
Chapter 14
Working with Binary Data
IN THIS CHAPTER
![]() Contrasting binary and textual data
Contrasting binary and textual data
![]() Analyzing binary data
Analyzing binary data
![]() Understanding the uses for binary data
Understanding the uses for binary data
![]() Performing binary-related data tasks
Performing binary-related data tasks
The term binary data is an oxymoron because as far as the computer is concerned, only binary data exists. Binary data is the data that people associate with a nonhuman-readable form; the data is a series of seemingly unrelated 0s and 1s that somehow form patterns the computer sees as data, despite the human inability to do so in many cases — at least, not without analysis. Consequently, when this chapter contrasts textual data to binary data, it does so from the human perspective, which means that data must be readable and understandable by humans to be meaningful. Of course, with computer assistance, binary data is also quite meaningful, but in a different way from text. This chapter begins by helping you understand the need and uses for binary data.
The days of worrying about data usage at the bit level are long gone, but binary data, in which individual bits do matter, still appears as part of data analysis. The search for patterns in data isn’t limited to human-readable form, nor is the output from an analysis always in human-readable form, even when the input is. Consequently, you need to understand the role of the binary form in data analysis. As part of understanding why functional programming is so important, this chapter considers the use of binary data in data analysis.
Binary data also appears in many human-pleasing forms. For example, raster graphic files rely exclusively on binary data for the data-storage part of the file. The conversion of a human-readable file to a compressed form also appears as binary data until you decompress it. This chapter explores a few of these forms of binary data. The chapter doesn't explore binary file forms in any depth, but you do get an overview of them.
Comparing Binary to Textual Data
Chapter 13 discusses textual data. All the information in that chapter is in a human-readable form. Likewise, most data you encounter directly today is in some human-readable form, much of it textual. However, under the surface lies the binary data that the computer understands. The true difference between binary and textual data is interpretation — that is, how humans see the data (or don’t see it). The letter A is simply the number 65 in disguise when viewed as ASCII.
Oddly enough, the ASCII numeric representation of the letter A isn’t the end of the line. Somewhere, a raster representation of the letter A exists that determines what you see as the letter A in print or onscreen. (The article at https://www.ibm.com/support/knowledgecenter/en/SSLTBW_2.3.0/com.ibm.zos.v2r3.e0zx100/e0z2o00_char_rep.htm discusses raster representations in more detail.) The fact is that the letter A doesn’t actually exist in your computer; you simply see a representation of it that is quite different to the computer.
 When it comes to numeric data, the whole issue of textual versus binary data becomes more complex. The number could appear as text — meaning a sequence of characters expressing a numeric value. The ASCII values 48 through 57 provide the required textual values. Add a decimal point and you have a human-readable, textual number.
When it comes to numeric data, the whole issue of textual versus binary data becomes more complex. The number could appear as text — meaning a sequence of characters expressing a numeric value. The ASCII values 48 through 57 provide the required textual values. Add a decimal point and you have a human-readable, textual number.
However, a numeric value can also appear as a number in various forms that the computer will directly understand (integers) or require to be translated (as in the IEEE 754 floating-point values). Even though integers and floating-point values both appear as 0s and 1s, the human interpretation often differs from the computer interpretation. For example, in a single-precision floating-point value, the computer sees 32-bits of data — just a series of 0s and 1s that mean nothing to the computer. Yet the interpretation requires splitting those bits into one sign bit, 8 exponent bits, and 23 significand bits (see https://www.geeksforgeeks.org/floating-point-representation-basics/ for details).
Underlying all these representations of data that humans create is a binary stream that the computer controls and understands. All the computer sees is 0s and 1s. The computer merely manipulates the stream and, as with any other machine, has no understanding whatsoever of what those 0s and 1s mean. When you work with binary data, what you really do is work with the computer presentation of the human-readable form that you want to express, no matter what form that data may take. All data is binary to the computer. To make the data useful, however, an application must take the binary presentation and translate it in some way to create a form that humans can understand and use.
Also, a particular language makes specific presentations available and controls the manner in which you create and manipulate the presentations. However, no language actually controls the underlying data, which is always in 0s and 1s. A language interacts with the underlying data through libraries, the operating system, and the machine hardware itself. Consequently, all languages share the same underlying data type, which is binary.
Using Binary Data in Data Analysis
Binary data figures strongly in data analysis, where it often indicates a Boolean value — that is, True or False. Some languages use an entire byte (8 bits in most cases) or even a word (16, 32, or 64bits, in most cases) to hold Boolean values because memory is cheap and manipulating individual bits can be time consuming. However, other languages use each bit in a byte or word to indicate truth-values in a form called flags. A few languages provide both options.
The Boolean value often indicates the outcome of a data analysis such as a Bernoulli trial (see http://www.mathwords.com/b/bernoulli_trials.htm for details). In pure functional programming languages, a Bernoulli trial is often expressed as a binomial distribution (see https://hackage.haskell.org/package/statistics-0.14.0.2/docs/Statistics-Distribution-Binomial.html) and the language often provides specific functionality to perform the calculations. When working with impure languages, you can either simulate the effect or rely on a third-party library for support, such as NumPy (see https://docs.scipy.org/doc/numpy/reference/generated/numpy.random.binomial.html for details). The example at http://www.chadfulton.com/topics/bernoulli_trials_classical.html describes the specifics of performing a Bernoulli trial in Python.
 When considering binary data, you need to think about how the calculation you perform can skew any results obtained. For example, many people use the coin toss as an example for explaining the Bernoulli trial. However, it works only when you ignore the possibility of a coin landing on its edge, landing on neither heads or tails. Even though the probability of such a result is incredibly small, a true analysis would consider it a potential output. However, to calculate the result, you must now eschew the use of binary analysis, which would greatly increase calculation times. The point is that data analysis is often an imperfect science, and the person performing the required calculations needs to consider the ramifications of any shortcuts used in the interest of speed.
When considering binary data, you need to think about how the calculation you perform can skew any results obtained. For example, many people use the coin toss as an example for explaining the Bernoulli trial. However, it works only when you ignore the possibility of a coin landing on its edge, landing on neither heads or tails. Even though the probability of such a result is incredibly small, a true analysis would consider it a potential output. However, to calculate the result, you must now eschew the use of binary analysis, which would greatly increase calculation times. The point is that data analysis is often an imperfect science, and the person performing the required calculations needs to consider the ramifications of any shortcuts used in the interest of speed.
Of course, Boolean values (binary data, really) is used for Boolean algebra (see http://mathworld.wolfram.com/BooleanAlgebra.html for details) where the truth value of a particular set of expressions comes as a result of the logical operators applied to the target monads. In many cases, the outcome of such binary analysis sees visual representation as a Hasse diagram (see http://mathworld.wolfram.com/HasseDiagram.html) for details.
Every computer language today has built-in primitives for performing Boolean algebra. However, pure functional languages also have libraries for performing more advanced tasks, such as the Data.Algebra.Boolean Haskell library discussed at http://hackage.haskell.org/package/cond-0.4.1.1/docs/Data-Algebra-Boolean.html. As with other kinds of analysis of this sort, impure languages often rely on third-party libraries, such as the SymPy library for Python discussed at http://docs.sympy.org/latest/modules/logic.html.
This section could easily spend more time on data analysis, but one final consideration is regression analysis of binary variables. Regression analysis takes in a number of analysis types, some of which appear at https://www.analyticsvidhya.com/blog/2015/08/comprehensive-guide-regression/. The most common for binary data are logistic regression (see http://www.statisticssolutions.com/what-is-logistic-regression/) and probit regression (see https://stats.idre.ucla.edu/stata/dae/probit-regression/). Even in this case, pure functional languages tend to provide built-in support, such as the Haskell library found at http://hackage.haskell.org/package/regress-0.1.1/docs/Numeric-Regression-Logistic.html for logistic regression. Of course, third-party counterparts exist for impure languages, such as Python (see http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html).
Understanding the Binary Data Format
As mentioned in earlier sections, the computer manages binary data without understanding it in any way. Moving bits around is a mechanical task. In fact, even the concept of bits is foreign because the hardware sees only differences in voltage between a 0 and a 1. However, to be useful, the binary data must have a format; it must be organized in some manner that creates a pattern. Even text data of the simplest sort has formatting that defines a pattern. One of the best ways to understand how this all works is to actually examine some files using a hexadecimal editor such as XVI32 (http://www.chmaas.handshake.de/delphi/freeware/xvi32/xvi32.htm). Figure 14-1 shows an example of this tool in action using the extremely simple MyData.txt file that you create in Chapter 13.

FIGURE 14-1: Use a product such as XVI32 to understand binary better.
In this case, you see the hexadecimal numbers in the middle pane of the main window and the associated letters in the right pane. The Bit Manipulation dialog box shows the individual bits used to create the hexadecimal value. What the computer sees is those bits and nothing more. However, in looking at this file, you can see the pattern—one character following the next to create words and then sentences. Each sentence ends with a 0D (carriage return) and a 0A (line feed). If you decided that it was in your best interest to do so, you could easily create this file using binary methods, but Chapter 13 shows the easier method of using characters.
Every file on your system has a format of some sort or it wouldn't contain useful information. Even executable files have a format. If you’re working with Windows, many of your executables will rely on the MZ file format described at https://www.fileformat.info/format/exe/corion-mz.htm. Figure 14-2 shows the XVI32.exe executable file (just the bare beginning of it). Notice that the first two letters in the file are MZ, which identify it as an executable that will run under Windows. When a native executable lacks this signature, Windows won’t run it unless it’s part of some other executable format. If you follow the information found on the FileFormat.Info site, you can actually decode the content of this executable to learn more about it. The executable even contains human readable text that you can use to discover some additional information about the application.

FIGURE 14-2: Even executables have a format.
This information is important to the functional programmer because the languages (at least the pure ones) provide the means to interact with bits should the need arise in a mathematical manner. One such library is Data.Bits (http://hackage.haskell.org/package/base-4.11.1.0/docs/Data-Bits.html) for Haskell. The bit manipulation features in Haskell are somewhat better than those found natively in Python (https://wiki.python.org/moin/BitManipulation), but both languages also support third-party libraries to make the process easier. Given a need, you can create your own binary formats to store specific kinds of information, especially the result of various kinds of analysis that can rely on bit-level truth-values.
Of course, you need to remember the common binary formats used to store data. For example, a Joint Photographic Experts Group (JPEG) file uses a binary format (see https://www.fileformat.info/format/jpeg/internal.htm), which has a signature of JFIF (JPEG File Information Format), as shown in Figure 14-3. The use of this signature is similar to the use of the MZ for executable files. A study of the bits used for graphic files can consume a lot of time because so many ways exist to store the information (see https://modassicmarketing.com/understanding-image-file-types). In fact, so many storage methodologies are available for just graphic files that people have divided the formats into groups, such as lossy versus lossless and vector versus raster.
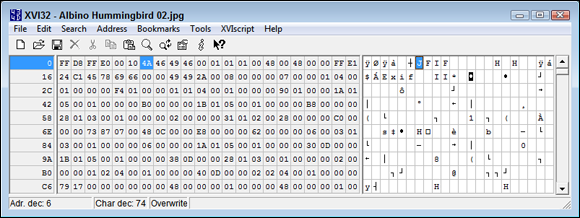
FIGURE 14-3: Many binary files include signatures to make them easier to identify.
Working with Binary Data
So far, this chapter has demonstrated that binary data exists as the only hardware-manipulated data within a computer and that binary data exists in every piece of information you use. You have also discovered that languages generally use abstractions to make the binary data easier to manipulate (such as by using text) and that functional languages have certain advantages when working directly with binary data. The question remains, however, as to why you would want to work directly with binary data when the abstractions exist. For example, you have no reason to create a JPEG file using bits when libraries exist to manipulate them graphically. A human understands the graphics, not the bits. In most cases, you don't manipulate binary data directly unless one of these conditions arises:
- No binary format exists to store custom data containing binary components.
- The storage capabilities of the target device have strict limits on size.
- Transmitting data stored using less efficient methods is too time consuming.
- Translating between common storage forms and the custom form needed to perform a task requires too much time.
- A common storage format file contains an error that self-correction can’t locate and fix.
- You need to perform bit-level data transfers so that you can perform machine control, for example.
- Curiosity mandates studying the file format in detail.
Interacting with Binary Data in Haskell
The examples presented in this section are extremely simple. You can find a considerable number of complex examples online; one appears at http://hackage.haskell.org/package/bytestring-0.10.8.2/docs/Data-ByteString-Builder.html and https://wiki.haskell.org/Serialisation_and_compression_with_Data_Binary. However, most of these examples don’t answer the basic question of what you need to do as a minimum, which is what you find in the following sections. For these cases, you write several data types to a file, examine the file, and then read the data back using the simplest methods possible.
Writing binary data using Haskell
Remember that you have no limitations when working with data in binary mode. You can create any sort of output necessary, even concatenating unlike types together. The best way to create the desired output is to use Builder classes, which contain the tools necessary to build the output in a manner similar to working with blocks. The Data.Binary.Builder and Data.ByteString.Builder libraries both contain functions that you can use to create any needed output, as shown in the following code:
import Data.Binary.Builder as DB
import Data.ByteString.Builder as DBB
import System.IO as IO
main = do
let x1 = putStringUtf8 "This is binary content."
let y = putCharUtf8 '
'
let z = putCharUtf8 '
'
let x2 = putStringUtf8 "Second line…"
handle <- openBinaryFile "HBinary.txt" WriteMode
hPutBuilder handle x1
hPutBuilder handle y
hPutBuilder handle z
hPutBuilder handle x2
hClose handle
This example uses two functions, putStringUtf8 and putCharUtf8. However, you also have access to functions for working with data types such as integers and floats. In addition, you have access to functions for working in decimal or hexadecimal as needed.
The process for working with the file is similar to working with a text file, but you use the openBinaryFile function instead to place Haskell in binary mode (where it won't interpret your data) versus text mode (where it does interpret things like escape characters). When outputting the values, you use the hPutBuilder function to chain them together. Putting output together like this (or using other, more complex methods) is called serialization. You serialize each of the outputs so that they appear in the file in the right order. As always, close the handle when you finish with it. Figure 14-4 shows the binary output of this application, which includes the carriage return and linefeed control characters.
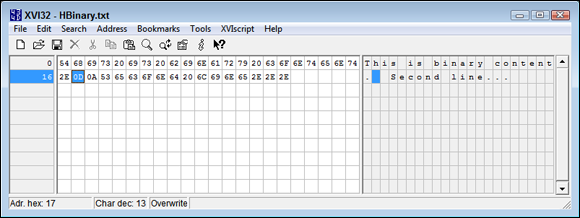
FIGURE 14-4: Even though this output contains text, it could contain any sort of data at all.
Reading binary data using Haskell
This example uses a simplified reading process because the example file does contain text. Even so, the Data.ByteString.Char8 library contains functions for reading specific file lengths. This means that you can read the file a piece at a time to deal with different data types. The process of reading a file and extracting each of the constituent parts is called deserialization. The following code shows how to work with the output of this example in binary mode.
import Data.ByteString.Char8 as DB
import System.IO as IO
main = do
handle <- openBinaryFile "HBinary.txt" ReadMode
x <- DB.hGetContents handle
DB.putStrLn x
hClose handle
Notice that you must precede both hGetContents and putStrLn with DB, which tells Haskell to use the Data.ByteString.Char8 functions. If you don't make this distinction, the application will fail because it won’t be able to determine whether to use DB or IO. However, if you guess wrong and use IO, the application will still fail because you need the functions from DB to read the binary content. Figure 14-5 shows the output from this example.

FIGURE 14-5: The result of reading the binary file is simple text.
Interacting with Binary Data in Python
Python uses a more traditional approach to working with binary files, which can have a few advantages, such as being able to convert data with greater ease and having fewer file management needs. Remember that Haskell, as a pure language, relies on monads to perform tasks and expressions to describe what to do. However, when you review the resulting files, both languages produce precisely the same output, so the issue isn't one of how one language performs the task as contrasted to another, but rather which language provides the functionality you need in the form you need it. The following sections look at how Python works with binary data.
Writing binary data using Python
Python uses a lot of subtle changes to modify how it works with binary data. The following example produces precisely the same output as the Haskell example found in the “Writing binary data using Haskell” section, earlier in this chapter.
handle = open("PBinary.txt", "wb")
print(handle.write(b"This is binary content."))
print(handle.write(bytearray(b'x0Dx0A')))
print(handle.write(b"Second line…"))
handle.close()
When you want to open a file for text-mode writing, in which case the output is interpreted by Python, you use "w". The binary version of writing relies on "wb", where the b provides binary support. Creating binary text is also quite easy; you simply prepend a b to the string you want to write. An advantage to writing in binary mode is that you can mix bytes in with the text by using a type such as bytearray, as shown in this example. The x0D and x0A outputs represent the carriage return and newline control characters. Of course, you always want to close the file handle on exit. The output of this example shows the number of bytes written in each case:
23
2
14
Reading binary data using Python
Reading binary data in Python requires conversion, just as it does in Haskell. Because this example uses pure text (even the control characters are considered text), you can use a simple decode to perform the task, as shown in the following code. Figure 14-6 shows the output of running the example.
handle = open("PBinary.txt", "rb")
binary_data = handle.read()
print(binary_data)
data = binary_data.decode('utf8')
print(data)

FIGURE 14-6: The raw binary data requires decoding before displaying it.