. Changing the settings using Central Administration mirrors the configuration and settings of all the IIS instances running across the farm. This step requires sufficient rights to perform the desired action—though the need to do so may be infrequent. Once at least one web application is created, several other levels to organize applications are provided, such as the creation of subsites.
The basic structure of a SharePoint application might include site collections and sites, and consequently a hierarchy of them. Adding custom code to sites or site collections or extending sites and site collections by application pages does not require you to touch either the web site within IIS or the web application within Central Administration. You may be struggling with the term application, as it appears at several levels in the hierarchy with different meanings. In this book we focus on the programmer or software developer. For these, a SharePoint application is a couple of ASP.NET pages, called application pages, that manifest as a part of a SharePoint site. That includes at least one SharePoint web application and in turn at least one IIS site that must exist. But it does not require you to program against these.
To create a web application, use Central Administration or the stsadm command-line tool or the corresponding PowerShell cmdlets.
Note
Both PowerShell and stsadm.exe are part of the distribution and are used for automation. See Chapter 5 for more details.
You can create a web application either by converting an existing IIS web site or by building a new one from scratch. If it is a new one, SharePoint takes care of creating the required parts with IIS and spreading the settings across the farm. This is necessary since incoming requests have to be routed initially to the ASP.NET runtime. However, the default configuration does not know about all the file extensions used by SharePoint. As even SharePoint does not know about these yet, the routing forwards all requests. Instead of requests just being mapped to file extensions such as .aspx and .ashx, virtually all requests are routed to the ASP.NET runtime. This means that SharePoint can handle .docx and similar extensions.
The integration of ASP.NET with SharePoint starts with the use of the custom HttpApplication object, SPHttpApplication. This class is deployed in the Microsoft.SharePoint.dll assembly. The declarative expression of an application in ASP.NET is the global.asax file. Its code usually derives from HttpApplication. SharePoint changes the web application's global.asax to the following:
<@Application Inherits="">
As shown previously, several modules and handlers are responsible for handling incoming requests. SharePoint takes the same approach, but with a dramatic twist. It firstly eliminates all the default ASP.NET handlers and modules and replaces them with its own. The following snippet is taken from a site's web.config file. It shows that SharePoint replaces several modules to handle incoming requests.
<modules runAllManagedModulesForAllRequests="true">
<remove name="AnonymousIdentification" />
<remove name="FileAuthorization" />
<remove name="Profile" />
<remove name="WebDAVModule" />
<add name="SPRequestModule" preCondition="integratedMode"
type="Microsoft.SharePoint.ApplicationRuntime.SPRequestModule,
Microsoft.SharePoint, ..." />
<add name="ScriptModule" preCondition="integratedMode"
type="System.Web.Handlers.ScriptModule, System.Web.Extensions, ..." />
<add name="SharePoint14Module" preCondition="integratedMode" />
<add name="StateServiceModule"
type="Microsoft.Office.Server.Administration.StateModule,
Microsoft.Office.Server, ..." />
<add name="PublishingHttpModule"
type="Microsoft.SharePoint.Publishing.PublishingHttpModule,
Microsoft.SharePoint.Publishing, ..." />
</modules>For the sake of clarity, some parts of the fully qualified assembly names have been removed.
SPHttpHandler and SPRequestModule are the classes used to handle incoming requests. First of all, both are required to initialize the SharePoint runtime. However, digging deeper you'll find that SharePoint still uses the default ASP.NET modules. Web configuration files build a hierarchy. Subsequent web.config files might add additional modules. That's exactly what happens with SharePoint sites. The central web.config file is augmented with the private modules and handlers that are positioned at the top of the pipeline. Each incoming request is handled there first. SharePoint adds some of the default handlers back into the pipeline. That means that the basic behavior of ASP.NET is still present. The initialization ensures that the API is accessible and the SharePoint object model is ready to operate.
It's helpful to get a basic idea of which modules and handlers are available with SharePoint and which have been replaced by custom variations. The global (machine-wide) web.config file contains the following section:
<configuration>
<system.webServer>
<handlers>
<clear />
<add name="PageHandlerFactory-Integrated" path="*.aspx"
verb="GET,HEAD,POST,DEBUG" type="System.Web.UI.PageHandlerFactory"
preCondition="integratedMode" />
<add name="ScriptHandlerFactory" verb="*" path="*.asmx"
preCondition="integratedMode"
type="System.Web.Script.Services.ScriptHandlerFactory,
System.Web.Extensions, ..." />
<add name="SimpleHandlerFactory-Integrated" path="*.ashx"
verb="GET,HEAD,POST,DEBUG" type="System.Web.UI.SimpleHandlerFactory"
preCondition="integratedMode" />
<add name="StaticFile" path="*" verb="*" modules="StaticFileModule"
resourceType="Either" requireAccess="Read" />
</handlers>
</system.webServer>
</configuration>The handlers are sufficient for application pages and web services used by the client features. As you can see from the namespaces, none of these handlers are specific to SharePoint. A step further into a specific application it looks quite different. The web.config file that is responsible for a specific site has another set of handler assignments:
<handlers>
<remove name="StaticFile" />
<remove name="OPTIONSVerbHandler" />
<remove name="WebServiceHandlerFactory-Integrated" />
<remove name="svc-Integrated" />
<add name="svc-Integrated" path="*.svc" verb="*"
type="System.ServiceModel.Activation.HttpHandler, System.ServiceModel, ..."
preCondition="integratedMode" />
<add name="OwssvrHandler" scriptProcessor="C:Program FilesCommon
FilesMicrosoft SharedWeb Server Extensions14isapiowssvr.dll"
path="/_vti_bin/owssvr.dll" verb="*"
modules="IsapiModule" preCondition="integratedMode" />
<add name="ScriptHandlerFactory" verb="*" path="*.asmx"
preCondition="integratedMode"
type="System.Web.Script.Services.ScriptHandlerFactory,
System.Web.Extensions ..." />
<add name="ScriptHandlerFactoryAppServices" verb="*" path="*_AppService.axd"
preCondition="integratedMode"
type="System.Web.Script.Services.ScriptHandlerFactory, ..." />
<add name="ScriptResource" preCondition="integratedMode" verb="GET,HEAD"
path="ScriptResource.axd"
type="System.Web.Handlers.ScriptResourceHandler,
System.Web.Extensions,.../>
<add name="JSONHandlerFactory" path="*.json" verb="*"type="System.Web.Script.Services.ScriptHandlerFactory,
System.Web.Extensions, ..."
resourceType="Unspecified" preCondition="integratedMode" />
<add name="ReportViewerWebPart" verb="*" path="Reserved.ReportViewerWebPart.axd"
type="Microsoft.ReportingServices.SharePoint.UI.WebParts.WebPartHttpHandler,
Microsoft.ReportingServices.SharePoint.UI.WebParts, ..." />
<add name="ReportServerProxy" verb="*" path="_vti_bin/ReportServer"
type="Microsoft.ReportingServices.SharePoint.Soap.RSProxyHttpHandler,
RSSharePointSoapProxy, ..." />
<add name="ReportBuilderProxy" verb="*" path="_vti_bin/ReportBuilder"
type="Microsoft.ReportingServices.SharePoint.Soap.ReportBuilderHttpHandler,
RSSharePointSoapProxy, ..." />
<add name="ReportViewerWebControl" verb="*"
path="Reserved.ReportViewerWebControl.axd"
type="Microsoft.Reporting.WebForms.HttpHandler,
Microsoft.ReportViewer.WebForms, ..." />
</handlers>For the sake of clarity and readability, some of the fully qualified assembly names are shortened (as noted by ...). The crucial information here is what kind of handlers are being removed from the stack and which are added to handle the respective requests. Ignoring the various handlers responsible for reporting features (see Chapter 18 for more information), you can see that the handlers do not add anything specific here for common requests.
Whereas the basic configuration is on top of ASP.NET, SharePoint goes a step further and adds its own section to the web.config file. The extensibility model of ASP.NET allows such private configuration sections while still using the web.config file as the single point of configuration. If you plan to add your own custom pages, modules, handlers, Web Parts, and so on, it's strongly recommended to adopt the same tactic and extend the configuration model for tight integration within the infrastructure. In the section "The Configuration Model" earlier in the chapter, we explained the basics. SharePoint is doing exactly this. The web.config file's basic structure contains two SharePoint-specific sections (apart from various others that pertain to ASP.NET). First is the client section that is responsible for the heavily used JavaScript-based client components:
<microsoft.sharepoint.client>
<serverRuntime>
<hostTypes>
<add type="Microsoft.SharePoint.Client.SPClientServiceHost,
Microsoft.SharePoint, Version=14.0.0.0, Culture=neutral,
PublicKeyToken=71e9bce111e9429c" />
</hostTypes>
</serverRuntime>
</microsoft.sharepoint.client>Second are the server-side configuration sections:
<SharePoint> <SafeMode /> <WebPartLimits /> <WebPartCache /> <WebPartControls /> <SafeControls />
<PeoplePickerWildcards /> <WorkflowServices /> <MergedActions /> <BlobCache /> <ObjectCache /> <RuntimeFilter /> </SharePoint>
The sections WorkflowServices and ObjectCache are new in SharePoint 2010. The runtime reads the values provided within the attributes and subelements of the sections. Some of them, such as SafeMode, support developers and have an impact on the applications running within SharePoint. We'll look into this several times in this book—whenever it's necessary to configure code.
Accessing the local file system has some limitations; in particular, it's hard to combine parts of files into one dynamically. Using a database, at least one like SQL Server, can overcome many of the drawbacks. However, storing pages in the database requires a different way to retrieve them at the right time. In the "Virtual Path Provider" section we explained the basics and the advantages of a custom path provider. The customized version in SharePoint is named SPVirtualPathProvider. It's initialized during the pipeline request using the SPRequestModule's Init method. The Virtual Path Provider is responsible for resolving predefined path tags, such as ˜MASTERURL, ˜SITE, ˜CONTROLTEMPLATES, ˜LAYOUTS, and ˜SITECOLLECTION, as well as the file tags DEFAULT.MASTER and CUSTOM.MASTER.
In addition, the page parser ASP.NET uses to parse and eventually compile pages is inherited by another SharePoint-specific class, SPPageParserFilter. This class passes compilation instructions to the regular page parser. You can add settings to the web.config file to change the behavior.
The SPVirtualPathProvider, along with its siblings, handles one of the basic concepts of SharePoint: ghosting. Ghosting is an optimization feature that is used to improve the performance when scaling out pages across a farm. Understanding how ghosting works is necessary if you want a broad understanding of SharePoint.
Ajax is a base technology used everywhere in SharePoint. You can use it in your own projects as well. This section introduces Ajax and some basic information to enable you to understand several examples in this book that use this technology.
Ajax (Asynchronous JavaScript and XML) is a technology to retrieve data from a server directly from a web page without sending a form. The underlying techniques are old and well known. But they were dormant for some time before they were recognized as a powerful additional method to program web pages. Several frameworks were created to simplify adoption of Ajax by developers. (One such framework is Microsoft ASP.NET AJAX, formerly known under the code name Atlas.) With .NET 3.5, the framework on which SharePoint 2010 is built, the library is part of the main distribution, and there are no additional steps required to use the related controls.
The term Ajax is one you may hear in relation to the Web 2.0 phenomena, such as RSS feeds, blogs, and social web sites. Ajax is used by almost all of those web sites to makes them easier to use and encourage the users to stay longer. This is especially important if one is working with such a site every day or several times a day. If the site is slow and hard to use, such social behavior would be not possible—at least for the masses. Ajax exposes a simple idea to everybody. However, Ajax itself does not turn an ordinary site into a social web site. By default, Ajax does nothing but make the programming model a bit more complicated. So if there is absolutely no reason for you to use Ajax, you are not forced to do so. Now you have that in writing!
Despite that, improving the user experience of a web site is generally a good idea. JavaScript is well supported and widely accepted. Visual Studio 2010 has sophisticated support for JavaScript, including IntelliSense and debugging capabilities. Both Internet Explorer and Firefox have developer dashboards to aid in viewing, understanding, and debugging JavaScript and the several libraries involved when dealing with Ajax. But what is Ajax exactly?
Firstly, it's a combination of known technologies. As the name implies, it is a way to get data asynchronously. The browser's JavaScript engine is single threaded. Firing a web service call synchronously would block the UI until the response is received. Programming asynchronously is the only feasible way to get a good user experience. Second, the j in Ajax stands for JavaScript. This is widely accepted and supported; however, theoretically, any client language will do. Skipping the second a in Ajax, which is there just to create a catchy acronym, is the final technology, XML. This was the preferred way to transfer complex data. I say "was" because in recent years, JSON (JavaScript Object Notation) has proved to be a superior data format for Ajax. JSON defines a way to describe a serializable object using JavaScript instead of XML. This is both faster to evaluate and more compact in size. Size matters, by the way, because the bandwidth is still a bottleneck between the server and client. (So you could say "Ajax" or "Ajaj"; however, Ajaj is unknown perhaps because nobody can pronounce it easily.)
If you program using Ajax, you need a few more technologies, such as the DOM (Document Object Model) to access elements within a page; XML and XSLT to transform incoming data if it's not yet serialized using JSON; CSS (Cascading Style Sheets) and HTML to understand how to create and format objects dynamically; and at least a basic understand of HTTP, because it is still the protocol spoken between client and server. And last but not least, you must be fluent with JavaScript.
Empowering users can harm any platform. As soon as a user is given the ability to do more, it increases the potential for malicious or damaging actions on your system. SharePoint is no exception, and the various ways that extend the platform make security considerations crucial. For development of controls this is particularly important, because this is frequently the way one codes for SharePoint.
The <SafeMode> element in web.config controls the code execution behavior. Its basic structure looks like this:
<SafeMode MaxControls="200" CallStack="false" DirectFileDependencies="10"
TotalFileDependencies="50" AllowPageLevelTrace="false">
<PageParserPath AllowServerSideScript="false" />
</SafeMode>Any customized page that can contain code is executed using so-called safe-mode processing. This adds some security, as no inline script is executed. That prevents intruders from infiltrating code through end user–enabled functions. To overwrite this behavior, set the AllowServerSideScript attribute to true, as follows:
<PageParserPath AllowServerSideScript="true" />
The MaxControls element prevents the server from rendering extensive pages with more than 200 controls by default. The attributes DirectFileDependencies and TotalFileDependencies address performance checks as well. Setting CallStack to true would expose the call stack if the page can show exception details.
SharePoint is a highly customizable platform. That's true not only for administrators and developers, but for end users as well. While this is one of the key advantages the platform offers, it's also a risk for those operating the servers. Not only can users change content and create lists, but they can also upload Web Parts and add them to their sites. While one could simply prevent users from doing so, this would limit the attractiveness of a site. To give users a limited, policed power, SharePoint has safe controls.
That means that the administrator must explicitly allow the controls used on pages before anybody—regardless of his or her specific rights—is able to add and activate them. As a result, you no longer check and regulate "untrusted" users and their activities. Instead, you check the controls spread throughout your installation and give approval for them to be installed. Such approved controls can then be used by anybody who is allowed to import controls.
In the application's root web.config file is a <SafeControls> section that contains several elements to define which controls are allowed.
<SafeControl Assembly="MyWebPartLibrary, Version=1.0.0.0, Culture=neutral,
PublicKeyToken=null" Namespace="MyWebPartLibrary" TypeName="*"
Safe="True" AllowRemoteDesigner="True"/>Use the Assembly attribute to define the fully qualified name of the assembly containing the type. Use NameSpace and TypeName to restrict which controls are permitted. For TypeName, the asterisk signifies "all controls." To make the control safe, set the Safe attribute to true. You might wonder why this is necessary, since just removing the entry would declare the control unsafe anyway. However, remember that web.config files form a hierarchy, and the final application folder can inherit settings from upper levels. Thus, an administrator can explicitly disallow a particular Web Part control anywhere deeper in the hierarchy to prevent users from using it. If this effect is desired, just repeat the definition and set Safe to false.
Directly editing the web.config file is not recommended. Doing so could result in an invalid file, and the application could stop working. Even worse, it could become insecure in some way without you noticing. To avoid this, the process of Web Part deployment and registering the assembly or its parts as safe should be closely followed, as shown in the next code snippet.
public override void FeatureActivated(SPFeatureReceiverProperties properties)
{
// A reference to the features site collection
SPSite site = null;
// Get a reference to the site collection of the feature
if (properties.Feature.Parent is SPWeb)
{
site = ((SPWeb)properties.Feature.Parent).Site;
}
else if (properties.Feature.Parent is SPSite)
{
site = properties.Feature.Parent as SPSite;
}
if (site != null)
{
SPWebApplication webApp = site.WebApplication;
// Create a modification
SPWebConfigModification mod = new SPWebConfigModification(
@"SafeControl[@Assembly="MyAssembly"][@Namespace="My.Namespace"]"
+ @"[@TypeName="*"][@Safe="True"][@AllowRemoteDesigner="True"]"
, "/configuration/SharePoint/SafeControls"
);
// Add the modification to the collection of modifications
webApp.WebConfigModifications.Add(mod);
// Apply the modification
webApp.Farm.Services.GetValue().ApplyWebConfigModifications();
}
}This code shows how to modify web.config using the appropriate classes called from a feature event receiver. If the Web Part is part of a feature and the feature is activated, the event is fired and the code executed. The code first checks the parent object the receiver refers to (i.e., the context object it's installed in). From that object, the SPWebApplication object is pulled to get the web.config file that contains the site's configuration. An XPath expression that contains the complete token and the path where it has to be added is used to get the configuration. A farm service is used finally to apply the modifications.
The feature event receiver is very flexible and powerful. However, adding an event receiver to merely modify the configuration is probably more work than it's worth. See Chapter 3 to learn more about event receivers and how to program them.
If you have a Web Part and want to make it safe anyway, you can add this information to the solution package, as shown in the following code. For more information about solution deployment, refer to Chapter 9.
<Solution SolutionId="{2E9DDE85-8822-42EC-3a92-E85537810BAA}"
xmlns="http://schemas.microsoft.com/sharepoint/">
<FeatureManifests />
<ApplicationResourceFiles />
<CodeAccessSecurity /><DwpFiles />
<Resources />
<RootFiles />
<SiteDefinitionManifests />
<TemplateFiles />
<Assemblies>
<Assembly DeploymentTarget="WebApplication" Location="Apress.WebParts.dll">
<SafeControls>
<SafeControl Assembly="Apress.WebPart, Version=1.0.0.0, Culture=neutral,
PublicKeyToken=a05eff78260564"
Namespace="Apress" TypeName="*" Safe="True"/>
</SafeControls>
</Assembly>
</Assemblies>
</Solution>This technique is limited to your own Web Parts, where you have control over the packaging process. But it's the safest way to add controls to web.config. (You can review how to modify web.config using the SharePoint API in Chapter 3.)
The SharePoint building blocks have a unique structure, object model, and behavior. In this book we show you how to work with and program against these blocks. This section contains a short introduction to each one, with links to other chapters where we elaborate on the building blocks in more detail. The list looks like this:
Data-related building blocks:
Lists and document libraries
Files and documents
Columns and field types
Content types
Queries and views
Deployment- and maintenance-related building blocks:
Features
Solutions
Web sites and site collections
Building blocks to create the UI:
Mobile pages, controls, and adapters
Ribbon
Pages and UI
Web Parts
Control flow, action, and events:
Event handling
Alerts
Workflows
For each part, we'll give a brief introduction and an overview of the entry points and the object model.
This section contains all the parts of SharePoint that deal with data. In particular, this includes lists and libraries, files and documents, and the parts they consist of, such as field types, column definitions (and templates for them), and content types. Furthermore, we explain how to query against such data containers using queries and views.
The data access techniques are explained in greater depth in Chapter 4.
Lists are the basic data containers and document libraries are lists that contain documents. Lists have columns—internally called fields—to structure the data. Depending on the kind of customization you need, SharePoint offers several APIs regarding lists and libraries. There are three realms of APIs you can use:
Server side, for working on the server (
Microsoft.SharePointnamespace)Client side, for working on a client using JavaScript or Silverlight (
Microsoft.SharePoint.Clientnamespace)Migrating content between site collections (
Microsoft.SharePoint.Deploymentnamespace)
In addition to what the API provides, the list web services allow remote access.
SharePoint comes with many predefined lists and libraries that you can use as templates for your own creations. It's possible to export a list as a template and reuse it in custom code by adding a few more columns or modifying a field type. To manage list templates, the SPListTemplate class contains the relevant methods.
Lists form a hierarchy of list types, based on a primary type defined by the SPBaseType enumeration. The base types are
GenericList: A generic list type for most custom listsDocumentLibrary: A document library for any kind of documentDiscussionBoard: A discussion board list that's able to create discussion threadsSurvey: A survey list that handles surveysIssue: An issue list to store and track issuesUnspecifiedBaseType: An unspecified base type for any other kind of list
The SPListTemplateType enumeration is used for default list template types in SharePoint. There is a relationship between the template and the base types. That means each list template has a specific base type. Each enum value also has an internal value used in XML configuration files. Table 2-1 shows this relationship for common types.
Table 2.1. List Template Types
Type | Value | Description |
|---|---|---|
| 100 | Type used for a custom list |
| 101 | Type that defines a document library |
| 102 | Type that defines a survey |
| 103 | Type that defines a list that can store hyperlinks |
| 104 | Type that defines announcements (news) |
| 105 | Type that defines contacts with fields that store addresses, phone numbers, and so on |
| 106 | Type that defines a calendar that supports events |
| 107 | Type that defines tasks assigned to users |
| 108 | Type that defines a discussion board list |
| 109 | Type that defines a library that has special views to show pictures |
| 110 | Type that collects all data sources for a site |
| 111 | Type that defines a site template gallery |
| 112 | Type that defines some user information |
| 113 | Type that defines a Web Part gallery |
| 114 | Type that defines a list template gallery |
| 115 | Type that defines an XML form library that stores InfoPath forms |
| 116 | Type that defines a gallery list that stores master pages |
| 117 | Type that contains simple no-code workflows |
| 118 | Type that defines custom workflows |
| 119 | Type that defines a Wiki page library |
120 | Type that defines a custom grid for a list to present data | |
| 130 | Type that defines a data connection library for sharing information about external data connections |
| 140 | Type that defines a workflow history |
| 150 | Type that defines project tasks that can create Gantt charts |
| 200 | Type that defines a meeting series |
| 201 | Type that defines an agenda for a meeting |
| 202 | Type that defines attendees of a meeting |
| 203 | Type that defines decisions of a meeting |
| 207 | Type that defines objectives of a meeting |
| 210 | Type that defines the text box container for a meeting |
| 211 | Type that defines things to bring for a meeting |
| 212 | Type that defines workspace pages for a meeting |
| 301 | Type that defines posts of a blog |
| 302 | Type that defines comments of a blog |
| 303 | Type that defines categories of a blog |
| 1100 | Type that defines issue-tracking items |
| 1200 | Type that defines administrator tasks used in Central Administration |
The base of a list is the SPList class, which provides access to list properties common to all lists. If the list is a library, the more specific SPDocumentLibrary class can be used. You can retrieve an SPList object using the List property of the SPWeb object. In the client model, the type is SP.List. If the list uses external data, you'll need the SPListDataSource class or the corresponding SP.ListDataSource class.
Lists can fire events, especially when users add, modify, or remove elements. The SPListEventProperties class provides properties for list events, and the SPListEventReceiver class contains methods to trap events that occur for lists.
If you already have a list, the SPListItem class represents an item or row in it. An efficient way to return a list item or an SPListItemCollection is through the GetItem method of SPList. In the client object model, the type is SP.ListItem.
Also, lists support versioning. Using the SPListItemVersion class, you can access a version of a list item.
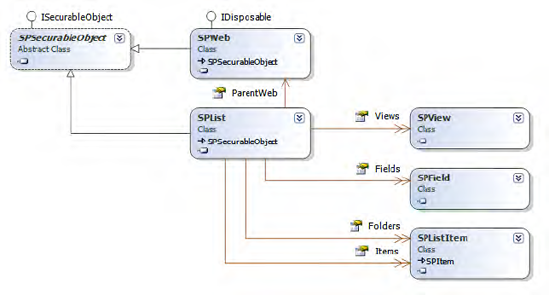
The Object Model at a Glance
Figure 2-4 shows the classes closely related to the SPList base class.
Configuring Lists and Libraries
Using the API you can define lists; add, modify, and remove items; and use lists as powerful and highly flexible data containers. If you merely want to define lists for deployment purposes, it's easier to create XML files. The schema.xml file contains list definitions. See Chapter 7 for more details concerning XML-based list definitions. Views that show the data for a list in a specific way are constructed with XSLT.
The previous section was about lists and libraries. Recall that libraries are lists that can contain documents. Documents usually start off as files on a local disk. However, in SharePoint, a file is everything that could be stored separately. This includes ASPX files, for instance. These files may reside on disk or in a database. Using the API you can read and write files with Stream objects.
A file is represented by an SPFile object. While the Files property of an SPList object returns all files, the same property of an SPWeb object returns the ASPX files associated with the web. In the client object model, the corresponding types are SP.File and SP.Folder.
As well as files attached to library items, a library supports folders. The SPFolder class provides the necessary properties and methods. A folder is a special item within a library. If you count items on an abstract level, the folders appear as items with a special property, namely FileSystemObjectType.
As files appear in collections, the type SPFileCollection is used to support adding, copying, and removing items. You can use SPFileCollectionAddParameters to add a file to a file collection. The SaveBinary method takes an SPFileStream and an SPFileSaveBinaryParameters object to save files to a stream. The target can be stored locally, written to disk, held in memory, or sent via HTTP. In the client object model, the method is called FileSaveBinaryInformation.
Like list items, even files can have versions. An SPFileVersion object represents a version of a file. In the client object model, SP.FileVersion is the equivalent.
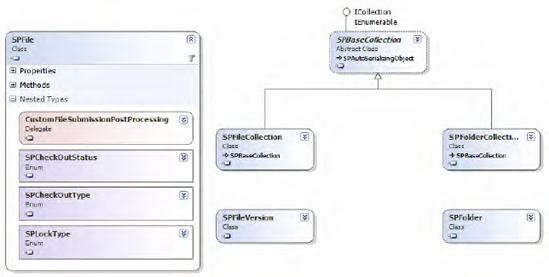
The Object Model at a Glance
Figure 2-5 shows the classes closely related to the SPFile base class.
Configuring Files and Documents
In the XML definition, especially for deployment purposes, the <Module> element represents a file, as shown in the following code:
<?xml version="1.0" encoding="utf-8"?>
<Elements xmlns="http://schemas.microsoft.com/sharepoint/">
<Module Name="Module1">
<File Path="Module1Sample.txt" Url="Module1/Sample.txt" />
</Module>
</Elements>The module encapsulates a collection of files that is part of the deployment package. In Chapter 7 we explain such files in more depth.
Lists and libraries structure data via columns. In SharePoint, the term field is used to distinguish relational database tables from their columns. You may translate columns into field types, rows into items, and cells of a row into fields. In the object model, a collection of field definitions is called Fields. A single field containing data of one column is represented by an SPField object.
In SharePoint, fields not only contain data of a particular type, but they are themselves a kind of type because the same field type can be used on multiple lists with different data. That means all such definitions are created once and reused throughout the site. A field type can persist in the site column gallery. A site column from such a gallery can be added to any list in the site, either programmatically or through the UI.
Some of the site columns that are built into SharePoint include Address, Birthday, StartDate, and EndDate. Each column belongs to one of a small set of basic field types, called scalar types. These are, for example, multiple lines of text (Note in the SPFieldType enumeration), date and time (DateTime), single line of text (Text), and hyperlink (URL). The complete list of field types is specified in the SPFieldType enumeration. Table 2-2 shows the most important values.
Table 2.2. Basic (Scalar) Types That All Field Types Inherit From
Type | Description |
|---|---|
| A field that accepts only |
| A field whose value is calculated at runtime from a mathematical formula. |
| A field that can have only one value, and the value must be from a finite list of values. There is also a |
| A field whose value depends on the value of another field in the same list item. It is usually the value of a logical operation performed on one or more other fields. |
| A field that is similar to a |
| A field that accepts a single line of text. There is also a field type for multiple lines of text called |
Chapter 4 contains a more detailed list, with examples. There is a rich object model to create and handle columns and field types. Use the SPListItem type to access a list item's data. The SPListItem object represents the list item, and you can use one of its indexers to reference a particular field. There is an indexer that accepts an Int32 object as an ID, one that accepts a String object as the field name, and a third that takes a Guid object. SPField and its derivatives represent field types. For example, SPFieldBoolean represents Boolean fields and SPFieldChoice represents Choice fields. Any specified column in a web site's site column gallery is an object instantiated from one of these classes. The properties of the class differentiate the various columns of a specified field type. The Birthday column and the StartDate column are both objects of the SPFieldDateTime class, for instance, but they differ in the value of the Title. An important member of the SPField class is the Update method. It must be called to save changes made to the column. Otherwise, changing values has no effect.
Storing data in fields is only the half of the process. Presenting the data to the user is the other half. One core feature of the SharePoint API is tight integration between the data layer and the UI layer. Even if Microsoft publicizes that SharePoint has a multitier architecture, this is not strictly correct. For developers, though, it is an advantage. Having a field and defining its UI and behavior in one place simplifies both distribution and usage. The rendering behavior of a field in a particular list item is usually managed by an object derived from the BaseFieldControl class. For example, the BooleanField renders a Boolean value, as in SPFieldBoolean. BooleanField derives from BaseFieldControl, which derives from System.Web.UI.Control. The rendering control holds a reference to the field object exposed by the Field property. This relationship is established in both directions—the field has a reference to the control through the FieldRenderControl property. Both objects form a couple—one for the data and one for the user interaction. The transfer of the value is done using the UpdateFieldValueInItem method and the Value property.
As a developer, when you create a custom field, you can inherit from BaseFieldControl or from any of the derived classes.
Closely related to field controls is the concept of rendering templates for controls. A rendering template is an element in one of the ASCX controls stored in this folder:
%ProgramFiles%Common FilesMicrosoft Sharedweb server extensions14 TEMPLATECONTROLTEMPLATES
You don't have to use templates, though it is recommended practice to do so by defining templates for public use. See Chapter 7 for more about this subject.
If your field holds more complex data than you will be able to present using a render template, you may consider using custom field types, too. There are a few built-in complex types, such as SPFieldLookupValue, which is used by the SPFieldLookup field type.
The Object Model at a Glance
Figure 2-6 shows the classes closely related to the SPField base class.
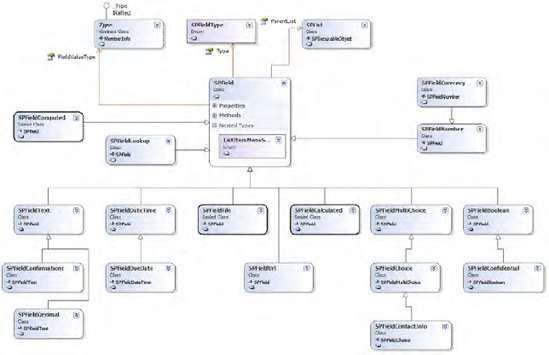
Configuring Columns and Field Types
For the purpose of site, feature, or Web Part definitions and deployment, you use various XML files. XML is used for columns and field types, too. It is needed to register custom field types using fldtypes*.xml files located in this folder:
%ProgramFiles%Common FilesMicrosoft Sharedweb server extensions14TEMPLATEXML
To declare custom fields, you use XML definition files. They also allow you to define the render pattern used to display a field's data under specific circumstances. For instance, one of the patterns determines the appearance of data when the field is a column header. Moreover, the XML defines the variable properties. For example, the Text field type not only contains text, but it also supports constraints such as the text's maximum length. The property schema is where you enter a value for the variable property, such as MaximumLength. Sometimes you need more than a text box to enter variable data of custom properties. In these situations you can use an external editor. This is another ASCX user control, invoked by clicking an ellipses button. See Chapter 7 for more details about such definitions.
The object model provides access—albeit read-only access—to the field type and column definitions via the SPFieldTypeDefinition class.
SharePoint defines all field types available out of the box in a file FLDTYPES.XML in the same location.
The following example shows both—the field definition as well as a small portion of code that renders a view partially using dynamic expressions:
<FieldTypes>
<FieldType>
<Field Name="TypeName">Counter</Field>
<Field Name="TypeDisplayName">$Resources:core,fldtype_counter;</Field>
<Field Name="InternalType">Counter</Field>
<Field Name="SQLType">int</Field>
<Field Name="ParentType"></Field>
<Field Name="UserCreatable">FALSE</Field>
<Field Name="Sortable">TRUE</Field>
<Field Name="Filterable">TRUE</Field>
<RenderPattern Name="HeaderPattern">
<Switch>
<Expr><Property Select='Filterable'/></Expr>
<Case Value="FALSE"></Case>
<Default>
<Switch>
<Expr><GetVar Name='Filter'/></Expr>
<Case Value='1'>
<HTML><![CDATA[<SELECT id="diidFilter]]></HTML>
<Property Select='Name'/>
<HTML><![CDATA["TITLE=]]></HTML>
<HTML>"$Resources:core,501;</HTML>
<Property Select='DisplayName' HTMLEncode='TRUE'/>
<HTML><![CDATA[" OnChange='FilterField("]]></HTML>
<GetVar Name="View"/>
<HTML><![CDATA[",]]></HTML>
<ScriptQuote>
<Property Select='Name' URLEncode="TRUE"/>
</ScriptQuote>
<HTML>
<![CDATA[,this.options[this.selectedIndex].value,
this.selectedIndex);' dir="]]></HTML>
<Property Select="Direction" HTMLEncode="TRUE"/><HTML><![CDATA[">]]></HTML>
<FieldFilterOptions
BooleanTrue="$Resources:core,fld_yes;"
BooleanFalse="$Resources:core,fld_no;"
NullString="$Resources:core,fld_empty;"
AllItems="$Resources:core,fld_all;">
</FieldFilterOptions>
<HTML><![CDATA[</SELECT><br>]]></HTML>
</Case>
</Switch>
</Default>
</Switch>
</RenderPattern>
</FieldType>
</FieldTypes>Content types are designed to organize SharePoint content in a more meaningful way. A content type is a reusable collection of settings, features, and metadata that you can apply to a certain category of content. They manage metadata and extend the concept of lists and libraries with another level of abstraction.
Their main benefit is that content types enable you to add different types of items to the same library and still be able to handle the data in a structured way. This aids with organizing data in some kind of a matrix rather than flat tables. A mathematician would say that it adds another dimension to the organization structure. A content type includes different columns for metadata and can have different workflows assigned to it. Chapter 4 includes an overview of defining and using content types.
The Object Model at a Glance
Figure 2-7 shows the classes closely related to the SPContentType base class.
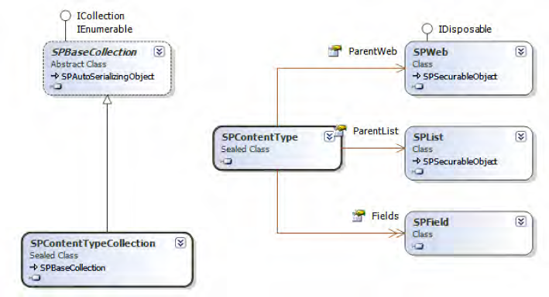
Custom content types can be part of any feature you deploy. Their basic configuration is via XML. Usually this is included with definitions of list templates and lists using this content type. However, it's possible to define the content type on its own, to allow for reuse.
A typical schema example looks like this:
<?xml version="1.0" encoding="utf-8" ?>
<Elements xmlns="http://schemas.microsoft.com/sharepoint/">
<ContentType ID="0x0100E26A05B64C8B4e96A9B0461156806FFA"
Name="Vehicle Data"
Group="$Resources:List_Content_Types"
Description="Store vehicle information of all kind."
Version="0">
<FieldRefs>
<FieldRef ID="{CC5A31EF-CCD5-4ed4-A691-1C26DD405864}" Name="Brand" />
<FieldRef ID="{B1105775-D16E-42ea-ABA1-1C26DD405864}" Name="Year" />
<FieldRef ID="{6CC4C31C-AA19-43de-2009-1C26DD405864}" Name="Model" />
</FieldRefs>
</ContentType>
</Elements>As you can see, the content type can't define columns directly. Instead, the <FieldRef> elements reference to some site columns, defined elsewhere. In custom list definitions, this can look like this:
<?xml version="1.0" encoding="utf-8" ?>
<Elements xmlns="http://schemas.microsoft.com/sharepoint/">
<Field ID="{CC5A31EF-CCD5-4ed4-A691-1C26DD405864}"Name="Brand"
SourceID="http://schemas.microsoft.com/sharepoint/v3"
StaticName="Brand"
Group="Vehicle Information"
Type="Text"
DisplayName="Brand" />
<Field ID="{B1105775-D16E-42ea-ABA1-1C26DD405864}"
Name="Year"
SourceID="http://schemas.microsoft.com/sharepoint/v3"
StaticName="Year"
Group="Vehicle Information"
Type="Text"
DisplayName="Year" />
<Field ID="{6CC4C31C-AA19-43de-2009-1C26DD405864}"
Name="Model"
SourceID="http://schemas.microsoft.com/sharepoint/v3"
StaticName="Model"
Group="Vehicle Information"
Type="Text"
DisplayName="Model" />
</Elements>In Chapter 7 you will find more information about the definition schema for site columns and content types.
Defining the structure and storing data puts the items into the database. Queries and views are used to retrieve it. A query is a straightforward way to execute a data retrieval clause. It is very similar to an SQL statement. In fact, internally, with some steps removed from your code, an SQL statement is sent to the database.
In SharePoint you can use LINQ to SharePoint to execute queries. They are compiled into Collaborative Application Markup Language (CAML) queries and translated internally into SQL. You can also write and execute CAML directly. This is faster but more complicated and error prone than using LINQ.
Chapter 4 contains a comparison of all the data retrieval techniques.
A view defines a combination of UI (render) instructions and a query. A view always contains a query, while a query does not necessarily need a view. Figure 2-8 shows the interface users use to select the current view.
On the server side, the Microsoft.SharePoint.SPQuery class represents a query. Its Query property contains a CAML string that defines the query. You can pass the query object to the GetItems method of a list to get a collection of items that satisfy the query conditions.
From the client side, a similar CamlQuery type exists in Microsoft.SharePoint.Client and for JavaScript in the SP namespace, respectively.
For views, SPView represents a view of list data. A view contains a query. The Views property of SPList provides access to the list's SPViewCollection. This assumes that a list can have as many views as you need. In the client object model, the type SP.View exists. The SPViewFieldCollection type represents the collection of fields that are returned in a view. Furthermore, the SPViewStyle type contains a view style. The ViewStyles property of SPWeb provides access to the SPViewStyleCollection for a web site. View styles are defined globally in this XML file:
%Program Files%Common FilesMicrosoft SharedWeb Server Extensions14TEMPLATEGLOBALXMLVWSTYLES.XML
View styles determine the default formatting of a view. Lists are usually shown as tables, while contacts can appear in a boxed format like cards. View styles define such formats.
You can define views associated to a list in XML. The view can contain XSLT code to define how the data will be rendered. This is usually used to deploy complex lists.
Instead of using CAML and invoking queries directly, the LINQ to SharePoint provider simplifies working with large data structures. The provider is an object-relational mapping (ORM) between the content database and the SharePoint application. The SPMetal.exe tool creates a proxy from existing lists that contain a typed object model. This model is based on the DataContext class. The class contains code for querying and updating the content databases. It also supports sophisticated object change management. The EntityList<T> object represents a list that can be queried, and SubmitChanges writes changes to the content database.
Lookup relationships can exist between lists. These relationships can be one-to-one, one-to-many, and even many-to-many. EntityRef<T> is a reference on the "one" side, while EntitySet<T> is on the "many" side. Lookups in SharePoint can contain multiple values. Use the LookupList<T> class to represents the values of such a lookup field.
Figure 2-9 shows the classes closely related to the SPQuery and SPView base classes.
Configuring Queries
Queries use CAML. The corresponding schema is called a query schema; for views, there is a view schema. Both schemas are explained in Chapter 4.
A CAML query can look like this:
<Query>
<Where>
<Geq>
<FieldRef Name="Expires"/>
<Value Type="DateTime">
<Today/>
</Value>
</Geq>
</Where>
<OrderBy>
<FieldRef Name="Modified"/>
</OrderBy>
</Query>The view schema is more verbose. It supports control elements for conditional rendering and supports specific parts of the page explicitly. These include render instructions for the header, footer, groups, empty sections, and so forth.
The view definition code can contain HTML within CDATA (character data) elements to create the page's output.
<View Type="HTML" Name="Summary">
<ViewBody ExpandXML="TRUE">
<![CDATA[ <p><SPAN class=DocTitle><ows:Field Name="Title"/></SPAN>
(<ows:Field Name="Author"/>, <ows:Field Name="Modified"/>)
<ows:Limit><Field Name="Body"/></ows:Limit>
</p> ]]>
</ViewBody>
<Query>
<Where>
<Geq>
<FieldRef Name="Expires"/>
<Value Type="DateTime">
<Today/>
</Value>
</Geq>
</Where>
<OrderBy>
<FieldRef Name="Modified"/>
</OrderBy>
</Query>
<ViewFields>
<FieldRef Name="Summary"/>
<FieldRef Name="Author"/>
<FieldRef Name="Modified"/>
<FieldRef Name="Body"/>
</ViewFields>
</View>As shown in the sample, the code can contain a query that filters the data further before it is displayed. Chapters 4 and 7 explain what to do with such a configuration and how to create it.
Some parts of SharePoint are responsible for deployment of new functionality, called features. Features can be deployed using solutions, which have to provide everything an application might need. The structure they run in or build (define) consists of what SharePoint applications are—web sites and site collections.
SharePoint is a highly extensible platform. To make extensions portable, the concept of features has been introduced. Features contain an XML file (Feature.xml) and one or more element files. These files describe the feature definition. Features contain all files required to get the extension running, such as templates and pages. They also come with assemblies that contain code for event handlers, workflows, and custom ribbons. Even support files such as images, CSS files, and JavaScript files are included in a feature.
Features appear in a specific scope, like a site or site collection. Features may depend on each other. For example, a feature for a site may require another feature on the site collection level. Other feature scopes are web and farm. From top to bottom, the scope levels are
Server farm: The feature will be available in the server farm. This scope corresponds to the
SPFeatureScope.Farmenumeration.Web application: The feature will be available in the web application. This scope corresponds to
SPFeatureScope.WebApplicationenumeration.Site collection: The feature will be available in a site collection. This scope corresponds to
SPFeatureScope.Siteenumeration.Site: The feature will be available in a single site. This scope corresponds to
SPFeatureScope.Webenumeration.
Warning
Note the discrepancies between the enumeration values and the scope names.
Features are typically activated by an administrator of the associated scope. During their activation or deactivation, a feature receiver can invoke code. For any change of the feature's state, such as activating, deactivating, uninstalling, or upgrading, the feature receiver's event handler can launch custom code.
Even features can be manipulated using the object model. This includes finding information, retrieving a list of installed features, and determining dependencies. The Microsoft.SharePoint namespace contains the SPFeature class. One SPFeature object represents one feature. A collection of features is stored in an SPFeatureCollection object. The SPFeatureCollection can be reached via the Features property on the SPWebService, SPWebApplication, SPSite, and SPWeb objects, depending on the scope of the feature. If a feature appears in the collection, it has been activated for the specified scope. That means that there is no activation method—adding the feature to the scope's container activates it. The SPFeatureProperty object represents a single property of an SPFeature object. Because there are multiple properties, they are stored in an SPFeaturePropertyCollection object and returned through the Properties property of the SPFeature object. If a feature depends upon another feature, an SPFeatureDependency object contains the associated information. Such dependencies can handle multiple types of data, which is why an SPFeatureDependencyCollection stores a collection of objects. You can use the ActivationDependencies property of the SPFeatureDefinition object to define that a feature depends on another one. For example, a feature on the site level may install particular Web Parts, while a feature on web level may install pages that use those Web Parts. The Microsoft.SharePoint.Administration namespace contains the SPFeatureDefinition class, which represents the base definition of a feature, including its name, scope, ID, and version. A collection of feature definitions is stored in an SPFeatureDefinitionCollection object. It can be accessed via the FeatureDefinitions property of the SPFarm or SPSite objects.
The SPElementDefinition class represents an abstract element that is provisioned when a feature is activated or used. The collection of elements is stored in an SPElementDefinitionCollection object and can be accessed using the GetElementDefinitions method of the SPFeatureDefinition class. Elements can be some types of objects, such as files.
Figure 2-10 shows the classes closely related to the SPFeature base class.
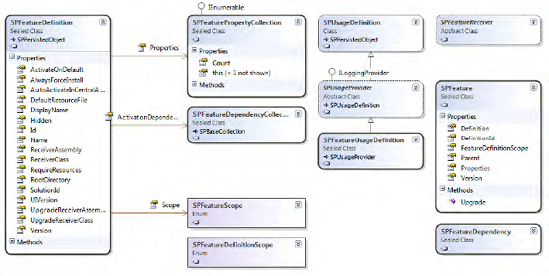
Features are defined by XML files to aid in deployment. You need at least two files: feature.xml and an element manifest file, which can have any name. These files define scope, dependencies, and related files. The feature.xml file specifies the location of assemblies, files, dependencies, and properties that the feature supports. A basic feature.xml file has the following form:
<Feature Title="Feature Title"
Scope="FeatureScope"
Id="GUID"
xmlns="http://schemas.microsoft.com/sharepoint/">
<ElementManifests>
<ElementManifest Location="ElementManifestFile.xml" />
</ElementManifests>
</Feature>See Chapters 7 and 9 for more information about creating and using feature definition files.
A feature extends an existing SharePoint installation. Site definitions are another distributable item, as are Web Parts. A complete installation may be provided as a solution and packed into a solution package (.wsp) file. Such a package contains a data definition file (DDF) and is compressed using the CAB file format. The API, enhanced with several tools, provides support for creating, deploying, and upgrading existing solutions to the servers of a farm.
In SharePoint 2010 there are two types of solutions: sandboxed and full trust. A SharePoint installation contains a gallery to store solutions for further installation and activation. Sandboxed solutions run with lower trust for hosted environments and secured production servers, and when testing foreign solutions.
Tip
We recommend always creating sandboxed solutions. Always run production code as a sandbox whether it is self-hosted (on-premise) or uploaded to an online facility. Avoid Visual Web Parts and other project types that don't support sandboxed solutions.
A sandboxed solution uses a subset of features of the object model. When uploading a sandboxed solution, a validator can check the validity of the package. The farm's administrator can restrict allowed solutions to sandboxed solutions to protect the servers from malicious code. In contrast, full-trust solutions have access to the complete object model, and yet are deployed directly to the farm's servers.
Solutions can be administered using the object model. This includes deploying, upgrading, and removing solutions. You can also define solution validators and set usage limits for sandboxed solutions through the object model.
All solutions share some common objects. The SPSolution class represents a solution on a server farm. If all the solutions of a farm are retrieved, an SPSolutionCollection object is returned. Solutions can be localized. The language pack for a solution is held in an SPSolutionLanguagePack object, and if you support multiple languages, an SPSolutionLanguagePackCollection object is employed.
Sandboxed solutions use another part of the object model. The SPUserSolution class represents a sandboxed solution and SPUserSolutionCollection a collection of such objects. If the solution is blocked for some reason, it is copied to an SPBlockedSolution object. As well as exposing built-in validators, the SPSolutionValidator base class provides support for custom validators.
Figure 2-11 shows the classes tightly related with the SPSolution base class. The sandboxed solutions have some additional types related to the SPUserSolution base classes.
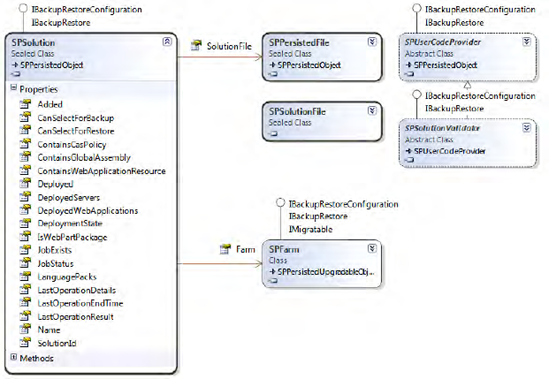
As in the previous sections, several XML files play a role in defining solutions. A solution is configured by a manifest file named manifest.xml. The solution manifest is stored at the root of the solution package and referenced from feature.xml. This file defines the features, site definitions, resources, and assemblies within the package.
<Solution SolutionId="SolutionGuid"
xmlns="http://schemas.microsoft.com/sharepoint/">
<FeatureManifests>
<FeatureManifest Location="FeatureLibraryfeature.xml"/>
</FeatureManifests>
<TemplateFiles>
<TemplateFile Location="ControlTemplatesTemplate.ascx"/>
</TemplateFiles>
<RootFiles>
<RootFile Location="ISAPIMyWebService.asmx">
</RootFiles>
<Assemblies>
<Assembly DeploymentTarget="GlobalAssemblyCache"Location="ms.samples.sharepoint.myFeature.dll"/> </Assemblies> </Solution>
Additionally, the DDF is required to create a complete package. It looks like this:
.OPTION EXPLICIT .Set CabinetNameTemplate=MySolutionFile.wsp .set DiskDirectoryTemplate=Setup .Set CompressionType=MSZIP .Set UniqueFiles="ON" .Set Cabinet=on .Set DiskDirectory1=Package buildmanifest.xml manifest.xml buildMySolutionFilefeature.xml MySolutionFilefeature.xml
Again, Chapter 9 goes beyond these simple examples and explains how to distribute your code as a solution.
For end users organizing their applications, the top-level elements are site collections and sites. A site collection consists of a root web site and any number of child sites, which in turn can have child sites. Web sites contain lists, libraries, and elements used to support them, such as content types, custom fields, workflow instances, and more. Web sites can also contain application pages and Web Parts. The search engine can also search within the scope of a web site.
Web sites are containers for child web sites; hence, they build a hierarchy. The site collection is the root and is virtually a web site too. Elements available on a higher level or the root can be used deeper in the hierarchy. The site collection is typically used to store elements that all subsequent web sites share. Think of elements as Web Parts, list templates, themes, workflows, and features.
The security model is directly related to the site collection. Each site collection has its own administrator. Users can be assigned to a site collection as the highest available scope.
For developers, all parts of a web site are accessible through the API at runtime. The definition of a web site uses templates that contain several different types of XML files. A huge object model is available to deal with all the elements of a site collection and its child elements.
Firstly, the SPWeb class is the core type for web sites and site collections. It allows you to manipulate the look and feel of the web site and access a site's users and these users' permissions and alerts. Using an SPWeb object you can also open and modify galleries of list templates and Web Parts. Many of the child elements in the site, such as its child sites, lists, list templates, and content types, are collections that can be reached via properties of the SPWeb class. For objects that allow modification, the Update method writes changes back to the database.
One crucial thing is to get a reference to an SPWeb instance, because this type provides a bunch of basic properties that gain access to related objects, such as lists. Typically, you use the SPSite class to instantiate the root site collection address and open an SPWeb instance using OpenWeb. Site collections are represented by objects of the SPSite class. It has members that you can use to manage child objects, including features, subsites, solutions, and event receivers. As with the SPWeb type, there are multiple ways of getting a reference to an SPSite object.
Getting a reference to any of those objects is different from other classes, because these objects are primary ones that don't have parents. If you are running inside a SharePoint application, a Web Part, or an event receiver, you can use the current context to retrieve the site:
SPSite site = SPContext.Current.Site;
If your code runs in an application page (ASPX) and you only have the regular ASP.NET context (HttpContext), you can use the SPControl class instead:
SPSite site = SPControl.GetContextWeb(this.Context);
This code assumes that you're inside the System.Web.UI.Page class instance, and this.Context references the current page's context. If you inherit your application page from either UnsecuredLayoutPageBase or LayoutsPageBase, you can get an SPWeb instance from the Web property:
SPWeb web = this.Web;
Warning
All of these methods use internal code to return SPSite and SPWeb instances. You're not supposed to dispose of or close any of these objects because the source instance takes care of this. Doing so results in unpredictable behavior.
The root web can be obtained using this code:
SPWeb root = SPContext.Current.Site.RootWeb;
Sometimes you need to go back from the current web to a higher level, such as the site or farm. The SPSite object gives direct access via the context's Site property:
SPFarm farm = SPContext.Current.Site.WebApplication.Farm;
The SPContext type does not exist in any application that runs outside SharePoint, such as a console application. In the case of a console application, you must access the site by calling the server:
SPSite site = new SPSite("http://myserver/site");Here it's your responsibility to dispose of the site object, as there is no parent instance that can control this:
using (SPSite site = new SPSite("http://myserver/site"))
{
// your code here
}To get any web in the site collection, you can use the OpenWeb method like this:
using (SPWeb web = site.OpenWeb("webname"))
{
// your code here
}The using statement assures an implicit call to SPWeb's Dispose method. Chapter 3 discusses this and dives deeper into the various object creation and disposal methods.
Figure 2-12 shows the classes closely related to the SPWeb and SPSite base classes.
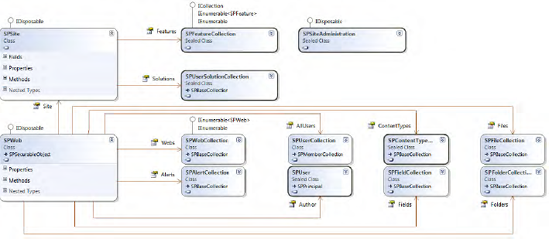
Configuring Sites and Site Collections
As for other elements, CAML is used to specify site definitions. Two types of files are required for site templates: WebTemp*.xml and Onet.xml.
The WebTemp*.xml file resides in the following directory:
%ProgramFiles%Common FilesMicrosoft Sharedweb server extensions14
TEMPLATE<LCID>XMLThe placeholder <LCID> is the numerical ID of the culture. Table 2-3 shows some common LCIDs.
Table 2.3. Common LCID Values
Language/Culture | LCID |
|---|---|
English | 1033 |
German | 1031 |
Italian | 1040 |
Spanish | 3082 |
French | 1036 |
Chinese (traditional) | 2052 |
Chinese (simplified) | 1028 |
Japanese | 1041 |
Korean | 1042 |
The markup contains templates and options from which the user creating a site from this template can choose.
As mentioned, you also need another essential file called ONET.xml. It resides in the following directory:
%ProgramFiles%Common FilesMicrosoft Sharedweb server extensions14
TEMPLATESiteTemplates<SiteType>XMLThe <SiteType> placeholder is the name of a site definition, such as internal ones like STS or BLOG. The markup provides metadata about the site type. It also itemizes and defines the lists, modules, and features that comprise the site type.
Site definitions are not the only way to define and distribute sites. Site definitions are intended to create an element chosen from administration and used to create several new sites from the same definition for subsequent customization.
Alternatively, there are site templates. Those templates are exported and stored as solution files (.wsp), and can be used to transfer templates from one server to another. The storage of solution templates as .wsp is new in SharePoint 2010—the former .stp format is still supported but deprecated.
The UI is not just a collection of controls. Many parts of SharePoint offer extensible interfaces, a wide range of predefined elements, and comprehensive support for many devices.
Note
Among the various building blocks, there is one especially for mobile controls. This book doesn't cover mobile controls and devices, and therefore we skip the definition. If you need information about this topic, please refer to http://msdn.microsoft.com/en-us/library/ee536690(office.14).aspx.
SharePoint is a web application, and such an application consists of pages. There are content pages that present lists and libraries, support pages that contain common functions (e.g., file upload), application pages that contain custom code, and master pages that define a common UI around all other types of pages.
Among the supported elements, you'll find everything you need to define a unique UI, including themes and CSS.
Content Pages
Content pages are any pages already used in a SharePoint application as part of the site definition. Users can change content pages using SharePoint Designer or Visual Studio, and even edit them using the embedded editors, such as the Web Part editor. Several common files (e.g., AllItems.aspx) are content pages. Unmodified content pages are stored in the file system and called unghosted or uncustomized. Customizing such pages transfers them into the database, and they become ghosted.
Warning
Customizing server files to change them server-wide is not recommended. Instead, a better approach is to change master pages or add customized master pages to change the look and feel in your farm's applications.
Using Code in Pages
Content pages are ASPX pages, and are therefore intended to contain custom code. However, because end users can distribute such pages, and active code can potentially harm a server's reliability, there are several security restrictions. As a general rule, inline code is not supported within a custom content page. You are supposed to use code-behind classes to provide code to content pages to overcome this restriction. A special configuration section, <SafeControls>, defines the controls permitted on content pages.
To prevent users from uploading Web Parts containing harmful custom code, the code portion must be explicitly registered in the <SafeControls> section. Otherwise, SharePoint will not execute it. As a general rule you should avoid custom code in content pages. However, internal pages can execute code at any time. If you create a new site definition using modified content pages with custom code, they will execute just fine. If a user later modifies those pages, making them ghosted, the code will no longer execute. To avoid this confusing behavior you should not use custom code in common content pages.
However, as with most other extensible parts on ASP.NET, the administrator of a farm can override this behavior by configuring the Virtual Path Provider. This provider is responsible for retrieving the page from wherever it is stored (file system or database) and handing it over for execution. The following definition in web.config enables the execution of server-side code:
<SharePoint>
<SafeMode ...>
<PageParserPaths>
<PageParserPath VirtualPath="/_mpg/*"
CompilationMode="Always"
AllowServerSideScript="true"
IncludeSubFolders="true"/>
</PageParserPaths>If you plan to create complete applications using code, using application pages is much more powerful and less confusing.
Application Pages
Application pages are regular ASPX pages that behave similarly to any other ASP.NET page. However, they run inside the context of SharePoint and have full access to the object model. The only restriction is that unlike content pages,[1] application pages cannot host SharePoint Web Parts zones. Application pages usually reside in a subfolder under the following base path:
%ProgramFiles%Common FilesMicrosoft Sharedweb server extensions14
TEMPLATELAYOUTSChapter 3 contains a more detailed introduction to the world of application pages. For SharePoint developers, it's one of the most powerful ways to create sophisticated applications.
Master pages define a common layout for all other pages. You can change the look and feel and customize the UI just by changing the master page. A master page contains placeholders, which will be filled with controls by content and application pages. When a page is executed, the server first combines the master and the page into a final page. A master page can contain other master pages to form a hierarchy to accommodate complex scenarios. This includes a master that defines a global navigation, and another master that defines a subnavigation within this frame.
The default global master is named v4.master; .master is the common file extension for all ASP.NET master pages. You can find the global master page in
%ProgramFiles%Common FilesMicrosoft Sharedweb server extensions14
TEMPLATEGLOBALIn a SharePoint installation you can handle many master pages in custom galleries. This allows centralized administration and easy reuse in multiple sites.
Note
Using master pages is a core concept for code reuse, consistent look and feel, easy maintenance, and centralized customization. As a general rule you should always use master pages, even for a single application page.
You can find more about master pages in Chapter 10.
The ribbon extends the UI and unifies the look and feel between SharePoint and Office products. A ribbon consists of tabs, and each tab contains groups of related UI elements called controls. The ribbon is stabler than a traditional menu or toolbar and makes it easier for a user to find a specific control. Several controls, such as drop-down lists, check boxes, and buttons, avoid the need for pop-up dialogs—meaning fewer clicks to accomplish an action. Context-sensitive controls are displayed in a tab with a highlight color at the end of the ribbon's tab row for rapid identification.
Ribbons reside in the rendered page only. While they can be configured and created on the server, you can use JavaScript on the client side to interact with ribbons via a large object model.
Use the IRibbonMenu interface to implement a new ribbon on the server. Within the ribbon you deal with menus, defined by SPRibbonMenu, and menu items, defined by SPRibbonMenuItem. Each control within a menu can issue a command, based on an SPRibbonCommand object.
On the client side, the SP.Ribbon.PageManager class is the entry point. To handle commands, the CUI.Page.CommandDispatcher and CUI.Page.PageCommand classes are used.
As a developer you can customize the ribbons of common pages. You can also create completely new ribbons for your application pages. We cover this in depth in Chapter 7.
Figure 2-13 shows the classes closely related to the SPRibbon base class.
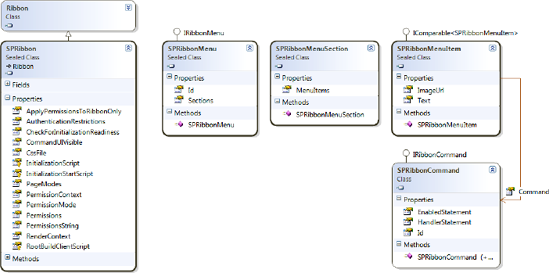
Like most of the building blocks, a ribbon is also defined via XML. The following example shows such a definition:
<?xml version="1.0" encoding="utf-8"?>
<Elements xmlns="http://schemas.microsoft.com/sharepoint/">
<CustomAction
Id="Ribbon.WikiPageTab.CustomGroupAndControls"
Location="CommandUI.Ribbon"
RegistrationId="100"
RegistrationType="List">
<CommandUIExtension>
<CommandUIDefinitions>
<CommandUIDefinition
Location="Ribbon.WikiPageTab.Groups._children">
<Group Id="Ribbon.WikiPageTab.CustomGroup"
Sequence="55"
Description="Apress Group"
Title="Apress Group"
Command="EnableApressGroup"
Template="Ribbon.Templates.Flexible2">
<Controls Id="Ribbon.WikiPageTab.CustomGroup.Controls">
<Button
Id="Ribbon.WikiPageTab.CustomGroup.Controls.CustomButton1"Command="CustomButtonShowAlert"
Image16by16="/_layouts/images/FILMSTRP.GIF"
Image32by32="/_layouts/images/PPEOPLE.GIF"
LabelText=""
TemplateAlias="o2"
Sequence="15" />
</Controls>
</Group>
</CommandUIDefinition>
</CommandUIDefinitions>
<CommandUIHandlers>
<CommandUIHandler Command="EnableApressGroup" />
<CommandUIHandler Command="CustomButtonShowAlert"
CommandAction="javascript:alert('Hello Apress!')," />
</CommandUIHandlers>
</CommandUIExtension>
</CustomAction>
</Elements>As you can see, it's neither trivial nor easy, but it's flexible enough to drive even an ambitious project.
Web Parts are probably SharePoint's most well-known component. SharePoint Web Parts are built on top of ASP.NET Web Parts, and share the same behavior and interfaces. Several built-in Web Parts plus an enormous list of third-party offers constitute a rich pool of powerful controls. A Web Part is simply a control you can place on a page. Web Parts can contain code, and can do everything from displaying a simple image to managing complex nested lists. Web Parts can interact through data connection interfaces. However, the most important feature is that end users can add, remove, and customize Web Parts without any coding, and without asking permission of an administrator or developer.
The object model mostly uses ASP.NET code, and is slightly extended to integrate well with SharePoint. The WebPartManager tracks the current state of the Web Parts on a page. This class provides the required JavaScript libraries, because Web Parts are managed on the client side. Within a page, one or more zones can be defined where the user can place Web Parts. The WebPartZone object creates such zones.
The Object Model at a Glance
Web Parts are one of the main types of controls that developers produce. Please refer to Chapter 3 for a comprehensive introduction, along with object class models and examples. When searching for more information, remember that Web Parts are plain ASP.NET controls, and the whole infrastructure resides in the System.Web.UI.WebControls.WebParts namespace, not Microsoft.Sharepoint.
Configuring Web Parts
Web Parts are defined with XML. The XML contains the information required to render it on the page and create the executable code. A sample XML file looks like this:
<?xml version="1.0" encoding="utf-8" ?>
<webParts>
<webPart xmlns="http://schemas.microsoft.com/WebPart/v3">
<metaData>
<type name="TypeName, Version=VersionNumber, Culture=neutral,PublicKeyToken=PublicKeyToken" />
<importErrorMessage>Cannot import this Web Part.</importErrorMessage>
</metaData>
<data>
<properties>
<property name="Title" type="string">WebPart's Title</property>
<property name="Description" type="string">WebPart's Description</properties>
</data>
</webPart>
</webParts>This XML contains the fully qualified name of the assembly that holds the Web Part's code. Web Parts can be exported and imported into another site by the user. If a Web Part import fails due to missing dependencies, the importErrorMessage tag is displayed. The <properties> section is a bag that can contain any property supported by the basic WebPart object.
In Chapter 3 you'll find a complete description of Web Parts.
Web Parts and Security
The advantages of Web Parts—being accessible to and manageable by end users—are at the same time their biggest disadvantages. Importing a Web Part containing executable code opens a barn door–wide security hole in SharePoint. Therefore, you must register any Web Part in the central web.config file, which an end user can't access. The following <SafeControl> element shows such an entry:
<SafeControl Assembly="AssemblyNameWithoutDLLExtension, Version=AssemblyVersionNumber, Culture=neutral, PublicKeyToken=PublicKeyToken" Namespace="NamespaceOfYourProject" TypeName="*" Safe="True" />
Even the assembly registered here can face further security restrictions that follow the common code security model provided by the .NET Framework. SharePoint is built on top of this model. For example, the administrator can restrict the ability of assemblies to access the server's hard disks. The keyword here is Code Access Security (CAS). We'll cover this in Chapter 3 in more detail.
These blocks provide dynamic action to your application. Whenever an event occurs, your code is called. You can, for example, achieve a higher level of customization by doing something with the data before or after internal operations. Using alerts, users can interact closely with the system. Alerts extend the event model to the outside world, primarily by sending fragments of information by e-mail or text message (Short Message Service [SMS]). Workflows provide a higher level of control over the behavior of a whole application, using conditions and loops to define sequences of actions.
Creating interactive applications requires code that executes if a specific event occurs. In SharePoint, event receivers are used to create event handlers. It is a loosely coupled model. Lists or features can fire an event, and as a result, code executes somewhere. That's because SharePoint objects are often created using the UI, and there is nowhere suitable for attaching an event handler. Receivers are event handlers that can be attached by configuration through internal mechanisms.
For the SPWeb class you can define event receivers using the SPWebEventReceiver type, while the SPList object has an SPListEventReceiver type. To implement an event receiver, you inherit from one of these base classes or from their common base class, SPEventReceiverBase. The custom class has to be registered with the event source and a specific scope.
Event handlers are part of their designated source. All objects that support events have a corresponding event receiver, following the naming scheme <Object>EventReceiver, where <Object> is something like SPList, SPWeb, or SPWorkflow. However, there are some nasty exceptions to this rule. For example, the event receiver for features is named SPFeatureReceiver, not "SPFeatureEventReceiver" as you might expect.
Event receiver types are associated with property bags providing access to various properties. Event property bags follow a similar naming scheme to the events itself, using the suffix EventProperties. This reads as SPWebEventProperties, SPListEventProperties, and so forth.
The Object Model at a Glance
Figure 2-14 shows the classes closely related to the SPEventReceiverBase classes.
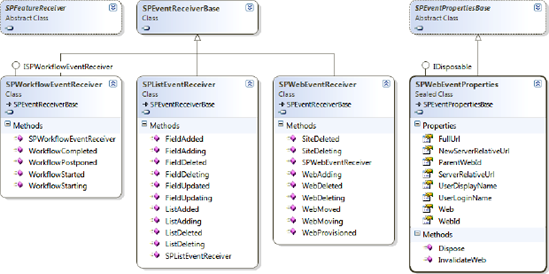
The SPWorkflowEventReceiver class is defined in the Microsoft.Sharepoint.Workflows namespace, while all others are in the default Microsoft.Sharepoint namespace.
Registering an Event
Even events can be registered using XML files. Event receiver definitions are part of a feature, and therefore they are defined using the Feature Schemas XML. Typically, this looks like this:
<Elements xmlns="http://schemas.microsoft.com/sharepoint/">
<Receivers
ListTemplateOwner="ADDABAAA-1111-2222-3333-111111111111"
ListTemplateId="104">
<Receiver>
<Name>SimpleUpdateEvent</Name>
<Type>ItemUpdating</Type>
<SequenceNumber>10000</SequenceNumber>
<Assembly>SimpleUpdateEventHandler, Version=1.0.0.0, Culture=neutral,
PublicKeyToken=10b23036c9b36d6d</Assembly><Class>Apress.Samples.SimpleItemUpdateHandler</Class>
<Data></Data>
</Receiver>
</Receivers>
</Elements>This code defines a receiver that's associated with a list and coded in the specified assembly. Each receiver has several distinct methods, such as Adding (before item is added), Added (after item is added), Deleting (before item is deleted), Deleted (after item is deleted), and so forth. You can simply override the particular method of the base class, and SharePoint will call this method if the event occurs.
Events within a web site are restricted in their reach. If you want to inform users about an event that occurs, writing something on a web site can only inform those users currently on the site. To overcome this limitation, SharePoint can reach the outside world through e-mail or SMS, or via other Office servers. Alerts define such transmissions. They operate at the item or list level.
The object model has several types to support alerts. The SPAlert class represents an alert, and includes such information as whether it is an e-mail or another message type, the template used, the alert frequency, and which user created the alert. To support reusability, the SPAlertTemplate class can define the content and format of an alert in a template format, such as the styles and rendering for e-mail alerts. The SPAlertEventData class is a container for information about an alert event. To define alerts in a more customizable way, use the base interface IAlertNotifyHandler for handling alert-sending events and IAlertUpdateHandler for handling changes that are made to an alert's definition.
The Object Model at a Glance
Figure 2-15 shows the types closely related to the SPAlert class. Note that the SPAlert class is sealed and can be used as is.
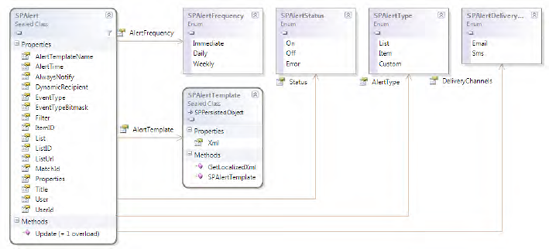
Because alerts communicate with the outside world, you need to specify a template. The templates define the layout of e-mails, along with placeholders and rules, to format the messages appropriately. Two template files, AlertTemplates.xml and AlertTemplates_SMS.xml, are located in the following folder:
%ProgramFiles%Common FilesMicrosoft Sharedweb server extensions14TemplateXML
You cannot change these files, but you can override any template with a template of your own. A stsadm command or corresponding PowerShell call overwrites the default template with your customized version, and that file is then stored in the configuration database.
If a SharePoint application provides support for business processes, a workflow can control the flow of data. SharePoint uses the Windows Workflow Foundation (WF) engine. A workflow has a trigger point where it starts and an execution engine that tracks the state. The workflow consists of activities that execute predefined or custom code. In a graphical designer, such activities are often called shapes, as they represent specific steps in the flow. Shapes clarify the workflow's behavior and meaning for businesspeople.
Workflows gather information from users and data stores while running. The UI can be any list or library, an application page, or even an InfoPath form. Forms associated with a workflow expose their data to the flow for further processing.
As with any other component, you can use the object model to work with workflows. While the underlying engine uses WF, SharePoint extends it in several namespaces:
Microsoft.SharePoint.Workflow: Contains the base classes and main entry points for developing custom workflowsMicrosoft.SharePoint.Workflow.Application: Contains three-stage workflow classes that are built into SharePointMicrosoft.SharePoint.WorkflowActions: Contains the workflow actions or activities that are included with SharePointMicrosoft.SharePoint.WorkflowActions.WithKey: Contains mirror classes that access workflows by using a string identifier
You can use the workflow designer in Visual Studio to build complex and highly customized workflows by dragging shapes onto the design surface to represent a business process. After that, they can be configured and programmed to execute specified code.
Please refer to Chapter 16 for an in-depth description.
Figure 2-16 shows the classes closely related to the SPWorkflow base classes.

Workflows are associated with a list or library that provides an action to launch the workflow. The following code defines such an association.
<Elements xmlns="http://schemas.microsoft.com/sharepoint/">
<Workflow Name="Moderation" Description="A standard WSS Moderation Workflow"
TemplateBaseId="681127D0-0919-416a-945B-05F1643C07E2"
WorkflowClass="Microsoft.SharePoint.Workflow.SPModerationWorkflow"
WorkflowAssembly="Microsoft.SharePoint, Version=12.0.0.0,
Culture=neutral, PublicKeyToken=94de0004b6e3fcc5"
CodeBesideClass="Unused"
CodeBesideAssembly="Unused"
HostServiceClass=
"Microsoft.SharePoint.Workflow.SPModerationHostServices"
HostServiceAssembly="Microsoft.SharePoint, Version=12.0.0.0,
Culture=neutral, PublicKeyToken=94de0004b6e3fcc5"
EngineClass="Microsoft.SharePoint.Workflow.SPModerationEngine"
EngineAssembly="Microsoft.SharePoint, Version=12.0.0.0,
Culture=neutral, PublicKeyToken=94de0004b6e3fcc5" >
<Metadata>
<Instantiation_FormURN>test.urn</Instantiation_FormURN>
</Metadata></Workflow> </Elements>
A workflow is coded in an internal or custom assembly, which must reside in the GAC. You can find an in-depth description in Chapter 16.
SharePoint has APIs for more than just applications. Even administrative tasks, such as those in Central Administration or in tools like stsadm, rely on an API.
In this section you'll find the basic programming methods used for administrative functions. These include an introduction to the object model and its structure. This is accompanied by several links to the official documentation on MSDN. The types and classes discussed here are used for maintenance purposes, such as adding servers to a farm, creating sites programmatically, or checking the state of the content database.
The SharePoint object model consists of approximately 50 public namespaces (several more used internally) in a dozen assemblies that are used in SharePoint sites on the server that is running SharePoint Services. A complete list can be found here: http://msdn.microsoft.com/en-us/library/ms453225(office.14).aspx.
Namespaces and classes that support access to the whole farm, its servers, the webs, and the sites defined there are part of the administrative view. Administration utilities usually complement users by building sites and applications and maintaining them, and help administrators manage huge installations. Such tools are built using the administrative API. End user–driven applications are not likely to use such classes much. This section gives an overview of the administrative object model. In Chapter 17, we're going to show some typical administrative tasks with code examples.
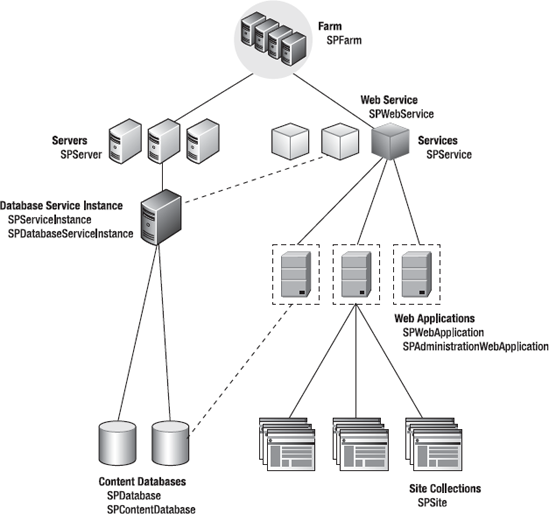
SharePoint offers a highly structured server-side object model that makes it easy to access objects that represent the various aspects of a SharePoint web site. You can drill down through the object hierarchy from higher to lower levels to obtain the object that contains the members you need to use in your code.
In this section we discuss the administrative aspects. These are the objects used to create the Central Application and several administration tools. You can use these classes to create your own tools, automate tasks, and extend the behavior of your distributed packages.
SharePoint has a two-pronged database architecture. There is one central configuration database and one or more content databases (see Figure 2-18). The configuration database contains references to such objects as
Sites
Content databases
Servers
Web applications
All objects that require persistence in the database inherit from the SPPersistedObject base class. They are stored with others in the Objects table.
Each content database exists once per web application. Sites can use multiple content databases to increase scalability. The databases store content and the following types of objects:
Service details
The structure of a site collection
User content
Files
Security information
Session state information of additional services of the Enterprise version, such as Excel services and InfoPath forms services, are also stored in a service database.
The search database is separate to improve scalability and ease of management. You set search databases through configuration. They typically contain the following:
Search data
History log
Search log
Crawl statistics data
Link tables and statistical tables
Index databases are stored in the file system and bound to the configuration database. If the configuration is part of a backup, this relationship ensures that the index files are saved too.
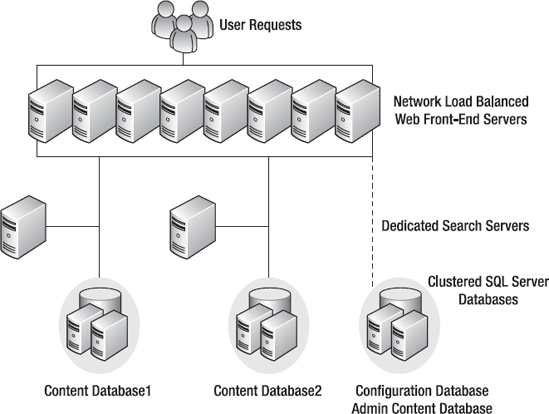
Any part of SharePoint that runs custom code has access to the database server. Therefore, several applications use their own databases to store private data. These databases can be registered in the configuration and become part of the infrastructure tasks, such as backup and restoration.
Figure 2-19 shows the SharePoint server architecture for the collections and objects of the Microsoft.SharePoint.Administration namespace.
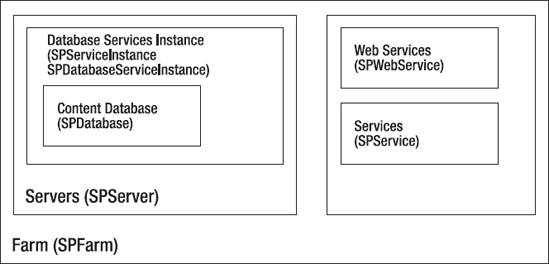
The SPFarm object is the root object within the SharePoint object model hierarchy. Its Servers property contains a collection representing all the servers in the environment, and similarly the Services property has a collection representing all the services. Each physical server computer is represented by an SPServer type. The ServiceInstances property provides access to the set of individual service instances that run on the individual computers, each as an SPService type.
Each SPService object represents a logical service or application installed in the server farm. A service object provides access to farm-wide settings of the load-balanced service that a respective service instance implements. Derived types of the SPService class include, for example, objects for Windows services, such as the timer service, search, Microsoft SQL Server, the database service, and objects for web services.
An SPWebService object provides access to configuration settings for a specific logical service or application. Its WebApplications property gets the collection of web applications that run the service.
An SPDatabaseServiceInstance object represents a single instance of a database service running on the server computer. The SPDatabaseServiceInstance class derives from the SPServiceInstance class and thus inherits the Service property, which provides access to the service or application that the instance implements. The Databases property gets the collection of content databases used in the service. The web application forms another hierarchy that parallels the physical elements (see Figure 2-20).

Each SPWebApplication object represents a load-balanced web application based on IIS. The SPWebApplication object provides access to credentials and other server farm–wide application settings. The Sites property contains the collection of sites or site collections within the web application, and the ContentDatabases property is a collection of content databases used in the web application. The SPWebApplication class replaces the obsolete SPVirtualServer class, but it can still be helpful to think of an SPWebApplication object as a virtual server—that is, a set of one or more physical servers that appear as a single server to users.
An SPContentDatabase object inherits from the SPDatabase class and represents a database that contains user data for a SharePoint web application. The Sites property gets the collection of sites or site collections for which the content database stores data, and the WebApplication property gets the parent web application.
An SPSite object represents the collection of site collections within the web application. The Item property or indexer gets a specified site collection from the collection, and the Add method creates a site collection within the collection.
You can get the current top-level server farm object as follows:
SPFarm myFarm = SPContext.Current.Site.WebApplication.Farm;
If your application does not run inside the context of a SharePoint site, you have to retrieve the Site object based on its URL:
SPSite mySiteCollection = new SPSite("AbsoluteURL");To return the top-level web site of the current site collection, use the RootWeb property:
SPWeb topSite = SPContext.Current.Site.RootWeb;
The SPContext class does not limit you to getting the current object of any given type. You can use the Microsoft.SharePoint.SPSite.AllWebs property to obtain a reference to any other web site than the current one. The following code returns the context of a specified site by using an indexer with the AllWebs property:
SPWeb webSite = SPContext.Current.Site.AllWebs["myOtherSite"];
Warning
You should explicitly dispose of references to objects obtained through the AllWebs property. There are a number of nuances to best practices with regard to when objects should and should not be disposed of. In Chapter 3 you'll find a thorough explanation about the disposal issue.
Finally, to get a reference to either the server farm or the current physical server, you can use the static properties Microsoft.SharePoint.Administration.SPFarm.Local or Microsoft.SharePoint.Administration.SPServer.Local.
SPFarm myFarm = SPFarm.Local;
To use either of the Local properties, you must add a using directive for the Microsoft.SharePoint.Administration namespace.
The following diagram shows the SharePoint site architecture in relation to the collections and objects of the Microsoft.SharePoint namespace.
Each SPSite object, despite its singular name, represents a set of logically related SPWeb objects. Such a set is commonly called a site collection, but SPSite is not a typical collection class, like SPWebCollection. Instead, it has members that can be used to manage the site collection. The AllWebs property provides access to the SPWebCollection object that represents the collection of all web sites within the site collection, including the top-level site. The Microsoft.SharePoint.SPSite.OpenWeb method of the SPSite class returns a specific web site. You'll learn later that there are numerous ways to open and access a web application.
Each site collection includes any number of SPWeb objects, and each object has members that can be used to manage a site, including its template and theme, as well as to access files and folders on the site. The Webs property returns an SPWebCollection object that represents all the subsites of a specified site, and the Lists property returns an SPListCollection object that represents all the lists in the site (see Figure 2-21).
Each SPList object has members that are used to manage the list or access items in the list. The GetItems method can be used to perform queries and retrieve items from the list. The Fields property of an SPList returns an SPFieldCollection object that represents all the fields, or columns, in the list, and the Items property returns an SPListItemCollection object that represents all the items, or rows, in the list.
Each SPField object has members that contain settings for the field. Each SPListItem object represents a single row in the list.
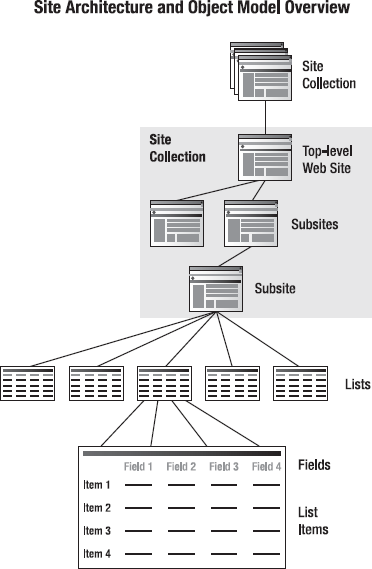
After the administration object overview, what follows is a more structured view. When working with the objects described earlier, you will see several relationships and dependencies between the objects. To understand the various hierarchies, three different conceptual views are possible:
Physical hierarchy
Content hierarchy
Services hierarchy
These views provide entry points into the object model. Some classes overlap the hierarchies and appear multiple times. Of course, they exist only once in the assemblies and namespaces. The hierarchies presented here are used only to explain the relationships between the objects.
The physical hierarchy (see Figure 2-22) contains objects that exist physically (e.g., the farm itself and the servers within the farm, as well as the folders and files containing the actual data). The farm term is always relevant, even if you have just one single server. In this case, this single server represents the farm.
The term physical object does not necessarily mean that the objects exist separately on disk. SharePoint stores all objects in the content database. You may consider a physical object as something that might exist (such as a server machine) or that can be stored elsewhere (such as a file).
The SPFarm object is the top-level object in the hierarchy. You'll quite often start here to get access to various subobjects. Running an application on one of the servers, the Local property returns the farm object:
SPFarm myfarm = SPFarm.Local;
The SPFarm class has three child classes: SPServer, which represents a single server within the farm; SPService, which gives access to the farm's services; and SPSolution, which is used to deploy something to the farm. SPFarm is closely related to the configuration database. For instance, the DisplayName property of the SPFarm object returns the name of the configuration database. Like many other objects, SPFarm inherits from SPPersistedObject, which means the object's data is persisted in the configuration database. That's the reason so many objects have static properties returning useful information without any visible connection to other objects. They simply pull the data from the configuration database. (See the section "The Database Architecture" for more information about the configuration database.)
The SPServer class represents a physical server or machine.
Note
Virtualization doesn't matter for the object model. A physical machine is everything running its own operating system, whether it's a box or just an instance of Hyper-V.
Typical properties of an SPServer object are the IP address (Address property) and the Role property. Role returns an enumeration of type SPServerRole:
As for SPFarm, the SPServer object has a static property, Local, that represents the local machine:
SPServer myserver = SPServer.Local;
Using the constructor with a server's address, you can instantiate any server's object from
SPServer myserver = new SPServer("myfarm-dev64");SPServer's ServicesInstances property returns all its services. This includes SharePoint's Windows and web services.
The content hierarchy (see Figure 2-23) contains classes that deal with the content the user stores in a SharePoint application. Most of the objects are containers that store other objects. The top level starts with the SPWebApplication class and steps all the way down to the SPField object, which contains data entered in a single field by an end user.
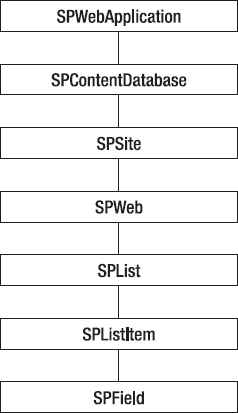
The top-level object, SPWebApplication, represents a whole application. Usually this object is directly related to at least one content database. (See the section "The Database Architecture" for more information.) SPWebApplication inherits from SPWebService, because an application is treated internally like a service. The ContentDatabases property returns a collection of content database represented by SPContentDatabase objects. Each web application is hosted in IIS; hence, the IisSettings property gives convenient access to the settings without needing a connection to IIS. Similarly, the ApplicationPool property gives access to the application pool. SPWebApplication is another object that inherits from SPPersistedObject, meaning that the object's data is persisted in the configuration database.
You can get an SPWebApplication object by different methods. Within a SharePoint application, you can use the current context:
SPWebApplication web = SPContext.Current.Site.WebApplication;
From anywhere else, such as a console application, use the following:
SPWebApplication web = new SPSite("http://myserver/site").WebApplication;You've already learned that any request is handled by an ASP.NET application and represented by an HttpApplication object. SharePoint has its own implementation, SPHttpApplication, which is tightly coupled to SPWebApplication. Each web application runs its own SPHttpApplication object.
The content stored with the features provided by a web application is held within one or more content databases. Each database object has, along with the web application object, references to one or more SPSite objects. There is no physical difference between a site and a site collection. A site collection just contains other sites. It's still exposed as an SPSite object. A collection of sites can be represented by an SPSiteCollection object. Hence, sites form a hierarchy, whose top object is called the root. To indicate the root, the RootWeb property returns true for that site. The corresponding AllWebs property returns a collection of all subsites. Besides the confusing usage of the terms web and site, the model is quite helpful for administrative tasks. The root web object has its own type, SPWeb. Even webs can form a hierarchy; therefore, an SPWeb object can contain other SPWeb objects. It can also be the child of an SPSite object.
Because site collections are just containers, they must have at least one web. This is the root web that is shown at the top of a page in the breadcrumb navigation. This tight relationship between a site collection and its root is another snag. However, at the end of the day you come down to pages. If you think in terms of pages, the SPWeb object is the final container for them. Pages are ASPX files stored in the application's content database. Pages form the representational layer on which UI objects are exposed. Pages contain Web Parts, such as grid views that show list content, and simple published content. If you drill further down from the SPWeb level, the content is not stored as pages. It's stored in lists (SPList) containing items (SPListItem) or files (SPFile), and is organized using field definitions (SPField). Items in a list that's defined as a document library can be published as pages, but that's another subject.
All services have the SPService base class. The most confusing thing here is that both Windows services and web services inherit from same base class. Moreover, the SharePoint-specific services, such as incoming e-mail, are in the same class hierarchy. This is another class that inherits from SPPersistedObject, ensuring persistence in the configuration database. The class provides members that return the assigned and currently running jobs. Most services process jobs in a queue. A service can have multiple instances. The Instances property returns them, and the SPServiceInstance class defines the objects representing an instance. An instance can be started or stopped.
Several web services support features provided by the API as well. The major difference is that web services can be used remotely. The API access is only possible if the code is executed on the target machine. The internal services that SharePoint provides can be configured in several ways. These services are
Front-end servers usually run services such as the Web Application service. Application servers with a dedicated function run the Search service, for instance. Depending on the entire farm configuration, the services spread across the farm. The criteria to let one or another service run on a specific machine depend on the expected performance and physical capabilities of the hardware. If you know that the Search service takes 80 percent of the CPU power, then it would be unwise to locate it on the same machine as the front-end server.
From the class model perspective, the services structure has five specific variants:
Windows services (
SPWindowsService)Web services (
SPWebService)Diagnostic services (
SPDiagnosticService)Outgoing E-mail services (
SPOutboundEmailService)Incoming E-mail services (
SPIncomingEmailService)
All these classes inherit from SPService.
To investigate the current configuration of all services within the farm, the following code snippet is helpful. It consists of a small console application:
SPServiceCollection services = SPFarm.Local.Services;
foreach (SPService service in services)
{
SPRunningJobCollection runningJobs = service.RunningJobs;
}Services provide specific functions. The execution can be scheduled by a job. A job can be launched by a timer—either regularly (e.g., every 12 hours) or at a specific time (e.g., Monday at 7:00 p.m.)—or triggered by an event. They execute either on one server or on several servers on the farm, depending on the purpose of the service.
This chapter provided you with the basic technologies used behind the scenes of SharePoint Foundation. Based on ASP.NET plus its Ajax implementation, SharePoint is built on top of a highly extensible platform.
The description of the building blocks lead you through the major pieces making up SharePoint. This included an overview of the various namespaces and classes for programmatic access. The subsequent chapters describe many of these classes, with examples.
An administrative overview showed the parts of SharePoint that help administrators and power users maintain the server landscape and manage settings and applications. The object model builds the foundation to create tools or extend existing ones.