
Consider a program that has to work with documents, keep track of users, log the IP addresses that have accessed a server, or store the names and birth dates of children in a school. In all of these cases, we’re storing many pieces of information. We’ll want to display, search through, extend, and modify this information.
These are such common tasks that every programming language supports collections, data structures designed for handling such cases. Lists and tuples are Python’s built-in collections. Technically, they differ in that lists are mutable, whereas tuples are immutable. But in practice, lists are meant to be used for sequences of the same type, whereas tuples are meant for sequences of different types.
For example, a series of documents, users, or IP addresses would be best stored in a list--because we have many objects of the same type. A record containing someone’s name and birth date would be best stored in a tuple, because the name and birth date are of different types. A bunch of such name-birth date tuples, however, could be stored in a list, because it would contain a sequence of tuples--and the tuples all would be of the same type.
Because they’re mutable, lists support many more methods and operators. After all, there’s not much you can do with a tuple other than pass it, retrieve its elements, and make some queries about its contents. Lists, by contrast, can be extended, contracted, and modified, as well as searched, sorted, and replaced. So you can’t add a person’s shoe size to the name-birth date tuple you’ve created for them. But you can add a bunch of additional name-birth date tuples to the list you’ve created, as well as remove elements from that list if they’re no longer students in the school.
Learning to distinguish between when you would use lists versus when you would use tuples can take some time. If the distinction isn’t totally clear to you just yet, it’s not your fault!
Lists and tuples are both Python sequences, which means that we can run for loops on them, search using the in operator, and retrieve from them, both using individual indexes and with slices. The third sequence type in Python is the string, which we looked at in the previous chapter. I find it useful to think of the sequences in this way.
In this chapter, we’ll practice working with lists and tuples. We’ll see how to create them, modify them (in the case of lists), and use them to keep track of our data. We’ll also use list comprehensions, a syntax that’s confusing to many but which allows us to take one Python iterable and create a new list based on it. We’ll talk about comprehensions quite a bit in this chapter and the following ones; if you’re not familiar or comfortable with them, look at the references provided in table 3.2.
Table 3.2 What you need to know
Exercise 9 ■ First-last
For many programmers coming from a background in Java or C#, the dynamic nature of Python is quite strange. How can a programming language fail to police which type can be assigned to which variable? Fans of dynamic languages, such as Python, respond that this allows us to write generic functions that handle many different types.
Indeed, we need to do so. In many languages, you can define a function multiple times, as long as each definition has different parameters. In Python, you can only define a function once--or, more precisely, defining a function a second time will overwrite the first definition--so we need to use other techniques to work with different types of inputs.
In Python, you can write a single function that works with many types, rather than many nearly identical functions, each for a specific type. Such functions demonstrate the elegance and power of dynamic typing.
The fact that sequences--strings, lists, and tuples--all implement many of the same APIs is not an accident. Python encourages us to write generic functions that can apply to all of them. For example, all three sequence types can be searched with in, can return individual elements with an index, and can return multiple elements with a slice.
We’ll practice these ideas with this exercise. Write a function, firstlast, that takes a sequence (string, list, or tuple) and returns the first and last elements of that sequence, in a two-element sequence of the same type. So firstlast('abc') will return the string ac, while firstlast([1,2,3,4]) will return the list [1,4].
Working it out
This exercise is as tricky as it is short. However, I believe it helps to demonstrate the difference between retrieving an individual element from a sequence and a slice from that sequence. It also shows the power of a dynamic language; we don’t need to define several different versions of firstlast, each handling a different type. Rather, we can define a single function that handles not only the built-in sequences, but also any new types we might define that can handle indexes and slices.
One of the first things that Python programmers learn is that they can retrieve an element from a sequence--a string, list, or tuple--using square brackets and a numeric index. So you can retrieve the first element of s with s[0] and the final element of s with s[-1].
But that’s not all. You can also retrieve a slice, or a subset of the elements of the sequence, by using a colon inside the square brackets. The easiest and most obvious way to do this is something like s[2:5], which means that you want a string whose content is from s, starting at index 2, up to but not including index 5. (Remember that in a slice, the final number is always “up to but not including.”)

Figure 3.1 Individual elements (from the Python Tutor)
When you retrieve a single element from a sequence (figure 3.1), you can get any type at all. String indexes return one-character strings, but lists and tuples can contain anything. By contrast, when you use a slice, you’re guaranteed to get the same type back--so a slice of a tuple is a tuple, regardless of the size of the slice or the elements it contains. And a slice of a list will return a list. In figures 3.2 and 3.3 from the Python Tutor, notice that the data structures are different, and thus the results of retrieving from each type will be different.
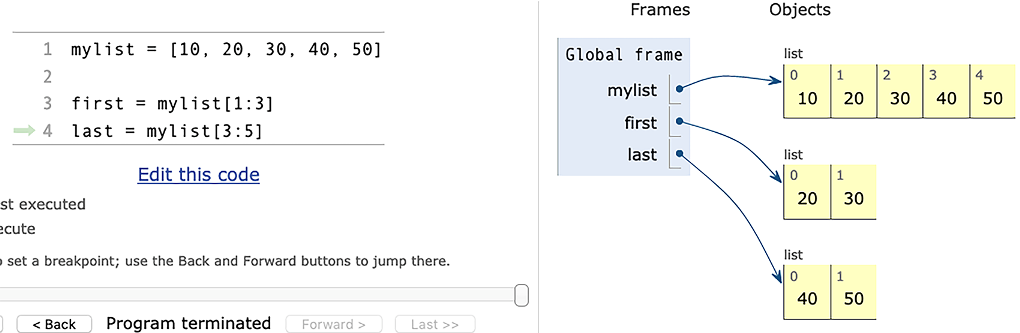
Figure 3.2 Retrieving slices from a list (from the Python Tutor)

Figure 3.3 Retrieving slices from a tuple (from the Python Tutor)
Given that we’re trying to retrieve the first and last elements of sequence and then join them together, it might seem reasonable to grab them both (via indexes) and then add them together:
# not a real solution!
def firstlast(sequence):
return sequence[0] + sequence[-1]
But this is what really happens (figure 3.4):
def firstlast(sequence): ❶ return sequence[0] + sequence[-1] t1 = ('a', 'b', 'c') output1 = firstlast(t1) print(output1) ❷ t2 = (1,2,3,4) output2 = firstlast(t2) print(output2) ❸
❷ Prints the string 'ac', not ('a', 'c')
❸ Prints the integer 5, not (1, 4)
We can’t simply use + on the individual elements of our tuples. As we see in figure 3.4, if the elements are strings or integers, then using + on those two elements will give us the wrong answer. We want to be adding tuples--or whatever type sequence is.
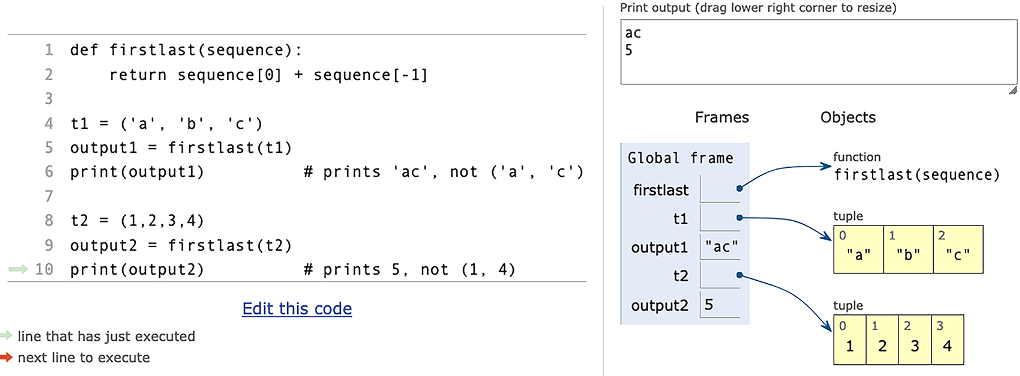
Figure 3.4 Naive, incorrect adding of slices (from the Python Tutor)
The easiest way to do that is to use a slice, using s[:1] to get the first element and s[-1:] to get the final element (figure 3.5). Notice that we have to say s[-1:] so that the sequence will start with the element at -1 and end at the end of the sequence itself.
The bottom line is that when you retrieve a slice from an object x, you get back a new object of the same type as x. But if you retrieve an individual element from x, you’ll get whatever was stored in x --which might be the same type as x, but you can’t be sure.

Figure 3.5 Working solution (from the Python Tutor)
Solution
def firstlast(sequence):
return sequence[:1] + sequence[-1:] ❶
print(firstlast('abcd'))
❶ In both cases, we’re using slices, not indexes.
You can work through this code in the Python Tutor at http://mng.bz/RAPP.
Screencast solution
Watch this short video walkthrough of the solution: https://livebook.manning.com/ video/python-workout.
Beyond the exercise
One of these techniques involves taking advantage of Python’s dynamic typing; that is, while data is strongly typed, variables don’t have any types. This means that we can write a function that expects to take any indexable type (i.e., one that can get either a single index or a slice as an argument) and then return something appropriate. This is a common technique in Python, one with which you should become familiar and comfortable; for example
-
Don’t write one function that squares integers, and another that squares floats. Write one function that handles all numbers.
-
Don’t write one function that finds the largest element of a string, another that does the same for a list, and a third that does the same for a tuple. Write just one function that works on all of them.
-
Don’t write one function to find the largest word in a file that works on files and another that works on the
io.StringIO(http://mng.bz/PAOP) file simulator used in testing. Write one function that works on both.
Slices are a great way to get at just part of a piece of data. Whether it’s a substring or part of a list, slices allow you to grab just part of any sequence. I’m often asked by students in my courses how they can iterate over just the final n elements of a list. When I remind them that they can do this with the slice mylist[-3:] and a for loop, they’re somewhat surprised and embarrassed that they didn’t think of this first; they were sure that it must be more difficult than that.
Here are some ideas for other tasks you can try, using indexes and slices:
-
Write a function that takes a list or tuple of numbers. Return a two-element list, containing (respectively) the sum of the even-indexed numbers and the sum of the odd-indexed numbers. So calling the function as
even_odd_sums([10,20,30,40,50,60]), you’ll get back[90,120]. -
Write a function that takes a list or tuple of numbers. Return the result of alternately adding and subtracting numbers from each other. So calling the function as
plus_minus([10,20,30,40,50,60]), you’ll get back the result of10+20-30+40-50+60, or50. -
Write a function that partly emulates the built-in
zipfunction (http://mng.bz/ Jyzv), taking any number of iterables and returning a list of tuples. Each tuple will contain one element from each of the iterables passed to the function. Thus, if I callmyzip([10,20,30],'abc'), the result will be[(10,'a'),(20,'b'),(30,'c')]. You can return a list (not an iterator) and can assume that all of the iterables are of the same length.
Exercise 10 ■ Summing anything
You’ve seen how you can write a function that takes a number of different types. You’ve also seen how you can write a function that returns different types, using the argument that the function received.
In this exercise, you’ll see how you can have even more flexibility experimenting with types. What happens if you’re running methods not on the argument itself, but on elements within the argument? For example, what if you want to sum the elements of a list--regardless of whether those elements are integers, floats, strings, or even lists?
This challenge asks you to redefine the mysum function we defined in chapter 1, such that it can take any number of arguments. The arguments must all be of the same type and know how to respond to the + operator. (Thus, the function should work with numbers, strings, lists, and tuples, but not with sets and dicts.)
Note Python 3.9, which is scheduled for release in the autumn of 2020, will apparently include support for | on dicts. See PEP 584 (http://mng.bz/mB42) for more details.
The result should be a new, longer sequence of the type provided by the parameters. Thus, the result of mysum('abc', 'def') will be the string abcdef, and the result of mysum([1,2,3], [4,5,6]) will be the six-element list [1,2,3,4,5,6]. Of course, it should also still return the integer 6 if we invoke mysum(1,2,3).
Working through this exercise will give you a chance to think about sequences, types, and how we can most easily create return values of different types from the same function.
Working it out
This new version of mysum is more complex than the one we saw previously. It still accepts any number of arguments, which are put into the items tuple thanks to the “splat” (*) operator.
Tip While we traditionally call the “takes any number of arguments” parameter *args, you can use any name you want. The important part is the *, not the name of the parameter; it still works the same way and is always a tuple.
The first thing we do is check to see if we received any arguments. If not, we return items, an empty tuple. This is necessary because the rest of the function requires that we know the type of the passed arguments, and that we have an element at index 0. Without any arguments, neither will work.
Notice that we don’t check for an empty tuple by comparing it with () or checking that its length is 0. Rather, we can say if not items, which asks for the Boolean value of our tuple. Because an empty Python sequence is False in a Boolean context, we get False if args is empty and True otherwise.
In the next line, we grab the first element of items and assign it to output (figure 3.6). If it’s a number, output will be a number; if it’s a string, output will be a string; and so on. This gives us the base value to which we’ll add (using +) each of the subsequent values in items.
Once that’s in place, we do what the original version of mysum did--but instead of iterating over all of items, we can now iterate over items[1:] (figure 3.7), meaning all of the elements except for the first one. Here, we again see the value of Python’s slices and how we can use them to solve problems.
You can think of this implementation of mysum as the same as our original version, except that instead of adding each element to 0, we’re adding each one to items[0].
But wait, what if the person passed us only a single argument, and thus args doesn’t contain anything at index 1? Fortunately, slices are forgiving and allow us to specify indexes beyond the sequence’s boundaries. In such a case, we’ll just get an empty sequence, over which the for loop will run zero times. This means we’ll just get the value of items[0] returned to us as output.

Figure 3.6 After assigning the first element to output (from the Python Tutor)
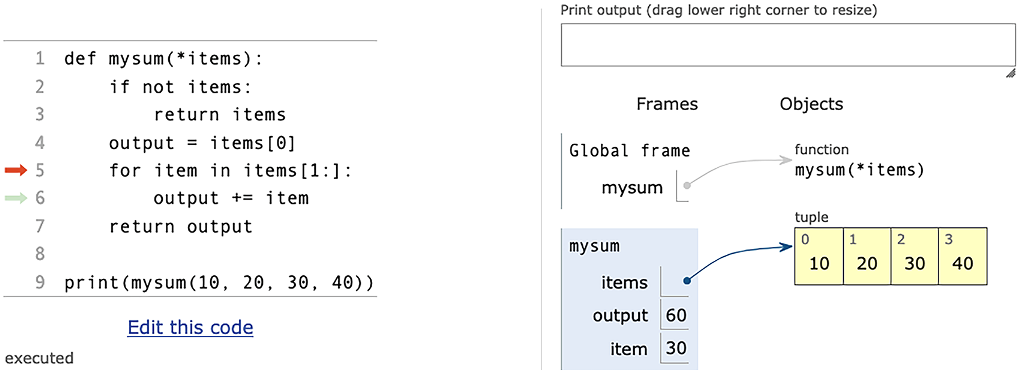
Figure 3.7 After adding elements to output (from the Python Tutor)
Solution
def mysum(*items):
if not items: ❶
return items
output = items[0]
for item in items[1:]:
output += item ❷
return output
print(mysum())
print(mysum(10, 20, 30, 40))
print(mysum('a', 'b', 'c', 'd'))
print(mysum([10, 20, 30], [40, 50, 60], [70, 80]))
❶ In Python, everything is considered “True” in an “if,” except for “None,” “False,” 0, and empty collections. So if the tuple “items” is empty, we’ll just return an empty tuple.
❷ We’re assuming that the elements of “items” can be added together.
You can work through this code in the Python Tutor at http://mng.bz/5aA1.
Screencast solution
Watch this short video walkthrough of the solution: https://livebook.manning.com/ video/python-workout.
Beyond the exercise
This exercise demonstrates some of the ways we can take advantage of Python’s dynamic typing to create a function that works with many different types of inputs, and even produces different types of outputs. Here are a few other problems you can try to solve, which have similar goals:
-
Write a function,
mysum_bigger_than, that works the same asmysum, except that it takes a first argument that precedes*args. That argument indicates the threshold for including an argument in the sum. Thus, callingmysum_bigger _than(10,5,20,30,6)would return50--because5and6aren’t greater than10. This function should similarly work with any type and assumes that all of the arguments are of the same type. Note that>and<work on many different types in Python, not just on numbers; with strings, lists, and tuples, it refers to their sort order. -
Write a function,
sum_numeric, that takes any number of arguments. If the argument is or can be turned into an integer, then it should be added to the total. Arguments that can’t be handled as integers should be ignored. The result is the sum of the numbers. Thus,sum_numeric(10,20,'a','30','bcd')would return60. Notice that even if the string30is an element in the list, it’s converted into an integer and added to the total. -
Write a function that takes a list of dicts and returns a single dict that combines all of the keys and values. If a key appears in more than one argument, the value should be a list containing all of the values from the arguments.
Exercise 11 ■ Alphabetizing names
Let’s assume you have phone book data in a list of dicts, as follows:
PEOPLE = [{'first':'Reuven', 'last':'Lerner',
'email':'[email protected]'},
{'first':'Donald', 'last':'Trump',
'email':'[email protected]'},
{'first':'Vladimir', 'last':'Putin',
'email':'[email protected]'}
]
First of all, if these are the only people in your phone book, then you should rethink whether Python programming is truly the best use of your time and connections. Regardless, write a function, alphabetize_names, that assumes the existence of a PEOPLE constant defined as shown in the code. The function should return the list of dicts, but sorted by last name and then by first name.
Note Python doesn’t really have constants; with the exception of some internal types and data structures, every variable, function, and attribute can always be modified. That said, variables defined outside of any function are generally referred to as “constants” and are defined in ALL CAPS.
You can solve this exercise several ways, but all will require using the sorted method that you saw in the last chapter, along with a function passed as an argument to its key parameter. You can read more about sorted and how to use it, including custom sorts with key, at http://mng.bz/D28E. One of the options for solving this exercise involves operator.itemgetter, about which you can read here: http://mng.bz/dyPQ.
Working it out
While Python’s data structures are useful by themselves, they become even more powerful and useful when combined together. Lists of lists, lists of tuples, lists of dicts, and dicts of dicts are all quite common. Learning to work with these structures is an important part of being a fluent Python programmer. This exercise shows how you can not only store data in such structures, but also retrieve, manipulate, sort, and format it.
The solution I propose has two parts. In the first part, we sort our data according to the criteria I proposed, namely last name and then first name. The second part of the solution addresses how we’ll print output to the end user.
Let’s take the second problem first. We have a list of dicts. This means that when we iterate over our list, person is assigned a dict in each iteration. The dict has three keys: first, last, and email. We’ll want to use each of these keys to display each phone-book entry.
for person in people:
print(f'{person["last"]}, {person["first"]}: {person["email"]}')
So far, so good. But we still haven’t covered the first problem, namely sorting the list of dicts by last name and then first name. Basically, we want to tell Python’s sort facility that it shouldn’t compare dicts. Rather, it should compare the last and first values from within each dict.
{'first':'Vladimir', 'last':'Putin', 'email':'[email protected]'}
['Putin', 'Vladimir']
We can do this by taking advantage of the key parameter to sorted. The value passed to that parameter must be a function that takes a single argument. The function will be invoked once per element, and the function’s return value will be used to sort the values.
Thus, we can sort elements of a list by saying
mylist = ['abcd', 'efg', 'hi', 'j'] mylist = sorted(mylist, key=len)
After executing this code, mylist will now be sorted in increasing order of length, because the built-in len function (http://mng.bz/oPmr) will be applied to each element before it’s compared with others. In the case of our alphabetizing exercise, we could write a function that takes a dict and returns the sort of list that’s necessary:
def person_dict_to_list(d):
return [d['last'], d['first']]
We could then apply this function when sorting our list:
print(sorted(people, key=person_dict_to_list))
Following that, we could then iterate over the now-sorted list and display our people.
But wait a second--why should we write a special-purpose function (person_dict _to_list) that’ll only be used once? Surely there must be a way to create a temporary, inline function. And indeed there is, with lambda (http://mng.bz/GVy8), which returns a new, anonymous function. With lambda, we end up with the following solution:
for p in sorted(people,
key=lambda x: [x['last'], x['first']]):
print(f'{p["last"]}, {p["first"]}: {p["email"]}')
Many of the Python developers I meet are less than thrilled to use lambda. It works but makes the code less readable and more confusing to many. (See the sidebar for more thoughts on lambda.)
Fortunately, the operator module has the itemgetter function. itemgetter takes any number of arguments and returns a function that applies each of those arguments in square brackets. For example, if I say
s = 'abcdef' t = (10, 20, 30, 40, 50, 60) get_2_and_4 = operator.itemgetter(2, 4) ❶ print(get_2_and_4(s)) ❷ print(get_2_and_4(t)) ❸
❶ Notice that itemgetter returns a function.
❷ Returns the tuple ('c', 'e')
If we invoke itemgetter('last', 'first'), we’ll get a function we can apply to each of our person dicts. It’ll return a tuple containing the values associated with last and first.
In other words, we can just write:
from operator import itemgetter
for p in sorted(people,
key=itemgetter('last', 'first')):
print(f'{p["last"]}, {p["first"]}: {p["email"]}')
Solution
import operator
PEOPLE = [{'first': 'Reuven', 'last': 'Lerner',
'email': '[email protected]'},
{'first': 'Donald', 'last': 'Trump',
'email': '[email protected]'},
{'first': 'Vladimir', 'last': 'Putin',
'email': '[email protected]'}
]
def alphabetize_names(list_of_dicts):
return sorted(list_of_dicts,
key=operator.itemgetter('last', 'first')) ❶
print(alphabetize_names(PEOPLE))
❶ The “key” parameter to “sorted” gets a function, whose result indicates how we’ll sort.
You can work through this code in the Python Tutor at http://mng.bz/Yr6Q.
Screencast solution
Watch this short video walkthrough of the solution: https://livebook.manning.com/ video/python-workout.
Beyond the exercise
Learning to sort Python data structures, and particularly combinations of Python’s built-in data structures, is an important part of working with Python. It’s not enough to use the built-in sorted function, although that’s a good part of it; understanding how sorting works, and how you can use the key parameter, is also essential. This exercise has introduced this idea, but consider a few more sorting opportunities:
-
Given a sequence of positive and negative numbers, sort them by absolute value.
-
Given a list of strings, sort them according to how many vowels they contain.
-
Given a list of lists, with each list containing zero or more numbers, sort by the sum of each inner list’s numbers.
glue = '*' s = 'abc' print(glue.join(s))
print('*'.join('abc'))
mylist = [10, 20, 30]
def hello(name):
return f'Hello, {name}'

Figure 3.8 Both mylist and hello point to objects (from the Python Tutor).
def hello(name):
return f'Hello, {name}'
def run_func_with_world(func):
return func('world')
print(run_func_with_world(hello))

Figure 3.9 Calling hello from another function (from the Python Tutor)
def run_func_with_world(f):
return f('world')
print(run_func_with_world(lambda name: f'Hello, {name}'))

Figure 3.10 Calling an anonymous function from a function (from the Python Tutor)
Exercise 12 ■ Word with most repeated letters
Write a function, most_repeating_word, that takes a sequence of strings as input. The function should return the string that contains the greatest number of repeated letters. In other words
words = ['this', 'is', 'an', 'elementary', 'test', 'example']
then your function should return elementary. That’s because
So the most common letter in elementary appears more often than the most common letters in any of the other words. (If it’s a tie, then any of the appropriate words can be returned.)
You’ll probably want to use Counter, from the collections module, which is perfect for counting the number of items in a sequence. More information is here: http:// mng.bz/rrBX. Pay particular attention to the most_common method (http://mng.bz/ vxlJ), which will come in handy here.
Working it out
This solution combines a few of my favorite Python techniques into a short piece of code:
For our solution to work, we’ll need to find a way to determine how many times each letter appears in a word. The easiest way to do that is Counter. It’s true that Counter inherits from dict and thus can do anything that a dict can do. But we normally build an instance of Counter by initializing it on a sequence; for example
>>> Counter('abcabcabbbc')
Counter({'a': 3, 'b': 5, 'c': 3})
We can thus feed Counter a word, and it’ll tell us how many times each letter appears in that word. We could, of course, iterate over the resulting Counter object and grab the letter that appears the most times. But why work so hard when we can invoke Counter.most_common?
>>> Counter('abcabcabbbc').most_common() ❶
[('b', 5), ('a', 3), ('c', 3)]
❶ Shows how often each item appears in the string, from most common to least common, in a list of tuples
The result of invoking Counter.most_common is a list of tuples, with the names and values of the counter’s values in descending order. So in the Counter.most_common example, we see that b appears five times in the input, a appears three times, and c also appears three times. If we were to invoke most_common with an integer argument n, we would only see the n most common items:
>>> Counter('abcabcabbbc').most_common(1) ❶
[('b', 5)]
❶ Only shows the most common item, and its count
This is perfect for our purposes. Indeed, I think it would be useful to wrap this up into a function that’ll return the number of times the most frequently appearing letter is in the word:
def most_repeating_letter_count(word):
return Counter(word).most_common(1)[0][1]
The (1)[0][1] at the end looks a bit confusing. It means the following:
-
We only want the most commonly appearing letter, returned in a one-element list of tuples.
-
We then want the count for that most common element, at index 1 in the tuple.
Remember that we don’t care which letter is repeated. We just care how often the most frequently repeated letter is indeed repeated. And yes, I also dislike the multiple indexes at the end of this function call, which is part of the reason I want to wrap this up into a function so that I don’t have to see it as often. But we can call most_common with an argument of 1 to say that we’re only interested in the highest scoring letter, then that we’re interested in the first (and only) element of that list, and then that we want the second element (i.e., the count) from the tuple.
To find the word with the greatest number of matching letters, we’ll want to apply most_repeating_letter_count to each element of WORDS, indicating which has the highest score. One way to do this would be to use sorted, using most_repeating _letter_count as the key function. That is, we’ll sort the elements of WORDS by number of repeated letters. Because sorted returns a list sorted from lowest to highest score, the final element (i.e., at index -1) will be the most repeating word.
But we can do even better than that: The built-in max function takes a key function, just like sorted, and returns the element that received the highest score. We can thus save ourselves a bit of coding with a one-line version of most_repeating_word:
def most_repeating_word(words):
return max(words,
key=most_repeating_letter_count)
Solution
from collections import Counter
import operator
WORDS = ['this', 'is', 'an',
'elementary', 'test', 'example']
def most_repeating_letter_count(word): ❶
return Counter(word).most_common(1)[0][1] ❷
def most_repeating_word(words):
return max (words,
key-most_repeating_letter_count (1) {0]{1} ❸
print(most_repeating_word(WORDS))
❶ What letter appears the most times, and how many times does it appear?
❷ Counter.most_common returns a list of two-element tuples (value and count) in descending order.
❸ Just as you can pass key to sorted, you can also pass it to max and use a different sort method.
You can work through this code in the Python Tutor at http://mng.bz/MdjW.
Screencast solution
Watch this short video walkthrough of the solution: https://livebook.manning.com/ video/python-workout.
Beyond the exercise
Sorting, manipulating complex data structures, and passing functions to other functions are all rich topics deserving of your attention and practice. Here are a few things you can do to go beyond this exercise and explore these ideas some more:
-
Instead of finding the word with the greatest number of repeated letters, find the word with the greatest number of repeated vowels.
-
Write a program to read
/etc/passwdon a Unix computer. The first field contains the username, and the final field contains the user’s shell, the command interpreter. Display the shells in decreasing order of popularity, such that the most popular shell is shown first, the second most popular shell second, and so forth. -
For an added challenge, after displaying each shell, also show the usernames (sorted alphabetically) who use each of those shells.
Exercise 13 ■ Printing tuple records
A common use for tuples is as records, similar to a struct in some other languages. And of course, displaying those records in a table is a standard thing for programs to do. In this exercise, we’ll do a bit of both--reading from a list of tuples and turning them into formatted output for the user.
For example, assume we’re in charge of an international summit in London. We know how many hours it’ll take each of several world leaders to arrive:
PEOPLE = [('Donald', 'Trump', 7.85),
('Vladimir', 'Putin', 3.626),
('Jinping', 'Xi', 10.603)]
The planner for this summit needs to have a list of the world leaders who are coming, along with the time it’ll take for them to arrive. However, this travel planner doesn’t need the degree of precision that the computer has provided; it’s enough for us to have two digits after the decimal point.
For this exercise, write a Python function, format_sort_records, that takes the PEOPLE list and returns a formatted string that looks like the following:
Trump Donald 7.85 Putin Vladimir 3.63 Xi Jinping 10.60
Notice that the last name is printed before the first name (taking into account that Chinese names are generally shown that way), followed by a decimal-aligned indication of how long it’ll take for each leader to arrive in London. Each name should be printed in a 10-character field, and the time should be printed in a 5-character field, with one space character of padding between each of the columns. Travel time should display only two digits after the decimal point, which means that even though the input for Xi Jinping’s flight is 10.603 hours, the value displayed should be 10.60.
Working it out
Tuples are often used in the context of structured data and database records. In particular, you can expect to receive a tuple when you retrieve one or more records from a relational database. You’ll then need to retrieve the individual fields using numeric indexes.
This exercise had several parts. First of all, we needed to sort the people in alphabetical order according to last name and first name. I used the built-in sorted function to sort the tuples, using a similar algorithm to what we used with the list of dicts in an earlier exercise. The for loop thus iterated over each element of our sorted list, getting a tuple (which it called person) in each iteration. You can often think of a dict as a list of tuples, especially when iterating over it using the items method (figure 3.11).

Figure 3.11 Iterating over our list of tuples (from the Python Tutor)
The contents of the tuple then needed to be printed in a strict format. While it’s often nice to use f-strings, str.format (http://mng.bz/Z2eZ) can still be useful in some circumstances. Here, I take advantage of the fact that person is a tuple, and that *person, when passed to a function, becomes not a tuple, but the elements of that tuple. This means that we’re passing three separate arguments to str.format, which we can access via {0}, {1}, and {2}.
In the case of the last name and first name, we wanted to use a 10-character field, padding with space characters. We can do that in str.format by adding a colon (:) character after the index we wish to display. Thus, {1:10} tells Python to display the item with index 1, inserting spaces if the data contains fewer than 10 characters. Strings are left aligned by default, such that the names will be displayed flush left within their columns.
The third column is a bit trickier, in that we wanted to display only two digits after the decimal point, a maximum of five characters, to have the travel-time decimal aligned, and (as if that weren’t enough) to pad the column with space characters.
In str.format (and in f-strings), each type is treated differently. So if we simply give {2:10} as the formatting option for our floating-point numbers (i.e., person[2]), the number will be right-aligned. We can force it to be displayed as a floating-point number if we put an f at the end, as in {2:10f}, but that will just fill with zeros after the decimal point. The specifier for producing two digits after the decimal point, with a maximum of five digits total, would be {5.2f}, which produces the output we wanted.
Solution
import operator
PEOPLE = [('Donald', 'Trump', 7.85),
('Vladimir', 'Putin', 3.626),
('Jinping', 'Xi', 10.603)]
def format_sort_records(list_of_tuples):
output = []
template = '{1:10} {0:10} {2:5.2f}'
for person in sorted(list_of_tuples,
key=operator.itemgetter(1, 0)): ❶
output.append(template.format(*person))
return output
print('
'.join(format_sort_records(PEOPLE)))
❶ You can use operator.itemgetter with any data structure that takes square brackets. You can also pass it more than one argument, as seen here.
You can work through this code in the Python Tutor at http://mng.bz/04KW.
Screencast solution
Watch this short video walkthrough of the solution: https://livebook.manning.com/ video/python-workout.
Beyond the exercise
Here are some ideas you can use to extend this exercise and learn more about similar data structures:
-
If you find tuples annoying because they use numeric indexes, you’re not alone! Reimplement this exercise using
namedtupleobjects (http://mng.bz/gyWl), defined in thecollectionsmodule. Many people like to use named tuples because they give the right balance between readability and efficiency. -
Define a list of tuples, in which each tuple contains the name, length (in minutes), and director of the movies nominated for best picture Oscar awards last year. Ask the user whether they want to sort the list by title, length, or director’s name, and then present the list sorted by the user’s choice of axis.
-
Extend this exercise by allowing the user to sort by two or three of these fields, not just one of them. The user can specify the fields by entering them separated by commas; you can use
str.splitto turn them into a list.
Summary
In this chapter, we explored a number of ways we can use lists and tuples and manipulate them within our Python programs. It’s hard to exaggerate just how common lists and tuples are, and how familiar you should be with them. To summarize, here are some of the most important points to remember about them:
-
Lists are mutable and tuples are immutable, but the real difference between them is how they’re used: lists are for sequences of the same type, and tuples are for records that contain different types.
-
You can use the built-in
sortedfunction to sort either lists or tuples. You’ll get a list back from your call tosorted. -
You can modify the sort order by passing a function to the
keyparameter. This function will be invoked once for each element in the sequence, and the output from the function will be used in ordering the elements. -
If you want to count the number of items contained in a sequence, try using the
Counterclass from thecollectionsmodule. It not only lets us count things quickly and easily, and provides us with amost_commonmethod, but also inherits fromdict, giving us all of the dict functionality we know and love.