
14
Product or Item-Based Recommender System
Jyoti Rani1, Usha Mittal2 and Geetika Gupta1*
1 Department of Biotechnology, Thapar Institute of Engineering and Technology, Patiala, India
2 Department of Computer Science and Engineering, Lovely Professional University, Phagwara, India
Abstract
Presently, most every tough task has been overtaken smoothly by machines in the name of intelligence/intellect/autonomous learning of computers from a given set of data. AI is being used on trial basis for a range of healthcare, entertainment, stock market and research purposes. It is widely used to make recommendations in different applications. Nowadays, users make their decisions by accessing the information on the internet. Before making any purchase, watch a movie, consult physicians, users check ratings about any particular event on internet. The item/product with high ratings is preferred by users. Even e-commerce sites have started taking feedback from customers after every transaction. Delivery service providers also demanding from customers to leave the rating after getting the product/service related to service. So, recommendation systems are becoming popular as it helps in increasing the sales of an organization. They provide recommendations based upon user’s interest by considering previous purchase/interest from particular user or interested products or items by other users. The challenges in designing of these systems involved are lack of information, altering behavior and habits, etc.
In this chapter, different types of product/item-based recommendations systems as well as a food recommender system has been explained.
Keywords: Artificial intelligence, nutritional information, food sector
14.1 Introduction
Considering food the basic necessity of life either in human being or any other living form it’s the mostly ignored need have been prevailing in the present busy hi-tech generation. As the life has become faster just like fast moving consuming goods, so the need has to be modified accordingly. Prioritizing the completion of work on time forced the food at the back end in terms of body need.
Because of massive amount of data is available related to food, maximum time is wasted in searching for appropriate food products. So, “Where should we go for lunch?” or “What should we eat for dinner?” are regular questions that comes to human’s mind every day. Earlier recommender systems was used to make recommendations based upon preferences of the users like books, items, movie, or music, but now a days, they are extensively used in the food domain to resolve the above queries. Example, “RecipeKey2” is a food recommending system which extracts recipes depending upon item descriptions like cuisine, preparation time, meal type etc., food allergies and favorite ingredients chosen by users.
As the retrospective information available on internet is very high for a particular food, it becomes very hard for the person to extract beneficial information. Therefore, recommender systems have become an efficient tool for the extraction of the relevant facts and return it in a productive way. Recommender systems estimate the user’s preference for unranked things and make new recommendations to users and enhance the scope of the system.
These days, due to changing life-style and eating habits, people are suffering from many chronic diseases like obesity, diabetes [35]. A person may take care of him/her-self by consuming suitable nutritional and balanced diet [23]. Thus, food recommending software are acting as powerful tools to help the people nourish themselves with healthy food [12]. In this way, these act as a learner for user’s or consumers’ preferred ingredients and food styles, as well as recommends healthy food by considering one’s health problems, nutritional needs, and previous eating behaviors.
Incomplete balanced diet and food consumption habits are the major reasons of minor and major diseases. As, a person is not aware about major reasons of deficiency or excess of different primary nutrients, like vitamins, proteins, calcium and how to balance them in daily diet.
Many research outcomes [31, 39] had given various food recommendation systems. These systems can be characterized as:
- Food recommender systems [31, 21],
- Diet plan recommender systems,
- Menu recommender system [33],
- Recipe recommender system [39],
- (e) Health recommender systems [13, 26].
All the given systems have given suggestions to either some particular disease or to balance the diet. For example, in [31], a food recommender system is given for the diabetic patients. The system suggests several foodstuffs for diabetic patients irrespective of diabetes level that may fluctuate frequently. Also, the authors in [21] do not take into account the nutritional information that is very important for a balanced diet.
14.2 Various Techniques to Design Food Recommendation System
In some researches, authors [6, 8] defined the recommending system as given in the following definition:
“Any system that guides a user in a personalized way to interesting or useful objects in a large space of possible options or that produces such objects as output”.
These systems are mainly used for suggesting products or services like mobile phones, digital cameras, movies, financial services, books and products which best meet the interest of the users’. Nowadays, the food recommending systems are playing a crucial role to aid users to handle with the huge volume of data associated with foods and recipes. Various methods have been suggested by different researchers have discussed are as follows.
14.2.1 Collaborative Filtering Recommender Systems
CF is the most popular technique in which intelligence/interest of the crowd (large group of people) is used for recommending items. A rated dataset id used for considering the others interest. Then, nearest neighbor algorithm is applied which returns the results that are comparable to given input [9]. To implement CF based systems various approaches are used like: item-based [34], user-based [3], matrix factorization, and model-based approaches [24].
14.2.2 Content-Based Recommender Systems (CB)
Here, the recommendations are made by exploiting information of available items like ingredients and nutrition’s and user profiles. CB based systems make recommendations with recorded content, like books [28], articles, and web-pages [30]. Machine learning algorithms [27] and information Retrieval [4] are the two main approaches used for development of these systems.
14.2.3 Knowledge-Based Recommender Systems
Knowledge-based systems (KBS) systems were designed to address the issues of classical approaches like ramp-up problems [6]. These types of systems are mainly used where availability of rated data is scarce like apartments and financial services or where user defines his/her own requirements explicitly (e.g., “the color of the car should be white”). To implement knowledge based recommendation systems, two main approaches are used i.e. constraint-based recommendation [15] and case-based recommendation [5]. Critiquing-based recommendation is an alternative of case-based system that is widely used to make recommendation of particular things, and it produces users’ opinion in terms of reviews/critiques so that system accuracy [14] can be enhanced. For the implementation of KB systems following steps are followed:
- Requirement specification: To specify the requirements, users must interact with recommender systems.
- Repair of inconsistent requirements: In case, if a recommender fails to provide a possible solution, it must suggest a set of corrective measures that should propose alternatives/options to user requirements [16].
- Result presentation: For a single input, a multiple recommendations can be generated by the same system. System should present them in a rank wise order [18].
- Explanation: For every recommendation, system should provide a brief explanation to understand the relevance of a particular item [17].
14.2.4 Hybrid Recommender Systems
Hybrid recommender systems (HRS) are designed by using two or more than two different techniques so that limitations of one technique can overcome by using the approach. Author [32] describes “A hybrid system combining techniques A and B tries to use the advantages of A to fix the disadvantages of B”. For example, collaborative filtering method performs worse when a new-item is given as input. While CB approach provides a valid result as it makes recommendation for new things depending upon existing description. Author [7] proposed many hybrid approaches by merging both collaborative filtering and content based, including, switching, mixed, weighted, cascade, feature augmentation, feature combination and meta-level.
14.2.5 Context Aware Approaches
Various exploratory data analysis has proved that context to a specific food is important in food recommendation. Thus gender, hobbies, location, food availability, and time are identified as important variables. Importance of every variable can be understood by identifying what is actually lacking with respect to context like color of the food with respect to cooking duration and effect of that on the nutritional content of that specified food.
14.2.6 Group-Based Methods
Normally people eat and go for dinner in a group. Usually these activities are done together with friends, families or colleagues as food has a social role too. According to the psychology, the food choices made by a user is influenced by the society to one belongs. If the food recommendation system in such social context is addressed by human group recommendation system will be a boon for online purchasing. In such systems, a list of items is produced, for a group of people rather than for an individual user. Despite the pervasiveness of shared food consumption experiences, group based food recommender systems research has been limited.
14.2.7 Different Types of Food Recommender Systems
As presented in [29] two kinds of food recommending systems are widely used. Earlier, first type (type 1) systems were mainly used to recommend healthier recipes or food items. The type 2 recommender system recommends items which are acknowledged by nutritionist. Type 3 makes recommendations by considering both type 1 and type 2 criteria to make a balance between the user liking and healthy life style. Above defined systems are mainly intended for particular users.
Type 1: Based on user preferences
To implement these systems, the first step is to learn and characterize the user taste. Many researchers have proposed various food recommendation systems based upon user preferences [10, 20, 36], and/or combine with other approaches to enhance the accuracy of system [11, 25].
Here, a simple food recommending system was presented [10] which made recommendations for single user. In this, TF–IDF (Term Frequency– Inverse Document Frequency) filtering method was used to create user profile and to calculate similarity between a food and profile of user. As a knowledge base, healthy and standard food database taken from the United States Department of Agriculture 3 (USDA) is used. Food items are rated by each user as relevant or not relevant. Final recommendation is made by computing the similarity value. If the computed value is greater than a fixed threshold, then food item is suggested, else it will be ignored.
Author [20] proposed an approach which uses a CB algorithm to provide the recommendation by exploiting relevant data of matching ingredients present in this recipe. The recommendation procedure follows the following steps:
- Divide an unranked target recipe (rt) into its ingredients.
- Allocate the ranking score for every ingredient in the target recipe (rt).
- Calculate the ranking score of the user (ua) for the target recipe (rt) (i.e., pred(ua, rt )) based on the average of ranking scores of all ingredients ingr1, ..., ingrj included in this recipe.
- High predicted ranking score things will be recommended to user.
Type 2: Based on nutritional needs of users
Due to bad eating habits and imbalanced nutritional food, people are suffered from obesity and other dietary-related diseases like hypertension, diabetes etc. Nutritionists or dieticians suggests regular exercises and give diet plans to their patients as a treatment and preventive measures. Thus, Nutritionists become burdened with too many patients to manually advice personalized diet plan for every user. In this situation, food recommending systems can act as a smart nutrition consultation system.
Consider an example where recommendation system provides recommendations based upon users health problems as well as nutritional needs. Suppose a user enters his personal information like age: 54, gender: female, occupation: office work, physical activities: walking (15 minutes per day), disease: cardiovascular. Based on this information, recommender system performs the following steps:
- An energy table is referred to find the total calories (in kcal) a user needs in a day. The total calories required to every person are computed as per age, gender, medical history and PAL (Physical Activity Level) value. �In the above example, user works in an office and does very less physical activity (only 15 minutes per day for walking). By referring energy table according to age, gender, medical history and physical activity assume, calories requirement for user is 2,300 kcal.
- Filter foods with the total calories ≤2,300 kcal/day.
- Filtered foods must be ranked in the increasing order of fat as user suffered from heart disease; so less oily food will be recommended to him.
Type 3: Based upon preferences of users and nutrition’s requirements of users
If recommendation system considers only one parameter i.e. either user preference or nutritional needs, the system may provide sub-optimal results. For example, if system considers only preferences given by user, then bad ingestion behaviour would be encouraged. On the other hand, if only requirement of nutrition’s are referred then users will not be attracted towards the designed. Thus, taking together, nutritional needs and preferences of users will give the best solution as users get more interesting results.
Consider an example in which system provides recommendations by considering both preferences of users and nutrition’s requirements. Suppose user enters personal information as follows: Age: 54, Gender: female, Occupation: office work, worker, Physical activity: walking (15 min per day), disease: cardiovascular, Favorite ingredients: potato. The proposed model makes recommendations considering both elements preferred by the user and user-related information as follows:
- Finding the total calories a user needs by referring to the energy table. As the user works in office and is a sedentary worker (only 15 min per day for walking), so calories requirement for user is 2,300 kcal.
- Extracting food which contains less than or equal to 2,200 kcal of calories, and consider favorite ingredient “potato”.
- Rank the extracted food in the increasing order of fat as user has vascular disease.
Author [12] suggested two ways to balance users’ preferences and nutritional needs to incorporate nutritional aspects into consideration.
- The first approach balances between the food liked by user and healthy foods. To implement such models, following steps are followed:
- A prediction algorithm is used which recommends favorite recipes with computed probability greater than a predefined threshold.
- For each recipe extracted by model calories and fat per gram present in it is calculated.
- Foods with minimum fat or calories per gram will be recommended to user.
- In the second approach, rather than recommending individual foods, complete diet plans are proposed to user, which are generated.
14.3 Implementation of Food Recommender System Using Content-Based Approach
Food domain can be defined as a set of foods in which each food contains a set of ingredients. Content-based approaches make recommendations by searching related items. On the basis of a graded food, the system finds the related items with the same ingredient. For example, if a user likes salmon then system might recommend foods having salmon like sushi. The recommender system implemented in the following section is represented by vectors. Flow diagram of the proposed model is given in Figure 14.1.
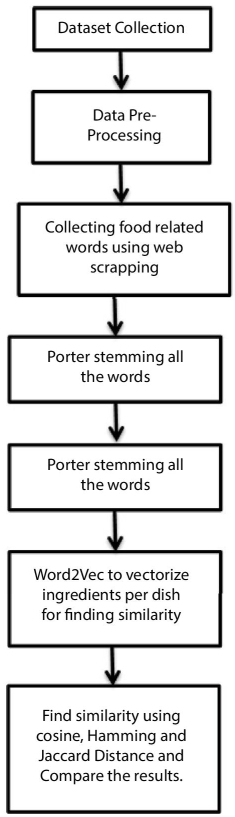
Figure 14.1 Flow chart of proposed method.
14.3.1 Item Profile Representation
In CB systems, features and attributes are used to describe the items. Different similarity metrics are used to compute the similarity between the feature vectors such as Euclidian or cosine similarity. Though, human decision of matching two things often gives different weights to different features. Other than this, document frequency is also commonly used criteria.
14.3.2 Information Retrieval
Information retrieval (IR) is a data search and collection technology which includes crawling, processing and indexing of content, and questioning for content. Web crawling is the process by which information is collected from the web, so that ranking can be performed. It supports a search engine. The aim of crawling is to quickly and efficiently collect as much suitable web pages as possible, along with the link structure that interconnects them.
Due to the high complexity of food domain, several challenges arise while making recommendations. For making suitable suggestions, maximum number of food items/ingredients need to be collected. As foods/ingredients are typically associated with each other in a recipe instead of being consumed independently [20], recipes dataset needs to collect. From the recipes datasets, food/ingredient words are extracted and all unnecessary words are discarded.
14.3.3 Word2vec
Machines are not good in dealing with raw data. In fact, it’s almost impossible for machines to deal with any other data except for numerical data. So, representing text in the form of vectors is the most important step in all NLP processes.
Word2vec embedding’s the most popular method introduced to the NLP community in 2013. This embedding’s proved to be state-of-the-art for tasks such as word analogies and word similarities. Word2vec embedding’s also able to accomplish tasks such as King—man, woman ~= Queen, which is considered an almost magical result.
There are two alternatives of a word2vec model II—Continuous Bag of Words and Skip-Gram model. In this implementation, Bag of Words model is used. In a document, the word occurrence is represented by bag-of-words model and widely used in applications like natural language processing (NLP) and information retrieval (IR). The model deals checks the presence of word without looking at the context. It consists of two things: a vocabulary of known words and a measure of the presence of known words. Features from the text can be extracted to model learning applications.
14.3.4 How are word2vec Embedding’s Obtained?
A word2vec model is a simple neural network (NN) model with a single hidden layer. The task of this model is to estimate the nearby words for each and every word in a sentence. However, our objective has nothing to with this task. All we want are the weights learned by the hidden layer of the model once the model is trained. These weights can then be used as the word embeddings. Let me give you an example to understand how a word2vec model works. Consider the sentence below:
“Quantum computing researcher’s teleport data inside a diamond.”
Let’s say the word “teleport” is our input word. It has a context window of size 2. This means we are considering only the 2 adjacent words on either side of the input word as the nearby words.
Note: The size of the context window is not fixed; it can be changed as per our requirement.
Now, the task is to pick the nearby words (words in the context window) one-by-one and find the probability of every word in the vocabulary of being the selected nearby word.
14.3.5 Obtaining word2vec Embeddings
Now, let’s say we have a bunch of sentences and we extract training samples from them in the same manner. We will end up with training data of considerable size. Suppose the number of unique words in this dataset is 5,000 and we wish to create word vectors of size 100 each. Then, with respect to the word2vec architecture given in Figure 14.2:
- V = 5000 (size of vocabulary)
- N = 100 (number of hidden units or length of word embeddings)
The inputs would be the one-hot-encoded vectors and the output layer would give the probability of being the nearby word for every word in the vocabulary. Once this model is trained, we can easily extract the learned weight matrix WV × N and use it to extract the word vectors.

Figure 14.2 word2vec Model.
14.3.6 Dataset
For the implementation of recommender system, dataset has been collected from “eightportions.com”. It contains approximately 125,000 recipes which are collected by web scrapping various web sites. A recipe is defined in a systematic system using different components like title of the recipe, a list of ingredients and measurements, directions for preparation, and a photo of the resultant dish.
This dataset is mainly used for machine learning algorithms as each recipe comprises many components, each of which provides additional information about the recipe.
14.3.6.1 Data Preprocessing
Data preprocessing is used to clean the data and converted into the input format. As dataset contains information of complete recipes, so a lot of unnecessary words are present. A list of stop words like ‘for, of, you’ etc. has been created and based upon stop lists useless words are removed from dataset.
14.3.7 Web Scrapping For Food List
As we have lot of unnecessary words in the recipe like cups, tablespoons, number etc. Thus, these words must be removed and only words related to foods needs to be retained. For this, knowledge of food words is mandatory. So, a list of food words has been created by using web scrapping from various websites.
14.3.7.1 Porter Stemming All Words
Porter stemming is a method for eliminating suffixes from words in English. Eliminating suffixes automatically is an operation which is especially useful in the information retrieval. Thus by using this, each word is converted into root word.
14.3.7.2 Filtering Our Ingredients
After stemming all words into the root words, all the recipes are filtered to get only food words.
14.3.7.3 Final Data Frame with Dishes and Their Ingredients
Final data frame with dishes and their ingredients have been created using word2vec method.
14.3.7.3.1 Similarity Metrics
Results are computed using three different matrices: Cosine Similarity, Hamming Distance and Jaccard Distance.
14.3.7.3.2 Cosine Similarity
Cosine similarity: It computes the similarity between user and item. This method is best when we have high dimensional features especially in information retrieval and text mining. The range of this is between −1 and 1 and there are two approaches:
- Top-n approach: In this, best ‘n’ suggestions are selected and here n is decided by user.
- Rating scale approach: In this a threshold is set and all the recommendations above threshold are recommended.
The cosine of two non-zero vectors can be computed by using the Euclidean dot product formula:
Thus, cosine similarity, cos(θ) is computed for given two vectors of attributes, A and B, is as follows

14.3.7.4 Hamming Distance
Hamming distance is computed by matching two binary strings of equal length. It is the number of bit positions in which the two bits are different. It is mainly used for detection and correction of errors during the transmission of data over computer networks. It is also using for measuring similarity in coding theory.
14.3.7.5 Jaccard Distance
This metric is performed to check for similarity between two items. It compares item vectors with each other and rejects the most similar item. This is only useful when vectors contain binary values. If any ratings or rankings having multiple values then this method is not applicable.
The Jaccard index, also called as Intersection over Union (IoU). Figures 14.3, 14.4 and 14.5 show the results computed using hamming distance, Jaccard distance and cosine similarity respectively.
14.4 Results
Input Data: Potato
Results of Hamming Distance:

Figure 14.3 Hamming distance output.
Results of Jaccard Distance:

Figure 14.4 Jaccard distance output.
Results of Cosine Similarity

Figure 14.5 Cosine similarity output.
14.5 Observations
From the experimental results, it can be concluded that hamming distance does not show any semantic similarity between input and output ingredients. Cosine similarity shows the semantic similarity but results are much better with Jaccard distance.
14.6 Future Perspective of Recommender Systems
The present study on the framework of the food recommender system plays an important role in terms of helping people to select a diet which matches their health conditions and interests. In order to develop food recommendation system, these research studies utilize the information about the user recipes and the profiles. It has been identified that the excellence of recommendations is greatly influenced by the capability and precision of nutritional and user information of food. However, on this concern, the modern study has not generated so much detailed information or outcome. But as per the postulates of some researchers [1, 40] that suggests food recommendations in perspective with health issues but suggestions on the subject of altering eating behaviors were still missing which are essential for the maintenance of healthy lifestyle. To generate the more trust of the users in the recommendations systems and to encourage the users to follow good eating habits explanations could be beneficial but the incorporation of explanations or detailed information has not received much attention from the researchers [18]. Moreover, food recommendation research rather than focusing on group scenarios focuses on the scenarios of the single user. Till now, research on group scenarios food recommender system in healthy food domain is very restricted. In the research [20] suggested a variety of aggregation techniques for creating food recommendations for user groups. However, still there exist some open concerns which need to be taken into consideration along with the scope of the future work for e.g.: development of group based food recommender system. Here, some research challenges of food recommender systems and their potential solutions are discussed.
14.6.1 User Information Challenges
14.6.1.1 User Nutrition Information Uncertainty
To provide efficient results, program must have nutritional needs, food item ratings/recipes and users,’ previous meal information [29]. Maximum data can be collected through regular interactions with the users. Though, nutritional intake is recorded by using some mechanism but in reality, recording users’ nutritional intake cannot avoid faults as users usually forget to or give false information regarding the foods they have eaten [19]. However, many researchers have proposed many systems to address these issues, such as FOODLOG [2], they are unable to provide precise data on the foods consumed, even though they can estimate the amount of nutritional balance from various type of food in a meal.
14.6.1.2 User Rating Data Collection
Food recommendation systems require user preferences information for the recommendation food items [29, 41]. It is possible to collect this information by requesting users to rank recipes/food. Though, it is not appropriate, if the system asks users to rank too many items. Therefore, it is big challenge that how to collect enough user ratings without taking much user time.
14.6.2 Recommendation Algorithms Challenges
Any algorithm requires the following information to calculate nutritional recommendations for user [29].
14.6.2.1 User Information Such as Likes/Dislikes Food or Nutritional Needs
when the food recommending system is first in other areas, it has faced the cold-start issue [29]. This issue can be resolved by considering knowledge about previous meals to measure similarities and then suggest new recipes to users [41], though this approach needs a great effort from the user and diminishes the incentive for device use.
14.6.2.2 Recipe Databases
Author [32] described about two issues: number of recipes should the program contain? The amount of recipes collected should be sufficiently large to satisfy multiple users, tastes and modify the suggested recipes while reducing the time consumption to make suggestions. This is a difficult issue when the system attempts to balance the response time of the system and variety of recommendations.
Ge et. al., [22] point out that long response times are the reasons of the user dissatisfaction that further limits the systems continued use. How to collect correct recipes nutritional information? Author [29] reported that with the same food item we can receive different nutritional values from it if we use different ways to cook it.
Furthermore, it is very hard to confirm that whether collected nutritional tables for food items are accurate, as it sometimes returns different values for the same food times on comparing different nutritional value table. For example, in “a salad recipe,” the nutritional value of celery differs from the nutritional value of itself “in a fried recipe,” as cooking at high temperatures causes celery to lose a large amount of essential oil. This means that in the “fried recipe” the quantity of essential celery oil may be less than in the “salad recipe.”
14.6.2.3 A Set of Constraints or Rules
The quality of recommendations will be enhanced by more constraints and rules in the recommendation process.For example, Food menus with less fat and salt should be recommended with a user who has heart disease. In addition, the contradictions between the constraints or rules that prevent the recommendation algorithms from finding a solution are very important to identify. Nevertheless, testing constraints/rules in the database with the large database (e.g., thousands of foods/recipes) has negative effects on system performance. Therefore, food recommendation systems must take into account restrictions about the availability of ingredients in households in order to help consumers to save money and avoid the actions of food waste. The problem here is how to recommend food that serves consumers’ health and nutritional needs, as well as take advantage of the ingredients already in the refrigerator. Recommendation systems appear to require a lot of effort from consumers in this situation as consumers need to document the use of all ingredients on a regular basis and this can discourage consumers from using the program permanently.
14.6.3 Challenges Concerning Changing Eating Behavior of Consumers
Presently, due to inappropriate eating habits, many people suffer from health problems [37]. For example, in relation with their level of physical activity, most people eat too much food and eventually become obese. While others limit extreme intake of nutrition, this leads to malnutrition. Therefore, recognizing the eating habits of consumers and persuading them to alter eating patterns in positive ways is one of the main functions of food recommender systems. This is a huge challenge for food recommendation system; however, as eating activity is influenced by many factors. In order to inspire consumers to follow healthy diet, food recommendation systems should incorporate health psychology theory. Using one simple change at a specific time, the first approach can be used until consumer behaviour becomes usual [32]. Further approach can be applied for food recommender system is to compare the ideal nutrient. Consumers can find the optimal diet structure from reputable data based on age and physical activity level (e.g., USDA, DACH) and then analyze the food they eat with what is prescribed in [37]. The comparison approach is also proposed to provide consumers with potential dietary changes in paper proposed [27].
14.6.4 Challenges Regarding Explanations and Visualizations
Visualizations and explanations have a vital role in recommendation systems as consumers’ confidence increases in the outcome of decisions [38]. Explanations are even more important in the healthy food domain as they not only increase confidence in recommenders but also encourage consumers to eat healthy foods and improve their eating habits. For the purpose of this, it makes sense that food recommendation systems explanations explain how adequacy results are obtained [11]. In addition, a specific explanation of food items such as a nutritional value table for a recipe must be involved in a manner that focuses the health of a particular consumer food.
14.7 Conclusion
Food recommender system plays a vital role in both individual’s life and society. Food recommender systems for nutritional researchers have suggested various approaches of integrating nutrition like nutritional components in algorithm, meal plans, and nudging etc., yet all these methods are not clear and none of them is proved best method to consider.
In this chapter, on the basis of addressing, various kinds of food recommendation systems are discussed. In many food recommendation systems, commonly used recommendation techniques such as collaborative filtering recommendation, content based recommendation, and constraint based recommendation are used. In addition, hybrid methods are also used for the improvement of the performance of the recommender. While seen in different contexts, all food recommendation systems generally play a vital role in providing food products or items that meet the preferences of the consumers’ and appropriate nutritional needs as well as persuading them to follow healthy eating habits.
Acknowledgements
The authors are grateful to Mr. Sambhal Shikhar, student of Lovely Professional University, Phagwara, India who helped us in the implementation of the project.
References
- 1. Aberg, J., Dealing with Malnutrition: A Meal Planning System for Elderly, in: AAAI Spring Symposium: Argumentation for Consumers of Healthcare, pp. 1–7, 2006.
- 2. Aizawa, K., De Silva, G.C., Ogawa, M., Sato, Y., Food log by snapping and processing images, in: 2010 16th International Conference on Virtual Systems and Multimedia, IEEE, pp. 71–74, 2010.
- 3. Asanov, D., Algorithms and methods in recommender systems, Berlin Institute of Technology, Berlin, Germany, 2011.
- 4. Balabanović, M. and Shoham, Y., Fab: content-based, collaborative recommendation. Commun. ACM, 40, 3, 66–72, 1997.
- 5. Bridge, D., Göker, M.H., McGinty, L., Smyth, B., Case-based recommender systems. Knowl. Eng. Rev., 20, 3, 315–320, 2005.
- 6. Burke, R., Knowledge-based recommender systems, in: Encyclopedia of library and information systems, vol. 69, Marcel Dekker (Ed.), pp. 180–200, 2000.
- 7. Burke, R., Hybrid recommender systems: Survey and experiments. User Model. User-ADAP, 12, 4, 331–370, 2002.
- 8. Burke, R., Felfernig, A., Göker, M.H., Recommender systems: An overview. AI Mag., 32, 3, 13–18, 2011.
- 9. Ekstrand, M.D., Riedl, J.T., Konstan, J.A., Collaborative filtering recommender systems. Found. Trends® Hum.–Comput. Interact., 4, 2, 81–173, 2011.
- 10. El-Dosuky, M.A., Rashad, M.Z., Hamza, T.T., El-Bassiouny, A.H., Food recommendation using ontology and heuristics, in: International Conference on Advanced Machine Learning Technologies and Applications, Springer, Berlin, Heidelberg, pp. 423–429, 2012.
- 11. Elahi, M., Ge, M., Ricci, F., Fernández-Tobías, I., Berkovsky, S., David, M., Interaction design in a mobile food recommender system, in: CEUR Workshop Proceedings, CEUR-WS, 2015.
- 12. Elsweiler, D., Harvey, M., Ludwig, B., Said, A., Bringing the “healthy” into Food Recommenders, in: DMRS, pp. 33–36, 2015.
- 13. Evert, A.B., Boucher, J.L., Cypress, M., Dunbar, S.A., Franz, M.J., Mayer-Davis, E.J., Yancy, W.S., Nutrition therapy recommendations for the management of adults with diabetes. Diabetes Care, 37, Supplement 1, S120–S143, 2014.
- 14. Felfernig, A., Biases in decision making, in: Proceedings of the First International Workshop on Decision Making and Recommender systems (DMRS2014), Bolzano, Italy, September 18–19, 2014, vol. 1278, CEUR Proceedings, pp. 32–37, 2014.
- 15. Felfernig, A. and Burke, R., Constraint-based recommender systems: technologies and research issues, in: Proceedings of the 10th International Conference on Electronic Commerce, ACM, p. 3, 2008.
- 16. Felfernig, A., Friedrich, G., Jannach, D., Zanker, M., Developing constraint-based recommenders, in: Recommender systems handbook, pp. 187–215, Springer, Boston, MA, 2011.
- 17. Felfernig, A., Zehentner, C., Ninaus, G., Grabner, H., Maalej, W., Pagano, D., Reinfrank, F., Group decision support for requirements negotiation, in: International Conference on User Modeling, Adaptation, and Personalization, pp. 105–116, Springer, Berlin, Heidelberg, 2011.
- 18. Felfernig, A., Hotz, L., Bagley, C., Tiihonen, J., Knowledge-based configuration: From research to business cases, Elsevier, Newnes, 2014.
- 19. Felfernig, A., Stettinger, M., Ninaus, G., Jeran, M., Reiterer, S., Falkner, A.A., Tiihonen, J., Towards Open Configuration, in: Configuration Workshop, pp. 89–94, 2014.
- 20. Freyne, J. and Berkovsky, S., Intelligent food planning: personalized recipe recommendation, in: Proceedings of the 15th International Conference on Intelligent User Interfaces, ACM, pp. 321–324, 2010.
- 21. Ge, M., Elahi, M., Fernaández-Tobías, I., Ricci, F., Massimo, D., Using tags and latent factors in a food recommender system, in: Proceedings of the 5th International Conference on Digital Health 2015, ACM, pp. 105– 112, 2015.
- 22. Hoxmeier, J.A. and DiCesare, C., System response time and user satisfaction: An experimental study of browser-based applications. AMCIS. 2000 Proc., 347, 140–145, 2000.
- 23. Knowler, W.C., Barrett-Connor, E., Fowler, S.E., Hamman, R.F., Lachin, J.M., Walker, E.A., Nathan, D.M., Reduction in the incidence of type 2 diabetes with lifestyle intervention or metformin. N. Engl. J. Med., 346, 6, 393–403, 2002.
- 24. Koren, Y., Bell, R., Volinsky, C., Matrix factorization techniques for recommender systems. Comput., 8, 30–37, 2009.
- 25. Kuo, F.F., Li, C.T., Shan, M.K., Lee, S.Y., Intelligent menu planning: Recommending set of recipes by ingredients, in: Proceedings of the ACM Multimedia 2012 Workshop on Multimedia for Cooking and Eating Activities, pp. 1–6, ACM, 2012.
- 26. LeFevre, M.L., Behavioral counseling to promote a healthful diet and physical activity for cardiovascular disease prevention in adults with cardiovascular risk factors: US Preventive Services Task Force Recommendation Statement. Ann. Intern. Med., 161, 8, 587–593, 2014.
- 27. Mankoff, J., Hsieh, G., Hung, H.C., Lee, S., Nitao, E., Using low-cost sensing to support nutritional awareness, in: International Conference on Ubiquitous Computing, Springer, Berlin, Heidelberg, pp. 371–378, 2002.
- 28. Mooney, R.J. and Roy, L., Content-based book recommending using learning for text categorization, in: Proceedings of the Fifth ACM Conference on Digital Libraries, ACM, pp. 195–204, 2000.
- 29. Mika, S., Challenges for nutrition recommender systems, in: Proceedings of the 2nd Workshop on Context Aware Intel. Assistance, Berlin, Germany, pp. 25–33, 2011.
- 30. Pazzani, M.J., Muramatsu, J., Billsus, D., Syskill & Webert: Identifying interesting web sites, in: AAAI/IAAI, vol. 1, pp. 54–61, 1996.
- 31. Phanich, M., Pholkul, P., Phimoltares, S., Food recommendation system using clustering analysis for diabetic patients, in: 2010 International Conference on Information Science and Applications, IEEE, pp. 1–8, 2010.
- 32. Ricci, F., Rokach, L., Shapira, B., Introduction to recommender systems handbook, in: Recommender systems handbook, pp. 1–35, Springer, Boston, MA, 2011.
- 33. Runo, M., FooDroid: a food recommendation app for university canteens. Unpublished semester thesis, Swiss Federal Institute of Theology, Zurich, 2011.
- 34. Sarwar, B.M., Karypis, G., Konstan, J.A., Riedl, J., Item-based collaborative filtering recommendation algorithms. Www, 1, 285–295, 2001.
- 35. Robertson, A., Tirado, C., Lobstein, T., Knai, C., Jensen, J., Ferro-Luzzi, A., James, W., Food and Health in Europe: A New Basis for Action (European Series No 96), WHO, 2004.
- 36. Svensson, M., Laaksolahti, J., Höök, K., Waern, A., A recipe based on-line food store, in: Proceedings of the 5th International Conference on Intelligent User Interfaces, ACM, pp. 260–263, 2000.
- 37. Snooks, M.K., Health psychology: Biological, psychological, and sociocultural perspectives, Jones & Bartlett Publishers, 2009.
- 38. Tintarev, N. and Masthoff, J., A survey of explanations in recommender systems, in: 2007 IEEE 23rd International Conference on Data Engineering Workshop, IEEE, pp. 801–810, 2007.
- 39. Teng, C.Y., Lin, Y.R., Adamic, L.A., Recipe recommendation using ingredient networks, in: Proceedings of the 4th Annual ACM Web Science Conference, ACM, pp. 298–307, 2012.
- 40. Ueta, T., Iwakami, M., Ito, T., A recipe recommendation system based on automatic nutrition information extraction, in: International Conference on Knowledge Science, Engineering and Management, Springer, Berlin, Heidelberg, pp. 79–90, 2011.
- 41. Van Pinxteren, Y., Geleijnse, G., Kamsteeg, P., Deriving a recipe similarity measure for recommending healthful meals, in: Proceedings of the 16th International Conference on Intelligent User Interfaces, ACM, pp. 105–114, 2011.
Note
- * Corresponding author: [email protected]