
Chapter 1
The Relational Database Structure
Introduction
In this chapter you will learn about the structure of the relational database. You will also learn about database modeling and a database design technique called normalization. Read over the chapter definitions before you begin.
Definitions
Attribute — The characteristics of an entity.
Client — A single-user computer that interfaces with a multiple-user server.
Client/server database system — A database system that divides processing between client computers for data input and output, and a database server, used for data inquiries and manipulations.
Column — A field within a table.
Data modeling — The process of organizing and documenting the data that will be stored in a database.
Database — A collection of electronically stored organized files that relate to one another.
Database management system (DBMS) — A system used to create, manage, and secure relational databases.
Entity — Any group of events, persons, places, or things used to represent how data is stored.
ERD model — The Entity Relationship Diagram model is a representation of data in terms of entities, relationships, and attributes.
File — A collection of similar records.
Foreign key — A column in a table that links records of the table to the records of another table.
Keys — Columns of a table with record values that are used as a link from other tables.
Normalization — A three-step technique used to ensure that all tables are logically linked together and that all fields in a table directly relate to the primary key.
Primary key — A column in a table that uniquely identifies every record in a table.
Referential integrity — A system of rules used to ensure that relationships between records in related tables are valid.
Relational database — A collection of two or more tables that are related by key values.
Relationship — An association between entities.
Row — A record within a table.
Server — A multiple-user computer that provides shared database connection, interfacing, and processing services.
Table — A two-dimensional file that contains rows and columns.
Before we begin exploring SQL we need to step back a bit and discuss the basics of databases. Yes, much of this will be old hat to most of you, but we hope that with this short discussion we can fill a few knowledge holes before they become obstacles so everyone is on the same footing.
Early Forms of Data Storage
Before the existence of the computer-based database, information was transcribed on paper and stored in a physical file. Ideally, each file contained a separate entity of information, and was most commonly stored in either a file cabinet or card catalog system.
An organization that stored files in this manner may have, for example, had one file for personal employee information and another file for employee evaluations. If the organization needed to update an employee name, each individual file for the employee needed to be updated to maintain consistent data.
Updating files for one employee was not a big deal, but if several employee names needed to be updated, this process was very time consuming. This method of storage not only called for multiple updates among individual files, but it also took up a great deal of physical space.
With the advent of computers, the information in the files moved to databases, but the format for the databases continued to mirror the hard copy records. In other words, there was one record for each piece of information. The problems with associated hard copy records were also mirrored. Using the example above, if an employee’s name needed to be updated, each individual file of the employee had to be updated. On the other hand, searching for information was considerably faster and storage was more centralized. Files of this type are referred to as “flat” files since every record contains all there is about the entity.
As a side note, for many years Microsoft tried to sell Excel as a basic database program in addition to its primary use as a spreadsheet. All the information was stored in a single place, with each Excel row containing all the information. Columns corresponded to fields, with every record containing every field that was used. Referring to Excel as a database program ceased when Microsoft bought FoxPro and acquired a “real” database program.
The Relational Database Structure
A modern database, on the other hand, alleviates the problem of multiple updates of individual files. The database enables the user to perform a single update across multiple files simultaneously. A database is a collection of organized files that are electronically stored. The files in a database are referred to as tables.
We come in contact with databases every day. Some examples of databases include ATMs, computer-based card-catalog systems at a library, and numerous Internet features including order forms and catalogs of merchandise.
The most popular and widely implemented type of database is called a relational database. A relational database is a collection of two or more tables related by key values.
Tables
We refer to the tables in a database as two-dimensional files that contain rows (records) and columns (fields). The reason we say that tables are two-dimensional is because the rows of a table run horizontally and the columns run vertically, hence two dimensions. Take a look at Figure 1-1.

Figure 1-1. A blank table
Figure 1-1 shows an unpopulated (empty) table with five columns and six rows. Each row in the table represents an individual record and each column represents an individual entity of information. For example, a table named Customers could have the following seven entities (columns) of information: First Name, Last Name, Address, City, State, Zip, and Phone. Each customer entered into the Customers table represents an individual record.
Keys
To create a relationship between two tables in a relational database you use keys. Keys are columns in a table that are specifically used to point to records in another table. The two most commonly used keys during database creation are the primary key and the foreign key.
The primary key is a column in a table that uniquely identifies every record in that table. This means that no two cells within the primary key column can be duplicated. While tables usually contain a primary key column, this practice is not always implemented. The absence of a primary key in a table means that the data in that table is harder to access and subsequently results in slower operation. On the other hand, tables with very few entries will often not be indexed. This is especially true if the value is not used for searches or lookups. A table with three values of single, married, and divorced might not be indexed, although a table that uses this information, like an employee table, would definitely index on this field.

Figure 1-2. Employees table
Figure 1-2 shows a table named Employees. The SocialSecNum column is the primary key column in the Employees table. Since no two people can have the same social security number, social security numbers are commonly used as a primary key. As you can see, the SocialSecNum column uniquely identifies every employee in the Employees table.
The foreign key is a column in a table that links records of one type with those of another type. Foreign keys create relationships between tables and help to ensure referential integrity. Referential integrity ensures that every record in a database is correctly matched to any associated records. Foreign keys help promote referential integrity by ensuring that every foreign key within the database corresponds to a primary key.
Every time you create a foreign key, a primary key with the same name must already exist in another table. For example, the SocialSecNum column is used to link the Employees table in Figure 1-2 to the Departments table in Figure 1-3.
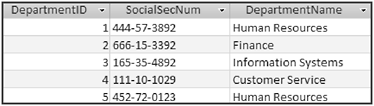
Figure 1-3. Departments table
The SocialSecNum column is a primary key column in the Employees table and a foreign key column in the Departments table. Notice that the Departments table in Figure 1-3 also contains its own primary key column named DepartmentID.
The Planning Stage
Before creating a database, careful planning must go into its design. Careful planning in the beginning can save you many headaches in the future such as major restructuring of the tables or a total redesign! You should begin by asking yourself and the users several key questions concerning the database system. Among other questions, find out who will use the database, what the users need from the database, and what information the database will store.
Side Note: Actually it is not really a good idea to use a social security number as a primary key, as one of the authors discovered during two different database projects. One of the qualities of a primary key is that the value should not change. In the case of one employee database, the client had employees who would periodically show up with a new, different social security card and request that all of their records be changed! Since the social security number was used in multiple tables as the linking field, the user had to carefully go through the entire database and make changes. One slipup and database integrity went out the window. In another case, a database of patients was created, only to find that many of the patients did not have social security numbers. We had to artificially generate special, unique numbers to compensate for the lack of social security numbers.
Data Modeling
You should also utilize data modeling techniques to better understand how the data will be represented in the database. Data modeling organizes and documents the data that will be stored in the database. It provides a graphical representation of the structure of the database and how data will be represented in the database. Understanding how data will be represented in the database will help you avoid storing redundant or insufficient data. Data modeling can be done either on a plain sheet of paper or with specialized software.
Entities and Relationships
One widely implemented data model is called the Entity Relationship Diagram, or ERD model. The ERD model represents data in terms of entities and relationships. An entity is any group of events, persons, places, or things used to represent how data is stored. You can think of an entity as a table stored in a database. A relationship is an association between entities. Additionally, the model demonstrates the attributes, or the characteristics, of the entities. You can think of attributes as the columns in a table. For example, the entity Employee can have the following attributes: Name, Address, Phone Number, and Email.
There are four types of relationships among entities: one-to-one relationship, one-to-many relationship, many-to-one relationship, and many-to-many relationship.
An ERD model graphically depicts relationships by use of shapes, numbers, letters, and lines. Rectangles represent entities. Diamonds combined with letters above lines that connect to the rectangles represent relationships. Using the most basic style of relationship notation, the number 1 represents one and the letter M represents many. Attributes in an ERD are represented by ovals.
Figure 1-4 represents a one-to-one relationship within an organization. It illustrates that one computer is assigned to a single employee. A single employee has one computer.

Figure 1-4. One-to-one relationship
Figure 1-5 represents a one-to-many relationship within an organization. The diagram illustrates that many customers conduct business transactions with the same employee. Each employee has many customers while every customer has a single employee to work with.

Figure 1-5. One-to-many relationship
Figure 1-6 represents a many-to-one relationship within an organization. The diagram illustrates that one department contains many employees. Many employees belong to one department.

Figure 1-6. Many-to-one relationship
Probably the most common and most useful relationship is the many-to-many, where multiple items of one group are associated with multiple items of a second group. Think in terms of a school with many classes and many students, which is illustrated in Figure 1-7. Each student is a member of many classes. Each class has many students. You can achieve the same overall result with two one-to-many relationships (many students to one class and many classes for each student), but the data is far more useful when viewed as a single relationship. By thinking of the information as a single relationship, you eliminate the need for multiple storage receptacles for the information and you improve on the ways you can look at the data.

Figure 1-7. Many-to-many relationship
Normalization
Another widely implemented technique used in the planning stage of database creation is called normalization. Normalization is a three-step technique used to ensure that all tables are logically linked together and that all fields in a table directly relate to the primary key.
In the first phase of normalization, you must identify repeating groups of information and create primary keys. For example, the following column names represent columns in a table named Products: Cashier ID, Product Name, Product Description, Product Price, Order ID, Order Date, and Cashier Name. Notice that the column names contain repeating groups of information and there is no primary key assigned. To complete the first form of normalization, eliminate the Cashier ID and Cashier Name columns since they represent a separate group of information and would be better suited in another table. Additionally, assign a primary key to the Products table. Now the columns for the Products table would look something like the following: Product ID, Product Name, Product Description, Order ID, Order Date, and Product Price.
In the second phase of normalization, you need to take another look at your column names to make sure that all columns are dependent on the primary key. This involves eliminating columns that may be partially in the same group, but not totally dependent on the primary key. Since the Order ID and Order Date columns are concerned with a customer’s order as opposed to the actual product information, they are not dependent on the primary key. These columns should be removed and placed in another table, perhaps one named Orders. Now the Products table should contain the following columns: Product ID, Product Name, Product Description, and Product Price.
In the third phase of normalization, you need to reexamine your columns to make sure each column is dependent on the primary key. Consider creating additional tables to eliminate non-dependent primary key columns, if necessary. Since the Products table contains columns that are all dependent upon the primary key, there is no need to further alter the columns for the Products table. Once all of your tables are normalized, you can begin to link tables by assigning foreign keys to your tables.
Client/Server Databases
As stated earlier in the chapter, databases alleviate the need to have multiple updates of individual files. Another great aspect of the database is that data can also be accessed simultaneously by more than one user. This is called a client/server database. A client/server database system divides processing between client computers and a database server, enabling many users to access the same database simultaneously. In addition, each machine in the system can be optimized to perform its specific function. This results in far greater efficiency, speed, and database stability.
The client is a single-user computer that interfaces with a multiple-user server. The server is a multiple-user computer that stores the database and provides shared database connection, interfacing, and processing services. You can think of a client as any of the many single-user computers that access the Internet. A server can be thought of as America Online’s server, which thousands of people access to connect to the Internet.
Database Management Systems
Databases are created using software programs called database management systems (DBMSs). DBMSs are specifically used to create, manage, and secure relational databases. The specific duties of a DBMS include the following: create databases, retrieve data, modify data, update data, generate reports, and provide security features. The most widely used DBMSs are Microsoft Access, Oracle, Microsoft SQL Server, DB2, Sybase, FileMaker, and MySQL. Most DBMSs employ a nonprocedural database programming language called SQL to help in the administration of databases. Chapter 2 discusses SQL in greater detail.
Summary
In this chapter, you learned about the early forms of data storage and the relational database structure. You learned about primary and foreign keys and about implementing data modeling techniques and normalization in the planning stage of database design. You also learned about client/server databases and about database management systems (DBMSs).
Quiz 1
1. True or False. Normalization is a three-step technique used to ensure that all tables are logically linked together and that all fields in a table directly relate to the primary key.
2. True or False. A relational database is a collection of one or more tables that are related by key values.
3. True or False. A table is a two-dimensional column that contains files and fields.
4. True or False. A foreign key is a column in a table that links records of one database with those of another database.
5. True or False. A primary key is a column in a table that uniquely identifies every record in that table.