
16. Building Custom Collections
Begin 2.0
Chapter 14 covered the standard query operators—that is, the extension methods on IEnumerable<T> that provide methods common to all collections. However, these operators do not make all collections equally suited for all tasks; there is still a need for different collection types. Some collections are better suited to searching by key, whereas others are better suited to accessing items by position. Some collections act like queues: The first element in is the first out. Others are more like stacks: The first element in is the last out. Others are not ordered at all.
The .NET Framework provides a plethora of collection types suited for many of the scenarios in which collections are needed. This chapter provides an introduction to some of these collection types and the interfaces they implement. It also describes how to create custom-built collections that support standard functionality, such as indexing. In addition, it explores the use of the yield return statement to create classes and methods that implement IEnumerable<T>. This C# 2.0 feature greatly simplifies implementation of collections that can be enumerated with the foreach statement.

Many nongeneric collection classes and interfaces are available in the .NET Framework, but in general these exist today only for backward compatibility with code written before generics came into use. The generic collection types are both faster, because they avoid boxing costs, and more type-safe than the nongeneric collections. Thus, new code should almost always use the generic collection types exclusively. Throughout this book, we assume that you are primarily using generic collection types.
More Collection Interfaces
We’ve already seen how collections implement IEnumerable<T>, the primary interface that enables iteration over the elements of a collection. Many additional interfaces exist that are implemented by more complex collections. Figure 16.1 shows the hierarchy of interfaces implemented by collection classes.

These interfaces provide a standard way to perform common tasks such as iterating, indexing, and counting elements in a collection. This section examines these interfaces (at least all of the generic ones), starting at the bottom of Figure 16.1 and moving upward.
IList<T> versus IDictionary<TKey, TValue>
An English-language dictionary can be thought of as a collection of definitions. A specific definition can be rapidly accessed by looking up its associated “key”—that is, the word being defined. A dictionary collection class is similarly a collection of values, in which each value can be rapidly accessed by using its associated unique key. Note, however, that a language dictionary typically stores the definitions sorted alphabetically by key; a dictionary class might choose to do so but typically does not. Dictionary collections are best thought of as an unordered list of keys and associated values unless specifically documented as being ordered. Similarly, one does not normally think of looking up “the sixth definition in the dictionary”; dictionary classes usually provide indexing only by key, not by position.
A list, by contrast, stores values in a specific order, and accesses them by their position. In a sense, lists are just the special case of dictionaries where the “key” is always an integer and the “key set” is always a contiguous set of non-negative integers starting with zero. Nevertheless, that is a strong enough difference that it is worth having an entirely different type to represent it.
Thus, when selecting a collection class to solve some data storage or retrieval problem, the first two interfaces to look for are IList<T> and IDictionary<TKey, TValue>. These interfaces indicate whether the collection type is focused on retrieval of a value when given its positional index or retrieval of a value when given its associated key.
Both of these interfaces require that a class that implements them provide an indexer. In the case of IList<T>, the operand of the indexer corresponds to the position of the element being retrieved: The indexer takes an integer and gives you access to the nth element in the list. In the case of the IDictionary<TKey, TValue> interface, the operand of the indexer corresponds to the key associated with a value, and gives you access to that value.
ICollection<T>
Both IList<T> and IDictionary<TKey, TValue> implement ICollection<T>. A collection that does not implement either IList<T> or IDictionary<TKey, TValue> will more than likely implement ICollection<T> (although not necessarily, because collections could implement the lesser requirement of IEnumerable or IEnumerable<T>). ICollection<T> is derived from IEnumerable<T> and includes two members: Count and CopyTo().
• The Count property returns the total number of elements in the collection. Initially, it might appear that this would be sufficient to iterate through each element in the collection using a for loop, but, in fact, the collection would also need to support retrieval by index, which the ICollection<T> interface does not include (although IList<T> does include it).
• The CopyTo() method provides the ability to convert the collection into an array. This method includes an index parameter so that you can specify where to insert elements in the target array. To use the method, you must initialize the array target with sufficient capacity, starting at the index, to contain all the elements in ICollection<T>.
Primary Collection Classes
Five key categories of collection classes exist, and they differ from one another in terms of how data is inserted, stored, and retrieved. Each generic class is located in the System.Collections.Generic namespace, and their nongeneric equivalents are found in the System.Collections namespace.
List Collections: List<T>
The List<T> class has properties similar to an array. The key difference is that these classes automatically expand as the number of elements increases. (In contrast, an array size is constant.) Furthermore, lists can shrink via explicit calls to TrimToSize() or Capacity (see Figure 16.2).
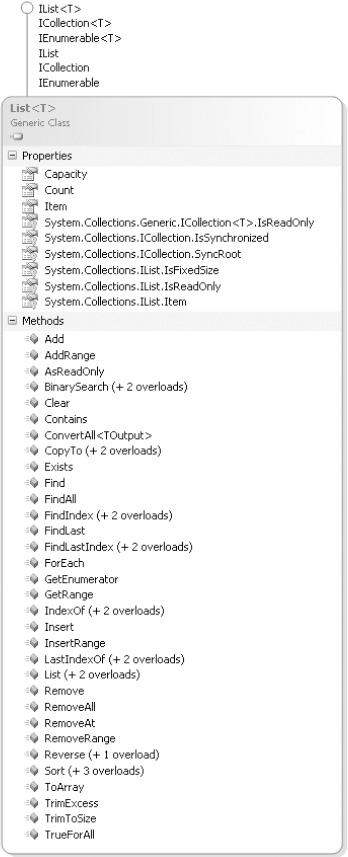
These classes are categorized as list collections whose distinguishing functionality is that each element can be individually accessed by index, just like an array. Therefore, you can set and access elements in the list collection classes using the index operator, where the index parameter value corresponds to the position of an element in the collection. Listing 16.1 shows an example, and Output 16.1 shows the results.
using System;
using System.Collections.Generic;
class Program
{
static void Main()
{
List<string> list = new List<string>();
// Lists automatically expand as elements
// are added.
list.Add("Sneezy");
list.Add("Happy");
list.Add("Dopey");
list.Add("Doc");
list.Add("Sleepy");
list.Add("Bashful");
list.Add("Grumpy");
list.Sort();
Console.WriteLine(
$"In alphabetical order { list[0] } is the "
+ $"first dwarf while { list[6] } is the last.");
list.Remove("Grumpy");
}
}
In alphabetical order Bashful is the first dwarf while Sneezy is the last.
C# is zero-index based; therefore, index 0 in Listing 16.1 corresponds to the first element and index 6 indicates the seventh element. Retrieving elements by index does not involve a search. Rather, it entails a quick and simple “jump” operation to a location in memory.
A List<T> is an ordered collection; the Add() method appends the given item to the end of the list. Before the call to Sort() in Listing 16.1, "Sneezy" was first and "Grumpy" was last; after the call, the list is sorted into alphabetical order, rather than the order in which items were added. Some collections automatically sort elements as they are added, but List<T> is not one of them; an explicit call to Sort() is required for the elements to be sorted.
To remove an element, you use the Remove() or RemoveAt() method, to either remove a given element or remove whatever element is at a particular index, respectively.
Total Ordering
You are required to produce a total order when implementing IComparable<T> or IComparer<T>. Your implementation of CompareTo must provide a fully consistent ordering for any possible pair of items. This ordering is required to have a number of basic characteristics. For example, every element is required to be considered equal to itself. If an element X is considered to be equal to element Y, and element Y is considered to be equal to element Z, all three elements X, Y, and Z must be considered equal to one another. If an element X is considered to be greater than Y, Y must be considered to be less than X. And there must be no “transitivity paradoxes”—that is, you cannot have X greater than Y, Y greater than Z, and Z greater than X. If you fail to provide a total ordering, the action of the sort algorithm is undefined; it may produce a crazy ordering, it may crash, it may go into an infinite loop, and so on.
Notice, for example, how the comparer in Listing 16.2 ensures a total order, even if the arguments are null references. It would not be legal to say, “If either element is null, then return zero,” for example, because then two non-null things could be equal to null but not equal to each other.
Guidelines
DO ensure that custom comparison logic produces a consistent “total order.”
Searching a List<T>
To search List<T> for a particular element, you use the Contains(), IndexOf(), LastIndexOf(), and BinarySearch() methods. The first three methods search through the array, starting at the first element (or the last element for LastIndexOf()), and examine each element until the desired one is found. The execution time for these algorithms is proportional to the number of elements searched before a hit occurs. (Be aware that the collection classes do not require that all the elements within the collection are unique. If two or more elements in the collection are the same, IndexOf() returns the first index and LastIndexOf() returns the last index.)
BinarySearch() uses a much faster binary search algorithm but requires that the elements be sorted. A useful feature of the BinarySearch() method is that if the element is not found, a negative integer is returned. The bitwise complement (~) of this value is the index of the next element larger than the element being sought, or the total element count if there is no greater value. This provides a convenient means to insert new values into the list at the specific location so as to maintain sorting. Listing 16.3 provides an example.
LISTING 16.3: Using the Bitwise Complement of the BinarySearch() Result
using System;
using System.Collections.Generic;
class Program
{
static void Main()
{
List<string> list = new List<string>();
int search;
list.Add("public");
list.Add("protected");
list.Add("private");
list.Sort();
search = list.BinarySearch("protected internal");
if (search < 0)
{
list.Insert(~search, "protected internal");
}
foreach (string accessModifier in list)
{
Console.WriteLine(accessModifier);
}
}
}
Beware that if the list is not first sorted, an element will not necessarily be found with this code, even if it is in the list. The results of Listing 16.3 appear in Output 16.2.
private
protected
protected internal
public
Dictionary Collections: Dictionary<TKey, TValue>
Another category of collection classes is the dictionary classes—specifically, Dictionary<TKey, TValue> (see Figure 16.3). Unlike the list collections, dictionary classes store name/value pairs. The name functions as a unique key that can be used to look up the corresponding element in a manner similar to that of using a primary key to access a record in a database. This adds some complexity to the access of dictionary elements, but because lookups by key are efficient operations, this is a useful collection. Note that the key may be any data type, not just a string or a numeric value.

One option for inserting elements into a dictionary is to use the Add() method, passing both the key and the value, as shown in Listing 16.5.
LISTING 16.5: Adding Items to a Dictionary<TKey, TValue>
using System;
using System.Collections.Generic;
class Program
{
static void Main()
{
// C# 6.0 (use {"Error", ConsoleColor.Red} pre-C# 6.0)
var colorMap = new Dictionary<string, ConsoleColor>
{
["Error"] = ConsoleColor.Red,
["Warning"] = ConsoleColor.Yellow,
["Information"] = ConsoleColor.Green
};
colorMap.Add("Verbose", ConsoleColor.White);
// ...
}
}
After initializing the dictionary with a C# 6.0 dictionary initializer (see the section “Collection Initializers” in Chapter 14), Listing 16.5 inserts the string a ConsoleColor of white for the key of "Verbose." If an element with the same key has already been added, an exception is thrown.
An alternative for adding elements is to use the indexer, as shown in Listing 16.6.
LISTING 16.6: Inserting Items in a Dictionary<TKey, TValue> Using the Index Operator
using System;
using System.Collections.Generic;
class Program
{
static void Main()
{
// C# 6.0 (use {"Error", ConsoleColor.Red} pre-C# 6.0)
var colorMap = new Dictionary<string, ConsoleColor>
{
["Error"] = ConsoleColor.Red,
["Warning"] = ConsoleColor.Yellow,
["Information"] = ConsoleColor.Green
};
colorMap["Verbose"] = ConsoleColor.White;
colorMap["Error"] = ConsoleColor.Cyan;
// ...
}
}
The first thing to observe in Listing 16.6 is that the index operator does not require an integer. Instead, the index operand type is specified by the first type argument (string), and the type of the value that is set or retrieved by the indexer is specified by the second type argument (ConsoleColor).
The second thing to notice in Listing 16.6 is that the same key ("Error") is used twice. In the first assignment, no dictionary value corresponds to the given key. When this happens, the dictionary collection classes insert a new value with the supplied key. In the second assignment, an element with the specified key already exists. Instead of inserting an additional element, the prior ConsoleColor value for the "Error" key is replaced ConsoleColor.Cyan.
Attempting to read a value from a dictionary with a nonexistent key throws a KeyNotFoundException. The ContainsKey() method allows you to check whether a particular key is used before accessing its value, thereby avoiding the exception.
The Dictionary<TKey, TValue> is implemented as a “hash table”; this data structure provides extremely fast access when searching by key, regardless of the number of values stored in the dictionary. By contrast, checking whether there is a particular value in the dictionary collections is a time-consuming operation with linear performance characteristics, much like searching an unsorted list. To do this you use the ContainsValue() method, which searches sequentially through each element in the collection.
You remove a dictionary element using the Remove() method, passing the key, not the element value.
Because both the key and the value are required to add a value to the dictionary, the loop variable of a foreach loop that enumerates elements of a dictionary must be KeyValuePair<TKey, TValue>. Listing 16.7 shows a snippet of code demonstrating the use of a foreach loop to enumerate the keys and values in a dictionary. The output appears in Output 16.3.
LISTING 16.7: Iterating over Dictionary<TKey, TValue> with foreach
using System;
using System.Collections.Generic;
class Program
{
static void Main()
{
// C# 6.0 (use {"Error", ConsoleColor.Red} pre-C# 6.0)
Dictionary<string, ConsoleColor> colorMap =
new Dictionary<string, ConsoleColor>
{
["Error"] = ConsoleColor.Red,
["Warning"] = ConsoleColor.Yellow,
["Information"] = ConsoleColor.Green,
["Verbose"] = ConsoleColor.White
};
Print(colorMap);
}
private static void Print(
IEnumerable<KeyValuePair<string, ConsoleColor>> items)
{
foreach (KeyValuePair<string, ConsoleColor> item in items)
{
Console.ForegroundColor = item.Value;
Console.WriteLine(item.Key);
}
}
}
Error
Warning
Information
Verbose
Note that the order of the items shown here is the order in which the items were added to the dictionary, just as if they had been added to a list. Implementations of dictionaries will often enumerate the keys and values in the order in which they were added to the dictionary, but this feature is neither required nor documented, so you should not rely on it.
Guidelines
DO NOT make any unwarranted assumptions about the order in which elements of a collection will be enumerated. If the collection is not documented as enumerating its elements in a particular order, it is not guaranteed to produce elements in any particular order.
If you want to deal only with keys or only with elements within a dictionary class, they are available via the Keys and Values properties, respectively. The data type returned from these properties is of type ICollection<T>. The data returned by these properties is a reference to the data within the original dictionary collection, rather than a copy; changes within the dictionary are automatically reflected in the collection returned by the Keys and Values properties.
Sorted Collections: SortedDictionary<TKey, TValue> and SortedList<T>
The sorted collection classes (see Figure 16.4) store their elements sorted by key for SortedDictionary<TKey, TValue> and by value for SortedList<T>. If we change the code in Listing 16.7 to use a SortedDictionary<string, string> instead of a Dictionary<string, string>, the output of the program is as appears in Output 16.4.
Error
Information
Verbose
Warning
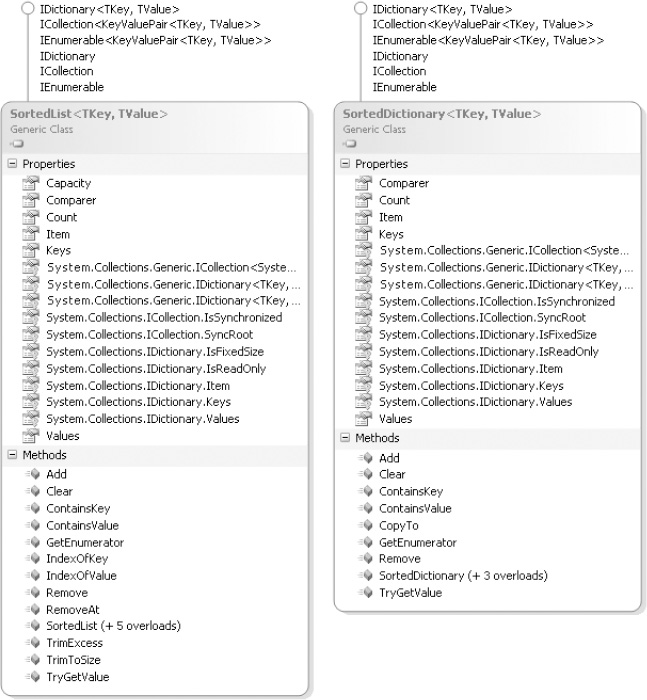
Note that the elements are sorted into order by key, not by value.
Because sorted collections must do extra work to maintain the sorted order of their elements, insertion and removal are typically slightly slower than insertion and removal of values in an unordered dictionary.
Because sorted collections must store their items in a particular order, it is possible to access values both by key and by index. To access a key or value by its index in the sorted list, use the Keys and Values properties. They return IList<TKey> and IList<TValue> instances, respectively; the resultant collection can be indexed like any other list.
Stack Collections: Stack<T>
Chapter 11 discussed the stack collection classes (see Figure 16.5). The stack collection classes are designed as “last in, first out” (LIFO) collections. The two key methods are Push() and Pop().
• Push() inserts elements into the collection. The elements do not have to be unique.
• Pop() removes elements in the reverse order in which they were added.
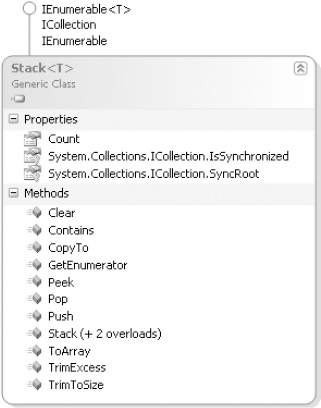
To access the elements on the stack without modifying the stack, you use the Peek() and Contains() methods. The Peek() method returns the next element that Pop() will retrieve.
As with most collection classes, you use the Contains() method to determine whether an element exists anywhere in the stack. As with all collections, it is also possible to use a foreach loop to iterate over the elements in a stack. This allows you to access values from anywhere in the stack. Note, however, that accessing a value via the foreach loop does not remove it from the stack—only Pop() provides this functionality.
Queue Collections: Queue<T>
Queue collection classes, shown in Figure 16.6, are identical to stack collection classes, except that they follow the ordering pattern of “first in, first out” (FIFO). In place of the Pop() and Push() methods are the Enqueue() and Dequeue() methods. The queue collection behaves like a pipe: You place objects into the queue at one end using the Enqueue() method and remove them from the other end using the Dequeue() method. As with stack collection classes, the objects do not have to be unique, and queue collection classes automatically increase in size as required. As a queue shrinks, it does not necessarily reclaim the storage space previously used, because that would make inserting a new element potentially more expensive. If you happen to know that a queue will remain the same size for a long time, however, you can hint to it that you would like to reclaim storage space by using the TrimToSize() method.

Linked Lists: LinkedList<T>
System.Collections.Generic also supports a linked list collection that enables both forward and reverse traversal. Figure 16.7 shows the class diagram. (There is no corresponding nongeneric type.)

Providing an Indexer
Arrays, dictionaries, and lists all provide an indexer as a convenient way to get or set a member of a collection based on a key or index. As we’ve seen, to use the indexer you simply put the index (or indices) in square brackets after the collection name. It is possible to define your own indexer; Listing 16.9 shows an example using Pair<T>.
LISTING 16.9: Defining an Indexer
interface IPair<T>
{
T First { get; }
T Second { get; }
T this[PairItem index] { get; }
}
public enum PairItem
{
First,
Second
}
public struct Pair<T> : IPair<T>
{
public Pair(T first, T second)
{
First = first;
Second = second;
}
public T First { get; } // C# 6.0 Getter-only Autoproperty
public T Second { get; } // C# 6.0 Getter-only Autoproperty
public T this[PairItem index]
{
get
{
switch (index)
{
case PairItem.First:
return First;
case PairItem.Second:
return Second;
default :
throw new NotImplementedException(
string.Format(
"The enum {0} has not been implemented",
index.ToString()));
}
}
}
}
An indexer is declared much as a property is declared, except that instead of the name of the property, you use the keyword this followed by a parameter list in square brackets. The body is also like a property, with get and set blocks. As Listing 16.9 shows, the parameter does not have to be an int. In fact, the index can take multiple parameters and can even be overloaded. This example uses an enum to reduce the likelihood that callers will supply an index for a nonexistent item.
The CIL code that the C# compiler creates from an index operator is a special property called Item that takes an argument. Properties that accept arguments cannot be created explicitly in C#, so the Item property is unique in this aspect. Any additional member with the identifier Item, even if it has an entirely different signature, will conflict with the compiler-created member, so it will not be allowed.
Returning Null or an Empty Collection
When returning an array or collection, you must indicate that there are zero items by returning either null or a collection instance with no items. The better choice in general is to return a collection instance with no items. In so doing, you avoid forcing the caller to check for null before iterating over the items in the collection. For example, given a zero-size IEnumerable<T> collection, the caller can immediately and safely use a foreach loop over the collection without concern that the generated call to GetEnumerator() will throw a NullReferenceException. Consider using the Enumerable.Empty<T>() method to easily generate an empty collection of a given type.
One of the few times to deviate from this guideline is when null is intentionally indicating something different from zero items. For example, a collection of user names for a website might be null to indicate that an up-to-date collection could not be obtained for some reason; that is semantically different from an empty collection.
Guidelines
DO NOT represent an empty collection with a null reference.
CONSIDER using the Enumerable.Empty<T>() method instead.
Iterators
Chapter 14 went into detail on the internals of the foreach loop. This section discusses how to use iterators to create your own implementation of the IEnumerator<T>, IEnumerable<T>, and corresponding nongeneric interfaces for custom collections. Iterators provide clean syntax for specifying how to iterate over data in collection classes, especially using the foreach loop. The iterator allows end users of a collection to navigate its internal structure without knowledge of that structure.
If classes want to support iteration using the foreach loop construct, they must implement the enumerator pattern. As Chapter 14 describes, in C# the foreach loop construct is expanded by the compiler into the while loop construct based on the IEnumerator<T> interface that is retrieved from the IEnumerable<T> interface.
The problem with the enumeration pattern is that it can be cumbersome to implement manually, because it must maintain all the state necessary to describe the current position in the collection. This internal state may be simple for a list collection type class; the index of the current position suffices. In contrast, for data structures that require recursive traversal, such as binary trees, the state can be quite complicated. To mitigate the challenges associated with implementing this pattern, C# 2.0 included a construct that makes it easier for a class to dictate how the foreach loop iterates over its contents.
Defining an Iterator
Iterators are a means to implement methods of a class, and they are syntactic shortcuts for the more complex enumerator pattern. When the C# compiler encounters an iterator, it expands its contents into CIL code that implements the enumerator pattern. As such, there are no runtime dependencies for implementing iterators. Because the C# compiler handles implementation through CIL code generation, there is no real runtime performance benefit to using iterators. However, there is a substantial programmer productivity gain in choosing iterators over manual implementation of the enumerator pattern. To understand improvement, we first consider how an iterator is defined in code.
Iterator Syntax
An iterator provides shorthand implementation of iterator interfaces, the combination of the IEnumerable<T> and IEnumerator<T> interfaces. Listing 16.12 declares an iterator for the generic BinaryTree<T> type by creating a GetEnumerator() method. Next, you will add support for the iterator interfaces.
LISTING 16.12: Iterator Interfaces Pattern
using System;
using System.Collections.Generic;
public class BinaryTree<T>:
IEnumerable<T>
{
public BinaryTree ( T value)
{
Value = value;
}
#region IEnumerable<T>
public IEnumerator<T> GetEnumerator()
{
//...
}
#endregion IEnumerable<T>
public T Value { get; } // C# 6.0 Getter-only Autoproperty
public Pair<BinaryTree<T>> SubItems { get; set; }
}
public struct Pair<T>
{
public Pair(T first, T second) : this()
{
First = first;
Second = second;
}
public T First { get; } // C# 6.0 Getter-only Autoproperty
public T Second { get; } // C# 6.0 Getter-only Autoproperty
}
As Listing 16.12 shows, we need to provide an implementation for the GetEnumerator() method.
Yielding Values from an Iterator
Iterators are like functions, but instead of returning a single value, they yield a sequence of values, one at a time. In the case of BinaryTree<T>, the iterator yields a sequence of values of the type argument provided for T. If the nongeneric version of IEnumerator is used, the yielded values will instead be of type object.
To correctly implement the iterator pattern, you need to maintain some internal state to keep track of where you are while enumerating the collection. In the BinaryTree<T> case, you track which elements within the tree have already been enumerated and which are still to come. Iterators are transformed by the compiler into a “state machine” that keeps track of the current position and knows how to “move itself” to the next position.
The yield return statement yields a value each time an iterator encounters it; control immediately returns to the caller that requested the item. When the caller requests the next item, the code begins to execute immediately following the previously executed yield return statement. In Listing 16.13, you return the C# built-in data type keywords sequentially.
LISTING 16.13: Yielding Some C# Keywords Sequentially
using System;
using System.Collections.Generic;
public class CSharpBuiltInTypes: IEnumerable<string>
{
public IEnumerator<string> GetEnumerator()
{
yield return "object";
yield return "byte";
yield return "uint";
yield return "ulong";
yield return "float";
yield return "char";
yield return "bool";
yield return "ushort";
yield return "decimal";
yield return "int";
yield return "sbyte";
yield return "short";
yield return "long";
yield return "void";
yield return "double";
yield return "string";
}
// The IEnumerable.GetEnumerator method is also required
// because IEnumerable<T> derives from IEnumerable.
System.Collections.IEnumerator
System.Collections.IEnumerable.GetEnumerator()
{
// Invoke IEnumerator<string> GetEnumerator() above.
return GetEnumerator();
}
}
public class Program
{
static void Main()
{
var keywords = new CSharpBuiltInTypes();
foreach (string keyword in keywords)
{
Console.WriteLine(keyword);
}
}
}
The results of Listing 16.13 appear in Output 16.5.
object
byte
uint
ulong
float
char
bool
ushort
decimal
int
sbyte
short
long
void
double
string
The output from this listing is a listing of the C# built-in types.
Iterators and State
When GetEnumerator() is first called in a foreach statement (such as foreach (string keyword in keywords) in Listing 16.13), an iterator object is created and its state is initialized to a special “start” state that represents the fact that no code has executed in the iterator and, therefore, no values have been yielded yet. The iterator maintains its state as long as the foreach statement at the call site continues to execute. Every time the loop requests the next value, control enters the iterator and continues where it left off the previous time around the loop; the state information stored in the iterator object is used to determine where control must resume. When the foreach statement at the call site terminates, the iterator’s state is no longer saved.
It is always safe to call GetEnumerator() again; “fresh” enumerator objects will be created when necessary.
Figure 16.8 shows a high-level sequence diagram of what takes place. Remember that the MoveNext() method appears on the IEnumerator<T> interface.

In Listing 16.13, the foreach statement at the call site initiates a call to GetEnumerator() on the CSharpBuiltInTypes instance called keywords. Given the iterator instance (referenced by iterator), foreach begins each iteration with a call to MoveNext(). Within the iterator, you yield a value back to the foreach statement at the call site. After the yield return statement, the GetEnumerator() method seemingly pauses until the next MoveNext() request. Back at the loop body, the foreach statement displays the yielded value on the screen. It then loops back around and calls MoveNext() on the iterator again. Notice that the second time, control picks up at the second yield return statement. Once again, the foreach displays on the screen what CSharpBuiltInTypes yielded and starts the loop again. This process continues until there are no more yield return statements within the iterator. At that point, the foreach loop at the call site terminates because MoveNext() returns false.
More Iterator Examples
Before you modify BinaryTree<T>, you must modify Pair<T> to support the IEnumerable<T> interface using an iterator. Listing 16.14 is an example that yields each element in Pair<T>.
LISTING 16.14: Using yield to Implement BinaryTree<T>
public struct Pair<T>: IPair<T>,
IEnumerable<T>
{
public Pair(T first, T second) : this()
{
First = first;
Second = second;
}
public T First { get; } // C# 6.0 Getter-only Autoproperty
public T Second { get; } // C# 6.0 Getter-only Autoproperty
#region IEnumerable<T>
public IEnumerator<T> GetEnumerator()
{
yield return First;
yield return Second;
}
#endregion IEnumerable<T>
#region IEnumerable Members
System.Collections.IEnumerator
System.Collections.IEnumerable.GetEnumerator()
{
return GetEnumerator();
}
#endregion
}
In Listing 16.14, the iteration over the Pair<T> data type loops twice: first through yield return First, and then through yield return Second. Each time the yield return statement within GetEnumerator() is encountered, the state is saved and execution appears to “jump” out of the GetEnumerator() method context and into the loop body. When the second iteration starts, GetEnumerator() begins to execute again with the yield return Second statement.
System.Collections.Generic.IEnumerable<T> inherits from System.Collections.IEnumerable. Therefore, when implementing IEnumerable<T>, it is also necessary to implement IEnumerable. In Listing 16.14, you do so explicitly, and the implementation simply involves a call to IEnumerable<T>’s GetEnumerator() implementation. This call from IEnumerable.GetEnumerator() to IEnumerable<T>.GetEnumerator() will always work because of the type compatibility (via inheritance) between IEnumerable<T> and IEnumerable. Since the signatures for both GetEnumerator()s are identical (the return type does not distinguish a signature), one or both implementations must be explicit. Given the additional type safety offered by IEnumerable<T>’s version, you implement IEnumerable’s implementation explicitly.
Listing 16.15 uses the Pair<T>.GetEnumerator() method and displays "Inigo" and "Montoya" on two consecutive lines.
LISTING 16.15: Using Pair<T>.GetEnumerator() via foreach
var fullname = new Pair<string>("Inigo", "Montoya");
foreach (string name in fullname)
{
Console.WriteLine(name);
}
Notice that the call to GetEnumerator() is implicit within the foreach loop.
Placing a yield return within a Loop
It is not necessary to hardcode each yield return statement, as you did in both CSharpPrimitiveTypes and Pair<T>. Using the yield return statement, you can return values from inside a loop construct. Listing 16.16 uses a foreach loop. Each time the foreach within GetEnumerator() executes, it returns the next value.
LISTING 16.16: Placing yield return Statements within a Loop
public class BinaryTree<T>: IEnumerable<T>
{
// ...
#region IEnumerable<T>
public IEnumerator<T> GetEnumerator()
{
// Return the item at this node.
yield return Value;
// Iterate through each of the elements in the pair.
foreach (BinaryTree<T> tree in SubItems)
{
if (tree != null)
{
// Since each element in the pair is a tree,
// traverse the tree and yield each
// element.
foreach (T item in tree)
{
yield return item;
}
}
}
}
#endregion IEnumerable<T>
#region IEnumerable Members
System.Collections.IEnumerator
System.Collections.IEnumerable.GetEnumerator()
{
return GetEnumerator();
}
#endregion
}
In Listing 16.16, the first iteration returns the root element within the binary tree. During the second iteration, you traverse the pair of subelements. If the subelement pair contains a non-null value, you traverse into that child node and yield its elements. Note that foreach (T item in tree) is a recursive call to a child node.
As observed with CSharpBuiltInTypes and Pair<T>, you can now iterate over BinaryTree<T> using a foreach loop. Listing 16.17 demonstrates this process, and Output 16.6 shows the results.
LISTING 16.17: Using foreach with BinaryTree<string>
// JFK
var jfkFamilyTree = new BinaryTree<string>(
"John Fitzgerald Kennedy");
jfkFamilyTree.SubItems = new Pair<BinaryTree<string>>(
new BinaryTree<string>("Joseph Patrick Kennedy"),
new BinaryTree<string>("Rose Elizabeth Fitzgerald"));
// Grandparents (Father's side)
jfkFamilyTree.SubItems.First.SubItems =
new Pair<BinaryTree<string>>(
new BinaryTree<string>("Patrick Joseph Kennedy"),
new BinaryTree<string>("Mary Augusta Hickey"));
// Grandparents (Mother's side)
jfkFamilyTree.SubItems.Second.SubItems =
new Pair<BinaryTree<string>>(
new BinaryTree<string>("John Francis Fitzgerald"),
new BinaryTree<string>("Mary Josephine Hannon"));
foreach (string name in jfkFamilyTree)
{
Console.WriteLine(name);
}
John Fitzgerald Kennedy
Joseph Patrick Kennedy
Patrick Joseph Kennedy
Mary Augusta Hickey
Rose Elizabeth Fitzgerald
John Francis Fitzgerald
Mary Josephine Hannon
Canceling Further Iteration: yield break
Sometimes you might want to cancel further iteration. You can do so by including an if statement so that no further statements within the code are executed. However, you can also use yield break to cause MoveNext() to return false and control to return immediately to the caller and end the loop. Listing 16.18 shows an example of such a method.
LISTING 16.18: Escaping Iteration via yield break
public System.Collections.Generic.IEnumerable<T>
GetNotNullEnumerator()
{
if((First == null) || (Second == null))
{
yield break;
}
yield return Second;
yield return First;
}
This method cancels the iteration if either of the elements in the Pair<T> class is null.
A yield break statement is similar to placing a return statement at the top of a function when it is determined that there is no work to do. It is a way to exit from further iterations without surrounding all remaining code with an if block. As such, it allows multiple exits. Use it with caution, because a casual reading of the code may overlook the early exit.
Creating Multiple Iterators in a Single Class
Previous iterator examples implemented IEnumerable<T>.GetEnumerator()—the method that foreach seeks implicitly. Sometimes you might want different iteration sequences, such as iterating in reverse, filtering the results, or iterating over an object projection other than the default. You can declare additional iterators in the class by encapsulating them within properties or methods that return IEnumerable<T> or IEnumerable. If you want to iterate over the elements of Pair<T> in reverse, for example, you could provide a GetReverseEnumerator() method, as shown in Listing 16.20.
LISTING 16.20: Using yield return in a Method That Returns IEnumerable<T>
public struct Pair<T>: IEnumerable<T>
{
...
public IEnumerable<T> GetReverseEnumerator()
{
yield return Second;
yield return First;
}
...
}
public void Main()
{
var game = new Pair<string>("Redskins", "Eagles");
foreach (string name in game.GetReverseEnumerator())
{
Console.WriteLine(name);
}
}
Note that you return IEnumerable<T>, not IEnumerator<T>. This is different from IEnumerable<T>.GetEnumerator(), which returns IEnumerator<T>. The code in Main() demonstrates how to call GetReverseEnumerator() using a foreach loop.
yield Statement Requirements
You can use the yield return statement only in members that return an IEnumerator<T> or IEnumerable<T> type, or their nongeneric equivalents. Members whose bodies include a yield return statement may not have a simple return. If the member uses the yield return statement, the C# compiler generates the necessary code to maintain the state of the iterator. In contrast, if the member uses the return statement instead of yield return, the programmer is responsible for maintaining his own state machine and returning an instance of one of the iterator interfaces. Further, just as all code paths in a method with a return type must contain a return statement accompanied by a value (assuming they don’t throw an exception), so all code paths in an iterator must contain a yield return statement if they are to return any data.
The following additional restrictions on the yield statement result in compiler errors if they are violated:
• The yield statement may appear only inside a method, a user-defined operator, or the get accessor of an indexer or property. The member must not take any ref or out parameter.
• The yield statement may not appear anywhere inside an anonymous method or lambda expression (see Chapter 12).
• The yield statement may not appear inside the catch and finally clauses of the try statement. Furthermore, a yield statement may appear in a try block only if there is no catch block.
Summary
The generic collection classes and interfaces made available in C# 2.0 are universally superior to their nongeneric counterparts; by avoiding boxing penalties and enforcing type safety at compile time, they execute more rapidly and are safer. Unless you must maintain compatibility with legacy C# 1.0 code, you should consider the entire namespace of System.Collections to be obsolete. In other words, don’t go back and necessarily remove all code that already uses this namespace. Instead, use System.Collections.Generics for any new code and, over time, consider migrating existing code to use the corresponding generic collections that contain both the interfaces and the classes for working with collections of objects.
The introduction of the System.Collections.Generic namespace is not the only change that C# 2.0 brought to collections. Another significant addition is the iterator. Iterators involve a new contextual keyword, yield, that C# uses to generate underlying CIL code that implements the iterator pattern used by the foreach loop.
In the next chapter we explore reflection, a topic briefly touched on earlier, albeit with little to no explanation. Reflection allows one to examine the structure of a type within CIL code at runtime.
End 2.0