
Now that you know how to extract data from Oracle, you need to know how to load it back in again. This is easy if you have generated a file of SQL commands — you simply execute that file from within SQL*Plus. Loading data is a little tougher, however, if you have a file of comma-delimited or fixed-width data.
In order to load data into Oracle from a flat file, you need to use a tool called SQL*Loader. SQL*Loader is a generic utility provided by Oracle for the express purpose of loading data into the database from a file. An entire book could be written about SQL*Loader, so it’s not possible to cover it exhaustively in the remainder of this chapter. What I can do is show you how to use SQL*Loader to reload the employee table from either a comma-delimited or fixed-width text file — the same files you learned how to create in this chapter. That should be enough to get you started.
If you extract data by using SQL*Plus to create a file of INSERT commands, loading the data somewhere else is as simple as creating the necessary table and executing the file. If you created a file of DDL commands, such as the CREATE PUBLIC SYNONYM commands shown earlier, you only need to execute that file.
As I mentioned, SQL*Loader is Oracle’s data loading utility, a general-purpose utility that can be configured to read and load data from a wide variety of record formats. It’s a very powerful and versatile utility, and, possibly because of that, it can be frustrating to learn. Certainly the manual can be a bit overwhelming the first time you look at it.
In order to load data from a flat file into a database, you need to provide several types of information to SQL*Loader. First of all, SQL*Loader needs to know what database to connect to, how to connect to it, and what table to load. Then SQL*Loader needs to know the format of the input file. It needs to know where the fields are, how long they are, and how they are represented. If, for example, your input file has date fields, SQL*Loader needs to know whether they are in MM/DD/YYYY format, MM/DD/YY format, or some other format.
The database connection and login information are usually passed to SQL*Loader as command-line arguments. The remaining information, describing the input file, needs to be placed in a text file called the control file. When you run SQL*Loader, you tell it where the control file is. Then SQL*Loader reads the control file and uses that information to interpret the data in the flat file you are trying to load. Figure 5.1 illustrates this, and shows the information flow into and out of SQL*Loader.
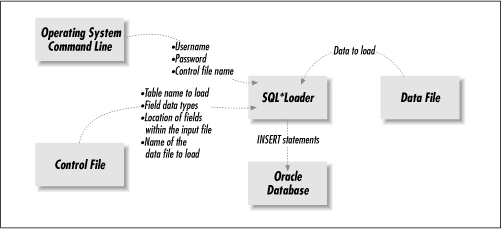
In addition to describing the input file, the control file can be used to tell SQL*Loader what to do with badly formatted data records, and it can be used to specify conditions limiting the data that is loaded. You can read more about SQL*Loader in the Oracle8 Server Utilities manual.
The extract example shown earlier in this chapter produced comma-delimited output that looks like this:
107,"Bohdan Khmelnytsky",01/02/1998,,45 108,"Pavlo Chubynsky",03/01/1994,11/15/1998,220 110,"Ivan Mazepa",04/04/1998,09/30/1998,84 111,"Taras Shevchenko",08/23/1976,,100
In order to load this same data back into the employee table, or into another copy of the employee table, you need a control file that looks like this:
LOAD DATA INFILE 'c:aemp_data.csv' INTO TABLE employee ( employee_id INTEGER EXTERNAL TERMINATED BY ',', employee_name CHAR TERMINATED BY ',' OPTIONALLY ENCLOSED BY `"', employee_hire_date DATE "MM/DD/YYYY" TERMINATED BY ',', employee_termination_date DATE "MM/DD/YYYY" TERMINATED BY ',', employee_billing_rate DECIMAL EXTERNAL TERMINATED BY ',' )
You can think of the above as one long SQL*Loader command. The keywords LOAD DATA tell SQL*Loader to load data, and the rest of the command tells SQL*Loader where to get the data and how it is formatted. The remaining clauses are interpreted as described below:
- INFILE `c:aemp_data.csv’
Tells SQL*Loader to read data from the file named
emp_data.csvin thec:adirectory.- INTO TABLE employee
Tells SQL*Loader to insert the data into the employee table owned by the current user. SQL*Loader will query Oracle’s data dictionary tables for the columns and datatypes used in this table.
- (...column_specifications...)
A comma-delimited list of column specifications. Each column specification consists of the column name, followed by the representation (in the flat file) of the column, followed by the delimiter information.
The column names must correspond to the column names used in the database table you are loading, and they control the destination of each data element. For a delimited file, the order in which the column specifications appear in the control file must match the field order in the record.
The four elements of the column specifications used in this example are described in the following list. Table 5.1 describes the three datatypes that were used.
- column_name
Must be a column name in the destination table.
- datatype
A SQL*Loader datatype; See Table 5.1.
- TERMINATED BY `,’
Tells SQL*Loader that a comma marks the end of the value for the data element.
- OPTIONALLY ENCLOSED BY `"'
Tells SQL*Loader that the data element may optionally be enclosed in quotes. If quotes are present, they are stripped off before the value is loaded.
SQL*Loader has its own set of datatypes, and they aren’t the same as the ones used by the database. The most common datatypes used for loading data from text files are the numeric EXTERNAL types, CHAR, and DATE.
Table 5-1. SQL*Loader Data Elements
|
Datatype |
Description |
|---|---|
|
The data is numeric integer data stored as a character string. The character string must consist of the digits through 9. Leading or trailing spaces are OK. Leading positive or negative signs (+ or -) are also OK. | |
|
The data is a date, and the date is in the format specified by the format string. | |
|
Similar to INTEGER EXTERNAL, except that the number may contain a decimal point. This type was used for the employee_billing_rate field, because the billing rate is a dollar and cent value. | |
|
Used for character data. |
The control file used to load fixed-width employee data is very similar to that used for delimited data. The only difference is that instead of specifying a delimiter for each field, you specify the starting and ending columns. Earlier in this chapter, you saw how to create a fixed-width file of employee data that looked like this:
00107 Bohdan Khmelnytsky 01/02/1998 +045.00 00108 Pavlo Chubynsky 03/01/1994 11/15/1998 +220.00 00110 Ivan Mazepa 04/04/1998 09/30/1998 +084.00 00111 Taras Shevchenko 08/23/1976 +100.00
Here is a control file that will load this fixed-width data back into the employee table:
LOAD DATA
INFILE 'c:aemp_data.dat'
INTO TABLE employee
(
employee_id POSITION (1:6) INTEGER EXTERNAL,
employee_name POSITION (8:28) CHAR,
employee_hire_date POSITION (29:38) DATE "MM/DD/YYYY",
employee_termination_date POSITION (40:49) DATE "MM/DD/YYYY"
NULLIF employee_termination_date=BLANKS,
employee_billing_rate POSITION (51:57) DECIMAL EXTERNAL
)Each column in this control file contains a position specification that tells SQL*Loader where each field begins and ends. For some reason I have never been able to fathom, the position specification must precede the datatype, whereas a delimiter specification must follow the datatype. The position specification takes the form:
POSITION (starting_column:ending_column)
The starting and ending column numbers tell SQL*Loader where in the record to find the data, and the first character of a record is considered position 1. Unlike the case with delimited files, you do not have to list the column specifications for a fixed-width data file in any particular order.
Tip
The position specification for EMPLOYEE_ID, in this example, allows for six digits. The reason for this is to match the format of the fixed-width text file you saw generated in an earlier example in this chapter. Because the EMPLOYEE_ID field is numeric, it contains one space for a leading sign character. You will see this if you run the earlier example that generates a fixed-width file and look at the results in a text editor such as Notepad.
The employee_termination date column in this control file contains an extra element, a NULLIF clause. The NULLIF clause (the way it is written in the example) tells SQL*Loader to set the employee_termination_date column to null when the input data record contains spaces instead of a date. You didn’t need this clause when loading the comma-delimited file because a null date was represented by a null string between two adjacent commas. In the case of this fixed-width data, a null date is represented as a string of spaces, or blanks. If SQL*Loader attempts to convert these blanks to a date, a validation error will occur, and the record will be rejected. The NULLIF clause avoids this problem because it is checked first. If the date field in the input file contains all blanks, the corresponding database column is set to null. No conversion is attempted, no validation error occurs, and the record will be loaded.
Once you have the control file written, you can invoke SQL*Loader to load the data into the database. You can pass the following three items as command-line parameters:
A login string
The control file name
A log file name
The last item, the log file name, is optional. If you include a log file name, SQL*Loader will generate a log of its activity and write it to that file. Among other things, any bad data records will result in log entries being made. At the end of the log file, SQL*Loader will print a summary showing how many records were loaded successfully and how many were rejected because of data errors. You won’t get this information without a log file, so it’s a good idea to generate one.
SQL*Loader is implemented as a command-line utility. To run it under
Microsoft Windows, you must first open up a command prompt (or DOS)
window. On most Unix systems, the command to run SQL*Loader will be
sqlldr
. In a Windows environment, the command
has the Oracle version number appended to it. If you have Oracle8
installed, the command will look like this:
SQLLDR80 jonathan/secret CONTROL=emp_delimited.ctl LOG=emp_delimited.log
The elements of this command are described next:
- SQLLDR80
This is the command to invoke SQL*Loader. The 80 in this example refers to the Oracle version number, and is only needed in a Windows environment. If you are running under Unix, the command will be
sqlldr.- jonathan/secret
This is the database username and password that SQL*Loader uses to connect to Oracle. This user must either own the table into which you are loading data, or must have INSERT access to that table.
- CONTROL=emp_delimited.ctl
This tells SQL*Loader where to find the control file. If your control file is not in the current working directory, you can include the path as part of the name.
- LOG=emp_delimited.log
This tells SQL*Loader what name to use for the log file. This name may include the path. It also tells SQL*Loader to create a log file. If you leave off this argument, you won’t get a log file at all.
Here is how it looks to execute the command just shown and load the employee data from the comma-delimited file:
C>SQLLDR80 jonathan/secret CONTROL=emp_delimited.ctl LOG=emp_delimited.log
SQL*Loader: Release 8.0.3.0.0 - Production on Mon Mar 30 21:52:51 1998
(c) Copyright 1997 Oracle Corporation. All rights reserved.
Commit point reached - logical record count 11
C>You can see that you don’t get much information at all about what happened. About all you can tell from SQL*Loader’s output to the display is that there were 11 records in the input data file. The log file has more detail, however, and will look like this:
SQL*Loader: Release 8.0.3.0.0 - Production on Mon Mar 30 21:52:51 1998
(c) Copyright 1997 Oracle Corporation. All rights reserved.
Control File: emp_delimited.ctl
Data File: c:aemp_data.csv
Bad File: emp_data.bad
Discard File: none specified
(Allow all discards)
Number to load: ALL
Number to skip: 0
Errors allowed: 50
Bind array: 64 rows, maximum of 65536 bytes
Continuation: none specified
Path used: Conventional
Table EMPLOYEE, loaded from every logical record.
Insert option in effect for this table: INSERT
Column Name Position Len Term Encl Datatype
------------------------------ ---------- ----- ---- ---- -------------------
EMPLOYEE_ID FIRST * , CHARACTER
EMPLOYEE_NAME NEXT * , O(") CHARACTER
EMPLOYEE_HIRE_DATE NEXT * , DATE MM/DD/YYYY
EMPLOYEE_TERMINATION_DATE NEXT * , DATE MM/DD/YYYY
EMPLOYEE_BILLING_RATE NEXT * , CHARACTER
Table EMPLOYEE:
11 Rows successfully loaded.
0 Rows not loaded due to data errors.
0 Rows not loaded because all WHEN clauses were failed.
0 Rows not loaded because all fields were null.
Space allocated for bind array: 65040 bytes(60 rows)
Space allocated for memory besides bind array: 0 bytes
Total logical records skipped: 0
Total logical records read: 11
Total logical records rejected: 0
Total logical records discarded: 0
Run began on Mon Mar 30 21:52:51 1998
Run ended on Mon Mar 30 21:52:53 1998
Elapsed time was: 00:00:02.58
CPU time was: 00:00:00.00The most important part of the log file to look at is the summary near the bottom, where SQL*Loader tells you how many rows were successfully loaded. In this case, all 11 records loaded cleanly. If any records were rejected because of bad data, there would be an entry for each in the log file telling you which record was rejected and why.
There is a lot more to SQL*Loader than what you have seen in this chapter. Here are some of the other things you can do with SQL*Loader:
You can specify a bad file, which is where SQL*Loader places records that are rejected because of bad data. After a load, you can review the bad file, fix the records, and attempt to load them again.
You can use a WHERE clause to place a restriction on the records to be loaded. Only those records that match the criteria in the WHERE clause will be loaded. Other records are ignored, or may optionally be placed in a discard file.
You can build expressions, using any of Oracle’s built-in SQL functions, to manipulate the data in the input file before it is loaded into Oracle.
The Oracle8 Server Utilities manual documents the SQL*Loader utility, and has a number of case studies that show you how to use these and other features.