
“The process of scientific discovery is, in effect, a continual flight from wonder.” | ||
| --Albert Einstein | ||
The previous chapter discussed the methods and techniques that form the foundations of Brownfield. We investigated each of these and compared the differences and similarities. Brownfield was shown to have evolved from these methods.
This chapter shows how the Brownfield method is used within the project lifecycle. As in the previous chapter, the lifecycle approach has again evolved as a composite of a number of existing lifecycle approaches.
Large-scale development has traditionally been based around well-organized phases. Each phase is completed before moving on to the next phase and is defined through work breakdown structures, work product definitions, and quality criteria. When viewed on a plan, these phases form steps down the page; this picture has led to the term “waterfall development.” The water moves in only one direction, filling each phase before moving on to the next phase.
The more complex projects get, the more rigorous the methods become—up to and including extensive use of static testing[1] and formal systems engineering techniques. These techniques are used to form quality assurance checkpoints at key points along the waterfall. The checkpoints check progress and create rigorous, strong baselines. The baselines are made up of a single set of unambiguous, formally signed-off documents. Figure 8.1 shows these project phases together with the quality assurance checkpoints used to enforce the rigor. The example shown uses the baselines defined in Carnegie Mellon’s Software Engineering Institute’s Capability Maturity Model® Integration (CMMI®).

On very large projects, many people have tried to shortcut this process (deliberately or through ineptitude, or both), and many have come unstuck.
As Barry Boehm and Richard Turner point out in their book, Balancing Agility and Discipline: A Guide for the Perplexed,[2] five factors determine whether waterfall or agile methods will prevail on any particular project. For the purposes of this book, we have rephrased them, but we have stayed true to the spirit of their findings (see Table 8.1).
Table 8.1. Comparison of Agile and Waterfall Methods
Agile Characteristics | Waterfall Characteristics | |
|---|---|---|
Size | Optimal for small projects and teams; reliance on tacit knowledge | Tailored for large projects and teams |
Mission-critical projects | Untested; general lack of documentation | Long history of use in such implementations |
Stability and complexity of existing environment | Continuous refactoring used; suitable for dynamic and simple environments (typically Greenfield) | Structured baselines used; suitable for more static and complex environments (typically Brownfield) |
Skills | Continuous involvement of highly skilled individuals; difficult to cope with many lower skilled resources | Highly skilled individuals needed in early phases; designed to cope with many lower-skilled resources in later phases |
Suitable organization culture | Chaotic; dynamic; empowered | Roles well defined; procedures in place |
As you can see, agile and waterfall development each have their strengths and drawbacks. To recast the comparison, it is both possible and safe to build a paper airplane without a detailed plan. It would be foolish to spend 20 minutes writing the instructions and then spend 20 seconds building the plane. However, building a passenger airliner without detailed, upfront design would be a long and expensive process involving a lot of rework that you would otherwise have avoided. (You’d also probably face a shortage of test pilots to take the airliner on its maiden flight.) Figure 8.2 summarizes the different development techniques used in building a paper airplane and building an airliner.

In formal waterfall methods, defects are detected as early as possible through static and then executable testing. If defects are found, changes are made to the requirements, specifications, or solution design documents. Changes can ripple forward from the first work product affected to the last. This approach reduces the overall number of defects and is far more cost-effective than not following these best practices because it reduces the number of surprises and the amount of rework.
Stringent baselines and static testing of work products improves overall quality and helps ensure that more defects are found earlier. However, this is not a cheap method of delivering systems. A high level of process and discipline is required, and the method does not take into account the complexity of the environment much more than any other Greenfield method. The knowledge and impact of those thousands of constraints is still held over to the end of the project, typically into the late testing phases when changes are expensive, even with the best possible walkthroughs and inspections.
In reality, even in rigorous projects, a detailed requirement fault detected late in the waterfall lifecycle generally does not result in a change to the original requirements and demand that the subsequent work products and baselines be re-created and revalidated. Generally, workarounds for such problems are found and the proper solution is postponed to the next release.
Traditional waterfall methods decompose the problem to ever-smaller Views until the View is sufficiently small, detailed, and self-contained for it to be built by an individual, often in isolation. These Views are then tested in the reverse order of the decomposition, up to the final stage of a complete acceptance test. Unfortunately, this encourages a testing of the system by Views, too. Some of those Views (such as the integration or data migration elements) are often tested late and are expensive to fix. As you learned earlier in this book, it’s cheaper to fix things at the front of the process. Figure 8.3 shows the decomposition and testing of the views together with the increased cost of finding an error in that phase.
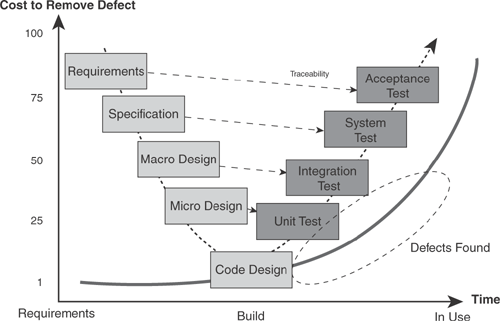
This test model, known as the V model because of its shape, is currently the industry’s best practice, but the requirements testing is performed only at the latest stage of the project lifecycle. This is the most expensive point in a project to find such errors and undoubtedly causes delays in what seemed like a project that was on schedule. Surely, a more cost-effective way of testing would be to follow the approach shown in Figure 8.4.
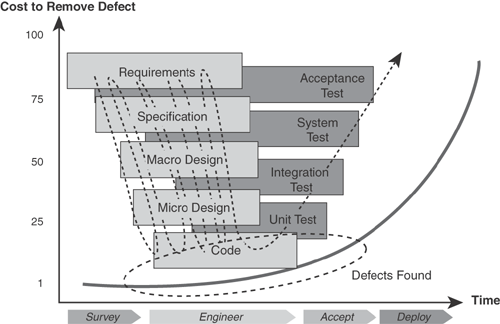
This alternative model preserves the traceability of the original testing model, but the testing of the corresponding baseline is performed as soon as possible. In addition, “deep dives” are repeatedly made by building some aspects of the system early and testing them against the requirements; this enables at least some of the late-stage testing to be brought forward. This approach clearly looks a lot like agile[3] development, and it is—agile works by effectively implementing some of the requirements and then using this to capture further requirements as deltas for the current situation. This is repeated until the total requirements are captured.
Unfortunately, the agile approach works well only for Greenfield projects or medium-size projects in simple environments; the approach is often flawed for bigger, more complex solutions or those that have a lot of constraints. The previous chapter detailed an example of a Greenfield approach destroying an essentially Brownfield project with the creation of a Web front end on a complex credit card processing legacy system. In that particular project, agile techniques were used to determine the user interface and Domain Object Model (DOM) that formed the basis of the new system. The DOM defined the business information and structures used to define the problem, and these were developed iteratively with the business. Alongside the DOM, user interface prototypes and object models were iteratively refined based on business user feedback.
However, the constraints of the legacy system were poorly understood, and the DOM that was created was inherently incompatible with its surrounding environment. The iterative approach did not allow those elements to be properly understood early enough.
Waterfall techniques are excellent at dealing with the nonfunctionals, good at dealing with functionals, and reasonably good at dealing with constraints. Agile is excellent with the functionals, poor with nonfunctionals, and very poor with constraints.
The options for a sizeable reengineering project seem to boil down to these:
Finding out all the requirements, including constraints, before starting, and designing the ideal system to implement them (very expensive)
Growing the solution and discovering all the requirements as you go, but with the effect of building a suboptimal system and the danger of substantial rework (also very expensive)
We need a technique that combines the best bits of agile and waterfall but that sorts out how to handle constraints. What has the industry achieved in this space so far?
Boehm and Turner look at good examples of hybrid waterfall/agile approaches in their book Balancing Agility and Discipline. One example takes a look at an agile project of considerable size and another considerably sized, mission-critical project with agile-like deadlines and targets that demand agile behavior.
Looking at a successful project that used agile programming techniques to deliver a system of the magnitude we are talking about, Boehm and Turner found the following to be true:
The effort to deliver features increased nonlinearly over time (well outside the bounds of a normal agile project). As you might expect from earlier chapters of this book, this was ascribed mostly to communications overheads.
Increased formality was required around the design. Architectural perspectives were required to divide work and to ensure a valid design for areas that were both complex and subject to change.
Tacit knowledge was not enough to define all the requirements (especially for specialized use of complex function) and did not scale sufficiently.
An “integration” gap (of some 12 weeks) arose between “zero defect” functionally “complete” code and actual delivery of working integrated code.
As a result, some of the key tenets of agile programming had to be diluted or lost completely from their hybrid approach. These findings strongly match our experience in using agile techniques on large projects.
Using another example in the same book, we look at a fundamentally waterfall-created, mission-critical system that applied agile techniques to accelerate its development. Boehm and Turner noted that agile development on its own was not enough to maintain control, and they had to introduce the following innovations:
The documentation for the system needed to be automatically generated from the architecture and code artifacts.
The early phases of the project were used to design and develop robust patterns that could underpin the elements developed with agility.
Integration and performance testing was performed early and often instead of being performed at the end.
Both of these examples are telling. The three points mentioned are also techniques we have used on Brownfield projects. Certainly, we should expect any “hybrid” method that contains the best of agile and waterfall to offer the kind of capabilities identified in the previous best practices examples. We believe that the Brownfield approach enshrines such a method that enables all three kinds of requirements (functional, nonfunctional, and constraints) to be applied iteratively and incrementally throughout a project without losing control.
Let’s look at a specific example of what the Brownfield approach is capable of—and let’s choose a painful example for traditional waterfall or agile approaches: the integration of a new system with a highly complex, mission-critical legacy system. Both methods tend to fall down in this area: Waterfall tends to find defects late; agile tends not to apply constraints early enough.
Determining all the requirements of an interface is often difficult, especially when dealing with a legacy interface. This is why so many large system projects stall at integration testing. An agile-type development style on interfaces might seem the ideal solution, but it is difficult to discover the requirements, and current approaches fail to turn around solutions fast enough to uncover a solution to missing requirements (usually constraints).
Capturing interface requirements relies on many stages of copying and translation before implementation. This creates a whispering game, which can be countered only by additional effort in cross-checking. A large part of the cost of testing an interface is in verifying that the built interface actually performs as specified. This normally has to happen before any real testing of an interface can be performed.
The whole situation is then made worse by assuming that the world stops when the project starts—that is, that requirements are captured at a point in time and don’t change. Is this a realistic assumption?
Clearly, when existing and well-established systems are involved in the integration, their release cycle is unlikely to synchronize with that of any new project. The constraints on the interface might subtly or importantly change during the elapsed time of the change project. Indeed, with the high stack of paper that described the interface constraints on one of our projects, it would have been surprising if a significant number of those pages hadn’t changed over the duration of a big project.
Surely there must be a better way.
These kinds of problems led to the development of the Brownfield approach.
So, how is this achieved?
The Brownfield development approach is partly based on the Model Driven Architecture (MDA) approach. Brownfield development extends MDA with the VITA architecture that Chapter 3, “Big-Mouthed Superhero Required,” introduced.
MDA is defined by the Open Management Group (OMG) as a way to enhance the delivery of systems so that a description of the business problem can be created independent of any specific technology.[4]
The industry has been on a long journey since before The Mythical Man Month to create standards for the formal documentation of its designs and its code. As you learned in Chapter 6, “Abstraction Works Only in a Perfect World,” there has also been a gradual rise of the abstraction level of code itself during this time (from machine code to business-modeling tools and the like).
Typically, these days this means that the models developers use to describe the code also work for round-trip engineering. The picture-based models are used to generate code “stubs,” which the developer must then fill in. If the developer changes the code so that the model needs to be updated, the model will be automatically updated as a result (hence, “round-trip”).
MDA takes this stub approach a step further and makes the model the central part of the process, with significant elements of the code being automatically generated from yet more abstract-level models.
Within the MDA philosophy are important divisions between the model types, creating a spectrum from business through to technology. These models are the Computation Independent Model (CIM), the Platform Independent Model (PIM), and the Platform Specific Model (PSM, which is then characterized by a Platform Model).
Table 8.2 describes the major characteristics of these models:
Table 8.2. Major Models in Model Driven Architecture
Model | Description |
|---|---|
Computation Independent Model (CIM) | A CIM does not portray any structure of the system that supports it. More colloquially, this is known as the Domain Model. Terminology that is familiar to the business itself gives it a way to represent the structure of the business problem. |
Platform Independent Model (PIM) | The PIM is a representation of the system without the specification of any technology. This is more colloquially known as the logical or analysis-level model. |
Platform Specific Model (PSM) | The PSM specifies how the PIM is implemented on a particular platform. Typically, the PSM is expressed via the relationship between the PIM and a Platform Model (PM). (For often-used platforms such as CORBA or J2EE, Platform Models are already available.) |
Figure 8.5 shows how these models are used to generate code that is relevant to the business problem (described in the domain).

This layering approach enables you to make the implementation choice (described by the PSM) of a particular business problem later in the project lifecycle. It also enhances the capability to move solutions between implementation platforms—or even to implement them on more than one platform, if necessary.
Pattern Driven Engineering (PDE) extends the MDA approach by encouraging the adoption of industry-proven patterns at each stage of the modeling process. These might be existing domain models (such as the IBM Insurance Application Architecture model for the insurance industry[5] that operates at all the modeling layers of the MDA stack) or simply well-recognized patterns specific to a particular technology. IBM has recently begun to formally identify and classify patterns that assist in the transformation of existing environments. (Aptly, these are informally known as Brownfield patterns.)
PDE is not yet as well known as MDA, but it likely will underpin the next wave of enterprise solutions, architectures, and assets.
Such use of patterns improves the maintainability, understandability, and reusability. In addition, because these are proven patterns, they should maximize the future flexibility of the generated systems. Patterns are a key mechanism to accelerate design and implementation while minimizing risk as they are previously proven and considered “best practice.”
Brownfield was born out of projects that made extensive use of MDA and early use of PDE to solve complex business problems. Brownfield, however, takes things a significant step further.
Brownfield builds on this MDA/PDE process of increasing precision and reducing abstraction by reversing it.
Brownfield uses code from your existing environment, code patterns, application patterns, and architectural patterns to infer the existence of the CIM.
Instead of applying patterns in a structured way, we identify the key patterns used at each layer of the existing environment and represent the environment at gradually higher levels of abstraction. Step by step, the underlying structure and logic from the existing environment is reverse-engineered. In simple environments with many existing sources of formal documentation, this is a quick process. In more complex, undocumented, or badly designed or architected environments, this can take much longer. In general, it is not cost-effective to understand everything about an environment, but to focus in on those areas that are central to understanding the problem being worked on.
Ultimately, the technology-independent elements that describe the existing business implementation can be represented in the Inventory. With the existing business problem so defined, the reengineering of the domain, logical, or physical system can be performed. This reengineering, which is performed by the creation and manipulation of target Views, often models themselves, can now be done in the full knowledge of the existing constraints that the existing systems impose. This enables us to impose a real-life understanding of the impact of any proposed changes.
The reengineering process then becomes an iterative one, with new Artifacts describing the new solution. These Artifacts can be modified models, new run-time elements, or simply visualizations of the new elements in context.
We can then use the existing MDA/PDE process outlined earlier to regenerate and reengineer elements of the business problem.
Figure 8.6 shows a comparison with the MDA approach.

We likely will not get the CIM from the code in one step, so the process is one of gradual refinement and incremental understanding—but it is fundamentally automated and much faster than trying to find out the information using conventional interview techniques or code inspections. Each time the Views are fed into the Inventory, additional observed patterns that were identified as missing from the previous iteration are fed into its “vocabulary” for conversion into Inventory entries.
As the code and architectural layering of the system are identified, the high-level, business logic elements of the system become more obvious as they are separated from the middleware or infrastructure code. The process is fast but necessarily incremental: It may initially be impossible to see the wood for the trees, but after a number of iterations, the areas of interest for the logical and business layers of the solution become clearer. The platform-specific elements are identified and fed into the Inventory, enabling the higher-level structures to be inferred or harvested.
The speed and efficiency of harvesting is further enhanced by the use of the Inventory to generate interim Artifacts that can be used for testing purposes.
These Artifacts can be documents, visualizations, or actual executables. Documents and visualizations are used for static testing. In static testing, the final solution is not available to be executed, so other techniques, such as walkthroughs, inspections, or mappings, are used to detect incompleteness or defects.
With an Inventory, the static testing mapping technique becomes highly automated. The Inventory is particularly powerful when the definition of one poorly understood element of a problem has to match a well-understood area. Missing Inventory entries (missing mappings or missing equivalent data in source and target, for example) are obvious clues for missing requirements and constraints.
The capability of Brownfield to cope with partial information over multiple iterations means that even executable testing becomes possible, potentially earlier in the lifecycle than would otherwise be the case. Not only that, but the quick cycle time of the Brownfield process means that iterative testing and improvement becomes the preferred way to work.
In a previous project, the Inventory was used to generate interface Artifacts for a complex environment. Now, when the project began, certain key elements of the environment were not known. First, the legacy systems that the interface had to connect to were unknown entities. Second, the executable environment for the interfaces was an Enterprise Service Bus (ESB) that had not yet been defined.
Although the project had access to basic interface specifications that described the format of messages and their valid content, the interface specifications did not contain all the information about the internal constraints of the legacy systems that governed their behavior. This information was not forthcoming because no one knew what it was.
In addition, although the team knew the basic patterns involved in creating a generic ESB, it was unclear which directions some of the key architectural decisions would go. Prevailing wisdom would have said, “Don’t write any code until you know how the ESB is going to be built.”
A Brownfield analysis of the major areas of the target legacy system code was a possibility, but access to the code was less than straightforward. As a result, the team decided to use a Brownfield approach to iteratively generate simple interfaces that could be enhanced over time.
The generation process did not just create pattern-based implementations of the necessary interfaces; it also generated (via an independent generation process) test cases that could help determine whether the Artifacts—and their generation process—were working as expected. This automation largely removed the need for unit and component system testing.
As failures from the automated tests were collected, the reasons for the failures were captured and used to augment the knowledge collected about the business domain. This new business domain knowledge was used to regenerate the interfaces, and the testing was repeated.
Simultaneously, as aspects of the ESB implementation became clearer, the patterns used to generate the interface implementations were enhanced to look more like the target platform model. Initially, the implementation was point to point (shown at the top of the diagram in Figure 8.7). Over a series of iterations, as the architecture of the ESB solution was decided and formal documentation was issued, the complexity of the model-driven implementation increased until the final solution included all the necessary patterns for a full-fledged and resilient ESB with redundancy across two sites.
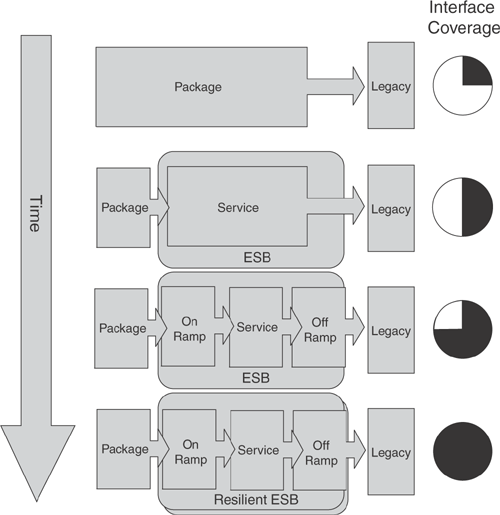
The iterative approach allowed a much earlier and much more gradual improvement of the logical correctness and completeness of the interface definition (the business definition) because the failure conditions were analyzed from the early model-driven implementations. If we had let the project wait until the final shape of the ESB was defined and had only discovered the unknown elements within the legacy systems when undertaking integration testing, then many months would have been added to the duration of the project. With more than 100 highly skilled people on the project, that’s conservatively a saving of $10 million.
From the previous description, you can more clearly see how the Brownfield techniques can accelerate and improve the solution quality of difficult and complex projects. Figure 8.8 summarizes the Brownfield development approach.
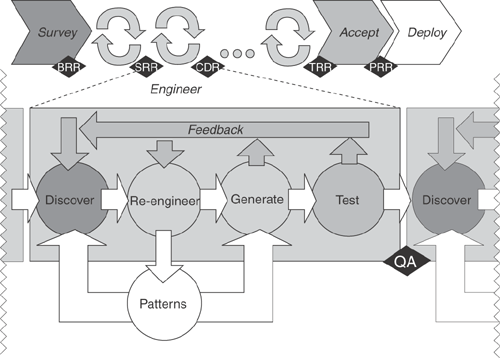
Brownfield essentially takes an iterative approach for design, development, and much of testing (in line with the modified V model we showed earlier). The main sequence of the method is essentially waterfall, however, and is split conventionally into four phases, as shown in Figure 8.8 and Table 8.3.
Table 8.3. Major Phases and Outputs of Brownfield Development Approach
Phase | Description | Major Outputs |
|---|---|---|
Survey | During the Survey Phase, the boundary of the solution is determined via a business context and a gathering of business events. The environment is scoured for potential inputs that lie within that boundary or interact over it. These inputs form part of a site survey, which is fed into the Inventory. The phase ends with an engineering plan being created, which structures the iterative engineering cycle that follows. | Business context Business events Use case list Inventory Engineering plan |
Engineering | The Engineering Phase is executed at least three times, but should ideally be executed on a daily to weekly cycle. (On a large project, it might be executed more than 100 times.) It follows a process of discovery, engineering, generation, and testing with feedback within that process. During this phase, the description of the problem, the solution, and the patterns underpinning the solution are incrementally refined. The individual steps within the Engineering Phase are covered in more detail later in this chapter. A formal estimation of project size (based on the Inventory, use case list, and problem definition) should be used to determine the actual cycle numbers and dates for n1, n2, nlast at the end of the Survey Phase and then should be revised at the end of Iteration n1. The Engineering Phase finalizes the Problem Definition and Solution Definition. | Iteration #n1 (SRR) Systems context Use cases Problem definition (CIM) Iteration #n2 (CDR) PIM definition Component model Operational model Performance model Source code Executables Test specifications Test report Iteration #nlast (TRR) PSM definition Test report Deployment package |
Accept | This phase performs the formal acceptance of the system by completing any remaining testing. The focus should be on acceptance and operational testing because other areas should be complete. | Test report Education and training materials |
Deploy | The accepted solution is handed over to service delivery and application maintenance personnel. Training and education for the new solution commences. The solution goes live. | Application maintenance turnover package Service delivery turnover package |
The Engineering Phase is worthy of specific attention because it breaks down into a number of subphases. The Engineering Phase is iterative in two ways; first, it is run at least three times during an engagement; in addition, it has built-in iterative feedback mechanisms within the phase itself. Table 8.4 describes the Engineering Phase.
Table 8.4. The Subphases and Outputs of the Brownfield Engineering Phase
Description | Major Outputs | |
|---|---|---|
Discovery | The Discovery phase is where additional information is fed into the Inventory. This information is in the form of formal Views or existing assets from the surrounding environment. Additional patterns can be created or sought out in this phase to increase the depth or breadth of knowledge within the Inventory. | Inventory updates Problem definition updates |
Reengineering | Within the Reengineering Phase, the knowledge in the Inventory forms the basis for a highly detailed description of the problem and, increasingly, a detailed description of the solution. It is likely that the “to be” state is different from the “as is,” and so some reengineering of Views, often expressed as models, is necessary. A pattern, asset, or package also might need to be reengineered to provide a good fit to the solution. Feedback from earlier engineering cycles will need to be taken into account in the solution definition and pattern definitions. | Definition updates Modified patterns Transforms |
Generate | The Inventory and patterns are combined to generate the solution or test Artifacts. Test Artifacts can include design documentation or visualizations for walkthroughs, formal test specifications, or unit test cases for executable testing. The generation component (also known as a Factory) can identify generation faults (which are corrected locally) or missing Inventory information that requires feedback to the next Discovery phase. | Factory defects (resolved locally for next iteration) View defects (fed into next Discovery iteration) Design documentation Visualizations Test specifications Unit test cases |
Test | Within each engineering iteration, some static or executable testing must be performed. Such tests will result in feedback for the correction of Views that are missing information (Discovery) or Views that need to be updated (Reengineering). | Test reports View defects (fed into next Discovery iteration) |
This chapter described how the Brownfield lifecycle is undertaken on a project. The lifecycle differs from that of the traditional waterfall method employed on large-scale developments and instead utilizes a more agile approach to the development lifecycle.
This approach has four major phases per release: the Survey, Engineering, Accept, and Deploy phases.
Within the Survey Phase is a site survey, just like what would be undertaken when building. The constraints of the existing environment are captured and then fed into the Inventory for later use.
The Engineering Phase is the main development phase on the project; it contains an iterative process of discovery, reengineering, generation, and testing. Requirements are discovered and introduced into the Inventory. The Inventory can them be checked to assess the implications of these requirements against the constraints captured during the survey phase. Reengineering includes the modeling of the problem and the application of patterns. The solution is then generated and tested. This cycle is repeated until the solution is complete.
The Acceptance Phase is the formal customer acceptance of the system. This includes operational and acceptance testing.
The final phase is to Deploy the solution, including handing it over to the operational staff, and to provide any training and education required to operate the system.
All these combine in a simple manner within a process to develop a large-scale development project efficiently while still retaining control of the project. Now that you understand the overall Brownfield process, the next chapter looks under the covers of the tooling that is required to support this process.
| 1. | Static testing consists of techniques such as inspections and design walkthroughs to test the system’s requirements, design, and implementation before the system can be executed. |
| 2. | Boehm, Barry and Richard Turner. Balancing Agility and Discipline: A Guide for the Perplexed. Boston, MA: Addison-Wesley, 2004. |
| 3. | This can equally be attributed to Rapid Application Development (RAD). Agile is used in this case as the current best practice of RAD-type development. |
| 4. | Mukerji, Jishnu and Joaquin Miller, eds. MDA Guide V1.0.1, Overview and Guide to OMG’s Architecture. www.omg.org/docs/omg/03-06-01.pdf. |
| 5. | IBM Financial Services Solutions. “Insurance Application Architecture.” www-03.ibm.com/industries/financialservices/doc/content/solution/278918103.html. |