
Chapter 1: Opportunities and Challenges
Machine Learning (ML) and data science are winning a popularity contest of sorts, as witnessed by their headline coverage in the popular and professional press and by expanding job openings across the technology landscape. Students typically learn ML techniques using their own computers on relatively small datasets. Those who enter the field often find themselves in the much different setting of a large company buzzing with workers performing specialized job roles, while collaborating with others scattered across the nation or world. Both data science students and data science workers have a few key things in common – they are in an exciting and growing field that businesses deem ever more critical to their future, and the data they thrive on is becoming exponentially more abundant and diverse.
There are huge opportunities for ML in enterprises because the transformational impacts of ML on businesses, customers, patients, and so on are diverse, widespread, lucrative, and life-changing. A backdrop of urgency exists as well from competitors who are all attempting the same thing. Enterprises are thus incented to invest in significant ML transformations and to supply the necessary data, tooling, production systems, and people to journey toward ML success. But challenges loom large as well, and these challenges commonly revolve around scale. The challenges of scale take on many forms inherent to ML at an enterprise level.
In this chapter, we will define and explore the challenge of ML at scale by covering the following main topics:
- ML at scale
- The ML life cycle and three challenge areas for ML at scale
- H2O.ai's answer to these challenges
ML at scale
This book is about implementing ML at scale and how to use H2O.ai technology to succeed in doing so. What specifically do we mean by ML at scale? We can see three contexts and challenges of scale during the ML life cycle – building models from large datasets, deploying these models in enterprise production environments, and executing the full range of ML activities within the complexities of enterprise processes and stakeholders. This is summarized in the following figure:

Figure 1.1 – The challenges of ML at scale
Let's drill down further on these challenges. Before doing so, we will oversee a generic conception of the ML life cycle, which will be useful as a reference throughout the book.
The ML life cycle and three challenge areas for ML at scale
The ML life cycle is a process that data scientists and enterprise stakeholders follow to build ML models and put them into production environments, where they make predictions and achieve value. In this section, we will define a simplified ML life cycle and elaborate on two broad areas that present special challenges for ML at scale.
A simplified ML life cycle
We will use the following ML life cycle representation. The goal is to achieve a simplified depiction that we can all recognize as central to ML while avoiding attempts at a canonical definition. Let's use it as our working framework for discussion:

Figure 1.2 – A simplified ML life cycle
The following is a brief articulation.
Model building
Model building is a highly iterative process with frequent and unpredictable feedback loops along the way toward building a predictive model that is worthy of deploying in a business context. The steps can be summarized as follows:
- Data ingestion: Data is pulled from sources or a storage layer in the model building environment. There is often significant work onward from here in finding and accessing potentially useful data sources and transforming the data into a useable form. Typically, this is done as part of a larger data pipeline and architecture.
- Data exploration: Data is explored to understand its qualities (for example, data profiling, correlation analysis, outlier detection, and data visualization).
- Data manipulation: Data is cleaned (for example, the imputation of missing data, the reduction of categorical features, and normalization) and new features are engineered.
- Model training: An ML algorithm, scoring metric, and validation method are selected, and the model is tuned across a range of hyperparameters and tested against a test dataset.
- Model evaluation and explainability: A fit of the model is diagnosed for performance metrics, overfitting, and other diagnostics; model explainability is used to validate against domain knowledge, to explain the model decisions at individual and global levels, and to guard against institutional risks such as unfair bias against demographic groups.
- Model deployment: The model is deployed as a scoring artifact to a software system and live scoring is made.
- Model monitoring: The model is monitored to detect whether the data fed into it changes over time compared to the distribution of data it was trained on. This is called data drift and usually leads to the decreased predictive power of the model. This usually triggers the need to retrain the model with a more current dataset and then redeploy the updated model. The model may also be monitored for other patterns, such as whether it is biasing decisions against a particular demographic group and whether malicious attacks are being made to try to cause the model to malfunction.
As mentioned, a key property in the workflow is the unknown number and sequence of iteration pathways taken between these steps before a model is deployed or before the project is deemed unsuccessful in reaching that stage.
The model building challenge – state-of-the-art models at scale
Let's, for now, define a large dataset as any dataset that exceeds your ability to build ML models on your laptop or local workstation. It may be too large because your libraries simply crash or because they take an unreasonable amount of time to complete. This may occur during model training or during data ingestion, exploration, and manipulation.
We can see four separate challenges of building ML models from large data volumes, with each contributing to a larger problem in general that we call the friction of iteration. This is represented in the following diagram:

Figure 1.3 – The challenge of model building with large data volumes
Let's elaborate on this.
Challenge one – data size and location
Enterprises collect and store vast amounts of diverse data and that is a boon to the data scientist looking to build accurate models. These datasets are either stored across many systems or centralized in a common storage layer (data lake) such as the Hadoop Distributed File System (HDFS) or AWS S3. Architecting and making data available to internal consumers is a major effort and challenge for an enterprise. However, the data scientist starting the ML life cycle with large datasets typically cannot move that data, once it becomes accessible, to a local environment due to either security reasons or high volume of data.. The consequence is that the data scientist must either do one of the following:
- Move operations on the data (in other words, move the compute) to the data itself.
- Move data to a high-compute environment that they are authorized to use.
Challenge two – data size and data manipulation
Manipulating data can be compute-intensive, and attempting to do so against insufficient resources either will cause the compute to fail (for example, the script, library, or tool will crash) or take an unreasonably long amount of time. Who wants to wait 10 hours to join and filter table data when it can be done in 10 minutes? What you might consider an unreasonable amount of time is obviously relative to the dataset size; terabytes of data will always take longer to process than a few megabytes. Regardless, the speed of your data processing is critical to reducing the sum time of your iterations.
Challenge three – data size and data exploration
Challenges of data size during data exploration are identical to those during data manipulation. The data may be so large that your processing crashes or takes an unreasonable amount of time to complete while exploring models.
Challenge four – data size and model training
ML algorithms are extremely compute-intensive because they step through each record of a dataset and perform complex calculations each time, and then iterate these calculations against the dataset repeatedly to optimize toward a training metric and thus learn a predictive mathematical pattern among the noise. Our compute environment is particularly pressured during model training.
Up until now, we have been discussing dataset size in relative terms; that is, large data volumes are those that cause operations on them to either fail or take a long time to complete in a given compute environment.
In absolute terms, data scientists often explore the largest dataset possible to understand it and then sample it for model training. Others always try to use the largest dataset for model training. However, accurate models can be built from 10 GB or less of sampled or unsampled data.
The key to proper use of sampling is that you have followed appropriate statistical and theoretical practices, and not that you are forced to do so because your ML processing will crash or take a long time to complete due to large data volumes. The latter is a bad practice that produces inferior models and H2O.ai overcomes this by allowing model building with massive data volumes.
There are also cases when data sampling may not lead to an acceptable model. In other words, the data scientist may need hundreds of gigabytes or a terabyte or more of data to build a valuable model. These are cases when the following applies:
- The data scientist does not trust the sampling to produce the best model and feels that each small gain in lift warrants the use of the full dataset.
- The data scientist does not want to segment the data into separate datasets and thus separate model building exercises, or the larger stakeholder group wants a single model in production that predicts against all segments versus many that each predicts against a single segment.
- The data is highly dimensional, sparse, or both. In this case, a large number of records are needed to reduce variance and overfitting to a training dataset. This type of dataset is typical for anomaly detection, recommendation engines, predictive maintenance, security threat detection, personalized medicine, and so on. It is worth noting that the future will bring us more and more data, and thus highly dimensional and sparse datasets will become more common.
- The data is extremely imbalanced. The target variable is very rare in the dataset and a massive dataset is needed to avoid underfitting, overfitting, or weighting the target variable from these infrequent records.
- The data is highly volatile. Each subset of data that is collected is unrepresentative of the others and thus sampling or cross-validation folds may not be representative. Time series forecasting may be particularly sensitive to this problem, especially when forecast categories are highly granular (for example, yearly, monthly, daily, and hourly) against a single validation dataset.
The friction of iteration
Model building is a highly iterative process and anything that slows it down we call the friction of iteration. These causes can be due to the challenges of working with large data volumes, as previously discussed. They can also arise from simple workflow patterns such as switching among systems between each iteration or launching new environments to work on an iteration.
Any slowness during a single iteration may seem acceptable but when multiplied across the seemingly endless iterations from the project beginning to failure or success, the cost in time from this friction becomes significant, and reducing friction can be valuable. As we will see in the next section, slow model building delays the main goal of ML in an enterprise – achieving business value.
The business challenge – getting your models into enterprise production systems
The bare truth about ML initiatives is that they do not really achieve value until they are deployed to a live scoring environment. Models must meet evaluation criteria and be put into production to be deemed successful. Until that happens, from a business standpoint, little is achieved. This may seem a bit harsh, but it is typically how success is defined in data science initiatives. The following diagram maps this thinking onto the ML life cycle:

Figure 1.4 – The ML life cycle value chain
The friction of iteration from this view is thus a cost. Time taken to iterate through model building is time taken from getting business results. In other words, lower friction translates to less time to build and deploy a model to achieve business value, and more time to work on other problems and thus more models per quarter or year.
From the same point of view, time to deploy a model is viewed as a cost for similar reasons. The model deployment step may seem like a simple one-step sequence of transitioning the model to DevOps, but typically it is not. Anything that makes a model easier and more repeatable to deploy, document, and govern helps businesses achieve value sooner.
Let's now continue expanding on a larger landscape of enterprise stakeholders that data scientists must work with to build models that ultimately achieve business value.
The navigation challenge – navigating the enterprise stakeholder landscape
The data scientist in any enterprise does not work in isolation. There are multiple stakeholders who become involved directly in the ML life cycle or, more broadly, in the business cycle of initiating and consuming ML projects. Who might some of these stakeholders be? At a bare minimum, they include the business stakeholder who funded the ML project, the administrator providing the data scientist with permissions and capabilities, the DevOps or engineering team members who are responsible for model deployment and the infrastructure supporting it, perhaps marketing or sales associates whose functions are impacted directly by the model, and any other representatives of the internal or external consumers of the model. In more heavily regulated industries such as banking, insurance, or pharmaceuticals, these might include representatives or offices of various audit and risk functions – data risk, code risk, model risk, legal risk, reputational risk, compliance, external regulators, and so on. The following figure shows a general view:
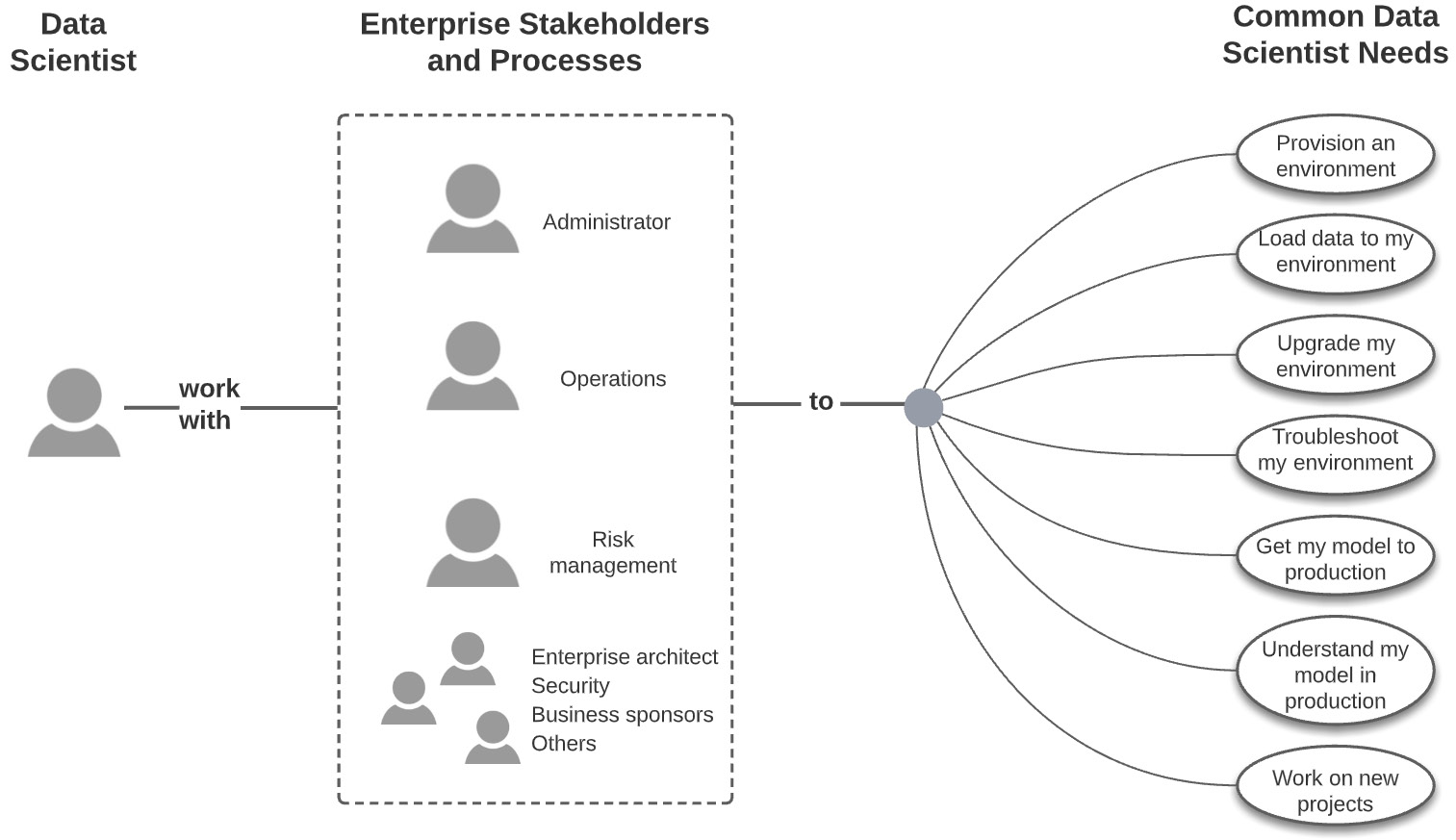
Figure 1.5 – Data scientists working with enterprise stakeholders and processes
Stakeholder interaction is thus complex. What leads to this complexity? Obviously, the specialization and siloing of job functions make things complex, and this is further amplified by the scale of the enterprise. A larger dynamic of creating repeatable processes and minimizing risk contributes as well. Explaining this complexity is the task of a different book, but its reality in the enterprise is inescapable. To a data scientist, the ability to recognize, influence, negotiate with, deliver to, and ultimately build trust with these various stakeholders is imperative to successful ML solutions at scale.
Now that we have understood the ML life cycle and the challenges inherent in its successful execution at scale, it is time for a brief introduction to how H2O.ai solves these challenges.
H2O.ai's answer to these challenges
H2O.ai provides software to build ML models at scale and overcome the challenges of doing so – model building at scale, model deployment at scale, and dealing with enterprise stakeholders' concerns and inherent friction along the way. These components are described in brief in the following diagram:

Figure 1.6 – H2O ML at scale
Subsequent chapters of this book elaborate on how these components are used to build and deploy state-of-the-art models within the complexities of the enterprise environment.
Let's try to understand these components at first glance:
- H2O Core: This is open source software that distributes state-of-the-art ML algorithms and data manipulations over a specified number of servers on Kubernetes, Hadoop, or Spark environments. Data is partitioned in memory across the designated number of servers and ML algorithm computation is run in parallel using it.
This architecture creates horizontal scalability of model building to hundreds of gigabytes or terabytes of data and generally fast processing times at lower data volumes. Data scientists work with familiar IDEs, languages, and algorithms and are abstracted away from the underlying architecture. Thus, for example, a data scientist can run an XGBoost model in Python from a Jupyter notebook against 500 GB of data in Hadoop, similar to doing so with data loaded into their laptop.
H2O Core is often referred to as H2O Open Source and comes in two forms, H2O-3 and Sparkling Water, which we will elaborate on in subsequent chapters. H2O Core can be run as a scaled-down sandbox on a single server or laptop.
- H2O Enterprise Steam: This is a web UI or API for data scientists to self-provision and manage their individual H2O Core environments. Self-provisioning includes auto-calculation of horizontal scaling based on user inputs that describe the data. Enterprise Steam is also used by administrators to manage users, including defining boundaries for their resource consumption, and to configure H2O Core integration against Hadoop, Spark, or Kubernetes.
- H2O MOJO: This is an easy-to-deploy scoring artifact exportable from models built from H2O Core. MOJOs are low latency (typically < 100 ms or faster) Java binaries that can run on any Java Virtual Machine (JVM) and thus serve predictions on diverse software systems, such as REST servers, database clients, Amazon SageMaker, Kafka queues, Spark pipelines, Hive user-defined functions (UDFs), and Internet of Things (IoT) devices.
- APIs: Each component has a rich set of APIs so that you can automate workflows, including continuous integration and continuous delivery (CI/CD) and retraining pipelines.
The focus of this book is on building and deploying state-of-the-art models at scale using H2O Core with help from Enterprise Steam and deploying those models as MOJOs within the complexities of enterprise environments.
H2O at Scale and H2O AI Cloud
We refer to H2O at scale in this book as H2O Enterprise Steam, H2O Core, and H2O Mojo because it addresses the ML at scale challenges described earlier in this chapter, especially through the distributed ML scalability that H2O Core provides for model building.
Note that H2O.ai offers a larger end-to-end ML platform called the H2O AI Cloud. The H2O AI Cloud integrates a hyper-advanced AutoML tool (called H2O Driverless AI) and other model building engines, an MLOps scoring, monitoring, and governance environment (called H2O MLOps), and a low-code software development kit, or SDK (called H2O Wave) with H2O API hooks to build AI applications that publish to the App Store. It also integrates H2O at scale as defined in this book.
H2O at scale can be deployed as standalone or as part of the H2O AI Cloud. As a standalone implementation, Enterprise Steam is not in fact required, but for reasons elaborated on later in this book, Enterprise Steam is deemed essential for enterprise implementations.
The majority of this book is focused on H2O at scale. The last part of the book will extend our understanding to the H2O AI Cloud and how H2O at scale components can leverage this larger integrated platform and vice versa.
Summary
In this chapter, we have set the stage for understanding and implementing ML at scale using H2O.ai technology. We have defined multiple forms of scale in an enterprise setting and articulated the challenges to ML from model building, model deployment, and enterprise stakeholder perspectives. We have anchored these challenges ultimately to the end goal of ML – providing business value. Finally, we briefly introduced H2O at scale components used by enterprises to overcome these challenges and achieve business value.
In the next chapter, we'll start to understand these components in greater technical detail so that we can start writing code and doing data science.