
A linked list is a data structure that allows the storage and manipulation of a variable number of nodes of data. Unlike a static array, the elements in a linked list are dynamically created. This enables the creation of a variable number of elements that are unknown at compile time. Because the elements are created at different times, they do not necessarily occupy contiguous regions in memory. Therefore, the elements need to be linked together, so each element contains a pointer to the next element. As elements are added or removed from the list, the pointer to the next node is simply adjusted.
The simplest data structure representing such a linked list would look similar to the following:
/* an element in a linked list */
struct list_element {
void *data; /* the payload */
struct list_element *next; /* pointer to the next element */
};
Figure A.1 is a linked list.

In some linked lists, each element also contains a pointer to the previous element. These lists are called doubly linked lists because they are linked both forward and backward. Linked lists, similar to the one in Figure A.1, that do not have a pointer to the previous element are called singly linked lists.
A data structure representing a doubly linked list would look similar to this:
/* an element in a linked list */
struct list_element {
void *data; /* the payload */
struct list_element *next; /* pointer to the next element */
struct list_element *prev; /* pointer to the previous element */
};
Figure A.2 is a doubly linked list.

Normally, because the last element in a linked list has no next element, it is set to point to a special value, usually NULL, to indicate it is the last element in the list. In some linked lists, the last element does not point to a special value. Instead, it points back to the first value. This linked list is called a circular linked list because the links are cyclic. Circular linked lists can come in both doubly and singly linked versions. In a circular doubly linked list, the first node's “previous” pointer points to the last node. Figures A.3 and A.4 are singly and doubly circular linked lists, respectively.
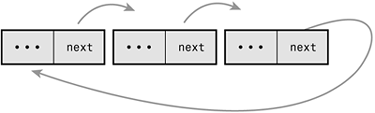

The Linux kernel's standard linked list implementation is a circular doubly linked list. Going with this type of linked list provides the greatest flexibility.
Movement through a linked list occurs linearly. You visit one element, follow the next pointer, and visit the next element. Rinse and repeat. This is the easiest method of moving through a linked list, and the one by which linked lists are best suited. Linked lists are usually not used when random access is an important goal. Instead, you use linked lists when iterating over the whole list is important and the dynamic addition and removal of elements is required.
Often the first element is represented by a special pointer—called the head—that makes it quick and easy to find. In a noncircular-linked list, the last element is delineated by its next pointer being NULL. In a circular-linked list, the last element is delineated by the fact that it points to the head element. Traversing the list, therefore, occurs linearly through each element from the first to the last. In a doubly linked list, movement can also occur backward, linearly from the last element to the first. Of course, given a specific element in the list, you can go back and forth any number of elements, too. You need not traverse the whole list.
The Linux kernel has a unique approach to traversing linked lists. When traversing a linked list, unless ordering is important, it does not matter if you start at the head element; in fact, it doesn't matter where you start at all! All that matters is that you visit each and every node. Indeed, we do not even need the concept of a first and last node. If a circular linked list simply contains a collection of unordered data, any element can be the head element. To traverse the list, simply pick an element and follow the pointers until you get back to the original element. This removes the need for a special head pointer. Additionally, the routines for manipulating a linked list are simplified. Each routine simply needs a pointer to a single element in the list—any element. The kernel hackers are particularly proud of this clever implementation.
Linked lists in the kernel, as with any complex program, are common. For example, the kernel uses a linked list to store the task list: Each process's task_struct is an element in the linked list.
In the old days, there were multiple implementations of linked lists in the kernel. A single, powerful linked list implementation was needed to remove duplicate code. During the 2.1 kernel development series, the official kernel linked-list implementation was introduced. All existing uses of linked lists now use the official implementation: All new users must use the existing interface, we are serious about this, do not reinvent the wheel.
The linked-list code is declared in <linux/list.h> and the data structure is simple:
struct list_head {
struct list_head *next
struct list_head *prev;
};
Note the curious name, list_head. The name takes a cue from the fact that there is no head node. Instead, because the list can be traversed starting with any given element, each element is in effect a head. Thus, the individual nodes are all called list heads.
The next pointer points to the next element in the list and the prev pointer points to the previous element. Thanks to the kernel's elegant list implementation with no concept of start or finish, you can ignore any concept of first and last element. Consider the list a big cycle with no start or finish.
A list_head by itself is worthless; it is normally embedded inside your own structure:
struct my_struct {
struct list_head list;
unsigned long dog;
void *cat;
};
The list needs to be initialized before it can be used. Because most of the elements are created dynamically (probably why you need a linked list), the most common way of initializing the linked list is at runtime:
struct my_struct *p; /* allocate my_struct .. */ p->dog = 0; p->cat = NULL; INIT_LIST_HEAD(&p->list);
If the structure is statically created at compile time, and you have a direct reference to it, you can simply do this:
struct my_struct mine = {
.list = LIST_HEAD_INIT(mine.list),
.dog = 0,
.cat = NULL
};
To declare and initialize a static list directly, use
static LIST_HEAD(fox);
This declares and initializes a static list named fox.
You should never actually need to play with the internal members of the linked list. Instead, just embed the structure in your data, and you can make use of the linked list interface to easily manipulate and traverse your data.
A family of functions is provided to manipulate linked lists. They all take pointers to one or more list_head structures. The functions are implemented as inlines in generic C and can be found in <linux/list.h>.
Interestingly, all these functions are O(1)[1]. This means they execute in constant time, regardless of the size of the list or any other inputs. For example, it takes the same amount of time to add or remove an entry to or from a list whether that list has 3 or 3,000 entries. This is perhaps not surprising, but still good to know.
To add a node to a linked list:
list_add(struct list_head *new, struct list_head *head)
This function adds the new node to the given list immediately after the head node. Because the list is circular and generally has no concept of first or last nodes, you can pass any element for head. If you do pass the “last” element, however, this function can be used to implement a stack.
To add a node to the end of a linked list:
list_add_tail(struct list_head *new, struct list_head *head)
This function adds the new node to the given list immediately before the head node. As with list_add(), because the lists are circular you can generally pass any element for head. This function can be used to implement a queue, however, if you do indeed pass the “first” element.
To delete a node from a linked list,
list_del(struct list_head *entry)
This function removes the element entry from the list. Note, it does not free any memory belonging to entry or the data structure in which it is embedded; this function merely removes the element from the list. After calling this, you would typically destroy your data structure and the list_head inside it.
To delete a node from a linked list and reinitialize it,
list_del_init(struct list_head *entry)
This function is the same as list_del(), except it also reinitializes the given list_head with the rationale that you no longer want the entry in the list, but you can reuse the data structure itself.
To move a node from one list to another,
list_move(struct list_head *list, struct list_head *head)
This function removes the list entry from its linked list and adds it to the given list after the head element.
To move a node from one list to the end of another,
list_move_tail(struct list_head *list, struct list_head *head)
This function does the same as list_move(), but inserts the list element before the head entry.
To check if a list is empty,
list_empty(struct list_head *head)
This returns nonzero if the given list is empty; otherwise it returns zero.
To splice two unconnected list together:
list_splice(struct list_head *list, struct list_head *head)
This function splices together two lists by inserting the list pointed to by list to the given list after the element head.
To splice two unconnected lists together and reinitialize the old list,
list_splice_init(struct list_head *list, struct list_head *head)
This function works the same as list_splice(), except that the emptied list pointed to by list is reinitialized.
Now you know how to declare, initialize, and manipulate a linked list in the kernel. This is all very well and good, but it is meaningless if you have no way to access your data! The linked lists are just containers that holds your important data; you need a way to use lists to move around and access the actual structures that contain the data. The kernel (thank goodness) provides a very nice set of interfaces for traversing linked lists and referencing the data structures that include them.
Note that, unlike the list manipulation routines, iterating over a linked list in its entirety is clearly an O(n) operation, for n entries in the list.
The simplest way to iterate over a list is with the list_for_each() macro. The macro takes two parameters, both list_head structures. The first is a pointer used to point to the current entry; it is a temporary variable that you must provide. The second is a list_head in the list you want to traverse. On each iteration of the loop, the first parameter points to the next entry in the list, until each entry has been visited. Usage is as follows:
struct list_head *p;
list_for_each(p, list) {
/* p points to an entry in the list */
}
Well, that is still worthless! A pointer to the list structure is usually no good; what we need is a pointer to the structure that contains the list. For example, with the previous my_struct example, we want a pointer to each my_struct, not a pointer to the list member in the structure. The macro list_entry() is provided, which returns the structure that contains a given list_head. It takes three parameters: a pointer to the given element, the type of structure in which the list is embedded, and the member name of the list within that structure.
Consider the following example:
struct list_head *p;
struct my_struct *my;
list_for_each(p, &mine->list) {
/* my points to the structure in which the list is embedded */
my = list_entry(p, struct my_struct, list);
}
The list_for_each() macro expands to a simple for loop. For example, the previous use expands to
for (p = mine->list->next; p != mine->list; p = p->next)
The list_for_each() macro also uses processor prefetching, if the processor supports such a feature, to prefetch subsequent entries into memory before they are actually referenced. Prefetching improves memory bus utilization on modern pipelined processors. To not perform prefetching, the macro __list_for_each() works just identically to this for loop. Unless you know the list is very small or empty, you should always use the prefetching version. You should never hand code the loop; always use the provided macros.
If you need to iterate through the list backward, you can use list_for_each_prev(), which follows the prev pointers instead of the next pointer.
Note that nothing prevents removal of list entries from the list while you are traversing it. Normally, the list needs some sort of lock to prevent concurrent access. The macro list_for_each_safe(), however, uses temporary storage to make traversing the list safe from removals:
struct list_head *p, *n;
struct my_struct *my;
list_for_each_safe(p, n, &mine->list) {
/* my points to each my_struct in the list */
my = list_entry(p, struct my_struct, list);
}
This macro provides protection from only removals. You probably require additional locking protection to prevent concurrent manipulation of the actual list data.