
Object-oriented programming has become a mainstream, or even the mainstream, way of approaching programming. The idea is a simple one: instead of defining our functions in one part of the code, and the data on which those functions operate in a separate part of the code, we define them together.
Or, to put it in terms of language, in traditional, procedural programming, we write a list of nouns (data) and a separate list of verbs (functions), leaving it up to the programmer to figure out which goes with which. In object-oriented programming, the verbs (functions) are defined along with the nouns (data), helping us to know what goes with what.
In the world of object-oriented programming, each noun is an object. We say that each object has a type, or a class, to which it belongs. And the verbs (functions) we can invoke on each object are known as methods.
For an example of traditional, procedural programming versus object-oriented programming, consider how we could calculate a student’s final grade, based on the average of their test scores. In procedural programming, we’d make sure the grades were in a list of integers and then write an average function that returned the arithmetic mean:
def average(numbers):
return sum(numbers) / len(numbers)
scores = [85, 95, 98, 87, 80, 92]
print(f'The final score is {average(scores)}.')
This code works, and works reliably. But the caller is responsible for keeping track of the numbers as a list ... and for knowing that we have to call the average method ... and for combining them in the right way.
In the object-oriented world, we would approach the problem by creating a new data type, which we might call a ScoreList. We would then create a new instance of ScoreList.
Even if it’s the same data underneath, a ScoreList is more explicitly and specifically connected to our domain than a generic Python list. We could then invoke the appropriate method on the ScoreList object:
class ScoreList():
def __init__(self, scores):
self.scores = scores
def average(self):
return sum(self.scores) / len(self.scores)
scores = ScoreList([85, 95, 98, 87, 80, 92])
print(f'The final score is {scores.average()}.')
As you can see, there’s no difference from the procedural method in what’s actually being calculated, and even what technique we’re using to calculate it. But there’s an organizational and semantic difference here, one that allows us to think in a different way.
We’re now thinking at a higher level of abstraction and can better reason about our code. Defining our own types also allows us to use shorthand when describing concepts. Consider the difference between telling someone that you bought a “bookshelf” and describing “wooden boards held together with nails and screws, stored upright and containing places for storing books.” The former is shorter, less ambiguous, and more semantically powerful than the latter.
Another advantage is that if we decide to calculate the average in a new way--for example, some teachers might drop the lowest score--then we can keep the existing interface while modifying the underlying implementation.
So, what are the main reasons for using object-oriented techniques?
-
We can organize our code into distinct objects, each of which handles a different aspect of our code. This makes for easier planning and maintenance, as well as allowing us to divide a project among multiple people.
-
We can create hierarchies of classes, with each child in the hierarchy inheriting functionality from its parents. This reduces the amount of code we need to write and simultaneously reinforces the relationships among similar data types. Given that many classes are slight modifications of other ones, this saves time and coding.
-
By creating data types that work the same way as Python’s built-in types, our code feels like a natural extension to the language, rather than bolted on. Moreover, learning how to use a new class requires learning only a tiny bit of syntax, so you can concentrate on the underlying ideas and functionality.
-
While Python doesn’t hide code or make it private, you’re still likely to hear about the difference between an object’s implementation and its interface. If I’m using an object, then I care about its interface--that is, the methods that I can call on it and what they do. How the object is implemented internally is not a priority for me and doesn’t affect my day-to-day work. This way, I can concentrate on the coding I want to do, rather than the internals of the class I’m using, taking advantage of the abstraction that I’ve created via the class.
Object-oriented programming isn’t a panacea; over the years, we’ve found that, as with all other paradigms, it has both advantages and disadvantages. For example, it’s easy to create monstrously large objects with huge numbers of methods, effectively creating a procedural system disguised as an object-oriented one. It’s possible to abuse inheritance, creating hierarchies that make no sense. And by breaking the system into many small pieces, there’s the problem of testing and integrating those pieces, with so many possible lines of communication.
Nevertheless, the object paradigm has helped numerous programmers to modularize their code, to focus on specific aspects of the program on which they’re working, and to exchange data with objects written by other people.
In Python, we love to say that “everything is an object.” At its heart, this means that the language is consistent; the types (such as str and dict) that come with the language are defined as classes, with methods. Our objects work just like the built-in objects, reducing the learning curve for both those implementing new classes and those using them.
Consider that when you learn a foreign language, you discover that nouns and verbs have all sorts of rules. But then there are the inevitable inconsistencies and exceptions to those rules. By having one consistent set of rules for all objects, Python removes those frustrations for non-native speakers--giving us, for lack of a better term, the Esperanto of programming languages. Once you’ve learned a rule, you can apply it throughout the language.
Note One of the hallmarks of Python is its consistency. Once you learn a rule, it applies to the entire language, with no exceptions. If you understand variable lookup (LEGB, described in chapter 6) and attribute lookup (ICPO, described later in this chapter), you’ll know the rules that Python applies all of the time, to all objects, without exception--both those that you create and those that come baked into the language.
At the same time, Python doesn’t force you to write everything in an object-oriented style. Indeed, it’s common to combine paradigms in Python programs, using an amalgam of procedural, functional, and object-oriented styles. Which style you choose, and where, is left up to you. But at the end of the day, even if you’re not writing in an object-oriented style, you’re still using Python’s objects.
If you’re going to code in Python, you should understand Python’s object system--the ways objects are created, how classes are defined and interact with their parents, and how we can influence the ways classes interact with the rest of the world. Even if you write in a procedural style, you’ll still be using classes defined by other people, and knowing how those classes work will make your coding easier and more straightforward.
This chapter contains exercises aimed at helping you to feel more comfortable with Python’s objects. As you go through these exercises, you’ll create classes and methods, create attributes at the object and class levels, and work with such concepts as composition and inheritance. When you’re done, you’ll be prepared to create and work with Python objects, and thus both write and maintain Python code.
Note The previous chapter, about modules, was short and simple. This chapter is the opposite--long, with many important ideas that can take some time to absorb. This chapter will take time to get through, but it’s worth the effort. Understanding object-oriented programming won’t just help you in writing your own classes; it’ll also help you to understand how Python itself is built, and how the built-in types work.
Table 9.1 What you need to know
|
Method that returns a string containing an object’s printed representation |
|||
|
Returns a proxy object on which methods can be invoked; typically used to invoke a method on a parent class |
|||
Exercise 38 ■ Ice cream scoop
If you’re going to be programming with objects, then you’ll be creating classes--lots of classes. Each class should represent one type of object and its behavior. You can think of a class as a factory for creating objects of that type--so a Car class would create cars, also known as “car objects” or “instances of Car.” Your beat-up sedan would be a car object, as would a fancy new luxury SUV.
In this exercise, you’ll define a class, Scoop, that represents a single scoop of ice cream. Each scoop should have a single attribute, flavor, a string that you can initialize when you create the instance of Scoop.
Once your class is created, write a function (create_scoops) that creates three instances of the Scoop class, each of which has a different flavor (figure 9.1). Put these three instances into a list called scoops (figure 9.2). Finally, iterate over your scoops list, printing the flavor of each scoop of ice cream you’ve created.

Figure 9.1 Three instances of Scoop, each referring to its class

Figure 9.2 Our three instances of Scoop in a list
Working it out
The key to understanding objects in Python--and much of the Python language--is attributes. Every object has a type and one or more attributes. Python itself defines some of these attributes; you can identify them by the __ (often known as dunder in the Python world) at the beginning and end of the attribute names, such as __name__ or __init__.
When we define a new class, we do so with the class keyword. We then name the class (Scoop, in this case) and indicate, in parentheses, the class or classes from which our new class inherits.
Our __init__ method is invoked after the new instance of Scoop has been created, but before it has been returned to whoever invoked Scoop('flavor'). The new object is passed to __init__ in self (i.e., the first parameter), along with whatever arguments were passed to Scoop(). We thus assign self.flavor = flavor, creating the flavor attribute on the new instance, with the value of the flavor parameter.
Just as with regular Python functions, there isn’t any enforcement of types here. The assumption is that flavor will contain a str value because the documentation will indicate that this is what it expects.
Note If you want to enforce things more strictly, then consider using Python’s type annotations and Mypy or a similar type-checking tool. You can find more information about Mypy at http://mypy-lang.org/. Also, you can find an excellent introduction to Python’s type annotations and how to use them at http://mng.bz/mByr.
To create three scoops, I use a list comprehension, iterating over the flavors and creating new instances of Scoop. The result is a list with three Scoop objects in it, each with a separate flavor:
scoops = [Scoop(flavor)
for flavor in ('chocolate', 'vanilla', 'persimmon')]
If you’re used to working with objects in another programming language, you might be wondering where the “getter” and “setter” methods are, to retrieve and set the value of the flavor attribute. In Python, because everything is public, there’s no real need for getters and setters. And indeed, unless you have a really good reason for it, you should probably avoid writing them.
Note If and when you find yourself needing a getter or setter, you might want to consider a Python property, which hides a method call behind the API of an attribute change or retrieval. You can learn more about properties here: http://mng.bz/5aWB.
I should note that even our simple Scoop class exhibits several things that are common to nearly all Python classes. We have an __init__ method, whose parameters allow us to set attributes on newly created instances. It stores state inside self, and it can store any type of Python object in this way--not just strings or numbers, but also lists and dicts, as well as other types of objects.
Note Don’t make persimmon ice cream. Your family will never let you forget it.
Solution
class Scoop():
def __init__(self, flavor): ❶
self.flavor = flavor ❷
def create_scoops():
scoops = [Scoop('chocolate'),
Scoop('vanilla'),
Scoop('persimmon')]
for scoop in scoops:
print(scoop.flavor)
create_scoops()
❶ Every method’s first parameter is always going to be “self,” representing the current instance.
❷ Sets the “flavor” attribute to the value in the parameter “flavor”
You can work through a version of this code in the Python Tutor at http://mng.bz/ 8pMZ.
Screencast solution
Watch this short video walkthrough of the solution: https://livebook.manning.com/ video/python-workout.
Beyond the exercise
If you’re coding in Python, you’ll likely end up writing classes on a regular basis. And if you’re doing that, you’ll be writing many __init__ methods that add attributes to objects of various sorts. Here are some additional, simple classes that you can write to practice doing so:
-
Write a
Beverageclass whose instances will represent beverages. Each beverage should have two attributes: a name (describing the beverage) and a temperature. Create several beverages and check that their names and temperatures are all handled correctly. -
Modify the
Beverageclass, such that you can create a new instance specifying the name, and not the temperature. If you do this, then the temperature should have a default value of 75 degrees Celsius. Create several beverages and double-check that the temperature has this default when not specified. -
Create a new
LogFileclass that expects to be initialized with a filename. Inside of__init__, open the file for writing and assign it to an attribute,file, that sits on the instance. Check that it’s possible to write to the file via thefileattribute.
class Foo():
def __init__(self, x):
self.x = x
f = Foo(10) print(f.x)
class Person:
def __init__(self, name):
self.name = name
p = Person('myname')

Figure 9.3 When we create an object, __new__ is invoked.

__Figure 9.4 new__ then calls __init__.

Figure 9.5 __init__ adds attributes to the object.

Figure 9.6 Finally, __init__ exits, and the object in __new__ is returned to the caller.
Exercise 39 ■ Ice cream bowl
Whenever I teach object-oriented programming, I encounter people who’ve learned it before and are convinced that the most important technique is inheritance. Now, inheritance is certainly important, and we’ll look into it momentarily, but a more important technique is composition, when one object contains another object.
Calling it a technique in Python is a bit overblown, since everything is an object, and we can assign objects to attributes. So having one object owned by another object is just ... well, it’s just the way that we connect objects together.
That said, composition is also an important technique, because it lets us create larger objects out of smaller ones. I can create a car out of a motor, wheels, tires, gearshift, seats, and the like. I can create a house out of walls, floors, doors, and so forth. Dividing a project up into smaller parts, defining classes that describe those parts, and then joining them together to create larger objects--that’s how object-oriented programming works.
In this exercise, we’re going to see a small-scale version of that. In the previous exercise, we created a Scoop class that represents one scoop of ice cream. If we’re really going to model the real world, though, we should have another object into which we can put the scoops. I thus want you to create a Bowl class, representing a bowl into which we can put our ice cream (figure 9.7); for example
s1 = Scoop('chocolate')
s2 = Scoop('vanilla')
s3 = Scoop('persimmon')
b = Bowl()
b.add_scoops(s1, s2)
b.add_scoops(s3)
print(b)

Figure 9.7 A new instance of Bowl, with an empty list of scoops
The result of running print(b) should be to display the three ice cream flavors in our bowl (figure 9.8). Note that it should be possible to add any number of scoops to the bowl using Bowl.add_scoops.

Figure 9.8 Three Scoop objects in our bowl
Working it out
The solution doesn’t involve any changes to our Scoop class. Rather, we create our Bowl such that it can contain any number of instances of Scoop.
First of all, we define the attribute self.scoops on our object to be a list. We could theoretically use a dict or a set, but given that there aren’t any obvious candidates for keys, and that we might want to preserve the order of the scoops, I’d argue that a list is a more logical choice.
Remember that we’re storing instances of Scoop in self.scoops. We aren’t just storing the string that describes the flavors. Each instance of Scoop will have its own flavor attribute, a string containing the current scoop’s flavor.
We create the self.scoops attribute, as an empty list, in __init__.
Then we need to define add_scoops, which can take any number of arguments--which we’ll assume are instances of Scoop--and add them to the bowl. This means, almost by definition, that we’ll need to use the splat operator (*) when defining our *new_scoops parameter. As a result, new_scoops will be a tuple containing all of the arguments that were passed to add_scoops.
Note There’s a world of difference between the variable new_scoops and the attribute self.scoops. The former is a local variable in the function, referring to the tuple of Scoop objects that the user passed to add_scoops. The latter is an attribute, attached to the self local variable, that refers to the object instance on which we’re currently working.
We can then iterate over each element of scoops, adding it to the self.scoops attribute. We do this in a for loop, invoking list.append on each scoop.
Finally, to print the scoops, we simply invoke print(b). This has the effect of calling the __repr__ method on our object, assuming that one is defined. Our __repr__ method does little more than invoke str.join on the strings that we extract from the flavors.
Notice, however, that we’re not invoking str.join on a list comprehension, because there are no square brackets. Rather, we’re invoking it on a generator expression, which you can think of as a lazy-evaluating version of a list comprehension. True, in a case like this, there’s really no performance benefit. My point in using it was to demonstrate that nearly anywhere you can use a list comprehension, you can use a generator expression instead.
Solution
class Scoop():
def __init__(self, flavor):
self.flavor = flavor
class Bowl():
def __init__(self):
self.scoops = [] ❶
def add_scoops(self, *new_scoops): ❷
for one_scoop in new_scoops:
self.scoops.append(one_scoop)
def __repr__(self):
return '
'.join(s.flavor for s in self.scoops) ❸
s1 = Scoop('chocolate')
s2 = Scoop('vanilla')
s3 = Scoop('persimmon')
b = Bowl()
b.add_scoops(s1, s2)
b.add_scoops(s3)
print(b)
❶ Initializes self.scoops with an empty list
❷ *new_scoops is just like *args. You can use whatever name you want.
❸ Creates a string via str.join and a generator expression
You can work through a version of this code in the Python Tutor at http://mng.bz/EdWo.
Screencast solution
Watch this short video walkthrough of the solution: https://livebook.manning.com/ video/python-workout.
Beyond the exercise
You’ve now seen how to create an explicit “has-a” relationship between two classes. Here are some more opportunities to explore this type of relationship:
-
Create a
Bookclass that lets you create books with a title, author, and price. Then create aShelfclass, onto which you can place one or more books with anadd_bookmethod. Finally, add atotal_pricemethod to theShelfclass, which will total the prices of the books on the shelf. -
Write a method,
Shelf.has_book, that takes a single string argument and returnsTrueorFalse, depending on whether a book with the named title exists on the shelf. -
Modify your
Bookclass such that it adds another attribute,width. Then add awidthattribute to each instance ofShelf. Whenadd_booktries to add books whose combined widths will be too much for the shelf, raise an exception.
s = 'abcd' print(s.upper())
class Foo():
def __init__(self, x):
self.x = x
def x2(self):
return self.x * 2
class Bar(Foo):
def x3(self):
return self.x * 3
b = Bar(10)
print(b.x2()) ❶
print(b.x3()) ❷

Figure 9.9 Bar inherits from Foo, which inherits from object.

Exercise 40 ■ Bowl limits
We can add an attribute to just about any object in Python. When writing classes, it’s typical and traditional to define data attributes on instances and method attributes on classes. But there’s no reason why we can’t define data attributes on classes too.
In this exercise, I want you to define a class attribute that will function like a constant, ensuring that we don’t need to hardcode any values in our class.
What’s the task here? Well, you might have noticed a flaw in our Bowl class, one that children undoubtedly love and their parents undoubtedly hate: you can put as many Scoop objects in a bowl as you like.
Let’s make the children sad, and their parents happy, by capping the number of scoops in a bowl at three. That is, you can add as many scoops in each call to Bowl.add_scoops as you want, and you can call that method as many times as you want--but only the first three scoops will actually be added. Any additional scoops will be ignored.
Working it out
We only need to make two changes to our original Bowl class for this to work.
First, we need to define a class attribute on Bowl. We do this most easily by making an assignment within the class definition (figure 9.11). Setting max_scoops = 3 within the class block is the same as saying, afterwards, Bowl.max_scoops = 3.

Figure 9.11 max_scoops sits on the class, so even an empty instance has access to it.
But wait, do we really need to define max_scoops on the Bowl class? Technically, we have two other options:
-
Define the maximum on the instance, rather than the class. This will work (i.e., add
self.max_scoops=3in__init__), but it implies that every bowl has a different maximum number of scoops. By putting the attribute on the class (figure 9.12), we indicate that every bowl will have the same maximum. -
We could also hardcode the value
3in our code, rather than use a symbolic name such asmax_scoops. But this will reduce our flexibility, especially if and when we want to use inheritance (as we’ll see later). Moreover, if we decide to change the maximum down the line, it’s easier to do that in one place, via the attribute assignment, rather than in a number of places.

Figure 9.12 A Bowl instance containing scoops, with max_scoops defined on the class
Second, we need to change Bowl.add_scoops, adding an if statement to make the addition of new scoops conditional on the current length of self.scoops and the value of Bowl.max_scoops.
Solution
class Scoop():
def __init__(self, flavor):
self.flavor = flavor
class Bowl():
max_scoops = 3 ❶
def __init__(self):
self.scoops = []
def add_scoops(self, *new_scoops):
for one_scoop in new_scoops:
if len(self.scoops) < Bowl.max_scoops: ❷
self.scoops.append(one_scoop)
def __repr__(self):
return '
'.join(s.flavor for s in self.scoops)
s1 = Scoop('chocolate')
s2 = Scoop('vanilla')
s3 = Scoop('persimmon')
s4 = Scoop('flavor 4')
s5 = Scoop('flavor 5')
b = Bowl()
b.add_scoops(s1, s2)
b.add_scoops(s3)
b.add_scoops(s4, s5)
print(b)
❶ max_scoops is not a variable--it’s an attribute of the class Bowl.
❷ Uses Bowl.max_scoops to get the maximum per bowl, set on the class
You can work through a version of this code in the Python Tutor at http://mng.bz/ NK6N.
Screencast solution
Watch this short video walkthrough of the solution: https://livebook.manning.com/ video/python-workout.
Beyond the exercise
As I’ve indicated, you can use class attributes in a variety of ways. Here are a few additional challenges that can help you to appreciate and understand how to define and use class attributes:
-
Define a
Personclass, and apopulationclass attribute that increases each time you create a new instance ofPerson. Double-check that after you’ve created five instances, namedp1throughp5,Person.populationandp1.populationare both equal to5. -
Python provides a
__del__method that’s executed when an object is garbage collected. (In my experience, deleting a variable or assigning it to another object triggers the calling of__del__pretty quickly.) Modify yourPersonclass such that when aPersoninstance is deleted, the population count decrements by 1. If you aren’t sure what garbage collection is, or how it works in Python, take a look at this article: http://mng.bz/nP2a. -
Define a
Transactionclass, in which each instance represents either a deposit or a withdrawal from a bank account. When creating a new instance ofTransaction, you’ll need to specify an amount--positive for a deposit and negative for a withdrawal. Use a class attribute to keep track of the current balance, which should be equal to the sum of the amounts in all instances created to date.
Exercise 41 ■ A bigger bowl
While the previous exercise might have delighted parents and upset children, our job as ice cream vendors is to excite the children, as well as take their parents’ money. Our company has thus started to offer a BigBowl product, which can take up to five scoops.
Implement BigBowl for this exercise, such that the only difference between it and the Bowl class we created earlier is that it can have five scoops, rather than three. And yes, this means that you should use inheritance to achieve this goal.
You can modify Scoop and Bowl if you must, but such changes should be minimal and justifiable.
Note As a general rule, the point of inheritance is to add or modify functionality in an existing class without modifying the parent. Purists might thus dislike these instructions, which allow for changes in the parent class. However, the real world isn’t always squeaky clean, and if the classes are both written by the same team, it’s possible that the child’s author can negotiate changes in the parent class.
Working it out
This is, I must admit, a tricky one. It forces you to understand how attributes work, and especially how they interact between instances, classes, and parent classes. If you really get the ICPO rule, then the solution should make sense.
In our previous version of Bowl.add_scoops, we said that we wanted to use Bowl.max _scoops to keep track of the maximum number of scoops allowed. That was fine, as long as every subclass would want to use the same value.
But here, we want to use a different value. That is, when invoking add_scoops on a Bowl object, the maximum should be Bowl.max_scoops. And when invoking add_scoops on a BigBowl object, the maximum should be BigBowl.max_scoops. And we want to avoid writing add_scoops twice.
The simplest solution is to change our reference in add_scoops from Bowl.max _scoops, to self.max_scoops. With this change in place, things will work like this:
-
If we invoke
add_scoopson an instance ofBowl, then inside the method, we’ll ask forself.max_scoops. By the ICPO lookup rule, Python will look first on the instance and then on the class, which isBowlin this case, and returnBowl.max_scoops, with a value of3. -
If we invoke
add_scoopson an instance ofBigBowl, then inside the method we’ll ask forself.max_scoops. By the iCPO lookup rule, Python will first look on the instance, and then on the class, which isBigBowlin this case, and returnBigBowl.max_scoops, with a value of5.
In this way, we’ve taken advantage of inheritance and the flexibility of self to use the same interface for a variety of classes. Moreover, we were able to implement BigBowl with a minimum of code, using what we’d already written for Bowl.
Solution
class Scoop():
def __init__(self, flavor):
self.flavor = flavor
class Bowl():
max_scoops = 3 ❶
def __init__(self):
self.scoops = []
def add_scoops(self, *new_scoops):
for one_scoop in new_scoops:
if len(self.scoops) < self.max_scoops: ❷
self.scoops.append(one_scoop)
def __repr__(self):
return '
'.join(s.flavor for s in self.scoops)
class BigBowl(Bowl):
max_scoops = 5 ❸
s1 = Scoop('chocolate')
s2 = Scoop('vanilla')
s3 = Scoop('persimmon')
s4 = Scoop('flavor 4')
s5 = Scoop('flavor 5')
bb = BigBowl()
bb.add_scoops(s1, s2)
bb.add_scoops(s3)
bb.add_scoops(s4, s5)
print(bb)
❷ Uses self.max_scoops, rather than Bowl.max_scoops, to get the attribute from the correct class
❸ BigBowl.max_scoops is set to 5.
You can work through a version of this code in the Python Tutor at http://mng.bz/ D2gn.
Screencast solution
Watch this short video walkthrough of the solution: https://livebook.manning.com/ video/python-workout.
Beyond the exercise
As I’ve already indicated in this chapter, I think that many people exaggerate the degree to which they should use inheritance in object-oriented code. But that doesn’t mean I see inheritance as unnecessary or even worthless. Used correctly, it’s a powerful tool that can reduce code size and improve its maintenance. Here are some more ways you can practice using inheritance:
-
Write an
Envelopeclass, with two attributes,weight(a float, measuring grams) andwas_sent(a Boolean, defaulting toFalse). There should be three methods: (1)send, which sends the letter, and changeswas_senttoTrue, but only after the envelope has enough postage; (2)add_postage, which adds postage equal to its argument; and (3)postage_needed, which indicates how much postage the envelope needs total. The postage needed will be the weight of the envelope times 10. Now write aBigEnvelopeclass that works just likeEnvelopeexcept that the postage is 15 times the weight, rather than 10. -
Create a
Phoneclass that represents a mobile phone. (Are there still nonmobile phones?) The phone should implement adialmethod that dials a phone number (or simulates doing so). Implement aSmartPhonesubclass that uses thePhone.dialmethod but implements its ownrun_appmethod. Now implement aniPhonesubclass that implements not only arun_appmethod, but also its owndialmethod, which invokes the parent’sdialmethod but whose output is all in lowercase as a sign of its coolness. -
Define a
Breadclass representing a loaf of bread. We should be able to invoke aget_nutritionmethod on the object, passing an integer representing the number of slices we want to eat. In return, we’ll receive a dict whose key-value pairs will represent calories, carbohydrates, sodium, sugar, and fat, indicating the nutritional statistics for that number of slices. Now implement two new classes that inherit fromBread, namelyWholeWheatBreadandRyeBread. Each class should implement the sameget_nutritionmethod, but with different nutritional information where appropriate.
Exercise 42 ■ FlexibleDict
I’ve already said that the main point of inheritance is to take advantage of existing functionality. There are several ways to do this and reasons for doing this, and one of them is to create new behavior that’s similar to, but distinct from, an existing class. For example, Python comes not just with dict, but also with Counter and defaultdict. By inheriting from dict, those two classes can implement just those methods that differ from dict, relying on the original class for the majority of the functionality.
In this exercise, we’ll also implement a subclass of dict, which I call FlexibleDict. Dict keys are Python objects, and as such are identified with a type. So if you use key 1 (an integer) to store a value, then you can’t use key '1' (a string) to retrieve that value. But FlexibleDict will allow for this. If it doesn’t find the user’s key, it will try to convert the key to both str and int before giving up; for example
fd = FlexibleDict() fd['a'] = 100 print(fd['a']) ❶ fd[5] = 500 print(fd[5]) ❷ fd[1] = 100 ❸ print(fd['1']) ❹ fd['1'] = 100 ❺ print(fd[1]) ❻
❶ Prints 100, just like a regular dict
❷ Prints 500, just like a regular dict
❹ Prints 100, even though we passed a str
❻ Prints 100, even though we passed an int
Working it out
This exercise’s class, FlexibleDict, is an example of where you might just want to inherit from a built-in type. It’s somewhat rare, but as you can see here, it allows us to create an alternative type of dict.
The specification of FlexibleDict indicates that everything should work just like a regular dict, except for retrievals. We thus only need to override one method, the __getitem__ method that’s always associated with square brackets in Python. Indeed, if you’ve ever wondered why strings, lists, tuples, and dicts are defined in different ways but all use square brackets, this method is the reason.
Because everything should be the same as dict except for this single method, we can inherit from dict, write one method, and be done.
This method receives a key argument. If the key isn’t in the dict, then we try to turn it into a string and an integer. Because we might encounter a ValueError trying to turn a key into an integer, we trap for ValueError along the way. At each turn, we check to see if a version of the key with a different type might actually work--and, if so, we reassign the value of key.
At the end of the method, we call our parent __getitem__ method. Why don’t we just use square brackets? Because that will lead to an infinite loop, seeing as square brackets are defined to invoke __getitem__. In other words, a[b] is turned into a.__getitem__(b). If we then include self[b] inside the definition of __getitem__, we’ll end up having the method call itself. We thus need to explicitly call the parent’s method, which in any event will return the associated value.
Note While FlexibleDict (and some of the “Beyond the exercise” tasks) might be great for teaching you Python skills, building this kind of flexibility into Python is very un-Pythonic and not recommended. One of the key ideas in Python is that code should be unambiguous, and in Python it’s also better to get an error than for the language to guess.
Solution
class FlexibleDict(dict):
def __getitem__(self, key): ❶
try:
if key in self: ❷
pass
elif str(key) in self: ❸
key = str(key)
elif int(key) in self: ❹
key = int(key)
except ValueError: ❺
pass
return dict.__getitem__(self, key) ❻
fd = FlexibleDict()
fd['a'] = 100
print(fd['a'])
fd[5] = 500
print(fd[5])
fd[1] = 100
print(fd['1'])
fd['1'] = 100
print(fd[1])
❶ __getitem__ is what square brackets [] invoke.
❷ Do we have the requested key?
❸ If not, then tries turning it into a string
❹ If not, then tries turning it into an integer
❺ If we can’t turn it into an integer, then ignores it
❻ Tries with the regular dict __getitem__, either with the original key or a modified one
You can work through a version of this code in the Python Tutor at http://mng.bz/ lGx6.
Screencast solution
Watch this short video walkthrough of the solution: https://livebook.manning.com/ video/python-workout.
Beyond the exercise
We’ve now seen how to extend a built-in class using inheritance. Here are some more exercises you can try, in which you’ll also experiment with extending some built-in classes:
-
With
FlexibleDict, we allowed the user to use any key, but were then flexible with the retrieval. ImplementStringKeyDict, which converts its keys into strings as part of the assignment. Thus, immediately after sayingskd[1]=10, you would be able to then sayskd['1']and get the value of10returned. This can come in handy if you’ll be reading keys from a file and won’t be able to distinguish between strings and integers. -
The
RecentDictclass works just like adict, except that it contains a user-defined number of key-value pairs, which are determined when the instance is created. In aRecentDict(5), only the five most recent key-value pairs are kept; if there are more than five pairs, then the oldest key is removed, along with its value. Note: your implementation could take into account the fact that modern dicts store their key-value pairs in chronological order. -
The
FlatListclass inherits fromlistand overrides theappendmethod. Ifappendis passed an iterable, then it should add each element of the iterable separately. This means thatfl.append([10,20,30])would not add the list[10,20,30]tofl, but would rather add the individual integers10,20, and30. You might want to use the built-initerfunction (http://mng.bz/Qy2G) to determine whether the passed argument is indeed iterable.
Exercise 43 ■ Animals
For the final three exercises in this chapter, we’re going to create a set of classes that combine all of the ideas we’ve explored in this chapter: classes, methods, attributes, composition, and inheritance. It’s one thing to learn about and use them separately, but when you combine these techniques together, you see their power and understand the organizational and semantic advantages that they offer.
For the purposes of these exercises, you are the director of IT at a zoo. The zoo contains several different kinds of animals, and for budget reasons, some of those animals have to be housed alongside other animals.
We will represent the animals as Python objects, with each species defined as a distinct class. All objects of a particular class will have the same species and number of legs, but the color will vary from one instance to another. We can thus create a white sheep:
s = Sheep('white')
I can similarly get information about the animal back from the object by retrieving its attributes:
print(s.species) ❶ print(s.color) ❷ print(s.number_of_legs) ❸
If I convert the animal to a string (using str or print), I’ll get back a string combining all of these details:
print(s) ❶
❶ Prints “White sheep, 4 legs”
We’re going to assume that our zoo contains four different types of animals: sheep, wolves, snakes, and parrots. (The zoo is going through some budgetary difficulties, so our animal collection is both small and unusual.) Create classes for each of these types, such that we can print each of them and get a report on their color, species, and number of legs.
Working it out
The end goal here is somewhat obvious: we want to have four different classes (Wolf, Sheep, Snake, and Parrot), each of which takes a single argument representing a color. The result of invoking each of these classes is a new instance with three attributes: species, color, and number_of_legs.
A naive implementation would simply create each of these four classes. But of course, part of the point here is to use inheritance, and the fact that the behavior in each class is basically identical means that we can indeed take advantage of it. But what will go into the Animal class, from which everyone inherits, and what will go into each of the individual subclasses?
Since all of the animal classes will have the same attributes, we can define __repr__ on Animal, the class from which they’ll all inherit. My version uses an f-string and grabs the attributes from self. Note that self in this case will be an instance not of Animal, but of one of the classes that inherits from Animal.
So, what else should be in Animal, and what should be in the subclasses? There’s no hard-and-fast rule here, but in this particular case, I decided that Animal.__init__ would be where the assignments all happen, and that the __init__ method in each subclass would invoke Animal.__init__ with a hardcoded number of legs, as well as the color designated by the user (figure 9.13).
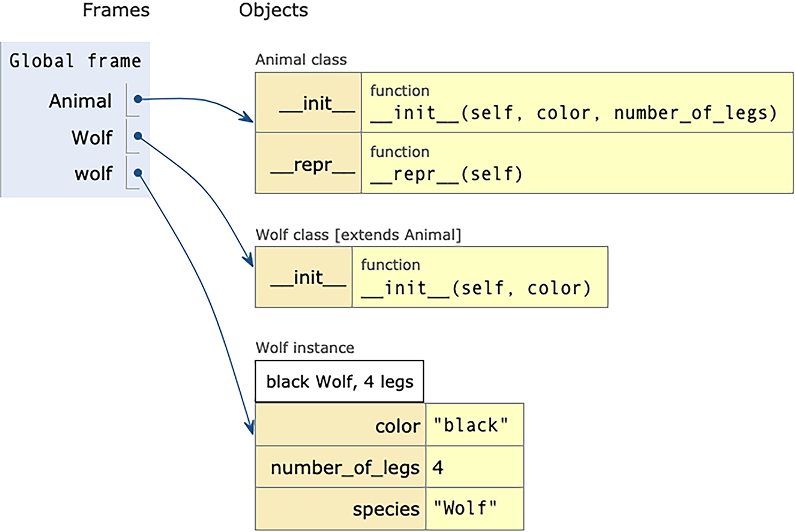
Figure 9.13 Wolf inherits from Animal. Notice which methods are defined where.
In theory, __init__ in a subclass could call Animal.__init__ directly and by name. But we also have access to super, which returns the object on which our method should be called. In other words, by calling super().__init__, we know that the right method will be called on the right object, and can just pass along the color and number_of_legs arguments.
But wait, what about the species attribute? How can we set that without input from the user?
My solution to this problem was to take advantage of the fact that Python classes are very similar to modules, with similar behavior. Just as a module has a __name__ attribute that reflects what module was loaded, so too classes have a __name__ attribute, which is a string containing the name of the current class. And thus, if I invoke self.__class__ on an object, I get its class--and if I invoke self.__class__.__name__, I get a string representation of the class.
Solution
class Animal():
def __init__(self, color, number_of_legs): ❶
self.species = self.__class__.__name__ ❷
self.color = color
self.number_of_legs = number_of_legs
def __repr__(self):
return f'{self.color} {self.species},
➥{self.number_of_legs} legs' ❸
class Wolf(Animal):
def __init__(self, color):
super().__init__(color, 4)
class Sheep(Animal):
def __init__(self, color):
super().__init__(color, 4)
class Snake(Animal):
def __init__(self, color):
super().__init__(color, 0)
class Parrot(Animal):
def __init__(self, color):
super().__init__(color, 2)
wolf = Wolf('black')
sheep = Sheep('white')
snake = Snake('brown')
parrot = Parrot('green')
print(wolf)
print(sheep)
print(snake)
print(parrot)
❶ Our Animal base class takes a color and number of legs.
❷ Turns the current class object into a string
❸ Uses an f-string to produce appropriate output
You can work through a version of this code in the Python Tutor at http://mng.bz/ B2Z0.
Screencast solution
Watch this short video walkthrough of the solution: https://livebook.manning.com/ video/python-workout.
Beyond the exercise
In this exercise, we put a few classes in place as part of a hierarchy. Here are some additional ways you can work with inheritance and think about the implications of the design decisions we’re making. I should note that these questions, as well as those following in this chapter, are going to combine hands-on practice with some deeper, philosophical questions about the “right” way to work with object-oriented systems:
-
Instead of each animal class inheriting directly, from
Animal, define several new classes,ZeroLeggedAnimal,TwoLeggedAnimal, andFourLeggedAnimal, all of which inherit fromAnimal, and dictate the number of legs on each instance. Now modifyWolf,Sheep,Snake, andParrotsuch that each class inherits from one of these new classes, rather than directly fromAnimal. How does this affect your method definitions? -
Instead of writing an
__init__method in each subclass, we could also have a class attribute,number_of_legs, in each subclass--similar to what we did earlier withBowlandBigBowl. Implement the hierarchy that way. Do you even need an__init__method in each subclass, or willAnimal.__init__suffice? -
Let’s say that each class’s
__repr__method should print the animal’s sound, as well as the standard string we implemented previously. In other words,str(sheep)would beBaa--whitesheep,4legs. How would you use inheritance to maximize code reuse?
Exercise 44 ■ Cages
Now that we’ve created some animals, it’s time to put them into cages. For this exercise, create a Cage class, into which you can put one or more animals, as follows:
c1 = Cage(1) c1.add_animals(wolf, sheep) c2 = Cage(2) c2.add_animals(snake, parrot)
When you create a new Cage, you’ll give it a unique ID number. (The uniqueness doesn’t need to be enforced, but it’ll help us to distinguish among the cages.) You’ll then be able to invoke add_animals on the new cage, passing any number of animals that will be put in the cage. I also want you to define a __repr__ method so that printing a cage prints not just the cage ID, but also each of the animals it contains.
Working it out
The solution’s definition of the Cage class is similar in some ways to the Bowl class that we defined earlier in this chapter.
When we create a new cage, the __init__ method initializes self.animals with an empty list, allowing us to add (and even remove) animals as necessary. We also store the ID number that was passed to us in the id_number parameter.
Next, we implement Cage.add_animals, which uses similar techniques to what we did in Bowl.add_scoops. Once again, we use the splat (*) operator to grab all arguments in a single tuple (animals). Although we could use list.extend to add all of the new animals to list.animals, I’ll still use a for loop here to add them one at a time. You can see how the Python Tutor depicts two animals in a cage in figure 9.14.
The most interesting part of our Cage definition, in my mind, is our use of __repr__ to produce a report. Given a cage c1, saying print(c1) will print the ID of the cage, followed by all of the animals in the cage, using their printed representations. We do this by first printing a basic header, which isn’t a huge deal. But then we take each animal in self.animals and use a generator expression (i.e., a lazy form of list comprehension) to return a sequence of strings. Each string in that sequence will consist of a tab followed by the printed representation of the animal. We then feed the result of our generator expression to str.join, which puts newline characters between each animal.

Figure 9.14 A Cage instance containing one wolf and one sheep
Solution
class Animal():
def __init__(self, color, number_of_legs):
self.species = self.__class__.__name__
self.color = color
self.number_of_legs = number_of_legs
def __repr__(self):
return f'{self.color} {self.species}, {self.number_of_legs} legs'
class Wolf(Animal):
def __init__(self, color):
super().__init__(color, 4)
class Sheep(Animal):
def __init__(self, color):
super().__init__(color, 4)
class Snake(Animal):
def __init__(self, color):
super().__init__(color, 0)
class Parrot(Animal):
def __init__(self, color):
super().__init__(color, 2)
class Cage():
def __init__(self, id_number):
self.id_number = id_number ❶
self.animals = [] ❷
def add_animals(self, *animals):
for one_animal in animals:
self.animals.append(one_animal)
def __repr__(self): ❸
output = f'Cage {self.id_number}
'
output += '
'.join(' ' + str(animal)
for animal in self.animals)
return output
wolf = Wolf('black')
sheep = Sheep('white')
snake = Snake('brown')
parrot = Parrot('green')
c1 = Cage(1)
c1.add_animals(wolf, sheep)
c2 = Cage(2)
c2.add_animals(snake, parrot)
print(c1)
print(c2)
❶ Sets an ID number for each cage, just so that we can distinguish their printouts
❷ Sets up an empty list, into which we’ll place animals
❸ The string for each cage will mainly be from a string, based on a generator expression.
You can work through a version of this code in the Python Tutor at http://mng.bz/ dyeN.
Screencast solution
Watch this short video walkthrough of the solution: https://livebook.manning.com/ video/python-workout.
Beyond the exercise
We’re once again seeing the need for composition in our classes--creating objects that are containers for other objects. Here are some possible extensions to this code, all of which draw on the ideas we’ve already seen in this chapter, and which you’ll see repeated in nearly every object-oriented system you build and encounter:
-
As you can see, there are no limits on how many animals can potentially be put into a cage. Just as we put a limit of three scoops in a
Bowland five in aBigBowl, you should similarly createCageandBigCageclasses that limit the number of animals that can be placed there. -
It’s not very realistic to say that we would limit the number of animals in a cage. Rather, it makes more sense to describe how much space each animal needs and to ensure that the total amount of space needed per animal isn’t greater than the space in each cage. You should thus modify each of the
Animalsubclasses to include aspace_requiredattribute. Then modify theCageandBigCageclasses to reflect how much space each one has. Adding more animals than the cage can contain should raise an exception. -
Our zookeepers have a macabre sense of humor when it comes to placing animals together, in that they put wolves and sheep in the first cage, and snakes and birds in the other cage. (The good news is that with such a configuration, the zoo will be able to save on food for half of the animals.) Define a dict describing which animals can be with others. The keys in the dict will be classes, and the values will be lists of classes that can compatibly be housed with the keys. Then, when adding new animals to the current cage, you’ll check for compatibility. Trying to add an animal to a cage that already contains an incompatible animal will raise an exception.
Exercise 45 ■ Zoo
Finally, the time has come to create our Zoo object. It will contain cage objects, and they in turn will contain animals. Our Zoo class will need to support the following operations:
-
Given a zoo
z, we should be able to print all of the cages (with their ID numbers) and the animals inside simply by invokingprint(z). -
We should be able to get the animals with a particular color by invoking the method
z.animals_by_color. For example, we can get all of the black animals by invokingz.animals_by_color('black'). The result should be a list ofAnimalobjects. -
We should be able to get the animals with a particular number of legs by invoking the method
z.animals_by_legs. For example, we can get all of the four-legged animals by invokingz.animals_by_legs(4). The result should be a list ofAnimalobjects. -
Finally, we have a potential donor to our zoo who wants to provide socks for all of the animals. Thus, we need to be able to invoke
z.number_of_legs()and get a count of the total number of legs for all animals in our zoo.
The exercise is thus to create a Zoo class on which we can invoke the following:
z = Zoo()
z.add_cages(c1, c2)
print(z)
print(z.animals_by_color('white'))
print(z.animals_by_legs(4))
print(z.number_of_legs())
Working it out
In some ways, our Zoo class here is quite similar to our Cage class. It has a list attribute, self.cages, in which we’ll store the cages. It has an add_cages method, which takes *args and thus takes any number of inputs. Even the __repr__ method is similar to what we did with Cage.__repr__. We’ll simply use str.join on the output from running str on each of the cages, just as the cages run str on each of the animals. We’ll similarly use a generator expression here, which will be slightly more efficient than a list comprehension.
But then, when it comes to the three methods we needed to create, we’ll switch direction a little bit. In both animals_by_color and animals_by_legs, we want to get the animals with a certain color or a certain number of legs. Here, we take advantage of the fact that the zoo contains a list of cages, and that each cage contains a list of animals. We can thus use a nested list comprehension, getting a list of all of the animals.
But of course, we don’t want all of the animals, so we have an if statement that filters out those that we don’t want. In the case of animals_by_color, we only include those animals that have the right color, and in animals_by_legs, we only keep those animals with the requested number of legs.
But then we also have number_of_legs, which works a bit differently. There, we want to get an integer back, reflecting the number of legs that are in the entire zoo. Here, we can take advantage of the built-in sum method, handing it the generator expression that goes through each cage and retrieves the number of legs on each animal. The method will thus return an integer.
Although the object-oriented and functional programming camps have been fighting for decades over which approach is superior, I think that the methods in this Zoo class show us that each has its strengths, and that our code can be short, elegant, and to the point if we combine the techniques. That said, I often get pushback from students who see this code and say that it’s a violation of the object-oriented principle of encapsulation, which ensures that we can’t (or shouldn’t) directly access the data in other objects.
Whether this is right or wrong, such violations are also fairly common in the Python world. Because all data is public (i.e., there’s no private or protected), it’s considered a good and reasonable thing to just scoop the data out of objects. That said, this also means that whoever writes a class has a responsibility to document it, and to keep the API alive--or to document elements that may be deprecated or removed in the future.
Solution
This is the longest and most complex class definition in this chapter--and yet, each of the methods uses techniques that we’ve discussed, both in this chapter and in this book:
class Zoo():
def __init__(self):
self.cages = [] ❶
def add_cages(self, *cages):
for one_cage in cages:
self.cages.append(one_cage)
def __repr__(self):
return '
'.join(str(one_cage)
for one_cage in self.cages)
def animals_by_color(self, color): ❷
return [one_animal
for one_cage in self.cages
for one_animal in one_cage.animals
if one_animal.color == color]
def animals_by_legs(self, number_of_legs): ❸
return [one_animal
for one_cage in self.cages
for one_animal in one_cage.animals
if one_animal.number_of_legs ==
number_of_legs]
def number_of_legs(self): ❹
return sum(one_animal.number_of_legs
for one_cage in self.cages
for one_animal in one_cage.animals)
wolf = Wolf('black')
sheep = Sheep('white')
snake = Snake('brown')
parrot = Parrot('green')
print(wolf)
print(sheep)
print(snake)
print(parrot)
c1 = Cage(1)
c1.add_animals(wolf, sheep)
c2 = Cage(2)
c2.add_animals(snake, parrot)
z = Zoo()
z.add_cages(c1, c2)
print(z)
print(z.animals_by_color('white'))
print(z.animals_by_legs(4))
print(z.number_of_legs())
❶ Sets up the self.cages attribute, a list where we’ll store cages
❷ Defines the method that’ll return animal objects that match our color
❸ Defines the method that’ll return animal objects that match our number of legs
You can work through a version of this code in the Python Tutor at http://mng.bz/ lGMB.
Screencast solution
Watch this short video walkthrough of the solution: https://livebook.manning.com/ video/python-workout.
Beyond the exercise
Now that you’ve seen how all of these elements fit together in our Zoo class, here are some additional exercises you might want to try out, to extend what we’ve done--and to better understand object-oriented programming in Python:
-
Modify
animals_by_colorsuch that it takes any number of colors. Animals having any of the listed colors should be returned. The method should raise an exception if no colors are passed. -
As things currently stand, we’re treating our
Zooclass almost as if it’s a singleton object--that is, a class that has only one instance. What a sad world that would be, with only one zoo! Let’s assume, then, that we have two instances ofZoo, representing two different zoos, and that we would like to transfer an animal from one to the other. Implement aZoo.transfer_animalmethod that takes atarget_zooand a subclass ofAnimalas arguments. The first animal of the specified type is removed from the zoo on which we’ve called the method and inserted into the first cage in the target zoo. -
Combine the
animals_by_colorandanimals_by_legsmethods into a singleget_animalsmethod, which useskwargsto get names and values. The only valid names would becolorandlegs. The method would then use one or both of these keywords to assemble a query that returns those animals that match the passed criteria.
Summary
Object-oriented programming is a set of techniques, but it’s also a mindset. In many languages, object-oriented programming is forced on you, such that you’re constantly trying to fit your programming into its syntax and structure. Python tries to strike a balance, offering all of the object-oriented features we’re likely to want or use, but in a simple, nonconfrontational way. In this way, Python’s objects provide us with structure and organization that can make our code easier to write, read, and (most importantly) maintain.