
Chapter 20
Leveraging big data and machine learning
The enterprise data warehouse may be the center of the business intelligence universe in many organizations, but it does not always meet the needs of every end user. Making changes to existing data warehouse processes comes at a high cost in both time and effort. In recent years there has also been a proliferation of data across organizations in a variety of forms.
In this chapter we begin with the trends around big data. Then we delve into how those trends, along with widespread adoption of container-based deployment, have helped Microsoft build a big data solution into SQL Server 2019.
Big Data Clusters (BDC) is an exciting new introduction to the big data landscape with SQL Server. Bringing together relational and non-relational data and using T-SQL for querying, BDC allows users to perform the analysis they need while minimizing the amount of data movement needed to gain those insights. The key part of the infrastructure is built on top of Kubernetes, so having a good understanding of this modern container orchestration system is to your advantage.
 Refer to Chapter 3, “Designing and implementing an on-premises database infrastructure” to learn more about Kubernetes.
Refer to Chapter 3, “Designing and implementing an on-premises database infrastructure” to learn more about Kubernetes.
The next section covers operationalizing analytics with Machine Learning Server, and will detail the installation, configuration, and operationalization of machine learning models.
This chapter also provides you with information about Microsoft machine learning and other big data features that are relevant for a DBA. You can determine what services to use and when to use them based upon what you want to achieve. The goal is to understand what objects are needed and what to request to support deployments of machine learning and big data solutions.
A big data primer
Traditional data processing uses extract, transform and load (ETL) tools like SQL Server Integration Services (SSIS), and internal SQL Server tools like transactional replication or linked servers. At the same time, business users are demanding that organizations evolve rapidly into a world far beyond relational databases, whether it’s JSON data from a company’s mobile app going into a MongoDB database, or a data lake consisting of large pools of data running on the Hadoop Distributed File System (HDFS). This is the realm of big data. Far from being a buzzword, big data refers to data sets that are too large to be processed by traditional tools, including relational database systems like SQL Server. The practile effects of big data along with the question of how to integrate data from disparate systems, are a longstanding challenge across IT organizations and are the challenge being met by BDC.
Introducing MapReduce with Hadoop and HDFS
Big data systems like Hadoop and Spark reduce the effort of ETL processes by applying a schema to data only when it is read, which allows for changes without moving large volumes of data around.
The lack of data movement combined with the horizontal scale of big data systems allows for the processing of petabytes of data. Some of the common Hadoop use cases include fraud detection for banks, firms analyzing semi-structured data from social media and mobile apps, and a batch processing center for data from Internet of Things (IoT) devices. It is important to remember that Hadoop was designed as a batch processing system—for the most part, even in well-tuned systems, large scans are performed as part of Hadoop’s MapReduce (shuffle and sort) processing.
Architecturally, Hadoop consists of two core components: the processing power that performs the MapReduce processes, and schedules and manages work in the cluster; and Hadoop Distributed File System (HDFS), which is the storage component. HDFS is a distributed file system that provides redundant storage space for very large files. To ensure reliability, files are separated into large blocks (64 to 128 MB in size) and distributed across nodes in a given cluster. Each block is also replicated to three nodes by default (this setting is configurable), so that in the event of a node going down, data can be retrieved from the other two nodes.
Note
HDFS is used more broadly than in just Hadoop clusters as you will see in the following sections. It has become the de facto standard for big data storage.
Introducing distributed memory with Spark
Spark is another open source project and is now a part of Apache Spark, which makes use of in-memory processing on its data nodes. Hadoop clusters are designed to execute large sequential I/O operations, while Spark leverages heavier memory utilization to deliver better performance. Because of this better performance, Spark has become popular for many workloads that were formerly processed by Hadoop.
Some common use cases for Spark include processing streaming data from IoT sensors, streaming ETL processes, machine learning, and general interactive querying because of the performance Spark offers. Spark has an active community of developers and offers a rich set of libraries and APIs to execute machine learning processes using Python.
Caution
Managing Spark clusters has traditionally been a challenge, even for mature organizations. Offerings like Databricks aim to reduce this complexity by making Spark available in a PaaS solution using automated cluster management.
Spark supports multiple storage engines including HDFS, HBase (which runs on top of HDFS), Solr (which provides search support), and Apache Kudu (a tabular storage model).
Introducing Big Data Clusters
A major challenge facing many organizations is moving data between systems. This is because ETL processes are complicated to build, and because of this complexity they can be expensive both in terms of resources and performance to change. In recent years data virtualization has become a buzzword in the industry, to help mitigate the complexity of ETL efforts. Data virtualization is the process of using data, while it stays in its original location. The process minimizes and the need for complex extract, transform, load (ETL) processes. The BDC provides the tools to provide a few key elements:
Abstraction. Technical details about the data are abstracted from the consumer.
Virtualized access. A common data point to deliver access to an array of data sources.
Transformation. Either prebuilt transformations or easy to use simple transforms like those built in the Excel Power Query plugin.
Data federation. Combines results from multiple sources.
Data delivery. Delivers data results as views and/or data services accessible to users or client applications.
Microsoft added the PolyBase feature to SQL Server 2016 to address some data virtualization concerns. Customers found the licensing and configuration to be complex, limiting the adoption. In the Azure Synapse, formerly Azure SQL Data Warehouse, offering it was widely adopted because it allowed users to consume text and parquet files of various formats and define external tables on them. These external tables are a virtual schema imposed on a file, which allows the file to be read and consumed by the Database Engine. The load pattern was to first load files to storage, create an external table on those files, and then insert the data from the virtual tables into a regular database table. In Synapse this allows for a massively parallel load process.
In an effort to increase adoption, and because the feature set of Big Data Clusters requires it, PolyBase has been revamped for SQL Server 2019. The original implementation of PolyBase for SQL Server supported Hadoop and text files in Azure Blob Storage. The new implementation builds on that support by adding Oracle, Teradata, and MongoDB support. PolyBase can also be used to connect SQL Servers to each other, with the limitation that PolyBase is not supported in Azure SQL database.
Bringing all of these trends and information together, Microsoft started a development path of building a fully integrated data virtualization solution using PolyBase, Kubernetes, and modern scale-out architecture, resulting in Big Data Clusters.
Big Data Clusters technical overview
The Big Data Cluster (BDC) technology is designed to give users a common entry point to all data needed for analysis, and to reduce the friction of bringing in new data sources. It offers a common security layer (via SQL Server and Apache Knox) and reduces data latency, allowing users to perform analysis on more recent data. It also takes advantage of the machine learning features built into the Database Engine to support R, Python, and Java.
A look at BDC architecture
Big data clusters are built on Kubernetes, and implemented as a cluster of containers. The nodes in the cluster are divided into three logical planes: the control plane, the compute plane, and the data plane. Each of these planes serve a different set of functionalities in the cluster as shown in Figure 20-1.

Figure 20-1 BDC architectural diagram.
The BDC control plane
The control plane performs a few functions. The first and most important is that it contains the SQL Server master instance and the SQL proxy. The master instance provides a secure endpoint (using TDS, the protocol used by SQL Server) for users to connect to using the tool of their choice. The master instance also contains the scale-out query engine that is used by PolyBase to distribute queries across all of the SQL Server instances in the compute pool(s). This instance also contains the cluster metadata, the HDFS table metadata (beyond what is stored in the Hive metastore), and a data plane shard map. SQL Server Machine Learning services are also available in the master instance, so you can execute R and Python jobs using sp_external_script.
BDC makes use of Hive, which is an Apache project for building tables on top of data stored in Hadoop, as well as Knox, an application gateway for interacting with Hadoop through the use of its APIs. Hive and Knox metadata are both stored in the control plane. Finally, Grafana and Kibana are both open source tools used to monitor your cluster.
The control plane also includes a controller service, which connects SQL Server, Kubernetes, Spark, and HDFS to each other. That service is deployed from a command line utility called azdata, which provides cluster management functions. The controller service performs the following functions:
Manages cluster lifecycle, including cluster bootstrap, delete, and configuration updates
Manages master SQL Server instances
Manages compute, data, and storage pools
Exposes monitoring tools to observe the state of the cluster
Exposes troubleshooting tools to detect and repair unexpected issues
Manages cluster security, ensuring secure cluster endpoints, managing users and roles, configuring and storing credentials for intra-cluster communication
Manages the workflow of upgrades to services in the cluster so that they are implemented safely
Manages high availability of the stateful services in the cluster
All communication using the controller is performed using a REST API over HTTPS. A self-signed certificate is created at the time of cluster creation along with the username and password for the controller.
The BDC compute plane
The compute plane, as its name suggests, provides computation resources to the cluster. It contains a number of Kubernetes pods running SQL Server on Linux and base services for cluster communications. This plane is divided into task-specific pools. The pool can act as a PolyBase scale-out group to help the performance of large PolyBase queries against sources like Oracle, Teradata, or Hadoop.
The BDC app pool
The application pool (part of the compute plane) is composed of a set of pods that hold multiple end-points for access to the overall cluster. SQL Server Integration Services is one example of an application available in this pool that can be run as a containerized application. A potential use case for a pool would be for a long-running job (for example, IoT device streaming) or machine learning endpoint. The pool could be used for scoring a model or returning an image classification.
The BDC data plane
The data plane is made up of two specific types of nodes:
Data pool. This node type runs SQL Server on Linux, and is used to ingest data from T-SQL queries or Spark jobs. To provide better performance, the data in the data pool is sharded across all of the SQL Server instances in the data pool and stored in columnstore indexes.
Storage pool. This node type is made up of SQL Server, HDFS, and Spark pods, which are all members of an HDFS cluster. It is also responsible for data ingestion through Spark and provides data access through HDFS and SQL Server endpoints.
Note
Sharding is a term for partitioning data across databases and is similar to the sharding feature in Azure SQL Database. It separates very large databases into smaller parts called shards. The smaller parts allow shards to be handled individually making the whole easier to manage and faster. This feature requires a shard map to be in place, which is provided by the BDC control plane.
Deploying Big Data Clusters
A Kubernetes infrastructure is a requirement for BDC deployment; however, you have several options to help you get Kubernetes in your cluster up and running. The following options are currently supported:
A cloud platform such as Azure Kubernetes Service (AKS)
On-prem/IAAS Kubernetes deployments using
kubeadmMinikube for training and testing purposes
If you are using AKS for your cluster, you should have the Azure Line Interface (Azure CLI) installed on your management machine, as well as kubectl for Kubernetes administration. Additionally, management access to the cluster is provided by Azure Data Studio.
No matter which approach you take for deploying your infrastructure, building the cluster is quite easy. You have to first install the azdata utility on the administration machine (not needed to be part of the Kubernetes cluster) and then run the following command:
azdata bdc create
This command will take you through a series of prompts to choose your target Kubernetes environment, which will prompt you for a series of usernames and passwords for the following accounts listed in Table 20-1.
Table 20-1 Accounts required for cluster services.
Accounts |
Description |
|---|---|
DOCKER_USERNAME |
The username to access the container images in case they are stored in a private repository. |
DOCKER_PASSWORD |
The password to access the above private repository. |
CONTROLLER_USERNAME |
The username for the cluster administrator. |
CONTROLLER_PASSWORD |
The password for the cluster administrator. |
KNOX_PASSWORD |
The password for Knox user. |
MSSQL_SA_PASSWORD |
The password of SA user for SQL master instance. |
These can be setup as environment variables using either bash or PowerShell to automate this processing.
- If you are using AKS, Microsoft has fully automated the deployment process with a Python script available at https://raw.githubusercontent.com/Microsoft/sql-server-samples/master/samples/features/sql-big-data-cluster/deployment/aks/deploy-sql-big-data-aks.py.
- To deploy with active directory mode, step-by-step instructions are available from books online at https://docs.microsoft.com/sql/big-data-cluster/deploy-active-directory.
Configuring BDC storage
BDC relies on the persistent volumes feature in Kubernetes to persist data. Kubernetes also supports the Network File System (NFS), which can be used for backup storage. You can define storage classes within your Kubernetes cluster. In AKS there are multiple classes of storage based on redundancy or, you can create your own storage classes within AKS. kubeadm does have predefined storage classes and you will have to define them in order to provision volumes. You should think of these storage classes like tiers in a storage area network (SAN). You will want your actively used data to be stored on low latency storage, most likely solid-state drives (SSD), particularly in the public cloud. These classes will also be used for dynamic storage provisioning, such as when a data file is growing rapidly.
- Refer to Chapter 3 to learn more about types of storage.
Big Data Clusters security
One of the benefits of the BDC architecture is a seamless security implementation. Security is executed via normal SQL Server security, and access control lists (ACLs) in HDFS, which associate permissions with the users identity. HDFS supports security controls by limiting access to service APIs, HDFS files, and execution of jobs. This limitation makes the following end points important to understanding security and ensuring the access you need.
There are three key endpoints to the BDC:
HDFS/Knox gateway. This is an HTTPS endpoint that is used for accessing webHDFS and other related services.
Controller endpoint. This is the cluster management services that exposes APIs for cluster management and tooling.
Master instance. This is the TDS endpoint for database tools and applications to connect to SQL Server.
As of this writing, there are no options for opening other ports in the cluster. Cluster endpoint passwords are stored as Kubernetes secrets. The accounts that get created at cluster deployment are detailed in Table 20-1, however, there are a number of additional SQL logins that are created. A login is created in the controller SQL instance that is system-managed and has the sysadmin role. Additionally, a sysadmin login is created in all SQL Server instances in the cluster, which is owned and managed by the controller. This login performs administrative tasks such as High Availability (HA) setup and upgrades, and it is also used for intra-cluster communication between SQL instances (see Figure 20-2).

Figure 20-2 Big Data Clusters endpoint architecture.
Benefits of PolyBase
As mentioned earlier, PolyBase is a feature now expanded with the Big Data Cluster architecture. There are four key scenarios that best use PolyBase in SQL Server:
Parallelized import of data into SQL Server
Joining multiple data sources in a single query
Eliminating data latency and reducing the need for multiple copies of data
Archiving data to alternate storage
To understand the difference between PolyBase on a stand-alone server compared to a big data cluster, look at these features detailed in Figure 20-3.

Figure 20-3 Big Data Cluster Features.
Unified data platform features
Apache Spark joined SQL Server and HDFS in SQL Server 2019, and is referred to as just Spark. This was done to extend the functionality to easily integrate and analyze data of all types in a single integrated solution. This expands the surface area of SQL Server to cover more big data options. The expansion includes HDFS, Spark, Knox, Ranger, and Livy, which all come packaged together with SQL Server. They can also be deployed as Linux containers on Kubernetes.
HDFS tiering
HDFS tiering is similar to PolyBase in that it allows you to access external data. HDFS tiering allows you to mount file systems that are compatible with HDFS. This includes Azure Data Lake Storage Gen2 and Amazon S3. This feature is only available in a big data cluster.
The benefit of tiering is that it allows seamless access to the data as though it was mounted locally. Only the metadata is copied over to your local database. The data is copied on demand when accessed. This allows Spark jobs and SQL queries to be executed as though they are being run on local HDFS systems.
The file mounts are read-only, and directories or files cannot be added or removed through the mount. If the location of a mount changes, the mount must be deleted and recreated. The mount location is not dynamic.
Note
Detailed steps to connect to Azure Data Lake Storage can be found in the Microsoft Docs at https://docs.microsoft.com/sql/big-data-cluster/hdfs-tiering-mount-adlsgen2#use-oauth-credentials-to-mount.
Detailed steps to connect to Amazon S3 are found at https://docs.microsoft.com/sql/big-data-cluster/hdfs-tiering-mount-s3.
The Spark connector
One of the more common ways of cleaning, analyzing, and processing data is in Spark. To make this process easier, two new connectors have been introduced in SQL Server 2019. The Spark to SQL connector uses JDBC to write data to the SQL Server. A sample of how this connector is used can be found at https://github.com/microsoft/sql-server-samples/blob/master/samples/features/sql-big-data-cluster/spark/data-virtualization/spark_to_sql_jdbc.ipynb
The second connector is the MSSQL Spark connector. This connector uses SQL Server Bulk copy APIS to write data to SQL Server. A sample of the connector code in use can be found at https://github.com/microsoft/sql-server-samples/blob/master/samples/features/sql-big-data-cluster/spark/data-virtualization/mssql_spark_connector_non_ad_pyspark.ipynb.
Shared access signatures
As the name suggests, a shared access signature (SAS) is a way to share an object in your storage account with others without exposing your account key. This gives you granular control over the access you grant. This can be done at the account, service, or user level.
You can set a start time and expiry time
Blob containers, file shares, queues and tables are all resources that accept SAS policies
You can set an optional IP address or range from which access will be accepted
You can restrict access from HTTPS clients by specifying the accepted protocol
Note
It is best practice to never share your account key. Think of it like a password on your bank account. Never distribute it or leave it in plain text anywhere, and regenerate it if you believe it has been compromised, just like you would a password. It is recommended that you use Azure Active Directory (AAD) for all your blob and queue storage applications. For more details on that see the Microsoft Docs at https://docs.microsoft.com/azure/storage/common/storage-auth-aad.
Shared access signatures (SAS) are used to allow clients to read, write, or delete data in your storage account without access to your account key. This is typically needed when a client wants to upload large amounts of data or high-volume transactions to your storage account, and creating a service to scale and match demand is too difficult or expensive. The SAS is a signed URI that points to resources and includes a token that contains a set of query parameters (token) that indicate how the resource can be accessed. Azure Storage checks both the storage piece and the provided token piece of the SAS URI to verify the request. If for any reason the SAS is not valid, it receives an error code 403 (Forbidden) and access is denied.
There are two different types of SAS:
The Service SAS delegates access to a resource in a single storage service (blob, queue, table, or file service).
The Account-level SAS delegates access to resources in one or more storage services within a storage account. This also includes the option to apply access to services such as Get/Set Service Properties and Get Service Stats.
For details on all the parameters that can be set with Shared access signatures at https://docs.microsoft.com/azure/storage/common/storage-dotnet-shared-access-signature-part-1#shared-access-signature-parameters.
An ad hoc SAS can be created either as an account SAS or service SAS, and the start time, expiry time, and permissions are all specified in the SAS URI. An SAS with a stored access policy is defined on a resource container and can be used to manage constraints on one or more SAS. When the SAS is associated with a stored access policy, it inherits the constraints defined for the stored access policy.
Any SAS access attributes egress costs to your Azure Subscription. The data that is uploaded with a SAS is not validated in any way, so a middle tier that performs rule validation, authentication and auditing may still be the better option. Regardless of what you choose, monitor your storage for spikes in authentication failures.
Examples of how to create account and service SAS can be found at https://docs.microsoft.com/azure/storage/common/storage-dotnet-shared-access-signature-part-1#sas-examples.
Note
Machine Learning Services and PolyBase are the key features of this section that have specific installation needs or prerequisites before starting. Azure Machine Learning Service is used to build, train, write code, or manage deployed models. The key to this is the Azure Machine Learning service workspace. The details on how to install it based on different methods can be found at https://docs.microsoft.com/azure/machine-learning/service/setup-create-workspace.
The Azure Machine Learning SDK for Python method is used in the accompanying example available for download at https://www.MicrosoftPressStore.com/SQLServer2019InsideOut/downloads
PolyBase installation is now available on Linux in SQL Server 2019, and the details for installing it on either Windows or Linux is in Chapter 5: “Installing and configuring SQL Server on Linux.”
Installation
With SQL Server 2019, PolyBase is available on Linux as well as Windows. The virtues and architecture of big data clusters were discussed earlier in this chapter. In this section we look at the installation and application of the PolyBase concepts.
Installation instructions for Windows can be found at https://docs.microsoft.com/sql/relational-databases/polybase/polybase-installation.
When installing on a Windows machine keep these items top of mind:
PolyBase can be installed on only one instance per machine
To use PolyBase you need to be assigned the sysadmin role or Control Server permission
All nodes in a scale-out group need to run under the same domain account
You must enable the PolyBase feature after installation
If the Windows firewall service is running during installation, the necessary firewall rules will be set up automatically
For step-by-step instructions on how to install PolyBase on Linux (Red Hat, Ubuntu, or SUSE) at https://docs.microsoft.com/sql/relational-databases/polybase/polybase-linux-setup.
As with Windows, you must enable the PolyBase feature after installation on Linux.
Note
The only way to change the service accounts for the PolyBase Engine Service and Data Movement Service is to uninstall and reinstall the PolyBase feature.
If you are connecting to Hadoop specifically, there are a few additional steps needed for configuration and security. Please follow the steps listed at https://docs.microsoft.com/sql/relational-databases/polybase/polybase-configure-sql-server.
With the installation complete the next steps are:
Configure sources
Enable access
Create External Tables
Configure and enable
A master key is a symmetric key used to protect other keys and certificates in the database. It is encrypted with both an algorithm and password. A master key is needed for protecting the credentials of the external tables. Details on how to create and update a master key, and the instructions to set it up, can be found in this chapter in the section called External Tables.
Along with the master key you will need to configure PolyBase globally using sp_configure. The configvalue can range from 0 to 7 with 1 through 6 dealing with the older versions of Hortonworks. Setting 7 allows for connectivity with more recent versions on both Windows and Linux as well as Azure Blob Storage. As you usually do after running the sp_configure command, RECONFIGURE needs to be run and a restart of SQL Server service needs to be completed. The PolyBase services will both have to be started manually as they are automatically turned off during this process and do not start automatically.
This can be done with these commands:
exec sp_configure @configname = 'polybase enabled', @configvalue = 1; exec sp_configure @configname = 'hadoop connectivity', @configvalue = 7; RECONFIGURE [ WITH OVERRIDE ] ;
You can find details on the command on Microsoft Docs at https://docs.microsoft.com/sql/database-engine/configure-windows/polybase-connectivity-configuration-transact-sql.
Database scoped credential
Scoped credentials are used to access non-public Azure blob storage accounts from SQL Server or Azure Synapse with PolyBase. Hadoop clusters secured with Kerberos that are accessed from SQL Server with PolyBase also require scoped credentials.
Syntax for creation of scoped credentials can be found in the Microsoft Docs at https://docs.microsoft.com/sql/t-sql/statements/create-database-scoped-credential-transact-sql.
Note
If your SAS key value begins with a ‘?’ be sure to remove the leading ‘?’ because it is not recognized. Ensure you have already set up a master key. The master key will be used to protect these credentials. If you do not yet have a master key, the instructions to set it up can be found in the section called External Tables.
External data source
External data sources are used to establish connectivity to systems outside of SQL Server for data virtualization or loading data using PolyBase. The most common use cases are loading data with bulk insert or openrowset activities or access to data that would otherwise not be available in SQL Server because it resides on another system such as Hadoop.
The following example shows how to load data from a CSV file in an Azure blob storage location, which has been configured as an external data source. This requires a database-scoped credential using a shared access signature.
-- Create the External Data Source
-- Remove the ? from the beginning of the SAS token
-- Do not put a trailing /, file name, or shared access signature parameters at the end
of the LOCATION URL when configuring an external data sources for bulk operations.
CREATE DATABASE SCOPED CREDENTIAL AccessPurchaseOrder
WITH
IDENTITY = 'SHARED ACCESS SIGNATURE'
, SECRET = '******srt=sco&sp=rwac&se=2017-02-01T00:55:34Z&st=2016-12-
29T16:55:34Z***************'
;
CREATE EXTERNAL DATA SOURCE ExternalPurchaseOrder
WITH
(LOCATION = 'https://newinvoices.blob.core.windows.net/week3'
,CREDENTIAL = AccessPurchaseOrder, TYPE = BLOB_STORAGE)
;
--Insert into
BULK INSERT Sales.Orders
FROM 'order-2019-11-04.csv'
WITH (DATA_SOURCE = ' ExternalPurchaseOrder');
Note
Ensure you have at least read permission on the object that is being loaded, and that the expiration period is valid (all dates are in UTC time). A credential is not needed if the Blob storage has public access.
External file format
The external file format is required before you can create the external table. As suggested, the file format specifies the layout of the data to be referenced by the external table. Hadoop, Azure Blob Storage, and Azure Data Lake Storage all need an external file format object defined for PolyBase. Delimited text files, Parquet, and both RCFile and ORC Hive files are supported.
An example is:
CREATE EXTERNAL FILE FORMAT skipHeader_CSV
WITH (FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS(
FIELD_TERMINATOR = ',',
STRING_DELIMITER = '"',
FIRST_ROW = 2,
USE_TYPE_DEFAULT = True)
)
Syntax for this command can be found at https://docs.microsoft.com/sql/t-sql/statements/create-external-file-format-transact-sql.
External table
External tables are used to read specific external data and to import data into SQL Server. No actual data is moved to SQL Server during the creation of an external table, only the metadata along with basic statistics about the folder and file are stored. The intent of the external table is to be the link connecting the external data to SQL Server to create the data virtualization. The external table looks much like a regular SQL Server table in format and has a similar syntax as you see here with this external Oracle table.
-- Create a Master Key CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password'; CREATE DATABASE SCOPED CREDENTIAL credential_name WITH IDENTITY = 'username', Secret = 'password'; -- LOCATION: Location string for data CREATE EXTERNAL DATA SOURCE external_data_source_name WITH ( LOCATION = 'oracle://<server address>[:<port>]', CREDENTIAL = credential_name) --Create table CREATE EXTERNAL TABLE customers( [O_ORDERKEY] DECIMAL(38) NOT NULL, [O_CUSTKEY] DECIMAL(38) NOT NULL, [O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL, [O_TOTALPRICE] DECIMAL(15,2) NOT NULL, [O_ORDERDATE] DATETIME2(0) NOT NULL, [O_ORDERPRIORITY] CHAR(15) COLLATE Latin1_General_BIN NOT NULL, [O_CLERK] CHAR(15) COLLATE Latin1_General_BIN NOT NULL, [O_SHIPPRIORITY] DECIMAL(38) NOT NULL, [O_COMMENT] VARCHAR(79) COLLATE Latin1_General_BIN NOT NULL ) WITH ( LOCATION='customer', DATA_SOURCE= external_data_source_name );
Note
It is important to remember that external tables can be affected by schema drift. If the external source changes, that does not automagically change in the external table definition. Any change to the external source will need to be reflected in the external table definition.
In ad-hoc query scenarios, such as querying Hadoop data, PolyBase stores the rows that are retrieved from the external data source in a temporary table. After the query completes, PolyBase removes and deletes the temporary table. No permanent data is stored in SQL tables. Connect to an employee.tbl file in blob storage on a Hadoop cluster. The query looks similar to a standard T-SQL query. Once the external table is defined the data is retrieved from Hadoop and displayed.
CREATE EXTERNAL DATA SOURCE mydatasource
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat
WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS (FIELD_TERMINATOR ='|')
);
CREATE EXTERNAL TABLE ClickStream (
url varchar(50),
event_date date,
user_IP varchar(50)
)
WITH (
LOCATION='/webdata/employee.tbl',
DATA_SOURCE = mydatasource,
FILE_FORMAT = myfileformat
)
;
SELECT TOP 10 (url) FROM ClickStream WHERE user_ip = 'xxx.xxx.xxx.xxx' ;
In an import scenario, such as select into from external table, PolyBase stores the rows that are returned as permanent data in the SQL table. The new table is created during query execution when PolyBase retrieves the external data.
PolyBase can push some of the query computation to Hadoop to improve query performance. This action is called predicate pushdown. It is used by specifying the Hadoop resource manager location option when creating the external data source, and turning the pushdown on using these parameters:
PUSHDOWN = [ON | OFF] , RESOURCE_MANAGER_LOCATION = '<resource_manager>[:<port>]'
You can create many external tables that reference the same or different external data sources.
Note
Elastic query also uses external tables, but the same table cannot be used for both elastic queries and PolyBase. Although they have the same name, they are not the same.
Statistics
Statistics on external tables is done the same as other tables.
Syntax for this command can be found at https://docs.microsoft.com/sql/t-sql/statements/create-statistics-transact-sql.
Note
If you are unsure if PolyBase is installed, you can check its SERVERPROPERTY with this command
SELECT SERVERPROPERTY ('IsPolyBaseInstalled') AS IsPolyBaseInstalled;
It returns 1 if it is installed and 0 if it is not.
Catalog views
There are catalog views for the installation and running of PolyBase.
sys.external_data_sources
Sys.external_data_sources is used to identify external data_sources and gives visibility into the metadata about it. This includes the source, type, name of the remote database, and in the case of Hadoop the IP and port of the resource manager, which can be very helpful.
Sys.external_file_formats
Sys.external_file_formats is used to get details on the external file format for the sources. Along with the file format type it includes details about the delimiters, general format, encoding, and compression.
Sys.external_tables
Sys.external_tables contains a row for each external table in the current database, detailing information needed about the tables such as id links to the above tables. The majority of the columns give details about external tables over the shard map manager. The shard map manager is a special database that maintains global mapping information about all shards (databases) in a shard set. The metadata allows an application to connect to the correct database based upon the value of the sharding key. Every shard in the set contains maps that track the local shard data (known as shardlets).
Dynamic management views
There are a number of dynamic management views that can be used with PolyBase. The list of relevant views can be found in the Microsoft Docs at https://docs.microsoft.com/sql/relational-databases/polybase/polybase-troubleshooting#dynamic-management-views.
They can be used to troubleshoot issues such as finding long running queries and to monitor nodes in a PolyBase group.
Operationalizing analytics with Machine Learning Server
It often falls to a data engineer or DBA to operationalize and deploy machine learning models to production for the Data Scientist or other data professionals in our organization. In this section, we review the installation and configuration of Machine Learning Services and the best practices for operationalization of models and their code to allow for client applications and users to access them.
Regardless of the program or IDE used to create the scripts, model, functions and algorithms used to create them, Machine Learning Services can be used to operationalize them.
The mrsdeploy package for R and/or the azureml-model-management-sdk package for Python are used to deploy the packages. These R and Python analytics packages are often deployed as web services to a production environment.
Once deployed, the web service is available to a broader audience that can then consume the service. Machine Learning Server provides the operationalizing tools to deploy R and Python inside web, desktop, mobile, and dashboard applications as well as backend systems. Machine Learning Server turns your scripts into web services, so R and Python code can be easily executed by applications.
Architecture
There are two main configurations for the operationalization of Machine Learning Services. Single Server is used for easy and quick processes like proof-of-concepts. Enterprise scales to support complex production usage.
1. Single Server – A single web and compute note run on a single machine along with a database (see Figure 20-4). It is ideal for development, proof-of-concepts, prototyping and very small implementations.

Figure 20-4 One-box Architecture, ideal for development and prototyping.
Supported platforms can be found at https://docs.microsoft.com/machine-learning-server/operationalize/configure-start-for-administrators#supported-platforms.
2. Enterprise. Enterprise-size installations are designed for production usage. This configuration uses multiple web and compute nodes configured on multiple machines with an active-active configuration to allow you to load balance the API requests and scale out as needed. Nodes can be scaled independently. They use SQL Server or PostgreSQL to share data. The web nodes are stateless; therefore, there is no need for session stickiness when using a load balancer. It is recommended you configure SSL and authenticate against Active Directory (LDAP) or Azure Active Directory for this configuration. A visual of the installation is shown in Figure 20-5.

Figure 20-5 Enterprise Architecture, ideal for production usage.
Detailed instructions on how to install the components for ML Server can be found in these locations:
Windows: https://docs.microsoft.com/machine-learning-server/install/machine-learning-server-windows-install
Linux: https://docs.microsoft.com/machine-learning-server/install/machine-learning-server-linux-install
CLI: https://docs.microsoft.com/machine-learning-server/operationalize/configure-admin-cli-launch
If you prefer to use Azure Resource Management (ARM) templates, they are available on GitHub at https://github.com/microsoft/microsoft-r/tree/master/mlserver-arm-templates.
Machine Learning Server
Machine Learning Server, formerly called Microsoft R Server, had its name changed when Python was released as part of the offering. Sometimes referred to as ML Server, it is used to operationalize and deploy models. When a cluster is deployed on HDInsight it is referred to as Machine Learning Services or ML Services. It can be deployed for use in a batch or real-time scoring scenario.
Machine Learning Services can be deployed on premises or in the cloud. An on-premises Machine Learning Server runs on Windows, Linux, Hadoop Spark, and SQL Server. In the cloud your options expand to:
Azure Machine Learning Server VMs
SQL Server VMs
Data Science VMs
Azure HDInsight for Hadoop and Spark
Azure Machine Learning
Azure SQL Database
Note
When installing Machine Learning Server, be sure to use elevated permissions to ensure all components can install. MLS is currently not supported on Windows 2019, please use Windows 2016.
How to operationalize your models
The job of a database administrator varies from organization to organization and when it comes to models it often includes the task of operationalizing them. In this section we are starting the operationalization of a model based on the model being already completed, tested and handed off with all its supporting libraries and files.
Once you have all the supporting libraries and files, you will need to install a few additional items on the client from which you will deploy. Complete the following based on whether you are deploying R or Python code.
R will require an IDE such as R Tools for Visual Studio or Azure notebooks. This will be used to develop your R analytics in your local R IDE using the functions in the mrsdeploy package that can be installed with R Client and R Server. It allows for you to connect from your local machine to deploy the models as web services. With the ML Server configured for operationalization, you can connect to the server from your local machine and deploy your models as a web service, which will allow users to consume them.
Configure ML Server for operationalization of models and analytics
All deployments must consist of at least a single web node, single compute node, and a database.
Web nodes are HTTP REST endpoints that users interact directly with to make API calls. They are used to access the data and send requests to the compute node. One web node can route multiple requests at the same time.
Commute nodes are used to execute the code. Each node needs its own pool of R or Python shells and can therefore execute multiple requests at the same time.
Security for operationalizing models
Machine Learning Server allows for seamless integration with Active Directory LDAP or Azure Active Directory. For more details on how to do this see the Microsoft Docs at https://docs.microsoft.com/machine-learning-server/operationalize/configure-authentication.
Configuring the server to use a trust relationship between the users and the operational engine will allow the use of username/password combination for verification. Once the user is verified, a token is issued to the authenticated user. More details on how to manage tokens can be found on Microsoft Docs at https://docs.microsoft.com/machine-learning-server/operationalize/how-to-manage-access-tokens.
In addition to authenticating the user, it is important to secure the tokens from interception during transmission and storage. This should be done using transport layer security (HTTPS), as shown in Figure 20-6. More details on how to enable SSL or TLS can be found on Microsoft Docs at https://docs.microsoft.com/machine-learning-server/operationalize/configure-https.
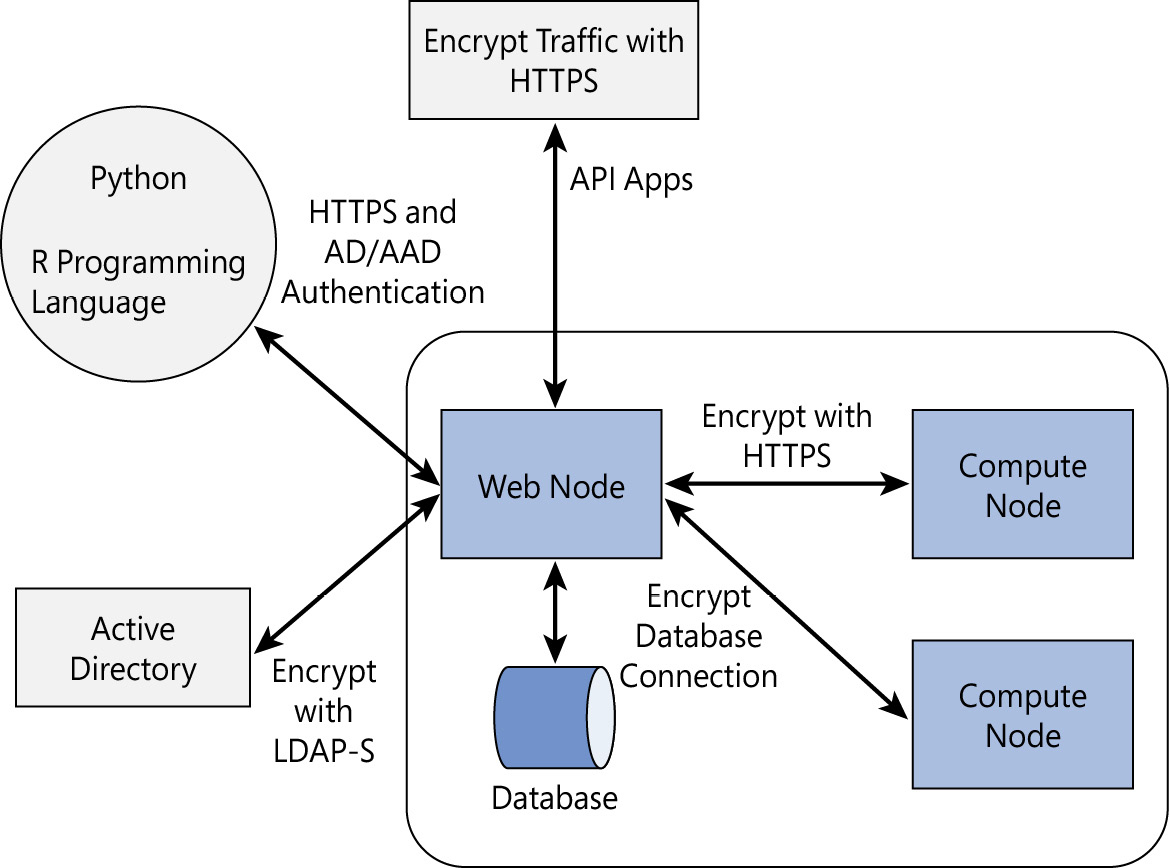
Figure 20-6 Deployment security.
Role-based access control for web services is also recommended. Role-based access control (RBAC) is used to grant minimum security required for a user’s role. More details on how to set up the roles can be found in MS Docs at https://docs.microsoft.com/machine-learning-server/operationalize/configure-roles.
Cross-Origin Resource Sharing
Cross-Origin Resource sharing (CORS) is used to request resources from a domain different than the one your web node is in. This is typical when using a government or third-party data source.
CORS is a mechanism that uses additional HTTP headers to tell a browser to let a web application running at one origin (your domain) have permission to access selected resources from a server at a different origin (a government site with data on how many people voted in the last election). A web application executes a cross-origin HTTP request when it requests a resource that has a different origin (domain, protocol, or port) than its own origin.
Here is an example of a cross-origin request: The frontend JavaScript code for a web application served from http://mydomain.com uses XMLHttpRequest to make a request for http://api.stats.gov.ca/data.json.
For security reasons, browsers restrict cross-origin HTTP requests initiated from within scripts. For example, XMLHttpRequest and the Fetch API follow the same-origin policy. This means that a web application using those APIs can only request HTTP resources from the same origin the application was loaded from, unless the response from the other origin includes the right CORS headers.
By default, Cross-Origin Resource sharing (CORS) is disabled and can be enabled by following the instructions in MS Docs at https://docs.microsoft.com/machine-learning-server/operationalize/configure-cors.
Packages for R and Python
When R or Python are installed with either SQL Server or with Machine Learning Services, a distribution of open source libraries are included. These libraries may vary with each version and can only be upgraded by upgrading your installation, regular service pack, or cumulative upgrades. An example would be upgrading from SQL Server 2016 to SQL Server 2019. The libraries should never be manually upgraded and may destabilize your installation should you do so.
Operationalizing and deploying code may often mean including additional packages in addition to the default ones included in an installation. These packages are publicly available, but due to enterprise restrictions on Internet access, it can sometimes be viable to have a repository inside the enterprise firewall. Note that all dependent packages need to be available to all nodes at runtime.
R package management options are available at https://docs.microsoft.com/machine-learning-server/operationalize/configure-manage-r-packages.
The Python package list can be found at https://docs.microsoft.com/sql/advanced-analytics/python/install-additional-python-packages-on-sql-server?view=sql-server-ver15#add-a-new-python-package.
Deploy model as a web service
Both R and Python models can be deployed as a web service. Using the mrsdeploy or azureml-model-management-sdk package that ships with Machine Learning Server, you can develop, test, and ultimately deploy these analytics as web services in your production environment.
Python uses the azureml-model-management-sdk Python package that ships with the Machine Learning Server to deploy the web services and manage the web service from a Python script. A set of RESTful APIs are also available for direct access. Details on how to deploy the service can be found at https://docs.microsoft.com/machine-learning-server/operationalize/python/quickstart-deploy-python-web-service.
R uses the functions in the mrsdeploy package to gain access to the web service from an R script, and then uses a set of RESTful APIs to provide access to the web service directly. Publish the model as a web service to Machine Learning Server using the publishService() function from the mrsdeploy package.
Details on how to deploy the service can be found at https://docs.microsoft.com/machine-learning-server/operationalize/quickstart-publish-r-web-service.
API libraries
Machine Learning Server uses Swagger for the creation of both Python and R APIs. Swagger is an open source tool used to build and enable APIs. Using core APIs, R, and Python code can be published as a Machine Learning Server hosted analytics Web service. Swagger offers templates to simplify this process, which are available at https://swagger.io. Swagger-based JSON files define the list of calls and resources available in the REST APIs. These are defined as either Core APIs or Service Consumption APIs. More details on the different APIs can be found at https://docs.microsoft.com/machine-learning-server/operationalize/concept-api. An API library is needed to access the RESTful APIs outside of R/Python. This library can be built with Swagger and will simplify the calls, the encoding of data, and a markup response handling on the API. Programming language options for the library are: C#, Java, JS, Python, or Node.js. Details on the swagger template files for APIs can be found at https://docs.microsoft.com/machine-learning-server/operationalize/how-to-build-api-clients-from-swagger-for-app-integration#get-the-swagger-file.
Note
For R applications, Swagger is not required if you use the mrsdeploy package directly, giving you two different options for deployment.
Steps for Deployment
Depending on the type of deployment you are doing and to what configuration, the steps are very different, however a simple practice example that follows the basic steps in a Python notebook can be found in the accompanying sample. This script and all scripts for this book are available for download at https://www.MicrosoftPressStore.com/SQLServer2019InsideOut/downloads.
Configuration
Workspace
Notebook
Access
Ensure you have data and a trained model
Save the package
Deploy
Run and test the deployed model
Launchpad service
The launchpad service is an NT service, added by the extensibility framework. It can be found with the other SQL Server services in the instance. It is used to execute external scripts for R and Python. An external script is the launching of a separate host for processing. This is similar to the way that the full-text indexing and query service launches a separate host for processing full-text queries. The Launchpad service has been redesigned in SQL Server 2019 to utilize AppContainer Isolation instead of the previous SQLRUserGroup (SQL restricted user group). This isolation layer removes the need to manage accounts and passwords of workers in the group for security. The SQLRUserGroup now has only one member, which is the service account instead of the multiple worker accounts.
The launch pad services used to create a separate process that runs under a low-privilege Windows account that is separate from SQL Server, the service, or the user that launched the query. This low-privilege account is a part of the SQLRUserGroup group (SQL restricted user group), which is the cornerstone of the isolation and security model for R and Python running on SQL Server. This is displayed in Figure 20-7.
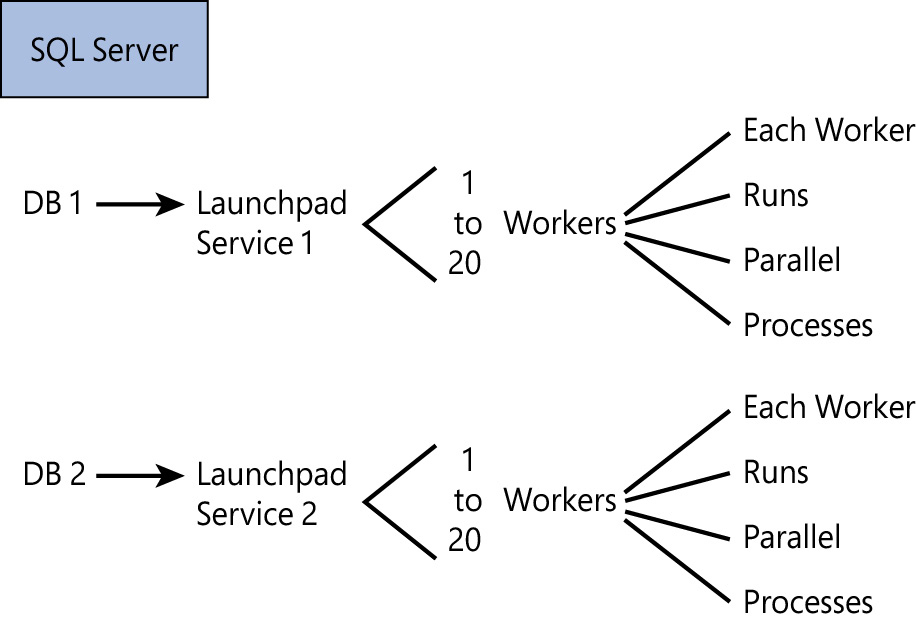
Figure 20-7 Launch Pad.
The number of worker accounts in the pool can be modified in the SQL Server Configuration Manager by right-clicking on the Launchpad and choosing properties.
Note
Any configuration changes to the server must be done in the SQL Server Configuration Manager. The ability to make changes in the ML Services configuration is no longer available.
Security
The Launchpad service maintains the worker accounts used to run the R or Python queries. If you need to change the passwords on a regular basis, this must be done by regenerating them for all workers. This is done in the SQL Server Configuration Manager by right-clicking on the Launchpad and choosing Properties. Choose Advanced and then change Reset External Users Password to Yes. This will change all worker passwords, and you must restart the service before running any queries to ensure the service reads the new passwords.
The security is not just a one-way process to the workers, launchpad also tracks the identity of the user that launched the process and maps that user back to SQL Server. In situations where a script, or piece of code, needs to request more data or perform additional operations in SQL Server, the Launchpad will manage the identity transfer for the request.