
Chapter 8. Organizing Data
In this chapter I discuss several refactorings that make working with data easier. For many people Self Encapsulate Field seems unnecessary. It’s long been a matter of good-natured debate about whether an object should access its own data directly or through accessors. Sometimes you do need the accessors, and then you can get them with Self Encapsulate Field. I generally use direct access because I find it simple to do this refactoring when I need it.
One of the useful things about object languages is that they allow you to define new types that go beyond what can be done with the simple data types of traditional languages. It takes a while to get used to how to do this, however. Often you start with a simple data value and then realize that an object would be more useful. Replace Data Value with Object allows you to turn dumb data into articulate objects. When you realize that these objects are instances that will be needed in many parts of the program, you can use Change Value to Reference to make them into reference objects.
If you see an Array or Hash acting as a data structure, you can make the data structure clearer with Replace Array with Object or Replace Hash with Object. In all these cases the object is but the first step. The real advantage comes when you use Move Method to add behavior to the new objects.
Magic numbers—numbers with special meaning—have long been a problem. I remember being told in my earliest programming days not to use them. They do keep appearing, however, and I use Replace Magic Number with Symbolic Constant to get rid of magic numbers whenever I figure out what they are doing.
Links between objects can be one-way or two-way. One-way links are easier, but sometimes you need to Change Unidirectional Association to Bidirectional to support a new function. Change Bidirectional Association to Unidirectional removes unnecessary complexity should you find you no longer need the two-way link.
One of the key tenets of Object-Oriented programming is encapsulation. If a collection is exposed, use Encapsulate Collection to cover it up. If an entire record is naked, use Replace Record with Data Class.
One form of data that requires particular treatment is the type code: a special value that indicates something particular about a type of instance. These are often implemented as integers. If the behavior of a class is affected by a type code, try to use Replace Type Code with Polymorphism. If you can’t do that, use one of the more complicated (but more flexible) Replace Type Code with Module Extension or Replace Type Code with State/Strategy.
Self Encapsulate Field
You are accessing a field directly, but the coupling to the field is becoming awkward.
Create getting and setting methods for the field and use only those to access the field.

Motivation
When it comes to accessing fields, there are two schools of thought. One is that within the class where the variable is defined, you should access the variable freely (direct variable access). The other school is that even within the class, you should always use accessors (indirect variable access). Debates between the two can be heated. (See also the discussion in Smalltalk Best Practices [Beck].)
Essentially the advantages of indirect variable access are that it allows a subclass to override how to get that information with a method and that it supports more flexibility in managing the data, such as lazy initialization, which initializes the value only when you need to use it.
The advantage of direct variable access is that the code is easier to read. You don’t need to stop and say, “This is just a getting method.”
I’m always of two minds with this choice. I’m usually happy to do what the rest of the team wants to do. Left to myself, though, I like to use direct variable access as a first resort, until it gets in the way. Once things start becoming awkward, I switch to indirect variable access. Refactoring gives you the freedom to change your mind.
The most important time to use Self Encapsulate Field is when you are accessing a field in a superclass but you want to override this variable access with a computed value in the subclass. Self-encapsulating the field is the first step. After that you can override the getting and setting methods as you need to.
Mechanics
1. Create a getting and setting method for the field.
2. Find all references to the field and replace them with a getting or setting method.
![]() Replace accesses to the field with a call to the getting method; replace assignments with a call to the setting method.
Replace accesses to the field with a call to the getting method; replace assignments with a call to the setting method.
3. Double check that you have caught all references.
4. Test.
Example
This seems almost too simple for an example, but, hey, at least it is quick to write:

To self-encapsulate I define getting and setting methods (if they don’t already exist) and use those:

When you are using self-encapsulation you have to be careful about using the setting method in the constructor. Often it is assumed that you use the setting method for changes after the object is created, so you may have different behavior in the setter than you have when initializing. In cases like this I prefer using either direct access from the constructor or a separate initialization method:

The value in doing all this comes when you have a subclass, as follows:


I can override all of the behavior of Item to take into account the import_duty without changing any of that behavior.
Replace Data Value with Object
You have a data item that needs additional data or behavior.
Turn the data item into an object.

Motivation
Often in early stages of development you make decisions about representing simple facts as simple data items. As development proceeds you realize that those simple items aren’t so simple anymore. A telephone number may be represented as a string for a while, but later you realize that the telephone needs special behavior for formatting, extracting the area code, and the like. For one or two items you may put the methods in the owning object, but quickly the code smells of duplication and feature envy. When the smell begins, turn the data value into an object.
Mechanics
1. Create the class for the value. Give it an equivalent field to the field in the source class. Add an attribute reader and a constructor that takes the field as an argument.
2. Change the attribute reader in the source class to call the reader in the new class.
3. If the field is mentioned in the source class constructor, assign the field using the constructor of the new class.
4. Change the attribute reader to create a new instance of the new class.
5. Test.
6. You may now need to use Change Value to Reference on the new object.
Example
I start with an Order class that has stored the customer of the order as a string and wants to turn the customer into an object. This way I have somewhere to store data, such as an address or credit rating, and useful behavior that uses this information.

Some client code that uses this looks like:

First I create the new Customer class. I give it a field for a string attribute, because that is what the order currently uses. I call it name, because that seems to be what the string is used for. I also add an attribute reader and provide a constructor that uses the attribute:

Now I change methods that reference the customer field to use the appropriate references on the Customer class. The attribute reader and constructor are obvious. For the attribute writer I create a new customer:

The setter creates a new customer because the old string attribute was a value object, and thus the customer currently also is a value object. This means that each order has its own customer object. As a rule, value objects should be immutable; this avoids some nasty aliasing bugs. Later I will want customer to be a reference object, but that’s another refactoring. At this point I can test.
Now I look at the methods on Order that manipulate Customer and make some changes to make the new state of affairs clearer. With the getter I use Rename Method to make it clear that it is the name not the object that is returned:

On the constructor and attribute writer, I don’t need to change the signature, but the name of the arguments should change:

Further refactoring may well cause me to add a new constructor and attribute writer that take an existing customer.
This finishes this refactoring, but in this case, as in many others, there is another step. If I want to add such things as credit ratings and addresses to our customer, I cannot do so now. This is because the customer is treated as a value object. Each order has its own customer object. To give a customer these attributes I need to apply Change Value to Reference to the customer so that all orders for the same customer share the same customer object. You’ll find this example continued there.
Change Value to Reference
You have a class with many equal instances that you want to replace with a single object.
Turn the object into a reference object.

Motivation
You can make a useful classification of objects in many systems: reference objects and value objects. Reference objects are things like customer or account. Each object stands for one object in the real world, and you use the object identity to test whether they are equal. Value objects are things like date or money. They are defined entirely through their data values. You don’t mind that copies exist; you may have hundreds of “1/1/2010” objects around your system. You do need to tell whether two of the objects are equal, so you need to override the eql? method (and the hash method too).
The decision between reference and value is not always clear. Sometimes you start with a simple value with a small amount of immutable data. Then you want to give it some changeable data and ensure that the changes ripple to everyone referring to the object. At this point you need to turn it into a reference object.
Mechanics
1. Use Replace Constructor with Factory Method.
2. Test.
3. Decide what object is responsible for providing access to the objects.
![]() This may be a hash or a registry object.
This may be a hash or a registry object.
![]() You may have more than one object that acts as an access point for the new object.
You may have more than one object that acts as an access point for the new object.
4. Decide whether the objects are precreated or created on the fly.
![]() If the objects are precreated and you are retrieving them from memory, you need to ensure they are loaded before they are needed.
If the objects are precreated and you are retrieving them from memory, you need to ensure they are loaded before they are needed.
5. Alter the factory method to return the reference object.
![]() If the objects are precomputed, you need to decide how to handle errors if someone asks for an object that does not exist.
If the objects are precomputed, you need to decide how to handle errors if someone asks for an object that does not exist.
![]() You may want to use Rename Method on the factory to convey that it returns an existing object.
You may want to use Rename Method on the factory to convey that it returns an existing object.
6. Test.
Example
I start where I left off in the example for Replace Data Value with Object. I have the following Customer class:

It is used by an Order class:

and some client code:

At the moment Customer is a value object. Each order has its own customer object even if they are for the same conceptual customer. I want to change this so that if we have several orders for the same conceptual customer, they share a single customer object. For this case this means that there should be only one customer object for each customer name.
I begin by using Replace Constructor with Factory Method. This allows me to take control of the creation process, which will become important later. I define the factory method on Customer:

Then I replace the calls to the constructor with calls to the factory:

Now I have to decide how to access the customers. My preference is to use another object. Such a situation works well with something like the line items on an order. The order is responsible for providing access to the line items. However, in this situation there isn’t such an obvious object. In this situation I usually create a registry object to be the access point. For simplicity in this example, however, I store them using a field on Customer, making the Customer class the access point:

Then I decide whether to create customers on the fly when asked or to create them in advance. I’ll use the latter. In my application startup code I load the customers that are in use. These could come from a database or from a file. For simplicity I use explicit code. I can always use Substitute Algorithm to change it later.

Now I alter the factory method to return the precreated customer:

Because the create method always returns an existing customer, I should make this clear by using Rename Method.

Change Reference to Value
You have a reference object that is small, immutable, and awkward to manage.
Turn it into a value object.

Motivation
As with Change Value to Reference, the decision between a reference and a value object is not always clear. It is a decision that often needs reversing.
The trigger for going from a reference to a value is that working with the reference object becomes awkward. Reference objects have to be controlled in some way. You always need to ask the controller for the appropriate object. The memory links also can be awkward. Value objects are particularly useful for distributed and concurrent systems.
An important property of value objects is that they should be immutable. Any time you invoke a query on one, you should get the same result. If this is true, there is no problem having many objects represent the same thing. If the value is mutable, you have to ensure that changing any object also updates all the other objects that represent the same thing. That’s so much of a pain that the easiest thing to do is to make it a reference object.
It’s important to be clear on what immutable means. If you have a money class with a currency and a value, that’s usually an immutable value object. That does not mean your salary cannot change. It means that to change your salary, you need to replace the existing money object with a new money object rather than changing the amount on an existing money object. Your relationship can change, but the money object itself does not.
Mechanics
1. Check that the candidate object is immutable or can become immutable.
![]() If the object isn’t currently immutable, use Remove Setting Method until it is.
If the object isn’t currently immutable, use Remove Setting Method until it is.
![]() If the candidate cannot become immutable, you should abandon this refactoring.
If the candidate cannot become immutable, you should abandon this refactoring.
2. Create an == method and an eql? method (the eql? method can delegate to the == method).
3. Create a hash method.
4. Test.
5. Consider removing any factory method and making a constructor public.
Example
I begin with a currency class:

All this class does is hold and return a code. It is a reference object, so to get an instance I need to use use a method that will return the same instance of currency for a given currency code:

The currency class maintains a list of instances. I can’t just use a constructor.

To convert this to a value object, the key thing to do is verify that the object is immutable. If it isn’t, I don’t try to make this change, as a mutable value causes no end of painful aliasing.
In this case the object is immutable, so the next step is to define an eql? method:

I’ve delegated the eql? method to the == method, since I don’t desire different behavior for these two methods. If I define eql?, I also need to define hash. The simple way to do this is to take the hash codes of all the fields used in the eql? method and do a bitwise xor (^) on them. Here it’s easy because there’s only one:

With both methods replaced, I can test. I need to do both; otherwise Hash and any collection that relies on hashing, such as Array’s uniq method, may act strangely.
Now I can create as many equal currencies as I like. I can get rid of all the controller behavior on the class and the factory method and just use the constructor.
![]()
Replace Array with Object
You have an Array in which certain elements mean different things.
Replace the Array with an object that has a field for each element.
Motivation
Arrays are a common structure for organizing data. However, they should be used only to contain a collection of similar objects in some order. Sometimes, however, you see them used to contain a number of different things. Conventions such as “the first element on the Array is the person’s name” are hard to remember. With an object you can use names of fields and methods to convey this information so you don’t have to remember it or hope the comments are up to date. You can also encapsulate the information and use Move Method to add behavior to it.
Mechanics
1. Create a new class to represent the information in the Array. Give it a method called [] so that callers that read the Array can be changed one by one. Give it a method called []= so that callers that write to the Array can be changed one by one.
2. Construct the new object wherever the Array was instantiated.
3. Test.
4. One by one, add attribute readers for each element in the Array that is read by a client. Name the attr_reader after the purpose of the Array element. Change the clients to use the attr_reader. Test after each change.
5. Add attribute writers for any attribute in the Array that is written to by a client. Name the attr_writer after the purpose of the Array element. Change the clients to use the attr_writer. Test after each change.
6. When all Array accesses are replaced by custom accessors, remove the [] and []= methods.
7. Test.
Example
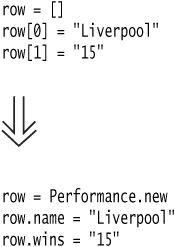
I start with an Array that’s used to hold the name, wins, and losses of a sports team. It would be declared as follows:
![]()
It would be used with code such as the following:

To turn this into a custom object, I begin by creating a class:

I then need to implement the Array accessor methods so that I can change the calling code one-by-one. I also need to initialize my Array to be empty.

Now I find the spots that create the Array, and modify them to construct the Performance object.
![]()
I should be able to run my tests now, because all callers should be able to interact with the Performance object in the same way they did the Array.
One by one, I add attr_readers for any attributes that are read from the Array by clients. I start with the name:

I can do the same with the second element. To make matters easier, I can encapsulate the data type conversion:
![]()

One by one, I add attr_writers (or convert attr_readers to attr_accessors) for any attributes that are written to the Array. I start with the name:

And then wins:

Once I’ve done this for each element, I can remove the Array element readers and writers:


I now have an object with an interface that reveals the intention of its attributes. I also have the opportunity now to use Move Method to move any behavior that relates to the performance onto the Performance object.
Refactor with Deprecation
If you’re developing a library that is being consumed by others, you may not want to remove old methods (like the Array element readers and writers in the previous example) straight away. You could deprecate the methods and leave them on the object, warning consumers that the method will be removed in future releases. By Adding a method to class Module, this can be done pretty easily:

Then you can deprecate a method on any class:

produces:

Replace Hash with Object
You have a Hash that stores several different types of objects, and is passed around and used for more than one purpose.
Replace the Hash with an object that has a field for each key.

Motivation
Like Arrays, Hashes are a common structure for organizing data. Outside the context of named parameters, they should only be used to store a collection of similar objects. Sometimes, however, you see them used to contain a number of different things. If they are then passed around from method to method, it becomes difficult to remember the keys that the Hash contains. With an object, you can define a class with a public interface to represent the way the object can be interacted with, and one does not have to traverse the entire algorithm to see how the object might behave. As with Replace Array With Object, you can also encapsulate the information and use Move Method to add behavior to it.
Mechanics
1. Create a new class to represent the information in the Hash. Give it a method called [] so that callers that read the Hash can be changed one by one. Give it a method called []= so that callers that write to the Hash can be changed one by one.
2. Construct the new object wherever the Hash was instantiated.
3. Test.
4. One by one, add attribute readers for any attribute in the Hash that is read by a client. Name the attr_reader after the key. Change the clients to use the attr_reader. Test after each change.
5. Add attribute writers for any attribute in the Hash that is written to by a client. Name the attr_writer after the key. Change the clients to use the attr_writer. Test after each change.
6. When all Hash accesses are replaced by custom accessors, remove the [] and []= methods.
7. Test.
Example
I start with a Hash that’s used to store the nodes for a network, and the old networks from which the nodes just came:

To turn the Hash into an object, I begin by creating a class:
class NetworkResult
end
I then need to implement the Hash accessor methods so that I can change the calling code one-by-one.

I need to initialize each of @old_networks and @nodes to an empty Array.

I can then instantiate my new object wherever I was instantiating the Hash.
![]()
becomes
new_network = NetworkResult.new
My tests should pass if I haven’t made any mistakes.
One-by-one, I can replace each of the calls to the Hash reader with calls to an attr_reader. First I add an attr_reader for :old_networks.
![]()
and replace calls to the Hash reader using the :old_networks key with calls to our new attr_reader.
![]()
becomes:
new_network.old_networks << node.network
Then I can do the same with :nodes:
new_network[:nodes] << node
becomes

I can then replace calls to the Hash writer with an attr_accessor.

becomes:

And finally, I can remove my Hash accessor methods from NetworkResult:

As with many of these refactorings, the true benefit comes when you can move behavior onto the newly created object. Take for example, the name attribute, which is set using data from the old networks. We can make name a method on NetworkResult and remove the attr_accessor for name.

Change Unidirectional Association to Bidirectional
You have two classes that need to use each other’s features, but there is only a one-way link.
Add back pointers, and change modifiers to update both sets.

Motivation
You may find that you have initially set up two classes so that one class refers to the other. Over time you may find that a client of the referred class needs to get to the objects that refer to it. This effectively means navigating backward along the pointer. Pointers are one-way links, so you can’t do this. Often you can get around this problem by finding another route. This may cost in computation but is reasonable, and you can have a method on the referred class that uses this behavior. Sometimes, however, this is not easy, and you need to set up a two-way reference, sometimes called a back pointer. If you aren’t used to back pointers, it’s easy to become tangled up using them. Once you get used to the idiom, however, it is not too complicated.
The idiom is awkward enough that you should have tests, at least until you are comfortable with the idiom. Because I usually don’t bother testing accessors (the risk is not high enough), this is the rare case of a refactoring that adds a test.
This refactoring uses back pointers to implement bidirectionality. Other techniques, such as link objects, require other refactorings.
Mechanics
1. Add a field for the back pointer.
2. Decide which class will control the association.
3. Create a helper method on the noncontrolling side of the association. Name this method to clearly indicate its restricted use.
4. If the existing modifier is on the controlling side, modify it to update the back pointers.
5. If the existing modifier is on the controlled side, create a controlling method on the controlling side and call it from the existing modifier.
Example
A simple program has an order that refers to a customer:

The Customer class has no reference to the Order.
I start the refactoring by adding a field to the Customer. As a customer can have several orders, so this field is a collection. Because I don’t want a customer to have the same order more than once in its collection, the correct collection is a set:

Now I need to decide which class will take charge of the association. I prefer to let one class take charge because it keeps all the logic for manipulating the association in one place. My decision process runs as follows:
• If both objects are reference objects and the association is one to many, then the object that has the one reference is the controller. (That is, if one customer has many orders, the order controls the association.)
• If one object is a component of the other, the composite should control the association.
• If both objects are reference objects and the association is many to many, it doesn’t matter whether the order or the customer controls the association.
Because the order will take charge, I need to add a helper method to the customer that allows direct access to the orders collection. The order’s modifier will use this to synchronize both sets of pointers. I use the name friend_orders to signal that this method is to be used only in this special case:

Now I replace the attr_accessor with an attr_reader and a custom attribute writer to update the back pointers:

The exact code in the controlling modifier varies with the multiplicity of the association. If the customer is not allowed to be nil, I can forgo the nil checks, but I need to check for a nil argument. The basic pattern is always the same, however: First tell the other object to remove its pointer to you, set your pointer to the new object, and then tell the new object to add a pointer to you.
If you want to modify the link through the customer, let it call the controlling method:

If an order can have many customers, you have a many-to-many case, and the methods look like this:

Change Bidirectional Association to Unidirectional
You have a two-way association but one class no longer needs features from the other.
Drop the unneeded end of the association.

Motivation
Bidirectional associations are useful, but they carry a price. The price is the added complexity of maintaining the two-way links and ensuring that objects are properly created and removed. Bidirectional associations are not natural for many programmers, so they often are a source of errors.
Having many two-way links also makes it easy for mistakes to lead to zombies: objects that should be dead but still hang around because of a reference that was not cleared.
Bidirectional associations force an interdependency between the two classes. Any change to one class may cause a change to another. Many interdependencies lead to a highly coupled system, in which any little change leads to a lot of unpredictable ramifications.
You should use bidirectional associations when you need to but avoid them when you don’t. As soon as you see a bidirectional association is no longer pulling its weight, drop the unnecessary end.
Mechanics
1. Examine all the readers of the field that holds the pointer that you want to remove to see whether the removal is feasible.
![]() Look at direct readers and further methods that call those methods.
Look at direct readers and further methods that call those methods.
![]() Consider whether it is possible to determine the other object without using the pointer. If so you will be able to use Substitute Algorithm on the attribute reader to allow clients to use the reader even if there is no pointer.
Consider whether it is possible to determine the other object without using the pointer. If so you will be able to use Substitute Algorithm on the attribute reader to allow clients to use the reader even if there is no pointer.
![]() Consider adding the object as an argument to all methods that use the field.
Consider adding the object as an argument to all methods that use the field.
2. If clients need to use the attribute reader, use Self Encapsulate Field, carry out Substitute Algorithm on the attribute reader, and test.
3. If clients don’t need the attribute reader, change each user of the field so that it gets the object in the field another way. Test after each change.
4. When no reader is left in the field, remove all updates to the field, and remove the field.
![]() If there are many places that assign the field, use Self Encapsulate Field so that they all use a single attribute writer. Test. Change the attribute writer to have an empty body. Test. If that works, remove the field, the attribute reader, and all calls to the attribute writer.
If there are many places that assign the field, use Self Encapsulate Field so that they all use a single attribute writer. Test. Change the attribute writer to have an empty body. Test. If that works, remove the field, the attribute reader, and all calls to the attribute writer.
5. Test.
Example
This example starts from where I ended up in the example in the section “Change Unidirectional Association to Bidirectional.” I have a customer and order with a bidirectional link:


I’ve found that in my application I don’t have orders unless I already have a customer, so I want to break the link from order to customer.
The most difficult part of this refactoring is checking that I can do it. Once I know it’s safe to do, it’s easy. The issue is whether code relies on the customer fields being there. To remove the field, I need to provide an alternative.
My first move is to study all the readers of the field and the methods that use those readers. Can I find another way to provide the customer object? Often this means passing in the customer as an argument for an operation. Here’s a simplistic example of this:
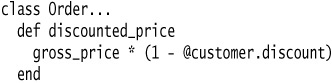
changes to

This works particularly well when the behavior is being called by the customer, because then it’s easy to pass itself in as an argument. So:

becomes:

Another alternative I consider is changing the attribute reader so that it gets the customer without using the field. If it does, I can use Substitute Algorithm on the body of Order.customer. I might do something like this:

Slow, but it works. In a database context it may not even be that slow if I use a database query. If the Order class contains methods that use the customer field, I can change them to use the customer reader by using Self Encapsulate Field.
If I retain the accessor, the association is still bidirectional in interface but is unidirectional in implementation. I remove the back-pointer but retain the interdependencies between the two classes.
If I substitute the attribute reader, I substitute that and leave the rest till later. Otherwise, I change the callers one at a time to use the customer from another source. I test after each change. In practice, this process usually is pretty rapid. If it were complicated, I would give up on this refactoring.
Once I’ve eliminated the readers of the field, I can work on the writers of the field. This is as simple as removing any assignments to the field and then removing the field. Because nobody is reading it any more, that shouldn’t matter.
Replace Magic Number with Symbolic Constant
You have a literal number with a particular meaning.
Create a constant, name it after the meaning, and replace the number with it.

Motivation
Magic numbers are one of oldest ills in computing. They are numbers with special values that usually are not obvious. Magic numbers are really nasty when you need to reference the same logical number in more than one place. If the numbers might ever change, making the change is a nightmare. Even if you don’t make a change, you have the difficulty of figuring out what is going on.
Many languages allow you to declare a constant. There is no cost in performance and there is a great improvement in readability.
Before you do this refactoring, always look for an alternative. Look at how the magic number is used. Often you can find a better way to use it. If the magic number is a type code, consider Replace Type Code with Polymorphism. If the magic number is the length of an Array, use an_array.size instead.
Mechanics
1. Declare a constant and set it to the value of the magic number.
2. Find all occurrences of the magic number.
3. See whether the magic number matches the usage of the constant; if it does, change the magic number to use the constant.
4. When all magic numbers are changed, test. At this point all should work as if nothing has been changed.
![]() A good test is to see whether you can change the constant easily. This may mean altering some expected results to match the new value. This isn’t always possible, but it is a good trick when it works.
A good test is to see whether you can change the constant easily. This may mean altering some expected results to match the new value. This isn’t always possible, but it is a good trick when it works.
Encapsulate Collection
A method returns a collection.
Make it return a copy of the collection and provide add/remove methods.

Motivation
Often a class contains a collection of instances. This collection might be an Array or a Hash. Such cases often have the usual attribute reader and writer for the collection.
However, collections should use a protocol slightly different from that for other kinds of data. The attribute reader should not return the collection object itself, because that allows clients to manipulate the contents of the collection without the owning class knowing what is going on. It also reveals too much to clients about the object’s internal data structures. An attribute reader for a multivalued attribute should return something that prevents manipulation of the collection and hides unnecessary details about its structure.
In addition there should not be an attribute writer for the collection: rather, there should be operations to add and remove elements. This gives the owning object control over adding and removing elements from the collection.
With this protocol the collection is properly encapsulated, which reduces the coupling of the owning class to its clients.
Mechanics
1. Add add and remove methods for the collection.
2. Initialize the field to an empty collection.
3. Find callers of the attribute writer. Either modify the writer to use the add and remove operations or have the clients call those operations instead.
![]() Attribute writers are used in two cases: when the collection is empty and when the attribute writer is replacing a nonempty collection.
Attribute writers are used in two cases: when the collection is empty and when the attribute writer is replacing a nonempty collection.
![]() You may want to use Rename Method to rename the attribute writer. Change it to
You may want to use Rename Method to rename the attribute writer. Change it to initialize_x or replace_x, where “x” is the name of your collection.
4. Test.
5. Find all users of the attribute reader that modify the collection. Change them to use the add and remove methods. Test after each change.
6. When all uses of the attribute reader that modify have been changed, modify the reader to return a copy of the collection.
7. Test.
8. Find the users of the attribute reader. Look for code that should be on the host object. Use Extract Method and Move Method to move the code to the host object.
9. Test.
Example
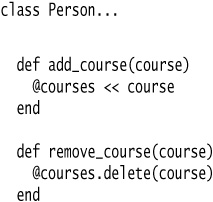
A person is taking courses. Our Course is pretty simple:

I’m not going to bother with anything else on the Course. The interesting class is the Person:
![]()
With this interface, clients add courses with code such as:

A client that wants to know about advanced courses might do it this way:
person.courses.select { |course| course.advanced? }.size
The first thing I want to do is to create the proper modifiers for the collection as follows:
Life will be easier if I initialize the field as well:

I then look at the users of the attribute writer. If there are many clients and the writer is used heavily, I need to replace the body of the writer to use the add and remove operations. The complexity of this process depends on how the writer is used. There are two cases. In the simplest case the client uses the writer to initialize the values, that is, there are no courses before the writer is applied. In this case I replace the attribute accessor with an explicit writer that uses the add method:
![]()

After changing the body this way, it is wise to use Rename Method to make the intention clearer.

In the more general case I have to use the remove method to remove every element first and then add the elements. But I find that occurs rarely (as general cases often do).
If I know that I don’t have any additional behavior when adding elements as I initialize, I can remove the loop and use +=.

I can’t just assign the Array, even though the previous Array was empty. If the client were to modify the Array after passing it in, that would violate encapsulation. I have to make a copy.
If the clients simply create an Array and use the attribute writer, I can get them to use the add and remove methods directly and remove the writer completely. Code such as:

becomes:

Now I start looking at users of the attribute reader. My first concern is cases in which someone uses the reader to modify the underlying collection, for example:
I need to replace this with a call to the new modifier:
![]()
Once I’ve done this for everyone, I can ensure that nobody is modifying through the attribute reader by changing the reader body to return a copy of the collection:

At this point I’ve encapsulated the collection. No one can change the elements of the collection except through methods on the Person.
Moving Behavior into the Class
I have the right interface. Now I like to look at the users of the attribute reader to find code that ought to be on person. Code such as:

is better moved to Person because it uses only Person's data. First I use Extract Method on the code:

And then I use Move Method to move it to person:

A common case is:
kent.courses.size
which can be changed to the more readable:
kent.number_of_courses

A few years ago I was concerned that moving this kind of behavior over to Person would lead to a bloated Person class. In practice, I’ve found that this usually isn’t a problem.
Replace Record with Data Class
You need to interface with a record structure in a traditional programming environment.
Make a dumb data object for the record.
Motivation
Record structures are a common feature of programming environments. There are various reasons for bringing them into an Object-Oriented program. You could be copying a legacy program, or you could be communicating a structured record with a traditional programming API, or a database record. In these cases it is useful to create an interfacing class to deal with this external element. It is simplest to make the class look like the external record. You move other fields and methods into the class later. A less obvious but very compelling case is an Array in which the element in each index has a special meaning. In this case you use Replace Array with Object.
Mechanics
1. Create a class to represent the record.
2. Give the class a field with an attribute_accessor for each data item.
3. You now have a dumb data object. It has no behavior yet but further refactoring will explore that issue.
Replace Type Code with Polymorphism
You have a type code that affects the behavior of a class.
Replace the type code with classes: one for each type code variant.
Motivation
This situation is usually indicated by the presence of case-like conditional statements. These may be case statements or if-then-else constructs. In both forms they test the value of the type code and then execute different code depending on the value of the type code.
Removing Conditional Logic
There are three different refactorings to consider when you’re trying to remove conditional logic: Replace Type Code with Polymorphism, Replace Type Code with Module Extension, or Replace Type Code with State/Strategy. The choice depends on relatively subtle design differences.
If the methods that use the type code make up a large portion of the class, I use Replace Type Code with Polymorphism. It’s the simplest, and just takes advantage of Ruby’s duck-typing to remove the conditional statements. It involves blowing away the original class and replacing it with a new class for each type code. Since the original class was heavily reliant on the type code, it generally makes sense for the clients of the original class to construct an instance of one of the new type classes (because they were probably injecting the type into the original class anyway).
If the class has a large chunk of behavior that doesn’t use the type code, I choose either Replace Type Code with Module Extension or Replace Type Code with State/Strategy. These have the advantage of enabling me to change the type at runtime. In the former we extend a module, mixing in the module’s behavior onto the object. Instance variables are shared automatically between the object and the module, which can simplify things. Replace Type Code with State/Strategy uses delegation: The parent object delegates to the state object for state-specific behavior. The state object can be swapped out at runtime when a change in behavior is required. Because of the delegation, sharing of instance variables between the parent object and the state object can be awkward. So the question becomes, why would you choose State/Strategy over Module Extension? It turns out that you can’t unmix a module in Ruby, so removing undesired behavior can be difficult. When the state changes become complex enough that unwanted behavior cannot be removed or overridden, I choose Replace Type Code with State/Strategy.
The great thing about Ruby is that you can do Replace Type Code with Polymorphism without inheritance or implementing an interface, something that is impossible in a language such as Java or C#.
Mechanics
1. Create a class to represent each type code variant.
2. Change the class that uses the type code into a module. Include the module into each of the new type classes.
3. Change the callers of the original class to create an instance of the desired type instead.
4. Test.
5. Choose one of the methods that use the type code. Override the method on one of the type classes,
6. Test.
7. Do the same for the other type classes, removing the method on the module when you’re done.
9. Repeat for the other methods that use the type code.
10. Test.
11. Remove the module if it no longer houses useful behavior.
Example
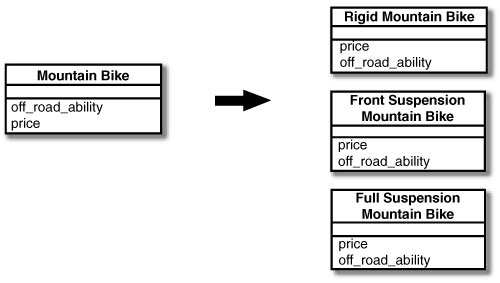
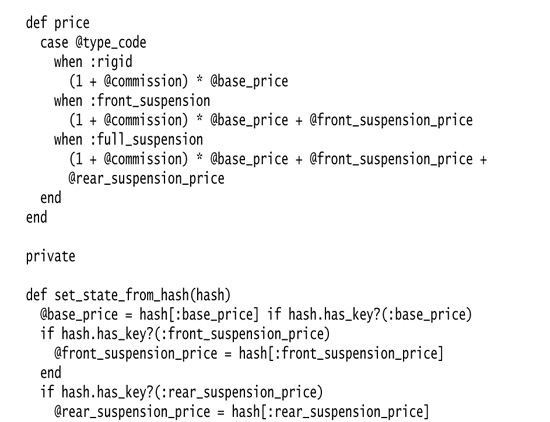
For this case I’m modeling mountain bikes. An instance of the MountainBike can either be :rigid (having no suspension), :front_suspension, or :full_suspension (having both front and rear suspension). The @type_code determines how things like off_road_ability and price are calculated:


We’ll start by creating a class for each type. We’ll change MountainBike to a module, and include it in each of our new classes.


The callers will need to change to create our new type.
![]()
becomes

Although we haven’t gotten far, we should be able to run the tests and they should still pass.
Next we use Replace Conditional with Polymorphism on one of the methods that we want to call polymorphically, overriding it for one of our new classes. I choose price and start with RigidMountainBike.

This new method overrides the whole case statement for rigid mountain bikes. Because I’m paranoid, I sometimes put a trap in the case statement:

All going well, the tests should pass.
I then do the same for the other type classes, removing the price method in the MountainBike module when I’m done.

I can then do the same for off_road_ability.


Since we’re no longer using the type code, I can remove it from the callers.

becomes
![]()
We’ll keep the MountainBike module in this case since it still houses some useful code that would otherwise need to be duplicated.
Replace Type Code with Module Extension
You have a type code that affects the behavior of a class.
Replace the type code with dynamic module extension.

Motivation
Like Replace Type Code with Polymorphism, Replace Type Code with Module Extension aims to remove conditional logic. By extending a module, we can change the behavior of an object at runtime. Both the original class and the module that is being extended can access the same instance variables. This removes some of the headache that comes along with a more traditional state/strategy pattern that uses delegation.
The one catch with module extension is that modules cannot be unmixed easily. Once they are mixed into an object, their behavior is hard to remove. So use Replace Type Code with Module Extension when you don’t care about removing behavior. If you do care, use Replace Type Code with State/Strategy instead.
Mechanics
1. Perform Self-encapsulate Field on the type code.
2. Create a module for each type code variant.
3. Make the type code writer extend the type module appropriately.
4. Choose one of the methods that use the type code. Override the method on one of the type modules.
5. Test.
6. Do the same for the other type modules. Modify the implementation on the class to return the default behavior.
7. Test.
8. Repeat for the other methods that use the type code.
9. Test.
10. Pass the module into the type code setter instead of the old type code.
11. Test.
Example
We’ll use a similar example to Replace Type Code with Polymorphism. Let’s say we have a mountain bike object in the system that at some stage in its life cycle we decide to add front suspension to.

MountainBike might look something like this:

The first step is to use Self Encapsulate Field on the type code. I’ll create a custom attribute writer because it will do something more interesting soon, and call it from the constructor.

The next step is to create a module for each of the types. We’ll make rigid the default, and add modules for FrontSuspensionMountainBike and FullSuspensionMountainBike.
I need to change the type code setter to extend the appropriate module. The case statement I’m introducing will be removed by the time we’ve finished this refactoring; it’s just there to make the next step a bit smaller.

I then begin Replace Conditional with Polymorphism. I’ll start with price, and override it on FrontSuspensionMountainBike.

I can put a trap in the case statement to make sure it’s being overridden:

At this point we haven’t gotten far, but our tests should pass.
I then repeat the process for FullSuspensionMountainBike. I can remove the case statement in price, and just return the default implementation for rigid mountain bikes.

I then do the same for off_road_ability. The constants will have to be scoped to access them on MountainBike.


I can remove the case statement I created by getting the callers to pass in the appropriate module.

becomes

I should now have removed all traces of @type_code.
Replace Type Code with State/Strategy
You have a type code that affects the behavior of a class and the type code changes at runtime.
Replace the type code with a state object.

Motivation
This refactoring has the same goal as Replace Type Code with Polymorphism and Replace Type Code with Module Extension: removing conditional logic. I use Replace Type Code with State/Strategy when the type code is changed at runtime and the type changes are complex enough that I can’t get away with Module Extension.
State and strategy are similar, and the refactoring is the same whichever you use. Choose the pattern that better fits the specific circumstances. If you are trying to simplify a single algorithm, strategy is the better term. If you are going to move state-specific data and you think of the object as changing state, use the state pattern.
Mechanics
1. Perform Self-encapsulate Field on the type code.
2. Create empty classes for each of the polymorphic objects. Create a new instance variable to represent the type. This will be the object that we’ll delegate to.
3. Use the old type code to determine which of the new type classes should be assigned to the type instance variable.
4. Choose one of the methods that you want to behave polymorphically. Add a method with the same name on one of the new type classes, and delegate to it from the parent object
![]() You’ll need to pass in any state that needs to be shared with the object being delegated to, or pass a reference to the original object.
You’ll need to pass in any state that needs to be shared with the object being delegated to, or pass a reference to the original object.
5. Test.
6. Repeat step 4 for the other type classes.
7. Test.
8. Repeat steps 4 through 7 for each of the other methods that use the type code.
Example
To easily demonstrate the differences between Replace Type Code with State/Strategy and the other Replace Type Code refactorings, we’ll use a similar example. This time we’ll add methods for upgrading the mountain bike to add front suspension and rear suspension.


The first step is to perform Self-encapsulate Field on the type code. By confining all access to the type code to just the getter and setter, we can more easily perform parallel tasks when the type is being accessed. This enables us to take smaller steps during the refactoring.
We add an attr_reader, and a custom attribute writer, which will do something more interesting soon.


Next we create empty classes for each variant of type code.

We need a new instance variable to represent the type. We’ll assign to it an instance of one of our new classes. This will be the object that we’ll delegate to.

It may seem strange that we’re introducing a case statement when the purpose of this refactoring is, in fact, to remove conditional logic. The case statement just enables a smaller step to the refactoring, by giving us the ability to modify the internals of the class without modifying the callers. Rest assured that it won’t last long: By the time we finish the refactoring all conditional logic will be removed.
Now the fun begins. We want to use Replace Conditional with Polymorphism on the conditional logic. I’ll start with off_road_ability, and add it to RigidMountainBike. We have to pass in the instance variables that are needed by the state object.


At this stage we shouldn’t have broken anything.
We do the same with the other new classes.


We can then make off_road_ability in mountain bike delegate to the type using Forwardable. (See the Hide Delegate section in Chapter 7 for an explanation of Forwardable.)

Our add_front_suspension and add_rear_suspension methods need to change to set the type object to an instance of one of our new classes.

We can then do the same with the price method.

Since price is the last method that we need to move, we can start to remove type_code.


Then we can change the callers of MountainBike and remove the case statement from our initialize method.

becomes

And with most of the instance data being set directly on the type object, we can remove all that instance variable setting in MountainBike.

Rather than reach into the type object when we’re upgrading, we can use Extract Method to encapsulate the upgradable parameters.
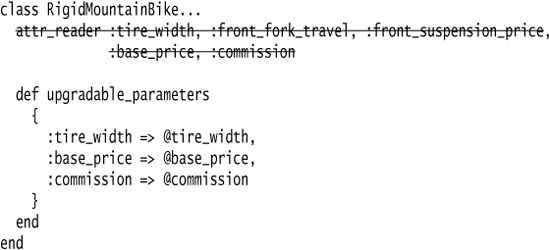

We could then use Extract Module to remove any duplication in our new classes.
Replace Subclass with Fields
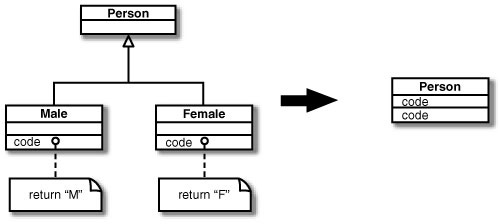
You have subclasses that vary only in methods that return constant data.
Change the methods to superclass fields and eliminate the subclasses.
Motivation
You create subclasses to add features or allow behavior to vary. One form of variant behavior is the constant method [Beck]. A constant method is one that returns a hard-coded value. This can be useful on subclasses that return different values for an accessor. You define the accessor in the superclass and override it with different values on the subclass.
Although constant methods are useful, a subclass that consists only of constant methods is not doing enough to justify its existence. You can remove such subclasses completely by putting fields in the superclass. By doing that you remove the extra complexity of the subclasses.
Mechanics
1. Use Replace Constructor with Factory Method on the subclasses.
2. Modify the superclass constructor to initialize a field for each constant method.
3. Add or modify subclass constructors to call the new superclass constructor.
4. Test.
5. Implement each constant method in the superclass to return the field and remove the method from the subclasses.
6. Test after each removal.
7. When all the subclass methods have been removed, use Inline Method to inline the constructor into the factory method of the superclass.
8. Test.
9. Remove the subclass.
10. Test.
11. Repeat inlining the constructor and eliminating each subclass until they are all gone.
Example
I begin with a Person and sex-oriented subclasses:

Here the only difference between the subclasses is that they have implementations of methods that return a hard-coded constant method [Beck]. I remove these lazy subclasses.
First I need to use Replace Constructor with Factory Method. In this case I want a factory method for each subclass:

I then replace calls of the form:
![]()
with
![]()
Once I’ve replaced all of these calls I shouldn’t have any references to the subclasses. I can check this with a text search or by enclosing the class in a module namespace and running the tests.
I add an initialize method on the superclass, assigning an instance variable for each:

I add constructors that call this new constructor:

With that done I can run my tests. The fields are created and initialized, but so far they aren’t being used. I can now start bringing the fields into play by putting accessors on the superclass and eliminating the subclass methods:

I can do this one field and one subclass at a time or all in one go if I’m feeling lucky.
After all the subclasses are empty, I use Inline Method to inline the subclass constructor into the superclass:

After testing I delete the Female class and repeat the process for the Male class.
Lazily Initialized Attribute
Initialize an attribute on access instead of at construction time.


Motivation
The motivation for converting attributes to be lazily initialized is for code readability purposes. While the preceding example is trivial, when the Employee class has multiple attributes that need to be initialized the constructor needs to contain all the initialization logic. Classes that initialize instance variables in the constructor need to worry about both attributes and instance variables. The procedural behavior of initializing each attribute in a constructor is sometimes unnecessary and less maintainable than a class that deals exclusively with attributes. Lazily Initialized Attributes can encapsulate all their initialization logic within the methods themselves.
Mechanics
1. Move the initialization logic to the attribute reader.
2. Test.
Example using ||=
The following code is an Employee class with the email attribute initialized in the constructor.

Moving to a Lazily Initialized Attribute generally means moving the initialization logic to the getter method and initializing on the first access.
![]()

Example Using instance_variable_defined?
Using ||= for Lazily Initialized Attributes is a common idiom; however, this idiom falls down when nil or false are valid values for the attribute.

In the preceding example it’s not practical to use an ||= operator for a Lazily Initialized Attribute because the find_by_boss_id might return nil. In the case where nil is returned, each time the assistant attribute is accessed another database trip will occur. A superior solution is to use code similar to the following example that utilizes the instance_variable_defined? method that was introduced in Ruby 1.8.6.

Eagerly Initialized Attribute
Initialize an attribute at construction time instead of on the first access.


Motivation
The motivation for converting attributes to be eagerly initialized is for code readability purposes. Lazily initialized attributes change their value upon access. Lazily initialized attributes can be problematic to debug because their values change upon access. Eagerly Initialized Attributes initialize their attributes in the constructor of the class. This leads to encapsulating all initialization logic in the constructor and consistent results when querying the value of the instance variable.
Discussion
I prefer Lazily Initialized Attributes, but Martin prefers Eagerly Initialized Attributes. I opened up the discussion to the reviewers of Refactoring: Ruby Edition and my current ThoughtWorks team, but in the end it was split 50/50 on preference. Based on that fact, I told Martin I didn’t think it was a good candidate for Refactoring: Ruby Edition. Not surprisingly, he had a better solution: Provide examples of both refactoring to Eagerly Initialized Attribute and refactoring to Lazily Initialized Attribute.
Martin and I agree that this isn’t something worth being religious about. Additionally, we both think it’s valuable for a team to standardize on Lazily or Eagerly Initialized Attributes.
Mechanics
1. Move the initialization logic to the constructor.
2. Test.
Example
The following code is an Employee class with both the email and voice_mail attributes lazily initialized.

Moving to an Eagerly Initialized Attribute generally means moving the initialization logic from the getter methods into the constructor.
