
A Short Tour of Mathematical Morphology on Edge and Vertex Weighted Graphs
Université Paris-Est
Laboratoire d’Informatique Gaspard-Monge
Equipe A3SI - ESIEE Paris
France
Email: [email protected]
Centre de Morphologie Mathématique
Ecole des Mines de Paris
Fontainebleau, France
Email: [email protected]
CONTENTS
6.3 Neighborhood Operations on Graphs
6.5 Connected Operators and Filtering with the Component Tree
6.6.1 The Drop of Water Principle
6.6.2 Catchment Basins by a Steepest Descent Property
6.6.3 Minimum Spanning Forests
6.6.4 Illustrations to Segmentation
6.7 MSF Cut Hierarchy and Saliency Maps
6.7.1 Uprootings and MSF Hierarchies
6.7.3 Application to Image Segmentation
6.8 Optimization and the Power Watershed
Mathematical morphology is a discipline of image analysis that was introduced in the mid-1960s by two researchers at the École des Mines in Paris: Georges Matheron [1] and Jean Serra [2, 3]. Historically, it was the first consistent nonlinear image analysis theory, which from the very start included not only theoretical results but also many practical aspects. Due to the algebraic nature of morphology, the space on which the operators are defined can be either continuous or discrete. However, it was only in 1989 [4] that researchers from the CMM at the École des Mines began to study morphology on graphs, soon formalized in [5]. Fairly recent developments [6, 7, 8, 9, 10, 11, 12] in this direction has several motivations and beneficial consequences that we are going to review in this chapter. Rather than trying to cover every aspect of the theory, we choose to present a comprehensive subset based on a recent unifying graph theoretical framework developed by the A3SI team of the LIGM at Paris-Est University. The presentation is roughly divided in three parts, dealing respectively with basic operators (mainly based on [10]), hierarchical segmentation (mainly based on [13] and [14]), and optimization (mainly based on [15]). For the reader interested in a more complete presentation of morphology, we recommend [16] and the recent [17].
One of the fundamental ideas of mathematical morphology is to compare unkown objects with known ones. We begin by presenting the tools that make such an idea practicable: mathematical structures called lattices (Section 6.2), allowing us to compare weighted and nonweighted edges and vertices. We then present (Section 6.3) several dilations and erosions, which always come in pairs (they are called adjunct operators). From there, we can build (Section 6.4) some morphological filters, called opening or closing. During the presentation of those various operators, we often give an interpretation of classical graph operators in morphological terms. We conclude this part by presenting (Section 6.5) some connected operators based on pruning a tree representation of the image, illustrating their usage for image filtering and simplification.
The second part of the chapter deals with hierarchical segmentation. During the course of the chapter’s first part, several times the minimum spanning tree appears. This tree is the oldest combinatorial optimization problem [18, 19]. Since the seminal work of Zahn [20], the minimum spanning tree has been extensively used in classification. Its first appearance in image processing dates from 1986, in a paper by Morris et al. [21]. Meyer was the first to explicitely use it in a morphological context [22]. A strong momentum to its usage in segmentation has been provided, thanks to a 2004 paper by Felzenswalb and Huttenlocher [23]. In the second part of the chapter, we revisit the watershed [24], and show that in the framework of edge-weighted graphs, the watershed has very strong links with the minimum spanning tree (Section 6.6). Thanks to such links, we can use the watershed for building hierarchies of segmentations (Section 6.7), relying on the filtering tools seen in the first part of the chapter.
The main principle of morphology, comparison, is rather different from the optimization paradigm. However, rather than opposing these two viewpoints, it is more fruitful to explore their connections. In the last part of the chapter (Section 6.8), we turn towards optimization and show that the watershed presented in the previous part can be extended to be used as an optimization tool.
In mathematical morphology, we compare objects with respect to each other. The mathemathical structure that allows us to make such an operation effective is called a lattice. Recall that a (complete) lattice is a partially ordered set, that also has a least upper bound, called supremum, and a greatest lower bound, called infimum. More formally, a lattice [25] (ℒ, ≤) is a set ℒ (the space) endowed with an ordering relationship ≤, which is reflexive (∀x∈ ℒ, x ≤ x), anti-symmetric (x ≤ y and y ≤ x ⇒ x = y), and transitive (x ≤ y and y ≤ z ⇒ x ≤ z). This ordering is such that for all x and y, we can define both a larger element x ∨ y and a smaller element x ∧ y. Such a lattice is said to be complete if any subset P of ℒ has a supremum ∨ P and an infimum ∧ P that both belongs to ℒ. The supremum is formally the smallest amongst all elements of ℒ that are greater than all the elements of P, and, conversely, the infimum is the largest element of ℒ that is smaller than all the elements of P.
Most of the morphological theory can be presented and developed at this abstract level, without making references to the properties of the underlying space. However, studying what impact such properties have can indeed be interesting in some situations. In the sequel, we study some lattices that can be built from graph spaces, and what kind of (morphological) operators can be built from such lattices.
We define a graph as a pair G = (V(G), ℰ(G)) where V(G) is a set and ℰ(G) is composed of unordered pairs of distinct elements in V(G), i.e., ℰ(G) is a subset of {{υ1, υ2} ⊆ V(G) | υ1≠ υ2}. Each element of V(G) is called a vertex or a point (of G), and each element of ℰ(G) is called an edge (of G). In the sequel, to simplify the notations, eij stands for the edge {υi, υj}∈ ℰ(G).
Let G1 and G2 be two graphs. If V(G2) ⊆ V(G1) and ℰ(G2) ⊆ ℰ(G1), then G1 and G2 are ordered and we write G2 ⊑ G1. If G2 ⊑ G1, we say that G2 is a subgraph of G1, or that G2 is smaller than G1 and that G1 is greater than G2.
Important remark. Hereafter, the workspace is a graph G = (V(G), ℰ(G)), and we consider the sets V(G), ℰ(G) and G of, respectively, all subsets of V(G), all subsets of ℰ(G) and all subgraphs of G. We also use the classical notations V = V(G) and ℰ = ℰ(G).
Let S0, S1 ⊆ G be the sets of, respectively, the graphs made of a single vertex and the graphs made of a pair of vertices linked by an edge, i.e., S0 = {({υ}, 0) | υ ∈ V(G)} and S1 = {({υi, υj}, {eij}) | eij ∈ ℰ(G)}. We set S = S0 ∪ S1. Any graph G1∈ G is generated by the family ℱ = {G1, …, Gℓ} of all elements in S smaller than G1 : G1 = (∪i ∈ [1, ℓ]V(Gi), ∪i∈ [1, ℓ]ℰ(Gi)); we say that the elements of ℱ are the generators of G1 [10]. Conversely, any family ℱ of elements in S generates an element of G. Hence, S (sup-) generates G.
Clearly, the ordering ⊑ on graphs amount to having G2 ⊑ G1 when all generators of G2 are also generators of G1. Therefore, ordering ⊑ provides a lattice structure on the set G. Indeed, the largest graph smaller than a family ℱ = {G1, …, Gℓ} of elements in G is the graph generated by the generators common to all Gi, i ∈ [1, ℓ]; this infimum is denoted by ⊓ℱ. Similarly, the supremum ⊔ℱ is generated by the union of the families of generators of all Gi, i ∈ [1, ℓ].
If V(G1)_ ⊆ V(G) (respectively ℰ(G2) ⊆ ℰ(G)), we denote by ¯V(G1) (respectively ¯ℰ(G2)) the complementary set of V(G1) (respectively ℰ(G2)_) in V(G) (respectively ℰ(G)), that is ¯V(G1) = V(G) V(G1) (respectively ¯ℰ(G2) = ℰ(G) ℰ(G2)). Observe that, if G1 is a subgraph of G, then, except in some degenerated cases, the pair (¯ℰ(G1), ¯ℰ(G1)) is not a graph.
Property 1 ([10])
The set G of the subgraphs of G forms a complete lattice, sup-generated by the set S = S0 ∪ S1, but not complemented. The supremum and the infimum of any family ℱ = {G1, … Gℓ} of elements in G are given by, respectively, ⊓ℱ = (∩i∈[1, ℓ]V(Gi), ∩i∈[1, ℓ]ℰ(Gi)) and ⊔ℱ = (∪i∈[1, ℓ]V(Gi), ∪i∈[1, ℓ]ℰ(Gi)).
As a fixed grid is able to represent images by assigning grey tones to pixels, the graph G is able to generate a number of derived graphs by assigning weights to the vertices and edges of the graph G. According to the applications, the weights can be real or integer, taking their values in ℝ, ℝ+, ℕ, [−n, +n], [0, +n]. The weight of a vertice υi is written wi, while the one of an edge eij is written wij. The set of all (edges and vertices) weights is written w. The case where the weights are binary, belonging to {0, 1} may be interpreted as presence/absence: wij = 1 and wk = 1 express respectively the existence of an edge eij and of a vertice vk. All edges and vertices of G with weight 0 do not exist in this weighted graph.
A possible lattice structure on the weights is given by the following. Let w1 and w2 be two sets of weights, we have w1 ≺ w2 whenever w1ij < w2ij and w1k < w2k. The supremum (respectively infimum) of a family of sets of weights is a set of weights where the weight of a given element is the greatest (respectively lowest) possible weight of the weights of the same element in the family.
Remark 2
In a graph, there may be isolated vertices, that is vertices which are not adjacent to an edge. On the contrary, each edge is adjacent to two vertices. For this reason not any binary distribution of weights on the vertices and edges of G represents a graph. It is the case if and only if each edge with weight 1 is adjacent to two vertices with weight 1. The same holds for any weight distributions. w correspond to a graph if each edge with weight wij is such that wij ≤ wi and wij ≤ wj. In other words, this is the case if the extremities of an edge have weights which are not lower than the weight of the edge. Graphs may be used for modeling many different structures. In some cases vertex weight only have a physical meaning, and the edge weights simply serve for storing intermediate results in the computation of the weights of the vertices. In other cases, it is the converse. In such situations one does not care whether the weights represent a graph. In other situations, on the contrary, one cares to define operators transforming one graph into another graph.
6.3 Neighborhood Operations on Graphs
Morphology really starts if one considers the neighborhood relations between vertices and edges. We now define operators taking as arguments such neighborhoods. The construction is incremental, from the smallest neighborhood to larger neighborhoods.
In the graph G, we can consider sets of points as well as sets of edges. Therefore, it is convenient to consider operators that go from one kind of sets to the other one. In this section, we investigate such operators and we study their morphological properties. Then, based on these operators, we propose several dilations and erosions, acting on the lattice of all subgraphs of G.
Let V(G1) be a subset of V(G), we denote by GV(G1) the set of all subgraphs of G whose vertex set is V(G1). Let ℰ(G2) be a subset of ℰ(G). We denote by Gℰ(G2) the set of all subgraphs of G whose edge set is ℰ(G2).
Definition 3 (edge-vertex correspondences, [10])
We define the operators δℰV, εℰV from ℰ(G) into V(G) and the operators εVℰ, δVℰ from V(G) into ℰ(G) as follows:
ℰ(G) → V(G) |
V(G) → ℰ(G) |
|
Provide the object with a graph structure |
ℰ(G1) → δℰV(ℰ(G1)) such that (δℰV(ℰ(G1)), ℰ(G1)) = ⊓Gℰ(G1) |
V(G1) → εVℰ(V(G1)) such that (V(G1), εVℰ(V(G1))) = ⊔GV(G1) |
Provide its complement with a graph structure |
ℰ(G1) → εℰV(ℰ(G1)) such that ¯(εℰV(ℰ(G1)), ¯ℰ(G1)) = ⊓G¯ℰ(G1) |
V(G1) → δVℰ(V(G1)) such that ¯(V(G1), ¯δVℰ(V(G1))) = ⊔G¯V(G1) |
In other words, if V(G1) ⊆ V(G) and ℰ(G2) ⊆ ℰ(G), (δℰV(ℰ(G2)), ℰ(G2)) is the smallest subgraph of G whose edge set is ℰ(G2), (V(G1), εVℰ(V(G1))) is the largest subgraph of G whose vertex set is V(G1), ¯(εℰV (ℰ(G2)), ¯ℰ(G2)) is the smallest subgraph of G whose edge set is ¯ℰ(G2), and ¯(V(G1), ¯δVℰ(V(G1))) is the largest subgraph of G whose vertex set is ¯V(G1).
These operators are illustrated in Figures 6.1(a–f). The following property locally characterizes them.
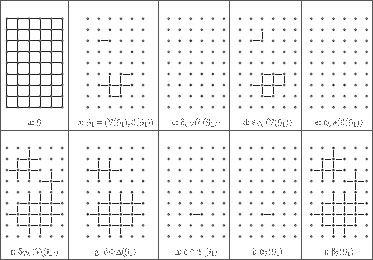
FIGURE 6.1
Dilations and erosions.
Property 4 ([10])
For any ℰ(G1) ⊆ ℰ(G) and V(G2) ⊆ V(G):
1. δℰV : ℰ(G) → V(G) is such that δℰV (ℰ(G1)) = {υi ∈ V(G) | ∃eij ∈ ℰ(G1)};
2. εVℰ : V(G) → ℰ(G) is such that εVℰ(V(G2)) = {eij ∈ ℰ(G) | υi ∈ V(G2) and υj ∈ V(G2)};
3. εℰV : ℰ(G) → V(G) is such that εℰV (ℰ(G1)) = {υi ∈ V(G) | ∀eij ∈ ℰ(G), eij ∈ ℰ(G1)};
4. δVℰ : V(G) → ℰ(G) is such that δVℰ (V(G2)) = {eij ∈ ℰ(G) | either υi ∈ V(G2) or υj ∈ V(G2)}.
In other words, δℰV(ℰ(G1)) is the set of all vertices that belong to an edge of ℰ(G1), εVℰ(V(G2)) is the set of all edges whose two extremities are in V(G2), εℰV(ℰ(G1)) is the set of all vertices which do not belong to any edge of ¯ℰ(G1), and δVℰ(V(G2)) is the set of all edges which have at least one extremity in V(G2).
From this characterization, we can recognize the general graph version of some operators introduced by Meyer and Angulo [8] (see also [7]) for the hexagonal grid. By translating supremum and infimum of the graph lattice to the corresponding supremum and infimum of the lattice of weigths, we obtain the weighted version of these operators. The four basic operators of Definition 3 translate to: (δℰV(w))i = max {wij | eij∈ ℰ}, εℰV(w)i = min {wij | eij ∈ ℰ}, (δVℰ(w))ij = max {wi, wj}, and (εVℰ(w))ij = min {wi, wj}.
Before further analyzing the operators defined above, let us briefly recall some algebraic tools that are fundamental in mathematical morphology [26].
Given two lattices ℒ1 and ℒ2, an operator δ : ℒ1 → ℒ2 is called a dilation when it preserves the supremum (i.e., ∀X ⊆ ℒ1, δ(∨1X) = ∨2{δ(x) | x ∈ X}, where ∨1 is the supremum in ℒ1 and ∨2 the supremum in ℒ2). Similarly, an operator which preserves the infimum is called an erosion.
Two operators ε : ℒ1 → ℒ2 and δ : ℒ2 → ℒ1 form an adjunction (ε, δ) when for any x in ℒ2 and any y in ℒ1, we have δ(x) ≤1 y ⇔ x ≤2 ε(y), where ≤1 and ≤2 denote the order relations on, respectively, ℒ1 and ℒ2. Given two operators ε and δ, if the pair (ε, δ) is an adjunction, then ε is an erosion and δ is a dilation.
Given two complemented lattices ℒ1 and ℒ2, two operators α and β from ℒ1 into ℒ2 are dual (with respect to the complement) of each other when, for any x∈ ℒ1, we have β(x) = ¯α(ˉx). If α and β are dual of each other, then β is an erosion whenever α is a dilation.
Property 5 (dilation, erosion, adjunction, duality, [10])
1. Both (εVℰ, δℰV) and (εℰV, δVℰ) are adjunctions.
2. Operators εVℰ and δVℰ (respectively εℰV and δℰV) are dual of each other.
3. Operators δℰV and δVℰ are dilations.
4. Operators εℰV and εVℰ are erosions.
Let us compose these dilations and erosions to act on V(G) and ℰ(G).
Definition 6 (vertex-dilation, vertex-erosion)
We define δ and ε that act on V(G) (i.e., V(G) → V(G))by δ = δℰV ∘ δVℰ and ε = εℰV ∘ εVℰ.
As compositions of, respectively, dilations and erosions, δ and ε are, respectively, a dilation and an erosion. Moreover, by composition of adjunctions and dual operators, δ and ε are dual, and (ε, δ) is an adjunction.
In fact, it can be shown that δ and ε correspond exactly to the usual notions of an erosion and of a dilation of a set of vertices in a graph [4, 5]. It means, in particular, that when V(G) is a subset of the grid points ℤd and when the edge set ℰ(G) is obtained from a symmetrical structuring element, then the operators defined above are equivalent to the usual binary dilation and erosion by the considered structuring element. For instance, in Figure 6.1, V(G) is a rectangular subset of ℤ2 and ℰ(G) corresponds to the basic “cross” structuring element. It can be verified that the vertex sets in Figure 6.1 (g) and (h), obtained by applying δ and ε to V(G1) (Figure 6.1(b), are the dilation and the erosion by a “cross” structuring element of V(G1).
We now consider a dual/adjunct pair of dilation and erosion acting on ℰ(G).
Definition 7 (edge-dilation, edge-erosion, [10])
We define Δ and ℰ that act on ℰ(G) by Δ = δVℰ ∘ δℰV and ℰ = εVℰ ∘ εℰV.
Definition 8 ([10])
We define the operators ![]() and
and ![]() by, respectively, (δ(V(G1)), Δ(ℰ(G1))) and (ε(V(G1)), ℰ(ℰ(G1))), for any G1∈ G.
by, respectively, (δ(V(G1)), Δ(ℰ(G1))) and (ε(V(G1)), ℰ(ℰ(G1))), for any G1∈ G.
For instance, Figures 6.1(f) and 6.1(g) present the results obtained by applying the operator ![]() and the operator
and the operator ![]() to the subgraph G1 (Figure 6.1(b)) of G (Figure 6.1(a)).
to the subgraph G1 (Figure 6.1(b)) of G (Figure 6.1(a)).
Theorem 9 (graph-dilation, graph-erosion,[10])
The operators ![]() and
and ![]() are respectively a dilation and an erosion acting on the lattice (G, ⊑). Furthermore,
are respectively a dilation and an erosion acting on the lattice (G, ⊑). Furthermore, ![]() is an adjunction.
is an adjunction.
Note that since lattice G is sup-generated by set S, it suffices to know the dilation of the graphs in S for characterizing the dilation of the graphs in G.
Compared to classical morphological operators on sets, the dilations and erosions introduced in this section furthermore convey some connectivity properties different than the ones which can be deduced from classical dilations and erosions. Observe, for instance, in Figure 6.1(g), that some 4-adjacent vertices of δ(V(G1)) are not linked by an edge in the graph ![]() . These properties can be useful in further processing involving for instance connected operators [27, 28, 29, 30].
. These properties can be useful in further processing involving for instance connected operators [27, 28, 29, 30].
Thanks to the operators presented in Definition 3, other intersecting adjunctions (hence dilations/erosions) can be defined on G:
1. (α1, β1) such that ∀G1 ∈ G, α1(G1) = (V(G), ℰ(G1)) and β1(G1) = (δℰV(ℰ(G1)), ℰ(G1));
2. (α2, β2) such that ∀G1 ∈ G,α2(G1) = (V(G1), εVℰ(V(G1))) and β2(G1) = (V(G1), 0);
3. (α3, β3) such that ∀G1 ∈ G, α3(G1) = (εℰV(ℰ(G1)), εVℰ ∘ εℰV(ℰ(G1))) and β3(G1) = (δℰV ∘ δVℰ (V(G1)), δVℰ(V(G1))).
The adjunction (α3, β3) is illustrated in Figures 6.1(i) and 6.1(j). Note also that, using usual graph terminologies, β1 (respectively α2) can be defined as the operator which associates to a graph the graph induced by its edge set (respectively, vertex set).
A more general version of those operators can be obtained in the framework of complexes [12], allowing us to deal for example with meshes. There also exist other recent graph-based approaches to morphology, for example based on hypergraphs [11] or on discrete differential equations [9].
In mathematical morphology, a filter is an operator α acting on a lattice ℒ that is increasing (i.e., ∀x, y ∈ ℒ, α(x) ≤ α(y) whenever x ≤ y) and idempotent (i.e., ∀x ∈ ℒ, α(α(x)) = α(x)). A filter α on ℒ that is extensive (i.e., ∀x∈ ℒ, x ≤ α(x)) is called a closing on ℒ, whereas a filter α on ℒ that is anti-extensive (i.e., ∀x∈ ℒ, α(x) ≤ x) is called an opening on ℒ. It is known that composing the two operators of an adjunction yields an opening or a closing, depending on the order in which the operators are composed [26]. In this section, the operators of Section 6.3 are composed to obtain filters on V(G), ℰ(G) and G.
Definition 10 (opening, closing, [10])
1. We define γ1 and ϕ1, which act on V(G), by γ1 = δ ∘ ε and ϕ1 = ε ∘ δ.
2. We define Γ1 and Φ1, which act on ℰ(G), by Γ1 = Δ ∘ ℰ and Φ1 = ℰ ∘ Δ.
3. We define the operators ![]() and
and ![]() by, respectively,
by, respectively, ![]() , and
, and ![]() for any G1 ∈ G.
for any G1 ∈ G.
Figures 6.2(b) and 6.2(f) present the result of ![]() and
and ![]() for, respectively, the subgraph of Figure 6.2(a) and the one of Figure 6.2(e).
for, respectively, the subgraph of Figure 6.2(a) and the one of Figure 6.2(e).
The opening γ1 and the closing ϕ1 correspond to the classical opening and closing on the vertices. The closing Γ1 and the opening Φ1 are the corresponding edge-version of these operators. By combination, we obtain ![]() and
and ![]() .
.
In fact, by composing δℰV with εVℰ and δℰV with εVℰ, we obtain smaller filters.
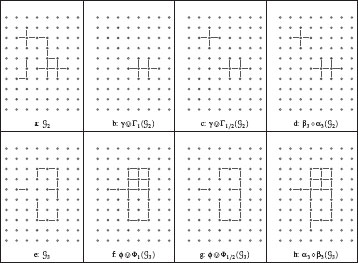
FIGURE 6.2
Openings and closings (G is induced by the 4-adjacency relation).
Definition 11 (half-opening, half-closing, [10])
1. We define γ1/2 and ϕ1/2, that act on V(G), by γ1/2 = δℰV ∘ ϵVℰ and ϕ1/2 = εℰV ∘ δVℰ.
2. We define Γ1/2 and Φ1/2, that act on ℰ(G) by Γ1/2 =δVℰ ∘ εℰV and Φ1/2 =εVℰ ∘ δℰV.
3. We define the operators ![]() and
and ![]() by, respectively,
by, respectively, ![]() and
and ![]() , for any G1 ∈ G.
, for any G1 ∈ G.
Thanks to Property 4, the operators defined above can be locally characterized. Let V(G1) ⊆ V(G) and ℰ(G2) ⊆ ℰ(G), we have:
γ1/2(V(G1))={υi ∈ V(G1) | ∃eij ∈ ℰ(G) with υj ∈ V(G1)}=V(G1) {υi∈ V(G1) | ∀eij ∈ ℰ(G), υj ∉ V(G1)}Γ1/2(ℰ(G2))={eij ∈ ℰ(G) | {eik ∈ ℰ(G)} ⊆ ℰ(G2)}=ℰ(G2) {e∈ ℰ(Y) | ∀υi ∈ e, ∃eij ∈ ℰ(G) with eij ∉ ℰ(G2)}ϕ1/2(V(G1))={υi ∈ V(G) | either υi∈ V(G1) or ∀eij∈ ℰ(G), υj ∈ V(G1)}=V(G1) ∪ {υi∈ ¯V(G1) | ∀eij∈ ℰ(G), υj∈ V(G1)}Φ1/2(ℰ(G2))={eij∈ ℰ(G) | ∃eik ∈ ℰ(G2) and ∃ejl ∈ ℰ(G2)}=Y ∪ {eij∈ ¯ℰ(G2) | υi∈ δℰV (ℰ(G2)) and υj ∈ δℰV (ℰ(G2))}.
Informally speaking, γ1/2 removes from G1 its isolated vertices, whereas Γ1/2 removes from G2 the edges that do not contain a vertex completely covered by edges in G2. It may be seen furthermore that γ1/2 (respectively, Γ1/2) is the dual of ϕ1/2 (respectively, Φ1/2). Thus, ϕ1/2 adds to G1 the vertices of ¯V(G1) completely surrounded by elements of G1 whereas Φ1/2 adds to G2 the edges of ¯ℰ(G2) whose two extremities belong to at least one edge in G2 (see, for instance, Figure 6.2).
The family G is closed under the operators presented in Definition 10.3 since they are obtained by composition of operators also satisfying this property. Furthermore, it can be deduced from the local characterization of the operators γ1/2, Γ1/2, ϕ1/2 and Φ1/2 that the family G is also closed under the operators of Definition 11.3. Hence, thanks to the properties of adjunctions recalled in the introduction of this section, the following theorem can be established.
Theorem 12 (graph-openings, graph-closings,[10])
1. The operators γ1/2 and γ1 (respectively, Γ1/2 and Γ1) are openings on V(G) (respectively, ℰ(G)) and ϕ1/2, and Φ1 (respectively, Φ1/2 and ϕ1) are closings on V(G) (respectively, ℰ(G)).
2. The family G is closed under ![]() ,
, ![]() ,
, ![]() , and
, and ![]() .
.
3. The operators ![]() and
and ![]() are openings on G and
are openings on G and ![]() , and
, and ![]() are closings on G.
are closings on G.
Composing the operators of the adjunctions (αi, βi), defined at the end of Section 6.3, also yields remarkable openings and closings. Indeed, it can be easily seen that: α1 ∘ β1 = α1, α2 ∘ β2 = α2, β1 ∘ α1 = β1, and β2 ∘ α2 = β2. Thus, α1 and α2 are both a closing and an erosion, and β1 and β2 are both a dilation and an opening. This means, in particular, that α1 and α2 are idempotent extensive erosions and that β1 and β2 are idempotent anti-extensive dilations. The opening and the closing resulting from the adjunction (α3, β3) are illustrated in Figures 6.2d and 6.2h.
The weighted versions of those various operators also have an interpretation related to classical notions of graph theory. Consider, for example, the weighted version of the opening Γ1/2 = δVℰ εℰV. The dilation δVℰ assigns to each edge the highest weight of its adjacent vertices; but each adjacent vertice has been assigned by εℰV the weight of its lowest edge. So if wij is left unchanged by Γ1/2, it means that the edge eij is (one of) the lowest edges of υi or of υj, say υi. Its weight is higher or equal to the weight of the lowest edge of υj. Thus, using some well-known properties of minimum spanning trees (see Section 6.6.3 for a precise definition of a minimum spanning tree), it can be shown that the graph induced by the set of edges that are left invariant by Γ1/2 is the union of all mininimum spanning trees of this graph, closely related to the Gabriel graph [31].
It is possible to associate with any lattice ℒ, the lattice of all increasing operators on ℒ. In this context, two filters, φ1 and φ2, on the lattice ℒ are said ordered if, for any ∈ ℒ, φ1(x) ≤ φ2(x) or if, for any x ∈ ℒ, φ2(x) ≤ φ1(x). A usual way to build a hierarchy of filters (i.e., an ordered family of filters) from an adjunct pair (α, β) of erosion and dilation consists of building the dilations and erosions obtained by iterating several times α and β. In general, composing these iterated versions of α and β leads to hierarchies of filters when the number of iterations increases. By combining and iterating the operators that we have defined in this section, we obtain [10] hierarchies of filters in the lattice G that perform better than the classical ones, in the sense that they are able to remove more noise (see Figure 6.3.)

FIGURE 6.3
Illustration of classical versus vertex-edge alternating filter (see [10]).
6.5 Connected Operators and Filtering with the Component Tree
Gray-level connected operators [27] act by merging neighboring “flat” zones. They cannot create new contours and, as a result, they cannot introduce in the output image a structure that is not present in the input image. Furthermore, they cannot modify the position of existing boundaries between regions, and therefore have very good contour preservation properties.
To create “flat” zones, a simple operation on a weighted graph is thresholding, that produces a level set. For λ ∈ ℝ+, the level-sets of an edge-weighted graph are denoted w<ℰ[λ] = {eij∈ ℰ|wij ≤ λ}. We define C<ℰ as the set composed of all the pairs [λ, C}, where λ∈ ℝ+ and C is a (connected) component of the graph w<ℰ[λ].
We note that one can reconstruct w from C<ℰ; more precisely, we have:
(6.1) |
One can remark that two elements of C<ℰ are either disjoint or nested, thus it is easy to order the elements of C<ℰ in a tree. This tree is called the (min) component tree, and there exists fast algorithms to compute it [32, 33].
Using C<ℰ allows us to deal with specific components of w. For example, a minimum of w is a component C such that there exists λ with , and it does not exist with C1 ⊏ C and C1 ≠ C. Observe that a minimum of w is a graph. The set of all minima of w is denoted . Similarly, we can define allowing us to deal with maxima of edge-weighted graphs and , allowing us to deal with node-weighted graphs, and , and allowing us to deal with node- and edge-weighted graphs.

FIGURE 6.4
Illustration of, respectively, a component tree (dashed lines), the height, the area, and the volume of a component and an area filtering.
We mention that other trees are possible, for example, the binary partition tree [34], the tree of level lines, also known as the inclusion tree or the tree of shapes [35], etc. The interest of the tree of shapes is that it allows us to interact both with maxima and minima, in a self-dual manner. See [36] for a survey of the usage of those trees in image processing. Here, we illustrate the usage of the component tree for filtering.
Given Equation (6.1), filtering a graph can be seen as equivalent to removing some components of (say) . Such a filtering is called flooding. One way to make this idea practicable is to design an attribute that tells us if a given component should be kept or not. Among the numerous attributes that can be computed, three are natural: the height, the area, and the volume (Figure 6.4). Let . We define
(6.2) |
(6.3) |
(6.4) |
For example, removing all the components whose area is lower than a threshold is a closing of w (Figure 6.4.e). Note that a filtering with either the height or the volume is not a closing, as such a filtering is not idempotent.
Figure 6.5 illustrates this kind of filtering. Figure 6.5.a is an image of a cell in which we want to extract the ten bright lobes. If we consider that the brighter a pixel is, the higher its weight, then the tree we want to process is . Figure 6.5.b shows that Figure 6.5(a) contains numerous maxima. Figure 6.5(c) is the filtered image obtained by a volume-based filtering, and Figure 6.5(d) shows the maxima of this filtered image.
As the components of the level sets can be ordered into a tree, they form a hierarchy of components. In the context of classification [37], hierarchies are widely studied, and the morphological framework can shed some light on the tools that are developed in that community. For example, let us look at the application Ψ that associates to any set of edge-weights w the map Ψ(w) such that for any edge , . Intuitively, and using a geographical metaphore, Ψ(w)(eij) is the lowest altitude to which one has to climb to go from υi to υj. It is straightforward to see that Ψ(w) ≤ w, that Ψ(Ψ(w)) = Ψ(w) and that if w′ ≤ w, Ψ(w′) ≤ Ψ(w). Thus, Ψ is an opening [38]. We remark that the subset of strictly positive maps that are defined on the complete graph and that are open with respect to Ψ is the set of ultrametric distances on . The mapping Ψ is known under several names, including “subdominant ultrametric” and “ultrametric opening”. It is well known that Ψ is associated to the simplest method for hierarchical classification called single linkage clustering [39, 40], closely related to Kruskal’s algorithm [41] for computing a minimum spanning tree.
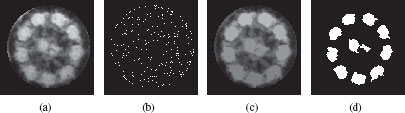
FIGURE 6.5
(a) Original image. (b) Maxima of image (a), in white. (c) Filtered image. (d) Maxima of image (c), which corresponds to the ten most significant lobes of the image (a).
Before concluding the section, let us mention another flooding that has been used as a preprocessing step for watershed segmentation with markers. It is called geodesic reconstruction from the markers [42, 43], where the markers is a subgraph. It consists in removing all the components of that are not marked (i.e., that do not contain a vertice of the markers) and is given as a function wR such that, for every edge e, we set wR(e) to be equal to the level λ of the lowest component of w containing e and at least one vertice of the markers. Observe that any component of wR indeed contains at least one vertice of the markers. Given some markers, the geodesic reconstruction is a closing. Such a closing is also useful as an efficient preprocessing for a fast power-watershed optimization algorithm (see [15] and Section 6.8).
There exist many possible ways for defining a watershed [24, 44, 45, 46, 13, 47]. Intuitively, the watershed of a function (seen as a topographical surface) is composed of the locations from which a drop of water could flow towards different minima. The framework of edge-weighted graph allows the formalization of this principle and the proof of several remarkable properties [13] that we review in the sequel of the section. We first show that watershed cuts can be equivalently defined by their “catchment basins” (through a steepest descent property) or by the “dividing lines” separating these catchment basins (through the drop of water principle). As far as we know, in discrete frameworks, a similar property does not hold. The second property establishes the optimality of watershed-cuts: there is an equivalence between the watershed-cuts and the separations induced by a minimum spanning forest relative to the minima.
6.6.1 The Drop of Water Principle
Definition 13 (from Definition 12 in [46])
Let and be two non-empty subgraphs of . We say that is an extension of (in ) if and if any component of contains exactly one component of .
The notion of extension is very general. Many segmentation algorithms iteratively extend some seed components in a graph; they produce an extension of the seeds. Most of them terminate once they have reached an extension that cover all the vertices of the graph. The separation thus produced is called a graph cut. Let . We denote by the complementary set of in , i.e., . Recall that the graph induced by , given by the dilation β1, is the graph whose edge set is and whose vertex set is made of all points that belong to an edge in , i.e., . In the following, the graph induced by is also denoted by .
Definition 14
Let and . We say that is a (graph) cut for if is an extension of and if is minimal for this property, i.e., if and is an extension of , then we have .
We introduce the watershed cuts of an edge-weighted graph. To this end, we formalize the drop of water principle. Intuitively, the catchment basins constitute an extension of the minima, and they are separated by “lines” from which a drop of water can flow down towards distinct minima.
Let π = (υ0, ⋯, υn) be a path. The path π is descending if, for any i ∈ [1, l – 1], w(υi−1, υi) ≥ w(υi, υi+1).
Definition 15 (drop of water principle, [13])
Let . We say that is a watershed cut (or simply a watershed) if is an extension of and if for any , there exist and , which are two descending paths in , such that and are vertices of two distinct minima of w; (respectively, ), whenever π1 (respectively, π2) is not trivial.
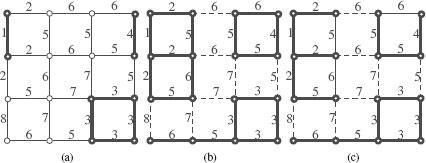
FIGURE 6.6
An edge-weighted graph The edges and vertices drawn in bold are (a), the minima of w; (b), an extension of ; (c), an MSF rooted in . In (b), the set of dashed edges is a watershed cut of w.
We illustrate the previous definition on the edge-weighted graph depicted in Figure 6.6. The weights w contain three minima (in bold in Figure6.6(a)). Let us denote by the set of dashed edges depicted in Figure 6.6(b) and by e = {υ1, υ2} the only edge whose altitude is 8. It may be seen that (in bold Figure 6.6(b)) is an extension of . We also remark that there exists π1 (respectively π2) a descending path in from υ1 (respectively υ2) to the minimum at altitude 1 (respectively, 3). The altitude of the first edge of π1 (respectively, π2) is lower than the altitude of e. It can be verified that the previous properties hold true for any edge in . Thus, is a watershed of F.
6.6.2 Catchment Basins by a Steepest Descent Property
A popular alternative to Definition 15 consists of defining a watershed exclusively by its catchment basins and the paths of steepest descent of w [48, 44, 49, 45], and does not involve any property of the divide. The following theorem (17) establishes the consistency of watershed cuts in edge-weighted graphs: they can be equivalently defined by a steepest descent property on the catchment basins (regions) or by the drop of water principle on the cut (border) which separate them. As far as we know, there is no definition of watershed in vertex-weighted graphs that verifies a similar property. This theorem thus emphasizes that the framework of edge-weighted graphs is adapted for the study of discrete watersheds.
Let π = (υ0, ⋯, υl) be a path in . The path π is a path of steepest descent (for w) if, for any i ∈ [1, l], .
Definition 16 ([13])
Let be a cut for . We say that is a basin cut (of w) if, from each point of to , there exists, in the graph induced by , a path of steepest descent for w. If is a basin cut of w, any component of is called a catchment basin (of w, for ).
Theorem 17 (consistency, [13])
Let be a cut for . The set is a watershed if and only if is a basin cut of w.
6.6.3 Minimum Spanning Forests
We establish the optimality of watersheds. To this end, we introduce the notion of minimum spanning forests rooted in some subgraphs of . Each of these forests induces a unique graph cut. The main result of this study (Th. 19) states that a graph cut is induced by a minimum spanning rooted in the minima of a function if and only if it is a watershed of this function.
Definition 18 (rooted MSF, [14])
Let and be two nonempty subgraphs of . We say that is rooted in if and if the vertex set of any component of contains the vertex set of exactly one component of . Recall that the weight of is the sum of its weight, i.e.,
We say that is a minimum spanning forest (MSF) rooted in if (1) is spanning for , (2) is rooted in , and (3) the weight of is less than or equal to the weight of any graph satisfying (1) and (2) (i.e., is both spanning for and rooted in ). The set of all minimum spanning forests rooted in is denoted by MSF(G1).
The above definition of rooted MSFs allows the usual notions of graph theory based on trees and forests to be recovered. In particular, if υ is a vertex of V, it can be seen that any element in MSF({υ}, ) is a minimum spanning tree of (G, w), and that, conversely, any minimum spanning tree of (G, w) belongs to MSF({υ}, ).
Let us consider the edge-weighted graph and the subgraph (in bold) of Figure 6.6(a). It can be verified that the graph (in bold in Figure 6.6(c)) is an MSF rooted in .
We now have the mathematical tools to present the main result of this section (Th. 19), which establishes the optimality of watersheds.
Let be a subgraph of and let be a spanning forest rooted in . There exists a unique cut for , and this cut is also a cut for . We say that this unique cut is the cut induced by .
Theorem 19 (optimality, [13])
Let . The set is a cut induced by a MSF rooted in if and only if is a watershed cut.
6.6.4 Illustrations to Segmentation
In this subsection, we illustrate the versatility of the proposed framework to perform segmentation on different kinds of geometric objects. Firstly, we show how to segment triangulated surfaces by watershed cuts, and, secondly, we apply the watershed cuts to the segmentation of diffusion tensors images, which are medical images associating a tensor to each voxel.
3D shape acquisition and digitizing have received more and more attention for a decade, leading to an increasing amount of 3D surface-models (or meshes) such as the one in Figure 6.7(d). In a recent work [50], a new search engine has been proposed for indexing and retrieving objects of interests in a database of meshes (EROS 3D) provided by the French Museum Center for Research. One key idea of this search engine is to use region descriptors rather than global shape descriptors. In order to produce such descriptors, it is then essential to obtain meaningful mesh segmentations.
Informally, a mesh M in the 3D Euclidean space is a set of triangles, sides of triangles, and points such that each side is included in exactly two triangles (see Figure 6.7(a)). In order to perform a watershed cut on such a mesh, we build a graph whose vertex set is the set of all triangles in M and whose edge set is composed by the pairs eij = {υi, υj} such that υi and υj are two triangles of M that share a common side (see Figure 6.7(a)). The graph is known under the term 2-dual of the surface mesh [51].
To obtain a segmentation of the mesh M thanks to a watershed cut, we need to weight the edges of (or equivalently the sides of M) by a map whose values are high around the boundaries of the regions that we want to separate. We have found that the interesting contours on the EROS 3D meshes are mostly located on concave zones. Therefore, we weight the edges of by a weighting w, which behaves like the inverse of the mean curvature of the surface (see [50] for more details). Then, we can compute a watershed cut (in bold in Figure 6.7(b)) which leads to a natural and accurate mesh segmentation in the sense that the “borders” of the regions are made of sides of triangles (in bold in Figure 6.7c) of high curvature.
The direct application of this method on the mesh shown Figure 6.7(d) leads to a strong over-segmentation (Figure 6.7(e)) due to the huge number of local minima. By using the methodology introduced in Section 6.5 to remove from w all the minima which have a depth lower than a predefined threshold (here, 50) A watershed cut of the filtered w is depicted in Figure 6.7(f).
In the medical context, Diffusion Tensor Images (DTIs) [52] provide a unique insight into oriented structures within tissues. A DTI T maps the set of voxels (i.e., is a cuboid of ) into the set of 3 × 3 tensors (i.e., 3 × 3 symmetric positive definite matrices). The value T(υ) of a DTI T at a voxel describes the diffusion of water molecules at υ. For instance, the first eigenvector of T(υ) (i.e., the one whose associated eigenvalue is maximal) provides the principal direction of water molecules diffusion at point x and its associated eigenvalue gives the magnitude of the diffusion along this direction. Since water molecules highly diffuse along fiber tracts and since the white matter of the brain is mainly composed of fiber tracts, DTIs are particularly adapted to the study of brain architecture. Figure 6.8a shows a representation of a cross-section of a brain DTI where the tensors are represented by ellipsoids. Indeed, the data of a tensor is equivalent to the one of an ellipsoid. In the brain, the corpus callosum is an important structure made of fiber tracts connecting homologous areas of each hemisphere. In order to track the fibers that pass through the corpus callosum, it is necessary to segment it first. The next paragraph briefly reviews how to reach this goal, thanks to watershed cuts [47].
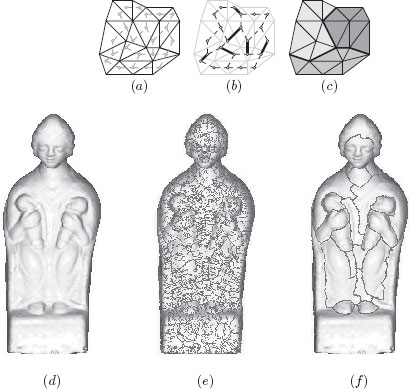
FIGURE 6.7
Surface segmentation by watershed cut. (a) A mesh in black and its associated graph in gray. (b) A cut on this graph (in bold); and (c), the corresponding segmentation of the mesh. (d) Rendering of the mesh of a sculpture. (e) A watershed (in red) of a map F which behaves like the inverse of the mean curvature and, in (f), a watershed of a filtered version of F. The mesh shown in (d) is provided by the French Museum Center for Research.

FIGURE 6.8
Diffusion tensor images segmentation. (a) A close-up on a cross-section of a 3D brain DTI. (b) Image representation of the markers (same cross-section as (a)), obtained from a statistical atlas, for the corpus callosum (dark gray) and for its background (light gray) (c) Segmentation of the corpus callosum by an MSF-cut for the markers. The tensors belonging to the component of the MSF that extends the marker labelled “corpus callosum” are removed from the initial DTI thus, the corresponding voxels appear black.
We consider the graph induced by the 6-adjacency and defined by iff and , where and . In order to weight any edge eij of by a dissimilarity measure between the tensors T(υi) and T(υj), we choose the Log-Euclidean distance, which is known to satisfy interesting properties [53]. Then, we associate to each edge eij ∈ E the weight wij = ‖log(T(υi)) – log(T(υj))‖, where log denotes the matrix logarithm and ‖.‖ the Euclidean (sometimes also called Frobenius) norm on matrices. To segment the corpus callosum in this graph, we extract (thanks to a statistical atlas), markers for both the corpus callosum and its background, and we compute an MSF-cut for these markers. An illustration of this procedure is shown in Figure 6.8.
To conclude this section, let us mention that spatio-temporal graphs are also feasible. For example, in [54], a 3D+t segmentation of the left-ventricle on cine-MR images was computed, showing an improvemnt with respect to the segmentation of each 3D volume separately.
6.7 MSF Cut Hierarchy and Saliency Maps
We now study some optimality properties of hierarchical segmentations (see [55, 56, 57, 58, 59, 60] for examples of hierarchical segmentations) in the framework of edge-weighted graphs, where the cost of an edge is given by a dissimilarity between two points of an image. Since the pioneering work of [39, 40] stating an equivalence between hierarchies and minimum spanning trees (MST), a large number of hierarchical schemes rely on the construction of such a tree (see [21] for one of the oldest). We formalize a fundamental operation called uprooting that allows us to merge a marked region with one of its neighbors with the cheapest cost. When applied sequentially on the weighted graph of neighboring regions, the uprooting builds a MST of this neighboring graph. Intuitively, one can see that, if one starts from a minimum spanning forest (MSF) rooted in the minima of the image (or, equivalently, from a watershed cut), then one builds a hierarchy of MSFs of the original image itself, the last uprooting step giving an MST of this original image. More surprisingly, Th. 23 states that the two processes are equivalent: any MST of the original image can be built from an uprooting sequence on a watershed cut. Thus, watershed cuts are the only watershed that allows the building of hierarchical segmentations that are optimal with respect to the original image, in the sense that they “preserve” the MST of the original image.

FIGURE 6.9
(a) An edge-weighted graph , the minima of w are depicted in bold. (b) A watershed cut represented by dashed edges; the watershed cut is equivalent to the graph represented in bold. (c,d) two bold graphs called, respectively, and such that is both an MSF hierarchy for and an uprooting by 〈M1, M2〉 (where Mi is the minimum of w whose altitude is i); their associated cuts are represented by dashed edges. (e) The saliency map of the MSF hierarchy .
Definition 20 (MSF hierarchy, [14])
Let be a sequence of pairwise distinct minima of w and let be a sequence of subgraphs of . We say that is an MSF hierarchy for if for any i ∈ [0, ℓ], the graph is an MSF rooted in , and for any i ∈ [1, ℓ], we have .
Any of an MSF hierarchy is a watershed cut of the geodesic reconstruction wR where the markers are the minima rooting the MSF .
6.7.1 Uprootings and MSF Hierarchies
In this section, we introduce a simple transformation, called uprooting, that allows a forest rooted in a graph to be incrementally transformed into a forest rooted in a graph obtained by removing some components of . Through an equivalence theorem, we establish an important link between the uprooting transform and the MSF hierarchies. This result opens the way toward efficient algorithms for computing MSF hierarchies.
Let be a subgraph of that is spanning for , and let . We denote by the component of whose vertex set contains υ. Let , we set .
Let , and let . The edge eij is outgoing from if eij is made of a vertex in and of a vertex in . In the following, by abuse of notation, we write for the supremum of , and the graph induced by .
Let , , and be three subgraphs of such that is spanning for and such that . We say that is an elementary uprooting of by if there exists an edge e of minimum weight among the edges outgoing from such that . We also say that is an elementary uprooting of by if and if there is no edge outgoing from .
Definition 22 ([14])
Let be a sequence of pairwise distinct minima of w. An uprooting by is a sequence of graphs such that and, for any i ∈ [1, ℓ], is an elementary uprooting of by Mi.
Theorem 23 ([14])
Let be a sequence of pairwise distinct minima of w. Let be a sequence of subgraphs of . The sequence is an MSF hierarchy for if and only if the sequence is an uprooting by .
The cuts of the sequence of any MSF hierarchy can be stacked to form a weighting called the saliency map. The saliency map allows us to easily assess the quality and the robustness of a hierarchical segmentation. Furthermore, it is a weighted graph, and can be further processed if needed, for example, to remove small regions unwanted in the hierarchy.
Let us give a precise defition of the saliency map [56, 14]. We first need to define, for a graph , the map ϕ as . In other words, is the union of all the graphs induced by the connected components of . It is easy to see that ϕ is an opening.
Let be a sequence of pairwise distinct minima of w and Let be a MSF hierarchy for . The saliency map s for is the map such that for any , either sij = k if there exists k such that k is the lowest number satisfying or sij = l + 1 if it does not exists any such that . Observe, in particular, that if , sij = 0, and that for λ ∈ {0, ⋯, l}.
Under the term of ultrametric watershed, one can give a computable definition to saliency maps, allowing to show the equivalenve between the set of hierarchical segmentations and the set of saliency maps [60].
6.7.3 Application to Image Segmentation
To use the framework in practice, we have to design an order on the minima of w. Let μ be an attribute on (i.e., a function from to that is increasing on ) such as the area, the volume, or the height. We compute an extinction measure [62, 63] μe to each minima of w by first definining a strict total order relation ≺ on the set of minima (based for example on the altitude of each minimum) such that M0 ≺ M1 ≺ ⋯ ≺ Ml; then we set μe(M0) = ∞ and
(6.5) |
The map μe will define the order ≺e of the sequence for the hierachy of MSF: Mi ≺e Mj whenever μe(Me) < μe(Mj).
Other choices for the ordering are possible: for example, waterfall [64], that consists in computing a sequence of watersheds of watersheds, each step leading to a drastic reduction in the number of basins. Another interesting ordering is done by optimization [57]). Let us consider a two-term-based energy function of the form λC + D, where D is a goodness-of-fit term and C is a regularization term. Finding an optimum of this function is NP-hard in the general case. On the other hand, on a hierarchy (hence, on a watershed cut), when the goodness-of-fit term decreases with the fineness of the partitions, and, inversely, that the regularization term increases with this fineness, we can show that finding an optimum can be done in linear time, by dynamic programming. Such an optimization is an efficient way to control the flooding, which is stopped when the optimum is reached. Varying the λ parameter allows us to obtain a complete hierarchy of segmentations.
Figure 6.10(b), (c), and (d) illustrates some saliency maps on the image of Figure 6.10a. The underlying graph is the one induced by the 4-adjacency relation whose edges are weighted by a simple color gradient (maximum, over the RGB channels, of the absolute differences of pixel values). The minima are ordered, thanks to extinction values [62] related to depth, volume, and color consistency.
6.8 Optimization and the Power Watershed
In this section, we review the Power Watershed framework [15] (see also Leo Grady’s chapter, this book). In the previous sections dealing with watershed cuts, the weights encode a dissimilarity such as a gradient. Classicaly, in the context of segmentation and clustering applications based on optimization, the weights encode affinity such that vertices connected by an edge with high weight are considered to be strongly connected and edges with a low weight represent nearly disconnected vertices. One common choice for generating weights from image intensities is to set a Gaussian weighting such as
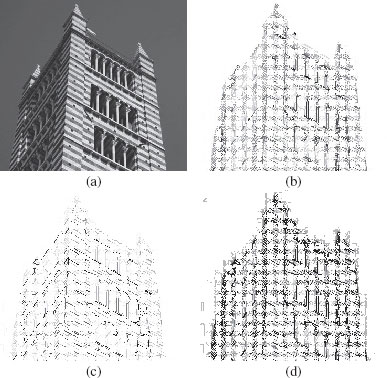
FIGURE 6.10
Illustration of saliencies of watershed cuts (original picture (a) from koakoo: http://blog.photos-libres.fr/).
(6.6) |
where ∇I is the normalized gradient of the image I. The gradient for a grey level image is Ii − Ij. As the weights are inverted, the maxima are considered instead of minima, and a thalweg is computed instead of watershed. A thalweg is the deepest continuous line along a valley. In the rest of the paper, we continue to use by convention the term “watershed” instead of “thalweg”.
Given foreground F and background B seeds, and p, q two real positive values, the energy presented for binary segmentation in [15] is given by
(6.7) |
In this energy, wij can be interpreted as a weight enforcing a regularization of the contours, such that any (usually unwanted) high-frequency content is penalized in x. The energy defined in (6.7) essentially forces x to remain smooth within the object, while allowing it to vary quickly close to point clusters near the boundary of the object. The data constraints enforce fidelity of x to a specified configuration, taking the values zero and one as the reconstructed object indicator. Observe that the values of x may not necessarily be binary when the value of q is strictly greater than one.
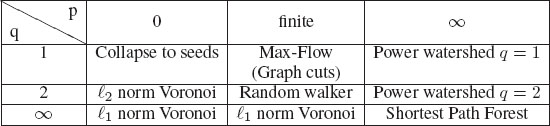
TABLE 6.1
The generalized scheme of [15] for image segmentation includes several popular segmentation algorithms as special cases of the parameters p and q. The power watershed may be optimized efficiently with a maximum spanning forest calculation.
The different values of p and q lead to different algorithms for optimizing the energy. Those algorithms form the underpinning for many of the advanced image segmentation methods in the literature. Table 6.1 gives a reference for the different algorithms generated by various values of p and q. The limit cases are the limit of the minimizers of Equation (6.7), e.g., the case p → ∞ reads
(6.8) |
Let us highlight the main choices for those parameters.
• When the power on the weight, p, is finite, and the exponent q = 1, we recover [61] the Max-Flow (Graph Cuts) energy which can be optimized by a max flow algorithm.
• When q = 2, we obtain a combinatorial Dirichlet problem also known as the random walker problem [65].
• When q and p converge toward infinity with the same speed, then [66] a solution to (6.8) can be computed by the shortest path (geodesics) algorithm [6, 67].
• As described in [15], by raising the power p toward infinity, and varying the power q, we obtain a family of segmentation models, which we refer to as power watershed, and that we detailed below.
A primary advantage of power watershed with varying q is that the main computational burden of these algorithms depends on an MSF computation, which is extremely efficient [68]. For example, interpreted from the standpoint of the Gaussian weighting function in (6.6), it is clear that we may associate β = p to understand that the watershed equivalence comes from operating the weighting function in a particular parameter range. In the case q = 1, an important insight from this connection is that above some value of β we can replace the expensive max-flow computation with an efficient maximum spanning forest computation.
Let us review some important theoretical results. First, we highlight that the cut obtained when minimizing the energy (6.8) is a watershed cut [13], and thus a maximum spanning forests [13] (MSF). Let x⋆ be a solution to (6.8) and s be the segmentation result defined as si = 1 if , 0 if . The set of edges eij such that si ≠ sj is a q-cut.
Theorem 24 ([15])
For q ≥ 1, any q-cut is a watershed cut of the (geodesically) reconstructed weights.
Furthermore, if every connected component of contains at least a vertex of B ∪ F, and q ≥ 1, then any q-cut when p → ∞ is an MSF cut for w.
Algorithm 1: Power watersheds algorithm p → ∞, q > 1

An algorithm is presented in Algorithm 1 to optimize the (unique) watershed that optimizes the energy for q > 1 and p → ∞. The case of parameter p → ∞ is particularly interesting.
1. The power watershed algorithm in the case q > 1 has a well-defined behavior in the absence or lack of weight information (presence of plateaus); indeed, as the energy is strictly convex, the solution to (6.8) is unique.
2. The worst-case complexity of the power watershed algorithm in the case p → ∞ is given by the cost of optimizing (6.7) for the given q. In the best-case scenario (all weights have unique values), the power watershed algorithm has the same asymptotic complexity as the algorithm used for a MSF computation (quasi-linear). In practical applications where the plateaus have a size less than some fixed value K, then the complexity of the power watershed algorithm matches the quasi-linear complexity of the standard watershed-cut algorithm.

FIGURE 6.11
Two applications of power watershed. (a-c) Shape fitting using power watershed [69]. (a) reconstructed bunny. (b) A close-up on one of the ears. (c) A close-up on the set of original scanned noisy points measurements. (d-e) Filtering of a liver image by anisotropic diffusion driven by power watershed [70]. In (e) noise and small vessels are both removed from (d), leading to a result which may be used as a first step before segmentation.
The main properties of Algorithm 1 (with q ≥ 1) are summarized in the following theorem. This theorem states that the energy found by the algorithm is the correct one, i.e. , and that furthermore, the computed cut is a MSF cut.
Theorem 25 ([15])
If q > 1, the potential x⋆ obtained by minimizing the energy of (6.7) subject to the boundary constraints converges toward the potential obtained by Algorithm 1 as p → ∞.
Furthermore, for any q ≥ 1, the cut C defined by the segmentation s computed by Algorithm 1 is an MSF cut for w.
Minimizing exactly the energy E1, 1 is possible by using the graph cuts (i.e., q = 1) algorithm in the case of two labels, but is NP-hard if constraints impose more than two different labels. However, the other algorithms presented in the framework (and, in particular, the watershed cuts and the power watershed) can efficiently perform seeded segmentation with as many labels as desired [15]. As several examples of segmentation have already been shown in this chapter, we rather highlight two other applications that take advantage the unique optimization characteristics of the power watershed.
The first example is shape fitting. Surface reconstruction from a set of noisy point measurements has been a well studied problem over the last decades. Recently, variational [71, 72] and discrete optimization [73] approaches have been applied to solve it, demonstrating good robustness to outliers thanks to a global energy minimization scheme. In [69], Couprie et al. use the power watershed framework to derive a specific watershed algorithm for surface reconstruction. The proposed algorithm is fast, robust to marker placement, and produces smooth surfaces. Figure 6.11(a–c) shows a surface reconstructed from noisy scanned dot sets using the power watershed algorithm.
The second example deals with filtering. In [70], Couprie et al. reformulate the problem of anisotropic diffusion as an L0 optimization problem, and show that power watersheds are able to optimize this energy quickly and effectively. This study paves the way for using the power watershed as a useful general-purpose minimizer in many different computer vision contexts. An example of such an L0 optimization is presented in Figures 6.11(d–e).
We have presented in this paper some applications of mathematical morphology to weighted graphs. The translation of the abstract framework of lattices to graphs allows us to obtain morphological operators thinner (in the sense that they process smaller details) than the usual ones commonly defined only on the vertices. We have shown how to filter an image using connected filters based on a tree representation of the image. We have exhibited the links between watersheds and minimum spanning trees, allowing us to make the equivalence between hierarchical segmentation based on watershed cuts and minimum spanning trees. We conclude the chapter by exploring links between the morphological and the optimization approaches.
For practical applications, we want to stress the importance of having a framework with an open-source generic implementation of existing algorithms, not limited to the pixel framework, but also able to deal transparently with edges, or, more generally, with graphs and complexes [74].
[1] G. Matheron, Random sets and integral geometry. New York: John Wiley & Sons, 1975.
[2] J. Serra, Image analysis and mathematical morphology. London, U.K.: Academic Press, 1982.
[3] J. Serra, Ed., Image analysis and mathematical morphology. Volume 2: Theoretical advances. London, U.K.: Academic Press, 1988.
[4] L. Vincent, “Graphs and mathematical morphology,” Signal Processing, vol. 16, pp. 365–388, 1989.
[5] H. Heijmans and L. Vincent, “Graph morphology in image analysis,” in Mathematical morphology in image processing, E. Dougherty, Ed. New York: Marcel Dekker, 1993, vol. 34, ch. 6, pp. 171–203.
[6] A. X. Falcão, R. A. Lotufo, and G. Araujo, “The image foresting transformation,” IEEE PAMI, vol. 26, no. 1, pp. 19–29, 2004.
[7] F. Meyer and R. Lerallut, “Morphological operators for flooding, leveling and filtering images using graphs,” in Graph-based Representations in Pattern Recognition (GbRPR’07), vol. LNCS 4538, 2007, pp. 158–167.
[8] F. Meyer and J. Angulo, “Micro-viscous morphological operators,” in Mathematical Morphology and its Application to Signal and Image Processing (ISMM 2007), 2007, pp. 165–176.
[9] V.-T. Ta, A. Elmoataz, and O. Lézoray, “Partial difference equations over graphs: Morphological processing of arbitrary discrete data,” in ECCV 2008, ser. Lecture Notes in Computer Science, D. Forsyth, P. Torr, and A. Zisserman, Eds. Springer Berlin / Heidelberg, 2008, vol. 5304, pp. 668–680.
[10] J. Cousty, L. Najman, and J. Serra, “Some morphological operators in graph spaces,” in International Symposium on Mathematical Morphology 2009, ser. LNCS, vol. 5720. Springer Verlag, Aug. 2009, pp. 149–160.
[11] I. Bloch and A. Bretto, “Mathematical morphology on hypergraphs: Preliminary definitions and results,” in Discrete Geometry for Computer Imagery, ser. Lecture Notes in Computer Science, I. Debled-Rennesson, E. Domenjoud, B. Kerautret, and P. Even, Eds. Springer Berlin / Heidelberg, 2011, vol. 6607, pp. 429–440.
[12] F. Dias, J. Cousty, and L. Najman, “Some morphological operators on simplicial complexes spaces,” in DGCI 2011, ser. LNCS, no. 6607. Springer, 2011, pp. 441–452.
[13] J. Cousty, G. Bertrand, L. Najman, and M. Couprie, “Watershed Cuts: Minimum Spanning Forests and the Drop of Water Principle,” IEEE PAMI, vol. 31, no. 8, pp. 1362–1374, Aug. 2009.
[14] J. Cousty and L. Najman, “Incremental algorithm for hierarchical minimum spanning forests and saliency of watershed cuts,” in ISMM 2011, ser. LNCS, no. 6671, 2011, pp. 272–283.
[15] C. Couprie, L. Grady, L. Najman, and H. Talbot, “Power Watersheds: A Unifying Graph Based Optimization Framework,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 33, no. 7, pp. 1384–1399, July 2011, http://doi.ieeecomputersociety.org/10.1109/TPAMI.2010.200. [Online]. Available: http://powerwatershed.sourceforge.net/
[16] P. Soille, Morphological Image Analysis. Springer-Verlag, 1999.
[17] L. Najman and H. Talbot, Eds., Mathematical morphology: from theory to applications. ISTE-Wiley, June 2010.
[18] Nesetril, Milkova, and Nesetrilova, “Otakar Boruvka on Minimum Spanning Tree problem: Translation of both the 1926 papers, comments, history,” DMATH: Discrete Mathematics, vol. 233, 2001.
[19] G. Choquet, “étude de certains réseaux de routes,” Comptes-rendus de l’Acad. des Sciences, pp. 310–313, 1938.
[20] C. Zahn, “Graph-theoretical methods for detecting and descibing Gestalt clusters,” IEEE Transactions on Computers, vol. C-20, no. 1, pp. 99–112, 1971.
[21] O. J. Morris, M. d. J. Lee, and A. G. Constantinides, “Graph theory for image analysis: an approach based on the shortest spanning tree,” IEE Proc. on Communications, Radar and Signal, vol. 133, no. 2, pp. 146–152, 1986.
[22] F. Meyer, “Minimum spanning forests for morphological segmentation,” in Procs. of the second international conference on Mathematical Morphology and its Applications to Image Processing, September 1994, pp. 77–84.
[23] P. Felzenszwalb and D. Huttenlocher, “Efficient graph-based image segmentation,” International Journal of Computer Vision, vol. 59, pp. 167–181, 2004.
[24] L. Vincent and P. Soille, “Watersheds in digital spaces: An efficient algorithm based on immersion simulations,” IEEE PAMI, vol. 13, no. 6, pp. 583–598, June 1991.
[25] G. Birkhoff, Lattice Theory, ser. American Mathematical Society Colloquium Publications. American Mathematical Society, 1995, vol. 25.
[26] C. Ronse and J. Serra, “Algebric foundations of morphology,” in Mathematical Morphology, L. Najman and H. Talbot, Eds. ISTE-Wiley, 2010, pp. 35–79.
[27] P. Salembier and J. Serra, “Flat zones filtering, connected operators, and filters by reconstruction,” IEEE TIP, vol. 4, no. 8, pp. 1153–1160, Aug 1995.
[28] C. Ronse, “Set-theoretical algebraic approaches to connectivity in continuous or digital spaces,” JMIV, vol. 8, no. 1, pp. 41–58, 1998.
[29] U. Braga-Neto and J. Goutsias, “Connectivity on complete lattices: new results,” Comput. Vis. Image Underst., vol. 85, no. 1, pp. 22–53, 2002.
[30] G. K. Ouzounis and M. H. Wilkinson, “Mask-based second-generation connectivity and attribute filters,” IEEE PAMI, vol. 29, no. 6, pp. 990–1004, 2007.
[31] R. K. Gabriel and R. R. Sokal, “A new statistical approach to geographic variation analysis,” Systematic Zoology, vol. 18, no. 3, pp. 259–278, Sep. 1969.
[32] P. Salembier, A. Oliveras, and L. Garrido, “Anti-extensive connected operators for image and sequence processing,” IEEE TIP, vol. 7, no. 4, pp. 555–570, April 1998.
[33] L. Najman and M. Couprie, “Building the component tree in quasi-linear time,” IEEE TIP, vol. 15, no. 11, pp. 3531–3539, 2006.
[34] P. Salembier and L. Garrido, “Binary partition tree as an efficient representation for image processing, segmentation and information retrieval,” IEEE Transactions on Image Processing, vol. 9, no. 4, pp. 561–576, Apr. 2000.
[35] V. Caselles and P. Monasse, Geometric Description of Images as Topographic Maps, ser. Lecture Notes in Computer Science. Springer, 2010, vol. 1984.
[36] P. Salembier, “Connected operators based on tree pruning strategies,” in Mathematical morphology:from theory to applications, L. Najman and H. Talbot, Eds. ISTE-Wiley, 2010, pp. 179–198.
[37] J. Benzécri, L’Analyse des données: la Taxinomie. Dunod, 1973, vol. 1.
[38] B. Leclerc, “Description combinatoire des ultramétriques,” Mathématique et sciences humaines, vol. 73, pp. 5–37, 1981.
[39] N. Jardine and R. Sibson, Mathematical taxonomy. Wiley, 1971.
[40] J. Gower and G. Ross, “Minimum spanning tree and single linkage cluster analysis,” Appl. Stats., vol. 18, pp. 54–64, 1969.
[41] J. B. Kruskal, “On the shortest spanning subtree of a graph and the traveling salesman problem,” Proceedings of the American Mathematical Society, vol. 7, pp. 48–50, February 1956.
[42] F. Meyer and S. Beucher, “Morphological segmentation,” JVCIR, vol. 1, no. 1, pp. 21–46, Sept. 1990.
[43] S. Beucher and F. Meyer, “The morphological approach to segmentation: the watershed transformation,” in Mathematical morphology in image processing, ser. Optical Engineering, E. Dougherty, Ed. New York: Marcel Dekker, 1993, vol. 34, ch. 12, pp. 433–481.
[44] L. Najman and M. Schmitt, “Watershed of a continuous function,” Signal Processing, vol. 38, no. 1, pp. 99–112, 1994.
[45] J. B. T. M. Roerdink and A. Meijster, “The watershed transform: Definitions, algorithms and parallelization strategies,” Fundamenta Informaticae, vol. 41, no. 1–2, pp. 187–228, 2001.
[46] G. Bertrand, “On topological watersheds,” JMIV, vol. 22, no. 2–3, pp. 217–230, May 2005.
[47] J. Cousty, G. Bertrand, L. Najman, and M. Couprie, “Watershed cuts: thinnings, shortest-path forests and topological watersheds,” IEEE PAMI, vol. 32, no. 5, pp. 925–939, 2010.
[48] F. Meyer, “Topographic distance and watershed lines,” Signal Processing, vol. 38, no. 1, pp. 113–125, July 1994.
[49] P. Soille and C. Gratin, “An efficient algorithm for drainage networks extraction on DEMs,” Journal of Visual Communication and Image Representation, vol. 5, no. 2, pp. 181–189, June 1994.
[50] S. Philipp-Foliguet, M. Jordan, L. Najman, and J. Cousty, “Artwork 3D Model Database Indexing and Classification,” Pattern Recogn., vol. 44, no. 3, pp. 588–597, Mar. 2011.
[51] L. J. Grady and J. R. Polimeni, Discrete Calculus: Applied Analysis on Graphs for Computational Science, 1st ed. Springer, Aug. 2010.
[52] P. J. Basser, J. Mattiello, and D. LeBihan, “MR diffusion tensor spectroscopy and imaging.” Biophys. J., vol. 66, no. 1, pp. 259–267, 1994.
[53] V. Arsigny, P. Fillard, X. Pennec, and N. Ayache, “Log-Euclidean metrics for fast and simple calculus on diffusion tensors,” Magnetic Resonance in Medicine, vol. 56, no. 2, pp. 411–421, August 2006.
[54] J. Cousty, L. Najman, M. Couprie, S. Clément-Guinaudeau, T. Goissen, and J. Garot, “Segmentation of 4D cardiac MRI: automated method based on spatio-temporal watershed cuts,” IVC, vol. 28, no. 8, pp. 1229–1243, Aug. 2010.
[55] F. Meyer, “The dynamics of minima and contours,” in Mathematical Morphology and its Applications to Image and Signal Processing, P. Maragos, R. Schafer, and M. Butt, Eds. Boston: Kluwer, 1996, pp. 329–336.
[56] L. Najman and M. Schmitt, “Geodesic saliency of watershed contours and hierarchical segmentation,” IEEE PAMI, vol. 18, no. 12, pp. 1163–1173, December 1996.
[57] L. Guigues, J. P. Cocquerez, and H. L. Men, “Scale-sets image analysis,” IJCV, vol. 68, no. 3, pp. 289–317, 2006.
[58] P. A. Arbeláez and L. D. Cohen, “A metric approach to vector-valued image segmentation,” IJCV, vol. 69, no. 1, pp. 119–126, 2006.
[59] F. Meyer and L. Najman, “Segmentation, minimum spanning tree and hierarchies,” in Mathematical Morphology: from theory to application, L. Najman and H. Talbot, Eds. London: ISTE-Wiley, 2010, ch. 9, pp. 229–261.
[60] L. Najman, “On the equivalence between hierarchical segmentations and ultrametric watersheds,” Journal of Mathematical Imaging and Vision, vol. 40, no. 3, pp. 231–247, July 2011, arXiv:1002.1887v2. [Online]. Available: http://www.laurentnajman.org
[61] C. Allène, J.-Y. Audibert, M. Couprie, and R. Keriven, “Some links between extremum spanning forests, watersheds and min-cuts,” IVC, vol. 28, no. 10, pp. 1460–1471, Oct. 2010.
[62] C. Vachier and F. Meyer, “Extinction value: a new measurement of persistence,” in IEEE Workshop on Nonlinear Signal and Image Processing, 1995, pp. 254–257.
[63] G. Bertrand, “On the dynamics,” IVC, vol. 25, no. 4, pp. 447–454, 2007.
[64] S. Beucher, “Watershed, hierarchical segmentation and waterfall algorithm,” in Mathematical Morphology and its Applications to Image Processing, J. Serra and P. Soille, Eds. Kluwer Academic Publishers, 1994, pp. 69–76.
[65] L. Grady, “Random walks for image segmentation,” IEEE PAMI, vol. 28, no. 11, pp. 1768–1783, 2006.
[66] A. K. Sinop and L. Grady, “A seeded image segmentation framework unifying graph cuts and random walker which yields a new algorithm,” in Proc. of ICCV’07, 2007.
[67] G. Peyre, M. Pechaud, R. Keriven, and L. Cohen, “Geodesic methods in computer vision and graphics,” Foundations and Trends in Computer Graphics and Vision, vol. 5, no. 3-4, pp. 197–397, 2010. [Online]. Available: http://hal.archives-ouvertes.fr/hal-00528999/
[68] B. Chazelle, “A minimum spanning tree algorithm with inverse-Ackermann type complexity,” Journal of the ACM, vol. 47, pp. 1028–1047, 2000.
[69] C. Couprie, X. Bresson, L. Najman, H. Talbot, and L. Grady, “Surface reconstruction using power watershed,” in ISMM 2011, ser. LNCS, no. 6671, 2011, pp. 381–392.
[70] C. Couprie, L. Grady, L. Najman, and H. Talbot, “Anisotropic Diffusion Using Power Watersheds,” in International Conference on Image Processing (ICIP’10), Sept. 2010, pp. 4153–4156.
[71] T. Goldstein, X. Bresson, and S. Osher, “Geometric applications of the Split Bregman Method: Segmentation and surface reconstruction,” UCLA, Computational and Applied Mathematics Reports, Tech. Rep. 09-06, 2009.
[72] J. Ye, X. Bresson, T. Goldstein, and S. Osher, “A fast variational method for surface reconstruction from sets of scattered points,” UCLA, Computational and Applied Mathematics Reports, Tech. Rep. 10-01, 2010.
[73] V. Lempitsky and Y. Boykov, “Global Optimization for Shape Fitting,” in Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Minneapolis, USA, 2007.
[74] R. Levillain, T. Géraud, and L. Najman, “Why and How to Design a Generic and Efficient Image Processing Framework: The Case of the Milena Library,” in 17th International Conference on Image Processing, 2010, pp. 1941–1944.