
Chapter 21. Installing and Updating with p2
In Chapter 14, “Adding Software Management,” you defined a feature for the Hyperbola plug-ins and added software management support to allow a user to install new features and update existing features. That discussion did not include the details of what is happening under the covers, especially with regard to how p2 operates.
p2 is the provisioning system developed by the Equinox project at eclipse.org. It is a powerful replacement for the original Eclipse Update Manager included with the Eclipse Platform. While retaining much of the original functionality, p2 allows system designers greater flexibility in how they define, structure, and deploy their systems. Fundamentally p2 is a provisioning platform; that is, it is not just one provisioning system but rather a collection of provisioning technologies on top of which you can build a fit-for-purpose provisioning solution. Of course, p2 comes with quite a number of preconfigured pieces to make the creation of your solution as straightforward as possible. This chapter digs deeper and
• Introduces the various roles of the p2 component
• Describes the p2 architecture and terminology
• Demonstrates how to use the p2 provisional API with Hyperbola
• Describes how to manage metadata and repositories
• Describes how to install plug-ins using the p2 director
21.1 The Roles of p2
Installation and updates are managed in Eclipse by the provisioning platform called p2. You can use p2 to install or manage any aspect of your application, from the physical plug-ins and native code, to the configuration of the installed software (e.g., file permissions, command-line arguments, etc.). Installation with p2 does more than simply add and remove files in the file system—p2 captures a sequence of events that must occur to lay down and configure a system so that it is ready to run. Core aspects of p2 include the following:
• Automatic resolution of dependencies between software components. With p2, you state the root set of items you want installed or uninstalled, and p2 computes the complete set of required system changes automatically.
• Transport of software components and configuration data from remote repositories to the system being installed. p2 includes sophisticated algorithms for performing multithreaded transfers, including support for mirrors and automatic rebalancing of transfers based on network state.
• An extensible mechanism for instructing p2 how to install and configure various kinds of software. By default p2 knows how to install and configure Eclipse plug-ins, features, and basic native integration such as setting permissions and creating symbolic links.
• A graphical user interface integrated into the Eclipse platform, to allow end users to examine and manage the application.
• A suite of command-line tools and Ant tasks, to allow developers and release engineers to build and configure p2-enabled applications.
21.2 Architecture
The centerpiece of the architecture is the agent. The agent is a notional concept—there is no actual agent object. Rather the agent is the logical entity that reasons about metadata to manage profiles by coordinating the downloading of artifacts from repositories and using an engine to manipulate the profiles. Figure 21-1 shows an overview of the agent, the large box in the middle, and how the various parts fit together.
Figure 21-1 Architecture of p2

The Hyperbola application is represented by a profile, a runnable configuration of software. The artifacts being installed and updated are mostly bundles, and the metadata being reasoned about is the dependency information extracted from the constituent bundle manifests and product configuration files. The integrated runtimes include the OS and Equinox/Eclipse.
The p2 architecture is quite loosely coupled. The metadata and artifact repositories are independent, the director and engine can be remote, profiles can be distributed, and so on. This allows for great flexibility in putting together provisioning solutions. This chapter shows you how p2 fits together and how the different parts interact to support software management in Hyperbola.
21.2.1 Installable Units
One of the key characteristics of p2 is its separation of metadata from the artifacts being manipulated. Managing these separately allows p2 to reason about vast numbers of artifacts without having to download any. It also allows for the addition of nonfunctional information to the provisioning setup without modifying the artifacts themselves.
All metadata is captured in installable units (IUs). Figure 21-2 shows the structure of an IU. An IU has an ID and a version, the combination of which must be globally unique. IUs also have an open set of key/value properties used to capture information such as name and type.
Figure 21-2 The structure of an installable unit

The basis of the p2 dependency structure is an IU’s generic capability mechanism. IUs provide and require capabilities. A capability is simply an ID and version number in a namespace. For example, a bundle that exports the org.eclipsercp.hyperbola package at version 1.0 is said to provide a capability with ID org.eclipsercp.hyperbola and version 1.0 in the java.package namespace. Similarly, a bundle that imports that package is said to require the corresponding capability. IUs requiring capabilities can specify a version range. Since the set of namespaces is open, the p2 metadata structure can be used to represent all manner of relationships.
In addition to the dependency information, each IU has a number of related artifacts that are installed when the IU is installed and a set of actions that are executed when the IU goes through an install, configure, unconfigure, and uninstall lifecycle.
21.2.2 Artifacts
p2 treats artifacts as opaque blobs of data and knows only about the metadata used to describe them. That being said, p2 is able to store the same artifact in multiple forms and do a number of interesting optimizations to reduce bandwidth and disk space requirements.
21.2.3 Repositories
All artifacts and metadata are stored in repositories in a p2 system. p2 specifies an API for repositories but not their internal representation. A repository may be on disk, in memory, structured using XML or in a database, or pretty much in any other form. For example, p2 includes repository definitions that integrate legacy Eclipse update sites unchanged. Metadata and artifact repositories are often colocated for convenience but need not be. p2 includes several tools for publishing to repositories and mirroring repositories.
21.2.4 Profiles
As mentioned previously, p2 defines profiles to represent runnable configurations of software. Technically profiles are just descriptions of the system; that is, they list the IUs installed in them. During the actual install operation the relevant artifacts are fetched, installed, and configured into the system. On completion, the fact that the artifact has been installed is recorded in the profile. A p2 agent can manage many profiles representing many different systems.
21.2.5 Director
The director is the brains of the p2 operation. It is responsible for working with the metadata available in the known repositories, the profile being managed, and the provisioning request supplied to it to come up with a set of install, uninstall, and update operations. These operations are then passed to the p2 engine for execution.
Note
On the surface the director’s job seems reasonably straightforward, but it turns out to be one of those very challenging (i.e., NP-complete) computer science problems. Fortunately, p2 includes a pseudo-Boolean constraint solver, SAT4J, to help with formulating provisioning solutions.
21.2.6 Engine
The engine’s job is simply to execute a given set of install, uninstall, and update operations. The engine walks through a set of phases and executes the relevant part of each operation in each phase. For example, when an IU is installed, its related artifacts must first be fetched, then installed, and finally configured. Each phase is executed for all involved IUs before proceeding to the next phase.
The engine is assisted in executing these phases by a set of touchpoints. A touchpoint is the interface between p2 and some runtime or configuration system. For example, when a bundle is installed into an Equinox system, its start level and auto-start state need to be configured. This is done by the Equinox touchpoint. If p2 were being used to install a WAR or RPM, the relevant operations would be carried out by, say, a Tomcat or RPM touchpoint, respectively.
21.3 Using the p2 API
p2 exposes a set of provisional APIs that can be used to fully customize the install experience for your application. The reason for this is that many applications need full control of how p2 works. For example, a developer may want to show an application-specific wizard to guide users through the update process, or nothing at all. To support these different workflows, p2 provides the mechanics and leaves it up to you to write the supporting code. To use advanced p2 functionality in Hyperbola, we first have to use some of the p2 provisional API:
• IProfileRegistry—manages the list of profiles
• IInstallableUnit—represents what to install (e.g., a feature or a plug-in)
• IPlanner—creates the provisioning plans needed when manipulating profiles
• IEngine—executes provisioning plans to effect the actual install or uninstall of software
• IMetadataRepositoryManager—tracks metadata repositories
• IArtifactRepositoryManager—tracks artifact repositories
21.3.1 Adding Repositories
The first step in updating Hyperbola is to ensure that there is a place to grab updates from. In p2 terminology, this ensures that there is an available metadata and artifact repository for Hyperbola to pull updates from. To advise where Hyperbola will search for updates, we can use a touchpoint advice file (p2.inf) to augment the metadata that is generated.

In Section 21.4 we cover in depth the various ways you can customize p2 metadata using touchpoint instructions and advice files. Touchpoint instructions are very flexible and allow you to do such things as add repositories, copy files, and set file permissions.
21.3.2 Loading Repositories
Now that the proper repositories are defined, we can load the metadata repository and begin structuring a query using the p2 API. To load repositories, we need to obtain the IMetadataRepositoryManager and get the list of known repositories to load:
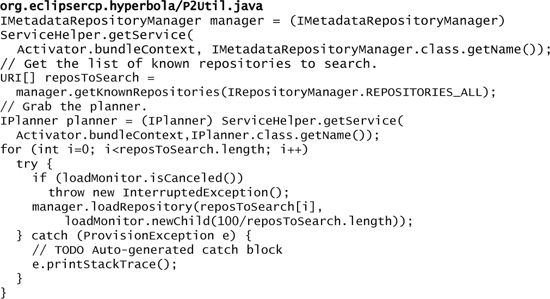
21.3.3 Searching Repositories
Now that the repositories are loaded, we need to create a ProvisioningContext to search the loaded repositories for updates using a Collector. The process involves going through all the available installable units, checking whether there is a more recent installable unit available, and recording it. In p2 terminology, an installable unit describes things that can be installed, updated, or uninstalled. The concept of an installable unit maps to features quite well. In the end, when you see installable units in the p2 API, think of features and plug-ins. However, note that it’s an abstraction and can describe anything that can be installed, updated, or uninstalled.

21.3.4 Executing a Provisioning Plan
The final step in the update process is to build a profile change request and obtain a provisioning plan to execute against the engine. To begin, we create a ProfileChangeRequest with the proper installable units obtained when querying the available repositories. Next, we obtain the IEngine service and create a ProvisioningPlan with the change request to pass to the engine.

Now that we have a better grasp of how to use p2 to query and install updates, it’s possible to build any type of user interface using these facilities.
Note
As of Eclipse 3.5, the p2 API is provisional and will likely change in the future. In the next release of Eclipse (3.6), the p2 API is expected to be solidified and simplified.
21.4 Metadata Management
As described before, p2 provides facilities for software dependency management and for performing all of the necessary steps to get an application physically installed and configured into an end user’s system. The information that describes the dependencies between application components and the steps required to properly configure a running system is called the p2 metadata. In many cases this metadata can be computed directly from the information in your plug-in and feature manifests, and an extra step is simply required to publish this data into a format suitable for consumption by p2. In other cases plug-in or application developers may need to author or customize the p2 metadata for their software.
21.4.1 Publishing Metadata
There are three different ways p2 repositories can be created: using the PDE Export wizards, using PDE Build, or using the publisher. Under the covers, PDE uses the publisher to generate the proper p2 metadata. The publisher is the means by which deployable entities like features or products get added to repositories. For example, the publisher can be used to create p2 metadata from a plug-in or a feature. The publisher consists of an extensible set of publishing actions, applications, and Ant tasks that allow users to generate p2 repositories from a number of different sources. Inside the org.eclipse.equinox.p2.publisher and org.eclipse.equinox.p2.updatesite plug-ins, there are four command-line applications you can use to generate p2 metadata:
• org.eclipse.equinox.p2.publisher.FeaturesAndBundlesPublisher
• org.eclipse.equinox.p2.publisher.ProductPublisher
• org.eclipse.equinox.p2.publisher.UpdateSitePublisher
• org.eclipse.equinox.p2.publisher.CategoryPublisher
For example, the org.eclipse.equinox.p2.publisher.ProductPublisher application can be used to generate metadata from an Eclipse product definition file as shown here:

See the p2 publisher documentation on the Eclipse wiki for more information: http://wiki.eclipse.org/Equinox/p2/Publisher.
21.4.2 Customizing Metadata
On occasion the metadata that is automatically generated by p2 for bundles, features, and products does not provide everything required to successfully provision an IU. Since Eclipse 3.5, p2 supports the use of a publishing advice file (a p2.inf file) that can be used to augment the metadata for an installable unit. The advice file allows an author to customize capabilities, properties, and instructions. The advice file is a properties file and can be placed within
• Plug-ins (META-INF/p2.inf): The instructions are added to the IU for the plug-in.
• Features (a p2.inf file colocated with the feature.xml): The instructions are added to the IU for the feature group.
• Products (a p2.inf file colocated with the .product file): The instructions are added to the root IU for that product.
Version substitution is a common practice, and two special version parameters are supported:
• $version$—returns the string form of the containing IU’s version
• $qualifier$—returns just the string form of the qualifier of the containing IU’s version
The syntax of a touchpoint advice file is listed here:

where {phase} is a p2 installation phase (collect, configure, install, uninstall, unconfigure).
The qualified action names for the IU’s touchpoint type are implicitly imported. All other actions need to be imported. For example, to use the instructions.install advice, we would have to import it as shown here:
![]()
21.4.3 Touchpoint Instructions
An IU is installed using the facilities provided by a touchpoint. The IU metadata consists of a reference to the touchpoint and describes instructions to execute in various p2 engine phases. Each instruction (e.g., install) describes a sequence of actions to execute for the referenced touchpoint. Examples of common actions are creating and removing directories, changing permissions or linking a delivered artifact, adding repository metadata, and installing and removing bundles. For a concrete example, look at the next sample, which uses a touchpoint instruction to symbolically link Linux libraries within a bundle:

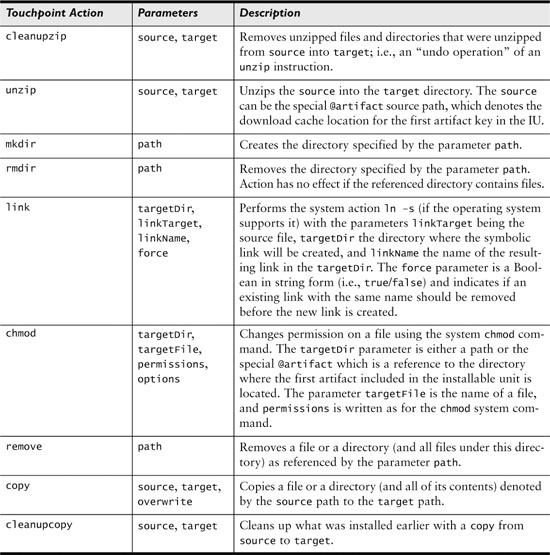
As of Eclipse 3.5, two touchpoints have been implemented (native and eclipse). In Table 21-1 we list the various native touchpoint instructions you can use in your application, from unzipping to copying files.
Table 21-1 Native Touchpoint Actions
In Table 21-2 we list some of the Eclipse-related touchpoint actions you can use within your application, from installing features to adding repositories. See the p2 documentation for the full list of Eclipse touchpoint actions.
Table 21-2 Eclipse Touchpoint Actions

21.5 Repository Management
Repositories are at the heart of p2, and there are many techniques for interacting with them. For example, a common use case is for users to be able to mirror external repositories within a repository of their own because of company policies or to provide developers faster access to artifacts.
21.5.1 Mirroring Repositories
p2 provides two applications that support copying (mirroring) the content of remote repositories to a local repository. The artifact mirroring application supports duplicating a complete artifact repository into a target repository. To perform this operation you simply need an Eclipse installation that contains the org.eclipse.equinox.p2.artifact.repository bundle. The following command will copy the complete contents of a source repository into the destination repository:

If the destination repository does not already exist, the mirroring application will create a new repository with the same properties as the source repository.
21.5.2 Composite Repositories
As repositories continually grow in size, they become harder to manage. The goal of composite repositories is to make this task easier by allowing site maintainers to have a parent repository that refers to multiple child repositories. Users are then able to reference the parent repository, and the content of all the child repositories will be transparently available to them. In order to automate composite repository actions in release engineering builds, Ant tasks (e.g., p2.composite.repository) have been provided that can be called to create and modify composite repositories. The tasks are defined in the org.eclipse.equinox.p2.repository.tools plug-in.
21.5.3 Content Categorization
By default, the p2 user interface groups all the IUs by category. If an IU is not categorized, it will not be displayed in the user interface. There are currently two supported methods for categorizing content: a category definition file, as we discussed in Section 14.7, “Defining Categories,” and a touchpoint advice file, as discussed in Section 21.3.
21.6 Installation Management
The easiest way to install plug-ins and features is via the Software Updates dialog we encountered while working with Hyperbola. However, there are use cases where installation has to happen programmatically or via the command line, such as in build and scripted environments. In p2 this is achieved using a tool called the p2 director that can perform installation operations in a headless fashion. The director application, org.eclipse.equinox.p2.director, is a command-line tool for installing additional software or uninstalling software from an Eclipse-based product. This application is capable of provisioning a complete installation from scratch or simply extending your application. Depending on your needs, it can be executed both inside and outside the target product being provisioned. For example, the next command will install the C/C++ Development Tools (CDT) into Eclipse:

You can also use the director to perform installations outside the host Eclipse installation. In this case the provisioning operation happens outside the targeted product. The targeted product is not started. This allows you to both modify an existing installation and create a complete installation from scratch, given proper metadata. This also has the advantage that since the targeted product does not need to be started, the provisioning operation can be performed on any platform for any other platform (e.g., on a Linux machine, you can add plug-ins to a windows-based target application).
For example, the command listed here will install the CDT into an existing Eclipse SDK.

In summary, if you need to install anything using p2, use the Software Updates dialog; if you’re running headless, the p2 director application can be useful.
21.7 Summary
After reading this chapter, you should have a grasp of p2 terminology and how the major parts of p2 work together. Although with Hyperbola we only scratch the surface of what we can do with p2, we encourage you to explore p2 further and see how you can take advantage of it in your applications. Key to the p2 design is that it is a provisioning platform. It supports a number of common workflows and scenarios out of the box and leaves open the option for you to customize and extend to suit your requirements.
21.8 Pointers
• The p2 wiki (http://wiki.eclipse.org/Equinox_p2) should be your first stop when looking for more information about p2.
• Platform Developer Guide > Reference > Provisioning platform, p2.
• The OSGi and Equinox book contains more information about p2: McAffer, Jeff, Paul VanderLei, and Simon Archer. OSGi and Equinox: Creating Highly Modular Java Systems (Addison-Wesley, 2010), ISBN 0321585712.