
Appendix D. Using EXPLAIN
This appendix shows you how to invoke EXPLAIN to get information about the query
execution plan, and how to interpret the output. The EXPLAIN command is the main way to find out how
the query optimizer decides to execute queries. This feature has
limitations and doesn’t always tell the truth, but its output is the best
information available, and it’s worth studying so you can learn how your
queries are executed. Learning to interpret EXPLAIN will also help you learn how MySQL’s
optimizer works.
Invoking EXPLAIN
To use EXPLAIN, simply add the
word EXPLAIN just before the SELECT keyword in your query. MySQL will set a
flag on the query. When it executes the query, the flag causes it to
return information about each step in the execution plan, instead of
executing it. It returns one or more rows, which show each part of the
execution plan and the order of execution.
Here’s the simplest possible EXPLAIN result:
mysql> EXPLAIN SELECT 1G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: NULL
type: NULL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: NULL
Extra: No tables usedThere’s one row in the output per table in the query. If the query
joins two tables, there will be two rows of output. An aliased table
counts as a separate table, so if you join a table to itself, there will
be two rows in the output. The meaning of “table” is fairly broad here:
it can mean a subquery, a UNION
result, and so on. You’ll see later why this is so.
There are two important variations on EXPLAIN:
EXPLAIN EXTENDEDappears to behave just like a normalEXPLAIN, but it tells the server to “reverse compile” the execution plan into aSELECTstatement. You can see this generated statement by runningSHOW WARNINGSimmediately afterward. The statement comes directly from the execution plan, not from the original SQL statement, which by this point has been reduced to a data structure. It will not be the same as the original statement in most cases. You can examine it to see exactly how the query optimizer has transformed the statement.EXPLAIN EXTENDEDis available in MySQL 5.0 and newer, and it adds an extrafilteredcolumn in MySQL 5.1 (more on that later).EXPLAIN PARTITIONSshows the partitions the query will access, if applicable. It is available only in MySQL 5.1 and newer.
It’s a common mistake to think that MySQL doesn’t execute a query
when you add EXPLAIN to it. In fact,
if the query contains a subquery in the FROM clause, MySQL actually executes the
subquery, places its results into a temporary table, and then finishes
optimizing the outer query. It has to process all such subqueries before
it can optimize the outer query fully, which it must do for EXPLAIN.[227] This means EXPLAIN can
actually cause a great deal of work for the server if the statement
contains expensive subqueries or views that use the TEMPTABLE algorithm.
Bear in mind that EXPLAIN is an
approximation, nothing more. Sometimes it’s a good approximation, but at
other times, it can be very far from the truth. Here are some of its
limitations:
EXPLAINdoesn’t tell you anything about how triggers, stored functions, or UDFs will affect your query.It doesn’t work for stored procedures, although you can extract the queries manually and
EXPLAINthem individually.It doesn’t tell you about ad hoc optimizations MySQL does during query execution.
Some of the statistics it shows are estimates and can be very inaccurate.
It doesn’t show you everything there is to know about a query’s execution plan. (The MySQL developers are adding more information when possible.)
It doesn’t distinguish between some things with the same name. For example, it uses “filesort” for in-memory sorts and for temporary files, and it displays “Using temporary” for temporary tables on disk and in memory.
It can be misleading. For example, it can show a full index scan for a query with a small
LIMIT. (MySQL 5.1’sEXPLAINshows more accurate information about the number of rows to be examined, but earlier versions don’t takeLIMITinto account.)
Rewriting Non-SELECT Queries
MySQL explains only SELECT queries, not
stored routine calls or INSERT,
UPDATE, DELETE, or any other statements. However,
you can rewrite some non-SELECT
queries to be EXPLAIN-able. To do
this, you just need to convert the statement into an equivalent
SELECT that accesses all the same
columns. Any column mentioned must be in a SELECT list, a join clause, or a WHERE clause.
For example, suppose you want to rewrite the following UPDATE statement to make it EXPLAIN-able:
UPDATE sakila.actor INNER JOIN sakila.film_actor USING (actor_id) SET actor.last_update=film_actor.last_update;
The following EXPLAIN
statement is not equivalent to the UPDATE, because it doesn’t require the
server to retrieve the last_update
column from either table:
mysql>EXPLAIN SELECT film_actor.actor_id->FROM sakila.actor->INNER JOIN sakila.film_actor USING (actor_id)G*************************** 1. row *************************** id: 1 select_type: SIMPLE table: actor type: index possible_keys: PRIMARY key: PRIMARY key_len: 2 ref: NULL rows: 200 Extra: Using index *************************** 2. row *************************** id: 1 select_type: SIMPLE table: film_actor type: ref possible_keys: PRIMARY key: PRIMARY key_len: 2 ref: sakila.actor.actor_id rows: 13 Extra: Using index
This difference is very important. The output shows that MySQL
will use covering indexes, for example,
which it can’t use when retrieving and updating the last_updated
column. The following statement is much closer to the
original:
mysql>EXPLAIN SELECT film_actor.last_update, actor.last_update->FROM sakila.actor->INNER JOIN sakila.film_actor USING (actor_id)G*************************** 1. row *************************** id: 1 select_type: SIMPLE table: actor type: ALL possible_keys: PRIMARY key: NULL key_len: NULL ref: NULL rows: 200 Extra: *************************** 2. row *************************** id: 1 select_type: SIMPLE table: film_actor type: ref possible_keys: PRIMARY key: PRIMARY key_len: 2 ref: sakila.actor.actor_id rows: 13 Extra:
Rewriting queries like this is not an exact science, but it’s often good enough to help you understand what a query will do.[228]
It’s important to understand that there is no such thing as an
“equivalent” read query to show you the plan for a write query. A
SELECT query needs to find only one
copy of the data and return it to you. Any query that modifies data
must find and modify all copies of it, in all indexes. This will often
be much more expensive than what appears to be an equivalent SELECT query.
The Columns in EXPLAIN
EXPLAIN’s output always has the
same columns (except for EXPLAIN
EXTENDED, which adds a filtered column in MySQL 5.1, and EXPLAIN PARTITIONS, which adds a partitions column). The variability is in the
number and contents of the rows. However, to keep our examples clear, we
don’t always show all columns in this appendix.
In the following sections, we show you the meaning of each of the
columns in an EXPLAIN result. Keep in
mind that the rows in the output come in the order in which MySQL
actually executes the parts of the query, which is not always the same
as the order in which they appear in the original SQL.
The id Column
This column always contains a number, which identifies
the SELECT to which the row
belongs. If there are no subqueries or unions in the statement, there
is only one SELECT, so every row
will show a 1 in this column.
Otherwise, the inner SELECT
statements generally will be numbered sequentially, according to their
positions in the original statement.
MySQL divides SELECT queries
into simple and complex types, and the complex types can be grouped
into three broad classes: simple subqueries, so-called derived tables
(subqueries in the FROM
clause),[229] and UNIONs. Here’s a
simple subquery:
mysql> EXPLAIN SELECT (SELECT 1 FROM sakila.actor LIMIT 1) FROM sakila.film;
+----+-------------+-------+...
| id | select_type | table |...
+----+-------------+-------+...
| 1 | PRIMARY | film |...
| 2 | SUBQUERY | actor |...
+----+-------------+-------+...Subqueries in the FROM clause
and UNIONs add more complexity to
the id column. Here’s a basic
subquery in the FROM clause:
mysql> EXPLAIN SELECT film_id FROM (SELECT film_id FROM sakila.film) AS der;
+----+-------------+------------+...
| id | select_type | table |...
+----+-------------+------------+...
| 1 | PRIMARY | <derived2> |...
| 2 | DERIVED | film |...
+----+-------------+------------+...As you know, this query is executed with an anonymous temporary
table. MySQL internally refers to the temporary table by its alias
(der) within the outer query, which
you can see in the ref column in
more complicated queries.
Finally, here’s a UNION
query:
mysql> EXPLAIN SELECT 1 UNION ALL SELECT 1;
+------+--------------+------------+...
| id | select_type | table |...
+------+--------------+------------+...
| 1 | PRIMARY | NULL |...
| 2 | UNION | NULL |...
| NULL | UNION RESULT | <union1,2> |...
+------+--------------+------------+...Note the extra row in the output for the result of the UNION. UNION results are always placed into an
anonymous temporary table, and MySQL then reads the results back out
of the temporary table. The temporary table doesn’t appear in the
original SQL, so its id column is
NULL. In contrast to the preceding
example (illustrating a subquery in the FROM clause), the temporary table that
results from this query is shown as the last row in the results, not
the first.
So far this is all very straightforward, but mixtures of these three categories of statements can cause the output to become more complicated, as we’ll see a bit later.
The select_type Column
This column shows whether the row is a simple or complex
SELECT (and if it’s the latter,
which of the three complex types it is). The value SIMPLE means the query contains no
subqueries or UNIONs. If the query
has any such complex subparts, the outermost part is labeled PRIMARY, and other parts are labeled as
follows:
SUBQUERYA
SELECTthat is contained in a subquery in theSELECTlist (in other words, not in theFROMclause) is labeled asSUBQUERY.DERIVEDThe value
DERIVEDis used for aSELECTthat is contained in a subquery in theFROMclause, which MySQL executes recursively and places into a temporary table. The server refers to this as a “derived table” internally, because the temporary table is derived from the subquery.UNIONThe second and subsequent
SELECTs in aUNIONare labeled asUNION. The firstSELECTis labeled as though it is executed as part of the outer query. This is why the previous example showed the firstSELECTin theUNIONasPRIMARY. If theUNIONwere contained in a subquery in theFROMclause, its firstSELECTwould be labeled asDERIVED.UNION RESULTThe
SELECTused to retrieve results from theUNION’s anonymous temporary table is labeled asUNION RESULT.
In addition to these values, a SUBQUERY and a UNION can be labeled as DEPENDENT and UNCACHEABLE. DEPENDENT means the SELECT depends on data that is found in an
outer query; UNCACHEABLE means
something in the SELECT prevents
the results from being cached with an Item_cache. (Item_cache is undocumented; it is not the
same thing as the query cache, although it can be defeated by some of
the same types of constructs, such as the RAND()
function.)
The table Column
This column shows which table the row is accessing. In most cases, it’s straightforward: it’s the table, or its alias if the SQL specifies one.
You can read this column from top to bottom to see the join order MySQL’s join optimizer chose for the query. For example, you can see that MySQL chose a different join order than the one specified for the following query:
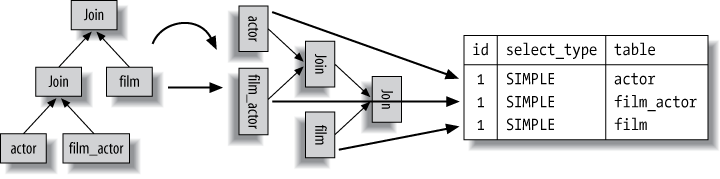
mysql>EXPLAIN SELECT film.film_id->FROM sakila.film->INNER JOIN sakila.film_actor USING(film_id)->INNER JOIN sakila.actor USING(actor_id);+----+-------------+------------+... | id | select_type | table |... +----+-------------+------------+... | 1 | SIMPLE | actor |... | 1 | SIMPLE | film_actor |... | 1 | SIMPLE | film |... +----+-------------+------------+...
Remember the left-deep tree diagrams we showed in Chapter 6? MySQL’s query execution
plans are always left-deep trees. If you flip the plan on its side,
you can read off the leaf nodes in order, and they’ll correspond
directly to the rows in EXPLAIN.
The plan for the preceding query looks like Figure D-1.
Derived tables and unions
The table column
becomes much more complicated when there is a subquery in the
FROM clause or a UNION. In these cases, there really isn’t
a “table” to refer to, because the anonymous temporary table MySQL
creates exists only while the query is executing.
When there’s a subquery in the FROM clause, the table column is of the form <derivedN>,
where N is the subquery’s id. This is always a “forward
reference”—in other words, N refers to a
later row in the EXPLAIN
output.
When there’s a UNION, the
UNION RESULT table column contains a list of ids that participate in the UNION. This is always a “backward
reference,” because the UNION
RESULT comes after all of the rows that participate in the
UNION. If there are more than
about 20 ids in the list, the
table column might be truncated
to keep it from getting too long, and you won’t be able to see all
the values. Fortunately, you can still deduce which rows were
included, because you’ll be able to see the first row’s id. Everything that comes between that row
and the UNION RESULT is included
in some way.
An example of complex SELECT types
Here’s a nonsense query that serves as a fairly compact
example of some of the complex SELECT types:
1 EXPLAIN 2 SELECT actor_id, 3 (SELECT 1 FROM sakila.film_actor WHERE film_actor.actor_id = 4 der_1.actor_id LIMIT 1) 5 FROM ( 6 SELECT actor_id 7 FROM sakila.actor LIMIT 5 8 ) AS der_1 9 UNION ALL 10 SELECT film_id, 11 (SELECT @var1 FROM sakila.rental LIMIT 1) 12 FROM ( 13 SELECT film_id, 14 (SELECT 1 FROM sakila.store LIMIT 1) 15 FROM sakila.film LIMIT 5 16 ) AS der_2;
The LIMIT clauses are just
for convenience, in case you wish to execute the query without EXPLAIN and see the results. Here
is the result of the EXPLAIN:
+------+----------------------+------------+... | id | select_type | table |... +------+----------------------+------------+... | 1 | PRIMARY | <derived3> |... | 3 | DERIVED | actor |... | 2 | DEPENDENT SUBQUERY | film_actor |... | 4 | UNION | <derived6> |... | 6 | DERIVED | film |... | 7 | SUBQUERY | store |... | 5 | UNCACHEABLE SUBQUERY | rental |... | NULL | UNION RESULT | <union1,4> |... +------+----------------------+------------+...
We’ve been careful to make each part of the query access a different table, so you can see what goes where, but it’s still hard to figure out! Taking it from the top:
The first row is a forward reference to
der_1, which the query has labeled as<derived3>. It comes from line 2 in the original SQL. To see which rows in the output refer toSELECTstatements that are part of<derived3>, look forward ......to the second row, whose
idis3. It is3because it’s part of the thirdSELECTin the query, and it’s listed as aDERIVEDtype because it’s nested inside a subquery in theFROMclause. It comes from lines 6 and 7 in the original SQL.The third row’s
idis2. It comes from line 3 in the original SQL. Notice that it comes after a row with a higheridnumber, suggesting that it is executed afterward, which makes sense. It is listed as aDEPENDENT SUBQUERY, which means its results depend on the results of an outer query (also known as a correlated subquery). The outer query in this case is theSELECTthat begins in line 2 and retrieves data fromder_1.The fourth row is listed as a
UNION, which means it is the second or laterSELECTin aUNION. Its table is<derived6>, which means it’s retrieving data from a subquery in theFROMclause and appending to a temporary table for theUNION. As before, to find theEXPLAINrows that show the query plan for this subquery, you must look forward.The fifth row is the
der_2subquery defined in lines 13, 14, and 15 in the original SQL, whichEXPLAINrefers to as<derived6>.The sixth row is an ordinary subquery in
<derived6>’sSELECTlist. Itsidis7, which is important......because it is greater than
5, which is the seventh row’sid. Why is this important? Because it shows the boundaries of the<derived6>subquery. WhenEXPLAINoutputs a row whoseSELECTtype isDERIVED, it represents the beginning of a “nested scope.” If a subsequent row’sidis smaller (in this case,5is smaller than6), it means the nested scope has closed. This lets us know that the seventh row is part of theSELECTlist that is retrieving data from<derived6>—i.e., part of the fourth row’sSELECTlist (line 11 in the original SQL). This example is fairly easy to understand without knowing the significance and rules of nested scopes, but sometimes it’s not so easy. The other notable thing about this row in the output is that it is listed as anUNCACHEABLE SUBQUERYbecause of the user variable.Finally, the last row is the
UNION RESULT. It represents the stage of reading the rows from theUNION’s temporary table. You can begin at this row and work backward if you wish; it is returning results from rows whoseids are1and4, which are in turn references to<derived3>and<derived6>.
As you can see, the combination of these complicated SELECT types can result in EXPLAIN output that’s pretty difficult to
read. Understanding the rules makes it easier, but there’s no
substitute for practice.
Reading EXPLAIN’s output
often requires you to jump forward and backward in the list. For
example, look again at the first row in the output. There is no way
to know just by looking at it that it is part of a UNION. You’ll only see that when you read
the last row of the output.
The type Column
The MySQL manual says this column shows the “join type,” but we think it’s more accurate to say the access type—in other words, how MySQL has decided to find rows in the table. Here are the most important access methods, from worst to best:
ALLThis is what most people call a table scan. It generally means MySQL must scan through the table, from beginning to end, to find the row. (There are exceptions, such as queries with
LIMITor queries that display “Using distinct/not exists” in theExtracolumn.)indexThis is the same as a table scan, except MySQL scans the table in index order instead of the rows. The main advantage is that this avoids sorting; the biggest disadvantage is the cost of reading an entire table in index order. This usually means accessing the rows in random order, which is very expensive.
If you also see “Using index” in the
Extracolumn, it means MySQL is using a covering index and scanning only the index’s data, not reading each row in index order. This is much less expensive than scanning the table in index order.rangeA range scan is a limited index scan. It begins at some point in the index and returns rows that match a range of values. This is better than a full index scan because it doesn’t go through the entire index. Obvious range scans are queries with a
BETWEENor>in theWHEREclause.When MySQL uses an index to look up lists of values, such as
IN()andORlists, it also displays it as a range scan. However, these are quite different types of accesses, and they have important performance differences. See the sidebar What Is a Range Condition? in Chapter 5 for more information.The same cost considerations apply for this type as for the
indextype.refThis is an index access (sometimes called an index lookup) that returns rows that match a single value. However, it might find multiple rows, so it’s a mixture of a lookup and a scan. This type of index access can happen only on a nonunique index or a nonunique prefix of a unique index. It’s called
refbecause the index is compared to some reference value. The reference value is either a constant or a value from a previous table in a multiple-table query.The
ref_or_nullaccess type is a variation onref. It means MySQL must do a second lookup to findNULLentries after doing the initial lookup.eq_refThis is an index lookup that MySQL knows will return at most a single value. You’ll see this access method when MySQL decides to use a primary key or unique index to satisfy the query by comparing it to some reference value. MySQL can optimize this access type very well, because it knows it doesn’t have to estimate ranges of matching rows or look for more matching rows after it finds one.
const,systemMySQL uses these access types when it can optimize away some part of the query and turn it into a constant. For example, if you select a row’s primary key by placing its primary key into the
WHEREclause, MySQL can convert the query into a constant. It then effectively removes the table from the join execution.NULLThis access method means MySQL can resolve the query during the optimization phase and will not even access the table or index during the execution stage. For example, selecting the minimum value from an indexed column can be done by looking at the index alone and requires no table access during execution.
The possible_keys Column
This column shows which indexes could be used for the query, based on the columns the query accesses and the comparison operators used. This list is created early in the optimization phase, so some of the indexes listed might be useless for the query after subsequent optimization phases.
The key Column
This column shows which index MySQL decided to use to
optimize the access to the table. If the index doesn’t appear in
possible_keys, MySQL chose it for
another reason—for example, it
might choose a covering index even when there is no WHERE clause.
In other words, possible_keys
reveals which indexes can help make row lookups
efficient, but key shows
which index the optimizer decided to use to minimize query
cost (see Chapter 6
for more on the optimizer’s cost metrics). Here’s an example:
mysql> EXPLAIN SELECT actor_id, film_id FROM sakila.film_actorG
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: film_actor
type: index
possible_keys: NULL
key: idx_fk_film_id
key_len: 2
ref: NULL
rows: 5143
Extra: Using indexThe key_len Column
This column shows the number of bytes MySQL will use in
the index. If MySQL is using only some of the index’s columns, you can
use this value to calculate which columns it uses. Remember that MySQL
5.5 and older versions can use only the leftmost prefix of the index.
For example, sakila.film_actor’s
primary key covers two SMALLINT
columns, and a SMALLINT is two
bytes, so each tuple in the index is four bytes. Here’s a sample
query:
mysql> EXPLAIN SELECT actor_id, film_id FROM sakila.film_actor WHERE actor_id=4;
...+------+---------------+---------+---------+...
...| type | possible_keys | key | key_len |...
...+------+---------------+---------+---------+...
...| ref | PRIMARY | PRIMARY | 2 |...
...+------+---------------+---------+---------+...Based on the key_len column
in the result, you can deduce that the query performs index lookups
with only the first column, the actor_id. When calculating column usage, be
sure to account for character sets in character columns:
mysql>CREATE TABLE t (->a char(3) NOT NULL,->b int(11) NOT NULL,->c char(1) NOT NULL,->PRIMARY KEY (a,b,c)->) ENGINE=MyISAM DEFAULT CHARSET=utf8 ;mysql>INSERT INTO t(a, b, c)->SELECT DISTINCT LEFT(TABLE_SCHEMA, 3), ORD(TABLE_NAME),->LEFT(COLUMN_NAME, 1)->FROM INFORMATION_SCHEMA.COLUMNS:mysql>EXPLAIN SELECT a FROM t WHERE a='sak' AND b = 112;...+------+---------------+---------+---------+... ...| type | possible_keys | key | key_len |... ...+------+---------------+---------+---------+... ...| ref | PRIMARY | PRIMARY | 13 |... ...+------+---------------+---------+---------+...
The length of 13 bytes in this query is the sum of the lengths
of the a and b columns. Column a is three characters, which in utf8 require up to three bytes each, and
column b is a four-byte
integer.
MySQL doesn’t always show you how much of an index is really
being used. For example, if you perform a LIKE query with a prefix pattern match, it
will show that the full width of the column is being used.
The key_len column shows the
maximum possible length of the indexed fields, not the actual number
of bytes the data in the table used. MySQL will always show 13 bytes
in the preceding example, even if column a happens to contain no values more than one
character long. In other words, key_len is calculated by looking at the
table’s definition, not the data in the table.
The ref Column
This column shows which columns or constants from
preceding tables are being used to look up values in the index named
in the key column. Here’s an
example that shows a combination of join conditions and aliases.
Notice that the ref column reflects
how the film table is aliased as
f in the query text:
mysql>EXPLAIN->SELECT STRAIGHT_JOIN f.film_id->FROM sakila.film AS f->INNER JOIN sakila.film_actor AS fa->ON f.film_id=fa.film_id AND fa.actor_id = 1->INNER JOIN sakila.actor AS a USING(actor_id);...+-------+...+--------------------+---------+------------------------+... ...| table |...| key | key_len | ref |... ...+-------+...+--------------------+---------+------------------------+... ...| a |...| PRIMARY | 2 | const |... ...| f |...| idx_fk_language_id | 1 | NULL |... ...| fa |...| PRIMARY | 4 | const,sakila.f.film_id |... ...+-------+...+--------------------+---------+------------------------+...
The rows Column
This column shows the number of rows MySQL estimates it will need to read to find the desired rows. This number is per loop in the nested-loop join plan. That is, it’s not just the number of rows MySQL thinks it will need to read from the table; it is the number of rows, on average, MySQL thinks it will have to read to find rows that satisfy the criteria in effect at that point in query execution. (The criteria include constants given in the SQL as well as the current columns from previous tables in the join order.)
This estimate can be quite inaccurate, depending on the table
statistics and how selective the indexes are. It also doesn’t reflect
LIMIT clauses in MySQL 5.0 and
earlier. For example, the following query will not examine 1,022
rows:
mysql> EXPLAIN SELECT * FROM sakila.film LIMIT 1G
...
rows: 1022You can calculate roughly the number of rows the entire query
will examine by multiplying all the rows values together. For example, the
following query might examine approximately 2,600 rows:
mysql>EXPLAIN->SELECT f.film_id->FROM sakila.film AS f->INNER JOIN sakila.film_actor AS fa USING(film_id)->INNER JOIN sakila.actor AS a USING(actor_id);...+------+... ...| rows |... ...+------+... ...| 200 |... ...| 13 |... ...| 1 |... ...+------+...
Remember, this is the number of rows MySQL thinks it will examine, not the number of rows in the result set. Also realize that there are many optimizations, such as join buffers and caches, that aren’t factored into the number of rows shown. MySQL will probably not have to actually read every row it predicts it will. MySQL also doesn’t know anything about the operating system or hardware caches.
The filtered Column
This column is new in MySQL 5.1 and appears when you use
EXPLAIN EXTENDED. It shows a
pessimistic estimate of the percentage of rows that will satisfy some
condition on the table, such as a WHERE clause or a join condition. If you
multiply the rows column by this
percentage, you will see the number of rows MySQL estimates it will
join with the previous tables in the query plan. At the time of this
writing, the optimizer uses this estimate only for the ALL, index, range, and index_merge access methods.
To illustrate this column’s output, we created a table as follows:
CREATE TABLE t1 ( id INT NOT NULL AUTO_INCREMENT, filler char(200), PRIMARY KEY(id) );
We then inserted 1,000 rows into this table, with random text in
the filler column. Its purpose is
to prevent MySQL from using a covering index for the query we’re about
to run:
mysql> EXPLAIN EXTENDED SELECT * FROM t1 WHERE id < 500G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 1000
filtered: 49.40
Extra: Using whereMySQL could use a range access to retrieve all rows with IDs
less than 500 from the table, but it won’t because that would
eliminate only about half the rows. It thinks a table scan is less
expensive. As a result, it uses a table scan and a WHERE clause to filter out rows. It knows
how many rows the WHERE clause will
remove from the result, because of the range access cost estimates.
That’s why the 49.40% value appears in the filtered column.
The Extra Column
This column contains extra information that doesn’t fit into other columns. The MySQL manual documents most of the many values that can appear here; we have referred to many of them throughout this book.
The most important values you might see frequently are as follows:
- “Using index”
This indicates that MySQL will use a covering index to avoid accessing the table. Don’t confuse covering indexes with the
indexaccess type.- “Using where”
This means the MySQL server will post-filter rows after the storage engine retrieves them. Many
WHEREconditions that involve columns in an index can be checked by the storage engine when (and if) it reads the index, so not all queries with aWHEREclause will show “Using where.” Sometimes the presence of “Using where” is a hint that the query can benefit from different indexing.- “Using temporary”
This means MySQL will use a temporary table while sorting the query’s result.
- “Using filesort”
This means MySQL will use an external sort to order the results, instead of reading the rows from the table in index order. MySQL has two filesort algorithms, which you can read about in Chapter 6. Either type can be done in memory or on disk.
EXPLAINdoesn’t tell you which type of filesort MySQL will use, and it doesn’t tell you whether the sort will be done in memory or on disk.- “Range checked for each record (index
map:
N)” This value means there’s no good index, and the indexes will be reevaluated for each row in a join.
Nis a bitmap of the indexes shown inpossible_keysand is redundant.
Tree-Formatted Output
MySQL users often wish they could get EXPLAIN’s output to be formatted as a tree,
showing a more accurate representation of the execution plan. As it is,
EXPLAIN is a somewhat awkward way to
see the execution plan; a tree structure doesn’t fit very well into a
tabular output. The awkwardness is highlighted by the large number of
possible values for the Extra column,
as well as by UNION. UNION is quite unlike every other kind of join
MySQL can do, and it doesn’t fit well into EXPLAIN.
It’s possible, with a good understanding of the rules and
particularities of EXPLAIN, to work
backward to a tree-formatted execution plan. This is quite tedious,
though, and it’s best left to an automated tool. Percona Toolkit
contains pt-visual-explain, which is such a
tool.
Improvements in MySQL 5.6
MySQL 5.6 will include an important enhancement to
EXPLAIN: the ability to explain
queries such as UPDATE, INSERT, and so on. This is very helpful
because although one can convert a DML statement to a quasi-equivalent
SELECT statement and EXPLAIN it, the result will not truly reflect
how the statement executes. While developing and using tools such as
Percona Toolkit’s pt-upgrade that attempt to use that technique,
we’ve found several cases where the optimizer doesn’t follow the code
path we expected when converting statements to SELECT. The ability to EXPLAIN a statement without transforming it to
a SELECT is thus helpful for
understanding what truly happens during execution.
MySQL 5.6 will also include a variety of improvements to the query optimizer and execution engine that allow anonymous temporary tables to be materialized as late as possible, rather than always creating and filling them before optimizing and executing the portions of the query that refer to them. This will allow MySQL to explain queries with subqueries instantly, without having to actually execute the subqueries first.
Finally, MySQL 5.6 will enhance a related area of the optimizer by adding optimizer trace functionality to the server. This will permit the user to view the decisions the optimizer made, as well as the inputs (index cardinality, for example) and the reasons for the decisions. This will be very helpful for understanding not just the execution plan that the server chose, but also why it chose that plan.
[227] This limitation will be lifted in MySQL 5.6.
[228] MySQL 5.6 will permit you to explain non-SELECT queries. Hooray!
[229] The statement “a subquery in the FROM clause is a derived table” is true,
but “a derived table is a subquery in the FROM clause” is false. The term “derived
table” has a broader meaning in SQL.