
Chapter 11
Delving into the Standard Library
WHAT’S IN THIS CHAPTER?
- What the coding principles used throughout the Standard Library are
- What kind of functionality the Standard Library provides
The most important library that you will use as a C++ programmer is the C++ standard library. As its name implies, this library is part of the C++ standard, so any standards-conforming compiler should include it. The standard library is not monolithic: It includes several disparate components, some of which you have been using already. You may even have assumed they were part of the core language.
The heart of the C++ standard library is its generic containers and algorithms. This subset of the library is often called the Standard Template Library, or STL for short, because of its abundant use of templates. The power of the STL is that it provides generic containers and generic algorithms in such a way that most of the algorithms work on most of the containers, no matter what type of data the containers store. Performance is a very important part of the STL. The goal is to make the STL containers and algorithms as fast as or faster than hand written code.
Many programmers who claim to know C++ have never heard of the Standard Template Library. A C++ programmer who wishes to claim language expertise is expected to be familiar with the Standard Template Library. You can save yourself immeasurable time and energy by incorporating the STL containers and algorithms into your programs instead of writing and debugging your own versions. Now is the time to master the standard library.
This first chapter on the standard library starts with a brief explanation on how to use templates and mentions the concept of operator overloading. Both of these concepts are used extensively by the STL. It also provides a general overview of the functionality available in the standard library and in the STL.
The next few chapters go into much more detail on several aspects of the standard library and the STL, including containers, iterators, generic algorithms, predefined function object classes; and customizing and extending the library by writing your own allocators, algorithms, containers, iterators, and using iterator adapters.
Despite the depth of material found in this and the next chapters, the standard library is too large for this book to cover exhaustively. You should read this and the following chapters to learn about the standard library and the STL, but keep in mind that they don’t mention every method and member that the various classes provide, or show you the prototypes of every algorithm. Appendix C provides a summary of all the header files in the standard library, while the Standard Library Reference resource on the website (www.wrox.com) presents a reference for the various classes and algorithms in the STL.
The standard library, and definitely the standard template library, make heavy use of the C++ features called templates and operator overloading. This section will give a brief introduction to both concepts.
Use of Templates
Templates are described in full detail in Chapter 19. This section will give a basic overview of how to use templates to avoid any problems with code samples. Templates are used to allow generic programming. They make it possible to write code that can work with all kinds of objects, even objects unknown to the programmer when writing the code. The obligation of the programmer writing the template code is to specify the requirements of the classes that define these objects, for example, that they have an operator for comparison, or a copy constructor, or whatever is deemed appropriate, and then making sure the code that is written uses only those required capabilities. The obligation of the programmer creating the objects is to supply those operators and methods that the template writer requires.
Unfortunately, many programmers consider templates to be the most difficult part of C++ and, for that reason, tend to avoid them. However, even if you never write your own templates, you need to understand their syntax and capabilities in order to use the STL.
Explaining the use of templates is best done with an example. Suppose that you would like to write a small class that wraps a standard fixed-sized array of elements of type int. The class definition could be as follows:
class MyArray
{
public:
MyArray(size_t size);
virtual ~MyArray();
size_t getSize() const;
int& at(size_t index) throw(out_of_range);
protected:
size_t mSize;
int* mArray;
};
Code snippet from MyIntArrayMyIntArray.cpp
The implementation is pretty straightforward. Note that error checking is omitted to keep the example compact.
MyArray::MyArray(size_t size) : mSize(size), mArray(nullptr)
{
mArray = new int[size];
}
MyArray::~MyArray()
{
if (mArray) {
delete [] mArray;
mArray = nullptr;
}
}
size_t MyArray::getSize() const
{
return mSize;
}
int& MyArray::at(size_t index) throw(out_of_range)
{
if (index >= 0 && index < getSize())
return mArray[index];
else
throw out_of_range("MyArray::at: Index out of range.");
}
Code snippet from MyIntArrayMyIntArray.cpp
The class defines a constructor that accepts the size of the wrapped array. The constructor allocates the memory for the array while the destructor frees the memory. The getSize() method allows you to query the size of the wrapped array. The class also includes an at() method to give you access to elements of the wrapped array. Note that the at() method returns a reference, so it can also be used to assign values to array elements like in the following example:
MyArray arr(10);
cout << "Array size: " << arr.getSize() << endl;
arr.at(3) = 42;
cout << "arr[3] = " << arr.at(3) << endl;
try {
arr.at(10) = 3;
} catch (const exception& e) {
cout << "Caught exception: '" << e.what() << "'" << endl;
}
Code snippet from MyIntArrayMyIntArray.cpp
Now that you have this class, what would you do when you need to wrap an array of type double, or float or maybe even std::string? One possible solution would be to copy/paste the preceding code and edit it so that the type name is changed to type double, float, or whichever type you need.
By now you should immediately think that this cannot be the best solution to this problem and you are right. Templates allow you to solve exactly this problem without writing any new classes. The only thing you need to do is rewrite the preceding class a little so that it becomes a generic template class that you will be able to use with any type you want. What you have to do is specify that the type of the objects is also a parameter to the specification. This is done with a special syntax. Only a few small changes are required, as shown in the following new class definition. Note also that templates require you to put the implementation of the methods in the header file itself, because the compiler needs to know the complete definition, including the definition of methods before it can create an instance of the template. Putting implementations in header files is only acceptable with templates. In all other cases, it’s highly recommended to put implementation details in source files, not in header files. Chapters 19 and 20 will go much deeper into all the details about templates.
#include <stdexcept> template<typename T> class MyArray { public: MyArray(size_t size) : mSize(size), mArray(nullptr) { mArray = new T[size]; } virtual ~MyArray() { if (mArray) { delete [] mArray; mArray = nullptr; } } size_t getSize() const { return mSize; } T& at(size_t index) throw(std::out_of_range) { if (index >= 0 && index < getSize()) return mArray[index]; else throw std::out_of_range("MyArray::at: Index out of range."); } protected: size_t mSize; T* mArray; };
Code snippet from TemplateIntroductionTemplateIntroduction.h
As you can see in the preceding code, instead of using a specific type such as int, an unspecified type T is used everywhere. Before the class keyword, it is stated that this is a template class that accepts just one type, T. You can use any name you want for T, as long as it is not an existing keyword or type.
This generic fixed sized array template class can be used as follows:
// Wrap an int array
MyArray<int> arrInt(10);
cout << "Array size: " << arrInt.getSize() << endl;
arrInt.at(3) = 42;
cout << "arr[3] = " << arrInt.at(3) << endl;
try {
arrInt.at(10) = 3;
} catch (const exception& e) {
cout << "Caught exception: '" << e.what() << "'" << endl;
}
// Wrap a std::string array
MyArray<string> arrString(5);
cout << "Array size: " << arrString.getSize() << endl;
arrString.at(3) = "This is a test";
cout << "arr[3] = " << arrString.at(3) << endl;
try {
arrString.at(10) = 3;
} catch (const exception& e) {
cout << "Caught exception: '" << e.what() << "'" << endl;
}
Code snippet from TemplateIntroductionTemplateIntroductionTest.cpp
The example code first runs a number of tests on an array of type int, which is created as follows:
MyArray<int> arrInt(10);
With the preceding line, the compiler will instantiate a version of the MyArray class where T is substituted by int. Basically, the compiler will copy all the code for the MyArray class and replace every T with int.
After that, the example runs the same number of tests but on an array with elements of type std::string, which is created as follows:
MyArray<string> arrString(5);
With this line, the compiler will create a second copy of the MyArray code and will replace every T with string.
As you can see, the template parameter between the angled brackets is different. Other than that, using the two arrays is completely the same, independent of the type of the array elements. The output of the preceding example is as follows:
Array size: 10 arr[3] = 42 Caught exception: 'MyArray::at: Index out of range.' Array size: 5 arr[3] = This is a test Caught exception: 'MyArray::at: Index out of range.'
Use of Operator Overloading
Operator overloading is used extensively by the C++ standard library, including the STL. Chapter 7 has a whole section devoted to operator overloading. Make sure you read that section and understand it before tackling this and subsequent chapters. In addition, Chapter 18 presents much more detail on the subject of operator overloading, but those details are not required to understand the following chapters.
OVERVIEW OF THE C++ STANDARD LIBRARY
This section introduces the various components of the standard library from a design perspective. You will learn what facilities are available for you to use, but you will not learn the coding details. Those details are covered in other chapters throughout the book.
Note that the following overview is not comprehensive. Some details are introduced later in the book where they are more appropriate, and some details are omitted entirely. The standard library is too extensive to cover in its entirety in a general C++ book; there are books with over 800 pages that cover only the standard library.
Strings
C++ provides a built-in string class. Although you may still use C-style strings of character arrays, the C++ string class is superior in almost every way. It handles the memory management; provides some bounds checking, assignment semantics, and comparisons; and supports manipulations such as concatenation, substring extraction, and substring or character replacement.
Technically, the C++ string is actually a typedef name for a char instantiation of the basic_string template. However, you need not worry about these details; you can use string as if it were a bona fide nontemplate class.
In case you missed it, Chapter 1 briefly reviews the string class functionality , and Chapter 14 provides all the details.
I/O Streams
C++ introduces a new model for input and output using streams. The C++ library provides routines for reading and writing built-in types from and to files, console/keyboard, and strings. C++ also provides the facilities for coding your own routines for reading and writing your own objects. Chapter 1 reviews the basics of I/O streams. Chapter 15 provides the details of streams.
Localization
C++ also provides support for localization. These features allow you to write programs that work with different languages, character formats, and number formats. Chapter 14 discusses localization.
Smart Pointers
One of the problems faced in doing robust programming is knowing when to delete an object. There are several failures that can happen. A first problem is not deleting the object at all (failing to free the storage). This is known as memory leaks, where objects accumulate and take up space but are not used. Another problem is where someone deletes the storage but others are still pointing to that storage, resulting in pointers to storage which is either no longer in use or has been reallocated for another purpose. This is known as dangling pointers. One more problem is when one piece of code frees the storage, and another piece of code attempts to free the same storage. This is known as double-freeing. All of these tend to result in program failures of some sort. Some failures are readily detected; others simply cause the program to produce erroneous results. Most of these errors are difficult to discover and repair.
C++11 introduces two new concepts, the unique_ptr and the shared_ptr, which attempt to address these problems.
The unique_ptr is analogous to an ordinary pointer, except that it will automatically free the memory or resource when the unique_ptr goes out of scope or is deleted. One advantage of the unique_ptr is that it simplifies coding where storage must be freed when an exception is taken. When the variable leaves its scope, the storage is automatically freed.
shared_ptr allows for distributed “ownership” of the data. Each time a shared_ptr is assigned, a reference count is incremented indicating there is one more “owner” of the data. When a shared_ptr goes out of scope, the reference count is decremented. When the reference count goes to zero it means there is no longer any owner of the data, and the object referenced by the pointer is freed.
Before C++11, the functionality of unique_ptr was handled by a type called auto_ptr, which is now deprecated and should not be used anymore. There was no equivalent to shared_ptr in the earlier STL, although many third-party libraries (for example Boost) did provide this capability.
If your compiler supports the new C++11 unique_ptr and shared_ptr, it is highly recommended to use them instead of the deprecated auto_ptr.
Chapter 21 discusses smart pointers in more detail.
Exceptions
The C++ language supports exceptions, which allow functions or methods to pass errors of various types up to calling functions or methods. The C++ standard library provides a class hierarchy of exceptions that you can use in your program as is, or that you can subclass to create your own exception types. Chapter 10 covers the details of exceptions and the standard exception classes.
Mathematical Utilities
The C++ library provides some mathematical utility classes. Although they are templatized so that you can use them with any type, they are not generally considered part of the standard template library. Unless you are using C++ for numeric computation, you will probably not need to use these utilities.
The standard library provides a complex number class, called complex, which provides an abstraction for working with numbers that contain both real and imaginary components.
The standard library also contains a class called valarray, which is similar to the vector class but is more optimized for high performance numerical applications. The library provides several related classes to represent the concept of vector slices. From these building blocks, it is possible to build classes to perform matrix mathematics. There is no built-in matrix class; however, there are third-party libraries like Boost that include matrix support.
C++ also provides a new way to obtain information about numeric limits, such as the maximum possible value for an integer on the current platform. In C, you could access #defines, such as INT_MAX. While those are still available in C++, you can also use the new numeric_limits template class defined in the <limits> header file. Its use is straightforward as is shown in the following code:
cout << "Max int value: " << numeric_limits<int>::max() << endl; cout << "Lowest int value: " << numeric_limits<int>::lowest() << endl; cout << "Max double value: " << numeric_limits<double>::max() << endl; cout << "Lowest double value: " << numeric_limits<double>::lowest() << endl;
Code snippet from numeric_limits umeric_limits.cpp
![]() Time Utilities
Time Utilities
C++11 adds the Chrono library to the standard. It is defined in the <chrono> header file. This library makes it easy to work with time; for example, to time certain durations or to perform actions based on timing. The Chrono library is discussed in detail in Chapter 16.
![]() Random Numbers
Random Numbers
C++ already had support for generating pseudo-random numbers; however, it was only very basic support. For example, you could not change the distribution of the generated random numbers.
C++11 adds a complete random number library, which is much more powerful than the old C++ way of generating random numbers. The new library comes with uniform random number generators, random number engines, random number engine adaptors, and random number distributions. All of these can be used to give you random numbers more suited to your problem domain, such as normal distributions, negative exponential distributions, etc.
Consult Chapter 16 for all the details on this new library.
![]() Compile-Time Rational Arithmetic
Compile-Time Rational Arithmetic
The compile-time rational arithmetic library is new to C++11 and provides a ratio template class defined in the <ratio> header file. This ratio class can exactly represent any finite rational number defined by a numerator and denominator. This library is discussed in Chapter 16.
![]() Tuples
Tuples
Tuples are sequences with a fixed size that can have heterogeneous elements and are defined in the <tuple> header file. All standard template library containers discussed further in this chapter store homogenous elements, meaning that all the elements in a container must have the same type. A tuple allows you to store elements of completely unrelated types in one object. The number and type of elements for a tuple instantiation is fixed at compile time. Tuples are discussed in Chapter 16.
![]() Regular Expressions
Regular Expressions
C++11 adds the concept of regular expressions to the standard library and are defined in the <regex> header file. Regular expressions make it easy to perform so-called pattern-matching, often used in text processing. Pattern-matching allows you to search special patterns in strings and optionally replace those with a new pattern. Regular expressions are discussed in Chapter 14.
The Standard Template Library
The standard template library (STL) supports various containers and algorithms. This section briefly introduces those containers and algorithms. Later chapters will provide the coding details for using them in your programs.
STL Containers
The STL provides implementations of commonly-used data structures such as linked lists and queues. When you use C++, you should not need to write such data structures again. The data structures are implemented using a concept called containers, which store information called elements, in a way that implements the data structure (linked list, queue, etc.) appropriately. Different data structures have different insertion, deletion, and access behavior and performance characteristics. It is important to be familiar with the data structures available so that you can choose the most appropriate one for any given task.
All the containers in the STL are templates, so you can use them to store any type, from built-in types such as int and double to your own classes. Each container instance stores only objects of one type, that is, they are homogeneous collections. There is a new type in C++11 called tuples that allows fixed-sized heterogeneous collections of objects; but for ordinary containers, you need to store objects of one type and one type only. If you need non fixed-sized heterogeneous collections, you could create a class which has multiple subclasses, and each subclass could wrap an object of your required type.
The C++ STL containers are homogenous: They allow elements of only one type in each container.
Note that the C++ standard specifies the interface, but not the implementation, of each container and algorithm. Thus, different vendors are free to provide different implementations. However, the standard also specifies performance requirements as part of the interface, which the implementations must meet.
This section provides an overview of the various containers available in the STL.
vector
A vector stores a sequence of elements and provides random access to these elements. You can think of a vector as an array of elements that grows dynamically as you insert elements and provides some bounds checking. Like an array, the elements of a vector are stored in contiguous memory.
A vector in C++ is a synonym for a dynamic array: an array that grows and shrinks automatically in response to the number of elements it stores.
vectors provide fast element insertion and deletion (amortized constant time) at the end of the vector. Amortized constant time insertion means that most of the time insertions are done in constant time O(1). However, sometimes the vector needs to grow in size to accommodate new elements which has a complexity of O(N). On average this results in O(1) complexity or amortized constant time. Details are explained in Chapter 12. A vector has slow (linear time) insertion and deletion anywhere else, because the operation must move all the elements “down” or “up” by one to make room for the new element or to fill the space left by the deleted element. Like arrays, vectors provide fast (constant time) access to any of their elements.
You should use a vector in your programs when you need fast access to the elements, but do not plan to add or remove elements often. A good rule of thumb is to use a vector whenever you would have used an array. For example, a system-monitoring tool might keep a list of computer systems that it monitors in a vector. Only rarely would new computers be added to the list, or current computers removed from the list. However, users would often want to look up information about a particular computer, so lookup times should be fast.
Use a vector instead of an array whenever possible.
There is a template specialization available for vector<bool> to store Boolean values in a vector. This specialization optimizes space allocation for the Boolean elements; however, the standard does not specify how an implementation of vector<bool> should optimize space. The difference between the vector<bool> specialization and the bitset discussed further in this chapter is that the bitset container is of fixed size.
list
An STL list is a doubly linked list structure. Like an array or vector, it stores a sequence of elements. However, unlike an array or vector, the elements of a list are not necessarily in contiguous memory. Instead, each element in the list specifies where to find the next and previous elements in the list (usually via pointers), hence the name doubly linked list.
The performance characteristics of a list are the exact opposite of a vector. They provide slow (linear time) element lookup and access, but quick (constant time) insertion and deletion of elements once the relevant position has been found. Thus, you should use a list when you plan to insert and remove many elements, but do not require quick lookup.
deque
The name deque is an abbreviation for a double-ended queue, although it behaves more like a vector instead of a queue which is discussed later. A deque provides quick (constant time) element access. It also provides fast (amortized constant time) insertion and deletion at both ends of the sequence, but it provides slow (linear time) insertion and deletion in the middle of the sequence.
You should use a deque instead of a vector when you need to insert or remove elements from either end of the sequence but still need fast access to all elements. However, this requirement does not apply to many programming problems; in most cases a vector or list should suffice.
![]() array
array
C++11 introduces a new type of sequential container called std::array. This is a replacement for the standard C-style arrays. Sometimes you know the exact number of elements in your container upfront and you don’t need the flexibility of a vector or a list, which are able to grow dynamically to accommodate new elements. The C++11 std::array is perfect for such fixed-sized collections and it does not have the same overhead as vector; it’s basically a thin wrapper around standard C-style arrays. There are a number of advantages in using std::arrays instead of standard C-style arrays; they always know their own size, do not automatically get cast to a pointer to avoid certain types of bugs, and have iterators to easily loop over the elements.
std::arrays do not provide insertion or deletion. They have a fixed size. Access to elements is very fast (constant time), just as with vectors.
![]() forward_list
forward_list
The forward_list, introduced in C++11, is a singly linked list, compared to the list container, which is doubly linked. The forward_list supports forward iteration only. They require less memory than a list; allow constant time insertion and deletion anywhere; and like lists, there is no fast random access to elements.
The vector, list, deque, array, and forward_list containers are called sequential containers because they store a sequence of elements.
queue
The name queue comes directly from the definition of the English word queue, which means a line of people or objects. The queue container provides standard first in, first out (or FIFO) semantics. A queue is a container in which you insert elements at one end and take them out at the other end. Both insertion (amortized constant time) and removal (constant time) of elements is quick.
You should use a queue structure when you want to model real-life “first-come, first-served” semantics. For example, consider a bank. As customers arrive at the bank, they get in line. As tellers become available, they serve the next customer in line, thus providing “first-come, first-served” behavior. You could implement a bank simulation by storing Customer objects in a queue. As customers arrive at the bank, they are added to the end of the queue. As tellers serve customers, they start with customers at the front of the queue. That way, customers are served in the order in which they arrived.
priority_queue
A priority_queue provides queue functionality in which each element has a priority. Elements are removed from the queue in priority order. In the case of priority ties, the FIFO semantics hold so that the first element inserted is the first removed. priority_queue insertion and deletion are generally slower than simple queue insertion and deletion, because the elements must be reordered to support the priority ordering.
You can use priority_queues to model “queues with exceptions.” For example, in the preceding bank simulation, suppose that customers with business accounts take priority over regular customers. Many real-life banks implement this behavior with two separate lines: one for business customers and one for everyone else. Any customers in the business queue are taken before customers in the other line. However, banks could also provide this behavior with a single line in which business customers move to the front of the line ahead of any nonbusiness customers. In your program, you could use a priority_queue in which customers have one of two priorities: business or regular. All business customers would be serviced before all regular customers, but each group would be serviced in first-come, first-served order.
stack
The STL stack provides standard first-in, last-out (FILO) semantics, also known as last-in, first-out (LIFO). Like a queue, elements are inserted and removed from the container. However, in a stack, the most recent element inserted is the first one removed. The name stack derives from a visualization of this structure as a stack of objects in which only the top object is visible. When you add an object to the stack, you hide all the objects underneath it.
The STL stack container provides fast (constant time) insertion and removal of elements. You should use the stack structure when you want FILO semantics. For example, an error-processing tool might want to store errors on a stack so that the most recent error is the first one available for a human administrator to read. Processing errors in a FILO order is often useful because newer errors sometimes obviate older ones.
Technically, the queue, priority_queue, and stack containers are container adapters. They are simple interfaces built on top of one of the standard sequential containers (vector, list, deque, array, and forward_list).
set and multiset
A set in the STL is, as the name suggests, a set of elements, loosely analogous to the notion of a mathematical set: Each element is unique, and there is at most one instance of the element in the set. One difference between the mathematical concept of set, and set as implemented in the STL, is that in the STL the elements are kept in an order. The reason for the order is that when the client enumerates the elements, they come out in the ordering imposed by the type’s operator< or a user defined comparator. The set provides logarithmic insertion, deletion, and lookup. This means insertions and deletions are faster than for a vector but slower than for a list. Lookups are faster than for a list, but slower than for a vector.
You should use a set when you need the elements to be in an order, have equal amounts of insertion/deletion and lookups, and want to optimize performance for both as much as possible. For example, an inventory-tracking program in a busy bookstore might want to use a set to store the books. The list of books in stock must be updated whenever books arrive or are sold, so insertion and deletion should be quick. Customers also need the ability to look for a specific book, so the program should provide fast lookup as well.
Use a set instead of a vector or list if you need order and want equal performance for insertion, deletion, and lookup.
Note that a set does not allow duplicate elements. That is, each element in the set must be unique. If you want to store duplicate elements, you must use a multiset.
map and multimap
A map stores key/value pairs. A map keeps its elements in sorted order, based on the key values, not the object values. In all other respects, it is identical to a set. You should use a map when you want to associate keys and values. For example, in the preceding bookstore example, you might want to store the books in a map where the key is the ISBN number of the book and the value is a Book object containing detailed information for that specific book.
A multimap has the same relation to a map as a multiset does to a set. Specifically, a multimap is a map that allows duplicate keys.
Note that you can use a map as an associative array. That is, you can use it as an array in which the index can be any type, such as a string.
The set and map containers are called associative containers because they associate keys and values. This term is confusing when applied to sets, because in sets the keys are themselves the values. These containers sort their elements, so they are called sorted or ordered associative containers.
bitset
C and C++ programmers commonly store a set of flags in a single int or long, using one bit for each flag. They set and access these bits with the bitwise operators: &, |, ^, ~, <<, and >>. The C++ standard library provides a bitset class that abstracts this bit field manipulation, so you shouldn’t need to use the bit manipulation operators anymore.
The <bitset> header file defines the bitset container, but this is not a container in the normal sense, in that it does not implement a specific data structure in which you insert and remove elements; they have a fixed size and don’t support iterators. You can think of them as a sequence of Boolean values that you can read and write. However, unlike the normal way this is handled in C programming, the bitset is not limited to the size of an int or other elementary data types. Thus, you can have a 40-bit bitset, or a 213-bit bitset. The implementation will use as much storage as it needs to implement N bits when you declare your bitset with bitset<N>.
![]() Unordered Associative Containers / Hash Tables
Unordered Associative Containers / Hash Tables
C++11 adds the concept of hash tables, also called unordered associative containers. Four hash tables are introduced:
- unordered_map
- unordered_set
- unordered_multimap
- unordered_multiset
Better names would have been hash_map, hash_set, and so on. Unfortunately, hash tables were not part of the C++ standard library before C++11, which means a lot of third-party libraries implemented hash tables themselves by using names with a prefix hash like hash_map. Because of this, the C++ standard committee decided to use the prefix unordered instead of hash to avoid name clashes.
These unordered associative containers behave similar to their ordered counterparts. An unordered_map is similar to a standard map except that the standard map sorts its elements while the unordered_map doesn’t sort its elements.
Insertion, deletion, and lookup with these unordered associative containers can be done on average in constant time. In a worst case scenario it will be in linear time. Lookup of elements in an unordered container can be much faster than with a normal map or set, especially when there are lots of elements in the container.
Chapter 12 explains how these unordered associative containers work and why they are also called hash tables.
Summary of STL Containers
The following table summarizes the containers provided by the STL. It uses the big-O notation introduced in Chapter 2 to present the performance characteristics on a container of N elements. An N/A entry in the table means that the operation is not part of the container semantics.

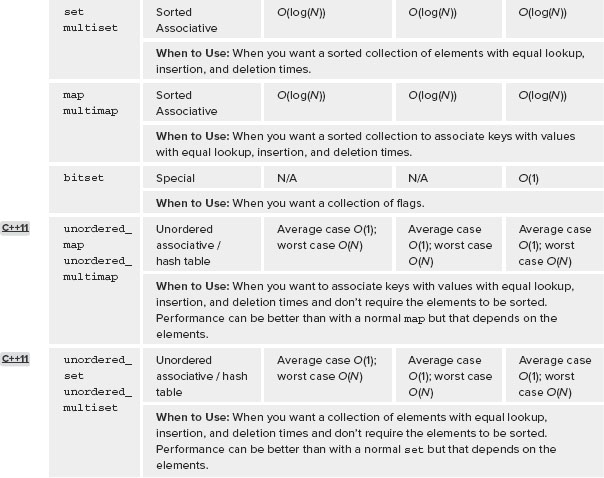
Note that strings are technically containers as well. They can be thought of as vectors of characters. Thus, some of the algorithms described in the material that follows also work on strings.
STL Algorithms
In addition to containers, the STL provides implementations of many generic algorithms. An algorithm is a strategy for performing a particular task, such as sorting or searching. These algorithms are also implemented as templates, so they work on most of the different container types. Note that the algorithms are not generally part of the containers. The STL takes the approach of separating the data (containers) from the functionality (algorithms). Although this approach seems counter to the spirit of object-oriented programming, it is necessary in order to support generic programming in the STL. The guiding principle of orthogonality maintains that algorithms and containers are independent, with (almost) any algorithm working with (almost) any container.
Although the algorithms and containers are theoretically independent, some containers provide certain algorithms in the form of class methods because the generic algorithms do not perform well on those particular containers. For example, sets provide their own find() algorithm that is faster than the generic find() algorithm. You should use the container-specific method form of the algorithm, if provided, because it is generally more efficient or appropriate for the container at hand.
Note that the generic algorithms do not work directly on the containers. They use an intermediary called an iterator. Each container in the STL provides an iterator that supports traversing the elements in the container in a sequence. The different iterators for the various containers adhere to standard interfaces, so algorithms can perform their work by using iterators without worrying about the underlying container implementation.
This section gives an overview of what kind of algorithms are available in the STL without giving all the fine points. The Standard Library Reference resource on the website (www.wrox.com) contains the exact prototypes of all the algorithms. The following chapters go deeper in on iterators, algorithms, and containers with coding examples.
Iterators mediate between algorithms and containers. They provide a standard interface to traverse the elements of a container in sequence, so that any algorithm can work on any container.
There are approximately 60 algorithms in the STL (depending on how you count them), generally divided into several different categories. In addition, C++11 adds several new algorithms to the STL. The categories tend to vary slightly from book to book. This book uses the following five categories: utility, non-modifying, modifying, sorting, and set. Some of the categories can be subdivided further. Note that whenever the following algorithms are specified as working on a “sequence” of elements, that sequence is presented to the algorithm via iterators.
When examining the list of algorithms, keep in mind that the STL was designed by a committee. The committee approach tends to add generality that might never be used, but which, if required, would be essential. You may not need every algorithm, or need to worry about the more obscure parameters which are there for anticipated generality. It is important only to be aware of what’s available in case you ever find it useful.
Utility Algorithms
Unlike the other algorithms, the utility algorithms do not work on sequences of data. We consider them part of the STL only because they are templatized.
| ALGORITHM NAME | ALGORITHM SYNOPSIS |
| min(), max() | Returns the minimum or maximum of two values. C++11 allows you to use the min() and max() functions to find the minimum and maximum of more than two values. |
| Returns the minimum and maximum of two or more values as a pair. | |
| swap() | Swaps two values. |
Non-Modifying Algorithms
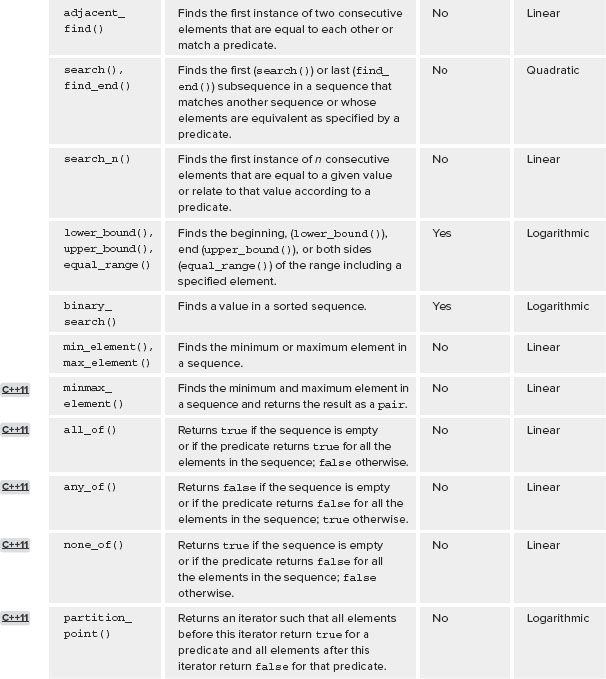
The non-modifying algorithms are those that look at a sequence of elements and return some information about the elements, or execute some function on each element. As “non-modifying” algorithms, they cannot change the values of elements or the order of elements within the sequence. This category contains four types of algorithms. The following tables list and provide brief summaries of the various non-modifying algorithms. With these algorithms, you should rarely need to write a for loop to iterate over a sequence of values.
Search Algorithms

Numerical Processing Algorithms
The following numerical processing algorithms are provided. None of them require the source sequences to be ordered. All of them have a linear complexity.
| ALGORITHM NAME | ALGORITHM SYNOPSIS |
| count(), count_if() | Counts the number of elements matching a value or that cause a predicate to return true. |
| accumulate() | “Accumulates” the values of all the elements in a sequence. The default behavior is to sum the elements, but the caller can supply a different binary function instead. |
| inner_product() | Similar to accumulate(), but works on two sequences. Calls a binary function (multiplication by default) on parallel elements in the sequences, accumulating the result using another binary function (addition by default). If the sequences represent mathematical vectors, the algorithm calculates the dot product of the vectors. |
| partial_sum() | Generates a new sequence in which each element is the sum (or other binary operation) of the parallel element, and all preceding elements, in the source sequence. |
| adjacent_difference() | Generates a new sequence in which each element is the difference (or other binary operation) of the parallel element, and its predecessor, in the source sequence. |
Comparison Algorithms
The following comparison algorithms are provided. None of them require the source sequences to be ordered. All of them have a linear worst case complexity.
| ALGORITHM NAME | ALGORITHM SYNOPSIS |
| equal() | Determines if two sequences are equal by checking if parallel elements are equal or match a predicate. |
| mismatch() | Returns the first element in each sequence that does not match the element in the same location in the other sequence. |
| lexicographical_compare() | Compares two sequences to determine their “lexicographical” ordering. Compares each element of the first sequence with its equivalent element in the second. If one element is less than the other, that sequence is lexicographically first. If the elements are equal, compares the next elements in order. |
Operational Algorithms
The following operational algorithms are provided. None of them require the source sequences to be ordered. All of them have a linear complexity.
| ALGORITHM NAME | ALGORITHM SYNOPSIS |
| for_each() | Executes a function on each element in the sequence. |
Modifying Algorithms
The modifying algorithms modify some or all of the elements in a sequence. Some of them modify elements in place, so that the original sequence changes. Others copy the results to a different sequence so that the original sequence is unchanged. All of them have a linear worst case complexity. The following table summarizes the modifying algorithms:
| ALGORITHM NAME | ALGORITHM SYNOPSIS |
| transform() | Calls a unary function on each element of a sequence or a binary function on parallel elements of two sequences. |
| copy(), copy_backward() | Copies elements from one sequence to another. |
| Sequentially assigns a given value to each element in a sequence and increments the given value after each element assignment. | |
| Copies elements for which the predicate returns true from one sequence to another. | |
| Copies n elements from one sequence to another. | |
| Copies elements from one sequence to two different sequences. The target sequence is selected based on the result of a predicate, either true or false. | |
| Moves elements from one sequence to another. This uses the efficient move semantics introduced by C++11. | |
| Moves elements from one sequence to another starting with the last element. This uses the efficient move semantics introduced by C++11. | |
| iter_swap(), swap_ranges() | Swaps two elements or sequences of elements. |
| replace(), replace_if() | Replaces all elements matching a value or that cause a predicate to return true with a new element. |
| replace_copy(), replace_copy_if() | Replaces all elements matching a value or that cause a predicate to return true with a new element, by copying results to a new sequence. |
| fill() | Sets all elements in the sequence to a new value. |
| fill_n() | Sets the first n elements in the sequence to a new value. |
| generate() | Calls a specified function to generate a new value and sets all elements in the sequence to the result of that function. |
| generate_n() | Calls a specified function to generate a new value and sets the first n elements in the sequence to the result of that function. |
| remove(), remove_if() | Removes elements that match a given value or that cause a predicate to return true. |
| remove_copy(), remove_copy_if() | Removes elements that match a given value or that cause a predicate to return true, by copying results to a different sequence. |
| unique(), unique_copy() | Removes consecutive duplicates from the sequence, either in place or by copying results to a different sequence. |
| reverse(), reverse_copy() | Reverses the order of the elements in the sequence, either in place or by copying the results to a different sequence. |
| rotate(), rotate_copy() | Swaps the first and second “halves” of the sequence, either in place or by copying the results to a different sequence. The two subsequences to be swapped need not be equal in size. |
| next_permutation(), prev_permutation() | Modifies the sequence by transforming it into its “next” or “previous” permutation. Successive calls to one or the other will permute the sequence into all possible permutations of its elements. Returns false if no more permutations exist. |
Sorting Algorithms
Sorting algorithms are a special category of modifying algorithms that sort the elements of a sequence. The STL provides several different sorting algorithms with varying performance guarantees.
| ALGORITHM NAME | ALGORITHM SYNOPSIS | COMPLEXITY |
| sort(), stable_sort() | Sorts elements in place, either preserving the order of duplicate elements or not. | Linear Logarithmic |
| partial_sort(), partial_sort_copy() | Partially sorts the sequence: The first n elements (specified by iterators) are sorted; the rest are not. They are sorted either in place or by copying them to a new sequence. | Linear Logarithmic |
| nth_element() | Relocates the nth element of the sequence such that the element in the position pointed to by nth is the element that would be in that position if the whole range were sorted. | Linear |
| merge() | Merges two sorted sequences by copying them to a new sequence. | Linear |
| inplace_merge() | Merges two sorted sequences in place. | Linear Logarithmic |
| make_heap(), is_heap(), is_heap_until() | A heap is a standard data structure in which the elements of an array or sequence are ordered in a semi-sorted fashion so that finding the “top” element is quick. Six algorithms allow you to use heap-sort on sequences. is_heap() and is_heap_until() are new since C++11. | Linear |
| push_heap(), pop_heap() | See previous row. | Logarithmic |
| sort_heap() | See previous row. | Linear Logarithmic |
| partition() | Sorts the sequence such that all elements for which a predicate returns true are before all elements for which it returns false, without preserving the original order of the elements within each partition. | Linear |
| stable_partition() | Sorts the sequence such that all elements for which a predicate returns true are before all elements for which it returns false, while preserving the original order of the elements within each partition. | Linear Logarithmic |
| random_shuffle() | “Unsorts” the sequence by randomly reordering the elements. In C++11, it is possible to specify the properties of the random number generator used for this. | Linear |
| Checks if a sequence is sorted or which subsequence is sorted. | Linear |
Set Algorithms
Set algorithms are special modifying algorithms that perform set operations on sequences. They are most appropriate on sequences from set containers, but work on sorted sequences from most containers. All of them have a linear worst case complexity.
| ALGORITHM NAME | ALGORITHM SYNOPSIS |
| includes() | Determines if every element from one sequence is in another sequence. |
| set_union(), set_intersection(), set_difference(), set_symmetric_difference() | Performs the specified set operation on two sorted sequences, copying results to a third sorted sequence. See Chapter 13 for an explanation of the set operations. |
Choosing an Algorithm
The number and capabilities of the algorithms might overwhelm you at first. It can also be difficult to see how to apply them in the beginning. However, now that you have an idea of the available options, you are better able to tackle your program designs. The next chapters cover the details of how to use these algorithms in your code.
What’s Missing from the STL
The STL is powerful, but it’s not perfect. Here is a list of omissions and unsupported functionality:
- The STL does not guarantee any thread safety for accessing containers simultaneously from multiple threads.
- The STL does not provide any generic tree or graph structures. Although maps and sets are generally implemented as balanced binary trees, the STL does not expose this implementation in the interface. If you need a tree or graph structure for something like writing a parser, you will need to implement your own or find an implementation in another library.
However, it is important to keep in mind that the STL is extensible. You can write your own containers or algorithms that will work with existing algorithms or containers. So, if the STL doesn’t provide exactly what you need, consider writing your desired code such that it works with the STL. Chapter 17 covers the topic of customizing and extending the STL.
This chapter provided an overview of the C++ standard library, which is the most important library that you will use in your code. It subsumes the C library and includes additional facilities for strings, I/O, error handling, and other tasks. It also includes generic containers and algorithms, which are together referred to as the standard template library (STL). The next chapters describe the standard template library in more detail.