
“We shall not fail or falter; we shall not waste or tire.... Give us the tools and we shall finish the job.” | ||
| --Winston Churchill | ||
Steps 5.1: Test Artifacts and 5.1a: Identify Generation Faults 199
</objective> <objective></objective> <objective></objective> <objective></objective> </feature>Chapter 3, “Big-Mouthed Superhero Required,” explained how the Elephant Eater was structured via the VITA architecture. Views are combined and interlinked in a single Inventory that can contain much of the aggregated knowledge of the existing environment and ways of working.
This Inventory supports translation between different representations of the same concept (Transforms) so that the enterprise can be pulled together into a documented baseline of understanding—a single source of truth. The Inventory can then be sliced from any perspective to generate Artifacts that can help engineer a solution to the problem.
Because the Artifacts are created from the Inventory, we can be sure that they will correctly represent the environment around them and will be consistent.
The machinery to support this capability is called the Elephant Eater. The overarching approach is called the Brownfield development approach. The terms Brownfield and Elephant Eater are used because the approach and tooling are designed to deliver large reengineering projects in existing complex business and IT environments.
This chapter delves into what is inside the Elephant Eater and explores some technologies and techniques that make it possible to build an Elephant Eater.
Clearly, the flow of the Brownfield development approach differs significantly from conventional large-scale IT systems development approaches. The approach is possible only when underpinned by the appropriate tooling. This chapter expands upon the Engineering subphase described in the previous chapter and looks at how Brownfield VITA-based tooling supports it.
Figure 9.1 provides further information on the Brownfield technology operation, expressed in terms of the VITA architecture presented in Chapter 3.
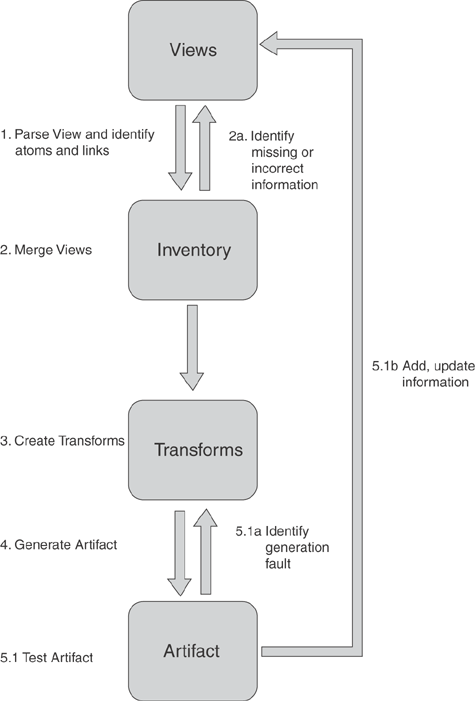
Views can be any means of describing the problem that follows a structured format. In practice, this is the Data Definition Language (DDL), use case, schemas, component models, process models, component business models, and even code. The following pages walk through Figure 9.1, following the steps and explaining how each element of the Elephant Eater works.
Views can be built from a wide variety of sources. Moving development tooling away from proprietary configurations to more open and published standards is helping the cause of Brownfield enormously. For example, Eclipse is an open-source community creating an open development platform. All Eclipse-based tools can easily be harvested to form part of an Inventory by creating plug-ins to facilitate the input the Inventory needs.
Table 9.1 lists other data sources that have been successfully harvested to form Inventories.
Table 9.1. Examples of View Input Types
Data Format | Harvested Examples |
|---|---|
Spreadsheets | Service models, requirements traceability and verification matrixes, nonfunctional requirements |
UML | Class diagrams, sequence diagrams, activity diagrams from component models and service component models |
XML/RDF/OWL | Other ontologies and inventories, including infrastructure inventories |
Formal data definitions | DDL and SQL, enabling the import of database schemas WSDL and XML Schema for Web services |
Code | Legacy COBOL, C++, Java, HTML |
We forecast that, over the next 10 years, the availability of discovery and static analysis tools will increase as clients demand flexibility from their existing estates instead of replacing them with new Greenfield applications. This will be the birth of the Brownfield movement, as the discovered information is drawn together in Inventories to enable reengineering and greater maintainability.
An early example of Brownfield discovery tooling is Tivoli® Application Dependency Discovery Manager (TADDM). TADDM can automatically discover the application infrastructure landscape of complex sites, including the layout of custom-developed applications built on J2EE or .NET.
The process of pulling together all these sources of information is collectively called the site survey. As in the rest of Brownfield, the site survey takes its name from the construction industry. If you wanted to build on any Brownfield site, local legislation would always insist that you do a thorough site survey first. We suggest that IT should be no different. The Brownfield development approach provides a cost-effective way of performing the site survey.
After you find and assemble the required Views, you must parse them into the Inventory.
Sometimes parsing a View is straightforward. Sometimes a View is simply created in a spreadsheet to stitch together two other previously unrelated Views. In such cases, the View is nothing more than a list of elements from View A paired with related elements from View B.
Diagrammatic views (such as UML diagrams) are not much harder. The Brownfield team has created an exporter that can automatically translate UML diagrams into simple subject/verb/object sentences that the Inventory uses. (Predicate is more formally used instead of verb in this context.) Using a class diagram as an example, the classes become subjects or objects, and the associations between those classes become verbs. Associations in UML are bidirectional by default, so a single association can often become two subject/verb/object sentences. These simple sentences are known as triples because they involve three elements. (The more correct term is semantic triple.)
In the simple example that follows, a small extract is provided from a component model. This component model describes the logical design of a small part of a system. Figure 9.2 shows how two components of the system talk to each other.
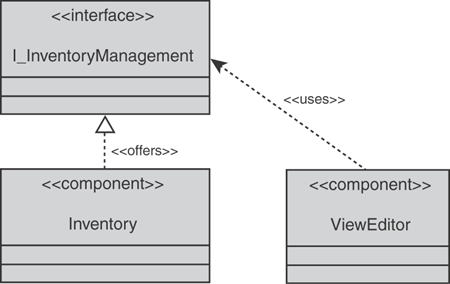
Don’t worry about the exact meaning of the lines and << >> symbols. For someone who understands UML, these lines make things clearer, but you don’t need to understand them; a textual description of the diagram will suffice to explain the point: In Figure 9.2, the Inventory is providing an interface that enables other components to interact with it (such as, submit data for inclusion). The diagram shows that such a View editing program (perhaps a spreadsheet) can use the advertised interface to talk to the Inventory. This diagram would be exported to the Inventory as a series of triples (see Table 9.2).
Table 9.2. Translation of Figure 9.2 into Triples
Subject | Verb | Object |
|---|---|---|
Inventory | Offers | I_InventoryManagement |
I_InventoryManagement | isOfferedBy | Inventory |
ViewEditor | Uses | I_InventoryManagement |
I_InventoryManagement | isUsedBy | ViewEditor |
Thus, it is easy to understand how such formal diagrams, XML, or spreadsheets can become Views. But for Brownfield to be truly effective, it must be capable of processing even the most mysterious of formal forms: legacy code (usually COBOL).
Now, this would be an almost impossible task if computer languages were not (by necessity) formally defined. Their formal definition puts them into exactly the right structure for them to be fed into our Inventory.
This is because the syntax (formal structure) of any computer language is almost always described (except for XML) in a variant of a standard form called the Backus–Naur Form (BNF). This syntax definition language was invented in the 1960s by John Backus to define ALGOL and then was simplified by Peter Naur.
When a program is parsed to be compiled, these BNF definitions are used to define a tree structure that can describe any valid program in that particular language. These Abstract Syntax Trees (ASTs) are routinely used throughout the computer industry to create development tools.
When a developer today uses advanced editing features within a code-editing program (such as when the editor automatically anticipates what is needed to finish a line of code), the development program is probably not analyzing the source code directly. More commonly, the code editor has loaded the developer’s code into an AST. The editing program then can conveniently analyze and modify the program source, ensuring that it remains consistent with the language definition.
As a result, programs to create ASTs from code have been readily available for pretty much any formal language since the 1960s. Some programs even use the formal BNF syntax definitions to automatically create programs that will read your programs and create the ASTs for you.
For the skeptical, Listing 9.1 gives a quick example of a simple Java™ program. The program simply declares a string called message with the content "Hello World" and then displays that message on the computer screen.
This short program was written within the Java editor that is available within Eclipse. Eclipse is a freely available open-source editor (www.eclipse.org). Eclipse sees this source code in a structure similar to our subjects, verbs, and objects. For each method, variable declaration, assignment of a value, or any other major valid operation in the language, additional triples are created in an AST that the editor holds in its memory. This simple program in Listing 9.1 has 25 of these top-level triples organized into a hierarchy.
Underneath these triples are further related triples that describe the features of that particular operation (and its allowed features). Even for such a simple program, these would run many pages in a printed book (some elements of the description are potentially recursive, so the printout could be very long). However, the Inventory does not need all this information—it needs only what is relevant to the current problem. Thus, the tree can be pruned to provide the important information. Figure 9.3 shows a simplified view of Listing 9.1 in its tree form.

By definition, this hierarchical breakdown of the code must encompass all the possible variations within the language, so encoding more complex programs just involves more of the same.
The gulf between Views (whether expressed as spreadsheets, XML, UML, or now code itself) and the Inventory triples should not seem quite so wide as it perhaps did. With these Views transformed into perhaps millions of simple semantic triples, the key question now is, how are these put together in the Inventory?
As discussed previously, the core structure of the Inventory is very simple: It consists almost entirely of triples. Before we delve into the detail of the Inventory, it is important to understand the complexity that triples can support. The next section explains how triples work in more detail.
Triples are really simple English sentences in the form subject/verb/object. You can use these triples to relate items in everyday life.
Consider a simple example of a dinner party with four people; let’s see how we can describe their social infrastructure using only triples. To keep this example brief, we will state only one triple, even though the inverse of the triple could also be stated. For example, “John is married to Janet” also implies (or could be assumed, given the nature of the marriage relationship and whether formal logic were applied) the inverse: “Janet is married to John.” Figure 9.4 shows how this triple is shown in diagram form.

Note that in Figure 9.4, the triple is represented as two circles, or atoms, and a linking line. In formal diagrams, these straight lines are usually shown as arcs, but for the purposes of this description, straight lines suffice. Each of these lines has the description of the relationship (or verb) identified as text alongside it. Note here that if Janet and John had multiple triples linking them, then, for the purposes of simplifying these diagrams, the multiple triples would be represented as additional lines of descriptive text on the same line, not as additional lines. (Multiple lines or arcs is the standard convention but would make these diagrams unnecessarily complex.) However, you should still read the relationships as separate triples, not as one pair of atoms with multiple descriptions.
The dinner party consists of two couples, John and Janet (John is married to Janet), and Bob and Marilyn (Bob is married to Marilyn). The couples know each other because John used to be married to Marilyn. (John is divorced from Marilyn.) This is a simple model of the situation and would be a good first attempt at capturing the situation. However, as noted previously, Brownfield is an iterative process of information gathering.
As more information is uncovered, it is revealed that John and Marilyn had two children at the time of the divorce, David and Katie. They have remained good friends for the sake of their children. (John has child Katie; John has child David; Marilyn has child Katie; Marilyn has child David.) Since John and Janet have gotten married, they have started their own family and now have a baby girl, Keira (John has child Keira; Janet has child Keira). David and Katie both live with their father (David resides with John; Katie resides with John). (We can also add that David resides with Janet; Katie resides with Janet.) Keeping up? More information has been added into the Inventory to further complete the picture.
As information about Bob and Marilyn is captured, it is discovered that Bob was also married previously, to someone outside the immediate group called Victoria. They had one child together, a boy called Tom (Bob has child Tom; Victoria has child Tom). It was a rather sad story: Victoria was killed in an automobile accident (Victoria has state deceased). Marilyn helped Bob get over the trauma, and now Tom lives with Bob and Marilyn (Tom resides with Marilyn; Tom resides with Bob). Figure 9.5 shows this information expressed in diagram form.

Further triples could be added to capture information such as age, sex, and address for each of our members to complete the picture. However, you can see the power of these simple triples: They have captured in a precise, unambiguous manner a complex social infrastructure that is difficult to explain in simple English.
However, care should be taken, in case some obvious information is missed. In the previous example, the Inventory does not contain information on whom Keira resides with. Keira is John and Janet’s new baby girl, so she resides with John and Janet (Keira resides with John; Keira resides with Janet).
This was implied but never stated explicitly. Care should be taken with triples to ensure that the implied information is also captured. For example, it is known that Keira resides with both John and Janet, but so do David and Katie. Therefore, it can be inferred that David and Katie reside with each other and also reside with Keira. This was never entered in the Inventory, although it can be inferred from the information already given. Figure 9.6 shows how this complex family information can be expressed as a diagram.

In Figure 9.6, the inferred links are shown as dotted lines. Some information already given has been left off this diagram because it is building into a complex diagram for two dimensions.
In a similar way, because David and Katie have the same parents, they can be seen as siblings. They could be brother and sister, but their sex has not yet been captured. This is the power of storing the data in the Inventory: The information that already has been imported can be used to infer other data. Perhaps this is obvious—why would a complex Inventory be required to determine something so obvious? The example given was indeed obvious because the information that was inferred was separated by only one degree of separation: Both children were linked by their parents. As the degree of separation increases, however, these relationships become less obvious, but links can be determined in the same manner from the Inventory.
In summary, the Inventory not only contains the captured information; it can also be used to infer further information and identify gaps in the information already supplied.
What if someone attempts to enter data that was incorrect? Let’s say Bob is married to Janet. Figure 9.7 shows this incorrect information together with some of the already known information.

This cannot be true, for two reasons: Bob is already married to Marilyn, and Janet is already married to John. Therefore, the information in the Inventory shows an inconsistency in the data. For this reason, the importer will not allow this information to be entered. If for some reason it is now true (for example, Bob and Marilyn, and Janet and John got divorced), those relationships would have to be corrected before the previously rejected fact of Bob and Janet being married could be entered into the Inventory.
Another error situation might not be so obvious: Suppose that John’s father is entered into the Inventory—he is called Peter (Peter has child John). This would be perfectly acceptable within the Inventory. But now attempting to enter that David is Peter’s father (David has child Peter) highlights an error (see Figure 9.8).

This cannot be true. Peter is John’s father, John is David’s father, and David is Peter’s father. Without trying to turn this into a sort of science fiction, time-travel paradox, the situation is impossible. This circular reference makes it invalid within the Inventory. The information will not be permitted in the Inventory because it will make the information inconsistent.
Triples not only allow the capture of this information in an unambiguous and consistent manner; they also enable you to check the data for consistency.
Triples are extremely useful for containing and supporting all the knowledge that is found about the project, but the Inventory itself needs a structure beyond that of the simple triples. Any system of this type needs to introduce some additional structure to make it maintainable and usable.
IBM has built and patented the structure for such an Inventory, as reproduced in Figure 9.9.
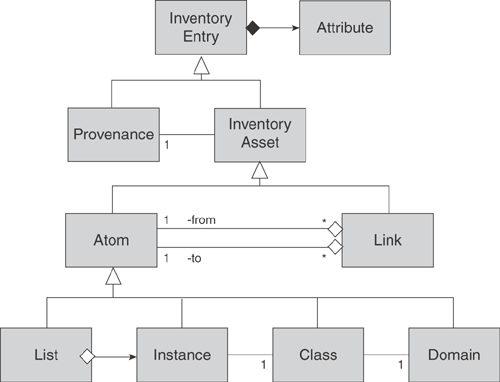
The diagram is rather technical because it is expressed in UML, but the following key points are important:
Inventory assets can be either atoms (also known as nodes) or links (also known as properties, arcs, or predicates).
A link is a directional relationship between two atoms (from and to).
Each asset in the Inventory (whether an atom or a link) must have a provenance to describe where it came from and when.
Different kinds of atoms can correspond to things, lists of things, types of things (classes), and areas of the Inventory (domains).
Every instance atom that represents a concrete item (a thing) must belong to a class atom that describes its contents and behavior.
Each type of thing in the Inventory (the class atoms) must be ascribed to a domain (Business, Logical, Physical) that describes its position in the hierarchy of models and information.
Although not shown, each Inventory entry has a mandatory “from” and “to” set of time-based attributes that describe the valid period(s) for that entry. This gives the Inventory a necessary time dimension, to allow for evolution over time.
These simple rules give an overall shape to the Inventory, making it easier to understand and deploy on projects. This is actually the meta-meta-model of an Inventory—it describes the high-level language of atoms and links. As you have already seen, almost any concept can be described using this approach—this structure is still very simple and extensible. This diagram does not define or impose a particular structure or specific language on the Inventory—individual projects can design and determine those (as with the metamodel in Figure 4.8 in Chapter 4, “The Trunk Road to the Brain”).
Over time, Inventory languages (ontologies) likely will arise for different purposes. A single ontology for IT might be achievable one day, but for many of the reasons covered earlier when discussing the development of a grand universal tool, a powerful and all-embracing formal language will not likely be created. For an example of a language that we have used with the Inventory, see the Business Architecture metamodel in Figure 4.8 in Chapter 4.
The next short section outlines some of the key technologies used in the Inventory and is necessarily technical in nature. Readers who don’t like acronyms and XML might want to jump to Step 2, where we move on to talk about how the Inventory is put together.
The content of IBM’s Inventory is expressed via the Web Ontology Language (OWL) and the Resource Description Framework (RDF). Both come from a family of frameworks created by the World Wide Web Consortium (W3C) to enable the semantic Web. RDF enables resources and relationships between resources to be described in XML form. RDF Schema extends this by incorporating the capability to express properties, classes, and hierarchies. OWL takes this yet further and provides a mechanism of describing relationships between these classes. The RDF metadata model enshrines the principle of the triple (subject, verb [or predicate], object), as you might expect.
The Inventory data can be stored in standard relational database management systems such as DB2®, SQL Server, or Oracle in specially configured triple stores.
When extracted, the Inventory data can be turned into text (a serialized form) for import or export to other Inventories. One such form is N-Triples (similar to the table view of the subject, verb, object list shown earlier in Table 9.2); another is the widely used RDF/XML. Listing 9.2 gives the simple UML example shown earlier in Figure 9.2 translated into RDF/XML. You don’t need to understand this example to understand the rest of this chapter; it merely illustrates what an Inventory looks like in text form. (Such a form is not intended to be easily human readable.)
Example 9.2. Translation of Figure 9.2 into RDF/XML
<?xml version="1.0"?> <rdf:RDF xmlns="http://www.elephanteaters.org/example#" xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:xsd="http://www.w3.org/2001/XMLSchema#" xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#" xmlns:owl="http://www.w3.org/2002/07/owl#" xml:base="http://www.elephanteaters.org/example" > <rdf:Description rdf:about="#isOfferedBy"> <rdf:type rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Property"/> <rdfs:range rdf:resource="#System"/> <rdfs:domain rdf:resource="#Interface"/> </rdf:Description> <rdf:Description rdf:about="#ViewEditor"> <rdf:type rdf:resource="#System"/> <uses rdf:resource="#I_InventoryManagement"/> </rdf:Description> <rdf:Description rdf:about="#System"> <rdf:type rdf:resource="http://www.w3.org/2002/07/owl#Class"/> </rdf:Description> <rdf:Description rdf:about="#Interface"> <rdf:type rdf:resource="http://www.w3.org/2002/07/owl#Class"/> </rdf:Description> <rdf:Description rdf:about="#offers"> <rdfs:domain rdf:resource="#System"/> <rdf:type rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Property"/> <rdfs:range rdf:resource="#Interface"/> </rdf:Description> <rdf:Description rdf:about="#uses"> <rdfs:range rdf:resource="#Interface"/> <rdf:type rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Property"/> <rdfs:domain rdf:resource="#System"/> </rdf:Description> <rdf:Description rdf:about="#System_A"> <rdf:type rdf:resource="http://www.w3.org/2002/07/owl#Thing"/> </rdf:Description> <rdf:Description rdf:about="#I_InventoryManagement"> <rdf:type rdf:resource="#Interface"/> <isOfferedBy rdf:resource="#Inventory"/> <isUsedBy rdf:resource=" "#ViewEditor"/> </rdf:Description> <rdf:Description rdf:about="#Inventory"> <offers rdf:resource="#I_InventoryManagement"/> <rdf:type rdf:resource="#System"/> </rdf:Description> <rdf:Description rdf:about="#System_"> <rdf:type rdf:resource="http://www.w3.org/2002/07/owl#Thing"/> <rdf:Description rdf:about="#isUsedBy"> <rdf:type rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Property"/> <rdfs:domain rdf:resource="#Interface"/> <rdfs:range rdf:resource="#System"/> </rdf:Description> </rdf:RDF>
The area highlighted in bold is an example triple that says the Inventory (which is a System) offers the Inventory Management interface.
An alternative way of representing this information is as an RDF graph (see Figure 9.10). Unfortunately, you might not find this representation particularly helpful.

The RDF (even in graph form) might seem quite unwieldy compared to the simple diagram or tables shown earlier in this book. Why would such a verbose mechanism be used to express the Inventory? The key reason is that the Inventory needs to be used as the base information for multiple transformations. The W3C frameworks are based on XML, so there are readily available technologies, tools, and skills for transforming the Inventory data into what we want (such as XSLT). Ultimately, the definition of the Inventory could be proprietary, but it would be far more useful if information could easily be exchanged between Inventories (especially during company merger talks). As Inventories become common, it would not be in the interests of our clients or the IT industry if the Inventories were proprietary or closed. The W3C technologies enable us to export and reimport Inventory data easily and exchange data among multiple industry-standard tools.
The emergence of the semantic Web (in which the natural language information on the Web is enhanced by including formal metadata that enables software agents to use and automatically generate it) means that future IT and Web services will want to be augmented with the kind of data we stored in the triples. The W3C frameworks should enable an Inventory user to achieve a leadership position in this new area. Indeed, RDF, RDFS, and OWL make the Inventory a key mechanism for sharing data and services, as well as consolidating and modernizing it. This is very different from the proprietary mentality of the CASE tools of the 1990s and will be central to the success and business cases for implementing Brownfield tooling.
For nontechnical readers who read the last bit, thanks for staying with us! That page of RDF/XML extract is the only codelike bit in the book (although we do refer to it once more).
To understand how the different Views can be merged to form a single Inventory, it is worth taking a closer look at the component model example discussed earlier.
In this example, two separate source programs (View A and View B) show how two separate Views can be combined to create a single Inventory. The example is deliberately simplistic but gives a good idea of how the Inventory is created from separate but related sources of information.
View A is the Inventory program itself. First, the parsing process has turned the program into an AST. Looking for the right patterns in that source program makes it relatively straightforward to identify that the program offers an Inventory Management interface.
The program that forms View B, the View Editor, is treated similarly. The AST created from that program contains another interesting pattern. The View Editor program now offers only one interface that returns the View; it also calls two other programs. One of these interface calls is used to publish the content of the View; the other is used to send the View to the Inventory.
Figure 9.11 shows the information that has been extracted from analyzing each of these independent source code files expressed as two separate Views.

When the parsed program is imported into the Inventory, View A translates into two atoms and two links. (The single arrow is translated into two offers and isOfferedBy links that enable the relationship to be navigated easily in both directions.)
On the subsequent import of View B, the import program registers a shared atom between Views A and B. This shared atom is I_InventoryManagement. Upon recognizing this, the Inventory merging process discards the duplicate atom from View B and links the new information from View B to the entry from View A. The View B atom represents a “called” interface, not the actual interface itself, so the View A atom takes precedence.
The end result is a single merged Inventory expressed in RDF as represented in Figure 9.12.[1]
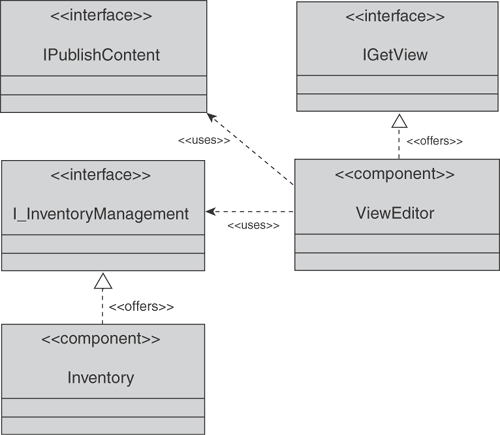
During this merging process, the combination of Views could result in a problem. These problems are often identified by enforcing the cardinality of allowed relationships within the Inventory.
When constructing the Inventory, a formal ontology (or language) is created for the Inventory to use. This ontology describes all the valid relationships allowed between different types of atoms and even specifies whether the relationship is optional or mandatory. If it is mandatory, the ontology specifies how many of these kinds of relationships should exist.
In the previous example, the formal relationships of “uses” and “offers,” plus their opposites, isUsedBy and isOfferedBy, were defined to be in place between components and interfaces.
The Inventory created in Figure 9.12 is perfectly consistent with this and would not raise any errors upon merging. But what happens if it is mandated that all interfaces must be offered by at least one component—that is, for the model to be complete, something must actually implement what the interface is promising to do?
If this is mandated, the resulting merged Inventory in Figure 9.12 has information of an IPublishContent interface, but this interface has no implementing component—nothing “offers” the interface.
This could be a sign of incomplete data, or it might actually mark the edge of knowledge of the Inventory. However, if there must be at least one isOfferedBy relationship for every interface atom in the Inventory, then the Inventory is invalid. The missing relationship will be highlighted so that it can be corrected by including another View (perhaps the source code of the Publishing program) or correcting a View to include or delete the missing information.
Clearly, the same logic applies not just for the cardinality of relationships (whether a relationship is optional or mandatory, and how many are allowed between different types of atoms), but also for the relationships themselves.
Sharp-eyed (or die-hard technical) readers might have noticed Listing 9.3 in the XML/RDF file reproduced earlier:
This states that isUsedby can be a relationship only from an interface (its domain) to a System (its range of targets).
If during processing, a View states that a component isUsedBy an interface, clearly the View is in error and must be amended.
The Inventory is essentially a multidimensional space with a time dimension. Information can be extracted from it via slices through that space and time. Visualizing it as a whole is not easy.
This is not surprising. By definition, the Inventory contains multiple Views, and the amount of information it contains would be beyond what a single person could understand. Nevertheless, it is possible to take many different—but always consistent—slices through the Inventory after it is built. These can be chosen as View-size slices that one person can comprehend.
The best slice to take varies, depending on the audience. The slice chosen might provide a View on the Inventory that differs from the other Views that were fed in. This ability to see consistent data in varying ways and at different levels of abstraction is the core strength of the VITA architecture.
Figure 9.13 shows an Inventory with Views being imported from a variety of sources. There are three sources of information used to feed in site survey information. (Luckily, in this case, there were formal design materials, so no code parsing is necessary.) The following information is shown being fed into the Inventory:
The infrastructure definition of the operational model (the infrastructure of the environment) is contained in an Eclipse-based tool called Architects’ Workbench.[2] To import this data into the Inventory, an Eclipse-based triple converter was used to migrate from the Eclipse Modeling Framework (EMF) to triples. The operational model also contains information about how the system infrastructure supports the realized components in the component model. (This information is represented in Figure 9.13 by the black circles in the Inventory.)
The business processes, business entities, and business process definitions are imported from WebSphere® Business Modeler. The naming convention used clearly indicates which use cases are being executed at which points in the business process. The export from this tool is in Business Process Execution Language (BPEL) and XML forms. Specially written Transforms convert this XML-based data into triples. (This information is represented in the diagram by the gray circles in the Inventory.)
Finally, the logical external design of the system in the component model (which comprises both component specifications and component realizations) is fed in from IBM Rational Software Architect (RSA). The component model also contains the full definition of the systems context so that all use case interactions—whether with users or systems (these would be identified as the primary and secondary actors in the Use Cases)—can be traced via sequence diagrams to operations on component interfaces. (This information is represented in the diagram by the white circles in the Inventory.)
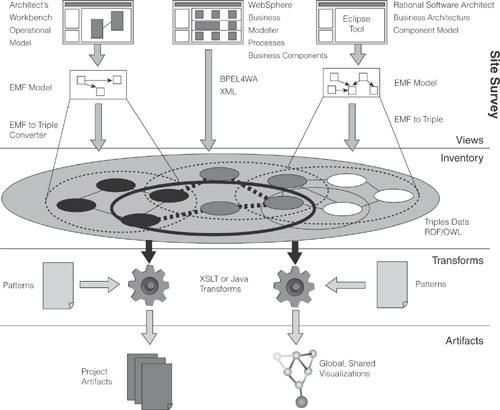
As this information is fed in, the links among the operational model, component model, use cases, sequence diagrams, and business process flows are established in the Inventory. In this case, it is lucky that the Inventory was always the target for this information; naming standards have been created and agreed upon in the tools, so the links between these sources of information can be automatically created (shown by the thick dotted lines between the circles).
Even if the information predates the intention to create an Inventory, the kind of traceability between documentation that the Inventory encourages is precisely the kind of information that should be looked for during static tests in the design process. Indeed, many people tacitly and repeatedly create such information in their heads during the design process (which, of course, takes time and introduces errors), so creating mappings or revising documentation in line with standards might be a good investment in its own right.
After the Inventory has been created by merging these sources, it is possible to extract information that was not present in the discrete Views. This is shown by the thick black circle within the Inventory. The information combined from all three sources can be extracted and used for a variety of purposes. This might include generating a performance model, checking the completeness of the operational and component models, generating deployment descriptors for Web services, and so on. The business architecture visualization perspective described in Chapter 4 can be produced from just such an extract from the Inventory. The list goes on and on.
The key aspect to grasp, however, is that all those outputs (including the visualization) can be generated from the Inventory information combined with patterns and templates. These outputs would also be absolutely consistent with the Inventory.
As any of the source Views change, the generated components are also quickly regenerated. Any new inconsistencies created by the updates are highlighted by the merging process of the Inventory. Clearly, this is a huge productivity and quality benefit for any large project because it massively reduces the communication overhead between teams. Different perspectives of this Inventory can be generated to help describe the problem to different audiences, to manage the complexity and set expectations. Importantly, these Views all look at the same problem and iron out inconsistencies when the Inventory is created. Everything can then be generated from the same consistent set of data. Using traditional means, on the other hand, would have required rewriting the information manually, often using multiple incomplete or inconsistent sources; this would introduce a source of error and maintenance overhead.
In addition, each entry in the Inventory has its own provenance (who created it, when it was created, what tool the information came from, and so on). As a result, the input of each atom or link can be traced back to the user and even the View that entered it into the Inventory. Because these Views include formal representations of the requirements for the solution, traceability from requirement through to generated Artifact is ensured.
Before we leave our description of the Inventory, we should consider one other important property: inference. We have shown that the Elephant Eater can suck in data from a wide variety of sources and interrelate it. If inconsistencies are spotted, they are highlighted at the time of import. A fair complaint about the Inventory, therefore, is that it contains a lot of interrelated stuff. How on earth can you see the forest for the trees? Well, some sources of data (for example, the formal architecture or design descriptions) might already be at a reasonable level of abstraction to be understood, but that is not likely true of undocumented source code.
Fortunately, the Inventory makes it possible to formally re-create architectural-level material from source code. Unlike the architecture pictures that are drawn early in a project and turn out to be incomplete, inaccurate, or simply massive oversimplifications of the truth, these pictures are precise and complete. (Even if they are high level, they can be precise and correct.) If the Views contain clearly structured data, the process of creating some architectural-level information is relatively trivial. Consider a simple example in Figure 9.14 in which the following relationships can be read:
The View Editor has a View Publisher component.
The View Publisher component uses the Inventory Management interface.
The Inventory Management interface is offered by the Import Handler component.
The Import Handler component is part of the Inventory system.
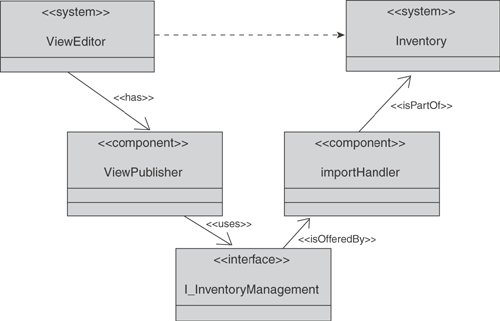
Clearly, it would be just as useful and accurate, but much shorter and clearer, to say “The View Editor uses the Inventory,” which is inferred via the dotted arrow at the top. Just as the Inventory can identify the wrong or missing relationships (see Step 2a earlier), it can infer such implied links at varying levels of depths or abstraction—it simply needs to be told which chains of relationships to look for. In this case, it would be a chain that could be written in English as follows:
A system has a component, which uses an interface, which is offered by a component, which is part of a system.
When it finds such a chain in the Inventory, the system can infer a new relationship, which is “system uses system.” This allows the complexity of the Inventory to be accurately summarized into higher-level drawings or architectures. Automatically providing such easy-to-absorb but precise information is a key strength of the Brownfield approach. These abstract links are different from those created from Views because their provenance is within the Inventory itself. As the Inventory is modified, these inferred links must be revalidated because the links that brought them into existence could have disappeared. This offers the further benefit that inferred links do not become a separate View to be maintained; the Inventory creates them after each merge.
Not all such Brownfield sites are sufficiently well documented to follow this approach. In these cases, the process of formal abstraction is a path of inference and builds up a picture layer by layer.
Today’s formal methods start trying to break down a problem by first ignoring what happens within the system and just understanding the external interactions that need to take place with the exterior of the system. You can think of the system as a black box. Once you understand the external interactions, you can look at what is happening inside the system; it is as if the light has been turned on for that system—it is essentially a white box. This white box can then be broken down into further components. These components themselves are seen as black boxes until the interactions are defined. Then their lights are turned on and their internals can be examined.
Essentially, today’s formal methods create a system by incrementally creating black-box descriptions of the solution required, working out the necessary internals to the next level of detail (white box) and then using those elements to frame a black-box description of what is required. The cycle then repeats. Figure 9.15 shows this black box, white box iteration (termed a “zebra” approach).
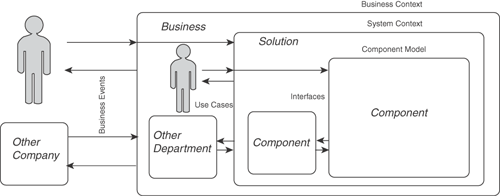
A typical large project follows this type of procedure, as shown graphically in Figure 9.15:
Identify the boundary of the business in a business context, and define all the business events that flow over that boundary (Black Box 1).
Using the business context as the scope and the business events as the starting point for processes, document the flow of work around the organization (White Box 1).
When the business processes are being created, identify the points at which the business process will need to access a system. Determine whether that access is within or outside the scope of the solution under design. Use these points to create the systems context and to identify the use cases that flow over the systems context (Black Box 2).
Determine from walking through and completing the use cases what capabilities the solution will need. Define high-level components that have distinct responsibilities and are relatively independent of each other in the component model (White Box 2).
For each of those components, describe a set of operations on an interface that tell what it must do. Describe the information it needs to do those operations and what the outcome of those operations is (Black Box 3).
For each of the components, identify how each of them will work in the application design (White Box 3).
This is a powerful approach because the successive black boxes tell the next layer down what they must do, without imposing a particular structure or solution.
Brownfield often appears to reverse Greenfield processes, so you won’t be too surprised to learn that precise architectures are abstracted from code by reversing these last three steps and putting the layers back on the onion where they have been lost.
For example, this Brownfield approach has been used to successfully impose a component model onto a solution that had grown (relatively organically) a formal data model and had no such structure. This encouraged some restructuring of the solution. As a result, the number of developers who could work on the solution in parallel increased.
The reversal of this process is as follows:
Identify the formal interfaces in the source code via the AST and pattern identification approach.
Analyze the calling and offering relationships in the source code to identify which areas are linked to each other.
Some components (such as a database) can be called from many points in the system, and these can easily be identified as calls between layers in the architecture.
After identifying the layers, you can identify the components within those layers. Certain elements within a layer call each other a lot; others hardly talk at all. Generating a UML diagram from the Inventory and loading it into a tool can help with this process because it requires some judgment as well as simple analysis. This resulting output is a new View that maps the programs into components.
The Inventory can now work out interface-level structures by inferring direct “uses” and “offers” relationships between the components that have been identified by inferring them from the interfaces within the source code (as shown in our simple example earlier in Figure 9.14).
These new components, with formally identified interfaces and relationships, can be used to refactor the existing system or, alternatively, to generate modern facades (such as Web services), advertising a structure that was always there but previously hidden, accidental, emergent, or forgotten. Before you get too excited, however, we should tell you that Brownfield is more akin to archaeology than magic. If there genuinely was no structure to begin with, only chaos, there would be little or no structure to uncover.
As you saw in Chapter 3, VITA optionally uses Transforms to create links between related concepts in the Inventory. Sometimes it is enough to simply indicate that two concepts are related in an informal way via a simple relationship. At other times, it might be advantageous to understand how to transform between them.
Each transformation is really three separate stages: classification of the data structures to be transformed, the actual transformation of those structures, and the application of any constraints. So what is meant by transformations?
Consider a simple example: Suppose that two systems within our enterprise have a date of birth stored. The first of these stores them in the American format of MM/DD/YY, whereas another system stores it in a format of DD/MM/YY, a format commonly used in Europe. Both represent the same date, just stored in a different manner. In this case, the transformation would have a relatively simple job of moving the first two sets of numbers to complete the transformation. So, transformations can be very easy. This likely would be a normal transformation that could be chosen from the Inventory as it’s a standard transformation. But suppose that it wasn’t.
The transformation is potentially very simple. It has one input (MM/DD/YY) and one output (DD/MM/YY). So it would be relatively easy to describe a transformation within the tooling to say what it has to do. Transpose the characters before the first / and the characters before the second /. A programmer could now create such a routine to do such a conversion. Because it is a relatively simple routine with minimal inputs and outputs and a simple description, it would be simple to develop. To avoid any programmer confusion, you could also specify some examples or test data to use with the appropriate results. For example, 12/21/07 becomes 21/12/07.
Assume now that the routine was written but seemed to fail when used on real data. It seems that the routine worked fine on the data when two characters were used, but not when one character was used to represent a month or day in the month. For example, 1/23/07 returned 3/21/07. The problem was not specified completely, and the programmer misunderstood and used literal positions for moving the data. This is a common mistake that frequently happens in system development. The description of the problem is often incomplete, and mistakes are then detected during testing.
The description is changed to state this and also give another few examples of data to convert (1/23/07 becomes 23/1/07). Now when the new routine is created, the Inventory can automatically test the transformation and reject it if it fails the test cases.
This simple example shows how transformations can be defined in a nonprogrammatic manner. It also illustrates how data transformation can be broken down into very small, simple, self-contained Transforms and can potentially be built anywhere. This is great when you are using a global sourcing model and one of the most difficult problems is precisely defining the requirements of what you want. This should be relatively simple here, and the Inventory tooling itself will provide an automated means of testing the results when completed.
Let’s extend the example slightly. Suppose that the format to convert from was the same, but the format to convert to was now DD/MM/YYYY. The day and month part of the transformation should be the same as described earlier; the difference here is that the year must now be converted from two to four digits.
If the year had to be converted from four to two digits, this would be extremely simple—the first two digits could just be dropped. However, in doing that operation, some of the original information is lost—the precise century that this date occurred. So, in reversing this operation and extending the year from two to four digits, we have to define some rules to make up this information.
If the same situation occurred in real life, it might be possible to make some assumptions and define this in rules to make up this missing data. For the sake of argument, assume that the original database contains only adults (over 18 years of age). You could use a 100-year window, 18 years behind the current year. Someone who had a year of 98 in the original data, would be assumed to be born in 1898 instead of 1998, because someone born in 1998 would not yet be an adult. This would work well in most cases for people up to the age of 118 years old. For the moment, that would seem a reasonable compromise. However, if the data was not all adults, that would make it correct for only people up to 100 years old. This might not be completely unreasonable, but you will be wrong a bit more often because there are more people of this age.
If the data was not even restricted to people who were currently alive, however, this solution would be totally unacceptable.
Although it might not be possible to determine the correct year with the birth date and the incomplete year specification, it might be possible to use some other information in the records to take a more educated approach to determining this year.
In looking through the available information, another field apparently was specified that contained a person’s age when he or she started dealing with the organization and the year in which this occurred (in four digits). The correct year of birth can be precisely determined using these three items of information. Although this is a very simple transformation, it illustrates that transformations are reversible. The simple date change in the first two-digit year can be reversed simply because no information is lost in the original transformation. In the case of changing a four-digit year to two digits, information is lost and the transformation may be reversed only by applying rules or combining data from a number of resources to re-create that information. However, in both cases the reverse transformation was possible.
This solution will work on dates of birth, but the same solution cannot be used for death dates, for example (although the same data could be used in a slightly different manner). Thus, it is important for the original data to be classified correctly before the transformation is defined. The original data would be classified as a date of birth and not just as a date. In this way, the correct transformation could be chosen for the correct date.
But there are really three parts to a transformation. The last of these is the application of constraints. These constraints determine whether the data that has been transformed will be included in the output. For example, a constraint could be applied so that bank account details are sent only if the person is applying for a loan; otherwise, that person will be left out. Although this is a very simple example, it again illustrates the basics of transformations.
To summarize, first, all data is categorized, then the Transforms are defined between these categories and other categorized data, and, finally, in defining the data sharing required between systems, the categories and Transforms are combined with constraints to determine exactly what is shared.
This Transform capability is often used when the Inventory is being used as a source of information to generate interfaces, gateways, enterprise service buses, or other forms of integration between systems. The concepts in System A and System B are mapped, and a simple reusable Transform is identified in the Inventory that can migrate the data from one format to another.
These atomic Transforms can be expressed as XSLT or as small programs that are then called upon when the Inventory generates an Artifact that needs to transform between two representations of the data or concept.
Artifacts were described in Chapter 3 to cover all outputs that can be generated from the Inventory information. Typically, these outputs include documentation, configuration, executables, and test Artifacts.
Documentation Artifacts are used to describe those outputs that are generated to describe the system, and even include the visualization Artifacts described in Chapter 4. Such documentation is always consistent with your solution and up-to-date.
Configuration Artifacts are used to provide the definition, setup, or control of products or systems within your IT estate. These may be for structures such as databases.
Executable Artifacts cover all generated Artifacts that are run within a computer system to perform a business task. This includes program code, user interface screens, interface definitions, or rules for business rules engines.
Test Artifacts are used for the testing of the output of the executable or configuration Artifacts. These may take the form of test scripts and the generation of the data required to test the system thoroughly.
Extracts can be produced from the Inventory—the Inventory can provide subsets of itself (usually represented by a single point in time and a “slice” through the Inventory data) to generate Artifacts.
These Artifacts are the standard stuff of Model Driven Development and Architecture, so we do not cover them in detail in this book. However, the capability to represent the Inventory in RDF/XML is a considerable boon because XSLT can create templates from which Artifacts can be generated. XSLT also ensures a clean separation between patterns and templates and the data from the Inventory.
Clearly, performing the site survey, buying tooling, and feeding information into the Inventory is a significant investment. The Inventory delivers its own benefits and pays its own way via the following:
Improved quality of Artifacts
Improved reuse of Artifacts and patterns at all levels
Improved conformance to patterns and architectures
Automated generation and unit testing of Artifacts
Earlier testing via visualization and early executable tests, for reduced cost of defect removal
Artifacts are not just simple perspectives or slices through the Inventory. The factory-based generator has been used to create all kinds of different Artifacts—for example, from data structures, interfaces Transforms, code, and even the documentation of the problem itself. Thus, the documentation always remains completely up-to-date and consistent. As described in ISO 9000, “You do what you document and you document what you do.”
The generated code Artifacts are tested automatically against validation code generated for this purpose. These tests are created from the same problem definition (via a different generation route) so that the generated tests’ coverage of the problem definition is known to be complete, and so that the data used in the tests (which is also generated) is consistent with what is expected. Negative testing (that is, testing values known to be outside the correct functioning of the component or interface) can also be performed.
This testing ensures that the solution does precisely what was expected—therefore, the problem has been correctly translated into a solution. Now, a system testing itself might seem poor practice, but these tests cover a large portion of what unit testing normally does in terms of industry best practices (that is, essentially, write a comprehensive test specification first and then write the code). Clearly, this automated testing cannot identify whether the description of the problem (the requirement) is wrong, although it can often identify that it is incomplete or inconsistent. Either way, this automation is a significant productivity benefit and removes defects early.
An additional benefit of Brownfield development is that because the exact composition of any generated solution is known (in terms of the data used to populate the pattern and the pattern[s] used), change impacts become manageable. Within the Brownfield approach, the impact of any change in requirement or design can determined by deriving all the affected components—and all the test cases needed to exercise the complete test coverage for a regression test.
As previously discussed, Brownfield is primarily an iterative approach for complex problems. As further requirements (normally, constraints) are discovered during testing, they can be added to the Views and the new version of the solution generated, with no degradation of the design or code.
In this chapter, we have offered some insight into what is contained within the tooling required to support Brownfield. The tooling is based upon open industry standards of XML, RDF, and OWL, which also are used to support the semantic Web.
The Brownfield tool itself does not support the development process; other tools are necessary for that. Instead, it imports information from other tools and links it together. Various importers have been written to convert the Views exported from the tools into the triples format that the Inventory supports. This combines the information from diverse tools that are used for different parts of the solution (for example, the component model, operational model, and business process model).
Such formal documentation rarely exists on legacy systems, so code can even be parsed to reverse-engineer the documentation required. This is not a simple code conversion; it builds up the underlying patterns and structures within the legacy code by using AST.
All this information is converted into the simple triple structure used within the Inventory. To make the information more useful and easier to navigate, a simple meta-meta-model extends the triple model to provide more shape to the Inventory. Provenance is also added via this meta-meta-model so that, for each item in the inventory, its source version and time validity is always known.
Solutions also must produce their own ontology (language) in these triples, to provide further structure. In the future, these could become consolidated into standard ontologies perhaps grouped by industry, which will further simplify the process of Brownfield development.
When the information is contained within the Inventory, it is ensured to be consistent because it is validated upon entry. This large volume of information provides a baseline of the information provided and also allows further knowledge to be obtained. Either information can be inferred from the existing information or gaps in areas of knowledge can be identified.
Transformations are defined between data so that the Inventory can identify the transformations required in transferring data between different systems.
Finally, the most powerful part of the Inventory is that it can be used to generate a variety of Artifacts that document, test, or provide the physical solution. This means that documentation can be created at the appropriate level for different audiences so that the audience will find it easier to understand the information. Artifacts used in the solution will have their own test Artifacts generated automatically. Whatever Artifacts are produced, they are always up-to-date and consistent.
In building an Elephant Eater, a tool is created that can handle the complexity of modern systems. It does not assume or ignore information. Solution development becomes an engineering process; it is not determined by a throw of the dice. Indeed, Brownfield provides a mechanism for agile, iterative development in the most complex environments. The iterative refinement of a system can be from both an operational and a functional perspective, with the capability to receive timely feedback on requirements or design changes.
Implementing an Elephant Eater is a nontrivial task, but Brownfield pays for itself through the generation of Artifacts and the early discovery of requirement defects. Unlike the benefits of enterprise architectures and other formal innovations such as systems engineering, the benefits of Brownfield can be easily measured against conventional approaches. Fortuitously, the application of the Brownfield development approach need not be adopted across the board, but may be prioritized on the key areas where the initial benefits are greatest, thus offsetting much of the initial investment and inevitable initial productivity hit of a new process and technology. These key areas are those that involve high degrees of code duplication—the standard fare for MDA—combined with areas of poor knowledge, where standard MDA fears to tread. In the final chapter, we examine these areas and describe how Brownfield can be deployed on a project.
| 1. | The technical reader will recognize the diagram in Figure 9.12 as UML instead of an RDF-based graph. We think the RDF graph is less readable, but the Inventory has been used to generate such UML diagrams from parsed source code. |
| 2. | The Architects’ Workbench is an internal IBM tool based on the open Eclipse platform used to capture information and produce architectural Artifacts. Because it captures this information in a formal manner, this information can be imported into the Inventory relatively simply. |
The following references apply to the chapter material in general.