
“Out of intense complexities, intense simplicities emerge.” | ||
| --Winston Churchill | ||
In the worst situations when communications break down and projects repeatedly fail, IT becomes a blocker, not an enabler, of change. Projects can become too large and complex to succeed, not only because of their internal complexity, but also because of the unavoidable complexity of the surrounding IT and the users’ environment. Information about those external environments and expert knowledge about them is often nonexistent or in short supply. In the worst situations, the elephant becomes frozen. As a result, the business becomes frozen, too—it cannot move.
The rest of this book is about thawing and eating those elephants.
This book intends to show that the way we deliver projects—the way we consume elephants—is inherently wrong. Indeed, as we continue the earlier metaphor, illustrated in Figure 3.1, we believe it is especially inadvisable to eat frozen elephants.

An organization can use three possible methods to eat an elephant:
A single person can eat the elephant (see Figure 3.2). This solves most of the communication problems, but it would take a very long time.
Use a number of stages and a number of people per stage, as shown in Figure 3.3. The IT industry currently uses this solution. The elephant will get eaten a lot faster than with the previous option, although the people will need a lot of management and coordination to direct who should eat which parts and when.
In desperation, we could look for a superhero (see Figure 3.4) with a very large mouth. This means that, in theory, the elephant could get eaten a lot faster. Unfortunately, most of the superheroes are too busy saving the world to take the time to eat an elephant.


Clearly, the first option is not viable. Although an elephant could be eaten that way, a business that waited that long for an IT solution to arrive would go out of business. The second option has all the communication and coordination problems discussed in Chapter 2, “The Confusion of Tongues.” Perhaps the third idea, although fanciful, has some merit. Clearly, the possibility of finding an IT superhero who could somehow swallow all that complexity is out of the question—no such individual exists. But perhaps it would be possible to build an elephant-eating machine. Is it possible to build an Elephant Eater that could accomplish the same task?
We faced all the problems we’ve talked about so far in this book during one particularly large and complex government project. Not only was the environment complex, but the systems that needed to be built were complex, too. Each system had thousands of business rules and tens of thousands of users who used the system every day. In addition, these systems were the very heart of the organization. They talked to virtually every other system across their IT estate (and many beyond). If these systems failed, the government’s advisors confidently predicted riots on the streets within a week. If an Elephant Eater was ever needed, it was needed now. So we decided to build one. | ||
| --R.H. and K.J. | ||
Any Elephant Eater needs to directly address the problems with the complexity and communication identified in the previous chapter. This involves addressing the reality of ambiguous communication, parochialism, and private languages that prevail in large projects. This also involves addressing the need for communication among multiple distributed teams, both on and off the project, with overlapping responsibilities.
First, we need to remove inconsistency between Views. To achieve this, the Elephant Eater needs to consume all Views on the project. As new Views are fed into the Elephant Eater, it checks them for any inconsistency with the other Views already entered. If the information inserted is inconsistent or contradicts the information already in the Elephant Eater, this needs to be corrected before the information is fed in.
The key question is, how can this be done? Surely this means that the information being fed in needs to be precise and unambiguous; otherwise, how will the Elephant Eater know whether it is consistent? This is a very fair point. To explain how this is done, we introduce three formal terms that help describe the core elements of communication:
Syntax—. The study of the rules or “patterned relations” that govern the way words combine to form phrases and the way phrases combine to form sentences
Semantics—. The aspects of meaning that are expressed in a language, code, or other form of representation
Context—. Important ancillary information for understanding the meaning being conveyed
To put it simply, we communicate at all levels by using syntax. But to get the full meaning of any communication, it is necessary to understand the semantics of its use and the context in which it is used.
Consider the word “check.” A check is an order for a bank to make payment of money from a bank account to some other party. A check could also be the bill in a restaurant. When talking about a process, it could be an inspection or verification step. At a tailor, it could be a pattern on a shirt. In playing chess, it could mean a direct attack on the king...and the list goes on. Of course, these are just its meanings as a noun. Thanks to the unusual flexibility of the English language, the word can also be used as a verb.
How is it possible to ascertain what meaning of the word is being used? Sometimes it’s impossible to be certain, but, more often than not, you can determine the meaning (that is, the semantics) by the surrounding context. For the Elephant Eater to be able to clarify all those Views, it needs to have some understanding of syntax, semantics, and context.
Historically, the IT industry has experienced many syntactic difficulties. In the earliest days, different flavors of common computer languages existed. A program that ran in one environment might need to be changed to run in a different one. The syntax or rule structure of implementations using the same computer language might be subtly different. Today the syntax of languages is highly standardized. The programs used to create computer programs (editors) recognize the required syntax and even helpfully fill in the rest of the line or correct your program’s syntax.
If you’ve seen green wavy lines appear under your sentences as you type in Microsoft® Word, you might be familiar with its grammar checker, which has a pretty impressive knowledge of English syntax.
Of course, the IT industry’s syntax problems went well beyond computing languages. Reading program code to understand the design of a system is a time-consuming business, so the computer industry uses “models” to record the core features and structure of complex systems. These models are usually recorded as diagrams that normally consist of two-dimensional boxes and lines.
Today’s system designs are created and maintained by these models. However, would a diagram that makes sense to you make as much sense to anyone else? If you added an extensive key or a lengthy explanation of the model, someone else might be able to understand it, but that defeats the whole point of having a model.
In the 1980s, few hard and fast rules provided syntax for the creation of diagrams. By the middle of the 1990s, they were all fighting for supremacy (which was just as confusing). Today, the ubiquitous Unified Modeling Language (UML) defines the syntax of many forms of formal models.
Twenty years ago, standardized syntax was problematic for achieving unambiguous communication. Over time, the problem has been addressed and formal standardized grammars are now available for programs, diagrams, documents, and other kinds of communication. If a group is using the same syntax and grammar, we have solved at least part of our communication problem. As long as the Elephant Eater has a good grasp of formal grammars, it will be able to eat almost any form of standardized communication.
If syntax is no longer a problem, then what about semantics and context? Even if groups can communicate with one another in formal structures or syntax, when they record the concept of “check,” as in the earlier example, using a syntax, the word might not mean the same thing. In Figure 3.5, the project has an Elephant Eater, which has already consumed some information. The blocks represent concepts, and the lines are semantic relationships between them. The diagram should be read as a number of short subject-verb-object sentences, with the arrow showing the direction of the sentence. The following sentences could already be extracted from the Elephant Eater:
Cover is a process step.
Write is a process step.
Check is a process step.
Cover, then write.
Write, then check.
Check has an expiration date.
Check has a value.

Apparently, we have some information about a simple process and some unrelated information about a financial check. Both pieces of information are separate, even though they share “check” as a concept.
Two more Views are now inserted into the Elephant Eater (see Figure 3.6). View A is from a process-modeling tool. View B is from a design model, which describes some of the core concepts for a retail bank computer program. Although the Views are in different formats, the Elephant Eater understands their syntax and can translate them into a similar form of simple sentences. View A can be read as follows:
Check is a process step.
Repeat is a process step.
Check, then repeat.
View B would be read as follows:
Check is an order of payment.
Check has a value.

Both Views contain the concept of “check,” which makes the Views potentially ambiguous. The Elephant Eater can clarify this information in two ways. You can use the context of the Views to ensure that the information is inserted into the right area of the Elephant Eater. For example, “check” and “repeat” in View A are from a process-modeling tool, so as they are consumed by the Elephant Eater, they are both classed as process steps due to their context. After this is done, you realize that the information from View A can link to the existing process information stored in the Elephant Eater.
In the case of View B, the Elephant Eater would detect that “View B: Check” shares the same semantic relationship with “value” as one of the existing “check” instances in the Inventory. As a result, the Elephant Eater merges the information, as shown in Figure 3.7. The Elephant Eater now stores the facts that checks have values and expiration dates, but that they are also a kind of payment order.

Using this process to feed all the Views into the Elephant Eater, we can avoid project documentation ambiguity. The combination of syntax, semantics, and context provides a single source of truth, which we can use to understand the surrounding environment, the requirement, and, ultimately, the solution that is created. Inconsistency between Views is short lived because the Elephant Eater checks all new incoming information for consistency with the other information already contained inside.
This consistency checking also guards against parochialism. It is impossible to ignore the rest of the project if your perspective of it is checked daily against everyone else’s.
Views aren’t the only thing defining the solution that is fed into the Elephant Eater—the definitions of the environment that surrounds the solution contribute, too. In this way, it is possible to understand the environmental complexity and use it to ensure system compatibility.
This approach needs strong governance to ensure compliance, but it is exceptionally powerful at guarding against costly mistakes and late discoveries of requirements. This approach is central to the next two Brownfield Beliefs:
Establish One Version of the Truth
Embrace Complexity
We’ve reviewed complexity, ambiguity, inconsistency, and parochialism—now, what can we do about our industry’s unavoidable language speciation? The Elephant Eater’s ability to consume any language with a formal syntax means that language speciation is less of a problem. As long as a consistent translation exists between terms, you can express the Views in any language with a strong syntax. Indeed, the Brownfield approach actually recommends that Views be maintained in a native form selected by the maintainers and consumers of that View. This gives us our next Belief:
Use Your Own Language
After the Views are unified, the amount of information inside the Elephant Eater becomes very large and complex. To ensure that we can successfully communicate this information to the business and project sponsors, we must make sure it is not too formal or technical. The instruction to “use your own language” flows both ways, not just in defining the information consumed by the Elephant Eater, but also in ensuring that any information issued from it is done in a suitable form for its consumer.
As you will see in the next chapter, Brownfield has much to offer in the area of communication, especially in bridging the communication gap between business and IT.
We explained previously how the Elephant Eater consumes the complexity on a project. This approach enables people to continue using their own languages to define their Views while resolving inconsistencies and ambiguities, to ensure that the project stays on track. How is such an Elephant Eater constructed?
You could build such a beast in many ways, but IBM has built and patented its own version of an Elephant Eater using a tooling architecture called VITA, shown in Figure 3.8.

VITA is an acronym for Views, Inventory, Transforms, and Artifacts:
Views describe the systems or processes that explain aspects of business or IT.
Inventory is the repository that stores the information from the Views.
Transforms define the relationships between concepts.
Artifacts are the results generated from the Inventory.
The four elements fit together in an iterative process, which is the focus of the rest of this chapter.
We introduced Views in the previous chapter as human perspectives of complex projects or systems. In the context of VITA, we need to define them more tightly. Views are formal[1] descriptions of systems or processes that enable business or IT goals to be met. The Views must be produced in a formal manner (using a syntax) so that users can interpret them in an unambiguous way, as described earlier. Views are typically maintained by one or a small group of individuals with similar concerns, so they usually correspond to the perspectives discussed in the last chapter.
Views are the outputs from your requirements capture, whether those requirements are functional or nonfunctional, or the constraints of your existing environments that we mentioned in Chapter 1, “Eating Elephants Is Difficult.” Views can be static or dynamic in nature—that is, the concepts and relationships in the Views might be defined so that they have beginning and ending points in time. Therefore, it is possible for a View to describe either a single point in time or a whole series of different time periods.
Surprisingly, requirements often are captured with ambiguous methods, using tools that are designed to support normal office functions (such as word processing) instead of defining and designing new IT systems. The Brownfield approach encourages an end to such practices wherever possible, but it does not mandate that particular tools be used to capture these requirements and create these Views. Any tool that uses a consistent syntax to capture the information is sufficient. You can use Office tools, but they require a lot of discipline to ensure consistency. If they are the only option available to maintain Views, we have found spreadsheets to be more helpful than word processors.
The functional and nonfunctional requirements will normally be created specifically for the project. They are the business requirements of the real problem that you are trying to solve. In Brownfield, the specific method and tool is not as important as the capability to capture and output this information as a formal description. The use of the Unified Modeling Language is encouraged along with formal tools for defining business processes, the system design itself, and the data it needs to process. Users can treat each of these elements as separate Views using existing formal tooling.
In addition to the functional and nonfunctional requirements, a third type of requirement exists: constraints. These often are imported from the existing environment, but they might also be derived from artificial constraints driven by legislation, contracts, standards, strategies, or enterprise architecture requirements.
The descriptions of the existing environment likely will come from numerous sources, some of which might exist in a structured format. For example, interfaces might have formal definitions, and existing database structures are also likely to be defined and documented. However, many of these constraints might not be documented in any way, or that documentation might have been lost or not updated. In such cases, it might be possible to discover some of these constraints.
You can discover these constraints in two basic ways. The first is to use a manual iterative cycle of testing, discovering new requirements until you develop a more complete picture of the environment. The second is to use automated tools to discover these constraints. In recent years, a number of “static” program-analysis tools have been developed to analyze and document existing program code and database structures. You can feed the output of these tools into the Elephant Eater as a source of requirements (especially constraints). This trend for automated discovery will likely continue in the future.
Whether an iterative discovery cycle or static analysis is used to discover the existing environmental complexity, the result is a documented set of Views that contains many previously unknown or ignored constraining requirements.
The Views described previously are collected and stored in a single repository called the Inventory. Views are imported into the Inventory via importers. IBM’s Elephant Eater already has a large number of importers to translate many common types of Views. Users can easily build Importers as required to cope with new and different Views from different methods and tools.
The importers translate the Views into a common form within the Inventory. The Inventory must be kept consistent, so the importers check the View and ensure that it is consistent with the information that the Inventory already contains. As you learned when we clarified the check example earlier in the chapter, the importers check a number of rules to ensure that the View and information within the Inventory are consistent. If any inconsistencies or potential ambiguities are identified, these need to be corrected before the information can be imported.
For the importers to read in the Views and translate them into the Inventory, you would expect the Inventory to be extremely complex in structure. This couldn’t be further from the truth: The Inventory is extremely simple and mimics how the human mind associates information. The method the Inventory uses to store and structure the information, called a triple, basically emulates how a baby would speak.
As you would suspect from the name, triples consist of three pieces of information: usually subject, verb, and object. You can use these triples to relate items in everyday life. “Player kicks ball” is a simple example of a triple. The subject is player, the verb is to kick, and the object is ball. Although this is an extremely simple construct, this method forms the basis of the Inventory, and we can use it to describe extremely complex relationships.
The power of the Inventory is its capability to eat almost any type of View and interlink the new information with its existing entries. As its knowledge of the existing environment and the new system grows, we can use it to supply information for increasingly sophisticated tasks.
Many of these tasks are enabled by the Transform capability, which describes how concepts within the Inventory interrelate. In an ideal world, a business would handle a concept in one way. In reality, however, businesses end up with concepts being addressed in different ways in different parts of the business. For example, a person might be simultaneously an employee, a customer, and a manager. The information held about each of those types of person might be different, but there might be a single individual who is all of these things at once. In such circumstances, transformations are required to translate between the different ways in which a business represents the same thing. For example, it would be ideal for every system in a business to use and maintain exactly the same information for the same person and for any information held about the person, which was stored on more than one business system, to be consistent across all of them. Unfortunately, due to the division of businesses into departments or via the process of mergers and acquisitions, such a world rarely exists. In the world of Brownfield environments, the same data or concepts commonly are stored in many different formats in multiple systems while the enterprise has grown organically. As a result, transformations are needed to match up the way different systems handle the same concept.
To illustrate how a transformation shows the relationships between concepts, consider a very simple example in which customers’ names are stored on two separate systems. On system A, the name is stored as a single field containing the full name. On system B, the name is stored in two separate fields, one for the family name and the second for the first name.
The fields are fundamentally storing the same data, but in slightly different ways. Transferring the name data requires a number of transformations to be defined. These transforms are dependent upon the direction in which the data is being transferred.
To transfer the name from system B to system A, a very simple transformation is required. System A requires the first name field and the family name field to be combined and separated by a single space.
Transferring the name from system A to system B requires two transformations. The first transformation to fill in the first name needs to extract all the names before the last space in the name in system B. The second transformation for the family name performs a similar process, but this time extracting the name after the last space.
Transforms enable the Elephant Eater not only to store basic concepts and their relationships, but also to store information about how these concepts interrelate. Such a transformation capability underpins many of the difficult and complex tasks we face on large projects, such as migrating data between systems and linking systems. To enable this to happen, the Elephant Eater uses its stored concepts, relationships, and Transforms to create Artifacts.
The concepts, relationships, and Transforms collected in the Inventory from multiple sources can help in a project only if we can use the Elephant Eater to inform and accelerate the production of the solution that is required. Instead of just being a repository of information, the Elephant Eater can be used to create a wide variety of Artifacts.
This capability of the Elephant Eater is based on an IT industry practice called Model Driven Development (MDD).[2] On a simple level, the approach enables code to be generated from the kinds of models we have been discussing instead of programmers writing them by hand. Our Brownfield approach similarly uses the information in the Inventory, along with the Transforms, to generate a wide variety of Artifacts. The term artifact is used to cover all outputs that the Inventory information can generate. Typically, these outputs include documentation, configuration, executables, and test cases.
Documentation is probably the easiest type of Artifact to understand. The Inventory holds most information about an entire organization. Therefore, it is only natural that one of its uses is to produce documentation that describes this environment. This documentation should be in the language (or format) of the consumer. Although the Views were input in a formal way, the output can be a simple word-processed document.
You can use the Inventory to produce documentation at all levels, from high-level, system- or enterprise-level overviews down to detailed system documentation regarding a particular interface or database table. We look at how this is done in the next chapter.
The great power of this technique is that all the documentation is generated instead of written by hand. As a result, it is self-consistent, and references between artifacts are always current. By ensuring that the information is consistently fed into the Inventory, we ensure that any output documentation is also consistent—whatever form the documentation might take. The output is often diagrams, Microsoft Word documents, or spreadsheets—whatever is most suitable for the consumer of the information.
Configuration artifacts are another category of output that the Inventory can generate. Configuration artifacts are used to define, set up, or control products within your IT estate. For many products, their configuration is stored in specially formatted text files that can be edited directly. Increasingly, the configuration files are generated as a result of user inputs. For example, most modern databases use standard formatted configuration files to define the database layout and structure. For many other products, proprietary configuration formats currently exist.
The use of MDD and the merging of information from many different Views into the Inventory enable the Elephant Eater to produce configuration artifacts for either standard or proprietary formats. This enables us to efficiently maintain database, package, and system configurations, and ensure consistency among them.
Executable artifacts are run within a computer system to perform a business task. Frequently, this is program code, but it can also include user interface screens, interface definitions, or rules for business rules engines. These Artifacts are generated from the information within the Inventory and can provide consistency across your enterprise. For example, a change to a concept in the Inventory might require changes to the user interface, the rules engine, and the database configuration. Fortunately, because these elements are now generated, ensuring consistency and verifying that all changes are made efficiently is no longer an issue.
Indeed, this capability to quickly make changes across a hugely complex system by changing one element of the requirement and watching that change result in the automatic regeneration of potentially hundreds of Artifacts shows how the Brownfield approach answers one of the problems raised in Chapter 1. In that chapter, we introduced the ripple effect, in which the interconnected complexity of a large environment can make small changes potentially costly and lengthy—the small change can create a ripple of changes, resulting in lengthy analysis, many manual changes, and massive retesting and reintegration. This is not the case with Brownfield. In our approach, the ripple is absorbed within the Inventory, and all the necessary changes to Artifacts are made when the solution is next generated. Admittedly, a change to a core concept (such as a customer) could result in huge numbers of Artifacts being changed and, thus, needing to be tested—but we have a mechanism to deal with that, too....
In addition to the documentation, configuration, and executables, the Elephant Eater can produce test artifacts. These test artifacts are designed to test the code that the Elephant Eater itself has generated.
It might seem strange to have the same system generate both the code to be tested and the tests to prove that code. However, a major part of everyday testing is to ensure that the system works as specified. The Inventory contains the information on all the constraints and valid values for the Artifacts that it produces, so the Inventory is in an excellent position to generate exhaustive test scripts and data to ensure that the requirements are all satisfied. Naturally, it uses a generation approach independent from the one that was used to generate the system itself.
With such a strong capability for test generation and self-testing, the Elephant Eater enables us to cope with ripple effects caused by environmental complexity. We can perform significant automated testing (regression testing) to ensure that the system still works as expected after an important change has rippled through the system.
When the automated Elephant Eater-based tests are complete, users and the system’s operators must perform overall acceptance tests to ensure that what was fed into the Elephant Eater as the requirement actually satisfies the business and technical needs. Because Brownfield is an accelerated, iterative process, we can quickly incorporate new requirements discovered at either testing state and generate a new system.
The Views, Inventory, Transforms, and Artifacts that make up VITA are the core elements that make up the Elephant Eater. By feeding all requirements, including constraints, into a single place (the Inventory) and ensuring consistency among them, you maintain in the Inventory a single source of “truth” for your project. Thus, you gain an always-consistent solution.
On one $600 million government project, the system being developed used a heavily scripted user interface to capture information. This information was stored within the system until a number of interviews were completed and all the required information was captured. The information was then split and passed on to a number of legacy systems for processing. Unfortunately, the legacy systems were rejecting the messages because the information they received was incomplete. The cause was simple: The rules used to generate the scripted questions and gather the information were not the same as the rules that the legacy systems used to validate that data. The two sides were generated from their own models, and those models didn’t quite match. This wasn’t as obvious a mistake as it would seem because more than 1,300 questions were used. The two parts of the solution were not completely consistent. | ||
| --K.J. | ||
Figure 3.9 shows an example of an Elephant Eater in action. First, we decide which Views we need to support the project and solution. In this particular case, we identify that we need three Views. One provides a business perspective (including the frequencies of business transactions), another provides the logical design of the system, and the final View contains the infrastructure design. The initial harvesting of these three Views from existing sources and converting them into a standard syntax form is known as the site survey.

In the example, these Views are fed into the Inventory from three separate tools. This is not unusual because each perspective is different and likely is maintained by a separate team. Each View provides a different perspective of the same solution. As they are imported into the Inventory, their contents are checked for consistency. The Inventory importers have been programmed with a number of simple rules that the system can use to check the consistency of the Inventory:
Every component in the logical View must be located on a computer in the infrastructure View.
Every computer in the infrastructure View must support at least one component.
After the Views are imported, they form a single interlinked body of knowledge expressed in triples. Regardless of how the information was fed in (shown by the three black outlined ovals), the system can produce a new extract of information from the Inventory that contains information from any or all of the original sources. In this case, the shaded extract uses some data from each of the Views.
This extract is used with any relevant Transforms and MDD techniques to generate a new Artifact. In this case, the elements are combined to automatically generate a performance model that predicts how big the hardware elements for this new system need to be and how long it will take to process each business transaction. The same extract can be used to generate many other Artifacts.
The great beauty of this approach is that as the Views change, the performance model changes with them. We can quickly and confidently predict the hardware cost of a business or system design change instead of manually impacting the change and trying to keep the performance model in step with three rapidly changing Views. Design optimization and priority balancing becomes much easier and is achieved in a dynamic and iterative way.
Figure 3.9 showed how a Brownfield project is built using Views as input to create a “single source of truth” in the Inventory. Of course, this is not necessarily the complete truth, nor is it necessarily true. The Inventory is just a well-documented collection of the requirements (Views), neatly cross-referenced. It is effectively a baseline understanding of the project at that point in time. The Inventory might be consistent and unambiguous, but the Views that populate it could still be wrong or incomplete. This is why Brownfield puts such an emphasis on early testing.
The Brownfield approach differs from the Greenfield approach, in that the nature of processing the requirement does not change during the lifecycle—however late a defect is discovered. In Greenfield approaches, the focus of defect fixing and testing moves from high-level design, to low-level design, to code, and then back out again through a variety of testing phases. Brownfield development ensures that the requirement is always maintained, not the end product. Every iteration brings you closer to your complete set of requirements and the solution. Figure 3.10 describes this lifecycle.
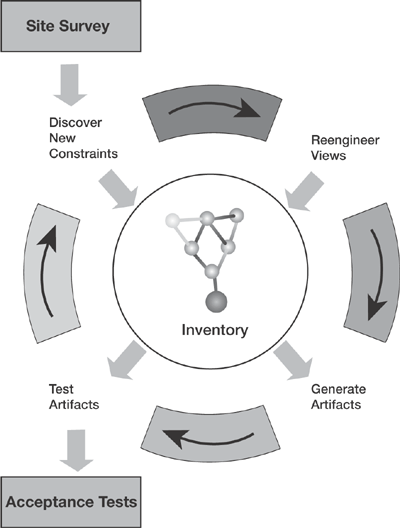
The lifecycle starts with a site survey, as described earlier, and then moves into an iterative development and testing cycle. Within that cycle, we iteratively do the following:
Discover further information about the problem by feeding in information from existing sources—. Sometimes converting the existing information into a formal View suitable for the Inventory can take significant effort, and often it is most effective to feed in the information in stages.
Reengineer the information in the Views to reflect our latest understanding of the requirements—. Artifacts are always regenerated instead of edited directly, so editing the Views (often expressed as UML models during re-engineering) or the patterns that are used to define the Artifacts is the way we create the solution. We use this method to correct any defects that the Inventory import process identifies.
Regenerate the Artifacts—. You should do this on a regular basis so that people know when Views need to reach a point of consistency. Each time, the Views are imported into the Inventory and the system produces a list of import errors for correction.
Test the Artifacts—. The configuration and executable Artifacts are automatically tested to ensure that the Inventory definition and the behavior of the executing components match. The system feeds defects back to the View owners for correction.
The iterative and generation aspects of Brownfield are important, so we give them a Brownfield Belief of their own.
When the Elephant Eater is in place, it changes the whole way we can efficiently execute projects. We can now generate a large proportion of the solution on a regular basis instead of writing it by hand. In addition, the generated elements are kept in step with the Inventory, and each other, with minimal effort. Indeed, on a Brownfield project, we would expect to see all artifacts regenerated on a daily (or nightly) basis.
This enforced consistency of requirements provides a robust, yet highly adaptable platform on which to build large and complex solutions. As the Inventory changes, the generated Artifacts also change with minimal effort. As a result, an initial import of information into the Inventory from a site survey might be enough to begin generating and testing elements of the solution much earlier in a project lifecycle than was previously possible. As you saw in Chapter 1, early defect detection is a highly advantageous strategy. The Brownfield approach makes it possible to quickly build solutions, test them against the real environment, find out where the requirements are lacking or poorly defined, and fix them. Because the solution is built up incrementally on firm foundations, this is a cost-effective and superb way of handling both system and environmental complexity.
Brownfield is designed to work alongside existing environments. The site survey is not just a way of feeding in environmental complexity; it is also a way of absorbing that complexity to reengineer and incrementally change it. Brownfield is not about throwing away existing systems, but instead enabling them to be reengineered piece by piece in a controlled manner. The use of discovery techniques in the site survey and the capability to “eat” existing complexity leads us to the last of our Brownfield Beliefs....
The Brownfield Beliefs represent a new way of thinking about delivering complex systems instead of a set of technologies or products. To change something so fundamental, you need an easily communicable set of ideas instead of 200 pages of prose. Therefore, the Brownfield Beliefs form the blueprints of the Elephant Eater, as shown in Figure 3.11.

Now that we’ve introduced them individually, we can consolidate them in one place. The Brownfield Beliefs are:
Make Business and IT Indivisible
Establish One Version of the Truth
Embrace Complexity
Use Your Own Language
Iteratively Generate and Refine
Use What’s Around
Many of these beliefs have a strong technical aspect to them, so although this chapter provides an overview of what they mean and why they are important, each one is covered in more detail in Part II, “The Elephant Eater.” The rest of this chapter summarizes the beliefs, and points the reader in the direction of further information, if desired.
IT is rarely a means to its own end. The move toward SOA is drawing IT and business closer than they have been for many years. Even so, many businesses still have separate groups within the IT organization fashioning the service requirements, and another group designing and deploying the solution.
Business and IT are intrinsically linked. A change in one ripples through to the other. Business and IT need to get used to this idea and start dealing with it properly. Changing an aspect of the business should be understood in the context of an IT change, and vice versa. Maintaining such traceability between the two domains as a matter of course is currently rare. We return to this theme in the next chapter to see how Brownfield meets this need.
Assuming that the world can be simplified is an assumption that appears to underpin the fundamental nature of the IT industry. Poor technical assumptions (generalizations and abstractions) during the early stages of projects—when the genuine complexity of the surrounding environment and the solution tends to be conveniently ignored—give projects a false sense of security. Using traditional Greenfield techniques, the IT industry sets out to build on very complex Brownfield sites by ignoring hundreds or thousands of relevant constraints until it is too late—or simply very expensive to cope with them.
Chaos theory tells us that even the simplest systems can be unpredictable. Humans, businesses, and economies are not simple, and change can be chaotic with multiple feedback loops and ripple effects.
The IT industry and business need to recognize the complexity of reality instead of taking a sanitized, generalized, and poorly abstracted “fluffy cloud” view of the world. To do this efficiently, we need to find automated ways of discovering what is out there and recording its complexity. We further elaborate on this belief in Chapter 6, “Abstraction Works Only in a Perfect World.”
Solutions for Brownfield sites must be cost-effective and optimizable, because the cost of maintaining the Brownfield itself absorbs a significant portion of the IT budget. Writing thousands of lines of code by hand is no longer an effective, maintainable, or acceptable, answer. Packages, software reuse, and legacy reuse need to be part of the solution, not part of the problem.
After the Elephant Eater discovers the complexity of Brownfield sites, it becomes possible to find effective ways of working with them and changing them incrementally. Strategies include incorporating packages, reusing existing code, and using MDD. We can even start using the power of the VITA architecture to perform software archeology on the legacy systems. By feeding legacy code and configuration files into the Elephant Eater as part of the site survey, we can mine and communicate the lost structures and patterns of the legacy code in new ways. In this way, we can begin to rebuild the legacy systems according to new patterns and technologies. Applications generated from the Inventory and comprised of components from many sources become the norm instead of the exception.
We explain how this software archeology is performed using the Elephant Eater in Chapter 9, “Inside the Elephant Eater.”
Adopting these approaches means that we can iteratively refine and test complex areas such as interface behavior or legacy business rules, similar to how agile development techniques changed the way the IT industry defines user interfaces (via direct interaction with the real world instead of the creation of theoretical specifications in isolation).
These innovations, combined with intelligent new ways of working with the existing Brownfield sites, result in smaller projects with a faster turnaround and greater levels of reuse. Projects become more incremental than revolutionary, reducing their overall risk and gradually reducing the maintenance cost. Chapter 8, “Brownfield Development,” elaborates on this topic.
Feeding information into the Elephant Eater can’t be done in some complex and precise dialect that everyone needs to learn. Just as Brownfield embraces complexity, it also embraces the idea that people genuinely need to look at problems in different ways and use different vocabularies. They need to speak their own language and create and maintain their own Views.
It is also imperative that the Elephant Eater communicates and relates the relevant information that it has digested so that we can build a new solution. Detail is often a necessary and desirable part of that communication, especially when generating code or configurations; however, summaries are also necessary to ensure that the Elephant Eater can communicate high-level information to people who don’t want to see the detail. These more abstract perspectives are created from the detail in the Inventory. Therefore, these perspectives are more reliable than the high-level information that IT architects using conventional Greenfield techniques often create and issue.
These outward communications from the Elephant Eater (the Artifacts) must be in multiple recognized languages (computer code, English, design languages or models, and so on) and multiple forms (text files, Microsoft Word, pictures, and so on) while maintaining the formal and precise meaning.
Ideally, the Elephant Eater will be such a good communicator that informal communication tools, such as PowerPoint or Visio, could be eliminated in most cases. We cover this topic in Chapter 4, “The Trunk Road to the Brain.”
However, for the Elephant Eater to work, each of those native format Views must be hooked into a single conceptual body of knowledge defining the overall environment and solution.
Ambiguity and inconsistencies are removed incrementally by converting imprecise documents to precise Views. These Views are combined in the Inventory, and then inconsistencies, ambiguities, and missing information are incrementally identified and corrected. In this way, natural language-based ambiguities—that is, Word or natural English-based specifications and designs—are gradually excised from the definition of the requirement. The requirement and, ultimately, the solution design become defined by the consistent and formal combination of all the Views. Ultimately, a recognizable and comprehensive single version of the truth emerges, to describe the whole of the environment and the solution expressed in terms of multiple, combined Views within the Inventory. This definition can then be used to generate much or all of the solution.
These Brownfield Beliefs set the bar very high for a new way of working. But as the first two chapters explained, some fundamental areas of the IT industry’s approach need to change if the delivery of complex change into complex environments is to become a repeatable and predictable process that does not rely upon big-mouthed superheroes.
In the next chapter, we look at how we can complement this capability to build complex systems in complex Brownfield IT environments with another Brownfield unique capability: new communication mechanisms to help bridge the communication gap between business and IT.