
Most of the examples used to demonstrate the capabilities of conditional random fields are related to text mining, intrusion detection, or bioinformatics. Although these applications have a great commercial merit, they are not suitable for introductory test cases because they usually require a lengthy description of the model and the training process.
For our example, we will select a simple problem: how to collect and aggregate an analyst's recommendation on any given stock from different sources with different formats.
Analysts at brokerage firms and investment funds routinely publish the list of recommendations or ratings for any stock. These analysts use different rating schemes from buy/hold/sell, A/B/C rating, and stars rating, to market perform/neutral/market underperform rating. For this example, the rating is normalized as follows:
- 0 for a strong sell (F or 1 star rating)
- 1 for sell (D, 2 stars, or marker underperform)
- 2 for neutral (C, hold, 3 stars, market perform, and so on)
- 3 for buy (B, 4 stars, market overperform, and so on)
- 4 for strong buy (A, 5 stars, highly recommended, and so on)
Here are examples of recommendations by stock analysts:
- Macquarie upgraded AUY from Neutral to Outperform rating
- Raymond James initiates Ainsworth Lumber as Outperform
- BMO Capital Markets upgrades Bear Creek Mining to Outperform
- Goldman Sachs adds IBM to its conviction list
The objective is to extract the name of the financial institution that publishes the recommendation or rating, the stock rated, the previous rating, if available, and the new rating. The output can be inserted into a database for further trend analysis, prediction, or simply the creation of reports.
Note
The scope of the application
Ratings from analysts are updated every day through different protocols (feed, e-mails, blogs, web pages, and so on). The data has to be extracted from HTML, JSON, plain text, or XML format before being processed. In this exercise, we assume that the input has already been converted into plain text (ASCII) using a regular expression or another classifier.
The first step is to define the labels Y representing the categories or semantics of the rating. A segment or sequence is defined as a recommendation sentence. After reviewing the different recommendations, we are able to specify the following seven labels:
- Source of the recommendation (Goldman Sachs and so on)
- Action (upgrades, initiates, and so on)
- Stock (either the company name or the stock ticker symbol)
- From (an optional keyword)
- Rating (an optional previous rating)
- To
- Rating (the new rating for the stock)
The training set is generated from the raw data by tagging the different components of the recommendation. The first (or initial) rating for a stock does not have the labels 4 and 5 from the preceding list defined.
Consider the following example:
Citigroup // Y(0) = 1 upgraded // Y(1) Macys // Y(2) from // Y(3) Buy // Y(4) to // Y(5) Strong Buy //Y(6) = 7
A training sequence can be visualized in the following undirected graph:

An example of a recommendation as a CRF training sequence
You may wonder why we need to tag the From and To labels in the creation of the training set. The reason is that these keywords may not always be stated and/or their positions in the recommendation differ from one source to another.
The implementation of the conditional random fields follows the design template for classifiers, which is described in the Design template for immutable classifiers section under Source code considerations in the Appendix A, Basic Concepts.
Its key components are as follows:
- A
CrfModelmodel of theModeltype is initialized through training during the instantiation of the classifier. A model is an array ofweights. - The predictive or classification routine is implemented as an implicit data transformation of the
ITransformtype. - The
Crfconditional random field classifier has four parameters: the number of labels (or number of features),nLabels, configuration of theCrfConfigtype, the sequence of delimiters of theCrfSeqDelimitertype, and a vector of name of filesxtthat contains the tagged observations. - The
CrfAdapterclass interfaces with the IITB CRF library. - The
CrfTaggerclass extracts features from the tagged files.
The key software components of the conditional random fields are described in the following UML class diagram:

The UML class diagram for the conditional random fields
The UML diagram omits the utility traits and classes such as Monitor or the Apache Commons Math components.
The test case uses the IIT-B's CRF Java implementation from the Indian Institute of Technology Bombay by Sunita Sarawagi. The JAR files can be downloaded from SourceForge (http://sourceforge.net/projects/crf/).
The library is available as JAR files and source code. Some of the functionalities, such as the selection of a training algorithm, is not available through the API. The components (JAR files) of the library are as follows:
- A CRF for the implementation of the CRF algorithm
- LBFGS for limited-memory Broyden-Fletcher-Goldfarb-Shanno nonlinear optimization of convex functions (used in training)
- The CERN Colt library for the manipulation of a matrix
- The GNU generic hash container for indexing
Let's take a look at the Crf class that implements the conditional random fields classifier. The Crf class is defined as a data transformation of the ITransform type, as described in the Monadic data transformation section in Chapter 2, Hello World! (line 2):
class Crf(nLabels: Int, config: CrfConfig, delims: CrfSeqDelimiter, xt: Vector[String])//1 extends ITransform[String](xt) with Monitor[Double]{//2 type V = Double //3 val tagsGen = new CrfTagger(nLabels) //4 val crf = CrfAdapter(nLabels, tagsGen, config.params) //5 val model: Option[CrfModel] = train //6 weights: Option[DblArray] = model.map( _.weights) override def |> : PartialFunction[String, Try[V]] //7 }
The constructor for Crf has the following four arguments (line 1):
nLabels: These are the number of labels used for the classificationconfig: This is the configuration parameter used to trainCrfdelims: These are the delimiters used in raw and tagged filesxt: This is a vector of name of files that contains raw and tagged data
The Monitor trait is used to collect the profiling information during training (refer to the Monitor section under Utility classes in the Appendix A, Basic Concepts).
The V type of the output of the |> predictor is defined as Double (line 3).
The execution of the CRF algorithm is controlled by a wide variety of configuration parameters encapsulated in the CrfConfig configuration class:
class CrfConfig(w0: Double, maxIters: Int, lambda: Double, eps: Double) extends Config { //8 val params = s"""initValue $w0 maxIters $maxIters | lambda $lambda scale true eps $eps""".stripMargin }
For the sake of simplicity, we use the default CrfConfig configuration parameters to control the execution of the learning algorithm, with the exception of the following four variables (line 8):
- Initialization of the
w0weight that uses either a predefined or random value between 0 and 1 (default 0) - The maximum number of iterations,
maxIters, that is used in the computation of the weights during the learning phase (default 50) - The
lamdbascaling factor for the L2 penalty function that is used to reduce observations with a high value (default 1.0) - The
epsconvergence criteria that is used to compute the optimum values for thewjweights (default 1e-4)
Note
The L2 regularization
This implementation of the conditional random fields support the L2 regularization, as described in the Regularization section in Chapter 6, Regression and Regularization. The regularization is turned off by setting λ = 0.
The CrfSeqDelimiter case class specifies the following regular expressions:
obsDelimto parse each observation in the raw fileslabelsDelimto parse each labeled record in the tagged filesseqDelimto extract records from raw and tagged files
The code will be as follows:
case class CrfSeqDelimiter(obsDelim: String,
labelsDelim: String, seqDelim: String)The DEFAULT_SEQ_DELIMITER instance is the default sequence delimiter used in this implementation:
val DEFAULT_SEQ_DELIMITER =
new CrfSeqDelimiter(", / -():.;'?#`&_", "//", "
") The CrfTagger tag or label generator iterates through the tagged file and applies the relevant regular expressions of CrfSeqDelimiter to extract the symbols used in training (line 4).
The CrfAdapter object defines the different interfaces to the IITB CRF library (line 5). The factory for CRF instances is implemented by the apply constructor as follows:
object CrfAdapter { import iitb.CRF.CRF def apply(nLabels: Int, tagger: CrfTagger, config: String): CRF = new CRF(nLabels, tagger, config) … }
Note
Adapter classes to the IITB CRF library
The training of the conditional random field for sequences requires to define a few key interfaces:
DataSequenceto specify the mechanism to access observations and labels for training and testing dataDataIterto iterate through the sequence of data created using theDataSequenceinterfaceFeatureGeneratorto aggregate all the feature types
These interfaces have default implementations bundled in the CRF Java library [7:12]. Each of these interfaces have to be implemented as adapter classes:
class CrfTagger(nLabels: Int) extends FeatureGenerator class CrfDataSeq(nLabels: Int, tags: Vector[String], delim: String) extends DataSequence class CrfSeqIter(nLabels: Int, input: String, delim: CrfSeqDelimiter) extends DataIter
Refer to the documented source code and Scaladocs files for the description and implementation of these adapter classes.
The objective of the training is to compute the weights wj that maximize the conditional log-likelihood function without the L2 penalty function. Maximizing the log-likelihood function is equivalent to minimizing the loss with the L2 penalty. The function is convex, and therefore, any variant gradient descent (greedy) algorithm can be applied iteratively.

The training file consists of a pair of files:
- Raw datasets: Recommendations (such as Raymond James upgrades Gentiva Health Services from Underperform to Market perform)
- Tagged datasets: Tagged recommendations (such as Raymond James [1] upgrades [2] Gentiva Health Services [3], from [4] Underperform [5] to [6] Market perform [7])
The training or computation of weights can be quite expensive. It is highly recommended that you distribute the observations and tagged observations dataset across multiple files, so they can be processed concurrently:

The distribution of the computation of the weights of the CRF
The train method creates the model by computing the weights of the CRF. It is invoked by the constructor of Crf:
def train: Option[CrfModel] = Try { val weights = if(xt.size == 1) //9 computeWeights(xt.head) else { val weightsSeries = xt.map( computeWeights(_) ) statistics(weightsSeries).map(_.mean).toArray //10 } new CrfModel(weights) //11 }._toOption("Crf training failed", logger)
We cannot assume that there is only one tagged dataset (that is, a single pair of *.raw and *.tagged files) (line 9). The computeWeights method used for computation of weights for the CRF is applied to the first dataset if there is only one pair of raw and tagged file. In the case of multiple datasets, the train method computes the mean of all the weights extracted from each tagged dataset (line 10). The mean of the weights are computed using the statistics method of the XTSeries object, which was introduced in the Time series in Scala section in Chapter 3, Data Preprocessing. The train method returns CrfModel if successful, and None otherwise (line 11).
For efficiency purpose, the map should be parallelized using the ParVector class as follows:
val parXt = xt.par val pool = new ForkJoinPool(nTasks) v.tasksupport = new ForkJoinTaskSupport(pool) parXt.map(computeWeights(_) )
The parallel collections are described in detail in the Parallel collections section under Scala in Chapter 12, Scalable Frameworks.
The computeWeights method extracts the weights from each pair of observations and tagged observation files. It invokes the train method of the CrfTagger tag generator (line 12) to prepare, normalize, and set up the training set, and then invokes the training procedure on the IITB CRF class (line 13):
def computeWeights(tagsFile: String): DblArray = { val seqIter = CrfSeqIter(nLabels, tagsFile, delims) tagsGen.train(seqIter) //12 crf.train(seqIter) //13 }
Note
The scope of the IITB CRF Java library evaluation
The CRF library has been evaluated with three simple text analytics test cases. Although the library is certainly robust enough to illustrate the internal workings of the CRF, I cannot vouch for its scalability or applicability in other fields of interests, such as bioinformatics or process control.
The predictive method implements the |> data transformation operator. It takes a new observation (the analyst's recommendation on a stock) and returns the maximum likelihood, as shown here:
override def |> : PartialFunction[String, Try[V]] = { case obs: String if( !obs.isEmpty && isModel) => { val dataSeq = new CrfDataSeq(nLabels,obs,delims.obsDelim) Try (crf.apply(dataSeq)) //14 } }
The |> method merely creates a dataSeq data sequence and invokes the constructor of the IITB CRF class (line 14). The condition on the obs input argument to the partial function is rather rudimentary. A more elaborate condition of the observation should be implemented using a regular expression. The code to validate the arguments/parameters of the class and methods are omitted along with the exception handler for the sake of readability.
Note
An advanced CRF configuration
The CRF model of the IITB library is highly configurable. It allows developers to specify a state-label undirected graph with any combination of flat and nested dependencies between states. The source code includes several training algorithms such as the exponential gradient.
The client code to execute the test consists of defining the number of labels, NLABELS (that is, the number of tags for recommendation), the LAMBDA L2 penalty factor, the maximum of iterations, MAX_ITERS, allowed in the minimization of the loss function, and the EPS convergence criteria:
val LAMBDA = 0.5 val NLABELS = 9 val MAX_ITERS = 100 val W0 = 0.7 val EPS = 1e-3 val PATH = "resources/data/chap7/rating" val OBS_DELIM = ", / -():.;'?#`&_" val config = CrfConfig(W0 , MAX_ITERS, LAMBDA, EPS) //15 val delims = CrfSeqDelimiter(DELIM,"//"," ") //16 val crf = Crf(NLABELS, config, delims, PATH) //17 crf.weights.map( display(_) )
The three simple steps are as follows:
- Instantiate the
configconfiguration for the CRF (line15) - Define the three
delimsdelimiters to extract the tagged data (line16) - Instantiate and train the CRF classifier,
crf(line17)
For these tests, the initial value of the weights (with respect to the maximum number of iterations for the maximization of the log likelihood and the convergence criteria) are set to 0.7 (with respect to 100 and 1e-3). The delimiters for labels sequence, observed features sequence, and the training set are customized for the format of rating.raw and rating.tagged input data files.
The first training run discovered 136 features from 34 analysts' stock recommendations. The algorithm converged after 21 iterations. The value of the log of the likelihood for each of those iterations is plotted to illustrate the convergence toward a solution of optimum w:

The visualization of the log conditional probability of a CRF during training
The training phase converges quickly toward a solution. It can be explained by the fact that there is little variation in the six-field format of the analyst's recommendations. A loose or free-style format would require a larger number of iterations during training to converge.
The second test evaluates the impact of the size of the training set on the convergence of the training algorithm. It consists of computing the difference Δw of the model parameters (weights) between two consecutive iterations {wi}t+1 and {wi}t:
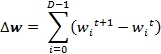
The test is run on 163 randomly chosen recommendations using the same model but with two different training sets:
- 34 analysts' stock recommendations
- 55 stock recommendations
The larger training set is a superset of the 34 recommendations' set. The following graph illustrates the comparison of features generated with 34 and 55 CRF training sequences:

The convergence of the CRF weight using training sets of different sizes
The disparity between the test runs using two different sizes of training sets is very small. This can be easily explained by the fact that there is a small variation in the format between the analyst's recommendations.
The third test evaluates the impact of the L2 regularization penalty on the convergence toward the optimum weights/features. The test is similar to the first test with a different value of λ. The following chart plots log [p(Y|X, w)] for different values of λ = 1/σ2 (0.2, 0.5, and 0.8):

The impact of the L2 penalty on the convergence of the CRF training algorithm
The log of the conditional probability decreases or the conditional probability increases with the number of iterations. The lower the L2 regularization factor, the higher the conditional probability.
The variation of the analysts' recommendations within the training set is small, which limits the risk of overfitting. A free-style recommendation format would have been more sensitive to overfitting.