
4
Enterprise Architecture and the DevOps Center of Excellence
This chapter introduces two orchestrators of the DevOps evolution and is divided accordingly into two main parts. We start with Enterprise Architecture (EA), outlining its overall value proposition for the DevOps evolution, and afterward we discuss the three layers of domain criticality, as well as their importance in the DevOps evolution, using examples. Continuing, we define the main alternative choices for platform modernization-facing incumbents by providing the business case and examples for each choice. Afterward, we shift focus to the importance of reference architectures in accelerating the DevOps evolution and we discuss the most decisive and dominant of these in the financial services industry. Closing the first part, we highlight the importance of establishing an EA assembly. The second part starts by discussing the value proposition of the DevOps Center of Excellence (CoE) and outlines the four potential roles it can have. The client engagement role is discussed in more length and is accompanied by an example. The chapter continues by providing tips and alternatives on how to staff and fund the CoE. It moves on to outline four different DevOps CoE use cases derived from four different incumbents and closes by proposing the three major life cycle steps of a successful DevOps CoE.
In this chapter, we’re going to cover the following main topics:
- Enterprise architecture
- DevOps Center of Excellence
Enterprise architecture
One of the main DevOps evolution orchestrators that incumbents use is EA. With the term EA, we refer to both a functional unit, as in a part of the organization dedicated to EA causes, but also a discipline, as in the frameworks and mechanisms supporting the required EA decisions and the direction that will both influence and enable the DevOps evolution.
What is the banking DevOps EA value proposition?
To some of you the answer is obvious, to some others maybe not. The EA value proposition is multidimensional and pivotal as it establishes some fundamental governance groundwork for the DevOps evolution, but also some frameworks to guide its direction and intelligence if you wish. The main responsibilities of EA, which are directly related to the DevOps evolution, are listed as follows:
- Identifying critical business domains and flow identification
- Defining the platform modernization strategy
- Establishing reference architectures
- Architecture assembly formation
- Business application and technological stack portfolio classification
The combination of these responsibilities and their corresponding outcomes provide some core elements of intelligence in a DevOps evolution, at relevance and in a multi-speed context. In the following sections, we will discuss all of the preceding responsibilities except the last one, to which we have dedicated Chapter 10, Tactical and Organic Enterprise Portfolio Planning and Adoption, combining this with service governance due to the close relation between them.
Defining the critical path of the banking portfolio
Your EA function will have neither the bandwidth nor the expertise to maintain its focus across your portfolio of business and technology platforms during the evolution. Bear in mind that an incumbent’s average portfolio has more than 2,000 business applications. As we will see in Chapter 10, Tactical and Organic Enterprise Portfolio Planning and Adoption, normally such portfolios are split into certain categories based on their criticality to the business. EA will focus only on the most critical ones, sharing the responsibility with the business IT units to define which they are. As with EA, the key stakeholders of your broader DevOps evolution will be unable to maintain their focus across the whole portfolio. Focus must be deployed tactically and intelligently. In this section, we will focus on what incumbents often call the portfolio’s critical path, defining this from a DevOps perspective.
Critical business domain/function
We define the incumbent’s business operations and activities as critical domains or functions when their discontinuity is very probable to result in the disruption of services essential to the incumbent’s revenue generation, the real economy, and the financial system’s stability, and could trigger supervisory involvement. Remember that the sample of incumbents represented in this book is of systemically important banks.
Did You Know?
An incumbent has to report its liquidity risk numbers to its main regulator daily. Failure to deliver the updated numbers for three days in a row results in a regulatory investigation.
There are certain eligibility criteria with which to classify criticality across the incumbent’s service portfolio and domains. The main ones are cited in the following list, together with examples:
- Revenue generation: For example, wealth management and loans
- Impact on real economy and reputation: Payments, savings, and deposits
- Regulatory impact: Group risk and liquidity reporting
- Risk hedging and funding: Profit and loss reporting
- Market share: Account opening and trading
- Partner impact: Open banking
- Enterprise shared services: Core technological infrastructure utilities (for example, a network)
The most critical (or core) domains that you typically find in an incumbent bank are outlined as follows:
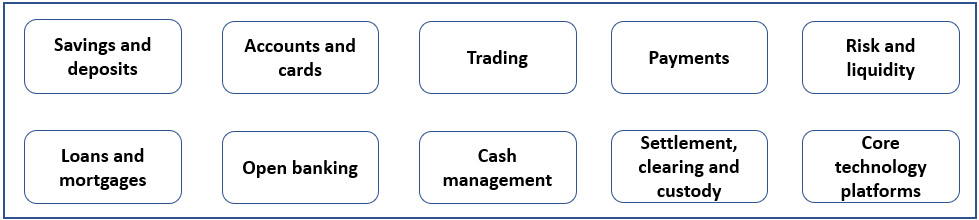
Figure 4.1 – Core business criticality domains example in banking
All incumbents, especially the systemically important ones, have their critical domains identified, as they are tightly connected to their business continuity, as well as the requirements of their regulatory and supervisory bodies.
Let me clarify something before we move on
It is important to clarify that with the term criticality in this book, we do not take the traditional approach focused on reliability and compliance, but also include the time to market, following the DevOps equilibrium we outlined in our DevOps definition. Innovating quickly with new mobile banking features is equally as important as ensuring the service’s stability and adequate compliance adherence.
From critical business domains to critical path business flows
The business criticality domains that we outlined are on criticality level 1. Drilling one level down into criticality level 2, we have cross-domain critical flows. With flows, we define a sequence of (cross-)domain activities that contribute to the execution of business unit, customer, and regulatory core-critical activities. To explain this concept, we will use two examples.
Critical path of the trade life cycle flow
The following is an illustration of a sample critical path crossing the trading, settlement, clearing and custody, and risks and liquidity domains. The flow consists of different IT applications, each of which applies its own business logic to the flow and utilizes certain technological components.
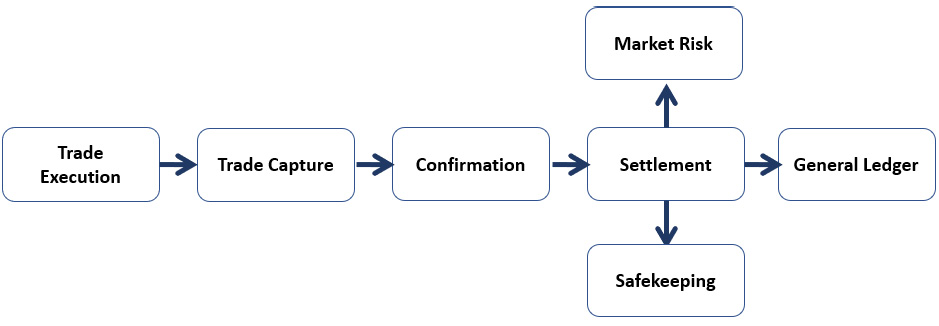
Figure 4.2 – Trade life cycle flow example
Failure in any step of the flow will result in an interruption to the trade life cycle and will result in a domino effect that, if severe, can spill across to other critical domains. The failure can be caused by a human mistake for which the IT applications do not have adequate error-handling capacities, or most often by a technology failure that can be as simple as latency on processing trade downstream, or something more severe, such as a network outage across the board.
Critical path of cross-border payments through mobile banking
A second example comes from a flow that crosses the saving and deposits and payments domains. As with the trade life cycle example, with payments, we also have several IT applications applying business logic and any interruption, small or fatal, will disrupt the flow.
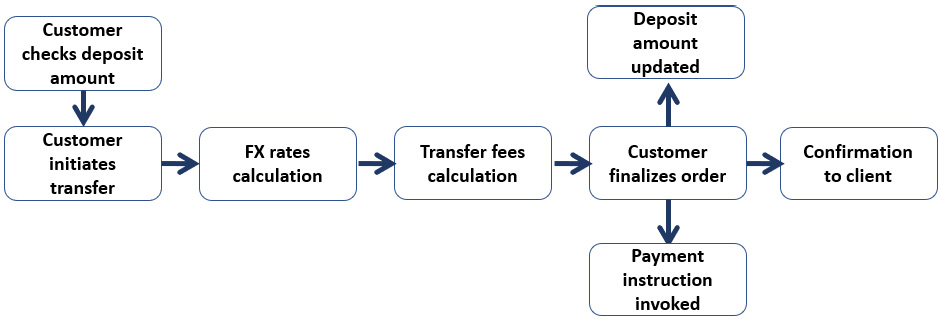
Figure 4.3 – Cross-border payment flow example
In both examples, a wide range of technological utilities is used by the IT applications, from servers to databases and from network to data transmission channels, which belong to the critical domain of core shared technology platforms.
From critical-path business flows to critical applications and services
Critical applications and services are the last level of criticality. Taking the example of the trade life cycle, the two most critical applications are those of trade execution and settlement, with the two most critical services as the following:
- CS 1: Equity trade deal capture service – trading execution system
- CS 2: Equity trade settlement service – settlement system
Why is defining these levels decisive for a DevOps evolution?
We intentionally drilled down into the criticality levels with examples as they are fundamental for the approach we take in this book. As we will see in later chapters, the criticality approach, apart from providing client, society, and regulatory DevOps centricity, will practically do the following:
- Support the DevOps evolution at relevance framework
- Define the tactical adoption candidates – that is, areas to front-run the evolution
- Define the scope of client engagements for the DevOps CoE
- Define candidates to front-run the Site Reliability Engineering (SRE) adoption (see Chapter 13, Site Reliability Engineering in the FSI)
- Define the portfolio prioritization for the compliance-as-code pilot areas (see Chapter 8, 360° Regulatory Compliance as Code)
- Visualize the interdependence across business domains when evolving DevOps at scale
Mastering the strategy of platform modernization
Incumbents are presently faced with what we call a strategic core legacy dilemma, while taking a tactical approach to platforms that are not necessarily classified as legacy but that do require modernization efforts to remain fit for purpose in the future.
True story and a tip
Once upon a time, we were discussing in a DevOps design authority how to deal with the legacy of our portfolio and whether it was indeed worth investing in DevOps engineering. Two interesting points arose during that discussion. First, we had to define the exact meaning of legacy. Was it only the applications written in Cobol and HPS, or also applications in C++, that we would decide to stop using as a technology? Second, who within our bank was actually holding the keys to the platform modernization strategy and could guide us? What if the mainframes were to stay for 20 more years and we had descoped them by mistake?
Your EA unit is the ideal place to anchor the creation of the master plan, undoubtedly in close collaboration with the business IT areas and core technology units. Obviously, one strategy will not fit every platform and budget, and skill set availability always has certain limitations. Nonetheless, there must be a strategic direction that will be followed at a minimum by the core strategic platforms. Typically, the strategic direction (which primarily concerns the core) offers three main choices for incumbents:
- Total replacement of the legacy core with modern platforms through strategic one-off initiatives. Most often the choices for this direction are sourced from vendors instead of self-built.
- Gradual modernization, keeping the legacy core but minimizing dependencies on business logic by reproducing it into modular microservices and decoupling the data dependencies through APIs. This approach is usually balanced between vendors and self-built solutions.
- New greenfield core based on cloud-native designs from scratch, architectural principles, and new modular business logic with gradual data migrations from the legacy core, which either partly stays or is decommissioned gradually. Most often, this results in the coexistence of self-built greenfield solutions alongside vendor-based brownfield ones.
Defining this strategic direction will strongly influence your DevOps evolution due to the domain and platform dependencies, but also guide you to be targeted when investing in new and long-lasting elements, especially regarding the engineering aspects. Examining the portfolio outside the core, you will discover several other business IT and core technology platforms with slightly more versatility regarding approaches to modernization. To shape their broader platform modernization strategy, banks have several options depending on their operating model, market concentration, risk appetite and profile, line-of-business demarcation, data strategy, platform criticality, and investment capital allocation.
Let us start by looking at the two less radical, safer approaches:
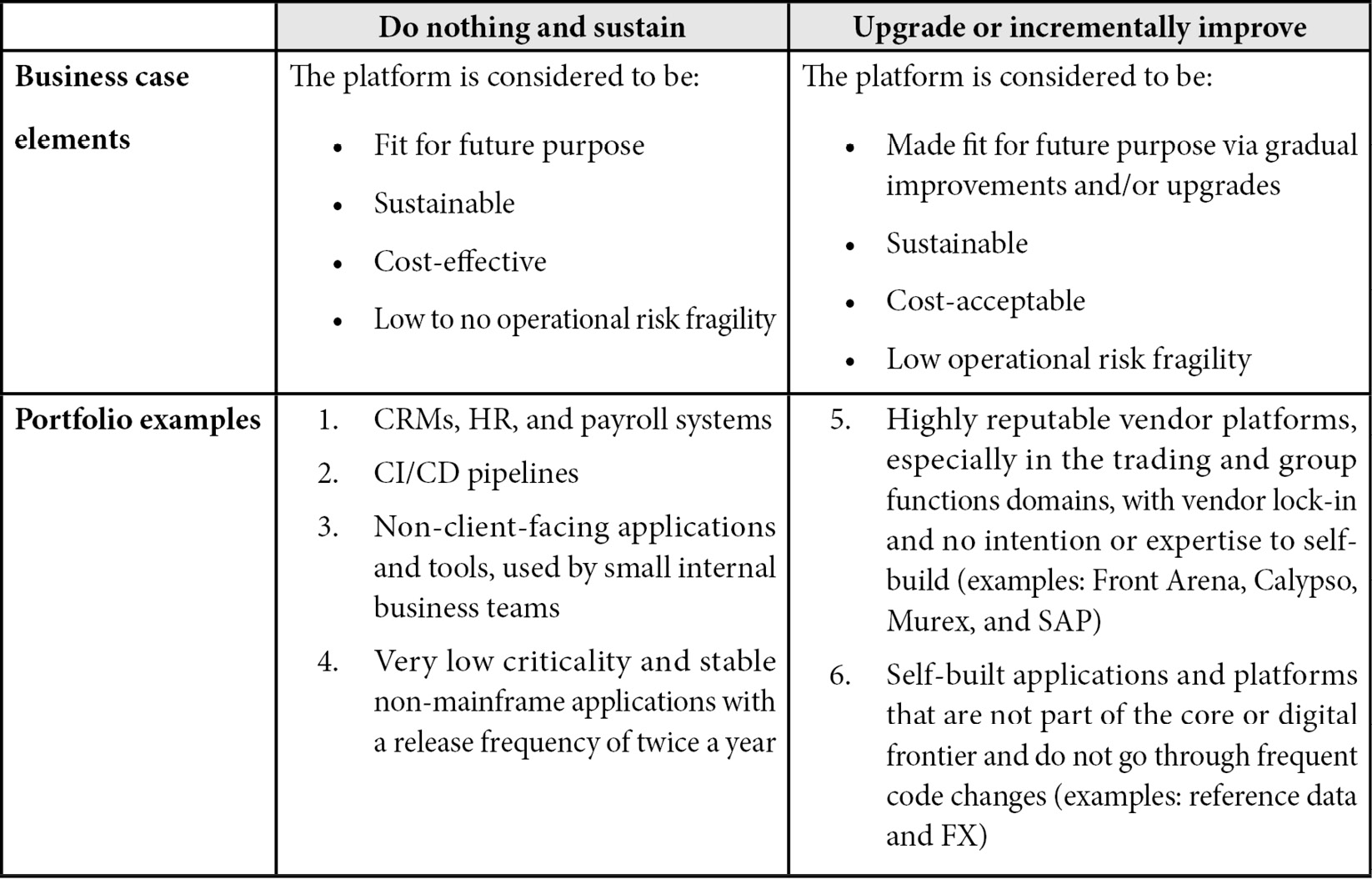
Table 4.1 – The “Do nothing and sustain” and “Upgrade or incrementally improve” approaches
Let’s move on to some more radical approaches that are effort-, risk-, and capital-intense:
Table 4.2 – The “Refactor and/or decouple” and “Full replacement, consolidation, or divestment” approaches
“How are these approaches linked to the DevOps 360° enterprise evolution?” you might wonder. The answer is simple – you need to be forward-looking and targeted on your evolution, especially on the engineering aspects of it. You will not invest heavily in DevOps engineering for a platform that you only plan to sustain, or that will be decommissioned in a year. At the same time, you might find limited DevOps engineering scope in a vendor platform, of which you do not own the code base and you just upgrade; plus, in most scenarios, such vendor platforms provide out-of-the-box observability capabilities, for instance. You need to have a plan for how your portfolio’s modernization is to evolve. Of course, you will never have perfect evolution data across your business, and your technological portfolio and plans will always be changing, but you will certainly have a fair picture of the direction you are to take, at least in your core domains.
Expect the Unexpected
Twice in my career, modernization plans have been changed and to some extent delayed, impacting the DevOps transformation. The first was due to a major organizational line-of-business change; the second was due to a restructuring of the firm’s legal entity. Things happen!
The reference architecture proposition in banking DevOps
Reference architectures have in recent years been very relevant and foundational to DevOps evolutions. Scaling fast and accelerating on an enterprise level requires recipes for adoption to be available and reusable. For these reference architectures, we define solution architectures and designs, which are provided as ready-to-use templates that can be reproduced, and may solve architectural challenges that someone else within your organization or in the industry solved before you. They promote a common vocabulary (remember the DevOps lexicon?) and support simplicity and standardization in both the business technology domains and core technological platforms. In this section, we will outline some of the main reference architectures that we propose to incumbents to define based on the latest industry trends.
The extended value proposition of reference architectures on DevOps evolutions
We have already mentioned simplicity and standardization, but the extended value proposition of reference architectures for banking is much larger and multidimensional:
- Streamlining digital customer journeys within and outside the bank
- Interoperability efficiencies across the ecosystem
- Harmonious plug ‘n’ play accelerated portfolio modernization
- Reusability of DevOps engineering frameworks and solutions
- Compliance, reliability, and security built in by design
- Compliant hybrid multi-cloud solutions
- Shared service integration models across the DevOps ecosystem
- Market experimentation and speedy delivery of new products and services
As can be easily understood, all the preceding aspects can directly or indirectly accelerate the DevOps enterprise evolution. Let us now outline some of the reference architectures that we consider to be of great importance to the DevOps enterprise evolution journey of an incumbent bank.
From monolithic to distributed modular microservices
A hot industry trend is the modernization and re-factoring of tightly coupled (monolithic) applications and platforms via domain-driven design principles, toward distributed architectures based on independent business logic microservices, packaged and deployed as containers. This involves the utilization of infrastructure-as-code provisioning independent of CI/CD pipelines and observability perspectives, using APIs for data transmission and overall fundamental cloud-native capabilities.
Enterprise message buses and communication layers
A domain of high focus for incumbents and closely related to distributed architectures is the domain of real-time and asynchronous data processing. Striving to move away from tightly coupled messaging queues and scheduled batch jobs and toward enabling dynamic interoperability with legacy and modern data sources, decoupling data dependencies, and increasing operational resiliency and observability are often requirements of clients, lines of business, and regulators. Yes, indeed, several regulatory standards around real-time data processing and transparency, especially in the payments and trading domains, have been developed in recent years. Enterprise message buses and communication-layer technologies gain ground as part of platform modernization journeys, replacing old transmission spaghetti solutions.
Composable banking
The term composable banking is used in the industry to refer to the ability of composability enabled by banking platforms, which provides the opportunity to select and compose components in various combinations to satisfy specific requirements. Composability is different from modularity, especially in core banking platforms. While in core banking, modularity indicates the extension of business logic from the core to individual predefined components, composability indicates the ability of the business logic extension to dynamically remove or add components that external partners can integrate with. Think of modularity like pieces of a puzzle brought together, while composability is more like Lego bricks brought together. Composable banking can create opportunities for incumbents to expand fast in new markets, with new customized products and services, reducing the build and maintenance overhead and supporting clients to personalize their journeys and service consumption, while further integrating with the Fintech ecosystem. Composable banking reference architectures are considered to be the industry’s future, especially for incumbents conducting regular M&A activities, as they provide patterns for plug ‘n’ play solutions to existing portfolios. Composable banking reference architectures are also applicable in cases where incumbents form new ventures by decomposing certain parts of their portfolios with the intention to recompose them under a separate legal entity, with its own independent business model.
Interoperating in one single DevOps technological ecosystem
As we will see later in the book, for various reasons, an incumbent will almost never be able to achieve perfect standardization and harmonization across its DevOps technological ecosystem. Some teams will keep utilizing their home-grown observability stacks, some others will not move to your common container platform and will keep conducting their own Docker image vulnerability scans, while others will keep their own CI/CD pipeline backbone but will migrate to the central open source scanning and code quality tools. When enabling interoperability across a hybrid technological ecosystem and balancing between home-grown and common core solutions, reference architectures can be proven silver bullets.
Greenfield banking
Greenfield is the new black in the industry without a doubt. Greenfield banking is gaining rapid momentum, mostly in the mobile banking, payments, and trading domains, and is seen by incumbents as a new business model that can support the independence of new digital services and products from legacy constraints, whether these are related to technology, data, processes, policies, or infrastructure. Through greenfield, banks can launch new products and services to various markets and regions more quickly, ensuring a full customer digital experience at a lower cost, while building the respective services and infrastructure under cloud-native principles from day one. However, building a greenfield bank is not as simple in reality as it sounds. The decoupling and demarcation of responsibilities from the legacy incumbent bank need to be carefully designed around five domains in particular:
- Data transmission, management, and synchronization
- Business logic integration to the core (if applicable)
- Dependencies on core infrastructure; landing zones
- Security policies
- Compliance
There are also scenarios for certain products and services where pure greenfield is not possible and a balance between green and brown is required. For all these reasons, reference architectures can provide predefined and proven designs to decode the greenfield landscape.
Public cloud adoption and migration
Most incumbents are well into their public cloud journey, or actually their multi-cloud journey, to be more precise. Business requirements, the plurality of public cloud solutions and capabilities, a strong focus on PaaS (over a traditional focus mostly on IaaS and SaaS), strategies to avoid vendor lock-in, and continuously evolving regulatory requirements can make the public (multi-) cloud adoption strategy an academic exercise. Reference architectures can support the optimization of the public cloud model choice and journey for candidates, as well as educate them in advance on the modernization journey and operating model changes that need to be undertaken to derive the most from the public cloud efficiencies. Reference architectures are everywhere in the public cloud journey, from industry-specific vendor patterns to proven solution designs, and from clarity on vendor due diligence to the practical adoption of certain PaaS capabilities such as analytics and machine learning. Moreover, the utilization of reference architectures can support the building of the public cloud business case and ensure alignment on the foundational capabilities that need to be established.
The most typical reference architectures found in the industry are as follows:
- Data center offloading through IaaS
- Hybrid cloud for resource-intense risk and liquidity calculation engines and models
- Mobile and online banking, as well as trading platform frontend migrations
- Big data and machine learning PaaS working on predictive customer analytics
- Enterprise message buses’ and operational data storage's PaaS
- Greenfield digital banking and payment gateways
- Provisioning of CI/CD pipelines and observability tools
Going further in the EA value proposition
There are further domains where the DevOps evolution can be supported by EA:
- Architecture design assessments and compliance: Assess certain architectures based on pre-defined criteria and accordingly propose improvements
- Cloud-native assessments: Set the standards and conduct assessments on platforms’ public cloud migration eligibility
- New platform due diligence: Supports the assessment of future fit for purpose
- Incremental and iterative architectures: Coach business IT and core technology teams on incremental, continuous, and iterative architectural evolution practices
- Technology menu: Defines the catalog of pre-approved technologies that the business IT and core technology teams can consume
- DevOps adoption application portfolio classification: Supports the portfolio classification based on non-functional parameters such as business criticality and impact
The EA assembly
On governing and collectively coordinating the EA work, we propose that you establish an EA assembly with members from your EA unit and solution design architects from your business IT areas and also from the core technology units. Their responsibilities can include the following:
- Alternative dispute resolution in case of architectural approach disagreements
- Architectural design reviews for common platforms strategic to the DevOps evolution solution
- Approval and maintenance of reference architectures
- Approval and maintenance of architectural standards and frameworks
- Portfolio modernization and classification decisions
As we discovered in the preceding section, the value proposition of EA for DevOps evolutions is solid, foundational, and multidimensional, while not so obvious. We will now move on and discover the value proposition of the DevOps CoE.
DevOps Center of Excellence
CoEs have become a mainstream industry approach in recent years to establish, enable, and orchestrate DevOps adoptions. A DevOps CoE is most often perceived and enabled as a function where rare DevOps experts are concentrated, aiming to enable organizational DevOps excellence. DevOps CoEs have various operating models without a standard shape but nonetheless with some commonalities around proven practices. This chapter discusses core aspects of DevOps CoEs, as well as proven practices, by comparing four different use cases from incumbent banks.
What is the value proposition for the CoE and its potential roles?
A DevOps enterprise evolution is a demanding endeavor. Legacy, culture, capability fragmentation, lack of expertise, leadership misalignment, multi-dependencies, and “Trust me, I’m an engineer” arguments will all raise barriers and can even generate adverse effects moving you toward further DevOps complexity instead of harmony. You must establish some functions that will keep the big picture together while orchestrating and facilitating the evolution, ensuring the deployment of DevOps expertise and excellence. In this section, we will discuss the various roles and respective value propositions of DevOps CoEs.
The DevOps enterprise evolution maestro
When defining your DevOps 360° operating model and adopting it at an enterprise level, your organization needs to get into almost perfect synchronization like a well-trained orchestra. Your various functions and stakeholders need to be orchestrated in order to achieve the most harmonized and synchronized DevOps tune. The DevOps CoE can act as the maestro, setting the rhythm and facilitating the journey toward DevOps alignment and harmony based on the definition of your new model. This orchestration involves the Head of the DevOps CoE coordinating the daily workstream operations, and the CoE members having strong representation in the DevOps design and advocacy group defining the future state, leading the prioritization of capability enablement across the DevOps technological ecosystem, and driving capability launches and adoption plans, but primarily getting everyone to align on a common vision through a broad coalition. Your DevOps CoE is the function that brings the pieces of the DevOps model together, while also bringing your people together and guiding them.
The DevOps CoE as the owner of the 360° operating model and DevOps governor
Imagine you have been through your evolution: you have created your brand-new DevOps 360° operating model and have started enabling its various pieces, while adopting it in parallel in certain areas. Your model will not stay steady, and you have to make sure that continuous evolution is applied to it. Your internal context and business strategy will evolve, your regulatory environment will probably tighten, digitalization will further disrupt your capabilities, new cloud services will become available, and your business units will become more aggressive. Obviously, you will have to evolve the model collectively as an enterprise and based on domain demarcation and expertise, but someone still needs to own the big picture. The DevOps CoE is the natural place for the complete model to be anchored and owned. Now, let me make sure that I am not misunderstood. Ultimately, the model will be owned by your COO, who is responsible for the operations of the organization, leads the business and technology lines and is the main counterpart of the regulator. Also, the several different parts comprising your model will be owned by the various DevOps stakeholders as appropriate. Now, you cannot expect your COO to ensure the model’s continuous evolution and integrity, nor the vast number of stakeholders contributing to the model to self-coordinate on keeping the big picture together. As the CoE will also naturally own parts of it anyway, we propose the CoE also having the overall responsibility of ownership to ensure that the model’s capability demarcation across stakeholders is clear and respected, that any major changes to it are centrally discussed and approved, and that there is a continuously evolving vision. The rest of the stakeholders will have accountability for the model sub-domains they own.
With the role of the internal DevOps governor, the CoE is by no means to play DevOps police, but to support the resolution of DevOps evolution disputes and provide model adherence guidance. For instance, some major vendor applications that your business IT teams use come with CI/CD and observability capabilities already embedded. The respective teams can raise a request to the DevOps CoE to get approval to utilize those capabilities, such as avoiding the central CI/CD pipeline, for example. Or a team might be uncertain about the difference between using AppDynamics or Prometheus for monitoring, with both being standard core offerings. The CoE should be able to guide that team to take the optimal decision.
The DevOps CoE as a (technological) capability provider
In this role, the DevOps CoE is responsible for providing certain technological and conceptual capabilities across the DevOps technological ecosystem that will support the DevOps evolution. They can span from technological features (CI/CD pipelines) to processes (open source scanning vulnerability remediation management) and from proven practices (backup and restoration of MongoDB) to policies (static code quality). As we will see in the coming chapters, the complete DevOps capability anatomy is quite complex and requires a strong mandate and domain expertise. Therefore, it is considered irrational and inadvisable to offload a large number of those capabilities to the CoE. Instead, we propose you strive toward domain-specific demarcation across your organization.
In industry adoptions, you will typically find DevOps CoEs primarily owning and offering the central and common technological and framework capabilities of CI/CD pipelines as a service. This is because they are perceived to be the core technological backbone of DevOps, as well as due to the incorrect perception that DevOps and CI/CD are the same thing. Let us not delve further into this fallacy as we have already outlined the DevOps definition used in this book. On top of CI/CD capabilities, we often find DevOps and cloud CoEs merged into one, offering further private cloud services and opening the path for the consumption of public cloud services. Whether or not a CoE is positioned to offer technological capabilities, it will have to be involved in keeping the DevOps technological ecosystem tightly together. In this chapter, we will not discuss this potential CoE role further, as we will get back to it later in the book in the chapter dedicated to the DevOps technology ecosystem as a service, where platform teams will be discussed in detail.
The DevOps CoE as a tactical adoption enablement partner
The last role that we typically observe in the industry is that of tactical adoption-enablement partners. Through this role, the DevOps CoE members are embedded in to either the business IT or technology utility areas and support their DevOps evolution capability enablement. The meaning of tactical in this context is that those areas are of high importance to the business and the benefits of their DevOps evolution can have a significant positive impact, which can potentially be maximized by other parts of the organization. You will often find these engagements in client-facing digital services domains, which are linked to revenue, competition, regulatory demand and reputation, or strategic DevOps technological utility areas, such as public cloud and core infrastructure services.
The engagement of the CoE’s members in the tactical adoption areas is characterized by formal agreements and by becoming a fully integrated part of the daily operations and strategic direction of the team they support. It is advisable to combine the CoE services with 360° evolution packages in order to provide a more targeted, complete, and interrelated engineering and advisory approach. You should not engage with single IT applications, but with whole domains or critical flows.
Your main two offerings can be as follows:
- Engineering services: Hardcore hands-on DevOps engineering evolution
- Advisory services: Consulting, observing, coaching, deputing, and guiding
The resulting detailed service catalog could look like the following example:
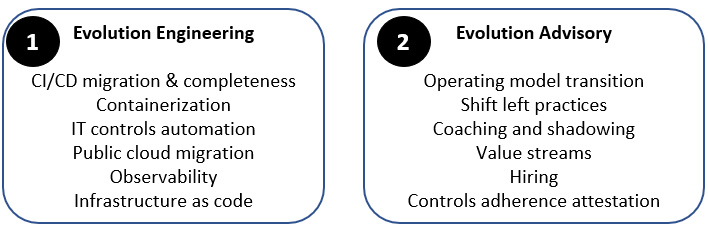
Figure 4.4 – CoE engineering and advisory services catalog example
Ideally, around the two pillars of your service offering you should build dedicated squads or pods of expertise from which you select people based on the objectives of your engagements. Note that a tactical engagement does not mean resource augmentation used to fill in skill gaps and getting consumed by business-as-usual activities, but scaled teams focusing on hardcore DevOps implementations that do not go after the land-and-expand tactic, but evolve, hand over, and move on.
Tactical adoptions are a golden opportunity for the CoE and the organization for the following reasons:
- They allow the collection of DevOps market insights into the DevOps evolution progress and state from both the business IT teams and infrastructure utilities.
- Hands-on support for the promotion of the DevOps 360° operating model and corresponding capability standardization, and feedback on improvements, applicability, and relevance.
- Cross-organization solutions can be implemented, creating success stories that can encourage others, allowing important alliances to be built and economies of scale to be achieved.
- Enabling a variety of career advancement paths and options for the CoE’s people, which can support talent retention.
What are the eligibility criteria when determining which tactical engagements to go for? We partly covered this earlier in this chapter when discussing criticality, but we will discover more in Chapter 10, Tactical and Organic Enterprise Portfolio Planning and Adoption, later in the book.
An example of getting the most out of your service catalog
Good deals make good partners, hence it is important to establish a formal agreement, ensuring the right investment by the CoE, solid preparation of the client, and a mutual and transparent understanding of the objectives and benefits to be realized.

Table 4.3 – Sample engagement template
In our hypothetical engagement called Market and Credit Risk DevOps Acceleration and Compliance, five CoE members were engaged. Aurimas, Michal, and Alex provided engineering services such as the migration of the shadow IT ELK instance to the common core cluster and the implementation of synthetic monitoring, the containerization of microservices, and the migration from Docker open source to an OpenShift central core. They also achieved the migration from the shadow IT Azure DevOps instance to the central one and made a shift toward a GitOps approach. In this scenario, from the central platforms mentioned, the DevOps CoE offered Azure DevOps and ELK as a service. So, this was a great win for the CoE as they increased their client coverage, promoted standardization in line with the new model, and passed direct feedback to the CoE’s platform segment team on potential enhancements through their observations of the engagement.
In parallel, Tomasz and Mario observed the operating model of the client team and provided suggestions on proven practices around completing the implementation of the SDLC controls and shifting operations left, as well as how to register their control adoption process in the service registry mechanism and how to use concepts such as error budgets to balance innovation and reliability on the product backlogs. Such engagements provided both engineering solutions and advice, while increasing the utilization of common platforms and fulfilling DevOps evolution governance objectives. This is where the return on investment is maximized both from the perspective of tangible (such as standardization and new engineering capabilities) but also intangible (such as new ways of working and governance) results for the CoE, the client, and the broader DevOps evolution.
Staffing and funding the CoE
Excellence can only be built by excellent and empowered people who combine strong domain experience and expertise and a combination of soft and hard skills. Important considerations on staffing are as follows:
- Strategically move some of the very best of your organization’s DevOps people to the CoE, either permanently or temporarily.
- Open up either for volunteers who might be interested in temporarily working for a function that has a broad organizational role, or people who might want a career change. This is a good way to maintain talent in your organization.
- Hire or incubate Π-shaped profiles. The CoE people must be fluent in the broad DevOps picture (horizontal) and have specialization in two domains (vertical).
- Hire software engineering profiles as well, not only DevOps engineering-oriented ones.
- Use a blend of internal and external hiring, so you mix organizational context insights with how DevOps is done elsewhere inspiration.
- Do not go the manage services way when scaling fast.
- Grant the CoE a hiring wildcard for periods when hiring freezes are imposed.
You need to continuously ensure that the CoE is funded, and its operations will not be disturbed by budgetary issues. The funding can be ideally addressed through four mechanisms:
- A client pot from multiple business IT and technology teams as part of the tactical adoption, with these teams contributing equally to fund the CoE from their improvement budgets.
- A DevOps evolution pot or a large compliance or digitalization program.
- Your own CoE budget, established through the annual maintenance budget cycles.
- Pay as you use: The clients pay for the services as per their consumption.
Four incumbent banks – four different use cases
There is no silver bullet for establishing a DevOps CoE but traditionally, incumbents have been pretty creative, following different approaches. In this section, we will look into four different use cases across a variety of DevOps CoE adoptions and will discuss what worked well and what didn’t in each case. As we cannot exhaust all aspects of a CoE’s operating model and topologies, we will focus on the following parameters that we consider the most important:
- DevOps operating model ownership
- Core CI/CD capabilities ownership
- Client engagement services
- Level of centralization
- Design motivating factor
Use case 1 – the three angles modus operandi CoE
The first use case is characterized by the following parameters:
- DevOps operating model ownership: DevOps CoE
- Core CI/CD capabilities ownership: DevOps CoE
- Client engagement services: Available and rotational
- Level of centralization: Highly centralized
Design motivating factor: The logic behind this decision was that a single unit should hold the keys to the DevOps operating model, support the flagship tactical areas of the organization by adopting the model in a sequence of waves, and offer the core CI/CD pipeline as a service. The aim of this is to ensure that the technological backbone of the adoption was close to the model and its future development would be closely influenced by the flagship adopters. The tactical adoption members of the CoE rotated between lines of business and were not dedicated to those lines of business. The CoE was located under the group technology unit, as the DevOps evolution was driven by the group’s CIO:
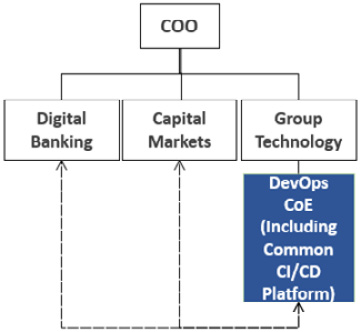
Figure 4.5 – The three-angles modus operandi CoE
The following table shows the pros and cons:
Table 4.4 – Pros and cons of the three angles modus operandi CoE
Use case 2 – the model owner and tactical adoption enabler CoE
The parameters characterizing the second case are as follows:
- DevOps operating model ownership: DevOps CoE
- Core CI/CD capabilities ownership: Platform teams, outside the DevOps CoE
- Client engagement services: Available and specialized
- Level of centralization: Highly centralized
Design motivating factor: The logic behind this decision was that a single unit should hold the keys to the operating model and support the flagship tactical areas of the organization in adopting the model, while building business domain specialization. The latter was done with the intention of intensifying and accelerating the evolution in those areas and they eventually absorbed the CoE people. The CoE did not own any technological capabilities as the decision was made to bring the broader DevOps technological ecosystem under a single unit, called Common Platforms. The CoE was under the CIO’s organization, based on the evolution’s ownership:
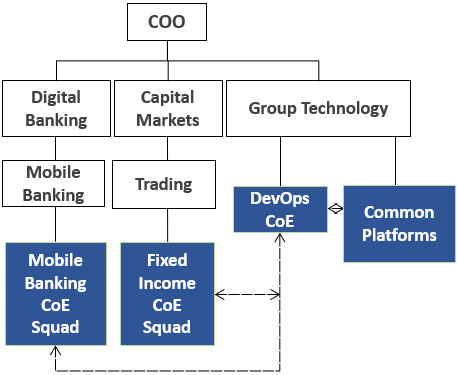
Figure 4.6 – The model owner and tactical adoption enabler CoE
The following table shows the pros and cons:
Table 4.5 – Pros and cons of the model owner and tactical adoption CoE
Use case 3 – the enterprise CoE as part of a broader DevOps community of practice
The third use case we will discuss is quite a hybrid one. The parameters characterizing this use case are as follows:
- DevOps operating model ownership: Enterprise DevOps and business IT CoEs
- Core CI/CD capabilities ownership:
- Enterprise DevOps CoE – group technology CI/CD
- Business IT DevOps CoEs – own CI/CD pipelines
- Client engagement services: Not available
- Level of centralization: Highly decentralized
Motivating factor: Using a decentralized and hybrid setup, an enterprise CoE was created with ownership of the DevOps enterprise operating model and only the CI/CD used by the group technology engineering teams, without offering client engagement services. Each line of business had its own DevOps CoE responsible for local enterprise DevOps operating model adherence, but with exceptions, meaning they could follow their own path with exceptions granted by the enterprise CoE. The business IT DevOps CoEs handled their own internal client engagements, as well as owning the lines of business’ common CI/CD pipelines. The reasoning was the existence of DevOps specializations per business domain and therefore focused domain expertise was required when adopting DevOps locally. All the CoEs together formed the DevOps community of practice (CoP), with a mission to collectively align around the DevOps enterprise operating model’s adoption and evolution:
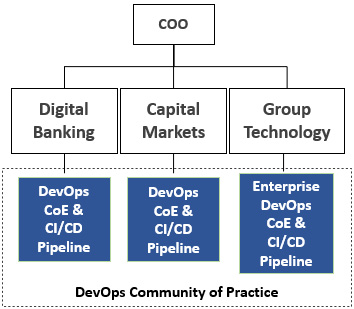
Figure 4.7 – The Enterprise CoE as part of a DevOps CoP
The following table shows the pros and cons:
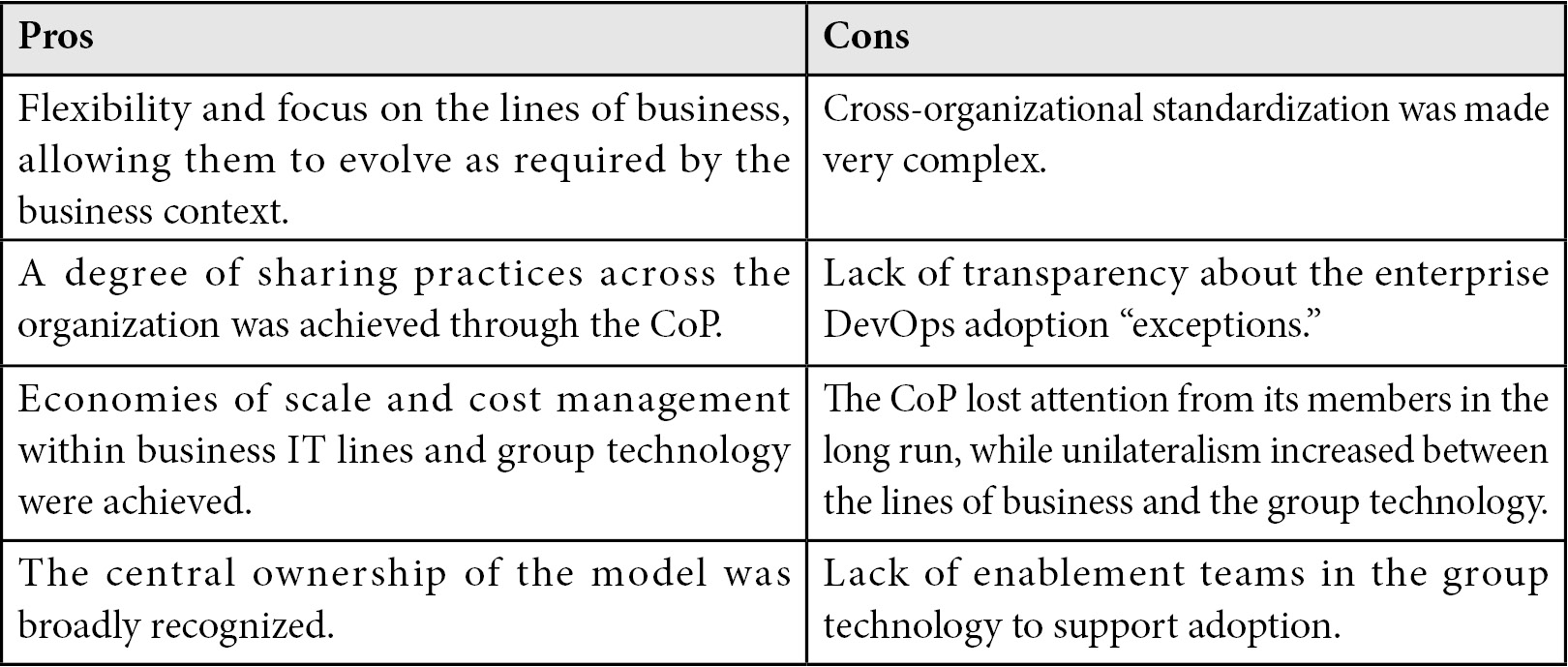
Table 4.6 – The Enterprise CoE as part of a DevOps CoP pros and cons
Use case 4 – the CI/CD DevOps CoE
This is a simplistic use case and very much an example to avoid regarding setting up and operating DevOps CoEs. The parameters characterizing this use case are as follows:
- DevOps operating model ownership: Business IT areas
- Core CI/CD capabilities ownership: DevOps – common CI/CD pipeline
- Client engagement services: Not available
- Level of centralization: Ambiguous
Motivating factor: DevOps in this organization was simply perceived as the implementation of CI/CD pipelines and a team was established to centrally offer it as a service. It was only due to industry trends that it was given the CoE title.
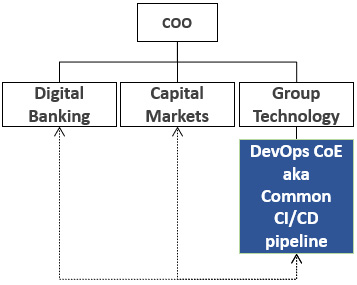
Figure 4.8 – The CI/CD DevOps CoE
You can probably guess that this type of CoE did not last long. It had no mandate on the DevOps adoption and was purely seen as a utility provider of a service that was already replicated in the lines of business. It achieved only limited standardization and simplification, with the CoE having almost zero visibility and involvement in the DevOps adoption taking place in the lines of business. Such CoEs are promptly either restructured into one of the preceding models or naturally or tactically terminated.
Which Approach Do I Propose?
It depends on your context, ambition, and capabilities, among other things. Going by experience only, I would choose a model between 1 and 2, as those are the ones I have seen delivering the most value and being decisive and sustainable in the long term.
The CoE’s long-term ambitions
In the long run, as the evolution becomes organic and institutionalized, the CoE’s importance, role, and necessity should be eliminated gradually, but in a controlled way.
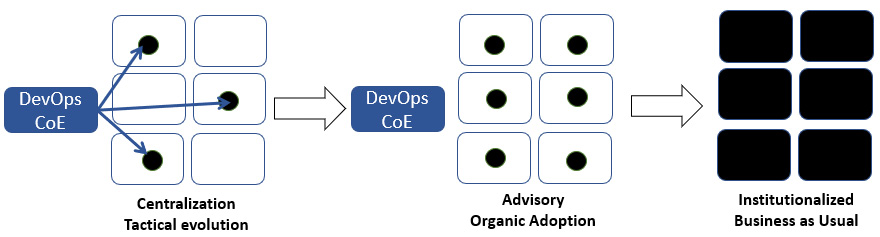
Figure 4.9 – The main phases of the CoE’s life cycle toward scaled DevOps institutionalization
It is a paradox indeed, but the DevOps CoE and the broader organization have only truly delivered on their DevOps promise if one day, the CoE is not needed anymore, having enabled a DevOps institutionalized autonomy in the business IT teams. And the future of its people? No worries at all. They will be in high demand both internally and externally.
Summary
In this chapter, we introduced and discussed the value proposition of two very important functions/orchestrators of the DevOps evolution: the EA and the DevOps CoE. We highlighted the importance of the business domains, flows, and service criticalities for a DevOps evolution using two examples of trading and mobile payments. Later on, we discussed the four portfolio modernization options that incumbents have, along with providing the business case parameters and examples for each. We then deep-dived into the essence of reference architectures for the DevOps evolution, and we discussed six of them in further detail. Next, the establishment of an EA assembly was outlined, along with some further value proposition extension domains that EA as a function can support during the DevOps evolution.
The chapter continued by providing the DevOps evolution value proposition for the DevOps CoE, presented through four potential roles, each of which was discussed at length. Continuing, we focused on the tactical adoption enabler role and defined a sample service catalog, complemented by a CoE engagement example, demonstrating how the CoE can potentially add a combination of engineering and advisory value. Furthermore, we provided clarity and tips on the essential matters of staffing and funding the CoE in the form of advice from real lessons learned. Closing the chapter, we outlined and discussed the pros and cons of four different DevOps CoE real-world approaches taken by four different incumbent banks.
In the next chapter, we will learn about the fundamental aspects of defining the DevOps model’s organizing principles through a proven practice and will examine how DevOps can be reconciled with business enterprise agility models in an agnostic way.
|
Refactor and/or decouple |
Full replacement, consolidation, or divestment | |
|
Business case elements |
The platform is considered to be:
On decoupling, a full replacement is considered operationally risky or cannot be funded. |
The platform is considered to be:
The platform will either be replaced or terminated. |
|
Portfolio examples |
|
|
|
Pros |
Cons |
|
Standardization and simplification of DevOps practices across engagements. |
The CoE could not scale outside the pre-defined client engagements. |
|
Effective and tactical utilization of the CoE’s resources. |
The “DevOps gap” between those supported and not supported by the CoE widened. |
|
Economies of scale through reusability. |
The CoE could not capture all the business IT context-related feedback and specialties. |
|
A single recognized owner and point of entry for the DevOps operating model. |
High capability concentration and density occasionally resulted in CoE unilateralism. |
|
Career mobility within the CoE. |
The client engagement rotations had a mixed effect due to switching context and focus frequently, as well as leaving gaps behind. |
|
DevOps model frameworks and CI/CD technology alignment. |
Feeling of exclusion in the broader organization due to fixed CoE engagements. |
|
The CoE’s engagements dominated the backlog evolution (this is a positive, as those teams were the most advanced in the organization). |
The CoE‘s engagements dominated the backlog CI/CD (this is a negative due to the feeling of exclusion for the rest of the organization and a lack of focus on their requirements). |
|
Pros |
Cons |
|
Standardization and simplification of DevOps practices across engagements. |
The CoE could not scale outside the pre-defined client engagements. |
|
Effective and tactical utilization of CoE resources focused on building the business IT area solutions. |
The “DevOps gap” between those supported and not supported by the CoE widened. |
|
Economies of scale through reusability. |
Priorities and authority conflicts arose between the CoE and platform teams. |
|
A single recognized owner and point of entry for the DevOps operating model. |
The organization continuously and mistakenly thought that the CI/CD platform team was under the CoE, which resulted in communication and expectation complexity. |
|
The CoE’s engagements dominated the backlog model (this is a positive, as those teams were the most advanced in the organization). |
The CoE’s engagements dominated the backlog model (this is a negative due to the rest of the organization feeling excluded and a lack of focus on their requirements). |
|
Cross-business IT areas experienced a certain degree of synergy driven by the CoE. |
Due to their dedication to business IT areas, the CoE people lost the sense of belonging to the CoE. |