
Chapter 5: Problem Solving with One and Two Columns
5.3 Comparing a Continuous Column to a Categorical Column
5.4 Comparing Two Continuous Columns
In contrast to earlier chapters that have focused on describing data and producing graphs and maps, this chapter is about getting answers to your questions and making sense of your data in a condensed and rapid way. This problem-solving activity is often a process of trial and error, and it does not lend itself to brief descriptive steps. It takes thought and practice to do this well, but JMP is the perfect companion on this journey. This chapter helps you develop some appreciation and basic JMP skills in this problem-solving process.
Just as we discussed in the first chapter, JMP provides a navigation framework that is designed around the workflow of the problem solver. So, what do we mean by, “the workflow of the problem solver?” First, we are talking about the class of problems that are measurable or countable or that already have data that is written down. If you need assistance importing or accessing your data, see Chapter 2. By workflow, we are referring to the process by which you analyze data to arrive at some understanding or insight. This involves thinking about the questions that you may have of the data and recognizing how the questions translate to the menu items. Users who learn this find JMP to be a very intuitive partner in that problem-solving process.
In the problem-solving process, the answer to one question often prompts other questions. JMP is designed to help you answer these follow-up questions quickly, resulting in more rapid learning. Throughout this chapter, we use simple examples with scenarios that prompt questions you might want to answer. We show you how JMP’s menus translate to these questions and how the results help you answer them. Just as many real-world problems start with basic questions and understanding and evolve into more complex ones, we start off with the basics here as well.
The transformation of data into information is a process that involves a few basic JMP platforms that we introduce in this chapter, including Distribution and Fit Y by X. Distribution and Fit X by Y correspond to analyzing the characteristics of one and two columns, respectively, which is the scope of this chapter. The tools are found in the Analyze menu. Table 5.1 outlines the tool name, how many columns it supports, and its statistical terms. Don’t worry if you do not recognize the statistical terms and acronyms; we will present the basic ideas as we go. Appendix B describes the statistical terms and concepts in this chapter.
The organization of the items on the Analyze menu is the same framework discussed in Section 1.3. Within this framework, we cover just a few menu items, but in the process, you gain access to over 100 statistical methods.
Table 5.1 Tool Name, Columns Supported, and Statistical Terms
|
Analyze Menu |
How Many |
Statistical Terminology |
|
Distribution |
Single Columns |
One sample univariate methods, histograms, box plots, quantiles, summary statistics, distribution and more |
|
Fit Y by X |
Two Columns |
Bivariate, scatterplot, contingency, logistic, oneway ANOVA, nonparametrics and more |
|
Note |
|
If there is magic to JMP, the Analyze menu is it. The arrows in Table 5.1 indicate how the menu works. First and simple questions are answered with the Distribution platform and then further questions are often addressed with items farther down the menu like Fit Y by X until you get the answers that you need to solve your problem. Thus, you proceed from the simple to just the level of complexity that you need to answer your questions as you work your way down the Analyze menu. Sometimes, a discovery is made with a more complex method farther down the Analyze menu that leads you to confirm it with a simpler method back up the Analyze menu. |
JMP’s goal in using this menu framework is to expose you to powerful methods in a logical order that enables you to learn about your data progressively and rapidly. The order is built into the menu structure.
Figure 5.1 displays the first item on the Analyze menu. It is the Distribution platform. It’s first on the menu because this platform answers many basic questions that you should ask at the beginning of analysis of data.
Figure 5.1 Analyze Distribution

Another way to remember Distribution as a starting point is that the platform enables you to look at one column at a time and produces results for those individual columns. The technical terminology for statistical calculations for one column (or variable) of data is univariate one-sample statistics, meaning analysis of the properties of one variable represented as a sample. There are dozens of one-sample univariate statistics, and most are conveniently arranged in the Distribution platform.
Example 5.1: Financial
We will be using the financial performance data in the Financial.jmp data file to illustrate the analyses explored in this chapter. The data are from financial performance data for Fortune 500 companies selected from the April 23, 1990 Fortune magazine issue. You can find the data set at Help Sample Data Library Financial.jmp.
This data file includes columns for:
● Type: type of company
● Sales($M): yearly sales in millions of dollars
● Profit($M): yearly profits in millions of dollars
● #emp: number of employees at time of measurement
● Profits/emp: profits per employee in thousands of dollars
● Assets($Mil.): assets in millions of dollars
● Sales/emp: sales per employee in thousands of dollars
● Stockholder’s Eq($Mil.): stockholder’s equity in millions of dollars
Let’s start working our way through an analysis. We will use this exercise to practice asking the early questions of unknown data using the Distribution platform in JMP. Let’s open a data table on which to explore some analyses:
1. Select Help Sample Data Library (Figure 5.2).
Figure 5.2 Help Sample Data

2. Then select Financial.jmp. (See Figure 5.3.) Some financial performance data are displayed. (See Figure 5.4.)
Figure 5.3 Select Financial.jmp

Figure 5.4 Financial Performance Data

Let’s assume that your objective is to use this financial data to help you select company stock types to add to your portfolio. Your goal is to select stock types that will maximize the likelihood of positive returns and to use those returns to fund your favorite charity. We assume that:
● The most profitable companies will also tend to have the highest positive returns.
● You have enough data to make a reasonable prediction.
● Each row represents a type of company stock. You will need to select about 10 types of company stocks to sufficiently diversify your portfolio.
● Market conditions for the next six months will remain mostly the same for all sectors.
What questions will you ask in order to choose company stock types?
|
Note |
|
Time is an important variable to consider in particular with financial data. For the purposes of illustration, however, we have omitted this variable. |
Questions That Involve One Column
In this example, you might ask what range of company profits has existed for these stocks. Or, what has been the average (the mean) profit for the companies? How much variability (standard deviation) has there been? Are there some companies whose profits or losses are very extreme (outliers) relative to others? Are these extremes genuine or did someone make a mistake when entering the data (data quality)?
These are the types of questions you might ask of any set of data. These initial questions and many more are all answered with the Distribution platform from the Analyze Menu.
Using Distribution to Understand a Column of Data
Let’s perform a distribution analysis to answer these early questions for company performance.
1. Select Analyze Distribution.
2. Select Type and Profits($M) and click Y, Columns. A fully populated window should look like Figure 5.5.
Figure 5.5 Distribution Window

3. Click OK.
You are presented with a result (Figure 5.6). In this example, you can see several things that might capture your attention. There are six black dots at the high end of the range. There are the most profitable companies.
Figure 5.6 Distribution Report

You might also notice that some company types in the portfolio are more heavily represented than others. The size of the bars in the Type distribution graph indicates that Oil has the most companies and Beverages the least. The frequencies are shown in the table below the graph. Oil has 27 companies in this data while Beverages has only seven. The average profit for all of the companies is slightly more than $426 million.
|
Note |
|
Did you know that graphs and tables of numerical results appear together in report windows by design? People can learn faster when both graphs and numerical results appear together in the same context. This is a guiding principle of all JMP reports. |
Now, let’s try something new to help us answer some important questions.
4. Draw a box with your pointer around some of the highest profit entries. (See Figure 5.7.) Just take the pointer, left-click and drag down over the dots in the profit graph, and a rectangle appears.
Figure 5.7 Draw a Box to Show Highest Profits

5. Notice that as you draw the box, the round dots become dark.
6. Notice also the graph bars on the left for company type. Certain types of company bars have turned dark green, including Oil, Computer, and Beverages. This means that companies with the greatest profits are also those mostly associated with the oil sector. Notice the tiny slivers of Computer and Beverages that turned dark green, which indicates that a small number of highly profitable companies are in these two business sectors.
7. Now select the Window menu from the top and select Financial.
This brings the data table to the foreground. You can also select the data table icon from the lower right corner in the associated report window to bring the data table to the foreground. (See Figure 5.8.)
Figure 5.8 Select the Report Icon to Bring Data Table to the Foreground

|
Note |
|
Color references used in this chapter indicate what you will see on your screen using the standard default settings in JMP. |
|
Note |
|
Nearly all graphs that appear in report windows in JMP are tied directly to any other displayed graphs AND to rows in the corresponding data table. By selecting graphical attributes, you see those corresponding values represented in other graphs AND highlighted in the data table. |
8. Scroll down to row 35. (See Figure 5.9.)
Figure 5.9 Rows Selected

Do you see how the highlighted rows match those same points that you highlighted by drawing the box in the Distribution window?
|
Note |
|
The highlighting is what we refer to as JMP’s dynamic linking, which automatically links graphs to data, data to graphs, and graphs to other graphs. |
Because these highlighted rows show high profits, let’s mark them so that we can always find them.
9. Select Rows Colors, and then select the color red from the color palette. (See Figure 5.10.)
Figure 5.10 Select Red for Row Color

10. Select Rows Markers, and select the marker type X. (See Figure 5.11.)
Figure 5.11 Select Marker Type X for Rows

These rows in the data table are now marked red and appear with a marker type of X, as shown in the row number column of the data table. (See Figure 5.12.)
Figure 5.12 Rows Colored Red and Marked with X

11. Select Window and bring the Financial – Distributions of Profit($M), Type result to the foreground. Focus on the Distributions result for Profit($M). (See Figure 5.13.)
Figure 5.13 Top Profit Marked with Red Xs

The distribution graph for profit also shows the red X markers as well as a box plot. The top X represents a company with over $3.7 billion in profits. (See Figure 5.13.) On the bottom of the range is a very unprofitable company with approximately $1 billion loss (Figure 5.13).
If a box plot or any graphical or numerical result is unfamiliar to you, use the question mark tool (?) from the Tools menu to identify the item in question and locate the corresponding documentation about the item.
12. Select the question mark (?) from the toolbar. The pointer changes to a question mark. (See Figure 5.14.)
Figure 5.14 Question Mark Tool from Toolbar

13. Then, move the question mark on top of the item that you are unfamiliar with and click on that item. (See Figure 5.15.) In this example, it is the item next to the distribution graph.
Figure 5.15 Question Mark on Distribution

The section of the documentation associated with the outlier box plot appears automatically. (See Figure 5.16.) Don’t forget to scroll down, because sometimes the topic of interest is a little below where you landed in the documentation.
Figure 5.16 Help for Box Plots

|
Note |
|
Unfamiliar graphics, geometric shapes, and results are explained using the context-sensitive question mark tool. Just select the question mark tool (?) from the Tools menu and click on the part of the result that you want to learn about. You can learn statistics while you explore your data! |
Summary of 5.2: What You Learned from the Distribution Platform
By observing the distribution, you found that the range of profits for the companies extended from a very unprofitable company at approximately -$1 billion to the most highly profitable company at over $3.7 billion (Figure 5.13). Companies were mostly on the profitable side, however, and most companies had moderate profits.
You might have noticed that the average, or mean, profits for all listed companies was $426 million.
The distribution results indicated that the variability, or standard deviation, of profits was about $717 million.
You found that all the extreme values were on the high side. By identifying them, you determined that most of these companies came from the oil sector and a few came from other industry types. You also identified an unfortunately unprofitable company.
5.3 Comparing a Continuous Column to a Categorical Column
Building upon the Distribution platform, the answers to questions you asked about one column have motivated you to ask further questions about the relationship between two columns. For example, what might be the relationship of profits to other columns in the data table? In fact, you have already identified an interesting relationship between the company type and its profits using dynamic linking, as some types of companies are associated with higher profits. This visual relationship suggests something is happening with profits that includes more than just one column. There may be a relationship between at least two columns that we will explore in this section.
The second item under the Analyze menu is Fit Y by X. It is designed to explore relationships between one column and another column. These are sometimes called bivariate relationships (meaning relationships between two variables). You might have noticed a pattern developing for items under the Analyze menu. The first item is Distribution, which is useful for looking at one column at a time. The second item is Fit Y by X for looking at the relationship between two columns. Figure 5.17 provides a description of each menu item.
Figure 5.17 Analyze Menu Item Descriptions

Let’s continue with our example and perform a Fit Y by X analysis. We already suspect that there are interesting profit differences among the different company types, and we have discovered a few by just looking at one column at a time using the Distribution platform and dynamic linking. We will now formalize that inference.
The relationship that we want to explore includes the Profit($M) column and the Type column.
1. Select Analyze Fit Y by X. (See Figure 5.18.)
Figure 5.18 Select Fit Y by X

2. In the window (see Figure 5.19), select Profit($M) and click Y, Response.
Figure 5.19 Fit Y by X Profit by Type Oneway Analysis

3. Select Type and click X, Factor.
4. Click OK.
Before we continue with the example, let’s examine that last Fit Y by X window. We will focus on the preview or circled area. (See Figure 5.19.)
Notice that each modeling type has its corresponding icon (continuous, nominal, or ordinal, which are described in section 2.3). The modeling type of the column that you cast into a role determines the type of analysis that is produced. (See Figure 5.20.) In this case, we have selected Profit($M) for the Y, Response (the vertical axis), which is continuous, and Type for the X, Factor (the horizontal axis), which is nominal. The arrows in Figure 5.20 are a close-up view of the Fit Y by X window shown in Figure 5.19, which shows these selections. Where they intersect on the matrix indicates the type of analysis that will be produced; in this case, a oneway.
Figure 5.20 Oneway Analysis Illustration

For now, don’t worry about terms like oneway in the preview. If you want to learn about the result, you can place the question mark tool on the result after generating it. Just note that the picture previews are there so that you can get an idea of what types of analyses will be produced when you cast certain types of columns into Y and X roles within the platform.
When you click OK, a oneway analysis graph appears. (See Figure 5.21.)
Figure 5.21 Oneway Analysis Graph
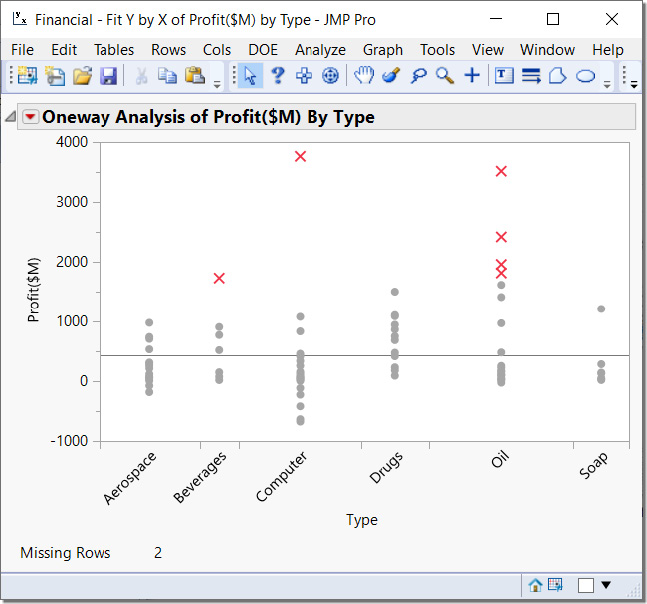
The Fit Y by X (two-column) analysis confirms what we started to observe earlier. We see that the highest profits have come from a mix of mostly oil companies, one computer company, and one beverage company. These are conveniently marked by Xs from a previous step.
|
Note |
|
Your selection of the most profitable companies might differ slightly from the selection shown here. This is okay. |
Based on the observed best performers among the company types, we might start asking more complex questions like these:
● Are there differences in profits among the company types?
● How big and in what direction (negative or positive) are these differences?
● Should I choose more companies from one particular company type than from another type?
These questions and others can be answered using Fit Y by X because they involve two columns. How? As you make selections from the choices in the Analyze menu, the types of questions you start asking at each step are anticipated for you.
You might notice the red triangle associated with the results that you have generated. (See Figure 5.22.)
Figure 5.22 Red Triangle

As we introduced earlier, red triangles anticipate questions that you might have at any stage of analysis and have been carefully placed on the report in the context of your analysis. Let’s use the choices on the menu for the oneway analysis to find out if there are differences in profits among company types.
You can already see some of these differences in the graph. Let’s further quantify the differences in profits by company type.
From the red triangle, select Means and Std Dev. (See Figure 5.23.)
Figure 5.23 Select Means and Std Dev

An additional table appears below your graph, and blue mean error bars and standard deviation lines appear on your graph. The blue lines on the graph correspond to mean lines, mean error bars, and standard deviation lines. These values also appear in the table as numbers. (See Figure 5.24.)
Figure 5.24 Means for Drugs and Oil

Using the table, we can now see that the highest average profits (mean) were obtained from the 12 companies represented in the drugs category. The second highest average profits were obtained from the oil category, and there were 26 companies represented.
Let’s review what we have learned so far. In Distribution, we learned that companies with the highest profits are likely to be in the oil category. From Fit Y by X, we learned that the highest average profits are found in the drug category and the next highest average profits are found in the oil category. Remember, you are trying to accumulate just enough knowledge to make your decisions. If you are keeping score, Oil is showing up as a good performer by at least two measures. The most extreme profits are coming from some of these oil companies and overall averages are also high for Oil.
Did you also notice the number of oil companies represented? This is another vote for Oil to be represented in our selection of company stocks because many highly profitable stocks are from this category. The risk associated with one oil company going down is hedged by having many profitable ones in the oil category.
|
Note |
|
This is true when the companies in the category are not highly correlated on the fundamentals. Seek professional advice when making investment decisions. |
If you are keeping score, Oil looks better by three measures now.
We don’t really have numerical measurements of range yet to help answer the question: “How big and in what direction (negative and positive) are the differences in profit between the types of business sectors?”
Where might we go to answer this question? Yes, it’s in the red triangle for the oneway result.
1. Select the red triangle next to Oneway.
2. Select Quantiles. (See Figure 5.25.) Quantiles are values that divide an ordered set of continuous data (from smallest to largest) into equal proportions. See “Quantiles” in Appendix B for more information.
Figure 5.25 Select Quantiles

A Quantiles table appears. This table appears in the context of your initial analysis, and box plots are added to your graph illustrating the quantiles. (See Figures 5.26a and 5.26b.)
Figure 5.26a Oneway Means and Quantiles

Figure 5.26b Oneway Means and Quantiles with Call-out Numbers

➊ The box encompasses the 25th through 75th percentiles.
➋ The whisker lines stretch out on the corresponding sides of the box to the last data point between the following values:
1st quartile - 1.5*(interquartile range)
3rd quartile + 1.5*(interquartile range)
➌ What type of company has the worst profit by examining the Minimum column? What type of company has the best profit in the Maximum column? Which has the lowest value for the Maximum column?
You can make the differences easier to see. Try this:
1. Right-click the Quantiles table.
2. From the submenu, select Sort by Column. (See Figure 5.27.)
Figure 5.27 Sort by Column

3. Select Minimum and click OK. (See Figure 5.28.)
Figure 5.28 Sort Column by Minimum

4. The Profit table now appears sorted by the Minimum column. (See Figure 5.29.)
Figure 5.29 Quantiles Sorted by Minimum

You can now see that the worst loss (or least profitable) is in the Computer category at
-680.4. Can you find the biggest profits in the Maximum column? Yes, it’s also in the Computer category at 3758. They are circled for you. (See Figure 5.29.)
Now you can start asking yourself about your risk tolerance. Review the oneway graph that you produced, the mean and standard dev, and the Quantiles table. If you are conservative, what types of companies would you select to assure profits? Wouldn’t you choose only companies that show no negative profits? Which ones are those? They are Drugs, Soap, and Beverages.
Higher profits appear in other categories, but more of those companies show higher variability and losses and, therefore, present more risk.
5. Finally, save the data table Finance.jmp. You will need this data table for the next chapter.
Summary of 5.3: What You Learned by Comparing a Continuous Column to a Categorical Column
You might have noticed that the highest mean (average) profits are found overall in the 12 companies in the drug category and the next highest mean profits are found in the 26 companies in the oil category.
You found that the biggest loser was in the computer category as well as the most profitable one.
You found that choosing company types depends on risk tolerance. If you are conservative, you might select Drugs, Soap, and Beverages. Higher profits might be achieved elsewhere, but they are in company types where there is higher variability or risk.
5.4 Comparing Two Continuous Columns
As shown in Figure 5.20, the Fit Y by X platform does different analyses depending on the modeling role of the columns entered into the Y and X roles in the dialog box. Section 5.3 examined the case where the column in the Y roles is continuous and the column in the X role is categorical. There, Fit Y by X invokes the Oneway platform for the analysis. In the case where both columns are continuous, Fit Y by X conducts a Bivariate analysis.
Continuing with use of the Financial.jmp data table, we can examine the relationship between Profit and Sales.
1. Select Analyze Fit Y by X.
2. Assign Profit to the Y, Response role and Sales to the X, Factor role.
3. Select OK.
The result shown in Figure 5.30 is a scatterplot of the data.
Figure 5.30 Bivariate Plot of Profit by Sales

The scatterplot shows what we might have expected. Higher sales seem to indicate higher profit. To define the relationship between profit and sales, you can fit a line to the data.
4. Click on the red triangle and select Fit Line. (See Figure 5.31.)
Figure 5.31 Select Fit Line from the Red Triangle Menu

This adds several tables of statistical information to the results. Concentrating on the first two, we see the equation of the line of fit and a summary of the fit (Figure 5.32).
Figure 5.32 Equation and Summary of Fit

The equation tells us that, within the range of sales in this data table, for each increase in sales of $1 million, we see an almost $47,000 increase in profits. (Note that 0.047 million is equal to 47,000.)
The equation also tells us that, for $0 in sales, we still expect almost $48,000,000 in profits. This intercept value is often not very interpretable when “0” falls outside of the range of expected values for sales, but it is important to helping the line fit the data well to make predictions in the range of sales values that are expected.
The Summary of Fit table shows us that 95 rows of data were used for this analysis and that the average profit is $426 million (Mean of Response). The RSquare statistic in the table is a measure of the fit of the line to the data. The RSquare shown here (0.708067) indicates that just over 70% of the variability in profits is explained by the sales. The closer the RSquare is to one, the more perfect the fit of the data to the line. In the next chapter we will introduce the use of more than one X variable in the regression model which can result in a better fit of the data and a higher RSquare.
|
Note |
|
In general, we never expect an RSquare statistic equal to one unless the data has been generated for teaching purposes. |
Examining the scatter plot shown in Figure 5.30 more closely, there appear to be a few companies with very high sales compared to the others. You might consider using the local data filter to exclude these points from the analysis and examine the effect of the exclusions on the equation of the line and the RSquare statistic.
5. From the red triangle, select Local Data Filter.
6. Select Sales as a filter column, then click on the + button to add it as a filter
7. Use your cursor to move the right blue line to exclude the companies with very high sales (over $40 billion) from the analysis. (See Figure 5.33.)
Figure 5.33 Bivariate Fit with Local Data Filter

Examine the differences between the linear equation and the RSquare for various setting in the Local Data Filter. For example, in Figure 5.33 you see that three companies have been excluded resulting in a steeper slope for the line and a much lower RSquare statistic. You might also use the Local Data Filter to examine the differences in the line for each of the Types of companies represented in the data.
Summary of 5.4: What You Learned by Comparing Two Continuous Columns
When using the Fit Y by X platform to compare two continuous columns, the simple linear regression analysis provides an equation for a line fit to the data. This equation provides a slope that defines the magnitude of the increase (or decrease) in the “Y, Response” column as the “X, Factor” column increases.
In this data, we found (as expected) an increase in profits as sales increased. We also discovered that the relationship might be defined differently if unusual observations (rows of data) are excluded from the analysis. We used the Local Data Filter to explore how the relationship changes as we include or exclude certain values. Finally, we considered, using our own common sense about what we need from our model, whether to include or exclude the extreme values and which equation to report.
This chapter has presented an approach to problem-solving that is unique to JMP. The approach underscores the progressive nature of problem solving that tends to build from simple descriptions of one column of data to relationships between two columns of data, leading to a better understanding of the data.
Learning about data using JMP tends to start slowly, increase rapidly, and then reach understanding. Also, the process does not go simply in one direction as you move from one column to two columns. As discoveries are made between two columns, confirmation and further analysis can be made by going back to simple one-column tools like Distribution.
Marking rows with colors and markers helps certain groups stand out in subsequent analyses. Visual identification with markers and colors speeds discovery and the effective communication of results.
Because many real-world problems involve multiple variables or columns, you will learn in the next chapter that JMP easily handles this increased complexity. We will build upon our example and the basic analyses introduced in this chapter to explore multivariable relationships. In the next chapter, we introduce several tools including the Partition platform, the Data Filter, and the Prediction Profiler to help you explore and discover deeper insights in your data.