
10
Parallel Tasks and Scheduling
When the complexity of the system increases and the software has to manage multiple peripherals and events at the same time, it is more convenient to rely on an operating system to coordinate and synchronize all the different operations. Separating the application logic into different threads offers a few important architectural advantages. Each component performs the designed operation within its running unit, and it may release the CPU while it is suspended, or waiting for input or a timeout event.
In this chapter, the mechanisms used to implement a multithreading embedded operating system will be covered. This will be done through the development of a minimalistic operating system tailored to the reference platform, and written step by step from scratch, providing a working scheduler to run multiple tasks in parallel.
The scheduler’s internals are mostly implemented within system service calls, and its design impacts the system’s performance and other features, such as different priority levels and time constraints for real-time-dependent tasks. Some of the possible scheduling policies, for different contexts, will be explained and implemented in the example code.
Running multiple threads in parallel implies that resources can be shared, and there is the possibility of concurrent access to the same memory. Most microprocessors designed to run multithreading systems provide primitive functions, accessible through specific assembly instructions, to implement locking mechanisms such as semaphores. Our example operating system exposes mutex and semaphore primitives that can be used by the threads to control access to shared resources.
By introducing memory protection mechanisms, it is possible to provide a separation of the resources based on their addresses and let the kernels supervise all the operations involving the hardware through a system call interface. Most real-time embedded operating systems prefer a flat model with no segmentation to keep the kernel code as small as possible, and with a minimal API to optimize the resources available for the applications. The example kernel will show us how to create a system call API to centralize the control of the resources, using physical memory segmentation to protect the resources of the kernel, the system control block, the mapped peripherals, and the other tasks, to increase the level of safety of the system.
This chapter is split into the following sections:
- Task management
- Scheduler implementation
- Synchronization
- System resource separation
By the end of this chapter, you will have learned how to build a multithreaded embedded environment.
Technical requirements
You can find the code files for this chapter on GitHub at https://github.com/PacktPublishing/Embedded-Systems-Architecture-Second-Edition/tree/main/Chapter10.
Task management
An operating system provides the abstraction of parallel running processes and threads by alternating the applications to run in parallel. In fact, on systems with a single CPU, there can only be one running thread at a time. While the running thread executes, all the others are waiting in line until the next task switch.
In a cooperative model, switching the task is always a voluntary action requested by the thread implementation. The opposite approach, known as preemption, requires that the kernel periodically interrupts tasks at any point of their execution, to temporarily save the status and resume the next task in line.
Switching the running task consists of storing the values of the CPU registers in RAM, and loading from memory those of the next task that has been selected for running. This operation is better known as context switching and is the core of the scheduling system.
The task block
Tasks are represented in the system in the form of a task block structure. This object contains all the information needed for the scheduler to keep track of the state of the task at all times and is dependent on the design of the scheduler. Tasks might be defined at compile time and started after the kernel boots, or spawned and terminated while the system is running.
Each task block may contain a pointer to the start function, which defines the beginning of the code that is executed when the task is spawned, and a set of optional arguments. Memory is assigned for each task to use as its private stack region. This way, the execution context of each thread and process is separated from all the others, and the values of the registers can be stored in a task-specific memory area when the task is interrupted. The task-specific stack pointer is stored in the task block structure, and it is used to store the values of the CPU register upon context switches.
Running with separate stacks requires that some memory is reserved in advance, and associated with each task. In the simplest case, all tasks using a stack of the same size are created before the scheduler starts and cannot be terminated. This way, the memory that has been reserved to be associated with private stacks can be contiguous and associated with each new task. The memory region used for the stack areas can be defined in the linker script.
The reference platform has a separate core-coupled memory, mapped at 0x10000000. Among the many ways to arrange the memory sections, we have decided to map the start of the stack space, used to associate stack areas with the threads, at the beginning of the CCRAM. The remaining CCRAM space is used as a stack for the kernel, which leaves all the SRAM, excluding the .data and .bss sections, for heap allocation. The pointers are exported by the linker script with the following PROVIDE instructions:
PROVIDE(_end_stack = ORIGIN(CCRAM) + LENGTH(CCRAM)); PROVIDE(stack_space = ORIGIN(CCRAM)); PROVIDE(_start_heap = _end);
In the kernel source, stack_space is declared as external, because it is exported by the linker script. We also declare the amount of space reserved for the execution stack of each task (expressed in four-byte words):
extern uint32_t stack_space; #define STACK_SIZE (256)
Every time a new task is created, the next kilobyte in the stack space is assigned as its execution stack, and the initial stack pointer is set at the highest address in the area since the execution stack grows backward:
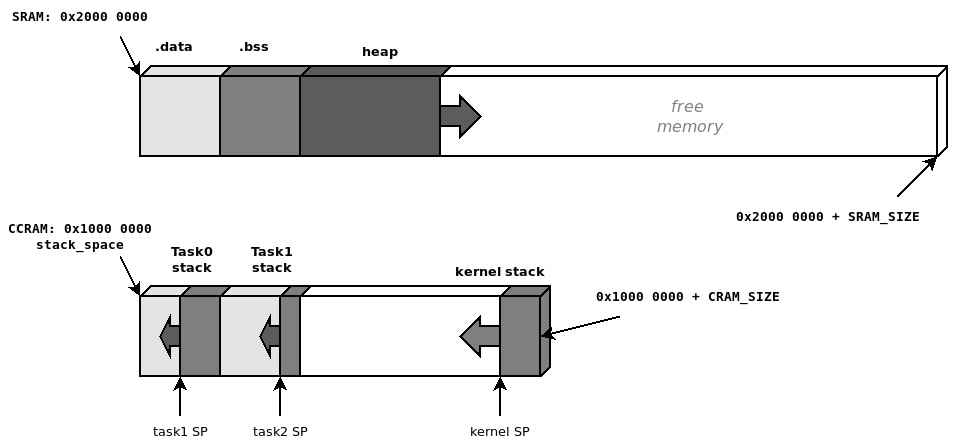
Figure 10.1 – Memory configuration used to provide separate execution stacks to tasks
A simple task block structure can then be declared, as follows:
#define TASK_WAITING 0
#define TASK_READY 1
#define TASK_RUNNING 2
#define TASK_NAME_MAXLEN 16;
struct task_block {
char name[TASK_NAME_MAXLEN];
int id;
int state;
void (*start)(void *arg);
void *arg;
uint32_t *sp;
};A global array is defined to contain all the task blocks of the system. We must use a global index to keep track of the tasks already created so that we can use the position in memory relative to the task identifier and the ID of the currently running task:
#define MAX_TASKS 8 static struct task_block TASKS[MAX_TASKS]; static int n_tasks = 1; static int running_task_id = 0; #define kernel TASKS[0]
With this model, the task block is pre-allocated in the data section, and the fields are initialized in place, keeping track of the index. The first element of the array is reserved for the task block of the kernel, which is the currently running process.
In our example, tasks are created by invoking the task_create function and providing a name, an entry point, and its argument. For a static configuration with a predefined number of tasks, this is done when the kernel is initialized, but more advanced schedulers may allow us to allocate new control blocks to spawn new processes at runtime, while the scheduler is running:
struct task_block *task_create(char *name, void (*start)(void *arg), void *arg)
{
struct task_block *t;
int i;
if (n_tasks >= MAX_TASKS)
return NULL;
t = &TASKS[n_tasks];
t->id = n_tasks++;
for (i = 0; i < TASK_NAME_MAXLEN; i++) {
t->name[i] = name[i];
if (name[i] == 0)
break;
}
t->state = TASK_READY;
t->start = start;
t->arg = arg;
t->sp = ((&stack_space) + n_tasks * STACK_SIZE);
task_stack_init(t);
return t;
}To implement the task_stack_init function, which initializes the values in the stack for the process to start running, we need to understand how the context switch works, and how new tasks are started when the scheduler is running.
Context switch
The context switch procedure consists of getting the values of the CPU register during the execution and saving them at the bottom of the stack of the currently running task. Then, we must restore the values for the next task to resume its execution. This operation must happen in the interrupt context, and its internal mechanisms are CPU-specific. On the reference platform, any interrupt handler can replace the currently running task and restore another context, but this operation is more often done within interrupt service routines associated with system events. Cortex-M provides two CPU exceptions that are designed to provide the basic support for context switching because they can be arbitrarily triggered in any context:
- PendSV: This is the default way for a preemptive kernel to force an interrupt in the immediate future, after setting one bit in a specific register within the system control block, and it is usually associated with the context switch of the next task.
- SVCall: This is the main entry point for the user application to submit a formal request to access a resource that is managed by the kernel. This feature is designed to provide an API to access the kernel safely to request operations from a component or a driver. As the result of the operation may be not immediately available, SVCall can also permit preempting the calling task to provide the abstraction of blocking system calls.
The routines used to store and restore the values of the CPU registers to/from memory during the context switch are partially implemented in hardware on the Cortex-M CPU. This means that, when the interrupt is entered, a copy of part of the register is automatically pushed into the stack. The copy of the registers in the stack is called the stack frame, and contains registers R0 to R3, R12, LR, PC, and xPSR, in the order shown in the following figure:
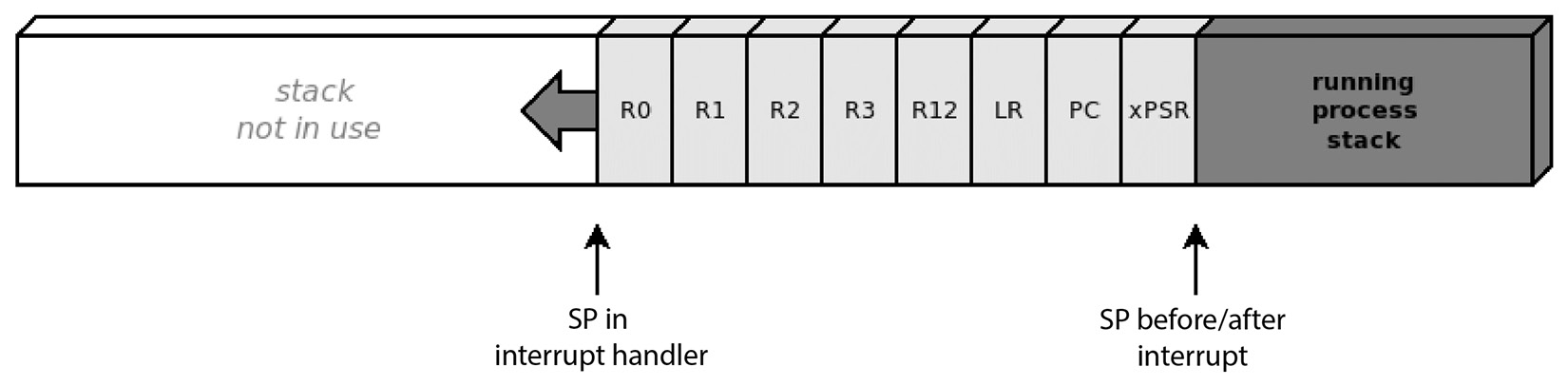
Figure 10.2 – Registers are automatically copied to the stack when entering an interrupt handler
The stack pointer, however, does not include the other half of the CPU registers – that is, R4 to R11. For this reason, to complete the context switch successfully, a system handler that intends to replace the running process must store the extra stack frame containing the value for these registers, and restore the extra stack frame of the next task just before returning from the handler. ARM Thumb-2 assembly provides instructions on how to push the value of contiguous CPU registers to the stack and pop them back in place. The following two functions are used to push and pop the extra stack frame in the stack:
static void __attribute__((naked)) store_context(void)
{
asm volatile("mrs r0, msp");
asm volatile("stmdb r0!, {r4-r11}");
asm volatile("msr msp, r0");
asm volatile("bx lr");
}
static void __attribute__((naked)) restore_context(void)
{
asm volatile("mrs r0, msp");
asm volatile("ldmfd r0!, {r4-r11}");
asm volatile("msr msp, r0");
asm volatile("bx lr");
}The ((naked)) attribute is used to prevent GCC from putting prologue and epilogue sequences, consisting of a few assembly instructions each, into the compiled code. The prologue would change the values of some of the registers in the extra stack frame area, which would be restored in the epilogue, and this conflicts with the purpose of the functions accessing register values using assembly instructions. Due to the missing epilogue, the naked functions return by jumping back to the calling instruction, which is stored in the LR register.
As a result of the assembly push operation, this is how the stack of the process being preempted looks:
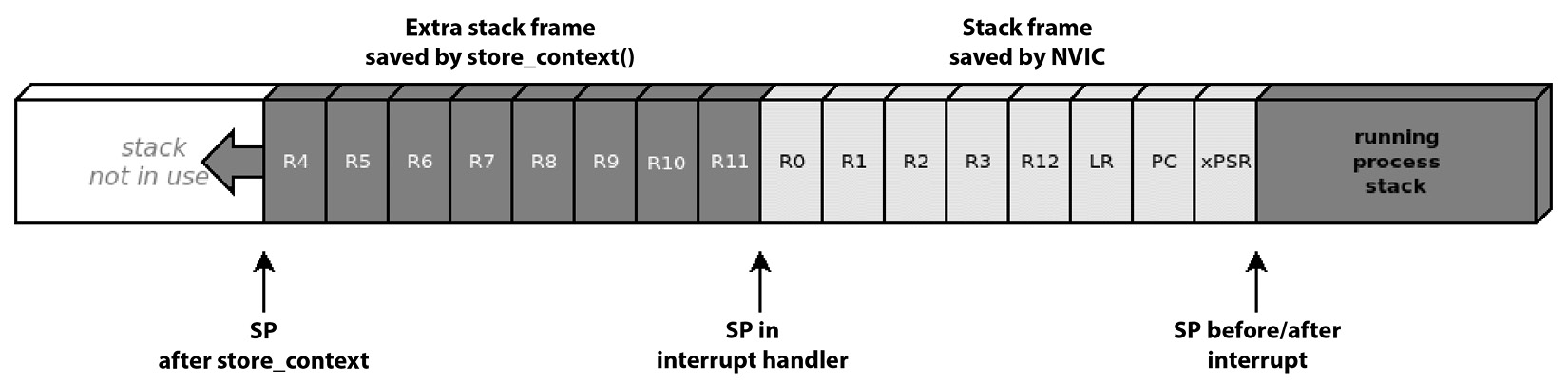
Figure 10.3 – The remaining register values are copied to the stack to complete the context switch
Creating tasks
When the system is running, all the tasks except the one running are in a wait state, which means that the full stack frame is saved at the bottom of the stack, and the stack pointer is stored in the control block to be used by the scheduler to resume each process.
A newly created task will wake up for the first time in the middle of the context switch. At that point, the task is expected to have preserved the previous state of its CPU registers, but obviously, a new task does not have such a thing. Upon stack creation, a forged stack frame is pushed to the end of the stack so that when the task resumes, the values stored are copied into the system registers, and the task can resume from its entry point.
The task_create function relies on a stack initialization function, task_stack_init, which pushes the initial values for the system registers to allow the task to be restored and moves the stored stack pointer to the beginning of the extra frame, which can be left uninitialized. To easily access the stored register in the stack frame, we must declare a stack_frame structure that uses one field per register, and an extra_frame structure, just for completeness:
struct stack_frame {
uint32_t r0, r1, r2, r3, r12, lr, pc, xpsr;
};
struct extra_frame {
uint32_t r4, r5, r6, r7, r8, r9, r10, r11;
};
static void task_stack_init(struct task_block *t)
{
struct stack_frame *tf;
t->sp -= sizeof(struct stack_frame);
tf = (struct stack_frame *)(t->sp);
tf->r0 = (uint32_t) t->arg;
tf->pc = (uint32_t) t->start;
tf->lr = (uint32_t) task_terminated;
tf->xpsr = (1 << 24);
t->sp -= sizeof(struct extra_frame);
}Once the context has been restored, the exception handler return procedure automatically restores the context from the stack frame we are forging. The registers for the starting task are initialized as follows:
- The program counter (PC) contains the address of the start function, where the system will jump to switch to this task for the first time.
- R0-R3 may contain optional arguments to pass to the start function, according to the ABI of the CPU. In our case, we carry the value of the single argument given for the start function by the caller of task_create.
- The execution program status register (xPSR) must be programmed to have only the mandatory thumb flag set at bit 24.
- The link register (LR) contains the pointer to the procedure that is called when the start function returns. In our case, tasks are not allowed to return from the start function, so the task_terminated function is just an infinite loop, and it is considered a system error. In other cases, if tasks are allowed to terminate, a function can be set as a common exit point for the tasks, to perform the cleanup operations required upon returning from the start function.
Once the initial stack frame has been created, the task can participate in multitasking, and can be picked by the scheduler at any time to resume the execution, from the same state as all the other tasks not running:

Figure 10.4 – Stack pointers of three tasks during different execution states
Our simple kernel main function can now create processes and prepare the stack but is not yet actually able to run them until we implement the scheduler internals. Timekeeping is useful in this case, so SysTick is enabled at startup to keep track of time in the system. The task block of the kernel is initialized, and two new tasks are created:
void main(void) {
clock_pll_on(0);
systick_enable();
led_setup();
kernel.name[0] = 0;
kernel.id = 0;
kernel.state = TASK_RUNNING;
task_create("test0",task_test0, NULL);
task_create("test1",task_test1, NULL);
while(1) {
schedule();
}
}The two main tasks are created so that they point to different start functions, and both have NULL as argument. Both functions should never return and can be interrupted and resumed according to the implemented scheduler policy.
To proceed from this point, the scheduler’s internals need to be implemented to start and alternate the execution of the parallel tasks we just defined.
Scheduler implementation
The architecture of the system depends on the way the scheduler is implemented. Tasks can be running in a cooperative model until they voluntarily decide to yield the CPU to the next task, or the OS can decide to trigger an interrupt to swap the running task behind the scenes, applying a specific policy to decide the interval in between task switches and the priority for the selection of the next task. In both cases, the context switch happens within one of the supervisor calls available, set to decide which tasks to schedule next, and to perform the context switch. In this section, the full context switch procedure through PendSV will be added to our example, and then a few of the possible scheduling policies will be analyzed and implemented.
Supervisor calls
The core component of the scheduler consists of the exception handler associated with the system interrupt events, such as PendSV and SVCall. On Cortex-M, a PendSV exception can be triggered at any time by the software by setting the PENDSET flag, corresponding to bit 28 of the interrupt control and state register, located in the SCB at address 0xE000ED04. A simple macro is defined to initiate the context switch by setting the flag:
#define SCB_ICSR (*((volatile uint32_t *)0xE000ED04)) #define schedule() SCB_ICSR |= (1 << 28)
The call to schedule from the kernel, and all the subsequent calls, will cause a context switch, which can now be implemented in the PendSV handler. To complete a context switch, the handler has to perform the following steps:
- Store the current stack pointer from the SP register in the task block.
- Push the extra stack frame to the stack by calling store_context.
- Change the state of the current task to TASK_READY.
- Select a new task to resume.
- Change the state of the new task to TASK_RUNNING.
- Retrieve the new stack pointer from the associated task block.
- Pop the extra stack frame from the stack by calling restore_context.
- Set a special return value for the interrupt handler to activate thread mode at the end of the PendSV service routine.
The isr_pendsv function must be naked because it accesses the CPU register directly through the store and restore_context functions:
void __attribute__((naked)) isr_pendsv(void)
{
store_context();
asm volatile("mrs %0, msp" : "=r"(
TASKS[running_task_id].sp));
TASKS[running_task_id].state = TASK_READY;
running_task_id++;
if (running_task_id >= n_tasks)
running_task_id = 0;
TASKS[running_task_id].state = TASK_RUNNING;
asm volatile("msr msp, %0"::"r"(
TASKS[running_task_id].sp));
restore_context();
asm volatile("mov lr, %0" ::"r"(0xFFFFFFF9));
asm volatile("bx lr");
}The value that is loaded in the LR before returning is used to indicate that we are returning to thread mode at the end of this interrupt. Depending on the value of the last 3 bits, the service routine informs the CPU which stack pointer to use when returning from the interrupt. The 0xFFFFFFF9 value used in this case corresponds to thread mode using the main stack pointer. Different values will be needed later on when the example is expanded to support separate stack pointers between the kernel and the process.
With that, the complete context has been implemented inside the PendSV service routine, which for now is simply selecting the next task and wraps around to execute the kernel with an ID of 0 after the last task in the array. The service routine is triggered to run in handler mode every time the schedule macro is called.
Cooperative scheduler
Different policies can be defined to alternate the execution of the tasks in the system. In the simplest case, the main functions of each task voluntarily suspend its execution by invoking the schedule macro.
In this example implementation, two threads have been defined. Both will turn on an LED and hold the CPU in a busy loop for 1 second before turning off the LED and explicitly calling the schedule() function to trigger a context switch:
void task_test0(void *arg)
{
uint32_t now = jiffies;
blue_led_on();
while(1) {
if ((jiffies - now) > 1000) {
blue_led_off();
schedule();
now = jiffies;
blue_led_on();
}
}
}
void task_test1(void *arg)
{
uint32_t now = jiffies;
red_led_on();
while(1) {
if ((jiffies - now) > 1000) {
red_led_off();
schedule();
now = jiffies;
red_led_on();
}
}
}The little operating system is finally working, and the kernel is scheduling the two tasks in sequence. The task with an ID of 0 is also resumed at the beginning of each loop, but in this simple case, the kernel task is only calling the schedule in a loop, immediately resuming the task with an ID of 1. With this design, the reactivity of the system depends entirely on the implementation of the tasks, as each task can hold the CPU indefinitely, and prevent other tasks from running. The cooperative model is only used in very specific scenarios, where each task is directly responsible for regulating its CPU cycles and cooperating with the other threads, and may impact the responsiveness and the fairness of the entire system.
For the sake of simplicity, this implementation does not take into account the wrap-around of the jiffies variable. If incremented every millisecond, jiffies would overflow its maximum value after about 42 days. Real operating systems, unlike our simplistic example, must implement an appropriate mechanism to compare time variables, not shown here, that can detect the wrap-around while calculating time differences.
Concurrency and timeslices
A different approach consists of assigning short intervals of CPU time to each task and continuously swapping processes at very short intervals. A preemptive scheduler autonomously interrupts the running task to resume the next one without an explicit request from the task itself. It can also impose its policy regarding the selection of the next task to run and the duration of the interval where the CPU is assigned to each task, namely its timeslice.
From the task’s point of view, the execution can now be continuous and completely independent from the scheduler, which acts behind the scenes to interrupt and resume each task continuously, giving the illusion that all the tasks are running at the same time. The threads can be redefined to blink the LEDs at two different intervals:
void task_test0(void *arg)
{
uint32_t now = jiffies;
blue_led_on();
while(1) {
if ((jiffies - now) > 500) {
blue_led_toggle();
now = jiffies;
}
}
}
void task_test1(void *arg)
{
uint32_t now = jiffies;
red_led_on();
while(1) {
if ((jiffies - now) > 125) {
red_led_toggle();
now = jiffies;
}
}
}To alternate tasks in a round-robin fashion, we can trigger the execution of PendSV from within the SysTick handler, which results in a task switch that occurs at regular intervals. The new SysTick handler triggers a context switch every TIMESLICE milliseconds:
#define TIMESLICE (20)
void isr_systick(void)
{
if ((++jiffies % TIMESLICE) == 0)
schedule();
}In this new configuration, we now have a more complete model, allowing multiple tasks to run independently, and the scheduling to be supervised completely by the kernel.
Blocking tasks
The simple scheduler we have implemented so far provides only two states for the tasks: TASK_READY and TASK_RUNNING. A third state can be implemented to define a task that does not need to be resumed because it has been blocked and is waiting for an event or a timeout. A task can be waiting for a system event of some type, such as the following:
- Interrupt events from an input/output (I/O) device in use by the task
- Communication from another task, such as the TCP/IP stack
- Synchronization mechanisms, such as a mutex or a semaphore, to access a shared resource in the system that is currently unavailable
- Timeout events
To manage the different states, the scheduler may implement two or more lists to separate the tasks currently running, or ready to run, from those waiting for an event. The scheduler then selects the next task among those in the TASK_READY state, and ignores the ones in the list of blocked tasks:
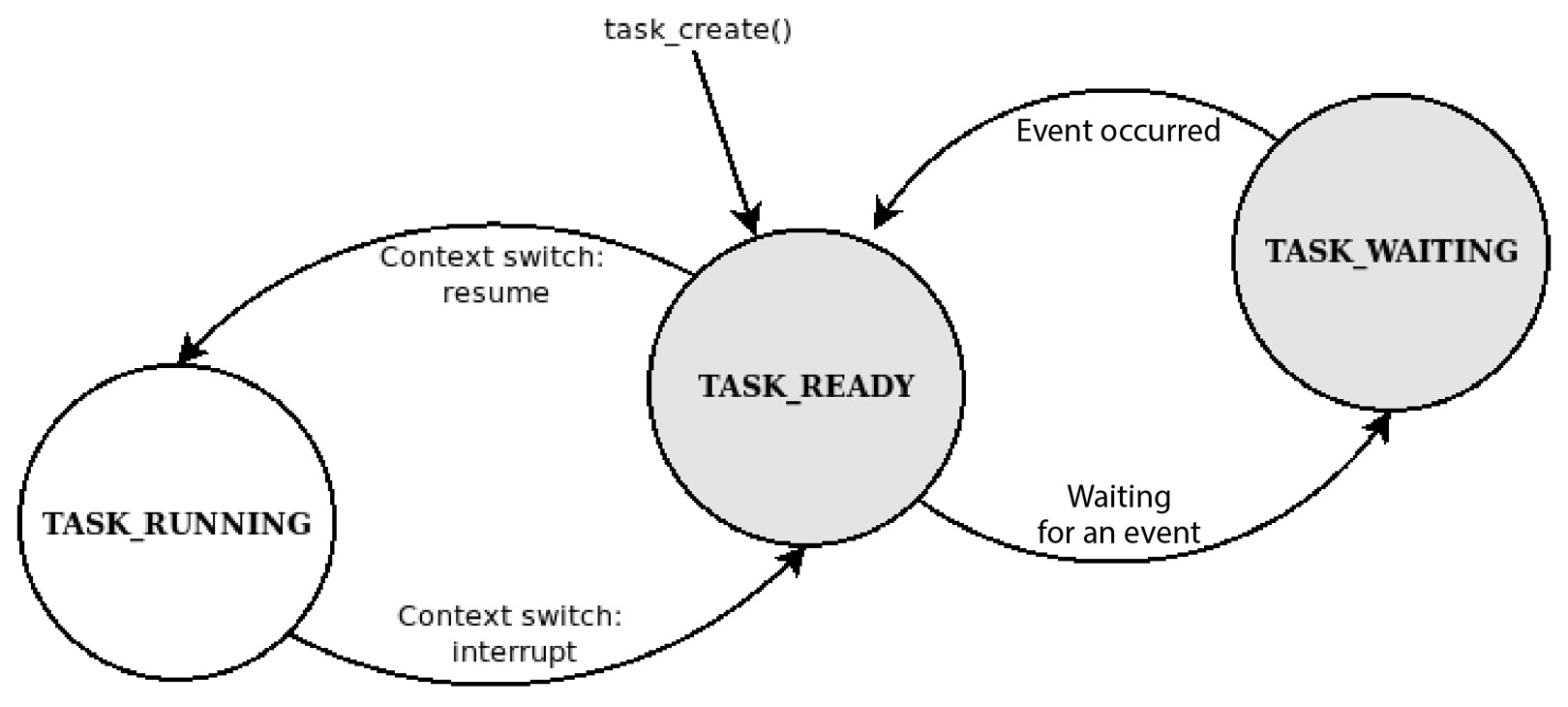
Figure 10.5 – State machine describing the task’s execution states
This second version of the scheduler keeps track of the currently running task using a global pointer, instead of the index of the array, and organizes the tasks into two lists:
- tasklist_active: This contains the task block for the running task and all the tasks in the TASK_READY state, waiting to be scheduled
- tasklist_waiting: This contains the task block of the tasks currently blocked
The easiest showcase to implement for this new mechanism is a sleep_ms function, which can be used by tasks to temporarily switch to a waiting state and set up a resume point in the future to be scheduled again. Providing this kind of facility allows our tasks to sleep in between LED toggle actions, instead of running a busy loop that repeatedly checks whether the timer expired. These new tasks are not only more efficient, because they do not waste CPU cycles in a busy loop, but are also more readable:
void task_test0(void *arg){
blue_led_on();
while(1) {
sleep_ms(500);
blue_led_toggle();
}
}
void task_test1(void *arg)
{
red_led_on();
while(1) {
sleep_ms(125);
red_led_toggle();
}
}To arrange the task blocks into lists, a pointer to the next element must be added to the structure so that the two lists are populated at runtime. To manage the sleep_ms function, a new field must be added to keep track of the system time when the task is supposed to be put in the active list to be resumed:
struct task_block {
char name[TASK_NAME_MAXLEN];
int id;
int state;
void (*start)(void *arg);
void *arg;
uint8_t *sp;
uint32_t wakeup_time;
struct task_block *next;
};These lists can be managed with two simple functions to the insert/delete elements:
struct task_block *tasklist_active = NULL;
struct task_block *tasklist_waiting = NULL;
static void tasklist_add(struct task_block **list,struct task_block *el)
{
el->next = *list;
*list = el;
}
static int tasklist_del(struct task_block **list, struct task_block *delme)
{
struct task_block *t = *list;
struct task_block *p = NULL;
while (t) {
if (t == delme) {
if (p == NULL)
*list = t->next;
else
p->next = t->next;
return 0;
}
p = t;
t = t->next;
}
return -1;
}Two additional functions must be added to move the tasks from the active list to the waiting list and vice versa, which additionally change the state of the task itself:
static void task_waiting(struct task_block *t)
{
if (tasklist_del(&tasklist_active, t) == 0) {
tasklist_add(&tasklist_waiting, t);
t->state = TASK_WAITING;
}
}
static void task_ready(struct task_block *t)
{
if (tasklist_del(&tasklist_waiting, t) == 0) {
tasklist_add(&tasklist_active, t);
t->state = TASK_READY;
}
}The sleep_ms function sets the resume time and moves the task to the waiting state, then activates the scheduler so that the task is preempted:
void sleep_ms(int ms)
{
if (ms < TASK_TIMESLICE)
return;
t_cur->wakeup_time = jiffies + ms;
task_waiting(t_cur);
schedule();
}The new PendSV handler selects the next task to run from the active list, which is assumed to always contain at least one task as the kernel main task is never put in the waiting state. The new thread is selected through the tasklist_next_ready function, which also ensures that if the current task has been moved from the active list, or is the last in line, the head of the active list is selected for the next timeslice:
static inline struct task_block *tasklist_next_ready(struct task_block *t)
{
if ((t->next == NULL) || (t->next->state != TASK_READY))
return tasklist_active;
return t->next;
}This small function is the core of the new scheduler based on the double list, and is invoked in the middle of each context switch to select the next active task in PendSV:
void __attribute__((naked)) isr_pendsv(void)
{
store_context();
asm volatile("mrs %0, msp" : "=r"(t_cur->sp));
if (t_cur->state == TASK_RUNNING) {
t_cur->state = TASK_READY;
}
t_cur = tasklist_next_ready(t_cur);
t_cur->state = TASK_RUNNING;
asm volatile("msr msp, %0" ::"r"(t_cur->sp));
restore_context();
asm volatile("mov lr, %0" ::"r"(0xFFFFFFF9));
asm volatile("bx lr");
}Finally, to check the wake-up time of each sleeping task, the kernel visits the list of waiting tasks and moves the task blocks back to the active list whenever the wake-up time has elapsed. The kernel initialization now includes a few extra steps to ensure that the kernel task itself is put in the list of running tasks at boot:
void main(void) {
clock_pll_on(0);
led_setup();
button_setup();
systick_enable();
kernel.name[0] = 0;
kernel.id = 0;
kernel.state = TASK_RUNNING;
kernel.wakeup_time = 0;
tasklist_add(&tasklist_active, &kernel);
task_create("test0",task_test0, NULL);
task_create("test1",task_test1, NULL);
task_create("test2",task_test2, NULL);
while(1) {
struct task_block *t = tasklist_waiting;
while (t) {
if (t->wakeup_time && (t->wakeup_time < jiffies)) {
t->wakeup_time = 0;
task_ready(t);
}
t = t->next;
}
WFI();
}
}Waiting for resources
Blocking at a given time interval is only one of the possibilities for a task to be temporarily excluded from the active list. The kernel may implement other event and interrupt handlers to bring the tasks back into the scheduler loop so that the task may block, waiting for I/O events from a specific set of resources while in a TASK_WAITING state.
In our example code, a read function can be implemented to retrieve the status of the button from a task, which would block and only return once the button is pressed. Until then, the calling task remains on the waiting list and is never scheduled. A task that toggles the green LED every time the button is pressed relies on button_read() as its blocking point:
#define BUTTON_DEBOUNCE_TIME 120
void task_test2(void *arg)
{
uint32_t toggle_time = 0;
green_led_off();
while(1) {
if (button_read()) {
if((jiffies - toggle_time) > BUTTON_DEBOUNCE_TIME)
{
green_led_toggle();
toggle_time = jiffies;
}
}
}
}The button_read function keeps track of the calling task, so the button_task pointer is used to wake it up when the button is pressed. The task is moved to the waiting list and the read operation is initiated in the driver, and then the task is preempted:
struct task_block *button_task = NULL;
int button_read(void)
{
if (button_task)
return 0;
button_task = t_cur;
task_waiting(t_cur);
button_start_read();
schedule();
return 1;
}To notify the scheduler whenever the button is pressed, the driver uses a callback, specified by the kernel during initialization, and passes it as an argument to button_setup:
static void (*button_callback)(void) = NULL;
void button_setup(void (*callback)(void))
{
AHB1_CLOCK_ER |= GPIOA_AHB1_CLOCK_ER;
GPIOA_MODE &= ~ (0x03 << (BUTTON_PIN * 2));
EXTI_CR0 &= ~EXTI_CR_EXTI0_MASK;
button_callback = callback;
}The kernel associates the button_wakeup function with the driver callback so that when an event occurs, if a task is awaiting the button press notification, it is moved back to the active tasks list and resumes as soon as the scheduler selects it to run:
void button_wakeup(void)
{
if (button_task) {
task_ready(button_task);
button_task = NULL;
schedule();
}
}In the button driver, to initiate the blocking operation, the interrupt is enabled and associated with the rising edge of a signal, which corresponds to the button press event:
void button_start_read(void)
{
EXTI_IMR |= (1 << BUTTON_PIN);
EXTI_EMR |= (1 << BUTTON_PIN);
EXTI_RTSR |= (1 << BUTTON_PIN);
nvic_irq_enable(NVIC_EXTI0_IRQN);
}The callback is executed in the interrupt context when the event is detected. The interrupt is disabled until the next call to button_start_read:
void isr_exti0(void)
{
nvic_irq_disable(NVIC_EXTI0_IRQN);
EXTI_PR |= (1 << BUTTON_PIN);
if (button_callback)
button_callback();
}Any device driver or system module that relies on interrupt handling to unlock the associated task may use a callback mechanism to interact with the scheduler. Using a similar blocking strategy, read and write operations can be implemented to keep the calling task on the waiting list until the desired event is detected and handled toward a callback in the scheduler code.
Other system components and libraries designed for bare-metal embedded applications may require an additional layer to integrate into the operating system with blocking calls. Embedded TCP/IP stack implementations, such as lwIP and picoTCP, provide a portable RTOS integration layer, including blocking socket calls, implemented by running the loop functions in a dedicated task, which manages the communication with the socket API used in the other tasks. Locking mechanisms, such as mutexes and semaphores, are expected to implement blocking calls, which would suspend the task when the resource requested is unavailable.
The scheduling policy we have implemented so far is very reactive and gives a perfect level of interaction among tasks, but it does not foresee priority levels, which is necessary when designing real-time systems.
Real-time scheduling
One of the key requirements for real-time operating systems is the ability to react to a selected number of events by executing the associated code within a short and predictable amount of time. To implement features with strict timing requirements, the operating system must focus on quick interrupt handling and dispatching, rather than other metrics, such as throughput or fairness. Each task might have specific requirements, such as deadlines, indicating the exact time when the execution must start or stop, or related to shared resources that might introduce dependencies to other tasks in the system. A system that can execute tasks with a deterministic time requirement must be able to meet the deadlines within a measurable, fixed amount of time.
Approaching real-time scheduling is a complex matter. Authoritative literature exists on the topic, so the subject will not be extensively explained here. Research has indicated that several approaches based on priorities assigned to each task, combined with an appropriate strategy used to switch the tasks at runtime, provide a sufficient approximation to provide a generic solution to real-time requirements.
To support hard real-time tasks with deterministic deadlines, an operating system should consider implementing the following characteristics:
- A fast context switch procedure implemented in the scheduler
- Measurable intervals where the system runs with the interrupts disabled
- Short interrupt handlers
- Support for interrupt priorities
- Support for task priorities to minimize the latency of hard real-time tasks
From the point of view of task scheduling, the latency for real-time tasks is mostly related to the ability of the system to resume the task when an external event occurs.
To guarantee a deterministic delay for a selected group of tasks, RTOSs often implement fixed-priority levels, which are assigned to tasks upon creation, and determine the order in which the next task is selected at each execution of the supervisor call of the scheduler.
Time-critical operations should be implemented in tasks with a higher priority. Many scheduler policies have been researched to optimize the reaction time of real-time tasks while keeping the system responsive and allowing issues related to the possible starvation of the tasks with a lower priority. Finding an optimal scheduling policy for a specific scenario can be very hard; the details regarding deterministically calculating the latency and jitter of a real-time system are outside the scope of this book.
One of the proposed approaches is very popular among real-time operating systems. It provides immediate context switches for real-time tasks by selecting the task with the highest priority among those ready for execution, upon every invocation of the scheduler supervisor call. This scheduling policy, known as static priority-driven preemptive scheduling, is not optimal in all cases, as the latency of the tasks depends on the number of tasks at the same priority level, and foresees no mechanism to prevent potential starvation of tasks with a lower priority in the case of higher system loads. However, the mechanism is simple enough that it can be easily implemented to demonstrate the impact of priority mechanisms on the latency of real-time tasks.
Another possible approach would consist of reassigning priorities dynamically at runtime, based on the characteristics of the tasks. Real-time schedulers may benefit from a mechanism that ensures that the task with the closest deadline is selected first. This approach, known as earliest-deadline-first scheduling, or simply EDF, is more efficient in meeting real-time deadlines in a system under a heavier load. The SCHED_DEADLINE scheduler, included in Linux starting from version 3.14, is an implementation of this mechanism, which is less popular in embedded operating systems despite being relatively simple to implement.
This example shows a simplistic implementation of a static priority-driven scheduler. We are using four separate lists to store the active tasks, one for each priority level supported on the system. A priority level is assigned to each task upon creation, and the kernel is kept at priority 0, with its main task running only when all the other tasks are sleeping, and whose unique purpose is to check the timers of the sleeping tasks. Tasks can be inserted into the active task list with the corresponding priority level when they become ready, and they are moved to the waiting list when they are blocked. To keep track of the static priority of the task, the priority field is added to the task block:
struct task_block {
char name[TASK_NAME_MAXLEN];
int id;
int state;
void (*start)(void *arg);
void *arg;
uint8_t *sp;
uint32_t wakeup_time;
uint8_t priority;
struct task_block *next;
};Two shortcut functions must be defined to quickly add and remove the task block from the list of tasks with the same priority:
static void tasklist_add_active(struct task_block *el)
{
tasklist_add(&tasklist_active[el->priority], el);
}
static int tasklist_del_active(struct task_block *el)
{
return tasklist_del(&tasklist_active[el->priority], el);
}They can then be used in the new versions of the task_waiting and task_ready functions when the task is removed or inserted into the corresponding list of active tasks at the given priority:
static void task_waiting(struct task_block *t)
{
if (tasklist_del_active(t) == 0) {
tasklist_add(&tasklist_waiting, t);
t->state = TASK_WAITING;
}
}
static void task_ready(struct task_block *t)
{
if (tasklist_del(&tasklist_waiting, t) == 0) {
tasklist_add_active(t);
t->state = TASK_READY;
}
}The three tasks are created on the system, but the one that would block upon the button press event is created with a higher priority level:
void main(void) {
clock_pll_on(0);
led_setup();
button_setup(button_wakeup);
systick_enable();
kernel.name[0] = 0;
kernel.id = 0;
kernel.state = TASK_RUNNING;
kernel.wakeup_time = 0;
kernel.priority = 0;
tasklist_add_active(&kernel);
task_create("test0",task_test0, NULL, 1);
task_create("test1",task_test1, NULL, 1);
task_create("test2",task_test2, NULL, 3);
while(1) {
struct task_block *t = tasklist_waiting;
while (t) {
if (t->wakeup_time && (t->wakeup_time < jiffies)) {
t->wakeup_time = 0;
task_ready(t);
}
t = t->next;
}
WFI();
}
}The function that selects the next task is reworked to find the task with the highest priority among those ready to run. To do so, the priority lists are visited, from highest to lowest. If the list with the highest priority is the same as one of the current tasks, the next task in the same level is selected, if possible, to guarantee a round-robin mechanism in the case of tasks competing for the CPU within the same priority level. In any other case, the first task in the list with the highest priority is selected:
static int idx;
static inline struct task_block *
tasklist_next_ready(struct task_block *t)
{
for (idx = MAX_PRIO - 1; idx >= 0; idx--) {
if ((idx == t->priority) && (t->next != NULL) &&
(t->next->state == TASK_READY))
return t->next;
if (tasklist_active[idx])
return tasklist_active[idx];
}
return t;
}The major difference between this scheduler and the one with a single priority level in terms of reacting to the button press event in the task with an ID equal to 2 is the time interval between the button press event and the reaction from the task itself. Both schedulers implement preemption by immediately putting the task back into the ready state within the interrupt handler of the button event.
However, in the first case, the task comes back to the carousel of the tasks being scheduled to compete with the other tasks on the same priority level, which can cause a delay in the reaction of the task. We can estimate this to be N * TIMESLICE in the worst-case scenario, where N is the number of processes ready to run at the moment when the interrupt occurs.
With the priority-driven scheduling approach, there is a degree of certainty that the real-time task is the first one to be scheduled after the interrupt occurs so that the time required from the interrupt to resuming the task is measurable, and in the order of a few microseconds, as the CPU executes a predictable amount of instructions to perform all the actions in between.
Real-time embedded OSs are fundamental to implementing life-critical systems, mostly in the transport and medical industries. On the other hand, they rely on simplified models to keep the basic system operations as lightweight as possible, and with minimum overhead for system call interfaces and system APIs. An opposite approach could consist of increasing the complexity of the kernel to introduce optimizations in terms of throughput, task interaction, memory safety improvements, and other performance indicators, which may be a better fit in embedded systems with loose or non-existent real-time requirements. Stricter priority-based scheduling policies improve latency and guarantee real-time responses in well-controlled scenarios but are less flexible to use in a general-purpose embedded system where other constraints are more compelling than task latency, where a time-based preemption-scheduling approach may provide better results.
Synchronization
In a multithreaded environment where memory, peripherals, and system accesses are shared, a system should provide synchronization mechanisms to allow the tasks to cooperate on the arbitration of the access to system-wide available resources.
Mutexes and semaphores are two of the most commonly used mechanisms of synchronization between parallel threads as they provide the minimal set to solve most concurrency problems. Functions that could block the calling tasks must be able to interact with the scheduler, to move the task to the waiting state whenever the resource is not available and until the lock is released or the semaphore is incremented.
Semaphores
A semaphore is the most common synchronization primitive, which provides a counter with exclusive access, and it is used by two or more threads to cooperate on the arbitration of the usage of a specific shared resource. The API provided to the tasks must guarantee that the object can be used to implement a counter with exclusive access, which, in general, requires some auxiliary features on the CPU. For this reason, the internal implementation of the synchronization strategies is dependent on the microcode implemented in the target processor.
On Cortex-M3/M4, the implementation of locking mechanisms relies on instructions provided by the CPU to perform exclusive operations. The instruction set of the reference platform provides the following two instructions:
- Load Register Exclusive (LDREX): Loads a value from an address in memory into a CPU register.
- Store Register Exclusive (STREX): Attempts to store the new value contained in the register in an address in memory corresponding to the last LDREX instruction. If the STREX succeeds, the CPU guarantees that writing the value in memory happened exclusively and that the value has not been modified since the last LDREX call. Between two concurrent LDREX/STREX sections, only one will result in a successful write to the register; the second STREX instruction will fail, returning zero.
The characteristics of these instructions guarantee exclusive access to a counter, which is then used to implement the primitive functions at the base of semaphores and mutexes.
The sem_trywait function attempts to decrement the value of the semaphore. The operation is always allowed unless the value of the semaphore is 0, which results in an immediate failure. The function returns 0 upon success, and -1 if the semaphore value is zero, and it is impossible to decrement the semaphore value at this time.
The sequence of the events in sem_trywait is as follows:
- The value of the semaphore variable (an integer accessed with exclusive load and store instructions) is read from the memory pointed to by the function argument into the register, R1.
- If the value of R1 is 0, the semaphore cannot be acquired, and the function returns -1.
- The value of R1 is decremented by one.
- The value of R1 is stored in the memory pointed to by the function argument, and the result of the STREX operation is put into R2.
- If the operation succeeds, R2 contains 0, the semaphore is acquired and successfully decremented, and the function can return with a success status.
- If the store operation fails (concurrent access is attempted), the procedure is immediately repeated for a second attempt.
Here is the assembly routine implementing all of the steps, returning 0 upon success and -1 when the decrement fails:
sem_trywait: LDREX r1, [r0] CMP r1, #0 BEQ sem_trywait_fail SUBS r1, #1 STREX r2, r1, [r0] CMP r2, #0 BNE sem_trywait DMB MOVS r0, #0 BX lr sem_trywait_fail: DMB MOV r0, #-1 BX lr
The following code is the corresponding function to increase the semaphore, which is similar to the wait routine, except that the counting semaphore is increased instead, and the operation is eventually going to succeed, even if multiple tasks are trying to access the semaphore at the same time. The function returns 0 on success, except if the value before the counter was zero, in which case it returns 1, to remind the caller to notify any listener in a wait state that the value has increased and the associated resource is now available:
.global sem_dopost sem_dopost: LDREX r1, [r0] ADDS r1, #1 STREX r2, r1, [r0] CMP r2, #0 BNE sem_dopost CMP r0, #1 DMB BGE sem_signal_up MOVS r0, #0 BX lr sem_signal_up: MOVS r0, #1 BX lr
To integrate the blocking status of the sem_wait function into the scheduler, the semaphore interface exposed by the OS to the tasks wraps the non-blocking sem_trywait call into its blocking version, which blocks the task when the value of the semaphore is zero.
To implement a blocking version of the semaphore interface, the semaphore object may keep track of the tasks accessing the resources and waiting for a post event. In this case, the identifiers of the tasks are stored in an array named listeners:
#define MAX_LISTENERS 4
struct semaphore {
uint32_t value;
uint8_t listeners[MAX_LISTENERS];
};
typedef struct semaphore semaphore;When a wait operation fails, the task is blocked and it will try again only after a successful post operation from another task. The task identifier is added to the array of listeners for this resource:
int sem_wait(semaphore *s)
{
int i;
if (s == NULL)
return -1;
if (sem_trywait(s) == 0)
return 0;
for (i = 0; i < MAX_LISTENERS; i++) {
if (!s->listeners[i])
s->listeners[i] = t_cur->id;
if (s->listeners[i] == t_cur->id)
break;
}
task_waiting(t_cur);
schedule();
return sem_wait(s);}The assembly routine, sem_dopost, returns a positive value if the post operation has triggered an increment from zero to one, which means that the listeners, if present, must be resumed to try to acquire the resource that just became available.
Mutexes
Mutex is short for mutual exclusion and is closely related to the semaphore, to the point that it can be implemented using the same assembly routines. A mutex is nothing but a binary semaphore that is initialized with a value of 1 to allow the first lock operation.
Due to the property of the semaphore, which would fail any attempt to decrement its counter after its value has reached 0, our quick implementation of the mutex interface renames the semaphore primitives sem_wait and sem_post to mutex_lock and mutex_unlock, respectively.
Two tasks can try to decrement an unlocked mutex at the same time, but only one will succeed; the other will fail. In the blocking version of the mutex for the example scheduler, the wrappers for the mutex API built on top of the semaphore functions are as follows:
typedef semaphore mutex; #define mutex_init(m) sem_init(m, 1) #define mutex_trylock(m) sem_trywait(m) #define mutex_lock(x) sem_wait(x) #define mutex_unlock(x) sem_post(x)
For both semaphores and mutexes, the example operating system written so far offers a complete API for synchronization mechanisms integrated with the scheduler.
Priority inversion
A phenomenon that is often encountered when developing operating systems with preemptive, priority-based schedulers using integrated synchronization mechanisms is priority inversion. This condition affects the reactivity time of the real-time tasks that share resources with other tasks with a lower priority, and, in some cases, may cause the higher-priority tasks to starve for an unpredictable amount of time. This event occurs when the high-priority task is waiting for a resource to be freed by a lower-priority one, which in the meanwhile may be preempted by other unrelated tasks in the system.
In particular, the sequence of events that might trigger this phenomenon is as follows:
- T1, T2, and T3 are three of the running tasks, with priority 1, 2, and 3, respectively.
- T1 acquires a lock using a mutex on resource X.
- T1 is preempted by T3, which has a higher priority.
- T3 tries to access the shared resource, X, and blocks on the mutex.
- T1 resumes the execution in the critical section.
- T1 is preempted by T2, which has a higher priority.
- An arbitrary number of tasks with priorities greater than 1 can interrupt the execution of T1 before it can release the lock and wake up T3.
One of the possible mechanisms that can be implemented to avoid this situation is called priority inheritance. This mechanism consists of temporarily increasing the priority of a task sharing a resource to the highest priority of all the tasks accessing the resource. This way, a task with a lower priority does not cause scheduling delays for the higher-priority ones, and the real-time requirements are still met.
System resource separation
The example operating system we have built throughout this chapter already has many interesting features, but it is still characterized by a flat model, with no memory segmentation or privilege separation. Minimalist systems do not provide any mechanisms to separate system resources and regulate access to the memory space. Instead, tasks in the system are allowed to perform any privileged operation, including reading and altering other tasks’ memory, executing operations in the address space of the kernel, and directly accessing peripherals and CPU registers at runtime.
Different approaches are available on the target platform, aimed at increasing the level of safety on the system by introducing a limited number of modifications to the kernel to:
- Implement kernel/process privilege separation
- Integrate memory protection in the scheduler
- Provide a system call interface through the supervisor call to access resources
Let’s discuss each in detail.
Privilege levels
The Cortex-M CPU is designed to run code with two different levels of privilege. Privilege separation is important whenever untrusted application code is running on the system, allowing the kernel to keep control of the execution at all times, and prevent system failures due to a misbehaving user thread. The default execution level at boot is privileged, to allow the kernel to boot. Applications can be configured to execute at the user level and use a different stack-pointer register during the context switch operations.
Changing privilege levels is possible only during an exception handler, and it is done using the special exception return value, which is stored in LR before it is returned from an exception handler that performed the context switch. The flag that controls the privilege level is the lowest bit of the CONTROL register, which can be changed during context switches before returning from the exception handler, to relegate application threads to run at the user privilege level.
Moreover, most Cortex-M CPUs provide two separate stack-pointer CPU registers:
- A Master Stack Pointer (MSP)
- A Process Stack Pointer (PSP)
Following the ARM recommendation, operating systems must use PSP to execute user threads, while MSP is used by interrupt handlers and the kernel. The stack selection depends on the special return value at the end of the exception handler. The scheduler we have implemented so far has this value hardcoded to 0xFFFFFFF9, which is used to return in thread mode after an interrupt and keeps executing the code at a privileged level. Returning the 0xFFFFFFFD value from the interrupt handler tells the CPU to select the PSP as a stack-pointer register when returning to thread mode.
To implement privilege separation properly, the PendSV handler used for switching tasks has to be modified to save and restore the context using the right stack pointer for the task being preempted and the stack selected. The store_context and restore_context functions we have used so far are renamed to store_kernel_context and restore_kernel_context, respectively, because the kernel is still using the master stack pointer. Two new functions are added to the store and restore thread contexts from the new context switch routine, which uses the PSP register instead, for storing and restoring the contexts of the threads:
static void __attribute__((naked)) store_user_context(void)
{
asm volatile("mrs r0, psp");
asm volatile("stmdb r0!, {r4-r11}");
asm volatile("msr psp, r0");
asm volatile("bx lr");
}
static void __attribute__((naked)) restore_user_context(void)
{
asm volatile("mrs r0, psp");
asm volatile("ldmfd r0!, {r4-r11}");
asm volatile("msr psp, r0");
asm volatile("bx lr");
}In the safe version of the scheduler, the PendSV service routine selects the correct stack pointer for storing and restoring the context and calls the associated routines. Depending on the new context, the return value stored in LR is used to select the register used as a new stack pointer, and the privilege level is set in the CONTROL register to switch to the user or privileged level in the upcoming thread mode, using values of 1 or 0, respectively:
void __attribute__((naked)) isr_pendsv(void)
{
if (t_cur->id == 0) {
store_kernel_context();
asm volatile("mrs %0, msp" : "=r"(t_cur->sp));
} else {
store_user_context();
asm volatile("mrs %0, psp" : "=r"(t_cur->sp));
}
if (t_cur->state == TASK_RUNNING) {
t_cur->state = TASK_READY;
}
t_cur = tasklist_next_ready(t_cur);
t_cur->state = TASK_RUNNING;
if (t_cur->id == 0) {
asm volatile("msr msp, %0" ::"r"(t_cur->sp));
restore_kernel_context();
asm volatile("mov lr, %0" ::"r"(0xFFFFFFF9));
asm volatile("msr CONTROL, %0" ::"r"(0x00));
} else {
asm volatile("msr psp, %0" ::"r"(t_cur->sp));
restore_user_context();
asm volatile("mov lr, %0" ::"r"(0xFFFFFFFD));
asm volatile("msr CONTROL, %0" ::"r"(0x01));
}
asm volatile("bx lr");
}A task running with the privilege mode bit set in the CONTROL register has restricted access to the resources of the system. In particular, threads cannot access registers in the SCB region, which means that some basic operations, such as enabling and disabling interrupts through the NVIC, are reserved for the exclusive use of the kernel. When used in combination with the MPU, privilege separation improves the safety of the system even further by imposing memory separation at the access level, which can detect and interrupt misbehaving application code.
Memory segmentation
Dynamic memory segmentation strategies can be integrated into the scheduler to ensure that the single tasks do not access memory regions associated with system-critical components and that the resources that require kernel supervision can be accessed from user space.
In Chapter 5, Memory Management, we saw how the MPU can be used to delimit contiguous segments of memory and disallow access to specific areas by any of the code running on the systems. The MPU controller provides a permission mask to change the attributes of the single-memory regions with more granularity. In particular, we can only allow access to some areas if the CPU is running at a privileged level, which is an efficient way of preventing user applications from accessing certain areas of the system without the supervision of the kernel. A safe operating system may decide to completely exclude the application tasks from accessing the peripheral region and the system registers by using kernel-only permission flags for these areas. The values associated with specific permissions in the MPU region attribute register can be defined as follows:
#define RASR_KERNEL_RW (1 << 24) #define RASR_KERNEL_RO (5 << 24) #define RASR_RDONLY (6 << 24) #define RASR_NOACCESS (0 << 24) #define RASR_USER_RW (3 << 24) #define RASR_USER_RO (2 << 24)
The MPU configuration can be enforced at boot by the kernel. In this example, we have set the flash region to be globally readable, as region 0, using RASR_RDONLY, and the SRAM region to be globally accessible, as region 1, mapped at an address of 0x20000000:
int mpu_enable(void)
{
volatile uint32_t type;
volatile uint32_t start;
volatile uint32_t attr;
type = MPU_TYPE;
if (type == 0)
return -1;
MPU_CTRL = 0;
start = 0;
attr = RASR_ENABLED | MPUSIZE_256K | RASR_SCB |
RASR_RDONLY;
mpu_set_region(0, start, attr);
start = 0x20000000;
attr = RASR_ENABLED | MPUSIZE_128K | RASR_SCB | RASR_USER_RW | RASR_NOEXEC;
mpu_set_region(1, start, attr);A stricter policy may even restrict the usage of the SRAM by the user tasks in non-privileged mode, but it would require a reorganization of the .data and .bss regions that are mapped when the task is started. In this example, we are simply demonstrating how to integrate the per-task memory protection policy into the scheduler to prevent access to system resources and protect the stack areas of the other tasks. The CCRAM is the area we want to protect as it contains the execution stack of the kernel, as well as those of the other tasks in the system. To do so, the CCRAM area must be marked to be of exclusive access of the kernel as region 2. Later, an exception must be created for the selected task during the context switch, to permit access to its own stack space:
start = 0x10000000; attr = RASR_ENABLED | MPUSIZE_64K | RASR_SCB | RASR_KERNEL_RW | RASR_NOEXEC; mpu_set_region(2, start, attr);
Peripheral regions and system registers are restricted areas in our system, so they too are marked for exclusive kernel access at runtime. In our safe OS design, tasks that want to access peripherals must use system calls to perform supervised privileged operations:
start = 0x40000000; attr = RASR_ENABLED | MPUSIZE_1G | RASR_SB | RASR_KERNEL_RW | RASR_NOEXEC; mpu_set_region(4, start, attr); start = 0xE0000000; attr = RASR_ENABLED | MPUSIZE_256M | RASR_SB | RASR_KERNEL_RW | RASR_NOEXEC; mpu_set_region(5, start, attr); SHCSR |= MEMFAULT_ENABLE; MPU_CTRL = 1; return 0; }
During the context switch, just before returning from the isr_pendsv service routine, the scheduler can invoke the function that is exported by our custom MPU module to temporarily permit access to the stack area of the task selected to run next in non-privileged mode:
void mpu_task_stack_permit(void *start)
{
uint32_t attr = RASR_ENABLED | MPUSIZE_1K |
RASR_SCB | RASR_USER_RW;
MPU_CTRL = 0;
DMB();
mpu_set_region(3, (uint32_t)start, attr);
MPU_CTRL = 1;
}These further restrictions have limited the possibility for the currently implemented tasks to access any resources directly. To maintain the same functionalities as before, the example system must now export a new safe API for the tasks to request system operations.
System calls
The latest evolution of the example operating system we have implemented in this chapter no longer allows our tasks to control system resources, such as input and output peripherals, and does not even allow the tasks to block voluntarily as the sleep_ms function is not allowed to set the pending flag to initiate a context switch.
The operating system exports an API that is accessible by the tasks through a system call mechanism via the SVCall exception, which is handled by the isr_svc service routine, and triggered at any time from tasks through the svc instruction.
In this simple example, we are using the svc 0 assembly instruction to switch to handler mode by defining a shortcut macro, SVC():
#define SVC() asm volatile ("svc 0")We wrap this instruction within a C function so that we can pass arguments to it. The ABI for the platform provides the first four arguments of the call across the mode switch inside the R0-R3 registers. Our example API does not allow us to pass any arguments to the system calls, but uses the first argument in R0 to identify the request that has been passed from the application to the kernel:
static int syscall(int arg0)
{
SVC();
}This way, we implement the entire system call interface for this operating system, which consists of the following system calls with no arguments. Each system call has an associated identification number, passed as arg0. The list of system calls is the contract for the interface between the tasks and the kernel, and the only way for the tasks to use the protected resources in the system:
#define SYS_SCHEDULE 0 #define SYS_BUTTON_READ 1 #define SYS_BLUELED_ON 2 #define SYS_BLUELED_OFF 3 #define SYS_BLUELED_TOGGLE 4 #define SYS_REDLED_ON 5 #define SYS_REDLED_OFF 6 #define SYS_REDLED_TOGGLE 7 #define SYS_GREENLED_ON 8 #define SYS_GREENLED_OFF 9 #define SYS_GREENLED_TOGGLE 10
Each of these system calls must be handled in isr_svc. Controlling peripherals and system block registers can be done by calling the driver functions in the handler context, even if this is done just for brevity here. In a proper design, operations that take more than a few instructions to complete should be deferred to be run by the kernel task the next time it is scheduled. The following code has been used just to show a possible implementation of isr_svc that reacts to user requests allowed by the system API, to control the LED and the button on the board, while also providing a mechanism that can be expanded to implement blocking system calls.
The svc service routine executes the requested command, passed as an argument to the handler itself. If the system call is blocking, such as the SYS_SCHEDULE system call, a new task is selected to complete a task switch within the handler.
The svc routine can now handle internal commands, as shown in the following example handler function:
void __attribute__((naked)) isr_svc(int arg)
{
store_user_context();
asm volatile("mrs %0, psp" : "=r"(t_cur->sp));
if (t_cur->state == TASK_RUNNING) {
t_cur->state = TASK_READY;
}
switch(arg) {
case SYS_BUTTON_READ: /* cmd to read button value */
button_start_read();
break;
case SYS_SCHEDULE: /* cmd to schedule the next task */
t_cur = tasklist_next_ready(t_cur);
t_cur->state = TASK_RUNNING;
break;
case SYS_BLUELED_ON: /* cmd to turn on blue LED */
blue_led_on();
break;
/* case ... (more LED related cmds follow) */
}The context is resumed at the end of the routine, in the same way as within PendSV. Though it is optional, a task switch might occur if the call must block:
if (t_cur->id == 0) {
asm volatile("msr msp, %0" ::"r"(t_cur->sp));
restore_kernel_context();
asm volatile("mov lr, %0" ::"r"(0xFFFFFFF9));
asm volatile("msr CONTROL, %0" ::"r"(0x00));
} else {
asm volatile("msr psp, %0" ::"r"(t_cur->sp));
restore_user_context();
mpu_task_stack_permit(((uint8_t *)((&stack_space))
+(t_cur->id << 10))); asm volatile("mov lr, %0" ::"r"(0xFFFFFFFD));
asm volatile("msr CONTROL, %0" ::"r"(0x01));
}
asm volatile("bx lr");}While limited in its functionalities, the new system exports all the APIs needed for our application threads to run again, once all the prohibited privileged calls have been removed from the task code, and the newly created system calls are invoked instead:
void task_test0(void *arg)
{
while(1) {
syscall(SYS_BLUELED_ON);
mutex_lock(&m);
sleep_ms(500);
syscall(SYS_BLUELED_OFF);
mutex_unlock(&m);
sleep_ms(1000);
}
}
void task_test1(void *arg)
{
syscall(SYS_REDLED_ON);
while(1) {
sleep_ms(50);
mutex_lock(&m);
syscall(SYS_REDLED_TOGGLE);
mutex_unlock(&m);
}
}
void task_test2(void *arg)
{
uint32_t toggle_time = 0;
syscall(SYS_GREENLED_OFF);
while(1) {
button_read();
if ((jiffies - toggle_time) > 120) {
syscall(SYS_GREENLED_TOGGLE);
toggle_time = jiffies;
}
}
}The code size of a safe operating system may grow quickly if it implements all the operations in kernel space and has to provide the implementation of all the system calls allowed. On the other hand, it provides physical memory separation among tasks, and it protects system resources and other memory areas from accidental errors in the application code.
Embedded operating systems
As illustrated in the previous sections of this chapter, building a scheduler tailored to a custom solution from scratch is not impossible and, if done properly, would provide the closest approximation of the desired architecture and focus on the specific characteristics offered by the target hardware. In a real-life scenario, however, it is advisable to consider one of the many embedded operating systems options available and ready to be integrated into the architecture among those supporting the selected hardware platform, and providing the features that we have learned about in this chapter.
Many of the available kernel implementations for microcontrollers are open source and in a healthy development state, so they are deserving of their well-established role in the embedded market. A few of them are sufficiently popular and widely tested to provide a foundation for building reliable embedded multitasking applications.
OS selection
Selecting the operating system that best fits the purpose and the platform under development is a delicate task that impacts the overall architecture, may have consequences on the whole development model, and may introduce API lock-ins in the application code base. The criteria for selection vary according to the hardware characteristics, the integration with the other components, such as third-party libraries, the facilities offered to interact with peripherals and interfaces, and, most importantly, the range of use cases that the system is designed to cover.
With a few exceptions, operating systems include, alongside the scheduler and the memory management, a set of integrated libraries, modules, and tools. Depending on the purpose, an embedded OS may provide a suite that covers several areas, including the following:
- Platform-specific hardware abstraction layers
- Device drivers for common peripherals
- TCP/IP stack integration for connectivity
- Filesystems and file abstractions
- Integrated power management systems
Depending on the implementation of the thread model in the scheduler, some systems are expected to run with a fixed amount of predefined tasks, configured at compile time, while others opt for more complex processes and thread hierarchies that allow us to create new threads at runtime, and terminate them at any point in the execution. However, dynamic task creation and termination are rarely a requirement on embedded systems, and in most of these cases, an alternative design may help us work around it.
More complex systems introduce some overhead due to the additional logic in the system exceptions code and are less fit for critical real-time operations, which is the reason why most successful RTOSs nowadays maintain their simple architecture, providing the bare minimum to run multiple threads with a flat-memory mode that is easy to manage and does not require additional context switches to manage the privilege of the operations, keeping the latency low and measurable to comply with real-time requirements.
Due to the many options available and the continuous evolution following technological progress, providing an exhaustive list of operating systems for embedded devices is outside the scope of this book. Unlike the PC domain, where less than a handful of operating systems dominate the entire market, the several embedded OSs are all very different from each other in terms of their design, APIs, drivers, supported hardware, and build tools.
In this last section of this chapter, we will explore two of the most popular open-source operating systems for embedded devices, FreeRTOS and Riot OS, by comparing their design choices for parallel task execution, memory management, and accessory features available.
FreeRTOS
Possibly the most popular among the open-source operating systems for embedded devices, approaching 20 years of active development at the time of writing, FreeRTOS is extremely portable across many embedded platforms, with tens of available hardware ports and support for most, if not all, embedded CPU architectures.
Designed with a small code footprint and simple interfaces in mind, this system does not offer a complete driver’s platform or advanced CPU-specific features, but rather focuses on two things: real-time scheduling of the threads and heap memory management. The simplicity of its design allows it to be ported to a large number of platforms and keeps the development focus on a restricted amount of well-tested and reliable operations.
On the other hand, third-party libraries and example code provided by hardware manufacturers often integrate FreeRTOS into their software kit, most of the time as the only alternative to the bare-metal approach for test applications and examples. Since third-party code is not directly included in FreeRTOS, this promotes competition among different solutions, as, for example, it is possible to integrate it with many TCP/IP stack implementations to provide networking support, even though none of them are part of the core system or tightly integrated with the kernel. Device drivers are not included in the kernel, but there are several demos of complete systems based on the integration of FreeRTOS with board support packages both distributed by the manufacturers or as part of a broader ecosystem, where FreeRTOS is included as a kernel.
The scheduler is preemptive, with fixed priority levels and priority inheritance through shared mutexes. Priority levels and stack space sizes for all threads are decided upon when the thread is created. A typical FreeRTOS application starts from its main function, which is in charge of initializing the threads and starting the scheduler. A new task can be spawned using the xTaskCreate function:
xTaskCreate(task_entry_fn, "TaskName", task_stack_size, ( void * ) custom_params, priority, task_handle);
The first parameter is a pointer to the main function, which will be the entry point for the task. When the entry point of the task is invoked, the custom parameters, which are specified as the fourth parameter here, will be passed as the sole argument for the function, allowing us to share a user-defined parameter with the thread upon task creation. The second argument of xTaskCreate is just the name of the task in a printable string, which is used for debugging purposes. The third and fifth parameters specify the stack size and the priority for this task, respectively. Finally, the last argument is an optional pointer to the internal struct of the task that will be populated when xTaskCreate returns, if a valid pointer was provided. This object, which is of the TaskHandle_t type, is required to access some of the task functionalities, such as task notifications or generic task utilities.
Once the application has created its tasks, the main function invokes the main scheduler by calling the following:
vTaskStartScheduler();
If everything goes well, this function never returns and the main function of the application becomes the actual kernel task, which is in charge of scheduling the tasks defined earlier and newer tasks that can be added later on.
One of the most interesting features offered by FreeRTOS is heap memory management, which is available in five flavors optimized for different designs:
- Heap 1: Allows only one-time, static allocation in the heap, with no possibility of freeing up the memory. This is useful if the applications can allocate all the space needed at the beginning, as the memory will never become available to the system again.
- Heap 2: Allows freeing memory, but does not reassemble the freed blocks. This mechanism is suitable for implementations with a limited number of heap allocations, especially if they keep the same size as previously freed objects. If used improperly, this model may result in a heavily fragmented stack with the risk of running out of heap in the long run, even if the total size of the allocated object does not increase, due to the lack of memory reorganization.
- Heap 3: This method is a wrapper for a malloc/free implementation provided by a third-party library that ensures that the wrapped memory operations become thread-safe when used within the FreeRTOS multithreading context. This model allows us to define a custom memory management method by defining the malloc/free function in a separate model, or by using the library implementation and attaching the sbrk() system call, as seen in Chapter 5, Memory Management.
- Heap 4: This is a more advanced memory manager with support for memory coalescence. Contiguous free blocks are merged and some housekeeping is done to optimize the use of the heap across heterogeneous allocations from different threads. This method limits the fragmentation of the heap and improves memory usage in the long run.
- Heap 5: This method uses the same mechanism as heap 4, but allows us to define multiple non-contiguous memory regions to be part of the same heap space. This method is a ready-to-use solution for physical fragmentation, provided that the regions are defined during initialization time and provided to the system through the available API.
Selecting a specific heap model consists of including one of the available source files defining the same functions with different implementations. These files are part of the FreeRTOS distribution under recognizable names (heap_1.c, heap_2.c, and so on). Only one is chosen and must be linked to the final application to manage memory.
The important functions that are exposed by the heap memory manager in FreeRTOS are pvPortMalloc and pvPortFree, both of which have similar signatures and effects as the malloc and free functions that we saw in Chapter 5, Memory Management.
Support for MPU and thread mode is available, and threads can be run in restricted mode, where the only memory that is accessible is the one assigned to the specific thread. When running threads in restricted mode, the system API is still available as the system functions are mapped in a specific area in memory. The main safety strategy consists of voluntarily placing tasks in restricted mode and defining memory access boundaries by allowing the task to only access its own stack and up to three configurable regions in the mapped memory.
Low-power management is limited to sleep mode, and no deep sleep mechanism is implemented by default. The system, however, allows us to redefine the scheduler callback functions to enter custom low-power modes, which may be used as starting points to implement tailored power-saving strategies.
Recent versions of FreeRTOS include specific distributions with third-party code as a starting point for building a secure connected platform for IoT systems. The same authors have created a TCP/IP stack that is designed for FreeRTOS, and it is distributed in a FreeRTOS Plus bundle package alongside the kernel and wolfSSL library to support secure socket communication.
RIOT OS
Mostly built on top of constrained microcontrollers, such as the Cortex-M0, low-power embedded systems are often little, battery-powered, or energy-harvesting devices, sporadically connecting to remote services using wireless technologies. These small, inexpensive systems are used in both IoT projects and install-and-forget scenarios, where they can operate for years on a single integrated power source with nearly no maintenance costs.
Bare-metal architectures are still very popular in these use cases. However, a few very lightweight operating systems have been designed to organize and synchronize tasks using as few resources as possible, while still keeping a specific focus on power saving and connectivity. The challenge when developing this kind of operating system is to find a way to fit complex networking protocols into a few kilobytes of memory. Future-proof systems designed for the IoT services offer native IPv6 networking, often through 6LoWPAN, and fully equipped yet minimalist TCP/IP stacks, designed to sacrifice throughput in favor of smaller memory footprints.
Due to their small code size, these systems may lack some advanced features by design. For example, they may not provide any memory safety strategies, or have a limited connectivity stack to save resources. It is not uncommon to have these kinds of systems run on a UDP-only network stack.
Riot OS has a fast-growing community of enthusiasts and system developers. The goal of the project is to provide a system designed for low power consumption, taking into account the requirements to integrate the device into larger distributed systems. The core system is very scalable, as single components can be excluded at compile time.
The approach used by Riot OS differs from the minimalist concept we saw in FreeRTOS, where the bare minimum amount of code is part of the core operating system, and everything else is integrated as external components. Riot OS offers a wide selection of libraries and device support code, including network stacks and wireless drivers communication, which makes this system particularly IoT-friendly. Components that are not part of the core functionality of the OS are divided into optional modules, with a custom, makefile-based build system designed to facilitate the inclusion of the modules in the application.
From an API point of view, the choice of the Riot community is an attempt to mimic the POSIX interface as much as possible. This improves the experience of embedded application development for programmers coming from different backgrounds and is used to write code using the APIs offered by the standard C language to access the resources on the system. The system, however, still runs on a flat model. Privilege separation is not implemented at the system level, and user space applications are still supposed to access system resources by referencing the system memory directly.
As an additional safety measure, the MPU can be used to detect stack overflows in the single threads by placing a small read-only area at the bottom of the stack, which triggers an exception if threads are attempting to write past the limit of their assigned stack space.
Riot implements a few communication stacks as modules, including a minimalist IP stack called GNRC. GNRC is an IPv6-only implementation tailored to the features of the underlying 802.15.4 network and provides a socket implementation to write lightweight IoT applications. The support for networking includes a lwIP compatibility layer. lwIP is included as a module to provide more complete TCP/IP implementations when required. WolfSSL is also available in a module, opening up possibilities for securing socket communication using the latest TLS version, as well as utilizing cryptography functionality to secure data at rest, for example.
One of the features offered by Riot is access to the configuration of low-power modes, which is integrated into the system through the power management module. This module provides an abstraction for managing platform-specific features, such as the stop and standby modes on Cortex-M platforms. Low-power modes can be activated at runtime from the application code to facilitate the integration of low-power strategies in the architecture. This is done using the real-time clock, the watchdog timer, or other external signals to return to normal running mode.
The scheduler in Riot OS is tickless and based mostly on cooperation. Tasks can suspend themselves explicitly by calling the task_yield function, or by calling any of the blocking functions to access kernel features (such as IPC and timers) and hardware peripherals. Riot OS does not enforce any concurrency based on timeslices; a task is forcibly interrupted uniquely in case a hardware interrupt is received. Programming applications with this scheduler requires particular attention, because accidentally creating a busy loop in one task may lock up the entire system to starvation.
Tasks in Riot OS can be created through the thread_create function:
thread_create(task_stack_mem, task_stack_size, priority, flags, task_entry_fn, (void*)custom_args, "TaskName");
While the syntax of thread_create may look similar to that of the equivalent function in FreeRTOS, we can spot a few differences in the approach to the two schedulers. In Riot OS, for example, the memory reserved for the stack space of the task being created must be allocated by the caller. The stack space cannot be automatically allocated upon task creation, which means more code in the caller but also more flexibility for customizing the location of each stack space in memory. As we mentioned previously, the scheduler is tickless, so there is no necessity to start it manually. Tasks can be created and stopped at any time during the execution.
Being designed for embedded targets with little RAM available, the use of dynamically allocated memory is discouraged in Riot OS. However, the system offers three different approaches for heap memory management:
- One-time static allocation: Similar to the FreeRTOS “heap 1” model, this allocator does not offer any facilities to free or reuse memory areas. Once allocated, the memory is reserved and never released. By default, the malloc function uses this implementation, and the free function has no effect.
- Memory-array allocator: A statically allocated buffer can be used as a memory pool for pseudo-dynamic allocation requests of a fixed, predefined size. This allocator may be useful in those scenarios where multiple buffers of the same size are handled by the application. This allocator has a custom API and does not modify the behavior of the default malloc function.
- Two-level segregate fit (TLSF) allocator: This allocator supports multiple memory pools based on an algorithm optimized for RTOS and provides dynamic memory support while dealing with real-time deadlines. The support for TLSF malloc is available as an optional module. When compiled in, the module replaces the malloc and free functions provided by the one-time allocator, which is then disabled.
Riot OS is an interesting choice as a starting point for IoT systems. It provides a wide range of device drivers and modules, built and integrated on top of a lightweight and energy-aware core system, including a microkernel with a pre-emptive scheduler.
Summary
In this chapter, we explored the typical components of an embedded operating system by implementing one from scratch, with the only purpose of studying the internals of the system, how the various mechanisms can be integrated into the scheduler, and how blocking calls, driver APIs, and synchronization mechanisms can be provided to tasks.
We then analyzed the components of two of the many very popular open-source, real-time operating systems for embedded microcontrollers, namely FreeRTOS and Riot OS, to highlight the differences in the design choices, implementation, and APIs provided for the applications to work with threads and memory management.
At this point, we can select the most appropriate OS for our architecture, and even write one ourselves when needed, by implementing our favorite scheduling, priority mechanisms, privilege separation between tasks and the kernel itself, and memory segmentation.
In the next chapter, we will take a closer look at Trusted Execution Environments (TEEs), with a particular focus on the TrustZone-M features recently introduced by ARM in their latest family of microcontrollers, which adds a new orthogonal level of privilege separation.