
OpenTSDB is a distributed timeseries database designed to accommodate the needs of modern dynamic large-scale environments. It was built with resilience in mind and has been proven to handle extremely high data loads. OpenTSDB embodies many concepts described in this book. It implements plotting functionality and has the ability to interface with alerting solutions, such as Nagios. If you’re looking to build a robust and scalable monitoring platform, OpenTSDB is the right place to start.
OpenTSDB was initially developed at StumbleUpon by Benoît Sigoure to address the issues of cost-effective, long-term metric retention and durability at an extremely large scale. OpenTSDB’s most distinctive feature is its decentralized nature. The implementation rests on top of HBase, a fully distributed, nonrelational database that offers a high degree of fault-tolerance. OpenTSDB uses that to provide resilience at the same time not compromising on performance and feature richness.
The code is distributed under GNU Lesser General Public License (LGPL) version 2.1.
Figure A-1 illustrates OpenTSDB in its operation. At the core of the solution lies the Timeseries Daemon (TSD), which assists the clients in storing and retrieving metrics from the HBase cluster. The two core components are loosely coupled and can be scaled independently.
Multiple instances of TSDs communicate between three actors: input sources, clients, and the datastore.
Input sources are servers with data collection agents deployed to them. The collectors gather and report hardware statistics, quantitative data extracted from application logs as well as SNMP information reported by the network devices and sensors.
The clients are system operators plotting the charts via the HTTP interface, alerting systems evaluating most recent data points for existence of alertable behavior, and automated processes that use monitoring information as input for routine tasks. TSD’s UI allows for juxtaposing any combination of timeseries at arbitrary temporal granularity starting with one second. The data points may also be exported over HTTP in clear text as inputs to alerting engines and for offline analysis. Such fine granularity is unprecedented at the scale that OpenTSDB can support.
Datastore typically refers to an HBase cluster, although the open source community has reported success with using alternative NoSQL solutions. It should be noted, however, that at the time of this writing HBase is the only supported datastore.
OpenTSDB’s data collection takes place by pushing data to the
datastore, that is, the sources report data points to TSD instances with
put operations. All put operations
are independent in that the reporting servers are not assigned to
specific TSDs or the other way around.

A single-box installation of OpenTSDB can be completed in 15 minutes. It involves deploying an HBase instance and populating it with OpenTSDB schema, spinning up the Timeseries Daemon (TSD), and feeding it with data! OpenTSDB fetches most of its dependencies at build time except for GNUPlot, Java Development Kit (JDK), and HBase. These three need to be installed separately.
To bootstrap a single-node HBase instance, visit this website.
Then for the latest OpenTSDB setup instructions, go here.
From here on I will assume that you followed the Getting Started guide on the OpenTSDB project website and have a running instance of HBase. In particular I assume that you have completed the following:
Downloaded and successfully built OpenTSDB
Deployed and started an HBase instance
Populated HBase with the OpenTSDB schema
Tip
To verify whether you’re ready to go, visit your HBase node on port 60030 if you’re running a single node cluster) and check for the existence of tsdb and tsdb-uid tables under Online Regions. If the page does not load or the tables aren’t there, consult the logs in your HBase’s installation logs/ directory.
Enter the build/ directory in the root of where OpenTSDB was built. It contains the tsdb shellscript wrapper which you’ll use for managing the TSD. Launching a TSD instance requires three mandatory command line options: the TCP port number to use, location of the web root from which to serve static files, and the request cache directory.
Addition of --auto-metric flag gets TSD to
create metric entries in TSDB for you on the fly. Otherwise, metrics
have to be created with tsdb mkmetric subcommand.
While automatic metric creation might not be ideal for a production
environment, this very convenient feature saves a lot of typing while
playing with tsdb.
The “staticroot” should already be present in the current
directory. Create the cache directory and start
tsdb on port 4242.
$ ./tsdb tsd --port=4242
--staticroot=./staticroot --cachedir=/tmp/tsd
--auto-metric
The last line should read “Ready to serve”. Now go here. You should be greeted by TSD’s HTTP interface. It’s time to upload some data inputs.
A running TSD instance is meant to receive inputs from data
collectors in push mode (Figure A-2). The collectors connect to TSD and upload data
via clear-text protocol with help of simple put
operations. Submitting inputs requires four pieces of
information:

The name of a metric that the input should be assigned to
A Unix timestamp at which to assign the value
The numeric value
One or more tags associated with the input
The template for the put directive is as
follows:
put <metric> <timestamp> <value>
<tagkey=tagvalue> [<tagkey=tagvalue>
…]
Every data input must to be described by at least one tag.
To report a data point simply open a TCP connection to a TSD and supply the data as follows:
$ echo "put test.metric $(date
+%s) 1 order=first" | nc localhost 4242
$ echo "put test.metric $(date +%s) 2
order=second" | nc localhost 4242
$ echo "put test.metric $(date +%s) 3
order=third" | nc localhost 4242
Now, go back to the HTTP interface and in the metric form field
enter “test.metric”. An auto-suggestion helper
window should pop up as you type. Leave the tags blank.
Click on the “From” field and when the calendar expands double click the “1m” link. This will set the start time at two minutes ago. Now, click on the “(now)” hyperlink next to the “To” field to select the present time as the end time of the observation. At this point, you should see a plot with three data points.
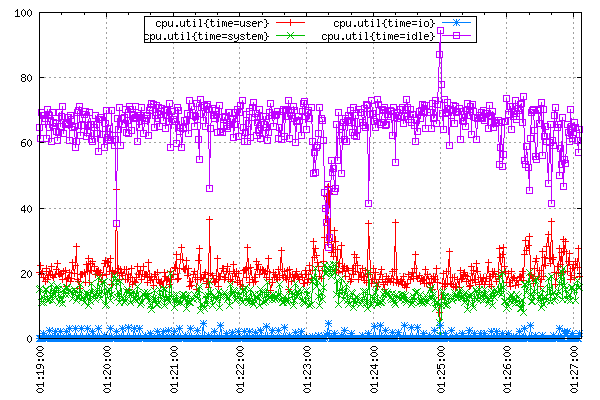
Okay, now let’s report something more useful. Assuming that System Activity Reporter (SAR) is installed on your system, telling it to run with 1 second frequency should result in a fine-grained report of CPU utilization in percentage terms.
$ sar 1
Linux 3.0.0-22-generic (hostname) 14/07/12 _i686_ (2
CPU)
01:18:10 CPU %user %nice %system %iowait %steal
%idle
01:18:11 all 18.59 0.00 13.57 2.51 0.00 65.33
01:18:12 all 19.00 0.00 13.00 0.00 0.00 68.00
01:18:13 all 20.81 0.00 11.17 0.00 0.00 68.02
01:18:14 all 17.82 0.00 12.38 0.00 0.00 69.80
…
The following shellscript reads in sar’s output, translates it into TSDB put instructions and uploads them to TSD.
#!/bin/bash# Ignore sar's header.sar -u 1 | sed -u -e'1,3d'|whileread timecpu usr nice sys io steal idle;doNOW=$(date +%s)echoput cpu.util$NOW$usrtime=userechoput cpu.util$NOW$systime=systemechoput cpu.util$NOW$iotime=ioechoput cpu.util$NOW$idletime=idle# Report values to standard error.echotimestamp:$NOWuser:$usrsys:$sysio:$ioidle:$idle>&2done| nc -w 30 localhost 4242
Let it run and pull up the TSD’s HTTP interface in the browser:
Enter “cpu.util” in the metric name.
Select last ten minutes as start date and now as the end date.
The first tag field under the metric name should get populated with “time” key by now. Enter an asterisk (“*”) in its corresponding value.
Select the “Autoreload” checkbox, and set the interval for 5 seconds.
Soon enough the resulting plot should look something like the one in Figure A-3.
Tagging provides an extremely convenient and flexible mechanism for aggregation by source of data at many levels. Tags are attributes of data inputs that describe their properties and origin. You can think of each tag as an added dimension on your data, with the help of which OpenTSDB will allow you to slice and dice through the data points at will.
Let me explain the idea on a simple example: network traffic
measurement. On a high level, network traffic is a flow of bytes
encapsulated in packets. Looking closer, each packet has a source and
destination, it represents one or more of the OSI layer protocols, and
it has a direction—it either leaves or enters the network. Consider
monitoring traffic flow in bytes per interval of time. The
put operation for each host would look something like
this:
put traffic <time> <value> src=<hostname>
subnet=<name> proto=<protocol>
direction=<in|out>
Reported traffic data can now be analyzed as cumulative flow, by protocol, by direction, and even by specific source host or any combination of these, for example, incoming HTTP traffic per subnet or outgoing ICMP traffic per host, as illustrated in Figure A-4.
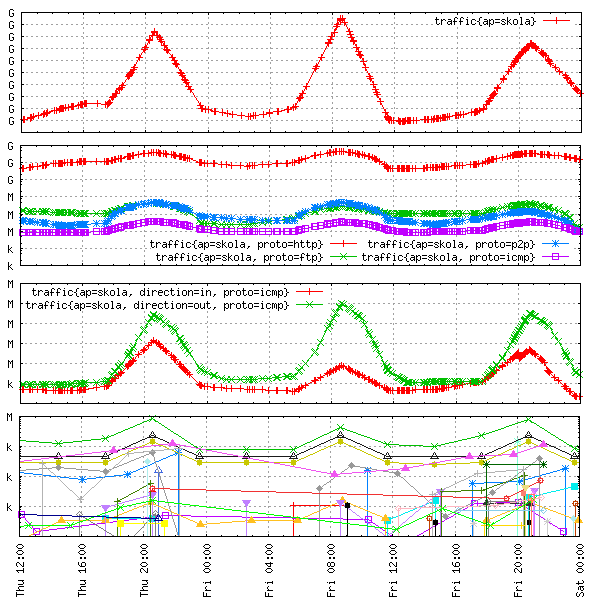
OpenTSDB supports basic wildcarding of tag values. This way, single metric entry may be plotted in a form of multiple timeseries, the number depending on how many tag values were reported by the sources.
There are currently two ways in which multiple timeseries can be plotted out of a single Metric tab. First, you enter the tag key in the lefthand input box next to the “Tag” label and then in the value input box
placing an asterisk (“*”) will render timeseries for all possible tag values in that metric,
delimiting selected tag values by a pipe sign (“|”) will make TSD render only the timeseries for selected tag values.
Short-lived technical blips that cause cascading failures up and down the solution stack happen in a matter of seconds. OpenTSDB was designed specifically to continuously monitor large clusters of servers at sufficient granularity, empowering the operators to detect and evidence problem sources without having to dig into logs just to extract quantitative information. OpenTSDB records data inputs at one second granularity, which is much finer than the vast majority of monitoring systems can offer.
Having said that, OpenTSDB does not lock the user into data point intervals of specific length. When one second interval is too short to reliably plot the desired effect on a timeseries, it’s possible to select custom temporal input aggregation. In the UI, this is referred to as downsampling. To make the data points on the selected metric’s timeseries less granular, select the “Downsample” checkbox and enter desired interval. The TSD will divide the timeseries into an evenly spaced time period group, aggregate all data inputs reported in that duration, and summarize them with a statistic of choice.
At the time of writing this, the TSD can condense inputs into data points with a selection of summary statistics: min and max—the smallest and largest values per interval (p0 and p100), the sum and average of values, and standard deviation. TSD’s UI refers to summary statistics as aggregators.
Rate of change is a series of data points derived from another timeseries by calculating the difference between two consecutive values from the original series.
Deriving the rate of change is especially useful for counter metrics, which are a special type of stock metric described in detail by Chapter 2. A rate of change of a counter metric is a flow-type metric, describing counter increases per interval.
For all other timeseries, rate of change illustrates the velocity of data point values: speed of their increase or decline, with the latter plotted in negative range. As a result, it usually makes sense to place the rate of change series on the right y-axis, leaving the left side y-axis for series ranging in nonnegative values only.
To plot the rate of change in OpenTSDB check the “Rate” box in the metric options window.
OpenTSDB is accompanied by a light-weight framework for data collection, tcollector. Its main objective is to gather inputs from local agents on all hosts in the system and push them to a TSD instance. Using tcollector over trivial, custom-built agents brings about a number of advantages:
Occasionally crashing local collectors get restarted.
Problems in communication with TSDs are handled for you, thus ensuring continuity of reported data.
Repeated inputs get deduplicated to keep the overhead to the minimum.
Data transfer to TSD is abstracted out so that any future changes to OpenTSDB will not require local code updates.
When data collection takes place from many machines system-wide, these advantages become really apparent.
The framework comes with a number of ready-made input collectors that support read-outs from standard Linux interfaces and software packages, such as /proc pseudo-filesystem, MySQL instances, and more. For custom data collection agents, tcollector provides a simple, clean, and consistent interface.
tcollector is written in Python and comes ready-to-run with a number of standard input collectors.
To get it, check out the latest version from the official repository:
$ git clone
git://github.com/stumbleupon/tcollector.git
$ cd
tcollector
The directory should contain licensing files, base tcollector code
and a number of standard input collectors in the collectors/0 subdirectory. If
you’ve started your TSD with --auto-metric option,
all you need to do now is to start tcollector. The following line will
kick off the process with root privileges.
$ sudo TSD_HOST=localhost
TCOLLECTOR_PATH=. ./startstop start
Starting ./tcollector.py
Okay, tcollector is running and reporting metrics. After fifteen seconds first inputs should have arrived. Switch back to the HTTP interface and plot some metrics; for example, juxtapose proc.stat.cpu with proc.meminfo.highfree and df.1kblocks.used. A detailed description of each metric’s supported by tcollector can be found here.
For production settings, tcollector should be packaged and deployed system-wide to every monitorable host. Typical setup on each machine involves the following:
Place tcollector in /usr/local/tcollector.
Leave only those local collectors in collectors/0/ subdirectory that you want to gather inputs and remove all the rest.
Place startstop script in /etc/init.d/tcollector and make it start at boot time.
It is extremely easy to plug a custom collection agent into
tcollector—simply create an executable script or binary that reports
data inputs at an interval and place it alongside other agents. The
inputs should be printed one per line to standard output in similar
format as for the put directive, but with the put
directive itself omitted:
<metric> <timestamp> <value>
<tagkey=value> [<tagkey=value> …]
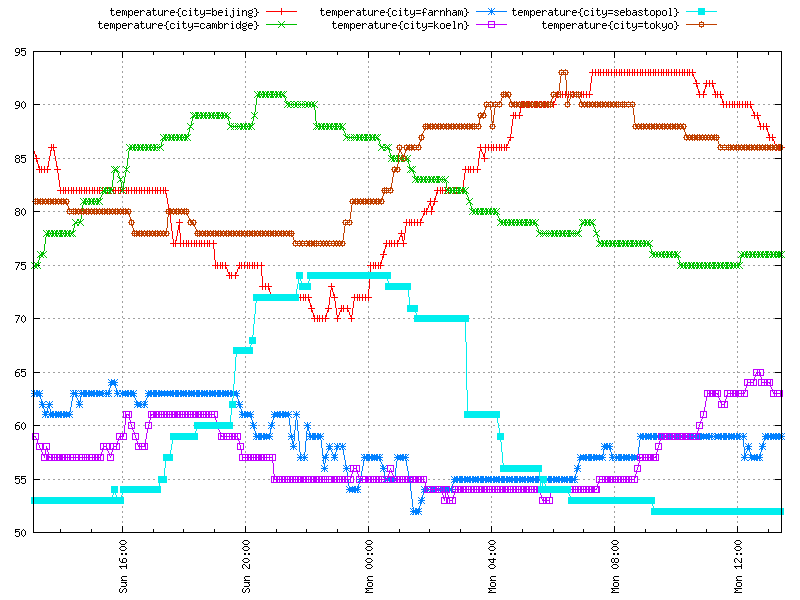
The following agent gathers temperature information for selected cities. It runs continuously in a closed loop at 5 minute intervals.
#!/usr/bin/pythonimportsysimporttimeimporturllib2COLLECTION_INTERVAL=300CITIES=['Beijing','Cambridge','Farnham','Koeln','Sebastopol','Tokyo']WEATHER_API='http://citytemp.effectivemonitoring.info/get'defget_temperature(city,scale='c'):"""Get temperature for a city."""city_url=WEATHER_API+'?city=%s&scale=%s'%(city,scale)api_response=urllib2.urlopen(city_url).read()ifapi_response.strip().isdigit():returneval(api_response)defmain():whileTrue:forcityinCITIES:ts=int(time.time())city_temp=get_temperature(city,scale='f')city_label=city.lower().replace(' ','_')'temperature%d%scity=%s'%(ts,city_temp,city_label)sys.stdout.flush()time.sleep(COLLECTION_INTERVAL)if__name__=="__main__":main()
tcollector will always add a host tag to the reported data. This way, data are guaranteed to have at least one dimension, and data points can always be reliably tracked back to a set of machines from which the inputs originated (Figure A-5).
A monitoring platform should empower the operators to make the most of gathered data. OpenTSDB does exactly that. The following features make OpenTSDB’s interface a powerful one:
Setting arbitrarily many system metrics against each other to allow for visual correlation in establishing cause and effect
Ability to model the plot on the fly through selection of summary statistic, temporal aggregation, trimming value range, rate of change and logarithmic scale transformations for each metric separately
Browser history, allowing for multi-metric plots to be statelessly exchanged between users with a copy and paste of a URL
There exist a number of tricks that skillful plotters use to extract the desired effect. Here are just a few of them:
When values of data points between two timeseries differ greatly, the fluctuations described by them may become less distinct. To emphasize the deviations from baseline of both timeseries, it is best to superimpose the two by plotting them on separate scales each laid out on both left and right y-axes.
To assign a timeseries to the right axis, check the “Right axis” box in the metric tab.
When three or more timeseries with data point values differing by orders of magnitude are to be plotted on a single chart, distributing the series between axes is not enough and logarithmic scale should be used. The best effect is achieved by grouping timeseries of similar magnitude on the same axes.
Check the “Log scale” box in the Axes tab to have one of the y-axes display in logarithmic scale.
In view of extreme value jumps, deviations that are still significant may become obstructed. To counter this effect, the value range of the y-axes may be trimmed from top and bottom:
Enter “[:100]” into the Range input box in the Axes window, to limit the plot from the lowest recorded value up to a value of one hundred.
The right balance between temporal granularity and selected time range should be struck, in accordance with what you’re trying to demonstrate. Very granular graphs spanning long periods may be visually appealing, but are very hard to extract meaning from. Long data point intervals plotted over relatively short periods, on the other hand, do not convey relevant information about the process of change.
To make default 1-second time interval coarser, click on “Downsample” and enter a selected time period, for example, 30m to plot half-hourly data points.
The summary statistic tells half the story. Average and median will smoothen out timeseries curves while the extreme percentiles and sum might make them spikier.
Experiment with a summary statistic from the “Aggregator” dropdown menu of the Metric tab.
To learn more about OpenTSDB, visit the project’s main website. Start by reading the manual and FAQ. For the latest code changes, follow the project on GitHub. For current developments, join the mailing list at [email protected].